所有文章
 雷峰网
雷峰网在大模型竞速进入推理能力深水区的 2025 年,一支神秘的团队悄然登场。他们不是来自一线大厂的 AI Lab,也没有高调预热和融资造势,而是在 Hugging Face 低调开源了一款 32B 的推理模型:AM-Thinking-v1。 令人惊讶的是,这个中等规模的稠密模型,在多个关键推理评测中击败了 DeepSeek-R1,并与超大规模的 MoE 模型Qwen3-235B-A22B、Seed1.5-Thinking 不相上下。 这款模型背后的团队,是国内一个从未对外披露的研究团队——A-M-team。他们不依赖私有数据、不依赖海量计算资源,仅凭开源底座和训练管线的极致设计,就做出了开放社区 32B 级别中最强的推理模型。  论文链接:https://arxiv.org/pdf/2505.08311 ## 性能全面超越 DeepSeek-R1:32B 模型中的“黑马” 在当前主流评测中,AM-Thinking-v1 也交出了极具冲击力的成绩单,仅 32B 的结构在数学推理(AIME 系列)和代码生成(LiveCodeBench)中分别取得了 85.3 和 70.3 的高分,不仅全面超越了 DeepSeek-R1(671B MoE 架构),还逼近甚至追平了 Qwen3-235B-A22B 和 Seed1.5-Thinking 等超大规模 MoE 模型的成绩。 把“小体积,大推理”的极限范式展现得淋漓尽致。 值得注意的是,AIME 系列题目来自美国数学邀请赛,结构复杂、要求精准,历来是衡量模型逻辑思维能力的金标准;LiveCodeBench 则强调代码可执行性和稳健性,数据污染难度高,是真实场景下“思考-编码-验证”链条的严苛考验。  AM-Thinking-v1 模型测试得分表  AIME2024 不同模型尺寸效果对比;x 轴为模型尺寸,y 轴为分数  LiveCodeBench 不同模型尺寸效果对比;x 轴为模型尺寸,y 轴为分数 推特大 V Aran Komatsuzaki 也下场转发,并配文:AM-Thinking-v1 正以 32B 的规模推进着推理前沿性能的边界。  分数之外,是更具实际意义的任务。当研究人员用 AM-Thinking-v1 去解决典型的“旋转三角形中红球反弹”问题时,AM-Thinking-v1 展现出了多步逻辑极强的理解,给出了完整的运动轨迹模拟和对于小球碰撞的判断。  而在逻辑推理任务中,AM-Thinking-v1 也能保持非常稳定的思考过程。  在长文本写作能力的测试中,AM-Thinking-v1 在表达逻辑和意象捕捉方面也展现出了初步的组织能力。  ## 32B 模型的新上限,是这样“训”出来的 与追求超大规模和大数据堆叠不同,A-M-team 的关键突破在于如何用有限的计算和开源数据,最大化32B模型的推理能力。 他们设计了一整套后训练(post-training)方案,其中包括冷启动式监督微调、通过率引导的数据筛选机制以及双阶段强化学习(Dual-stage RL)。 首先在监督微调(SFT)阶段,团队用了一个相对激进但效果很好的设置:把学习率拉到了 8e-5,batch size 也做了加大,还支持最长 32K 的输入长度。训练样本被特别设计成“先思考再回答”的格式。 这个设计帮助模型建立了“先想清楚、再说话”的好习惯。而且,训练中还能明显看到模型越来越懂得控制长度、避免啰嗦——这些变化在平均生成长度和终止率上都有反映  其次在数据这块,团队完全依靠开源资源,从数学、代码、科学推理到指令跟随和通用对话,总共整理出了五类核心任务的数据。 他们花了大量时间做清洗:不仅去重、改写问题,防止和评测集“撞题”,还对数学数据进行严格验证,甚至用 DeepSeek-R1 和 o4-mini 来交叉比对标准答案。生成的训练样本也经过层层筛选,比如用 PPL 算分、检查重复短语和结构完整性,最终留下的数据干净又靠谱。  在最后的强化学习(RL)阶段,团队选用了 GRPO 这种轻量级算法,还特别搞了个“难度感知”的策略,意思是:先挑一些模型做得不太好的题来练,等熟练了,再加入一些通用对话和指令跟随任务来拓展能力。 奖励机制也挺讲究:数学和代码类的问题用规则验证或者直接跑沙盒程序验证答案;而像 open-ended 回答这种,就让 LLM 来打分,从有用性、准确性、连贯性这三方面评估,保证模型在各方面都能进步。 当然,为了让整个 RL 训练高效跑得动,A-M-team 还在工程上动了不少脑筋。比如他们把推理和训练分开,用了 streaming rollout 的方式,还配了个前端负载均衡器,能根据每张 GPU 的实际压力动态分配任务,最大限度避免“有的卡闲着、有的卡累死”的情况。不仅训练稳,还能大大节省时间和算力  总的来说,虽然 AM-Thinking-v1 已经在推理上做得很出色,但它目前还不支持函数调用、多模态输入,对低资源语言的能力也有待验证。 不过,即便如此,它已经把 32B 模型的性能潜力挖掘到了极致,也为开源 LLM 社区提供了一个值得借鉴的思路:不靠堆参数、不靠私有数据,通过细致训练设计,也能做出足够聪明的模型。 ## 为什么要做一个 32B 推理模型? 在当前大模型发展趋势中,主流路线正不断追求更大的参数规模、更复杂的架构(如 MoE)、更庞大的训练数据和更昂贵的训练资源。但这条路线的成本极高,同时也带来了模型部署难、推理延迟高、适配门槛大等一系列现实问题。 A-M-team 选择反其道而行之,专注在 32B 这一“中尺度模型”的参数区间,其实背后也有有着明确的考量:他们想探索一种在计算资源可控、数据完全开源的条件下,也能实现强大推理能力的路径。 具体来说,32B 是一个对研究与应用都更友好的“黄金尺寸”: 足够强大:相比 7B 或 13B 模型,32B 在能力上能支持复杂的数学推理和代码生成,具备执行严肃 reasoning 任务的基础; 成本可控:相比 100B、200B 甚至 670B 的巨型模型,32B 模型训练与推理资源需求显著更低,更适合在企业或研究机构内部复现、部署和迭代; 部署更友好:在单节点或小规模集群上即可运行,可应用于更多落地场景; MoE 替代探索:它也是对 MoE 路线的替代探索,A-M-team 想要验证,不使用专家模型,仅靠稠密结构和扎实的后训练设计,是否也能达到甚至超越 MoE 模型的表现。 AM-Thinking-v1 正是在这样的问题驱动下诞生的:一个不依赖私有数据、没有特殊硬件依赖、完全基于社区资源训练而成的中尺度模型。 而它的表现也正好印证了这个方向的潜力——不仅在 AIME 和 LiveCodeBench 等高难度任务上超越了 DeepSeek-R1,还在多个维度接近 Qwen3-235B-A22B 这类百亿级 MoE 模型。雷峰网简而言之,AM-Thinking-v1 想要回答的是一个关键问题:“大模型能力的上限,能不能用更小的体量实现?” 结果是肯定的。 而这正是 32B 推理模型的价值所在。
 人人都是产品经理 · 乌鸦智能说
人人都是产品经理 · 乌鸦智能说
