所有文章
 cnBeta全文版
cnBeta全文版
**日前,广汽丰田凯美瑞智驾版正式上市。此次共推出了双擎2.5HG尊贵智驾版和双擎2.5HXS运动Plus智驾版两款车型,指导价21.98万元起,购车提供价值5万元综合权益。**     **与在售车型相比,智驾版标配TSS 3.0 PRO智能驾驶辅助系统,新增LCA变道辅助、FCTA前方交通穿行警示、DMC驾驶员状态监测等功能。**  外观方面,智驾版基于现款升级,双擎2.5HG尊贵智驾版采用无边界格栅,双擎2.5HXS运动Plus智驾版配备19英寸轮辋和专属运动套件。 内饰延续现款设计,配备12.3英寸悬浮式中控屏、液晶仪表、HUD抬头显示,搭载Toyota Space智能座舱,支持多种手机互联功能。 动力上,**智驾版搭载2.5升混动系统,综合最大功率169千瓦,匹配E-CVT变速箱。同级竞品包括广汽本田雅阁和东风日产天籁等。** [查看评论](https://m.cnbeta.com.tw/comment/1491660.htm)

微软已放弃在俄亥俄州利金县建设数据中心的计划。该公司告诉《哥伦布快报》,它不再推进之前在纽奥尔巴尼、希思和希伯伦的三个数据中心园区投资 10 亿美元的计划。  微软在新阿克巴尼拥有的土地– Google地图 这是微软一系列数据中心项目取消的最新一例。近期有报道称,该公司已撤回了美国和欧洲多达2GW的数据中心项目。不久后,又有报道称,亚太地区和英国也取消了数据中心项目。 早在2024 年 10 月,微软就宣布计划在俄亥俄州中部投资 10 亿美元建设数据中心园区。 当时,新奥尔巴尼数据中心园区已获得 4.2 亿美元的专项拨款,同月市议会批准为微软提供15 年的减税优惠。 该数据中心计划占地 245000 平方英尺(22800 平方米),位于 Beech Road 和 Licking-Franklin 县界之间、Fitzwilliam Lane NW 以北的一块 200 英亩的土地上,建设时间为 2025 年 7 月。 希思和希伯伦数据中心的具体位置尚未公布,但微软此前已在希思索恩伍德大道(Thornwood Drive)沿线购买了227英亩土地,并在希伯伦高街(High Street)购买了223英亩土地。希思开发项目计划于2025年夏季开工,希伯伦数据中心计划于2026年开始建设。 微软发言人在接受《哥伦布快报》采访时谈到撤回俄亥俄州项目的决定时表示:“我们将继续根据我们的投资策略评估这些地点。我们真诚感谢俄亥俄州政府官员的领导与合作,以及利金县居民的支持。” 该公司随后补充说,它将继续拥有这片土地,并计划在未来某个未指定的时间继续开发。与此同时,其中两处土地将保持适宜耕作的状态,该公司正在推进道路和公用设施升级的协议。 关于微软取消数据中心项目的猜测不断增多,外界议论纷纷。券商TD Cowen率先关注此事,该公司分析师推测,“租赁取消和容量推迟表明,相对于当前的需求预测,数据中心供应过剩。” 到目前为止,微软的立场一直没有改变,该公司向出版物提供了以下笼统的声明:“得益于我们迄今为止所做的大量投资,我们完全有能力满足当前和不断增长的客户需求。仅去年一年,我们新增的产能就超过了历史上任何一年。虽然我们可能会在某些地区战略性地调整基础设施建设的速度或规模,但我们将继续在所有地区保持强劲增长。这使我们能够投资并配置资源,以促进未来的增长。我们本财年在基础设施建设上投入超过800亿美元的计划仍在按计划进行,我们将继续以创纪录的速度增长以满足客户需求。” [查看评论](https://m.cnbeta.com.tw/comment/1491658.htm)

Google DeepMind 和 Google Cloud 与 Sphere Studios、Magnopus、华纳兄弟等公司合作,在拉斯维加斯 Sphere 娱乐场 160000 平方英尺的球形巨型屏幕Sphere 上重现了拥有 86 年历史的经典作品《绿野仙踪》 。  《绿野仙踪》是一部于1939年上映的剧情片,因采用特艺彩色技术而闻名。影片使用了一台三色特艺彩色35毫米电影摄影机,呈现出影片中黄砖路和翡翠城等鲜艳的色彩。 Google在一篇[博客文章](https://blog.google/products/google-cloud/sphere-wizard-of-oz/)中表示,他们使用了“经过特殊调校”的Veo、Imagen 和Gemini 生成式人工智能工具来完成这项工作。Google的多个团队和合作伙伴开发了一种基于人工智能的全新“超分辨率”工具,可以将 1939 年的微小胶片画面转换成“超高清”图像,并将其呈现在 Sphere 中。 值得一提的是,拉斯维加斯Sphere 拥有一块巨大的16K LED屏幕,这是迄今为止世界上分辨率最高的屏幕。这块屏幕环绕着球体内部,可容纳17600名观众观看正在播放的内容。 这些团队以原版 102 分钟的影片为基础,并利用拍摄脚本、制作插图、照片、布景计划和乐谱等档案作为补充材料。 通过一种称为微调的过程,所有材料都用于训练 Veo 和 Gemini 了解原始角色、其环境以及其他制作元素(例如特定场景的摄像机焦距)的具体细节。 Google和其他团队面临的一个复杂问题是,如何将原始的颗粒状图像放大,以适应 Sphere 16K x 16K 的分辨率。“团队可不是简单地输入几个 AI 指令,然后集体敲击几下就能完事的,”Google表示。 传统电影会使用镜头切换来移除特定场景中的人物。然而,Sphere 的体验要求所有元素以超现实的细节组合在一起。 虽然Google可以使用传统的 CGI 来处理缩放问题,但它表示,有效地填充其余场景并非易事。团队使用 AI 绘制技术来扩展背景,并以数字方式重建原本不会出现在同一个屏幕上的现有角色。 新闻稿称:“团队开发了创新的叙事技巧,即使传统剪辑方式需要进行剪辑,也能让多个角色长时间出现在屏幕上。这增强了观众的沉浸感,让他们感觉自己仿佛置身于史诗般的旅程之中。 ” Google Cloud 提供了高度可扩展且经过 AI 优化的基础架构,以处理该电影项目的海量数据和计算需求。迄今为止,整个项目已处理了超过 1.2PB 的数据。 该项目邀请了Google及其合作伙伴的数千名研究人员、程序员、视觉特效艺术家、档案管理员和制作人参与。他们历经数月,运用人工智能、传统视觉特效和电影技术,重新构思了这部1939年的经典作品。《绿野仙踪》将于今年8月28日登陆拉斯维加斯环球剧场。 [查看评论](https://m.cnbeta.com.tw/comment/1491652.htm)
 人人都是产品经理 · 刀客
人人都是产品经理 · 刀客
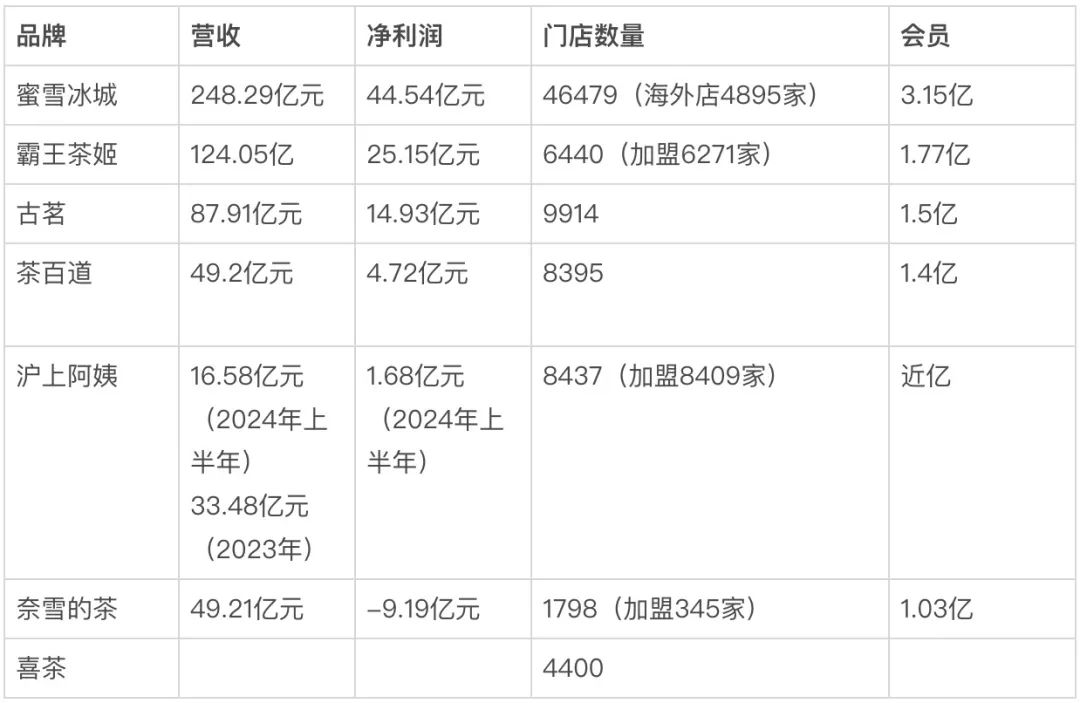
<blockquote><p>随着亚马逊Prime Video推出低价广告套餐,Netflix等传统流媒体巨头的广告价格大幅下降。本文将分析流媒体广告市场的现状,探讨亚马逊如何凭借其商业生态优势搅动市场格局,以及Netflix等平台面临的挑战和应对策略。</p> </blockquote>  ## 01 要说在美国广告市场里,未被巨头垄断且最为活跃的板块,应该就是流媒体了。 根据群邑智库的数据,2025年CTV广告将以20%的增速,冲刺460亿美元的市场规模。到2029年,全球流媒体电视的广告收入将占电视总收入的37.5%。 蛋糕是越来越大。可以说在美国的广告市场,流媒体电视是增长前景最好的赛道之一,也是竞争最为充分的领域。目前的现状是,流媒体广告市场已经陷入到了价格战的泥潭之中,而今年尤甚。 Netflix的广告价格降幅最大。在2022年,Netflix刚开始发展广告业务的时候,CPM价格是60−65美元,尽管高得离谱,却也还供不应求。 根据emarketer的预测,2024年第一季度至2025年第二季度之间,Netflix的平均CPM将从42.14美元跌至31.05美元,降幅达26.3%。也就是说,到今年二季度,Netflix的广告价格与三年前相比,已然是腰斩了。 其他头部的流媒体服务也遭遇着同样的境遇,华纳旗下的MAX一路下跌,不过还能和Netflix一样,体面地保持30美元以上的售价。而迪士尼旗下的D+,以及NBC环球旗下的Peacock,CPM价格预计到今年二季度都将跌破30美元。 从市场的价格曲线来看,各家的价格区间越来越接近,价差从最高的9.43美元,将在今年二季度降到5.75美元,这意味着流媒体的广告价格战在今年进入胶着状态。 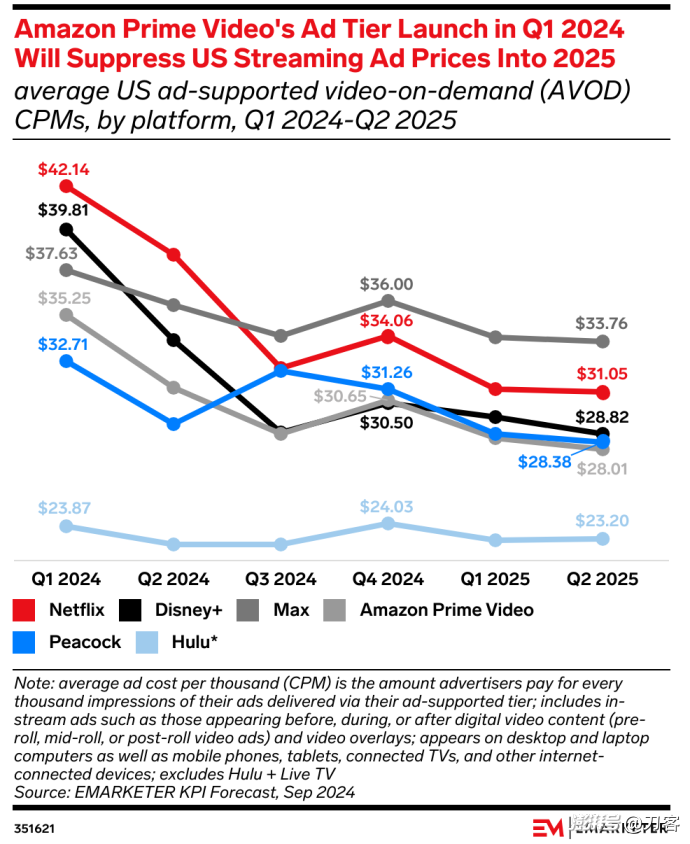 ## 02 很多人对流媒体的概念不是很清楚,比如流媒体电视广告和CTV(联网电视广告)。两者经常混淆,甚至被交替使用。也确实,两者在很多情形下有很大的交集,比如电视剧的贴片广告,可以说是CTV广告,也能认为是流媒体电视广告。 不过两者的区别在于,流媒体广告更多是内容层的广告,比如通过互联网传输的广告,可在电视终端播放,侧重内容分发形式。 CTV广告还包括设备层的广告。所以,电视上的开机广告,属于CTV广告,而不是流媒体广告。 在美国流媒体的广告市场里,还可以进一步为SVOD和AVOD两个阵营: **1、SVOD(Subscription Video On Demand订阅型视频点播):**用户通过付费订阅获得独家内容的访问权,平台提供无广告或者少广告的内容体验,依赖稳定的订阅收入支撑高成本原创内容制作,典型平台如Netflix和HBO。 **2、AVOD(Advertising-Based Video On Demand广告型视频点播):**通过免费内容吸引大量用户,依靠广告曝光盈利,如YouTube和Hulu,适合价格敏感用户,但每用户收入较低且内容多为非独家。 现在美国流行一种**FAST流媒体服务,即FreeAd-SupportedStreamingTV**(广告支撑的免费流媒体电视),它是AVOD流媒体的子集。福克斯和派拉蒙等传统媒体公司分别通过Tubi和PlutoTV提供FAST服务。Roku、LG、三星和Vizio等电视设备制造商也拥有自己的FAST平台。我做了一个图示,表示各个电视广告媒介的关系。 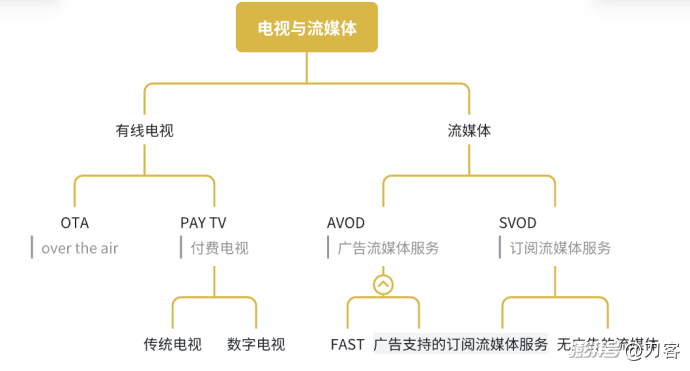 其实从这个图表中,我们可以看出这次价格战的动因了。 - 广告库存量剧增,这是供给侧的基本因素。 - 亚马逊primevideo搅局,这是价格战的直接原因。 - FAST电视越来越受欢迎。 ## 03 简单说下FAST吧,它锚定了流媒体CPM价格的下限。FAST的CPM一般在10至15美元之间,如果以保量的方式购买,价格甚至会更低。 这两年它确实很火,目前FAST在美国用户的渗透率达三分之一。不过FAST和订阅流媒体,颇有些井水不犯河水的意思,它对流媒体价格战的影响并不大。 因为它们只占电视总观看时间的一小部分。尼尔森有一份数据,2024年4月,头部的FAST平台Roku占电视总观看时间的1.0%以上,Tubi占比最大,也只有1.7%。 我认为今年价格战越打越凶的一个更基本的原因是供给的增加——**SVOD平台广告库存的供应量剧增**。 相比有线电视(linerTV),美国流媒体服务的进入门槛还是比较低的。它不需要单独铺设电缆光纤,通过云计算服务(如AWS)和开源流媒体解决方案,就能以较低成本搭建平台。 当然,美国有相对宽松的政策环境,1996年的《电信法案》打破行业壁垒,允许电信、互联网和传统媒体公司跨界竞争,传统有线电视受到冲击。这不仅催生了Netflix等早期玩家,也为小众流媒体玩家的进入铺平道路。 当下美国的流媒体市场发展,有些像早些年的杂志媒体,除了头部的大众类媒体,更多的垂直化、窄众化的流媒体平台涌现出来,并且活得很好。 比如AMC旗下专注于英国悬疑剧集的AcornTV,成为美国流媒体中用户流失率最低的平台之一。Shudder则深耕恐怖惊悚题材,他们的制作成本相比Netflix等大平台很低,比如备受好评的《夺魂连线》还用家用设备远程制作的,成本十分低廉,实现了现金流回正。 全球流媒体数据科学公司BBMedia有一份研究:2024年,全球共推出了56个流媒体平台,而美国成为新增流媒体平台数量最多的国家,去年共有25个流媒体平台在美国上线。截至2024年底,美国有流媒体平台总数达402个,2025年数量还会增加。 越来越多的流媒体玩家,是广告库存增长的其中一个原因。 另外一个更重要的因素是,Disney+、Netflix、Max等订阅流媒体平台,也推出了含广告的订阅套餐,进一步扩充了新的广告库存池。 BBmedia的数据,截至2024年前三季度,北美地区主要平台广告套餐用户占比均创新高:迪士尼Disney+达31%、PrimeVideo平台32%、华纳兄弟探索集团旗下Max平台25%,连长期抵制广告的Netflix也突破22%关口。 从用户端看,选择广告计划的订阅流媒体观众的比例正在增长。根据Antenna的数据,这一比例从2023年第一季度的39%上升到2024年第一季度的56%。2023年至2025年间,美国人每天观看CTV的时间将增加20分钟,这大大增加了市场上的广告库存数量。 2024年上半年,程序化广告公司FreeWheel的数据显示,投放的美国联网电视(CTV)广告展示量同比增长14%。 ## 04 如果说库存增加是价格战的一个基本因素,那么亚马逊的搅局介入才是一个更直接的原因。 2024年1月,亚马逊旗下的PrimeVideo推出了含有广告的订阅套餐,亚马逊的CPM定价约为35美元,远远低于Max、Netflix和Disney+的收费。 亚马逊之所以敢于在流媒体领域打价格战,是因为**亚马逊有能力把PrimeVideo的CPM成本压低,而Netflix们做不到。** 我将之总结为三个能力: - **商业化的扩容能力;** - **广告转化能力;** - **库存消耗能力。** 先说库存的扩容。 2024年1月起,亚马逊把广告设为Prime Video默认选项。这一招直接把所有Prime会员默认划入广告套餐,用户想跳过广告得额外付钱(2.99美元),这种捆绑式打法明显是为了快速扩大广告库存,毕竟Prime会员基数庞大,哪怕只有小部分人懒得升级无广告版,也能瞬间让Prime Video的广告覆盖量冲上行业前排。 研究公司MoffettNathanson的数据,PrimeVideo仅仅在2024年就为美国CTV市场增加约500亿次广告展示。 而Netflix虽然也推广告套餐,但始终保留无广告的高价选项,用户得主动选择带广告的便宜档位。 作用上,亚马逊走是生态捆绑的老套路,靠电商会员的惯性吃红利——很多人本来就是为了免运费才开Prime,对视频里的广告容忍度更高。 最狠的是用户体验差异。Prime Video的广告已经渗透到暂停画面,甚至准备搞可购物广告,明显在学国内视频网站的套路。而Netflix的广告还守着传统电视那套,每小时只插4-5分钟,生怕惹毛老用户。说到底,亚马逊把视频当电商流量入口,广告怎么塞都不心疼;Netflix却得端着内容王者的架子,生怕广告砸了招牌。 目前仅45%新用户选择广告套餐,广告库存依赖用户主动转化,规模化效率与成本优势弱于亚马逊。 再看广告的转化能力。 即使亚马逊和Netflix有类似的广告位,有相同的人群包,即使如此,亚马逊视频的广告流量与Netflix也是不同的。 亚马逊依托Prime会员的电商行为数据(如购物历史、搜索关键词、加购未购记录),有远超Netflix的精准定向,这能放大流量的转化能力。 流量转化能力如何影响CPM价格的呢? 这背后的逻辑是:更高的转化效率意味着广告主能以更低的CPM实现同等ROI。假设传统流媒体CPM为50时,ROI为100,亚马逊通过数据优化后,即使CPM降至30,仍能通过转化率提升保证ROI达到100+。因此,亚马逊可主动降价仍保持广告主预算流入。 最后说库存的消耗能力。 Netflix初期仅服务品牌大客户,这些客户只喜欢掐头去尾,一些质量不怎么好的流量就被闲置了。虽然Netflix也接入了程序化广告平台,比如The Trade Desk、Magnite以及微软的Xandr平台等,但显然自研广告系统更能实现「内容场景+用户偏好」的精准匹配,提升库存的销售效率。 亚马逊可以通过程序化广告放量,借助自己的广告平台(DSP)降低中小广告主门槛。比如一个芝加哥的瑜伽工作室,可能只愿意花15美元的CPM定向周边5公里用户,这种长尾需求通过程序化系统自动匹配凌晨时段或小众剧集的剩余广告位。通过把海量中小广告主纳入竞价系统,亚马逊能加速广告的库存消耗效率,进一步拉低CPM价格。 归根结底,流媒体平台的广告竞争是内容的比拼,也是商业效率的较量。 Netflix面对亚马逊的介入明显有些力不从心——亚马逊借着电商基因把流媒体广告和电商数据整合,硬生生把流媒体的竞争逻辑拉到了自己定义的轨道上。单纯依赖内容优势的Netflix们,还能靠什么守住阵地? 这也昭示着:在流媒体战场上,拥有完整商业生态的平台才能掌握定价权。 这也让我想到了阿里和优酷。当年阿里妈妈将优酷商业化团队整合在一起,也是这个逻辑,不过为什么阿里没有像亚马逊一样在流媒体领域大杀四方呢? 哈哈,这可能是另外一个故事了。 作者:刀客,公众号:刀客doc 本文由 @刀客 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