<blockquote><p>在AI浪潮席卷全球的今天,一家名为Clay的AI销售公司凭借其独特的“预测式销售”模式,成功在传统SaaS市场中脱颖而出。短短几年间,Clay的收入增长了6倍,估值更是飙升至15亿美金。他们是如何做到的?本文将带你深入剖析Clay的成功秘诀,探索其背后的技术创新和商业模式。</p> </blockquote>  在不久前的第三届红杉资本AI峰会上,有一句话令人印象深刻: AI结果的累积速度,将决定你公司价值增长的上限。 这一点,在AI销售领域体现得尤为明显。这两年,靠着帮企业收集销售线索,一批AI销售公司迅速崛起,其中最具代表性的公司当属Clay。 简单来说,Clay干的事情就是整合了100家Data供应商的数据,比如Hubspot、领英、地图、CRM,结合Agent的研究能力,对网页的信息进行爬取、判断比对、总结处理,完成类似SDR(销售发展代表)员工的基本信息检索工作。 同时,他们也通过AI进一步强化了平台能力,比如为用户构建高度定向的潜在客户列表,还能自动生成个性化的电子邮件、博客文章等。 与传统SaaS产品不同,Clay在定价模式上选择了更加灵活的“积分付费制”。这也大大提升了企业付费的意愿,也加速了公司业务的增长。 在2023年实现10倍增长后,2024年Clay收入再次实现了6倍以上的增长。伴随收入的快速增长,公司估值也水涨船高。 今年1月,Clay完成了4000万美元的B轮融资,公司估值达12.5亿美元。到了5月,在新一轮老股转让里,红杉对公司的出价提升到了15亿美金。 一起来看看这家“万人夸夸”的AI销售公司吧。 ## / 01 /多元数据整合能力,预测高价值线索 最强的销售,不是能说会道,不是全年无休,而是善假于物。 以前做营销,全靠员工手动整理各种渠道的数据,不仅反应慢半拍,而且市面上的营销方法都差不多。为了争夺有限的客户资源,企业间开始打“价格战”,加入销售投入。 而企业常用的CRM系统操作复杂,字段设计又和实际业务需求脱节,既麻烦又不实用。 AI的出现,为销售行业带来了转机。在整个销售工作流中,售前GTM(产品商业化)和客户服务两个环节最适合AI发挥作用。 而售前阶段急需的自动化功能,集中在潜在客户生成和外呼上。 发现toB这些痛点后,一家名为Clay的AI销售该公司出手了。他们将客户响应效率提升2-3倍,30%企业每天通过他们的AI处理50万次任务,更催生出一些年收入百万美元的代理机构。  这家成立仅3年的40人团队,与传统销售公司拉开差距的关键,在于其强大的多源异构数据整合能力。 Clay开发了AI研究代理“Claygent”,该工具可以看作是AI+SDR Agent。它允许用户创建适合其特定需求的定制数据源和丰富工作流程,让企业在网络上寻找潜在客户信息。 围绕数据智能与自动化引擎,它构建了“三步”工作流:检索并获取数据、验证并给出来源、以指定格式输出检索结果。 ### 第一步,检索并获取数据。 “Claygent”整合包括招聘网站、公共数据库和新闻媒体等在内的75个数据提供商的信息,如企业信息库Crunchbase、客户管理系统Salesforce等,将信息聚合到一个统一的平台上,方便用户一次性访问。 “Claygent”连客户的社交动态也不放过。在LinkedIn、HubSpot、Clearbit等平台上,只要潜在客户出现工作变动、融资变化、发布招聘信息等情况,“Claygent”就会自动察觉,按位置、公司规模、经验、社交网络连接等对潜在客户进行分类,帮助销售团队准确地制定策略。 在数据整合方面,Clay的技术核心是“GPT-4+二分搜索法”。 在开始搜索前,Claygent不会直接抓取整个网站,而是会先咨询GPT-4,确定哪些部分最有可能包含所需信息,再运用二分搜索法进行搜索。 所谓的二分搜索法就是,先选择网站的一部分进行检查,如果未找到目标数据,则转向另一部分。这种方法通过逐步缩小搜索范围,最终精准定位所需信息。 这样的搜索方式不仅能够精准收集到用户所需要的信息,还显著提升了抓取效率。 ### 第二步,验证并给出来源。 “Claygent”还结合多数据源交叉验证,如比对Crunchbase与PitchBook数据,确保输出结果的可靠性。用户也可以要求Claygent给出其数据的源头。 另外,每家企业都可以自行设定潜在客户的资格审查标准。例如,最近发布的AI产品或功能可“+10分”,最近销售团队扩张可“+15分”等等。一旦所有设置完成,“Claygent”就会对每个独特的潜在客户进行测试,以确定他们进行购买的可能性。 ### 第三步,以指定格式输出检索结果。  “Claygent”可以输出指定格式的检索结果。比如,文本、数字、网址等其他自定义格式。 在“发现线索”之后的“主动联系”环节,Clay也提供了简单的自动化外联功能。例如邮件内容生成,但Clay不能像Outreach和Apollo那样自动发送电子邮件。 不过,Clay可以集成reply等专用销售互动工具,实现跨平台执行跟进规则、生成个性化邮件/短信。借助Reply,Clay用户可以为潜在客户创建序列,利用电子邮件、电话、LinkedIn和WhatsApp等进行外联。 创始人KareemAmin曾任微软工程师,与NicolaeRusan早期专注于降低编程门槛。2021年,随着客户需求从功能满足转向价值共创,Clay战略转型至销售自动化,帮助企业实现数据驱动 ## / 02 /口碑传播拉动增长,积分付费——用量即价值 Clay早期成功的关键在于定价策略和内容营销。 在销售行业,当“AI解决方案”逐渐成为标配,同质化的产品演示、雷同的订阅套餐和铺天盖地的功能列表,也在加速客户的选择疲劳。 Clay选择使用“反套路”推广,不强制绑定信用卡,也没有复杂的付费墙,直接开放产品全功能试用。 这意味着,用户可以自由探索、试错,亲自感受AI在销售数据处理上的提升。 这种极具诚意的打法,不仅迅速抓住了客户眼球,更在不经意间点燃了口碑传播的引擎。Clay的社区中有超过11000人参与讨论,并且有超过100个基于Clay构建的业务案例。 在此之前,Clay也尝试过多种增长方式,例如电子邮件营销、付费广告、SEO,甚至在旧金山投放广告牌,主要目标是吸引“已经有需求但不知道选哪款工具”的企业客户,但还是“口碑传播”的效果最为明显。 现在,Clay已经建立起一套内容生产的反馈闭环: 在全球各地举办Clay线下活动,将活动中产出的内容整理成LinkedIn帖子,再整合成博客文章,最终汇编成指南。如此一来,企业决策者也能直观看到同行如何用AI处理海量数据。  客户之所以愿意主动分享,是因为Clay的产品特性使然。这些客户大多是代理商,他们希望通过LinkedIn树立专业形象。当然,Clay团队也积极协助客户创作内容,例如介绍新功能、合作撰写文章等。 后期在SEO优化方面,Clay也算是吃透了用户心理。Clay的目标用户是“对数据敏感、渴望提高销售效率”的企业。因此,他们SEO优化集中在“AI”、“自动化”、“客户数据”元素上,例如在“销售自动化工具”“AI数据分析”“客户线索挖掘”关键词上,Clay排列靠前。 定价方面,Clay也聪明地没有采用Figma的按席位定价模式,而是选择了一种更符合客户利益的方式——Credits积分制。 Clay的核心产品是数据查询、线索挖掘和智能匹配,价值取决于使用量,而不是使用者的数量,因此不适用ToB Saas按席位制的收费。 