我国在应急救援装备领域取得重大突破——**由中船海神公司联合中国科学院等机构共同研发的全球首款急救转运无人机正式问世。**该无人机集成了多项尖端医疗功能,包括生命体征监护、呼吸支持、液体输注、自动除颤等完整急救系统,同时配备环境监测和远程视频监控模块。 其卓越的环境适应性令人瞩目:**可在-25℃至46℃的极端温度范围、海拔5000米的高原环境,以及6级海况的海上条件下稳定运行,实现精准搜救、现场急救与快速转运的一体化救援。** 技术参数显示,这款无人机起飞自重600公斤,有效载荷达300公斤,具备自主航线跟踪和悬停功能,同时支持地面站遥控操作。 **其多场景适用性尤为突出,不仅能满足战时伤员后送需求,还可广泛应用于传染病防控、自然灾害救援等突发事件中的危重症患者转运救治。** [](//img1.mydrivers.com/img/20250409/b3663e0b76a24e4d91311c112ae423e2.png) [查看评论](https://m.cnbeta.com.tw/comment/1491650.htm)

博主Majin Bu晒出了iPhone 17 Air的机模,**对比iPhone 16e,iPhone 17 Air更薄,但是其摄像头凸起要比iPhone 16e更严重。**据悉,**iPhone 17 Air机身厚度在5.5mm左右,含摄像头凸起的总厚度约为9.5mm,这是苹果史上最薄机型,相比之下,iPhone 16e的机身厚度是7.8mm。** [](https://img1.mydrivers.com/img/20250409/9f666fa5d32f460bb724460c0ce04c03.jpg) 另外,iPhone 17 Air采用横置相机模组,相机DECO神似条形跑道,后置一颗4800万像素摄像头,正面依然是灵动岛屏幕,支持ProMotion智能刷新率调节。 [](https://img1.mydrivers.com/img/20250409/e8781a1ea54a4f2faaee2b2c7ddc7743.jpg) 核心配置上,iPhone 17 Air配备6.6英寸显示屏,同时搭载自研基带芯片C1,首发全新的A19芯片,电池容量不到4000mAh。 值得注意的是,因iPhone 17 Air的设计过于超薄,苹果没有预留物理SIM卡槽,仅支持eSIM,此前中国联通内测了iPhone eSIM功能,这意味着国行版iPhone 17 Air eSIM有望支持联通运营商。 该机将在9月登场,它将取代Plus机型,和iPhone 17、iPhone 17 Pro、iPhone 17 Pro Max同台亮相。 [](https://img1.mydrivers.com/img/20250409/d27fbecabb324118babf1c58cdb48d02.jpg) [](https://img1.mydrivers.com/img/20250409/66dafd7d09ab4c7b9528570e4ce76839.jpg) [](https://img1.mydrivers.com/img/20250409/efb1b69de473467a8b70a9aab713916d.jpg) [](https://img1.mydrivers.com/img/20250409/b0dc602a538548caa372fe98dcb13551.jpg) [](https://img1.mydrivers.com/img/20250409/54e62c2715444d9ca6a86771f7ac8048.jpg) [查看评论](https://m.cnbeta.com.tw/comment/1491648.htm)

<blockquote><p>随着AI技术的飞速发展,大模型如ChatGPT、Stable Diffusion等已广泛应用于产品开发中。然而,许多产品经理对AI模型的原理和应用仍缺乏深入了解。本文将从产品视角出发,深入剖析AI模型的底层原理、训练流程、评估方法以及典型应用场景,为产品经理提供一份清晰、实用的AI产品实战指南。</p> </blockquote>  AI技术日新月异,大模型如ChatGPT、Stable Diffusion 已经走入产品一线。作为产品经理,是否该深入算法底层? 其实,**不需要精通编程或建模,只要掌握常见模型的原理、能力边界和典型应用场景,就能让你的产品更智能、更高效。** 本文将从一个产品视角出发,逐步拆解大模型背后的“原理+应用+落地方案”,覆盖从文本生成到图像识别,从语音交互到智能Agent,为你提供一份清晰、可落地的 AI 产品实战指南。 ## 01 底层原理:AI如何像人类一样思考 人工智能简单来说就是机器对人类智能的模仿,对人的思维或行为过程的模拟,让它像人一样思考或行动。人类不断的积累经验,从而应对新的情况出现时能优化之前的行为。  那么机器,根据输入的信息(data)能进行模型结构,再输入新的信息时,**能自行优化模型的结果,从而优化输出的结果,甚至超越人类**。 ### 1.1 从规则驱动到数据驱动:AI进化简史 **(1)符号主义时代(1950s-1980s)** 代表:专家系统(如医疗诊断MYCIN) 特点:依赖人工编写规则,遇复杂问题崩溃 产品启示:规则系统仍用于简单场景(如客服FAQ) **(2)统计学习时代(1990s-2010s)** 代表:垃圾邮件过滤(贝叶斯算法) 突破:从数据中自动发现规律 **(3)深度学习革命(2012-至今)** 里程碑:AlexNet在ImageNet竞赛碾压传统方法 关键转变:特征工程→特征自动学习 使用一个很形象的例子: 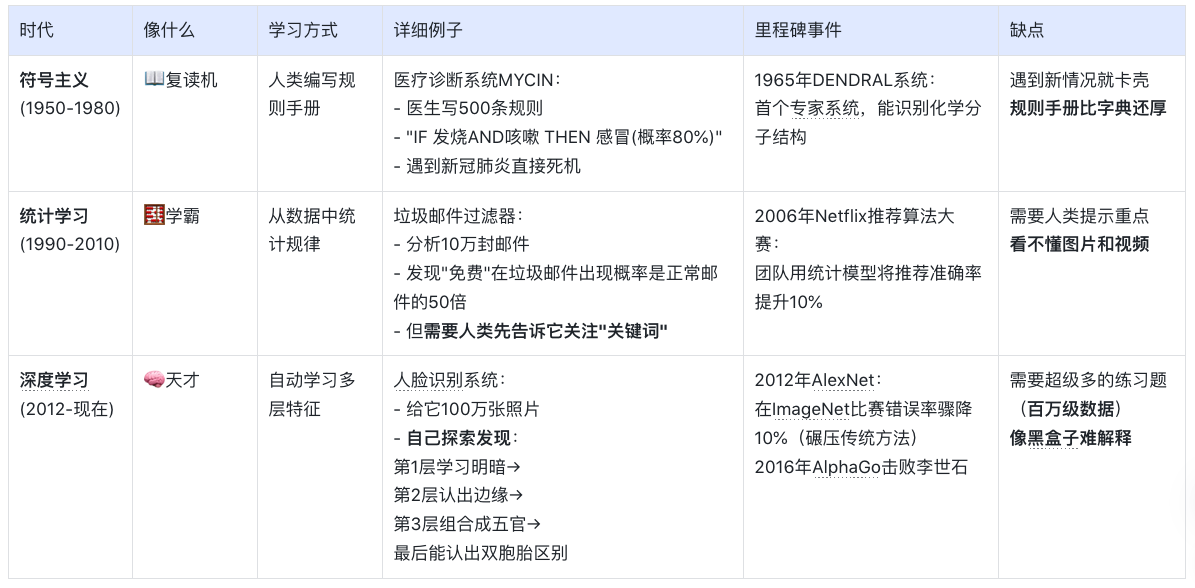 ### 1.2 关键三要素:数据/算法/算力的协同作用 人工智能的概念提出许久,现在火了更像是集中了天时地利人和。人工智能的三大基石:算法、算力、数据。 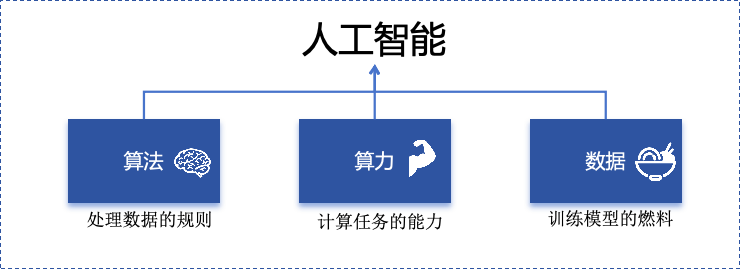 **算法**:2012年出现的**深度卷积神经网络**,能大幅提升图像识别准确率,标志深度学习进入实用阶段;2017年的**Transformer架构**解决了长序列数据处理难题,推动自然语言处理NLP,成为了GPT等大模型的基础。 - **算力**:GPU、TPU等专用硬件大幅提升计算效率,训练时间从数月缩短到几天,使训练百亿参数级模型成为可能。 - **数据**:得益于互联网的发展积累了海量的数据、图形等,大量的数据提供了模型训练的燃料,而数据的质量也决定了模型的准确率。 ### 1.3 神经网络:模仿人脑的”分层学习法” 首先要对神经网络所处的位置进行阐述,人工智能的实现方式主要包括符号学习与机器学习两类: 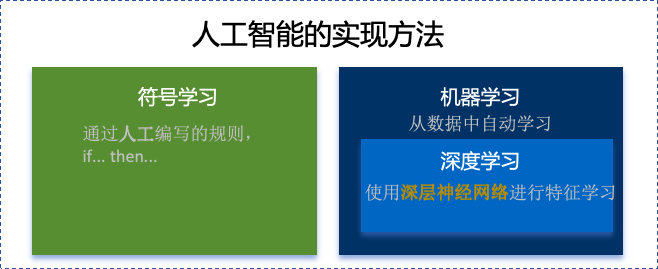 - **符号学习(对应前文的符号主义时代**):通过人工编写的规则来模拟人类推理。典型应用是专家系统(如IBM深蓝国际象棋程序)。局限性在于**全部依赖人工预设的规则**,无法处理未知的场景。 - **机器学习(对应前文的统计学习时代与深度学习革命)**:从**数据**中**自动学习规律**,主要分类方式有监督学习(分类、回顾),无监督学习(聚类、降维),强化学习。所谓的深度学习(使用了神经网络)其实是一种非常强大学习工具,可以用,可以不用,如下图所示: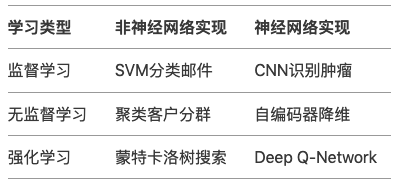 为什么说神经网络强大,先来看看它的原理。神经网络是一种模仿生物神经系统结构和功能的计算模型,就像人类大脑由数十亿个相互连接的神经元组成一样,人工神经网络也由大量相互连接的人工神经元(或称”节点”)构成,这些神经元通过协同工作来处理复杂的信息。 神经网络之所以被称为”**分层学习法**“,是因为它采用层级结构来处理信息。与传统的单层机器学习模型不同,神经网络通过多个处理层(包括输入层、隐藏层和输出层)逐步提取和转换数据特征,每一层都会对数据进行一定程度的抽象和理解,最终实现对复杂模式的识别和预测。 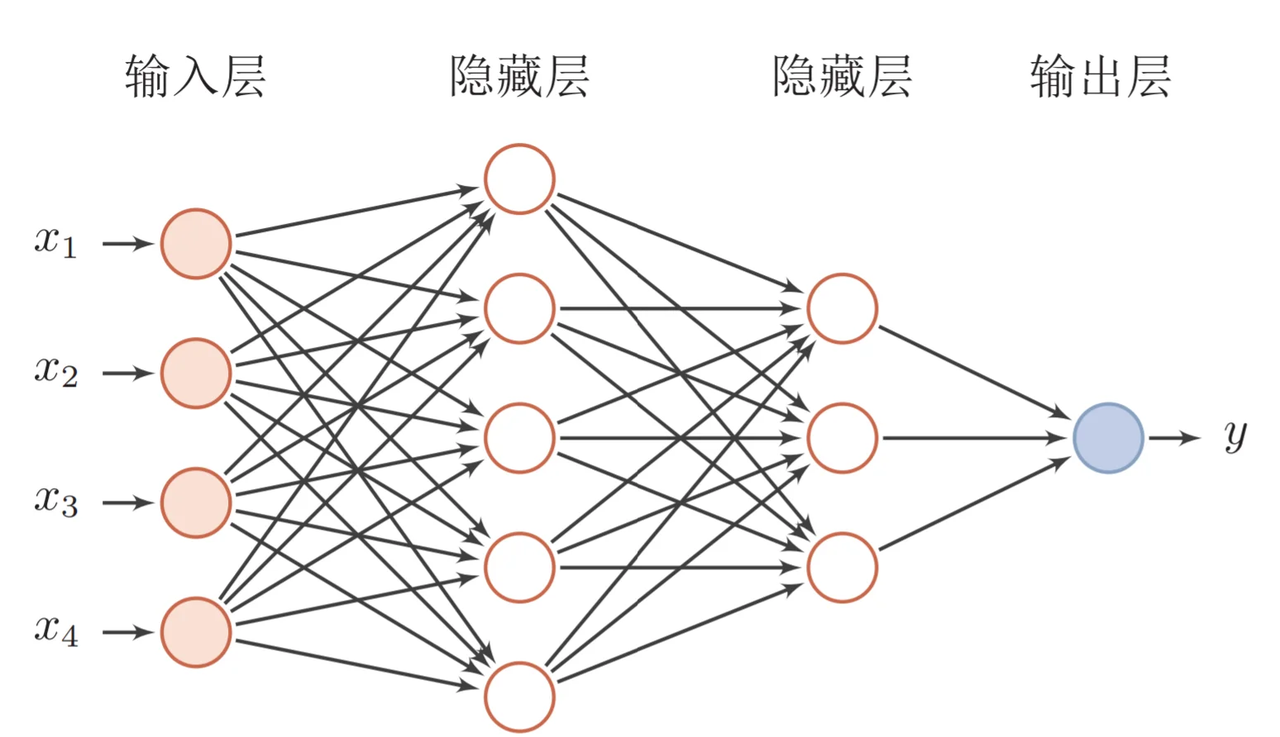 一个典型的神经网络由三个主要部分组成: - **输入层**:这是网络的”感官”部分,负责接收原始数据。比如在图像识别任务中,输入层可能是图像的像素值;在语音识别中,可能是声音信号的频率特征。 - **隐藏层**:这是网络进行实际”思考”的部分,由多层神经元组成。每一层都会对前一层的输出进行变换和抽象,逐步提取更高层次的特征。隐藏层的层数和每层的神经元数量决定了网络的深度和复杂度。 - **输出层**:这是网络产生最终结果的部分。根据任务的不同,输出可能是类别标签(如”猫”或”狗”)、连续值(如房价预测)或更复杂的数据结构(如句子翻译)。 这些层之间的连接都有相应的”权重”,这些权重决定了信号在神经元之间传递的强度,也是网络通过学习不断调整的关键参数。 ### 1.4 产品经理必懂的3个技术概念(Transformer/注意力机制/损失函数) **1)Transformer** Transformer是一种基于自注意力机制的神经网络架构,已成为NLP(Natural Language Processing,自然语言处理)和CV(Computer Vision,计算机视觉)领域的标准模型(如GPT、BERT等)。 产品经理需要知道的要点: - **并行处理优势**:相比RNN(Recurrent Neural Network,循环神经网络)的顺序处理,Transformer可以并行处理所有输入,大幅提升训练速度 - **上下文理解能力**:能够同时考虑输入的所有部分,实现更好的语义理解 - **可扩展性**:模型规模可以灵活调整(参数量从百万到千亿级) 产品应用启示: - 当需求涉及长文本理解时(如自动摘要),Transformer比传统模型表现更好 - 需要权衡模型大小与响应速度(大模型效果更好但更耗资源) - 注意输入长度限制(如GPT-3最多2048个token) 补充说明: **Token**是模型处理文本时的最小单位,可以是单词、子词或字符,具体取决于分词方式。例如: - **英文场景**:单词”unhappy”可能被拆分为子词[“un”, “happy”]作为两个token - **中文场景**:句子”产品体验优秀”可能被分词为[“产品”, “体验”, “优秀”]三个token **2)注意力机制** 注意力机制模拟人类认知的聚焦能力,让模型能够动态决定**输入的哪些部分更重要**。 产品经理需要知道的要点: - **权重分配**:为输入的不同部分分配不同重要性权重 - **自注意力**:让输入序列中的元素相互计算关联度(如理解”它”指代前文的哪个名词) - **多头注意力**:同时从多个角度计算注意力,捕捉不同维度的关系 产品应用启示: - 解释为什么AI有时会”答非所问”(注意力分配错误) - 设计产品时考虑提供更明确的上下文线索(帮助AI分配注意力) - 在需要关系推理的场景(如客服工单分类)优先考虑基于注意力的模型 **3)损失函数** 损失函数量化模型预测与真实值的差距,是训练过程中优化的目标。 产品经理需要知道的要点: **常见类型**: - 分类任务:交叉熵损失 - 回归任务:均方误差 - 生成任务:对抗损失(GAN) **自定义可能性**:可通过修改损失函数实现特殊业务目标 **评估指标关联**:损失函数值≠产品指标(如准确率),但通常正相关 产品应用启示: - 当标准指标不满足业务需求时,可考虑定制损失函数 - 理解模型优化目标与实际业务目标的差异(如推荐系统可能过度优化点击率而忽略多样性) - 评估训练进度时,除了看损失值下降,更要关注验证集的产品指标 ## 02 模型训练:AI的”学习”过程揭秘 在AI产品的开发过程中,模型训练是最核心也最神秘的环节。对于产品经理而言,理解模型训练的基本原理和关键环节,不仅能帮助团队更高效地推进项目,还能避免许多常见的”坑”。 ### 2.1 数据预处理:清洗/标注/增强的实战方法 AI需要大量的数据进行训练与学习,因此数据预处理是第一步。 **(1)数据清洗:质量大于数量** 在实际项目中,我们常常遇到”脏数据”的问题。比如在开发一个电商评论情感分析系统时,原始数据可能包含大量无关符号(如”####”)、乱码、甚至完全无关的内容。花在数据清洗上的每一分钟,都能为你节省后续十倍的调试时间。 常见的数据清洗方法包括: - 去除重复样本(约5-15%的数据可能是重复的) - 处理缺失值(删除或合理填充) - 统一格式(日期、单位等标准化) - 异常值检测与处理 实战技巧:建立一个可复用的数据清洗pipeline(一系列按顺序连接的处理步骤),将清洗规则代码化。例如使用Python的Pandas库,可以高效处理百万级的数据清洗任务。 **(2)数据标注:成本与质量的平衡术** 数据预处理环节并不一定要进行数据标注,是否需要数据标注取决于采用的机器学习方法: 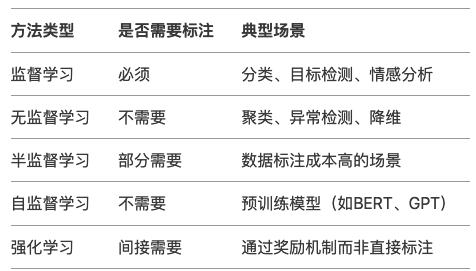 我们可以用下面的决策树图来判断是否需要标注以及如何实现标注: 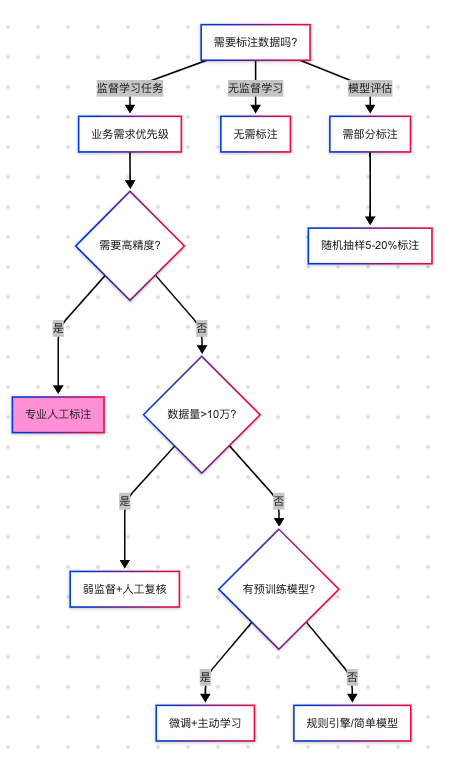 **(1)弱监督+人工复核**: **弱监督(Weak Supervision)**:用低成本方式生成“伪标签”,比如: - 用关键词匹配(如评论含“太差”=差评) - 用简单规则(如“订单金额>1000”=高价值客户) - 用已有小模型预测(如用BERT初步标注文本情感) - **人工复核:对弱监督结果抽样检查,修正错误** **例子**: <blockquote><p>电商评论分类(好评/差评)</p> <p><strong>-弱监督</strong>:用“太棒了”“垃圾”等关键词自动打标签</p> <p><strong>-人工复核</strong>:随机抽10%检查,修正错误标签</p></blockquote> **(2)微调+主动学习**: - **微调(Fine-tuning)**:用少量标注数据调整已有模型,让它适应业务 - **主动学习(Active Learning)**:让模型自己挑“最难”的数据,人工标注这些关键样本,提升效率 **例子**: <blockquote><p>法律合同风险检测</p> <p><strong>-微调</strong>:用1000条已标注合同训练BERT</p> <p><strong>-主动学习</strong>:模型找出“最不确定”的合同(比如既像高风险又像低风险),人工重点标注这些</p></blockquote> **(3)规则引擎/简单模型:** **方法**: - **规则引擎(Rule-based)**:用if-else逻辑处理数据,例:“IF 评论包含‘退款’ THEN 分类为投诉” - **简单模型(如逻辑回归、决策树)**:用少量标注数据训练可解释模型 **例子**: <blockquote><p>客服工单自动分类</p> <p><strong>规则引擎</strong>:</p> <p>-“无法登录” → 技术问题</p> <p>-“我要退货” → 售后问题</p> <p><strong>简单模型</strong>:用500条标注数据训练决策树</p></blockquote> ### 2.2 训练流程四步法:前向传播→损失计算→反向传播→参数更新 下图所示,是一个模型的训练过程,我们按照步骤进行讲解: 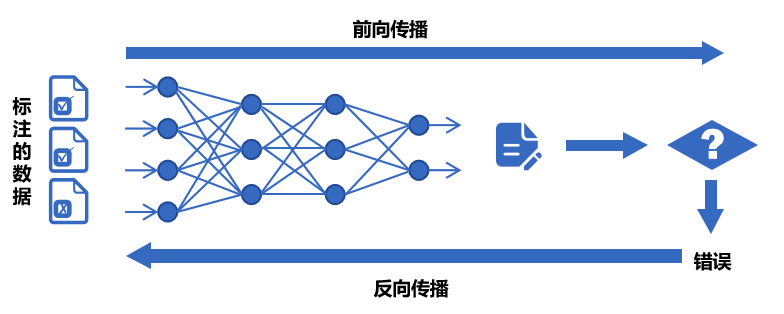 **(1)前向传播:模型的”初次尝试”** 就像第一次按照食谱做蛋糕,模型接收输入数据(原料),根据当前参数(食谱步骤),输出预测结果(成品)。 假设我们要训练**预测商品价格**的模型: - **输入数据**:商品类别、品牌、历史销量、评论数 - **当前参数**:初始**随机设置**的权重(类似新手厨师的直觉) - **预测输出**:预估价格(如¥299) **(2)损失计算:量化”错误”程度** 比较预测值与真实值的差距,这些训练数据对应的有真实的值,将真实值与第一步模型计算出来的值进行量化比较。做一个简化的例子: 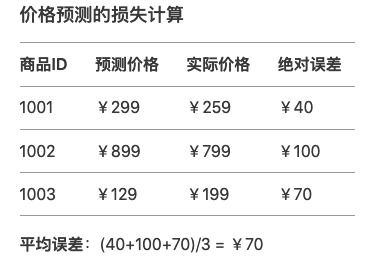 **(3)反向传播:找出”失败原因”** 不用担心,这一步是系统自动完成的(框架如PyTorch/TensorFlow实现),比如在前面的例子,通过数学方法计算: - 品牌权重对误差贡献:35% - 评论数量权重:15% - 历史销量权重:50% **(4)参数更新:调整权重** 根据归因结果调整参数,比如: 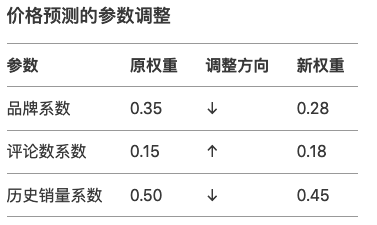 不断的重复上面过程调整权重与参数,何时停止训练: - 当验证集准确率连续3轮无提升 - 边际收益<1%时,边际收益 = (本轮指标 – 上轮指标) / 训练成本 ### 2.3 产品经理最常踩的3个坑(过拟合/数据泄漏/算力浪费) 在AI产品的落地过程中,产品经理往往更关注业务需求而忽略技术细节,但以下3个技术问题一旦发生,轻则导致模型失效,重则引发生产事故。 **坑1:过拟合(模型”死记硬背”)** **问题现象**:模型在测试数据上表现优异,上线后效果断崖式下跌。典型案例:某电商优惠券预测模型,训练准确率98%,实际发放后转化率不足5% **本质原因**: 模型**过度拟合训练数据中的噪声**(如特定用户ID、时间戳等无关特征),丧失了泛化能力。就像学生只会背例题却不会解新题。 **避坑方法**: **1.数据层面**: - 确保训练数据覆盖足够多的场景(如不同时段、地域、用户群) - 通过交叉验证检查过拟合(训练集/验证集效果差异>15%即预警) **2.产品设计层面**: - 设置灰度发布机制,先对小流量用户测试模型效果 - 监控核心指标衰减(如推荐系统的点击率周环比下降超20%需介入) **坑2:数据泄漏(”考试泄题”式作弊)** **问题现象**:模型开发阶段表现反常识地好,上线后完全失效。典型案例:某金融风控模型在训练集上AUC=0.99,实际识别欺诈准确率仅60%,后发现训练数据混入了未来信息(用还款结果反推风险等级) **本质原因**: 训练数据中混入了本应在预测时才能获取的信息(如用”用户最终购买结果”作为”点击预测”的特征),相当于让模型提前知道答案。 **避坑方法**: **1.特征工程隔离**: - 严格区分**特征数据时间戳**(如只能用用户历史行为,不能用未来行为) - 产品PRD中明确标注每个特征的可用时间范围(示例) **2.流程管控**: - 要求算法团队提供《数据隔离说明文档》 - 在AB测试时使用全新时间段的验证数据 **坑3:算力浪费(”大炮打蚊子”)** **问题现象**:简单业务使用千亿参数大模型,服务成本飙升10倍。典型案例:某企业用GPT-3处理客服FAQ匹配,每月算力支出20万+,后改用轻量级BERT模型效果相近,成本降至5000元/月 **本质原因**: 错误认为”模型越大越好”,忽视业务实际需求与ROI评估。 **避坑方法**:要求技术团队公开模型推理的**单次调用成本,**例如 - [当前模型] gpt-3.5-turbo - [单次成本] 0.002元/请求 - [日均成本] 240元(12万次/天) ### 2.4 微调(Fine-tuning)与迁移学习:低成本适配业务场景 在AI产品落地时,从头训练模型就像“为了喝牛奶养一头牛”,成本高且不现实。而微调(Fine-tuning)和迁移学习(Transfer Learning)能让产品经理用20%的成本,获得80%的定制化效果。 **迁移学习**:把预训练模型(如BERT、GPT)的通用知识“迁移”到新任务。类比:医学院学生先学基础解剖学(通用知识),再专攻心脏外科(垂直领域) **微调**:在预训练模型基础上,用业务数据做小规模调整。类比:咖啡师用标准意式咖啡机(基础模型),根据本地顾客口味微调研磨度(业务适配) 产品经理必知以下三种微调策略: **策略1:全参数微调(适合高精度场景)** **操作**:调整模型所有参数 **案例**:某法律合同审核系统,用2000条标注合同微调BERT,准确率从75%提升至92% **成本**:需GPU算力支持,适合数据量>1000条的场景 **策略2:轻量微调(适合快速试错)** **方法**:仅调整模型最后几层(如分类头)+ 冻结底层参数 **案例**:跨境电商用500条英语商品评论微调多语言BERT,一周内上线小语种分类功能 **优势**:节省80%训练资源,适合MVP阶段 **策略3:Prompt微调(适合小样本场景)** **创新点**:通过设计提示词(Prompt)激活模型能力 用下面的表进行三种策略对比: 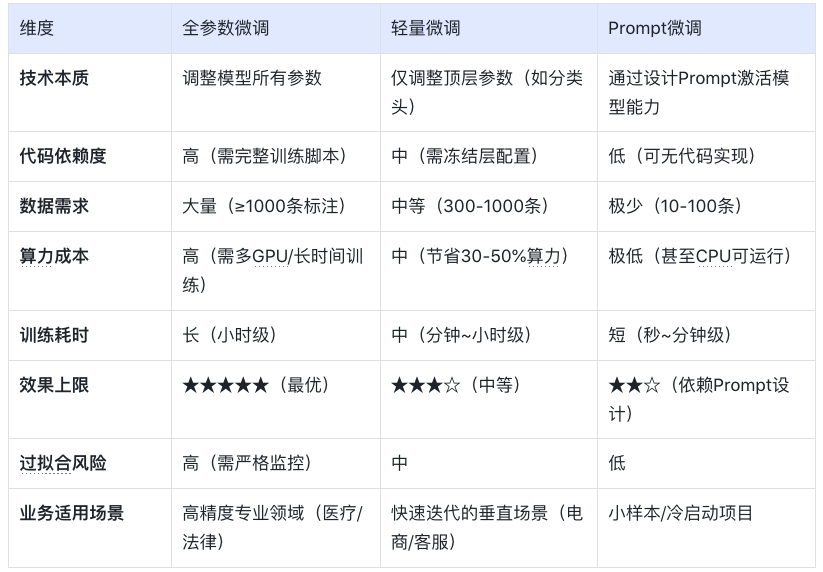 ## 03 模型评估:如何判断AI是否靠谱 ### 3.1 常用指标全解读 (1)**准确率(Accuracy)**:模型预测正确的样本占总样本的比例 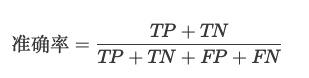  (2)精确率(Precision) vs 召回率(Recall) **精确率(查准率)**:预测为正的样本中,真实为正的比例(TP/(TP+FP))。用于“减少误伤”(如金融风控中,避免将正常交易误判为欺诈)。 **召回率(查全率, TPR)**:真实为正的样本中,被正确预测的比例(TP/(TP+FN))。用于“宁可错杀,不可放过”(如癌症筛查,漏诊代价远高于误诊)。 矛盾关系:提高召回率通常需降低精确率(可通过调整分类阈值平衡)。 (3)**F1值:精确率和召回率的“调和平均”** F1 = 2×(Precision×Recall)/(Precision+Recall),综合反映模型均衡性。 **使用场景**: - 类别不平衡时,比准确率更客观; - 需同时关注误判和漏判的业务(如客服质检)。 (4)**AUC-ROC** 1.先搞懂2个核心指标 前面已经介绍了**召回率(查全率, TPR)**,TPR = TP / (TP + FN),**“抓对了多少坏人”** 例子:100个新冠患者中,模型检测出80个 → TPR=80%(越高越好,漏诊越少) **假正率(FPR)**,FPR = FP / (FP + TN),**“冤枉了多少好人”** 例子:100个健康人中,模型误判了10个为阳性 → FPR=10%(越低越好,误诊越少) 2.**ROC曲线** **横轴(FPR)**:冤枉好人的概率(从0%到100%)。 **纵轴(TPR)**:抓到坏人的概率(从0%到100%)。 **曲线的画法**: 调整模型的判断阈值(比如新冠检测的阳性判定标准从严格到宽松),每调整一次阈值,就计算一对(FPR, TPR)坐标点,连起来就是ROC曲线(下图中蓝色的线)。 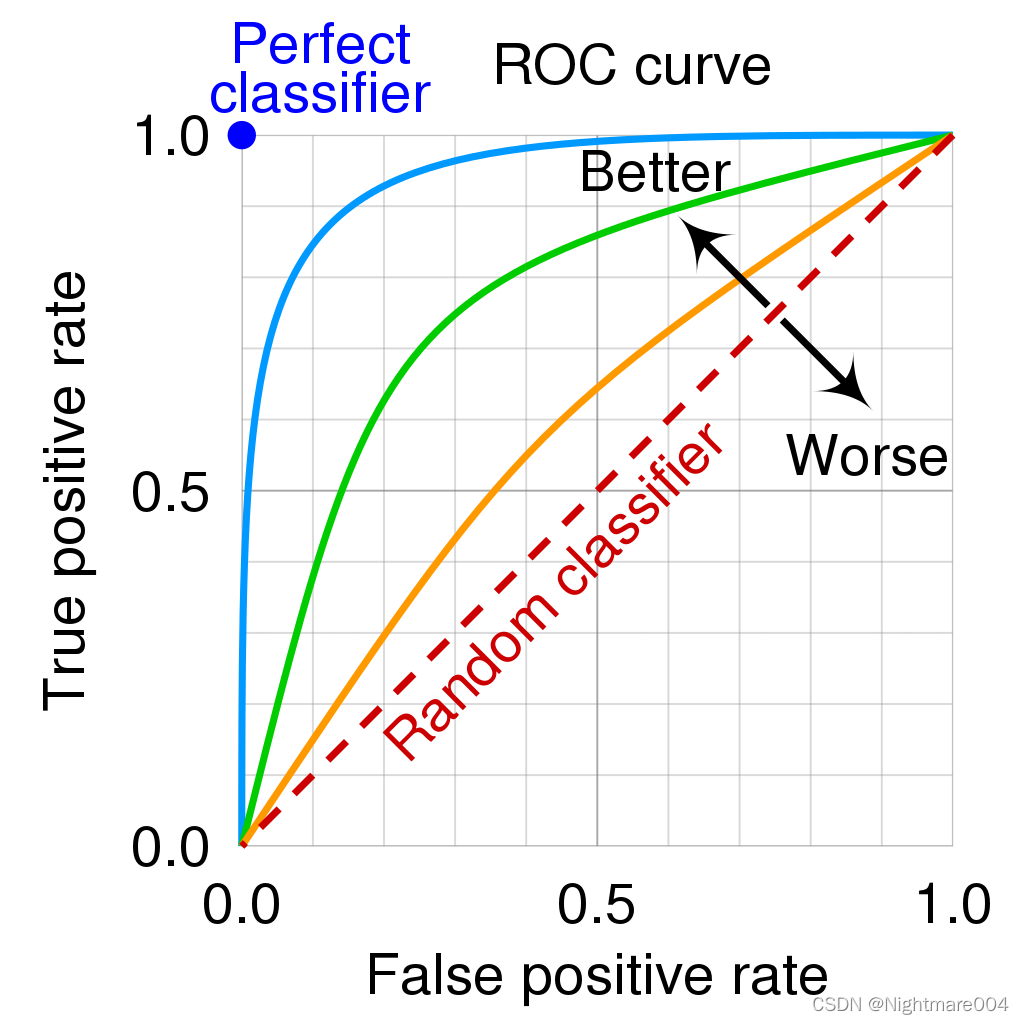 **AUC值:衡量ROC曲线的”含金量”** **AUC = 1**(完美模型): 能100%抓到坏人,且0%冤枉好人(曲线贴左上角,像直角尺)。 **AUC = 0.5**(随机瞎猜): 模型和抛硬币一样不准(曲线是45°对角线)。 **AUC在0.5~1之间**: 值越大,说明模型在”多抓坏人”和”少冤枉好人”之间平衡得越好。 ### 3.2 可解释性分析:LIME/SHAP工具可视化决策逻辑 **可解释性** = 让AI学会“讲人话”,解释自己的决策。就是让AI解释“为什么它做出某个决定”,而不是只丢给你一个结果。**LIME**和**SHAP**就是解释的工具。 **① LIME:局部解释(针对单次预测)** **干什么用**:解释AI对某一个具体案例的判断。 **怎么工作**:假设AI说“这条邮件是垃圾邮件”,LIME会告诉你:“因为邮件里有‘免费领取’和‘限时促销’这两个词,所以AI判断为垃圾邮件。” **② SHAP:全局解释+局部解释** **干什么用**:不仅能解释单次预测(像LIME),还能总结整个AI模型的决策规律。 **怎么工作**:分析AI的贷款模型,SHAP可能告诉你: **全局规律**:“收入”和“信用分”是主要判断依据,“性别”几乎没用。 **单次决策**:“张三被拒贷,因为他的信用分比阈值低20分。” LIME/SHAP通常是代码库,需要技术人员调用,但产品经理要懂它们的输出结果。 ### 3.3 AB测试在AI中的特殊用法 **1. 传统AB测试 vs AI时代的AB测试** **传统AB测试**: - 用途:对比两个静态方案(如按钮颜色A/B)。 - 局限:只能测“固定规则”,无法应对动态变化的AI模型。 **AI时代的AB测试**: 用途:验证**模型迭代效果**、**算法策略优劣**、**数据质量影响**。 特点: - 测的不是“静态界面”,而是“动态学习能力”; - 不仅要看短期指标(如点击率),还要关注长期影响(如用户留存)。如可在需求文档中说明“本次推荐算法升级需同时优化点击率和7日复购率,技术方案采用多目标学习(MMoE)。” **2.AI项目中AB测试的3大特殊场景** **场景1:模型版本对比(Model A/B Testing)** **问题**:新训练的模型比旧模型准确率高,但上线后效果可能不同(数据分布变化)。 **解法**: - 将用户**随机分流**,50%用旧模型,50%用新模型。 - 对比关键指标(如推荐系统的点击率、风控模型的误杀率)。 **案例**: 电商发现新推荐模型CTR提升10%,但AB测试显示客单价下降5%——说明模型可能过度推荐低价商品。 **场景2:算法策略对比(Algorithm A/B Testing)** **问题**:不同算法(如协同过滤 vs 深度学习)适合不同场景。 **解法**: - 同一模型,不同算法策略并行测试。 - 重点关注**业务指标**而非技术指标(如“收入”优于“准确率”)。 **案例**: 外卖平台测试“距离优先”和“口碑优先”两种排序算法,发现午高峰用距离优先,晚高峰用口碑优先更优。 **场景3:数据质量影响测试(Data A/B Testing)** **问题**:新数据源(如用户画像标签)是否真能提升模型效果? **解法**: - 对照组:旧数据训练的模型;实验组:加入新数据后的模型。 - 验证数据是否有“信息增量”。 **案例**: 金融风控模型加入“社交关系数据”后,AB测试显示欺诈识别率提升,但误杀率也增加——需权衡取舍。 **3.AI项目AB测试的3个关键技巧** **技巧1:分层抽样(Stratified Sampling)** **问题**:AI效果可能因用户群体差异巨大(如新老用户)。 **解法**:按用户分层(如地域/活跃度)随机分组,确保对比公平。 **技巧2:渐进式发布(Canary Release)** **问题**:新模型可能有未知风险。 **解法**:先小流量(如1%用户)测试,监控异常后再全量。 **技巧3:长期效果监控(Delayed Impact)** **问题**:AI的短期指标可能欺骗人(如推荐系统靠标题党提升CTR,但伤害用户体验)。 **解法**:增加“7日复购率”“用户停留时长”等长期指标。 ## 04 典型模型:从原理到应用场景 在AI加速落地的时代,理解典型模型的原理和应用场景,对数字化产品经理来说已成为基础能力之一。以下我们将拆解几类典型AI模型,结合原理、场景,并重点说明如何在产品中落地。 ### 4.1 对话类模型:Transformer 架构(以 ChatGPT 为例) **模型简介** Transformer 是由 Google 于 2017 年提出的自然语言处理架构,其核心是“注意力机制(Attention)”,可捕捉词语之间的长距离依赖关系。GPT 系列(Generative Pre-trained Transformer)即基于 Transformer 的 Decoder 架构演进而来。 **应用场景** - 智能客服 / 企业内部助手 - 内容生成(写作、摘要、翻译) - 编程助手 - 教育陪练 / 作文点评 - 知识问答机器人 **产品落地方式** **接入方式**:使用 OpenAI API、Azure OpenAI,或国内厂商的类ChatGPT API(如通义千问、文心一言等) **落地场景设计**: - 将模型集成至对话窗口(如帮助中心、CRM系统) - 与企业知识库结合,实现上下文问答 - 与内容库结合,做智能创作助手嵌入 IDE / 后台系统做代码建议和提示 **关键评估指标:** - 回复命中率 / 准确率 - 人力节省比 - 用户满意度(CSAT)提升 **产品经理思考角度** - 业务是否存在高频但重复的问答类工作? - 是否具备结构化或非结构化的内容知识库? - 用户是否对回答质量有高容错要求? ### 4.2 图像生成类模型:扩散模型(以 Stable Diffusion 为例) **模型简介** 扩散模型通过逐步对随机噪声进行去噪,生成高质量图像,适用于根据文字描述生成图像。代表模型有 Stable Diffusion、Midjourney、DALL·E。 **应用场景** - 电商图生成 - 广告视觉草图 / Banner - AI头像 / 个性化图像 - 游戏原画 / 插图 **产品落地方式** 接入方式:使用 HuggingFace / Stability AI 提供的 API,或私有部署开源模型(如 Stable Diffusion) 落地场景设计: - 编辑器类产品内嵌“AI生成图”按钮 - 结合运营系统,批量生成活动海报 - 提供Prompt模板给用户快速创作关键评估指标: - 素材生成效率提升 - 设计人力节省率 - 图像生成质量反馈分数 **产品经理思考角度** - 用户是否有大量视觉素材创作需求? - 是否需要 AI 图像与品牌风格保持一致? - 是否要在用户端控制生成成本(如限制次数)? ### 4.3 推荐类模型:深度推荐(DeepFM / DIN / 多模态推荐) **模型简介** 推荐系统模型基于深度神经网络(DNN)对用户、物品及上下文做特征嵌入,再用交叉模块(如 FM)和序列建模(如 Attention)捕捉兴趣变化,生成推荐结果。 **应用场景** - 短视频 / 内容流推荐(抖音、小红书) - 电商商品推荐(淘宝、京东) - 资讯 / 新闻推荐 - 广告精准投放 **产品落地方式** 接入方式:大公司自建推荐引擎;中小型产品可用阿里PAI、腾讯云推荐平台等 落地场景设计: - App首页内容流由推荐系统动态生成 - 用户行为触发实时兴趣建模(点击、收藏、停留) - 联动标签系统或知识图谱强化推荐粒度 **关键评估指标:** - CTR / CVR - 用户停留时长 - 推荐召回率 / 精准率 **产品经理思考角度** - 用户行为数据是否足够支撑训练? - 内容/商品池是否足够丰富? - 是否具备冷启动解决策略(如规则+AI混合)? ### 4.4 多模态模型:CLIP / GPT-4V / Gemini **模型简介** 多模态模型能同时理解图像和文本(甚至语音、视频),如 OpenAI 的 CLIP 能将图像和文字映射到统一语义空间,实现“看图说话”、“图文检索”等。 **应用场景** - 图文搜索 / 图文问答(文档问答) - 视频摘要 / 图像理解 - 商品图智能分类与打标 **产品落地方式** 接入方式:调用 OpenAI GPT-4V、Gemini、或开源如 BLIP、MiniGPT 等 落地场景设计: - 在搜索引擎中加入“图搜文”、“文搜图”能力 - 实现图像知识问答机器人(例如问产品图) - 用于文档解析、发票识别、PPT内容理解等 关键评估指标: - 图文匹配准确率 - 检索速度 / 召回率 - AI识别后的提效率 **产品经理思考角度** - 是否存在“图+文”的复杂内容理解任务? - 当前内容是否难以结构化? - AI多模态是否能带来搜索/理解效率的提升? ### 4.5 语音类模型:Whisper / TTS / 语音识别 **模型简介** Whisper 是 OpenAI 推出的通用语音识别模型,支持多语种、多口音识别。TTS(Text to Speech)模型则用于将文本转为语音。 **应用场景** - 客服语音转写 / 质检 - 智能语音助手(如小爱同学) - 无障碍阅读 / 播客生成 - 视频字幕自动生成 **产品落地方式** 接入方式:调用 Whisper API、讯飞开放平台、阿里云语音服务等 落地场景设计: - 语音转文字后结构化为知识点、标签 - 视频自动加字幕、翻译 - 用户语音输入场景接入识别能力 关键评估指标: - 转写准确率 / 延迟时间 - 语音合成自然度评分 - 用户体验评分(Voice UX) **产品经理思考角度** - 是否有大量语音内容需要转写/处理? - 是否存在用户语音交互需求? - TTS是否能与品牌声音匹配? ## 写在最后 AI 已不仅仅是算法工程师的专属武器,而正成为每一位产品经理的“第二大脑”。无论是用对话模型优化客服体验,还是用图像生成提升运营效率,抑或是构建多模态理解、自动执行任务的智能 Agent——我们正处于一个“技术从幕后走向产品前台”的转折点。 与其担心被 AI 取代,不如积极思考:**你的产品,如何因为 AI 而变得更聪明、更高效、更具竞争力?** 希望这份“模型原理与落地指南”能成为你与 AI 合作的起点,也欢迎你在评论区分享你的产品实践与灵感,一起推动“AI + 产品”的落地进程。 本文由 @Jessie 原创发布于人人都是产品经理。未经作者许可,禁止转载。 题图来自Unsplash,基于CC0协议。 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。