在Clay的定价页面上,客户可以预先购买一定数量的积分(Credits),Clay根据客户的实际数据查询、处理、匹配等操作消耗这些积分。  传统的收费方式如同让不同饭量的人付相同自助餐费——企业为用不到的功能买单。Clay改成按数据操作次数计费,并每年发布定价透明报告。这种方式就像手机流量套餐,用多少付多少,灵活适配企业规模。 ## / 03 /总结 从长远看,AI销售的故事才刚刚开始。 原因很简单,销售环节的工作流程长,端到端提供产品服务的价值足够大。同时,销售工作交付的结果往往有一个清晰的目标,更容易用一种可衡量的服务效果来衡量价值。 与此同时,AI销售的成本远远低于人力。a16z合伙人Alex Rampell曾经拿AI客户支持软件公司Zendesk举例: 如果一家公司用Zendesk来处理2000个工单,1000个Zendesk智能体就可以替代1000名客服。如此这般,使用AI销售员一年花费140万美元,而原本1000个人类销售员却要花7500万美元。 算下来,一张工单(销售线索),用人类销售员(客服)的成本是37.50 美元,而AI销售员的成本仅为0.69美元。 结果可衡量,加上AI在成本端的巨大优势,AI销售产品虽处于发展早期,却已展现出良好价值,其价值也将从企业当前销售活动的简化,延伸到企业销售和工作流程的重构。 文/朗朗本文由人人都是产品经理作者【智能乌鸦】,微信公众号:【乌鸦智能说】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。
明晚8点(5月16日晚8点),2025天猫618正式现货开卖。今年淘宝天猫主打“官方立减”的极致简单玩法,并陆续推出了打通小红书种草链路、简化大促报名流程、上线退款超时外呼等多项举措,全方位助商家大促提效。此外据了解,淘宝天猫还提供了覆盖商家经营全链路的多种AI提效工具。 其中,“图生视频”是淘宝面向商家最新发布的AIGC产品,商家只需上传一张或多张商品图,即可自动生成最长20秒的动态短视频,大促期间可大幅提升素材制作效率。此外,淘宝还提供一键成片、智能修片、搭配视频、脚本成片等多种能力,满足不同视频制作需求,并通过优质视频提升商品浏览及转化率。 例如,本周三刚刚上线的“脚本成片”功能,基于全网热门优质脚本及商品信息,自动生成可编辑的脚本及分镜,最终合成为高质量的商品卖点、种草视频;“搭配视频”则更适合服饰类商家,商家可自主选择要进行搭配的上下装、模特、场景,即可一键生成各种风格的真人上身短视频。  AI自动为商家生成分镜 目前,MAX&Co.、敦奴等多家知名时尚品牌正在使用淘宝官方提供的图生视频能力。敦奴品牌视觉设计负责人表示:“图生视频的功能不仅节省了时间和人力成本,还让品牌能够快速生成高质量的视频素材,供品牌直接投放。” 数据显示,按商家平均一个月制作7个视频计算,图生视频上线一个月以来,帮助每个商家节省视频制作成本超千元,压缩视频制作周期10天以上。大促期间,所有淘宝天猫商家每天都可免费生成三十个视频,商家可通过“千牛工作台-商品-素材中心”体验。 此外,淘宝官方AI工具已经全面融入营销投放、店铺经营、售后管理等商家经营全链路中,深度帮助商家提高生产效率、降低经营复杂度。 营销投放方面,阿里妈妈全新升级的“货品全站推”将在本月全量上线,可通过AI智能筛选并预测未来有GMV增长空间的商品,按照优质新品、潜力品和机会爆品进行选品打标并提供差异化增长方案,从而有效提升商品的投放转化率。 店铺经营上,淘宝商家AI产品“生意管家”涵盖了图像生成和编辑、视频生成和编辑、AI千人千面人群运营、AI客服辅助接待、AI经营助手等能力,可帮助商家完成店铺巡检、数据分析、素材生成、文案创作、日常咨询等经营事项。 本周四“生意管家”还全新升级了AI分人群测图能力,支持商家为不同消费者匹配不同的商品主图,从而提升商品转化率。 针对客服场景,“生意管家”已上线AI客服辅助接待能力,可自动提炼多轮对话要点,识别买家意图和情绪,结合店铺历史会话、商品、订单等信息,推荐回复话术,帮助商家快速提升客服接待效率。目前,该功能已有超百万商家使用。 与此同时,店小蜜AI客服的能力持续升级,可以实现更加拟人化的多轮精准应答,并结合商家服务策略实现售后问题智能化、自动化解决。实测数据显示,升级后消费者咨询转人工率直降超20%,订单转化率提升超15%。目前,所有店小蜜商家均可免费使用店小蜜AI能力。
 机核 · YT17
机核 · YT17 仅由一人开发制作的国产肉鸽卡组构建式游戏《卡牌少女不会受伤》,于5月15日在Steam平台发售正式版。游戏国区售价为29元,首周提供10%购买折扣,折后价为26元。  《卡牌少女不会受伤》是一款肉鸽牌组构建类游戏,充满手绘动画风格的二次元萌妹卡面。玩家将扮演一位少女,误入将所有生物变成卡牌的异世界后不断逃离,揭开世界的真相。在低饱和又可爱的美术风格下伴随灵活的快节奏战斗,冒险途中还能遭遇各类变成卡片的有趣美少女们,喜欢二次元风格和卡牌游戏的玩家不要错过。 #### 献祭大萌妹 游戏借鉴《邪恶冥刻》的卡牌机制,采用献祭手牌以支付费用的设计:单位登场需消耗等量在场单位作为资源。与灵感作将动物作为卡面设计不同的是,我方的单位全变成了可爱美少女,卡面还会根据不同的卡牌效果绘制出不同的萌妹。  #### 合成大萌妹 最具特色的机制在于卡牌融合系统,玩家可自由选择任意两张卡牌进行合成,生成一张具备融合效果的新卡。尽管卡面图像保持不变,但上百张可融合卡牌为玩家提供了高度自由的组合空间,鼓励大家尝试挖掘卡牌间潜在的协同效应,不断合成探索卡牌合成的无尽种可能。 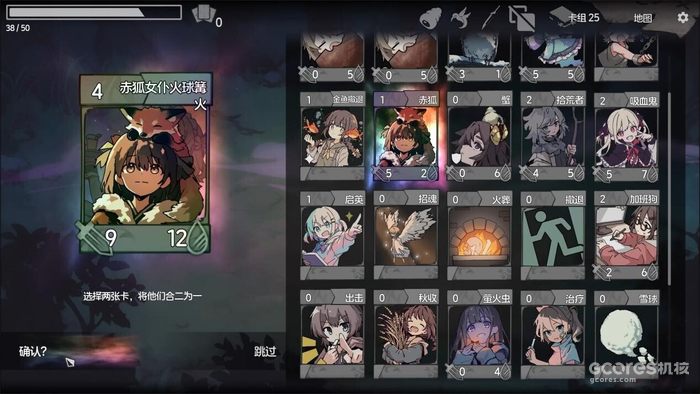 #### 遭遇大萌妹 游戏采用蛛网式爬塔探索结构,玩家每通过一个节点,即可自主选择分支路径向外扩展地图。在探索过程中,将陆续遇到美少女NPC加入队伍,触发与之相关的重力剧情,随着不断深入,玩家将逐步揭开世界背后的真相。   完整版包含内容: - - 九张爬塔式小地图关卡,其中包含遭遇战、营地、卡牌融合等机制,通关后解锁10个进阶模式。 - - 100+二次元萌妹卡面、10+种BOSS变体卡牌、30+张不同类型小怪卡牌。 - - 可自由合成任意两张卡牌成新卡牌的高度的策略性和可玩性的玩法。 游戏特色 - l 生物卡与法术卡相结合,运用合理出牌策略击败敌方场上的所有生物来取得胜利。 - l 将牌组中的任意两张卡牌融合,能创造出属于玩家独一无二的流派。 - l 蛛网式前进路线,玩家更自由规划前进路线,险中求胜以获取更大的利益。 - l 风格各异的二次元风格美少女萌卡面,探险不再孤独。