当地时间4月8日凌晨1点34分,美国华盛顿州莱西市的一个特斯拉超级充电站发生了爆炸事件。现场照片显示,特斯拉超充站的变压器核心组件遭到严重毁坏,电气开关设备也遭到损坏,该超充站也被迫停止运营。 据初步调查,此次爆炸可能是由小型炸弹引起的,警方证实,联邦调查局已介入。 [](//img1.mydrivers.com/img/20250409/4da1ac4d022c4b16a34b758cf4f1d1de.jpg) [](//img1.mydrivers.com/img/20250409/11d7faff6a324f3084b6af5c5f4059ae.jpg) 特斯拉在其X平台的充电账号上发表声明,表示正在与莱西警方和FBI合作调查,并与普吉特湾能源公司协调,争取尽快恢复超级充电站的运营。特斯拉还警告称:“不要破坏关键基础设施”。 据了解,因为对马斯克本人言论和政策的反对,美国近期多地出现针对特斯拉门店、车辆及补能基础设施的破坏行为。 此前报道显示,特斯拉门店被人为纵火、特斯拉车辆被打砸喷漆、充电站线缆被剪断等。人们的抗议和示威活动也波及到了特斯拉车主,以至于不少车主将自己的特斯拉车辆更换车标,以显示其对马斯克的反对态度。 马斯克本人也表示,“如果你看新闻,会觉得就像世界末日一样,我每次从电视机前走过,都会看到一辆特斯拉着火了。如果你不想买我们的产品,我可以理解,但你不必把它烧掉。” 为应对愈发升级的特斯拉破坏行为,美国总统特朗普前段时间在社交媒体上表示:“那些被抓到破坏特斯拉的人,将有很大可能被判入狱长达20年,这包括资助(破坏特斯拉汽车)者,我们正在寻找你。” [](//img1.mydrivers.com/img/20250409/051f24ad6776419fac17b42e4f0bc54a.jpg) [查看评论](https://m.cnbeta.com.tw/comment/1491646.htm)

<blockquote><p>2025年4月,特朗普签署两项关于“对等关税”的行政令,对全球贸易格局产生重大冲击。在这一背景下,中国出海企业面临前所未有的挑战。本文将探讨中国企业在海外市场的用户研究现状,分析“伪洞察”和“纸上谈兵”等问题,并提出“脏活经济学”、文化入侵和重建“中国溢价”等策略,帮助企业在全球化竞争中实现从“接单者”到“造浪者”的转变。</p> </blockquote>  2025年4月3日,特朗普在白宫签署两项关于所谓“对等关税”的行政令,宣布美国对贸易伙伴设立10%的“最低基准关税”,并对某些贸易伙伴征收更高关税。这一政策犹如一颗重磅炸弹,将全球贸易局势推向新的动荡阶段。中国制造的“低价魔法”正在失效,但真正致命的并非关税本身——而是中国企业对海外市场的集体误判。某家电巨头花百万调研东南亚,结论却是“用户要更便宜的产品”,结果被越南本土品牌用“爱国营销”打得满地找牙。这场关税海啸,正在血洗那些把“出海”等同于“倾销”的投机者。 特朗普的新关税政策不仅增加了中国企业的出口成本,还将全球供应链推入更加复杂的博弈之中。叠加此前对中国商品加征的10%关税,东南亚市场成为许多企业转移生产的新目标。然而,这种简单的“地理位移”并未从根本上解决核心问题——如何赢得消费者的心。 ## 你的用户研究正在批量生产自杀工具 **1. “伪洞察”正在吃掉你的利润** 特朗普的新关税政策不仅增加了中国企业的出口成本,还加剧了海外消费者对价格敏感度的变化。例如,某新能源车企进军德国时,调研只盯着“充电桩覆盖率”,却漏掉了“用户宁可多花钱也要买本土品牌”的文化傲慢。这种文化认知的缺失使得该企业的产品在市场上毫无竞争力。 更荒谬的是,某快消品公司用AI抓取百万条海外评论,得出“中东女性最爱大红唇”,结果实地调研发现她们买口红只为婚礼等特殊场合。算法能抓数据,但抓不住人心——你的研究员在假装思考。 **2. 会议室里的“纸上谈兵”** 麦肯锡的一项调查显示,超过60%的出海企业承认自己的用户研究“无法量化价值”。这些企业高价购买的报告里充斥着“人口红利”“消费升级”等陈词滥调,却忽视了墨西哥蓝领工人宁愿多花3小时通勤也要分期付款买iPhone的心理需求。特朗普的关税政策进一步压缩了低成本产品的生存空间,迫使企业重新审视目标市场的真实需求。 ## 用户研究的三把核武器 **1. “脏活经济学”:全员进战壕,把PPT扔进垃圾桶** 硅谷顶级团队早已摒弃了传统的办公室式研究方法,转而采取更加贴近一线的操作方式。某跨境电商强制所有高管每年在海外仓库工作15天。当CEO亲眼看到巴西快递员暴力分拣包裹时,才明白“防摔包装”比“降价促销”更能提升复购率。特朗普关税政策的出台,让中国企业不得不从“价格战”转向“价值战”,而这需要深入一线获取真实反馈。 **2. 文化入侵:用他们的语言,洗他们的脑** 面对特朗普关税政策带来的挑战,某国产手游成功征服中东市场的秘诀在于雇佣当地作家重新编写剧情,将主角设定为阿拉伯英雄;同时,专门为穆斯林玩家开发了斋月专属皮肤。这种本土化战略不是妥协,而是通过融入当地文化实现更高维度的价值输出。同样,在日本市场,某美妆品牌敏锐捕捉到年轻女性偏爱自然妆容的趋势,推出了一系列“裸妆感”彩妆产品,迅速俘获人心。 **3. 重建“中国溢价”:从跪舔到定义规则** 大疆无人机为何能让欧美用户心甘情愿支付额外30%的关税?因为它已经牢牢占据了“无人机=大疆”的心智地位。TikTok虽然屡遭围剿,但依然难以被取代,因为它的上瘾机制彻底改变了用户的娱乐习惯。SHEIN则通过实时数据分析用户喜好,重塑了全球年轻人的购物方式。特朗普的关税政策或许提高了进入门槛,但也为中国企业提供了机会,通过创新和品牌建设重新定义行业规则。 ## 从“接单者”到“造浪者” **1. 杀死“性价比幻觉”** 如果只盯着价格做文章,那么一旦失去成本优势,企业就会陷入万劫不复的境地。相反,那些能够挖掘独特需求并提供创新解决方案的品牌,才能真正站稳脚跟。例如,某国产智能硬件品牌发现欧美家庭对宠物健康监测存在强烈兴趣,于是推出了具备心率、体温监测功能的智能项圈。这种“非你不可”的产品定位,才是制胜之道。 **2. 从“跟随者”到“引领者”** 成功的品牌不仅满足现有需求,还能引导未来趋势。某电动车品牌在欧洲市场另辟蹊径,将自身定位为“零碳出行的未来”,并通过社交媒体持续输出相关内容,吸引了大批忠实粉丝。用户研究的最高境界,就是让用户离不开你所创造的新世界。特朗普的关税政策虽然推高了通胀并减缓经济活动,但同时也推动了企业向更高附加值方向转型。 ## 结语:要么进化,要么等死 2025年的关税风暴并不是灾难,而是一剂猛药。它逼迫中国企业反思过去的粗放式增长模式,重新审视用户研究的重要性。那些靠“信息差”“价格差”苟活的玩家终将被淘汰,而敢于用深度洞察重构商业本质的企业,则正在把“Made in China”升级为“Created by China”。 记住,关税能挡住低价货,但挡不住“非你不可”的价值。你的用户研究,准备好迎接这场硬仗了吗? ### 全球化格局下的中国角色与应对策略 **1. 全球化新格局:从“制造中心”到“创新引擎”** 特朗普关税政策的出台标志着全球化进程进入新阶段。过去几十年,中国凭借廉价劳动力和完善的供应链体系,成为“世界工厂”。然而,随着全球贸易环境恶化和技术竞争加剧,单纯依赖制造能力已不足以支撑中国经济的可持续发展。 在这一背景下,中国企业必须加速完成从“制造中心”到“创新引擎”的转变。以华为为例,其在5G技术领域的领先地位使其在全球市场上具备不可替代性。即便面临美国政府的多重制裁,华为依然凭借强大的研发能力和专利储备维持了竞争优势。这充分说明,只有掌握核心技术,才能在全球化新格局中立于不败之地。 **2. 区域化布局:深耕东南亚及其他新兴市场** 面对特朗普关税政策的压力,越来越多的中国企业选择将生产基地迁往东南亚等地区。然而,这种“物理迁移”仅仅是第一步。要想在这些新兴市场站稳脚跟,企业还需深入了解当地文化、法律和社会环境。 例如,小米在印度市场的成功得益于其对本地消费需求的精准把握。针对印度消费者对性价比的高度敏感,小米推出了价格亲民且性能优越的智能手机,并通过线上渠道大幅降低分销成本。此外,小米还积极参与印度社区建设,树立了良好的品牌形象。这种“软硬结合”的策略值得其他企业借鉴。 **3. 可持续发展:打造绿色竞争力** 近年来,全球范围内对环境保护的关注度不断提升,各国纷纷出台相关政策鼓励绿色经济发展。特朗普关税政策虽然短期内可能对中国企业造成冲击,但从长期来看,这也为中国企业提供了一个展示绿色竞争力的机会。 以比亚迪为例,其在新能源汽车领域的持续投入使其成为全球领先的电动汽车制造商之一。在欧洲市场,比亚迪不仅提供高质量的产品,还积极推广“零排放”理念,赢得了消费者的广泛认可。未来,随着环保意识的普及,类似的绿色竞争力将成为中国企业开拓国际市场的重要武器。 ### 特朗普关税政策的影响与启示 **1. 对中国经济的影响** 特朗普关税政策的实施无疑会对中国经济产生深远影响。一方面,出口导向型企业将面临更大的成本压力;另一方面,国内消费市场的重要性将进一步凸显。在这种情况下,中国政府需要采取有效措施帮助企业渡过难关,例如加大财政支持力度、优化营商环境等。 **2. 对全球供应链的影响** 特朗普关税政策的出台也对全球供应链产生了连锁反应。为了规避关税风险,许多跨国企业开始重新评估其供应链布局。一些企业选择将生产基地迁至东南亚等地区,而另一些企业则尝试通过技术创新减少对外部资源的依赖。 值得注意的是,这种供应链重组并非完全负面。对于中国企业而言,这也是一个提升自身竞争力的机会。例如,通过加强自主研发能力,中国企业可以在关键领域实现突破,从而减少对进口零部件的依赖。 **3. 对消费者行为的影响** 最后,特朗普关税政策还对消费者行为产生了重要影响。随着部分商品价格上涨,消费者对价格的敏感度有所提高。与此同时,他们对产品质量和服务体验的要求也在不断上升。因此,企业需要在保证性价比的同时,注重提升用户体验,以满足日益多元化的需求。 ### 迎接挑战,拥抱机遇 2025年的关税风暴不仅是对中国企业的考验,更是推动其转型升级的催化剂。那些能够准确把握市场动态、深刻理解用户需求的企业,将在未来的全球化竞争中占据有利位置。正如前文所述,“关税能挡住低价货,但挡不住‘非你不可’的价值。”希望每一位中国企业决策者都能从中汲取教训,以更加开放的心态和扎实的行动迎接挑战,拥抱机遇。 本文由 @蒋昌盛 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自 Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

据博板堂表示,**NVIDIA RTX 5060 Ti系列新品的价格定位已经敲定,并已向各AIC品牌厂商通知了RTX 5060Ti系列的首发指导价格。****具体MSRP指导价为:** RTX 5060Ti 16GB系列首发价确定429美金,人民币定价为3599元, RTX 5060 Ti 8GB系列首发价确定379美金,人民币定价为3199元。 作为对比,RTX 4060 Ti 8GB的首发定价为3199元,16GB版本为3899元。 根据此前消息,RTX 5060 Ti和RTX 5060都将配备GDDR7显存,显存位宽为128bit,总带宽达到448GB/s,相比RTX 4060 Ti提升了55%。 **RTX 5060 Ti采用GB206-300芯片,拥有4608个流处理器,核心频率为2407-2572MHz,整卡功耗为180W。** 不仅如此,还有消息称NVIDIA此次还强制要求每一家AIC厂商,在首发时必须有一款MSRP原价卡销售,至于数量有多少,那就不好说了。  [查看评论](https://m.cnbeta.com.tw/comment/1491644.htm)
 机核 · YT17
机核 · YT17 感谢游戏科学的邀请,我们提前观看了游戏科学有关黑生化悟空的线下艺术展。本次艺术展是游戏科学与中国美术学院合办,展览之中包括黑神话悟空的原画设计图,参考的艺术作品,还有大量复原文物的实体展品。                   这是国家重点美术馆首次为单一游戏 IP 召开艺术展,也是游戏科学决心将《黑神话》做成全球 IP 的一小步。本次艺术展每一位购买门票的用户(全价票和半价票)都会获得一份免费随赠的伴手礼,是一本200多页、精装订的《黑神话:悟空》艺术展原画集。展览时间为4月9日-5月21日,地点在中国美术学院(杭州·南山校区)欢迎玩家朋友们莅临!

**本田在欧洲推出了CR-V 30周年纪念版概念车CR-V Dream Pod**,据称其灵感来自日本的胶囊旅馆,彰显冒险精神。该车基于CR-V e:PHEV打造,**搭载一台2.0升四缸发动机和电动机,并配有17.7kWh电池,纯电续航约79公里。** 不同于一般的概念车,CR-V Dream Pod设计看齐在售车型,一点儿也不张扬,但配备了诸多实用配件,包括车顶行李架和Thule自行车架,休旅风浓烈。    更让人感到惊奇的是车内,其配有EGOE Nestboard 650套件,**展开后就是一张双人床垫,可供两名成年人休息,通知支持安装后窗百叶窗,落下可收缩窗帘后秒变私人卧室。**    除了床垫,套件还提供了一个抽屉,其中隐藏了炉灶和可折叠水槽,方便用户烹饪和清洗,此外车内还设有储物格,用于存放餐具和其他旅行必备装备。   不仅如此,**这款车还配有橡胶地垫、可拉出的侧桌和“科技舱”,提供LED阅读灯和USB充电接口,方便夜间照明和给手机、无人机等设备补电。**   种种元素均表明,这款车打造的其实就是“移动的家”,虽然地方小了点,但确实能够满足最基本的生活需求和在路上的渴望,当然了,至于会不会量产,那就另当别论了。 [查看评论](https://m.cnbeta.com.tw/comment/1491642.htm)

今天微信是否开通已读功能引起网友热议,绝大多数网友都持坚决反对意见。腾讯客服在回答网友咨询时表示,微信暂不提供这个功能。同时,腾讯公司公关总监@腾讯张军 也发文强调,这个话题此前就进行过回复。 [](//img1.mydrivers.com/img/20250409/b119f2568e394a659d4d8300b70c2eae.jpg) 张军表示:“已读”会增加信息接收者的心理负担和社交压力,所以从一开始微信就坚定不移地不提供这个功能,以后也不会。 当时微信官微也回复称:放心,没有“如果”。 大家可以完全放心了,从官方的多次回应来看,微信完全没有考虑增加已读功能。从发送者的角度而言,当然需要知道对方到底收到没有,有一个“已读”标志,看似很好地解决了这个问题。 但对于接收者来说,压力就非常大了,一旦标记“已读”,接下来就是“到底要不要回”。 张军表示曾表示:“对方明明知道读过了,我却不回,是不是不好?如果是上级发送的,压力就更大了。” [查看评论](https://m.cnbeta.com.tw/comment/1491640.htm)

特朗普的关税政策冲击了多个行业,其中就包括电子商务领域。据《商业内幕》报道,关税导致美国电商巨头亚马逊的员工、供应商以及卖家面临不确定性。**亚马逊首先想到是自保,要求供应商自行吸收关税成本,保证公司的利润率。**  亚马逊仓库 一些亚马逊员工一直与公司供应商保持直接联系。这些供应商通常被称为第一方供应商,他们以批发方式将产品卖给亚马逊,然后亚马逊再卖给消费者。 据这些供应商反映,**亚马逊不愿为他们的产品支付更高的价格,即便加征关税会增加供应商的成本。**据《商业内幕》看到的一封发自3月份的电子邮件,亚马逊的一名员工鼓励供应商从其产品制造商那里寻找进一步降低成本的途径,或者通过政府补贴来降低成本。 “我们理解当前经济和贸易环境所带来的挑战。然而,我们认为,还有一些尚未被充分探索的替代方案可以避免直接提高成本。”亚马逊员工在邮件中称。 一些供应商告诉《商业内幕》,**亚马逊还在寻求与供应商签署“利润率协议”,要求供应商在涨价后仍保证亚马逊获得相同的利润率**。也就是说,即使亚马逊以更高的价格购买产品,也要维持从供应商那里获得的利润率。 在某些情况下,亚马逊会暂停供应商的发货订单以监测市场动态。据《商业内幕》看到的一封电子邮件,一家航运公司最近告知一位供应商,“按照亚马逊的要求”,该公司暂停了提货安排,以**“降低关税带来的影响”。** 截至发稿,亚马逊发言人尚未就此置评。 [查看评论](https://m.cnbeta.com.tw/comment/1491638.htm)

凯茜·伍德的方舟投资管理公司周二进行了涉及亚马逊等科技股的交易,其中最引人注目的是,她的旗舰基金方舟创新ETF(ARKK)重新建仓了英伟达。该基金当天买入了188980股英伟达股票,按收盘价计算价值约1820万美元。 [](https://n.sinaimg.cn/tech/transform/59/w550h309/20240606/5171-68591f79b21041c15b69e6007339c81e.jpg) 在特朗普宣布征收全面关税后,英伟达的股票一直与其他主要科技股一起受到关注。在过去5天里,该股下跌了10%以上,周二下跌1.37%,收于96.30美元。 伍德的旗舰基金早在2014年就开始买入英伟达的股票,但2023年初清仓了这只股票,从而错过了后来的暴涨行情,尽管她的另外几只基金仍持有少量英伟达股票。 自那以来,伍德曾多次为她的旗舰基金清仓英伟达的决定进行辩护,称“ARK在2014年就以大约5美元的价格买入了英伟达,当时大多数投资者都将其视为一家PC游戏芯片公司。在涨幅超过150倍之后,我们正继续套现利润。” 伍德的基金周二还买入了33746股亚马逊股票,价值约576万美元。亚马逊最近发布了一款新的人工智能模型Amazon Nova Sonic,旨在彻底改变实时语音交互。然而,正如马克·库班最近的评论所强调的那样,随着关税可能影响亚马逊的运营,潜在的挑战迫在眉睫。 伍德的基金还买入了46790股Tempus AI股票,价值约174万美元,尽管该公司股价周二大跌了12.81%,但Ark仍然对其充满信心,此前曾对该公司进行了大量投资。 伍德的基金还买入了31730股Coinbase股票,价值约481万美元。Coinbase仍然是加密货币市场的关键参与者,Ark的持续投资突显了其对该公司长期潜力的信心。 [查看评论](https://m.cnbeta.com.tw/comment/1491636.htm)
 钛媒体 · 钛小股
钛媒体 · 钛小股
2025年4月9日,截止收盘,沪指涨1.31%,报收3186.81点;深成指涨1.22%,报收9539.89点;创业板指涨0.98%,报收1858.36点,两市成交额较上一交易日增加739.62亿元,合计成交16996.05亿元。

对于坐了全球首富位置多年的比尔盖茨来说,人生经历是传奇的,其中就包含了“辍学办微软”的神话。**近日,比尔盖茨女儿菲比接受公开采访时表示,父亲反对我像他那样辍学创业。** [](https://n.sinaimg.cn/finance/transform/116/w550h366/20250401/ee66-c096e905f75daf2b7230fd4bbebd0f6c.jpg) “我几乎从没听过爸爸讲微软是怎么创立的,他总是更愿意谈基金会的工作。我记得当我向他提到想创办一家公司的时候,他的反应是:‘你确定你真的想这么做吗?’” 这也引发了网友的热议,有人直言:“这么看千万别在被盖茨辍学办微软的鸡汤文毒害了,他本人都不要求自己的女儿这么干,大家为啥要效仿呢,更何况现在世界已经跟过去不可同日而语了。” 1977年初,微软公司的业务迅速扩大,租赁的四个房间已经无法容纳这个公司。他们决定搬家,选阿尔伯克基市双圆中央大楼八楼一套房间为公司新址。这时,比尔·盖茨在哈佛办理了正式退学手续。 “在校园里多待一天,就会多一份悔恨;在校园里多待一天,就会少一个机会。”这是比尔盖茨当时最真切的感受。 当然后来的事情我们都知道了,微软大获成功,比尔·盖茨1995-2007年连续13年成为《福布斯》全球富翁榜首富 ,连续20年成为《福布斯》美国富翁榜首富 。 [查看评论](https://m.cnbeta.com.tw/comment/1491634.htm)
 雷峰网
雷峰网 雷峰网讯 4月9日,阿里云百炼上线业界首个全生命周期MCP服务,无需用户管理资源、开发部署、工程运维等工作,5分钟即可快速搭建一个连接MCP服务的 Agent(智能体)。百炼平台首批上线了高德、无影、Fetch、Notion等50多款阿里巴巴集团和三方MCP服务,覆盖生活信息、浏览器、信息处理、内容生成等领域,可满足不同场景的Agent应用开发需求。 MCP已被公认为大模型连接软件应用的标准协议,短短数月,兼容MCP协议的软件应用呈现指数型增长,极大地拓宽了大模型的应用边界。尽管国内外顶级科技企业相继推出基于MCP协议的Agent应用,但这些Agent应用仍无法解决千行百业真实场景的需求。企业和个人都需要针对专属场景定制一个具备自主思考、任务拆解、决策执行等能力的Agent。 此次,阿里云百炼上线的MCP服务可快速让大模型转化成真实场景的生产力工具。平台集成了阿里云函数计算、200多款业界领先的大模型、50多款主流MCP服务,全面解决Agent开发所需的算力资源、大模型资源和应用工具链等,用户可根据需求选择大模型和MCP服务,仅需简单的配置工作,无需代码几分钟即可完成一个Agent应用的搭建。据介绍,未来阿里巴巴集团更多应用和三方应用的MCP服务将逐步上线百炼平台,满足任意场景Agent的开发需求。 以日常生活应用场景为例,用户不需要繁杂的资源部署和运维工作,且无需编写代码让大模型调用和接管工具,直接在百炼平台上选择通义千问大模型和高德MCP服务,即可快速搭建一个具备城市旅游美食规划的Agent应用。该Agent不仅能完成基础的地图信息查询任务,它可根据用户需求查询目的地天气、规划一日游行程、搜索美食店铺推荐、导航或打车到对应店铺等,真正意义上实现了AI和真实世界的交互。 阿里云百炼高级产品专家徐志远表示:“MCP的出现正在加速大模型的应用落地,而Agent正是大模型落地的最佳载体,预计未来几年Agent的数量将远远超过现有的软件应用。我们需要构建一套完整的MCP服务生态,为用户提供一站式MCP服务托管及调用能力,让千行百业都建立起生产级的AI应用。” 雷峰网文章