就在刚刚,DeepSeek团队发布最新论文《洞察 DeepSeek-V3:规模的挑战和对AI架构硬件的思考》。  论文链接:https://arxiv.org/pdf/2505.09343 在保持性能不变的情况下,论文采用了双重视角——跨越硬件架构和模型设计,通过研究这种协同作用,探索 DeepSeek-V3 如何实现经济高效的大规模训练和推理。 随着 OpenAI o1/o3、DeepSeek-R1、Claude-3.7 Sonnet 等先进模型的出现,大规模架构和上下文推理的进步强调了对更快、更高效推理的需求。因此,计算资源的需求也在逐步扩大。 DeepSeek 的出现证明了有效的软硬件协同设计可以实现大型模型的成本效益训练,为较小的团队提供公平的竞争环境。 基于这一传统,DeepSeek-V3 代表了成本效益训练的新里程碑,仅需 2,048 个 NVIDIA H800 GPU 就实现了最先进的性能。DeepSeek-V3 的实践和见解展示了如何充分利用现有硬件资源,为更广泛的 AI 和 HPC 社区提供宝贵的经验教训。 论文章节的主要内容如下: DeepSeek 模型的设计原则 低精度驱动设计 以互联为驱动的设计 大规模网络驱动设计 面向未来的硬件架构设计 ## DeepSeek 模型的设计原则 如下图 所示,DeepSeek-V3 采用 DeepSeek-MoE 和多头潜在注意力 (MLA)架构,通过压缩键值 (KV) 缓存大大减少了内存消耗。此外,DeepSeek-V3 还采用了 FP8 混合精度训练,显著降低了计算成本。  这些创新旨在解决LLM规模中的三个核心挑战——内存效率、成本效益和推理速度。 LLM 通常需要大量的内存资源,内存需求每年增长 1000% 以上。相比之下,高速内存(例如 HBM)容量的增长速度要慢得多,通常每年不到 50%。与使用 BF16 进行权重的模型相比,FP8 将内存消耗显著降低了一半,有效缓解了 AI 内存挑战。 DeepSeek-V3 还采用了多头潜在注意力 (MLA),它使用投影矩阵将所有注意力头的 KV 表示压缩成一个更小的潜在向量,该矩阵与模型联合训练。在推理过程中,只需要缓存潜在向量,与存储所有注意力头的 KV 缓存相比,显著减少了内存消耗。 除了 MLA 之外,DeepSeek 还提出了其他几种方法来减小 KV 缓存的大小: 共享 KV:多头共享一组 KV 配对,从而显著压缩了 KV 存储。 窗口 KV:对于长序列,缓存中只保留 KV 配对的滑动窗口。 量化压缩:KV 配对使用low-bit进行存储,进一步减少了内存使用。 对于稀疏计算,DeepSeek 还开发了 DeepSeek-MoE 架构,MoE 模型的优势在于两个方面: 第一,减少训练的计算要求:MoE 架构的主要优势在于它能够显著降低训练成本。通过选择性地仅激活专家参数的子集,MoE 模型允许参数总数急剧增加,同时保持计算要求适中。  如图表2所示,DeepSeek-V3 的总计算成本约为每个令牌 250 GFLOPS,而 72B 密集模型需要 394 GFLOPS,405B 密集模型需要 2448 GFLOPS。这表明 MoE 模型实现了与密集模型相当甚至更好的性能,同时消耗的计算资源减少了一个数量级。 第二,个人使用和本地部署的优势:由于每个请求只激活了一个参数子集,因此内存和计算需求大大减少。例如,DeepSeek-V2(236B 参数)在推理过程中仅激活 21B 参数。这使得配备 AI SoC 芯片的 PC 能够实现每秒近 20 个令牌 (TPS)。相比之下,具有相似能力的密集模型(70B 参数)在类似硬件上通常只能达到个位数的 TPS。 除此之外,为了最大限度地提高吞吐量,DeepSeek-V3 从一开始就被构建为利用双微批处理重叠,有意将通信延迟与计算重叠。它将 MLA 和 MoE 的计算解耦为两个不同的阶段,当一个微批处理执行 MLA 或 MoE 计算的一部分时,另一个微批处理同时执行相应的调度通信。相反,在第二个微批处理的计算阶段,第一个微批处理经历组合通信步骤。 这种流水线化方法实现了全对全通信与正在进行的计算的无缝重叠,确保 GPU 始终保持充分利用。此外,在生产中,V3 还采用预填充和解码解聚架构,将大批量预填充和延迟敏感的解码请求分配给不同的专家并行组大小,这可以最大限度地提高系统吞吐量。 虽然 MoE 模型表现出良好的可扩展性,但仅通过增加硬件资源来实现高推理速度的成本很高。因此,软件和算法也必须有助于提高推理效率。 DeepSeek-V3 引入了多标记预测 (MTP) 框架,该框架同时增强了模型性能并提高了推理速度。MTP 可以让模型能够以较低的成本生成额外的候选标记并并行验证,缓解了解码步骤中标记顺序生成的瓶颈,在不影响准确性的情况下显着加快了推理速度。 真实世界的实践数据表明,MTP 模块预测第二个后续令牌的接受率为 80% 到 90%,与没有 MTP 模块的场景相比,生成 TPS 提高了 1.8 倍。 此外,通过预测每步多个令牌, MTP 增加了推理批量大小,这对于提高 EP 计算强度和硬件利用率至关重要。 ## 低精度驱动设计 虽然 GPTQ 和 AWQ 等量化技术已将位宽减少到 8 位、 4 位甚至更低,但是这些技术主要应用于推理期间以节省内存,而不是在训练阶段。在 DeepSeek-V3 之前,没有利用 FP8 进行训练的开源大型模型。 DeepSeek 通过基础设施和算法团队之间的深入合作,为 MoE 模型开发了一个与 FP8 兼容的训练框架,在训练管道中使用 FP8 精度前向和后向过程的计算组件。 虽然 FP8 在加速训练方面具有巨大潜力,但需要解决几个硬件限制才能充分利用其功能: FP8 累积精度: FP8 在 Tensor Core 中使用约束累加精度,这会影响训练大型模型的稳定性 细粒度量化挑战:细粒度量化在传输部分结果时引入了大量的反量化开销,会导致频繁的数据移动,从而降低计算效率并使硬件利用率复杂化 为了解决现有硬件的限制,DeepSeek 对未来的设计有以下建议: 提高累积精度:硬件应改进并调整 Accumulation Register 精度到适当的值(例如 FP32),或支持可配置的 Accumulation Precision 对原生细粒度量化的支持:硬件应该支持原生细粒度量化,使 Tensor Core 能够接收缩放因子并通过组缩放实现矩阵乘法,避免频繁的数据移动以减少去量化开销。 DeepSeek-V3 架构采用低精度压缩进行网络通信。在 EP 并行期间,使用细粒度的 FP8 量化来调度令牌,与 BF16 相比,通信量减少了 50%,显著缩短了通信时间。 他们的建议是,为 FP8 或自定义精度格式定制的压缩和解压缩单元提供本机支持是未来硬件的可行方法。这有助于最大限度地减少带宽需求并简化通信管道,能大幅提升 MoE 训练等带宽密集型任务的效率。 ## 以互联为驱动的设计 研究团队当前使用的 NVIDIA H800 GPU SXM 架构,基于 Hopper 架构,类似于 H100 GPU。然而,它为了满足监管要求,降低了 FP64 浮点计算性能和 NVLink 带宽。具体来说,H800 SXM 节点中的 NVLink 带宽从 900 GB/s 降低到了 400 GB/s。这个节点内部带宽的显著下降对高性能工作负载带来了挑战。  为了解决这个问题,他们在每个节点都配备了 8 张 400G 的 Infiniband(IB)CX7 网卡,从而增强了向外扩展(scale-out)的能力,以弥补带宽不足。为了应对这些硬件限制,DeepSeek-V3 模型在设计时结合了多项考虑,既贴合了硬件的优势,也规避了其局限。 为适配 H800 架构的硬件限制,DeepSeek-V3 在并行策略上还进行了如下优化: 避免使用张量并行(TP):在训练阶段,TP 因为受限的 NVLink 带宽效率低下而被禁用。