<blockquote><p>随着人工智能技术的飞速发展,小模型、大模型、推理模型和多模态大模型等概念层出不穷,让人眼花缭乱。本文将用通俗易懂的语言,帮助大家在5分钟内快速理解这些模型的特点、区别以及它们在不同场景中的应用。</p> </blockquote>  现在很火的大模型到底是哪里来的,看下面这个图,熟悉生物学的应该一眼看出,这个是神经突触传递示意图。没错,现在的AI大模型的技术来源就是受人脑启发演变而来的,尽管我们对真实的人脑运作认知有限。 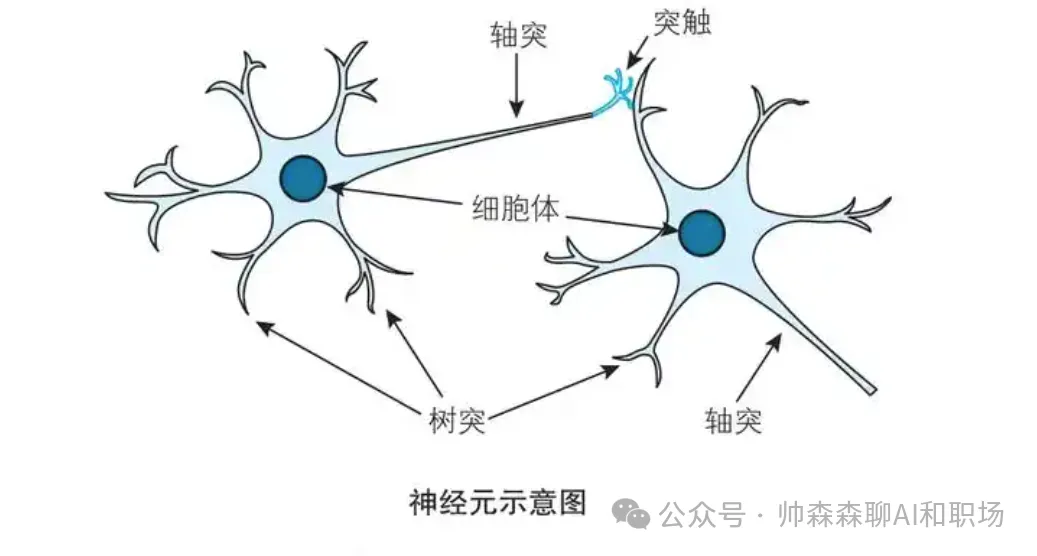 AI领域的模型大小都是以自身的参数量为衡量的,根据行业经验,大模型的参数量是10亿起步,因为衡量大模型参数的单位就是billion。 步入正文前叠个甲,下面这个图片都不陌生,但你知道这2个按钮该怎么使用吗?什么时候开?什么时候关?后面给出答案。  ## 小模型 顾名思义就是模型参数较小的模型,特点如下: - 参数量较小,在AI领域,**参数量在1亿(0.1B)以下**的模型通常被称为小模型。 - 计算需求较低,可以在资源有限的设备上运行,如手机、嵌入式系统等。 - 训练数据需求相对较少。 - 专注于特定任务,例如图像分类、目标检测、语音识别等。 **使用场景:** - 移动设备上的实时应用,如相机应用中的人脸识别,物体检测(方形框)。 - 物联网(IoT)设备上的边缘计算,如智能传感器。 **神经网络模型示意图如下:** 模型结构分为输入层、隐藏层、输出层。区分是大模型还是小模型就是中间隐藏层参数的层数和每一层参数量之和。比如下面这定义为小模型。 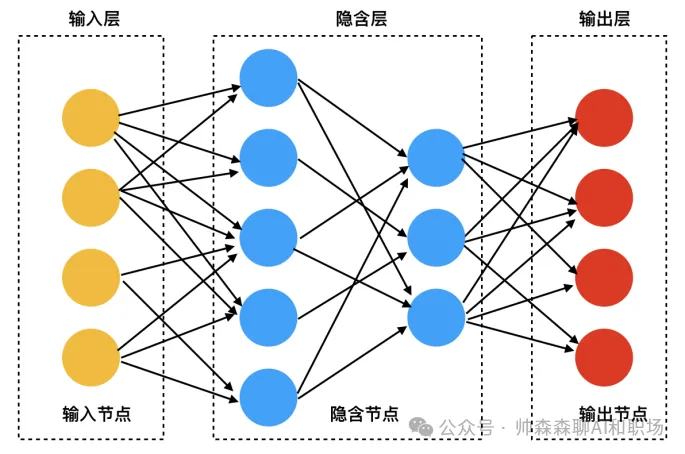 与之相对,当我们把隐藏层的层数和每一层参数量不断扩大后,达到一定程度,就变为大模型,也就是我们现在熟知的大语言模型。如下图: 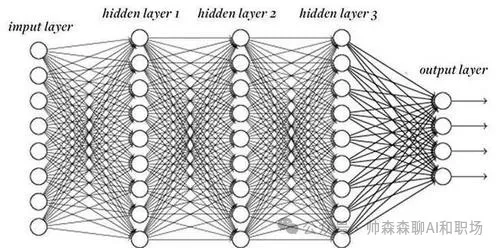  ## 大语言模型 (Large Language Models, LLMs) 特点如下: - 参数量巨大,通常在数百亿到数千亿之间。 - 在海量文本数据上进行训练,能够生成高质量的自然语言文本。 - 具有较强的通用性,可以完成多种自然语言处理任务,如文本生成、翻译、问答、摘要等。 - 智能涌现,当模型学习一定程度后,慢慢的会举一反三,给他一个没有见过的语言问题,也能尝试解答。  **使用场景:** - 聊天机器人: 提供对话式交互,例如客服机器人、虚拟助手。 - 文本生成: 创作各种类型的文本,例如文章、诗歌、剧本。 - 机器翻译: 将文本从一种语言翻译成另一种语言等等。几乎所有语言处理的任务都可以使用大语言模型和小模型不一样的是,大模型的受众更广,想用的好使用也会有一定门槛 **使用技巧:** - 提示工程 (Prompt Engineering): 设计有效的提示语,引导模型生成所需的输出。 - 清晰明确的指令: 准确描述所需的任务和输出格式。 - 提供上下文: 提供足够的背景信息,帮助模型理解任务。 - 少样本学习 (Few-shot Learning): 在提示中提供少量示例,帮助模型学习新的任务。 - 微调 (Fine-tuning): 在特定领域的数据上进一步训练模型,提高其在该领域的性能。 - 检索增强生成 (Retrieval Augmented Generation, RAG): 结合外部知识库,提高生成文本的准确性和相关性。 这个里面的各个概念我们会单独出一篇文章,详细介绍给大家。上面这么多概念技巧表明,想让大语言模型发挥效果,其实是要借助各种工具的,模型自身就有很大局限。所以想用好,还是要好好学习一番,想学习AI的,可以评论区留言,告诉我你想解决什么问题 ## 推理大模型 有了大语言模型,为什么还要推理大模型? 推理大模型诞生的背景,当然是语言大模型的局限性 语言大模型(如GPT系列)虽然在文本生成、对话等任务上表现出色,但其核心能力仍局限于“直进直出”概率驱动的文本预测,这导致以下问题: - 复杂任务表现不足:在数学证明、科学问题求解等需要多步分解的任务中,传统语言模型易出现逻辑断裂或“幻觉”。 - 缺乏反思能力:模型无法像人类一样通过“慢思考”验证中间步骤,导致错误累积 **推理大模型怎么工作的?** - 思维链技术:核心是“分步思考”。通俗说就是大的问题分布拆解若干步骤,然后求解。但是和人的真正思考不是一回事,毕竟现在人的智能还没有被解析。 - 强化学习训练:通过“试错”学习,像教小孩做题:做对了奖励,错了就调整。这让模型自己学会最优推理路径(如OpenAI的o1系列) **推理模型真的会推理吗?** - **答案很微妙:**它会模拟人类推理的“表面行为”,但不会像人类一样“理解逻辑”。 - **像推理的“演员”:**模型通过海量数据学习解题步骤的规律(比如先设变量、再列方程),但不懂背后的数学原理。 - **作弊式推理:**它像考试时偷偷带小抄,把“看到问题→匹配套路→输出答案”变成肌肉记忆。 - **人类开挂法:**为了让模型更像“真会推理”,工程师还会用数学题答案当参考答案逼它练习(强化学习),或者让它调用计算器算数(工具增强)。 总结一下:**推理模型不会真的推理,只是在模仿人思考的模板,就是学套路学得好。不信可以看下面这个例子:**  解答模式真的没问题,但是不是哪里不太对?看下面 首先有翅膀不意味着会飞,比如鸡就有翅膀 汤姆猫显然是一个动画角色,模型此时就不知道“变通”啦 总结:没有常识,只会按照固定的模版执行 如果我们这样问:“汤姆猫是什么剧中的那个角色?”  结合上面2个事例,可以知道其实模型是有这方面的记忆,但是它不知道**“联想和思考”** ## deepseek界面为例,介绍不同按钮的功能和作用  大家用了这么长时间的大模型,是否明白上面2个按钮打开或关闭分别起什么作用嘛? - 联网和深度思考都开:推理模型R1回答问题时会结合搜索到的互联网内容进行解答 - 联网和深度思考都关闭:那就是deepseek的V3模型自己在进行问题解答 - 联网开和深度思考关闭:V3模型回答问题时会结合搜索到的互联网内容进行解答 - 联网关闭和深度思考开:那就是deepseek的推理模型R1自己在进行问题解答 那么,在使用中,“深度思考”和“联网搜索”按钮打开或关闭的分别适用场景和作用是什么? **深度思考(DeepSeek-R1模式)** - 作用:调用深度推理模型,专注于复杂逻辑分析、多步骤推演和长文本处理(如数学建模、代码调试、学术论文解析)。 - 优势:回答准确性高,支持256k超长上下文记忆,适合专业领域问题 - 劣势:响应速度较慢,无法实时获取外部信息,个别时候推理会带来“致幻” **联网搜索(实时检索模式)** - 作用:接入互联网实时数据(如新闻、政策、学术论文)和平台生态内容(公众号、视频号),解决时效性问题。 - 优势:信息更新快(如股票行情、赛事比分),整合多源数据(3000+信源)增强答案权威性。 - 劣势:可能引入噪声干扰,响应速度略慢 **何时开启?** 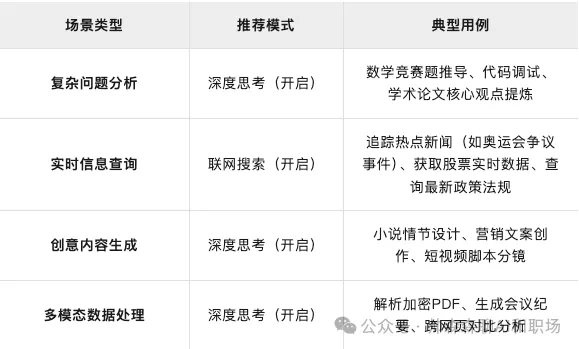 **何时关闭?** 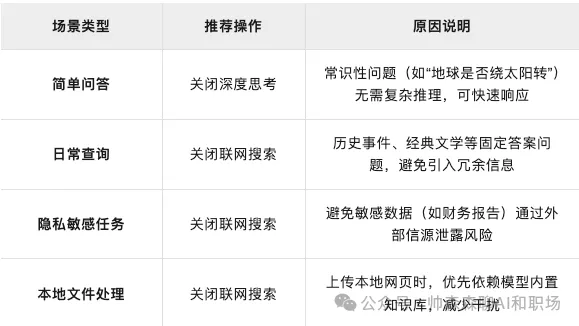 大语言模型一般只能处理文本信息,如果想结合图文音视频信息解决问题,就需要多模态大模型 ## 多模态大模型 特点: - 能够处理多种类型的输入数据,例如文本、图像、音频、视频等。 - 通过跨模态学习,理解不同模态数据之间的关系。 - 能够生成多种模态的输出,例如根据文本生成图像,或者根据图像生成描述。 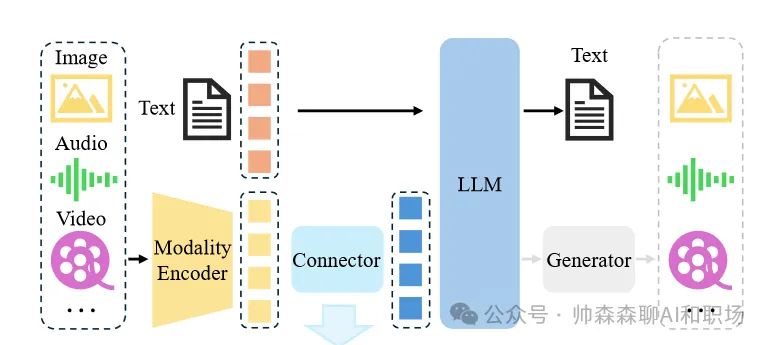 **使用场景:** - 跨模态检索: 根据一种模态的数据检索另一种模态的数据,例如根据文本描述搜索图像。 - 视觉问答 (Visual Question Answering, VQA): 回答与图像内容相关的问题。 - 图像描述生成 (Image Captioning): 生成描述图像内容的自然语言文本。 - 多模态对话: 进行涉及多种模态信息的对话,例如“这张图片中的人正在做什么?” (需要理解图像内容)。 - 具身智能 (Embodied Intelligence): 帮助智能体理解周围环境并与之交互。 现有模型能力,输入可以是文本、图像、音频、视频等。但是输出还是局限在文字和图片(图片能力进化中)。随着模型能力和边界的扩展,未来模型可实现下图构思。 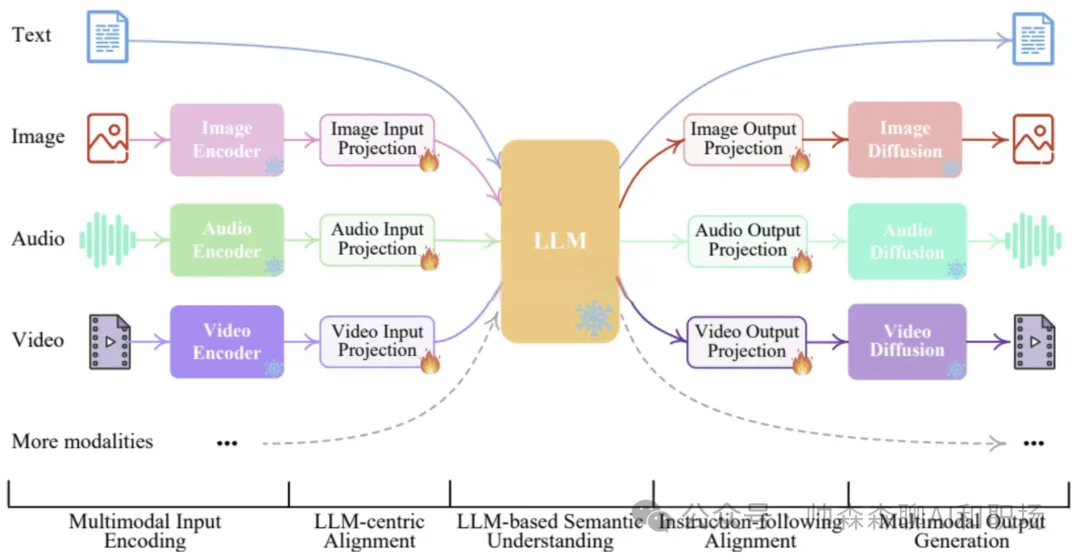 ## 总结 不是功能越丰富就越好,要根据问题的特点选择合适的模型和辅助工具。不是每个问题都需要使用推理模型,因为模型在推理的过程中会出现推理错误,从而导致“致幻”回复。 作者:帅森森,公众号:帅森森聊AI和职场 本文由 @帅森森 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

值得注意的是,对于香港而言,此次特朗普对全球加征关税事件或许“危中有机”,或许有助于香港在和新加坡的竞争中获得更多优势。
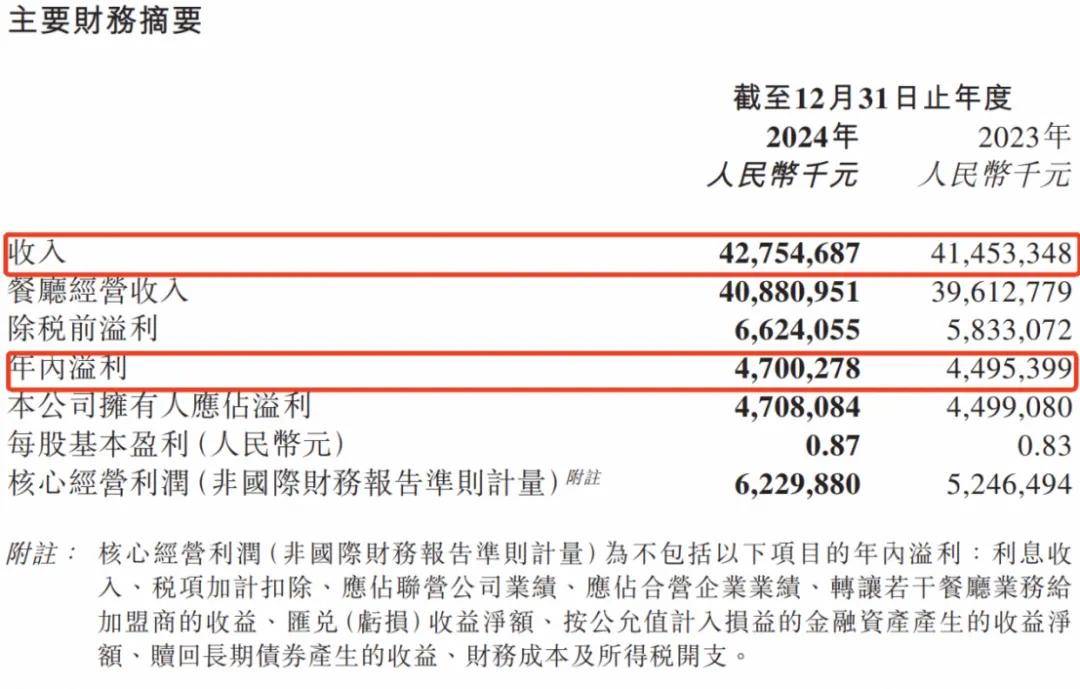


<blockquote><p>随着零售业务的复杂性不断增加,对采购结算系统的要求也日益提高。本文深入探讨了零售行业采购结算系统的设计思路,重点分析了表结构设计、主要表单及其核心字段的设置。</p> </blockquote>  在零售行业,【采购结算系统(Procurement Settlement System)】是财务系统和供应链系统中,均不可或缺的一环。随着零售业务的快速发展及其带动相关供应链企业的共同壮大,对【采购结算系统】的准确性、及时性和自动化要求越来越高。 本文(下篇)将围绕【采购结算系统】的表结构设计、主要表单及其核心字段两方面浅析【采购结算系统】的设计思路。 ## 一、采购系统的表结构设计 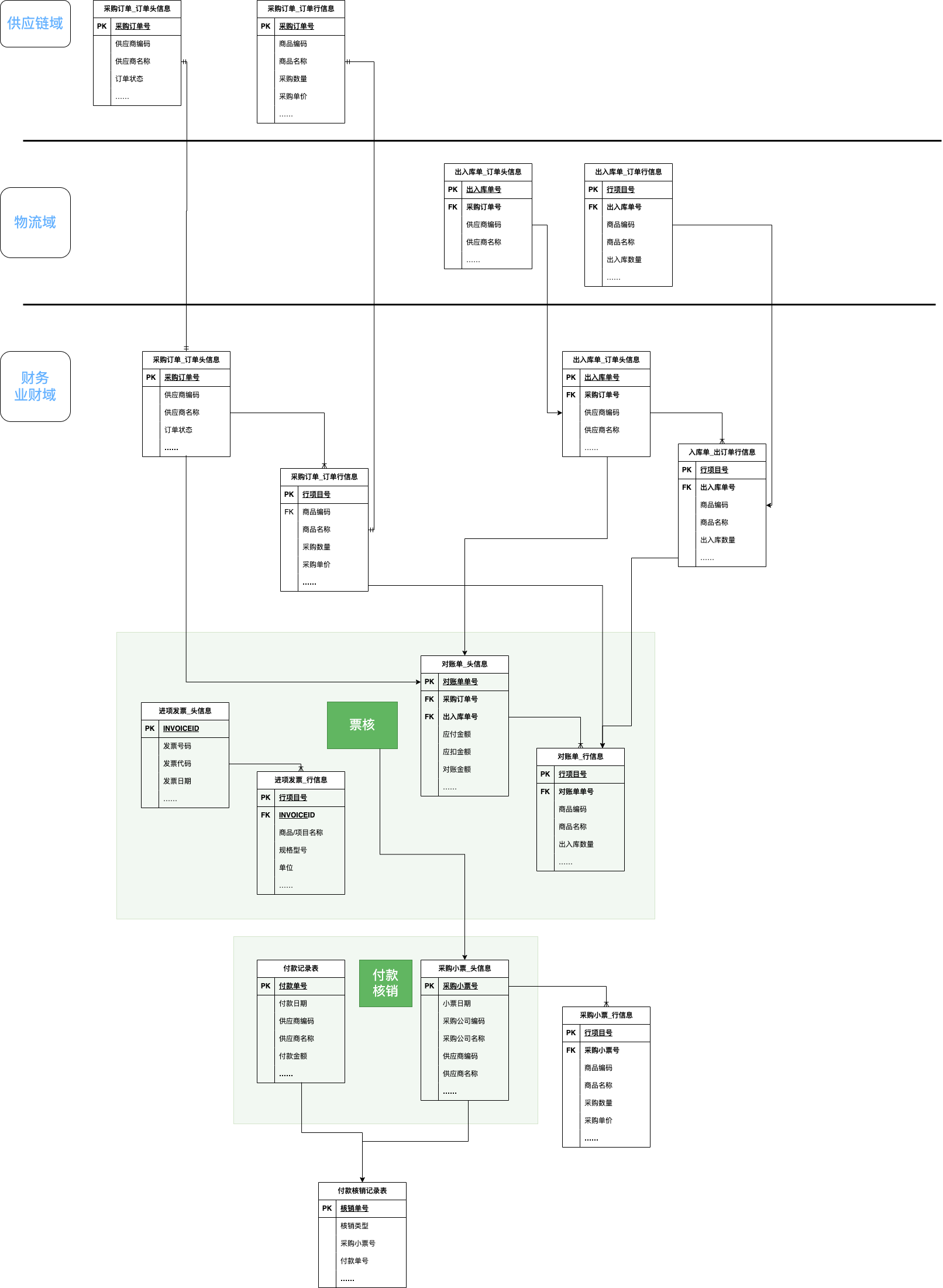 【采购结算系统】的源数据分别来源于【采购管理系统(PMS)】和【物流管理系统(WMS)】,所以其数据表设计上首先会有对“采购订单”和“出入库单”两项对源数据的继承,按头行信息分别为“采购订单_订单头信息表、采购订单_订单行信息表”和“出入库单_订单头信息表、出入库单_订单行信息表”4张数据表,用于记录采购订单中关于供应商、采购商品的信息和出入库中商品实际到货信息。 有了上游系统的源数据后,【采购结算系统】对“采购订单数据”和“实际到货数据”加工形成“对账数据”,即“对账业务单_头信息表”和“对账业务单_行信息表”,并基于此形成“对账单表”,用于记录需与供应商对账确认的“采购-到货-付款”信息。 供应商对账确认后,作为销售方会开具增值税发票至采购方,采购方收到发票后,录入系统形成发票的结构化信息,即需要“进项发票_发票头信息表”和“进项发票_发票行信息表”,用于记录发票的信息。 有了确认的对账信息和进项发票信息,【采购结算系统】会执行其核心职能之一的“票核”,即对“对账信息与发票信息进行一对一核对”,核对之后的数据,形成所谓的“采购小票”,其数据记录至“采购小票_头信息表”和“采购小票_行信息表”。 基于“采购小票”,系统会判断是否已有预付款,如果无预付,则会生成待付款数据,用于后期按供应商付款账期推送付款指令,即需要“付款记录表”记录这一数据;如果已有预付,会将预付款和采购小票进行“核销”,完成付款确认,则需要“付款核销记录表”,确认已对付款执行完成。 ## 二、采购结算系统的主要表单和核心字段 (注:表单限于版面,仅列示了部分核心字段,也未做相关按钮,以表意为主。) ### 1.采购订单同步表 连接采购活动和财务结算的关键环节,记录采购订单中涉及财务结算需要的字段。 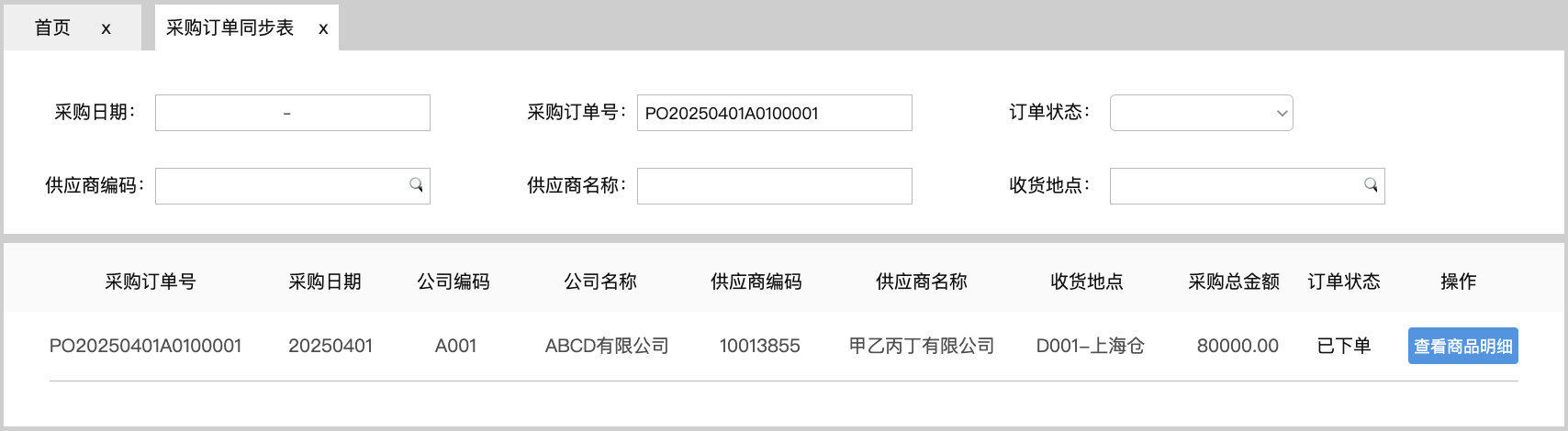 核心字段:采购订单号、公司信息(编码、名称)、供应商信息(编码、名称)、采购信息(数量、单价、总金额)、订单状态、商品明细信息(编码、名称、数量、单价) ### 2.库存同步表 同步库存实际到货/退货的商品数量,作为与供应商对账的采购数量依据。 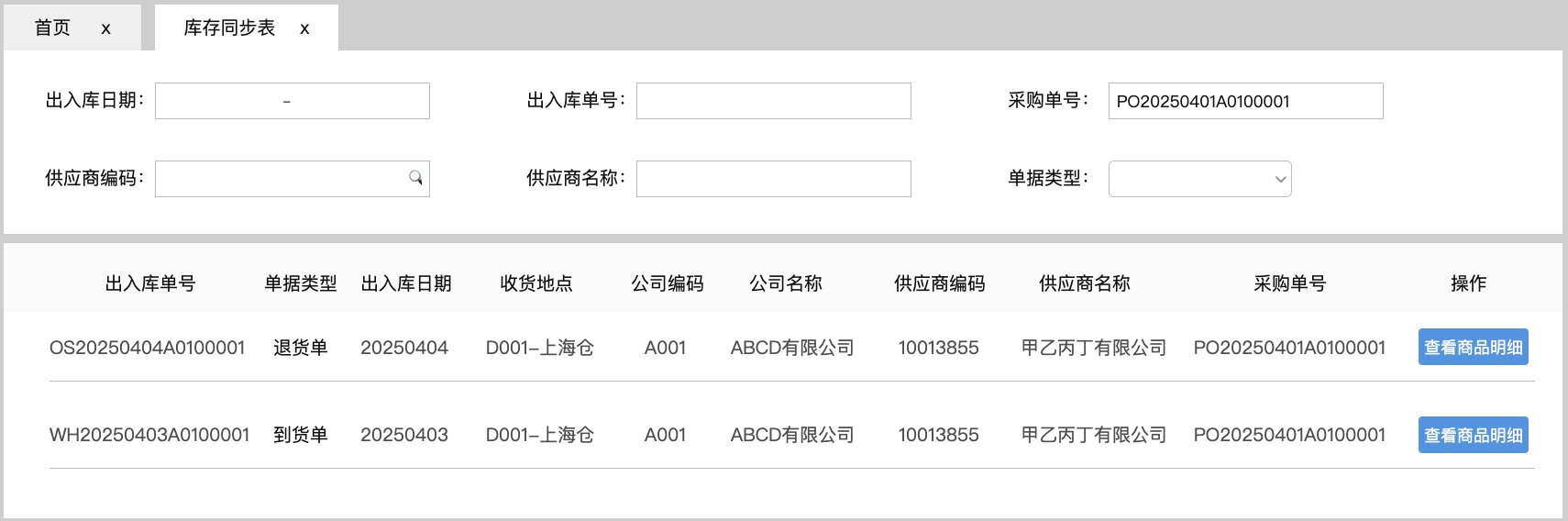 核心字段:出入库单号、单据类型(到货、退货)、商品信息(编码、名称)、库存信息(入库数量、退货数量)、采购信息(采购订单号、供应商编码、供应商名称、采购公司编码、采购公司名称) ### 3. 对账业务单表 根据采购订单和库存到货信息形成的供应商结算依据,以出入库单为基础,一一对应生成的对账基础数据。 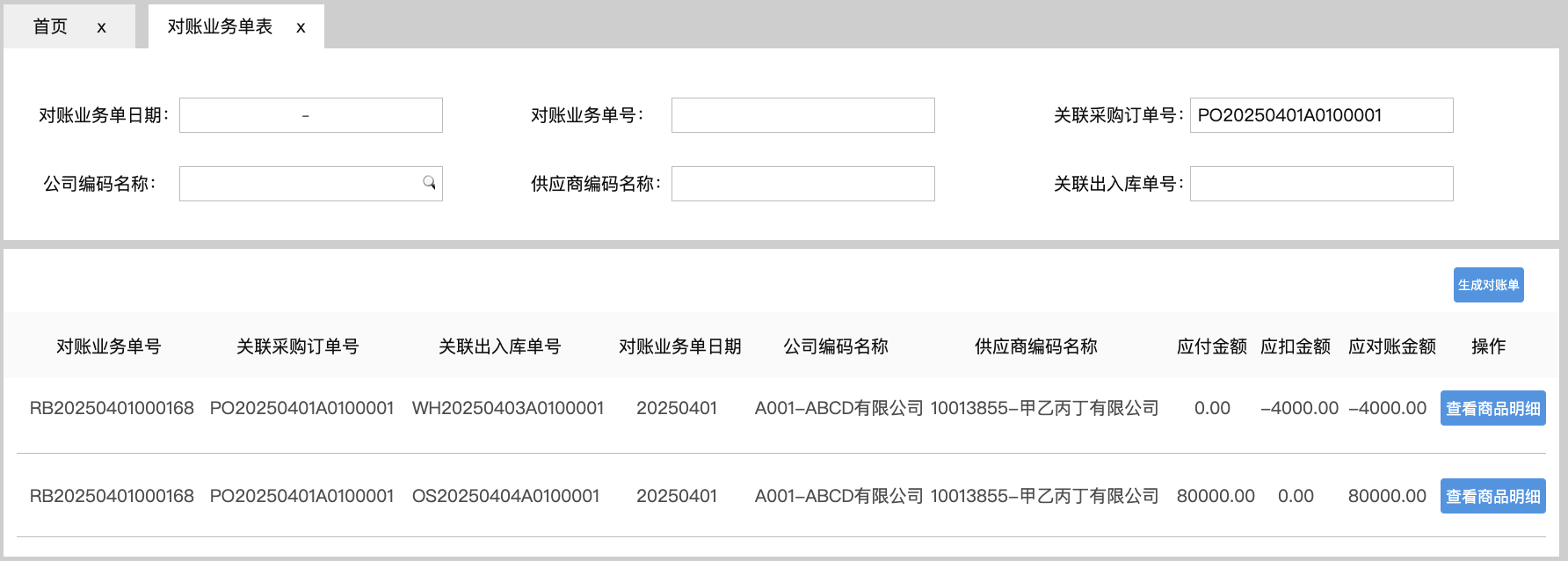 核心字段:对账业务单号、上游关联信息(关联采购订单号、关联出入库单号)、供应商信息(编码、名称)、金额信息、商品明细信息(采购数量、到货数量、单价)。 ### 4.对账单表 基于对账业务单合并或独立生成的供应商对账数据,与供应商结算及其开票的依据。 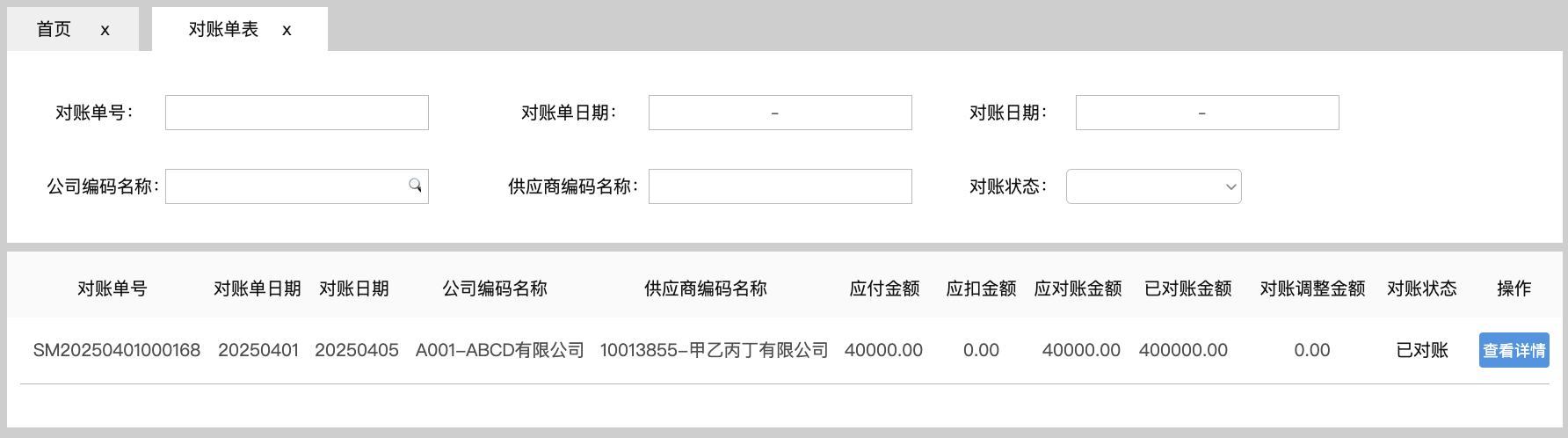 核心字段:对账单号、供应商信息(编码、名称)、采购订单号、、对账信息(对账日期、对账金额、对账状态)、商品明细信息(采购数量、到货数量、单价) ### 5.发票信息查询表 记录发票信息,查看发票票核情况,特别是税额的及时抵扣情况。 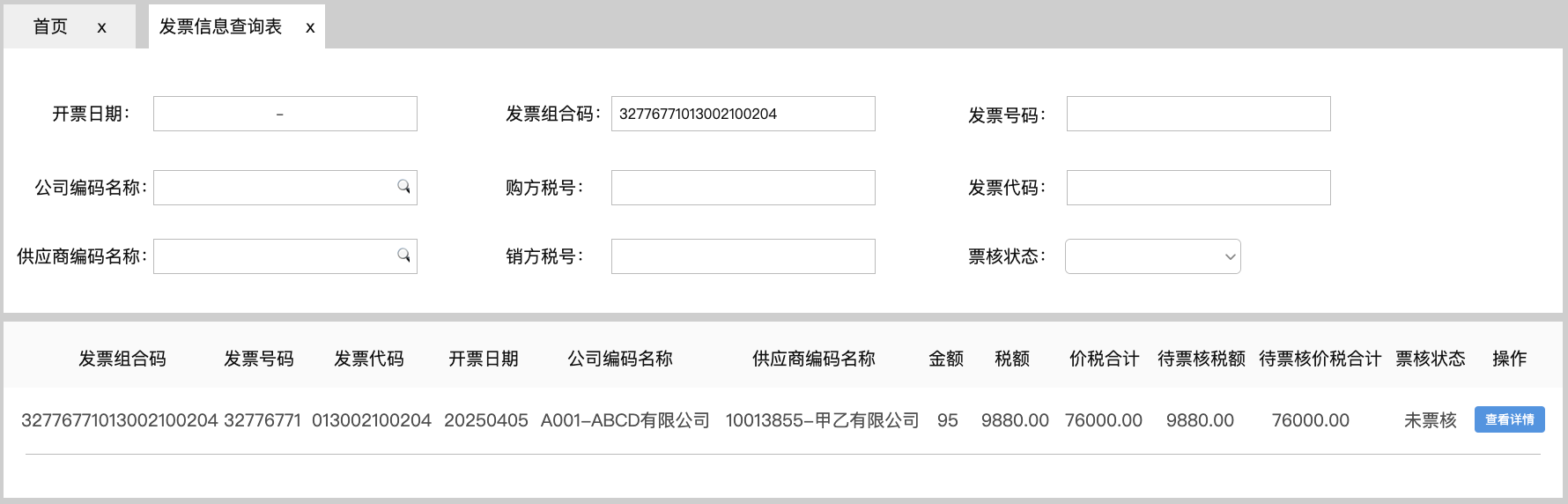 核心字段:发票信息(号码、代码、日期、购销方信息)、公司信息(编码、名称)、供应商信息(编码、名称)、票核信息(金额、状态) ### 6.付款信息表 记录预付款和票核后的付款申请,并查看付款状态及其付款凭证的状态。 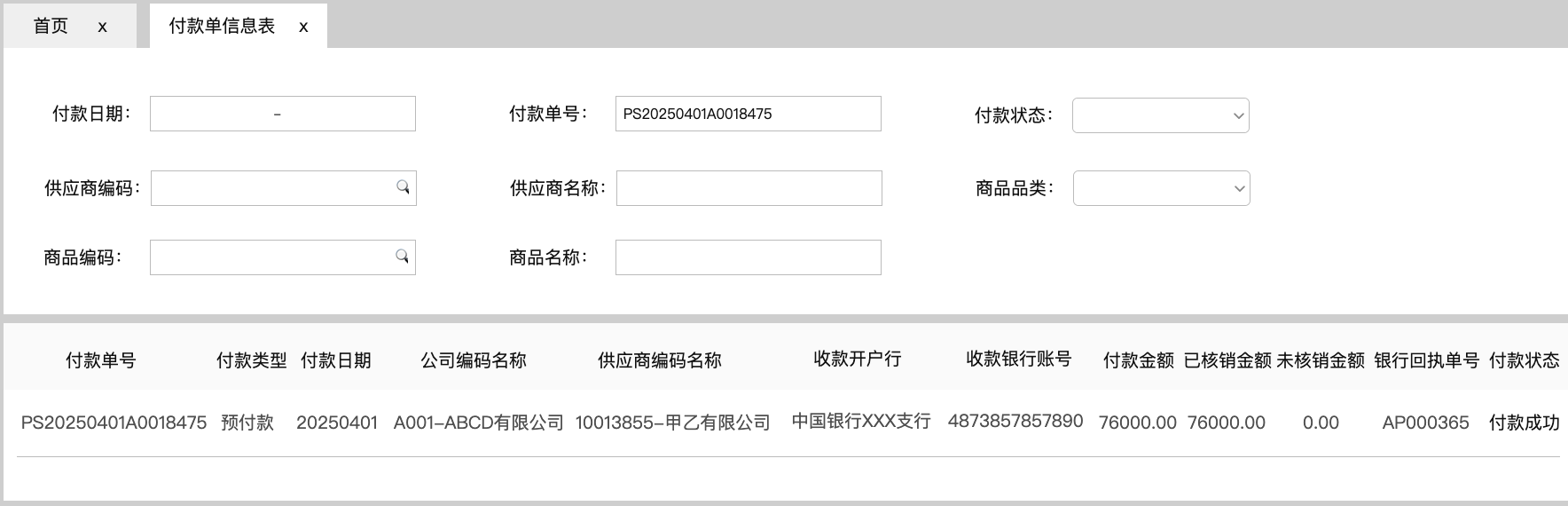 核心字段:申请人信息(公司、部门、人员)、付款对象信息(公司、开户行、账号)、收款对象信息(供应商、开户行、账号)、金额信息(付款金额、已核销金额、未核销金额)、审核信息、状态信息。 本文由 @藤真君 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
 小众软件 · 青小蛙
小众软件 · 青小蛙
Auto Mouse Clicker 是一款简单易用的自动鼠标点击器,只需要让他录制你的鼠标操作,包括移动和点击,然后重放这个过程,就实现了自动点击。还可以设置循环,以及每次的间隔。@Appinn 这