但在推理阶段,TP 可以被选择性地启用,用于降低延迟和提升 TPOT(Tensor Parallel Optimized Transformer)性能。 增强的流水线并行(PP):采用 DualPipe 机制,以便将注意力计算和 MoE 计算与通信重叠。这也有助于减少流水线空泡,并在多个 GPU 间平衡内存使用,从而提升整体吞吐量。 加速的专家并行(EP):借助 8 张 400Gbps 的 Infiniband(IB)网卡,系统可以实现超过 40GB/s 的全互联通信。 然而在 H800 架构中,节点内(intra-node)通信与节点间(inter-node)通信的带宽差异约为 4:1。具体来说,NVLink 提供 200GB/s 的带宽(实际可用约 160GB/s),而每张 400Gbps 的 IB 网卡实际带宽约为 50GB/s(考虑小消息和延迟因素后,计算为 40GB/s 的有效带宽)。 为了充分利用更高的节点内带宽,模型架构特别在 TopK 专家选择策略中,与硬件协同设计。 设想一个系统包含 8 个节点(共 64 张 GPU),以及 256 个路由专家(每张 GPU 有 4 个专家)。在 DeepSeek-V3 中,每个 token 会被路由到一个共享专家和 8 个路由专家。如果这 8 个目标专家平均分布在所有节点上,那么 token 在 IB 上的通信成本将是 8t(t 为传输一个 token 所需时间)。 但如果利用 NVLink 的更高带宽,将路由到同一节点的 token 先在节点内通过 NVLink 传输,再由该节点的 GPU 使用 IB 转发到其他节点,这种 NVLink 中继方式可以显著减少 IB 流量。当目标专家分布在 M 个节点时,这种策略可将通信成本降低为 Mt(M < 8)。 为实现这一策略,DeepSeek-V3 引入了节点受限的专家路由策略(Node-Limited Routing)。 具体来说,研究人员将 256 个路由专家分成 8 组,每组 32 个专家,并且每组部署在同一个节点上,而在实际部署时,他们使用算法保证每个 token 最多只会被路由到最多 4 个节点。这种做法有效地缓解了 IB 通信的瓶颈,提升了训练期间通信带宽的使用效率。 虽然节点受限路由策略(Node-Limited Routing)在一定程度上降低了通信带宽的需求,但由于节点内(NVLink)和节点间(IB)通信带宽之间存在差异,这也使得通信流水线内核的实现变得更为复杂。 在实际操作中,GPU 的流处理器( SM)既用于处理网络消息(例如填充 QPs 和 WQEs),也用于通过 NVLink 进行数据转发,这会消耗大量计算资源。例如,在训练过程中,H800 GPU 上多达 20 个 SM 被分配给与通信相关的操作,从而减少了用于实际计算的资源。 为最大化在线推理的吞吐量,研究团队在 EP(专家并行)全互联通信中完全采用 NIC RDMA,实现通信与计算资源的分离,避免 SM 资源竞争,从而提升计算效率。这也凸显了 RDMA 的异步通信模型在计算与通信重叠处理方面的优势。 当前,在 EP 通信(特别是 combine 阶段的 reduce 操作与数据类型转换)中,SM 执行的主要任务包括: 数据转发:聚合目标为同一节点中多个 GPU 的 IB 流量,实现 IB 与 NVLink 域之间的数据桥接; 数据传输:在 RDMA 缓冲区(GPU 注册内存区域)与输入/输出缓冲区之间传输数据; 规约操作:执行 EP combine 所需的规约操作; 内存布局管理:对穿越 IB 和 NVLink 域的分块数据进行精细化内存布局管理; 数据类型转换:在 all-to-all 通信前后执行数据类型的转换。 研究团队还给出了一些如何在编程框架层面实现 scale-up 与 scale-out 的融合建议: 统一网络适配器:设计能够同时连接 scale-up 与 scale-out 网络的 NIC(网络接口卡)或 I/O Die。这些适配器应具备基本的交换功能,比如能将来自 scale-out 网络的包转发到 scale-up 网络中的特定 GPU。可以通过一个 LID(本地标识符)或带有策略路由的 IP 地址实现。 专用通信协处理器:引入一个专用协处理器或可编程组件(如 I/O die),用于处理网络流量。这种组件可将报文处理任务从 GPU 的 SM 上卸载,避免性能下降,并具备硬件加速的内存拷贝能力,以提升缓存管理效率。 灵活的转发、广播和规约机制:硬件应支持灵活的转发、EP 分发阶段的广播操作、以及 EP 聚合阶段的规约操作,这些机制需跨越 scale-up 与 scale-out 网络运行。这样可以复现我们当前基于 GPU SM 的实现逻辑,不仅提升了有效带宽,也减少了网络操作的计算复杂度。 硬件同步原语(Hardware Synchronization Primitives):提供更精细粒度的硬件同步指令,用于处理内存一致性问题或乱序报文抵达问题。这将替代基于软件的同步机制(如 RDMA 的完成事件),后者通常会引入额外的延迟并增加编程复杂度。基于 acquire/release 模型的内存语义通信是一个有前景的解决方案。 他们认为,通过实现上述建议,未来的硬件设计将能够显著提升大规模分布式 AI 系统的效率,同时简化软件开发的复杂度。 ## 大规模网络驱动设计 在 DeepSeek-V3 的训练过程中,研究团队部署了一个“多平面胖树”(Multi-Plane Fat-Tree, MPFT)scale-out 网络。每个节点配备了 8 张 GPU 和 8 张 IB 网卡,每对 GPU-NIC 映射到一个独立的网络平面(plane)。  这是一个八平面、两层的胖树结构网络,其中每对 GPU 和 IB NIC 映射到一个网络平面,并且跨平面的流量必须通过另一个 NIC,并通过 PCIe 或 NVLink 进行节点内转发。 在保留两层网络拓扑在成本和延迟方面优势的同时,由于政策和监管限制,最终实际部署的 GPU 数量仅略高于 2000 张。 此外,每个节点还配有一张 400Gbps 的以太网 RoCE NIC,用于连接分布式存储系统 3FS 所在的独立存储网络平面。在该 scale-out 网络中,我们使用了 64 端口的 400G IB 交换机,从理论上讲,这种拓扑可支持最多 16384 张 GPU。 然而,由于 IB ConnectX-7 的当前技术限制,他们部署的 MPFT 网络尚未完全实现理想架构。 理想情况下,每张 NIC 应该具备多个物理端口,每个连接到不同的网络平面,但对用户而言,它们通过端口绑定暴露为一个统一的逻辑接口。  从用户角度来看,单个 QP(队列对)可以跨所有可用端口无缝收发数据包,类似于“报文喷洒”(packet spraying)。但这也带来了一个问题:同一个 QP 发出的数据包可能通过不同的网络路径传输,导致到达接收端时的顺序被打乱,因此需要 NIC 提供原生的乱序报文排序能力。 研究团队还介绍了多平面胖树网络的优势: 多轨胖树(MRFT)的子集:MPFT 拓扑结构是更广义的 Multi-Rail Fat-Tree(MRFT)架构的一个特定子集。因此,NVIDIA 和 NCCL 为多轨网络开发的现有优化策略可以无缝应用到多平面网络的部署中。此外,NCCL 对 PXN(Port eXtended Network)技术的支持,解决了平面间通信隔离的问题,即便在平面之间没有直接互联的情况下,也能实现高效通信。 成本效益高(Cost Efficiency):多平面网络使用两层胖树(FT2)拓扑即可支持超过 1 万个端点,显著降低了与三层胖树(FT3)架构相比的网络成本。其每个端点的成本甚至比高性价比的 Slim Fly(SF)拓扑还要更低。 流量隔离(Traffic Isolation):每个平面独立运行,确保某一个平面的拥塞不会影响到其他平面。这种隔离机制提高了整体网络的稳定性,并防止级联式性能下降的发生。 低延迟(Latency Reduction):实验表明,两层胖树(Two-Layer Fat Tree)拓扑相较于三层胖树具有更低的延迟。这一点使其特别适合延迟敏感型任务,如基于 MoE 架构的大模型训练与推理。 鲁棒性(Robustness):配备多端口的 NIC 提供多个上行链路,因此即使某个端口发生故障,也不会导致通信中断,系统能够实现快速、透明的故障恢复。 值得注意的是,由于当前 400G NDR InfiniBand 的限制,跨平面通信仍需通过节点内的转发实现,这在推理过程中会引入额外的延迟。如果未来硬件能够实现之前建议的 scale-up 与 scale-out 网络的融合,那么这种延迟将大大减少,从而进一步增强多平面网络的可行性。  为了验证多平面网络设计的有效性,研究人员在实际部署的集群上进行了一系列实验。通过修改集群的网络拓扑,我们比较了多平面两层胖树(MPFT)和单平面多轨胖树(MRFT)在性能上的差异。 他们发现在全互联通信任务中,多平面网络的性能几乎与单平面多轨网络持平。这一性能上的一致性归因于 NCCL 的 PXN 机制 [54],它能在多轨拓扑中优化 NVLink 的流量转发,而多平面拓扑同样可以受益于该机制。  而在 16 张 GPU 上进行的 all-to-all 通信测试中,MPFT 与 MRFT 在延迟方面几乎没有差异。  为了进一步评估 MPFT 在实际训练中的表现,他们还测试了训练中常见的专家并行通信(EP)模式。在多平面网络中,每张 GPU 都能达到超过 40GB/s 的高带宽,表明其在训练场景下具有出色且稳定的通信能力。 研究人员还比较了 DeepSeek-V3 模型在 MPFT 与 MRFT 网络中的训练指标: MFU(Model Flops Utilization)指标是基于 BF16 理论峰值计算的; Causal MFU 只考虑注意力矩阵下三角部分的 FLOPs; Non-Causal MFU 则包括整个注意力矩阵的 FLOPs; 表中 1F、1B 和 1W 分别代表前向时间、输入反向传播时间、权重反向传播时间。 实验显示,在 2048 张 GPU 上训练 V3 模型时,MPFT 的整体性能几乎与 MRFT 持平,两者间的性能差异完全处于正常波动范围内。  除此之外,团队还对 InfiniBand 还是 RoCE 的问题进行了实验,他们发现 InfiniBand(IB)在延迟方面始终优于 RoCE,因此成为分布式训练和推理等延迟敏感型任务的首选网络方案。 不过,尽管 IB 拥有更低的延迟表现,但它也存在一些实际限制: 成本(Cost):IB 硬件远比 RoCE 成本高,限制了其在更大范围的部署中普及。 可扩展性(Scalability):IB 交换机通常最多支持 64 个端口,而 RoCE 交换机常见为 128 个端口。这使得 IB 在构建超大规模集群时面临扩展性瓶颈。  尽管 RoCE 被认为是 IB 的一个高性价比替代方案,但目前在延迟和可扩展性上的不足,限制了其在大规模 AI 系统中的应用潜力,介于这一点,研究团队也对 RoCE 提出了一些优化意见: 专用低延迟 RoCE 交换机:他们建议以太网设备厂商开发专为 RDMA 工作负载优化的 RoCE 交换机,去除那些不必要的传统以太网功能。 例如,Slingshot 架构就展示了如何通过以太网设计实现接近 IB 的低延迟性能。类似地,Broadcom 的一系列新技术也展现出在 AI 应用场景中的巨大潜力,包括 AI Forwarding Header(AIFH)机制和即将发布的低延迟以太网交换机。这些创新展示了基于以太网的高性能 RDMA 网络是完全可行的。 优化的路由策略:RoCE 默认采用 ECMP(Equal-Cost Multi-Path)路由策略,在跨互联网络时难以高效地分散流量,常常导致 NCCL 集合通信中的严重拥塞和性能下降。 例如,在数据并行(DP)训练中,LLM 的通信流量往往缺乏足够的随机性,导致多个流聚集到同一个链路,引发瓶颈。而自适应路由(Adaptive Routing, AR)可以动态地将数据包“喷洒”到多条路径上,从而显著提升网络性能。虽然手动配置的静态路由表(Static Routing)能在特定目标下避免链路冲突,但它缺乏灵活性。对于大规模 all-to-all 通信,自适应路由无疑在性能和扩展性方面更具优势。  改进的流量隔离与拥塞控制机制: 当前的 RoCE 交换机通常仅支持有限数量的优先队列(priority queues),这对于同时涉及多种通信模式(如 EP 的 all-to-all 与 DP 的 all-reduce)的复杂 AI 工作负载来说远远不够。在这种混合通信场景中,all-to-all 会因突发性的一对多传输引发“入端拥塞(incast congestion)”,严重时会拖慢整条网络路径的性能。 研究团队认为可以使用虚拟输出队列:为每个队列对(QP)分配一个虚拟队列,做到流量级别的隔离,以及使用更高效的拥塞控制机制,如基于 RTT 的拥塞控制(RTTCC),或用户可编程的拥塞控制(PCC)。这些机制可以实现网卡与交换机之间的协同优化,在动态流量条件下保持低延迟与高吞吐。 最后,研究人员表示他们自己是使用 IBGDA 技术来降低网络通信中的延迟。而传统的 GPU 网络通信流程中通常需要通过 CPU 协程作为代理线程,为此他们还贴心的整理出了流程: GPU 准备好要发送的数据、通知 CPU 代理、CPU 填写控制信息(Work Request, WR),然后通过 doorbell 机制通知网卡启动数据传输。 他们表示这种方式引入了不小的通信开销。而 IBGDA 则通过允许 GPU 直接填写 WR(无需经过 CPU),极大减少了中间环节的延迟,提高了通信效率。 ## 面向未来的硬件架构设计 研究团队在识别了当前硬件面临的限制,并提出了相应的建议后,将视野扩展至更宏观的层面,提出未来硬件架构设计的前瞻性方向。他们认为当前主要的限制包括: 互联故障(Interconnect Failures):高性能互联系统(如 InfiniBand 与 NVLink)易受到间歇性断连的影响,这会破坏节点之间的通信。在通信密集型任务(如专家并行 EP)中,即便是短暂的通信中断,也可能造成明显的性能下降,甚至任务失败。 单点硬件故障(Single Hardware Failures):节点宕机、GPU 故障,或 ECC(纠错码)内存错误都可能影响到长时间运行的训练任务,往往需要代价高昂的任务重启。