<blockquote><p>本文将为新媒体运营新人揭示这一矛盾的本质,分析获客与品牌宣传的不同策略和侧重点,并提供实用的建议,帮助新人在工作中找到平衡,提升运营能力,避免在行业竞争中迷失方向。</p> </blockquote>  无论你是新媒体运营专员、运营助理,还是专注于小红书、抖音等平台的内容运营岗位,这篇文章是我作为新媒体运营过来人,为你写的血泪教训。 我知道,刚踏入新媒体运营这个行业的你们,可能还在迷茫中摸索。 你有没有想过,你现在真正的工作目标是什么?是获客,还是做品牌宣传?这可是两个截然不同的方向啊。 **获客,是为了直接带来客户,让产品或服务触达潜在消费者;** **而品牌宣传,则是提升品牌知名度,让品牌在用户心中扎根。** 两者虽然相辅相成,但操作方式和侧重点完全不同。 之前找我咨询过的不少新媒体实习生,毕业后稀里糊涂地进入公司,靠运气发了几篇爆款文章或视频,就误打误撞地坐上了新媒体运营的岗位。 但进入公司后,你总得学点真本事吧?有些公司甚至没有新媒体主管这个职位。 你进去后拿着几千块钱的工资,模仿着别人的爆款笔记发内容,一个月下来,账号数据惨不忍睹。 运气好的,能混一两个月,出一篇爆文还能撑下去;运气不好,就只能被公司淘汰。 初阶的新媒体运营,每天就只是机械地发文、做设计,甚至还要帮销售岗位拉客源,却没有时间去学习、进步。几个月过去,还在原地踏步,甚至被限流封号走弯路。 做品牌宣传的小伙伴,不知道怎么提升品牌的知名度和曝光量,拿着产品图就发,却没想过提升自己的文案能力。 我知道,这时候肯定有人会说:“我不想努力,只想躺平。” 但我想说的是,如果你真的努力提升文案编辑能力、海报设计能力、品牌策划能力,学会拆解对标账号、搭建引流体系、编写SOP(标准操作流程),那你完全可以跳槽到更好的公司,当上运营主管,月薪过万,这难道不香吗? 我知道,很多新人会问:“你说的这些我都不懂,该怎么接触呢?会不会很难?”其实,难的不是学习这些技能,而是突破自己的舒适区。 你的老板可能只关注热门内容,让你跟着热点走,口播火了就让你做口播,创始人的个人IP火了就让你学着打造老板IP,还让你结合公司同事拍视频、做宣传。 完不成任务,被扣绩效的是你,挨骂的还是你。这就是大多数新媒体人面临的挑战。 为什么说新媒体运营越来越“水”?大环境不好,越来越多的个体户老板不懂新媒体,只知道缺这个岗位,却不知道怎么培养人才。 两边都不努力,老板思想保守,把新媒体当作销售岗位,低底薪+提成画饼,却要求你既做品牌宣传,又做拉客引流。 获客和品宣本身就是冲突的,品牌宣传账号(蓝V号、官方号)应该发布公司理念、品牌价值等内容,而引流号则应该通过各种小号,按照引流SOP去寻找潜在客户。 这两者之间的矛盾很大,如果你的老板还不明白这一点,下次就把这篇文章转发给他看看! 所以,作为过来人我懂你的辛酸,努力不是为了让你每天拆解账号,也不是为了让你死记硬背SOP,而是为了让你在跳槽时,有更多拿得出手的过往案例和亮眼数据。 媒体行业竞争激烈,如果你没有沉淀经验,又不努力提升自己,只会让这个圈子变得越来越糟。 你可能连直播间怎么搭建、直播软件怎么用都不知道,却要承担全面的运营工作。这样的情况,只会让行业环境越来越差。 记住,你发的每一篇笔记、每一条视频,不能只是数量多,更要保证质量。努力提升自己,总比浑浑噩噩地混日子强。 相信我,努力一定会有回报!希望你们都能在这个行业找到自己的方向,实现自己的价值。 本文由 @秃头老王聊运营 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自 Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

<blockquote><p>在电商和本地生活服务领域,店铺营业时间的管理对于提升用户体验和商家运营效率至关重要。本文将详细探讨如何设计一套灵活且高效的店铺营业时间管理系统,以应对节假日停业、日常营业时间调整等复杂场景。</p> </blockquote>  ## 一、业务需求 根据店铺不同的营业需求(节假日停业、日常营业时间调整),设计一套可灵活配置的营业时间管理系统,同时优化用户在非营业时间或停业期间的交互体验,确保用户能够清晰了解店铺状态并合理引导用户行为 ## 二、方案设计与核心思路 ### 目标 - 提供灵活配置店铺营业时间的工具,适应节假日停业、非高峰日调整等场景 - 确保用户端交互清晰,避免非营业时段下单导致的客诉 ### 核心功能模块 - 营业配置:支持节假日停业计划(如春节)、日常营业时间(按星期配置) - 实时校验:系统在用户下单全流程中实时校验营业状态,确保订单有效性 - 交互提示:通过界面交互(如提示文案、按钮置灰)告知用户当前店铺状态,减少无效操作,达到结算流程阻断效果 - 异常处理:动态校验营业状态,处理因营业时间变更的冲突场景,设计回滚或拦截机制 ### 核心逻辑 - 分层判断:优先判断停业计划,再判断日常营业时间。 - 实时性:关键节点(进入店铺、加购、商品详情页、结算、提交订单)均触发营业状态校验。 - 用户感知:通过文案、按钮状态、页面拦截等方式明确传递停业信息 ## 三、功能设计 ### 3.1 营业计划配置(商家端) **1)节假日停业计划配置** 建议功能入口:商家后台「门店设置」→「营业计划」→「停业计划」。 配置逻辑: - 支持设置停业时间段(如2025/5/1 00:00 – 2025/5/5 24:00),期间用户不可下单 - 支持多时段停业(如:春节停业+清明节停业)。 - 交互:日历选择器 + 时间选择控件 **优先级规则:停业计划优先于日常营业时间,若停业期间内,系统直接判定为停业状态**。 **2)日常营业时间配置** 建议功能入口:商家后台「门店设置」→「营业计划」→「日常营业时间」。 配置逻辑: - 按星期一至星期日分别设置每日的营业时间(如:周一10:00-22:00,周二09:00-21:00)。 - 支持全天停业(如:周日00:00-00:00) - 交互:表格化设置,支持批量复制某天配置到其他日期 ### 3.2 交互设计(用户端) **1)店铺状态提示** 店铺首页: - 停业期间:顶部横幅显示“店铺停业中(2025年5月1日 0点至5月5日24点)”。 - 未到营业时间:显示“店铺未开业,请在XX点至XX点营业时间内下单”。 商品详情页: 禁止点击“加入购物车”按钮,点击时提示“当前非营业时间,无法下单”。或加购按钮置灰不可点击 **2)购物车与结算页交互** 购物车页面: - 非营业时段:结算按钮置灰,悬浮提示“当前店铺未营业,无法下单”。 - 提示文案同步显示具体营业时间或停业时段。 确认订单页: * 用户提交订单时,再次校验营业状态。若已停业,弹窗提示“店铺已暂停营业,暂时无法接单”(针对用户已进入结算页但店铺修改了营业时间场景处理) **3)异常场景处理** 营业时间动态变更冲突 - 用户提交订单瞬间店铺修改时间,处理方式为:系统在提交订单时再次校验营业状态,若状态变更则拦截并提示。 - 用户已进入订单页但未提交,处理方式为:定时轮询营业状态(每30秒),变化时弹窗提示。 缓存与数据一致性 营业时间数据缓存5分钟,商家修改后强制刷新缓存,确保用户端及时生效 ### 3.3 系统判断逻辑(后端) **1)核心判断流程** 触发场景:用户进入店铺首页,商品详情页、商品加购、点击购物车结算、提交订单。 校验逻辑: - 停业计划优先级:检查当前时间是否在停业时间段内。 - 日常营业时间校验:若未停业,则检查当前星期对应的营业时间是否包含当前时间。 - 结果反馈:返回状态码(营业/停业/未到时间),并触发对应交互提示。 **2)具体实施** 进入店铺页时 - 请求最新营业计划,判断是否在停业期或非营业时段。 - 若停业,展示停业横幅;若未营业,展示营业时间。 加购商品时 禁止点击“加入购物车”按钮,点击时提示“当前非营业时间,无法下单”。或加购按钮置灰不可点击 购物车结算按钮点击时 调用实时接口校验营业状态,阻断非营业时段操作 订单提交时 提交前调用强制校验接口,若停业则返回错误码,前端拦截并提示 **3)接口设计** 接口1:获取营业状态 - GET /api/store/operation-status - 返回字段:is_open(是否营业)、current_status(停业/未到时间)、start_time、end_time。 接口2:订单提交校验 - POST /api/order/submit - 校验通过后允许提交,否则返回错误码并提示用户 ### 3.4 案例说明 **案例1:春节停业配置** 店铺配置: 在后台设置停业计划:2025年1月20日0点至1月28日24点。 用户交互: - 进入店铺页显示“店铺1月20日0点至1月27日24点暂停营业” - 购物车结算按钮置灰,提示停业时间。 **案例2:日常营业时间调整** 店铺配置: 设置周一营业时间:10:00-22:00,周二09:00-21:00。 用户交互: - 周一9:50进入店铺:提示“店铺未开业,10:00开始营业”。 - 周二21:05尝试下单:提示“当前店铺已打烊,请在明天09点后可下单” ## 四、异常场景处理方案 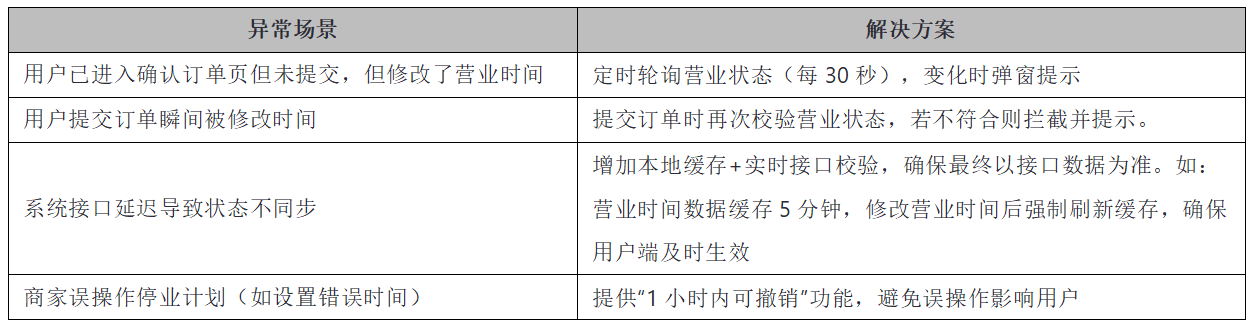 ## 五、总结 **1)核心价值:** - 店铺可灵活配置营业计划,减少因时间冲突导致的用户投诉与平台处罚。 - 用户通过清晰提示确感知停业状态,减少无效操作,提升体验。 **2)技术实现:** - 后台配置模块需支持多时段存储与优先级判断。 - 前端需实时获取状态并触发交互,确保一致性。 **3)扩展性:** - 未来可接入天气、活动等智能推荐营业时间,如高峰营业时段 早餐(06:00-9:59) 午餐(10:00-13:59) 下午茶(14:00-16:59) 晚餐(17:00-20:59) 宵夜(21:00-05:59)。 - 结合促销活动,支持临时延长营业时间 **4)风险控制** - 停业期间自动拒绝所有订单,避免履约纠纷。 - 关键操作记录日志,便于售后溯源 ## 六、最后说下功能设计构思思路(很重要) 在拿到这个需求后,我们需要先梳理整个功能大概框架思路,这是每个产品经理的基本功 首先,我们需要想到核心点可能是营业时间灵活配置、实时判断、友好的提示和容错机制 功能配置上,需要有两种配置:节假日停业配置和日常营业时间配置,系统需要判断当前时间是否在营业时间内,或者是否在停业计划内,所以在设计时需要设计一个优先级,比如停业计划优先于日常设置,或者两者叠加 交互设计上,我们需要想到店铺详情页、商品页、购物车、结算页都有对应的提示。如当店铺停业时,显示具体的停业时间段,这里要确保提示信息明确,告知用户何时可以下单 异常场景处理,这个是最关键的,很多产品经理在做功能设计时,最容易忽略此点,如:用户已经进入确认订单页,商家突然修改了营业时间,这时候系统需要在提交前再次检查营业状态,如果发现变更,阻止下单并提示,所以我们在设计时需要考虑系统如何实时同步数据,或者在提交时再次验证的系统逻辑 另外在做功能设计时,需考虑订单创建时的状态需要记录,避免出现后续纠纷。比如,用户下单时店铺是营业的,但之后店铺关闭,这样的订单可能需要特殊处理,比如联系用户或商家协商 **结合以上思路,输出整体可执行的产品解决方案** 本文由 @pemg的笔记 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

如果台积电不赴美建厂有何后果?被征收100%的税是跑不了的。美国总统特朗普当地时间4月8日在共和党全国委员会活动上自爆曾威胁台积电,如果不在美国设厂将缴纳高达100%的税金。 [](https://static.cnbetacdn.com/article/2025/0102/784fb5a13027d1c.jpg) 两名知情人士透露,台积电可能面临10亿美元或更高的罚款,以了结美国对该公司生产的一款芯片的出口管制调查。 **之前台积电高级副总裁Peter Cleveland在美国表示,该企业在美子公司TSMC Arizona的第二座先进制程晶圆厂正在建设中,而台积电对第三晶圆厂的态度是希望尽快动工,这需要美国政府在环评认证流程上配合。** 根据美国官方《芯片与科学法案》相关网页,TSMC Arizona第二晶圆厂将提供3nm FinFE 制程产能,预计将于2028年投产;而第三晶圆厂将深入2nm和A16的Nanosheet (GAA) 制程,有望在本十年末投产。 在这之前,芯片代工巨头台积电计划对美国工厂追加投资1000亿美元,以提升其在美国本土的芯片产能,并支持总统特朗普壮大国内制造业的目标。 魏哲家表示,将在已规划的650亿美元投资的基础上追加这笔投资,将创造数千个就业岗位。 [查看评论](https://m.cnbeta.com.tw/comment/1491624.htm)

《华尔街日报》周二发文称,在被埃隆·马斯克(Elon Musk)收购后,X一度形势危急,濒临破产。然而,马斯克利用他的另外一家公司xAI以及自己与美国总统特朗普的亲密关系把X从悬崖边拉了回来,并让它成为了一个估值超8000亿元的AI巨头。  马斯克 今年1月,一群投资者聚集在摩根士丹利纽约办事处,聆听X的销售推介,渴望投资一笔曾经让华尔街避之不及的债务。在这场活动上,手机被禁止使用,听众被告知要保持坐姿,直到X CEO琳达·雅卡里诺(Linda Yaccarino)和其他人离开房间。雅卡里诺等人在活动上做了简短发言,没有接受观众提问。 2022年,马斯克斥资440亿美元收购了Twitter(现在叫X),其中130亿美元是摩根士丹利等七家银行提供的贷款。银行通常会在发放贷款后,把这些债务以可交易的债券形式出售给投资者,借此将风险转移到认购投资者身上。 摩根士丹利等银行原计划以每美元95美分的价格出售30亿美元的债券,但最终以更高的价格出售了逾100亿美元的债券。这笔债券销售的成功证明,投资者相信X有能力吸引广告商回归,这在很大程度上得益于马斯克与特朗普的密切关系。  X 另外,促成此次债券成功销售的另一个重要因素是,X有朝一日可能会与一家更热门、更具上升潜力的公司合并,也就是马斯克的人工智能公司xAI。X高管在与华尔街投资者的私下会面中表示,X很有可能最终会与xAI合并。xAI开发了Grok聊天机器人。 **濒临破产** 马斯克称,他从未让投资者蒙受损失,但在很长一段时间里,他看起来要在X身上栽跟头。在马斯克2022年收购X后,广告商因为内容审核担忧纷纷撤离。X收入下滑,贷款眼看也要成为银行的不良资产。在马斯克接管X一个月后,他表示这家公司濒临破产。 知情人士称,X 2023年营收从2022年的大约46亿美元下降到了30亿美元。2023年初,资产管理公司富达投资对X的估值只有马斯克收购价的大约三分之一。 马斯克曾试图说服心存担忧的广告商回归,一度提供了大幅广告优惠,甚至威胁广告商称,如果他们的广告支出不足,就会失去认证。 **东山再起** 首先,X得到了xAI的拉动。xAI是马斯克在2023年春季创办的创业公司,旨在与OpenAI竞争。X为xAI提供了构建AI模型所需的芯片和其他关键硬件。作为回报,X获得了xAI 25%的股份。 随着xAI估值的飙升,这些股份成为了X资产负债表上最有价值的资产之一。 接着在去年,马斯克与特朗普的关系越走越近,并为特朗普的胜选立下了汗马功劳。马斯克与特朗普的亲密关系协助说服了一些广告商回归X。 知情人士称,虽然X的2024年营收再次下降至大约26亿美元,但是在去年最后一个季度有所回升。而且,X还在积极削减成本。 **放大招** 知情人士称,马斯克和他的顾问们早就考虑过将X和xAI合并,这一计划在美国大选后提速。为了实现这一目标,他们知道需要按照正确的顺序成功执行几笔操作,同时还需要一点运气。 美国大选后,马斯克影响力大增。X采取了新的策略来增加广告收入。去年12月,X的一位律师致电广告集团埃培智(IPG)的一位律师,暗示埃培智与竞争对手宏盟集团的130亿美元合并交易可能会因特朗普政府的干预而受阻,因为马斯克可以在这笔交易中发挥重要作用(有威胁的意思)。随后,埃培智就广告支出与X达成了新的年度协议。 接着,其他广告商也开始增加对X的广告投入。其中,亚马逊的态度也发生了变化,从1月份开始增加在X上的广告支出。 今年3月初,X从新旧投资者那里筹集了大约9亿美元资金,估值刚好略高于马斯克最初收购X时的价格。此次融资使得X的估值重新调整,使其与马斯克收购X时的估值更加一致。  马斯克与特朗普 就在宣布X与xAI合并前,马斯克在摩根大通全球技术银行业务主席马杜·南布里(Madhu Namburi)组织的一个峰会上发言,回顾了他收购X后的早期时光。 他向包括伊万卡·特朗普(Ivanka Trump)、前Alphabet CEO拉里·佩奇(Larry Page)、OpenAI CEO萨姆·奥特曼(Sam Altman)以及特朗普加密货币负责人大卫·萨克斯(David Sacks)在内的听众吹嘘,X的估值比他收购时更高,而且公司现在的盈利情况也大大改善。 **8000亿AI巨头诞生** 上个月底,马斯克在X上宣布,将把X与xAI合并,新公司的估值达到1130亿美元(约合8293亿元人民币)。对于X来说,它并入的是一家参与全球角逐,开发尖端生成式AI的更大规模公司,这能让它以更高估值融资。这个估值放在几年前是不可想象的。 而且,马斯克赶在特朗普宣布新的关税政策前达成了这笔交易。特朗普的关税政策实质上关闭了交易市场。 另外,这也让马斯克更加接近他的长期目标:将X打造成一个“万能应用”,让用户在上面分享新闻、支付账单和自娱自乐。知情人士称,合并后的公司首先会专注于将xAI的聊天机器人Grok与X进行更深入整合,使其成为应用体验的核心,类似于Google将AI功能整合到搜索中。 [查看评论](https://m.cnbeta.com.tw/comment/1491622.htm)