在大规模部署中,这类单点故障的概率随着系统规模的扩大而急剧上升。 静默数据损坏(Silent Data Corruption):某些错误(如多位内存翻转、计算错误等)可能逃逸 ECC 机制的检测,造成模型训练中的数据悄然被破坏。这类错误最为隐蔽,会在长时间训练过程中积累,导致下游计算被污染,严重损害模型质量。当前的缓解措施主要依赖于应用层启发式检测,但这不足以确保系统层面的整体鲁棒性。 他们还认为,为了应对传统 ECC 所无法覆盖的错误类型,硬件需要引入更先进的检测机制。例如:基于校验和(checksum)的验证机制、硬件加速的冗余校验(redundancy checks)。这些方法能为大规模部署提供更高的系统可靠性。 此外,硬件厂商应向最终用户提供全面的诊断工具包,以支持其对系统完整性的验证,并及时识别潜在的静默数据损坏风险。若这些工具作为标准硬件的一部分预装,能够实现持续运行期内的验证流程,从而提升整个系统的透明度与可信度。 尽管加速器(如 GPU)往往成为设计焦点,但CPU 依旧是协调计算任务、管理 I/O 操作、保持系统吞吐量不可或缺的关键组件。但研究团队认为当前架构存在几个严重瓶颈: PCIe 成为瓶颈:CPU 与 GPU 之间的 PCIe 接口在传输大规模参数、梯度或 KV 缓存时,常成为带宽瓶颈。 为此,研究团队也给出了一些建议,他们认为未来系统应采用CPU-GPU 直连方式(如 NVLink、Infinity Fabric),或将 CPU 与 GPU 一并纳入 scale-up 域中,从根本上消除节点内互联瓶颈。 内存带宽不足:为了支撑高速数据传输,还需匹配足够高的内存带宽。例如,要跑满 160 条 PCIe 5.0 通道,需要每个节点拥有 640 GB/s 的 IO 吞吐,对应约 1 TB/s 的内存带宽,这对传统 DRAM 架构构成巨大挑战。 对 CPU 性能的需求提升: 在 Chiplet 架构中,还需更多核心支持按缓存感知方式(cache-aware)划分与隔离负载。 同时,为避免控制侧成为瓶颈,每张 GPU 需要配备足够多的 CPU 核; 对于内核调度、网络处理等低延迟任务,需要基础频率在 4GHz 以上的单核性能; 除此之外,他们还提出了几个关键方向,为满足低延迟、高效率的 AI 工作负载,未来的互联网络不仅要具备低延迟,更应具备“智能感知能力”,指出了一条道路: 共封装光学(Co-Packaged Optics):通过集成硅光技术,可实现可扩展的超高带宽与能效比,这对构建大规模分布式系统至关重要。 无损网络(Lossless Network):虽然基于信用的流量控制(CBFC)机制可以保证无损数据传输,但如果触发方式不当,会导致严重的“队头阻塞”(head-of-line blocking)。因此,必须部署由终端主动驱动的高级拥塞控制(Congestion Control, CC)算法,主动调节注入速率,防止极端拥塞情况的发生。 自适应路由(Adaptive Routing):未来网络应标准化动态路由机制,例如“分包喷洒(packet spraying)”与“拥塞感知转发”。 对于 load/store 的内存语义通信在跨节点通信中具备效率高、编程友好的优势,但当前的实现常受限于内存顺序约束(memory ordering)的问题,研究团队也给出了自己的意见。 他们先是举了个例子:发送方在写入数据后,必须先执行一次内存屏障(memory fence),再更新通知接收方的标志位,才能确保接收方读到的是“已完成写入”的数据。这种强顺序要求带来额外的 RTT 延迟,并可能阻塞当前线程,降低系统的吞吐量。 类似地,在消息语义的 RDMA 场景中也存在乱序同步的问题。例如,在 InfiniBand 或 NVIDIA BlueField-3 上,在 RDMA 写之后再执行基于分包喷洒的 RDMA 原子加操作,也会引发额外的 RTT 延迟。 然后给出了建议:在硬件层面加入对内存语义通信顺序的一致性保障,包括编程接口层面支持 acquire/release 语义,以及在接收端由硬件保证顺序投递(in-order delivery),避免引入软件侧开销。 一种可行的方法是:接收方缓存原子消息,并利用数据包序号确保按序处理。然而,他们认为更优雅也更高效的方式是使用 Region Acquire/Release(RAR)机制: 硬件在接收端维护一个 bitmap,用于记录某段 RNR(remote non-registered)内存区域的状态,acquire/release 操作在此地址范围内生效,并且只需极小的 bitmap 开销,即可实现由硬件强制的通信顺序保障,最重要的是,这一机制理想情况下可由 NIC 或 I/O Die 来实现。 最后研究团队强调,RAR 不仅适用于内存语义操作,也同样能扩展到 RDMA 的消息语义原语中,具有广泛的实用性。 雷峰网关注到,他们还认为在混合工作负载环境下,未来硬件应该具备动态带宽分配和流量优先级控制的能力。例如,在训练与推理任务混合部署的场景中,应当将推理请求从训练任务中隔离,以确保延迟敏感型应用的响应速度。 此外,未来网络还应当: 采用智能路径选择策略,实时监测网络状态,智能分流,缓解通信热点; 支持自愈协议、冗余端口、快速故障切换(failover)机制,保障系统的鲁棒性; 具备高效的拥塞控制机制,比如端侧主导的流控与注入速率调节机制,避免严重拥塞; 支持 lossless 网络协议但避免“队头阻塞”问题,比如通过优化 CBFC(基于信用的流控)与自适应拥塞感知机制配合。 最后,研究团队指出模型规模的指数级增长,已经远远超过了高带宽内存(HBM)技术的进展速度。这种不匹配导致了严重的内存瓶颈,特别是在以注意力机制为核心的架构(例如 Transformer)中,内存带宽限制成为性能提升的最大障碍。 为此他们也提出了两点建议: DRAM 堆叠加速器(DRAM-Stacked Accelerators):借助先进的三维堆叠(3D stacking)技术,可以将 DRAM 芯片垂直整合在计算逻辑芯片之上。这种设计能够提供极高的内存带宽、超低延迟,同时具备实用的内存容量(尽管受限于堆叠层数)。对于专家混合(MoE)模型中的超高速推理任务,这种架构极具优势,因为它能显著缓解内存吞吐瓶颈。例如,SeDRAM 架构就展示了这种模式的潜力,在内存受限的工作负载下提供了前所未有的性能表现。 晶圆级系统集成(System-on-Wafer, SoW):晶圆级集成技术通过将多个计算单元和存储模块整合在一整块晶圆上,可以最大化计算密度与内存带宽,满足超大规模模型在训练与推理阶段对存储和带宽的极端需求。 他们表示,这些内存中心的架构创新,旨在打破当前内存发展滞后于模型规模扩张的瓶颈,是下一代 AI 系统持续迈向“更大、更快、更稳”的关键路径之一。同时这些方案也在 DeepSeek-V3 训练与推理实践中均取得了实效,为下一代高性能 AI 系统构建了坚实的内存支撑基础。

<blockquote><p>在 AI 技术飞速发展的当下,知识付费行业正经历深刻变革。从业者们或焦虑于被时代抛弃,或积极探索借力 AI 提升服务。文章以作者亲身体验及行业观察为例,剖析 AI 如何为知识付费提效、重塑行业格局,以及从业者应如何抓住机遇实现升维发展。</p> </blockquote>  4月底的时候,应小鹅通的邀请,去一次300多人的线下大会做了次分享 大会的主题关于AI+私域 正好,在这块有一些想法,和大家聊聊 ## 1. AI的到来,到底带来了什么 从去年到现在,我就看过好几篇追热点的文章,说AI来了知识付费要团灭 在我去年还没开始用AI的时候,我的确会有点恐慌,心想那我的职业生涯就完蛋了 但是经过了这几个月,我反而越来越平静了 对抗一个新事物带来的恐惧,最好的办法,是去拥抱这个新事物 我现在用的最习惯的是DEEPSEEK 我会用他来干嘛呢,用在自己身上,以及当我在做私域陪跑交付的时候,会用在我的交付上 比如:写朋友圈,我会丢给DS一个指令,让他给我写朋友圈,那效率真的很神奇,要多少条有多少条 但是呢,我并没有完全copy复制 为什么呢?我举个例子 这是我想让DS给我写一条朋友圈,我给他的提示  如下是TA生成的朋友圈给我  你看,DS有时候真的有点放飞最后,我融合了我自己想讲的话,和他的一些不错的句子,整合成了一条我的朋友圈还有最近我帮我一个客户做发售,需要给他写朋友圈SOP规划,一共100多条 因为 因为里面要做到至少70%以上是客户可以直接复制黏贴的 这项工作,之前人工操作,可能需要花大半天 现在,我用Deepseek,100多条的朋友圈,加上我的一些修改调整,1个小时内搞定 看到这里,不知道你们是什么想法 AI的到来,到底带来了什么? 我的答案:AI最大的改变是提效,而不是改命 作为知识付费从业者,帮助我在做课程,做产品详情页,写朋友圈,写公众号,写直播稿等,都会帮我提效, 大大节省我的时间 ## 2. AI红利分配:服务者升维VS信息贩子退场 我先说说,AI的到来,对知识付费行业,哪部分人群最不友好 第一,只卖课程,特别是录播课的IP 第二,”知识二传手”的IP:没有原创方法论的内容拼凑者 现在随便问AI一个问题,免费给你提供360度内容解析 AI都可以生成10万字的行业报告,足够摧毁这种靠信息的差盈利模式 你想:AI能免费回答的问题,为什么要付费买课? AI在免费,知识付费在崩溃 说的就是这两类IP 自从意识到这个问题,我今年开始已经不主卖我的课程产品了 我开始主推我的陪跑服务 因为,越是AI时代,越缺这种可以给客户带来结果,陪伴式的解决方案 前两天刚好有一个学员,是一位在线下做了10几年的线下培训师,专门给企业做内训讲企业管理之类的 他说最近在尝试做IP,一直找不准定位 也问了DS,DS也给出了好几个方向 但是,自己觉得都不好 你看,这个AI时代,不缺知识,不缺方案,缺的是什么? 所以,我现在越来越不焦虑,因为我知道我的服务,不会被AI取代 像我这样的强交付型从业者,AI正成为我们服务的放大器 ## 3. 怎么能够更高质量的用好AI 因为看到一些同行老师,也在开始卖智能体的工具了,所以我也在思考 什么才算是好的智能体? 为此,我之前,专门找这个行业的一个老师请假过,给大家看看  总结来说,就是智能体,可以更精准的回答你的问题 比如,有专门写朋友圈的智能体,有专门做短视频选题的智能体,有专门做定位的智能体 但是,问题又来了,什么样的智能体才算是好的智能体? 很简单,做一个智能体,主要需要用到工作流和方法论 那同样是一个写朋友圈的智能体,做这个智能体的是是两位不同的人 A: 是这方面的大V,专家,出过相关书籍,也带过很多学员 B: 和A对比,有点差距 你觉得谁做的智能体,会更好? 当然是A, 因为在他的智能体中用到他的知识库,方法论  只有最懂业务细分场景的人,才能把智能体的能力发挥出来 ## 4. 每个阶段的IP,需要用到哪些AI/智能体 上个月,去见了一位老板,专门做实体商家的,公司几百人 他问了一个他最感兴趣的问题:之前我们给销售培训的那一套,能不能喂给AI,让他降本增效? 你看,对于大IP, 不管是上面这位老板,还是类似我之前服务过的博商系,网易系等大IP,有着大几十,上百人的销售团队。 我觉得目前最需要用到的是:AI销售 相当于,过去你们需要100个销售,现在用AI销售,把销售的工作流和方法论,做成一个销冠智能体,就可以1个智能体抵10个销售 对于中小IP呢,我觉得其实每个阶段都可以用到,从定位,到私域成交,到公域流量,关键还是你怎么用 说起来,不管是针对哪个阶段的,都是4个字:降本增效 降本增效的前提,是你有自己的业务 如果当你自己业务还没跑通的时候,你去研究AI怎么帮你降本增效,有点本末倒置了 本文由人人都是产品经理作者【JJ说私域】,微信公众号:【J姐说私域】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。

<blockquote><p>在大模型时代,如何提升 AI 生成内容的确定性?本篇文章将深入探讨影响 AI 生成稳定性的关键因素,分析当前技术挑战,并提供优化策略,帮助产品经理打造更可靠的智能交互体验。</p> </blockquote>  ## 提高大模型确定性的通用方法 由于我们日常的使用大模型是通过对话的方式,我们的核心方法只能是建立在不调整大模型参数的状态下力求更好的答案,所以就是苦修提示词。提高提示词能力的细节方法。 - **提高你的认知深度和拆解能力,从而把让你的提示词足够具体。**让大模型自由发挥的框被限定在一个很小的范围内,你要不断地追问自己,你要的结果到底是什么?【主题/内容风格/格式/要用到的思维方式等】比如用cursor创建代码,你如果可以清晰要使用的框架和技术等,那么大模型的生成就不会混乱。 - **引导模型一步一步思考**,常见框架是:首先研究问题的核心和本质,然后基于问题去搜索大量的相关优质信息,总结相关信息,然后给出几个优质的解决方案和优缺点,然后选择一个最好的解决方案。 - **给模型设定角色和给一些引导和示例**,这样打模型寻找搜索相关信息和参数就会与你设定的信息和示例进行匹配。 - **让自己对于结果好坏有一个较客观的评价标准**,然后去迭代自己的提示词,提示词不是一蹴而就的,一个好的能够提高很多人效果的提示词需要不断地迭代测试。  我们在学习写作提示词的过程中也要参考别人的优秀的提示词,从而却理解别人的方法和内在逻辑,去更快的迭代自己的提示词。 还有一些很好的工具可以帮助我们迭代提示词。https://prompt.always200.com/  ## 提高大模型确定性的超参数优化法 我们可以通过API接入直接调整大模型的参数,只需要简单的调整就能让大模型本身发生一些变化,下面我们介绍几个核心的超参数(人为可以设定的参数)。 ### 1. temperature(温度系数) 取值范围:0-2 原理:控制输出的随机性和创造性。温度参数就像一个旋钮,调整概率分布的形状。低温使概率分布更尖锐,高概率词的概率更高,模型更倾向于选择最可能的词;高温使概率分布更平缓,模型更可能选择不常见词。 设置建议: - 0-0.3:适合事实性回答、代码生成等需要精确性的场景 - 0.4-0.7:平衡创造性和一致性,适合一般对话 - 0.8-1.0:适合创意写作、头脑风暴等需要多样化的场景 - 1.0以上:产生更随机、可能不连贯的输出(谨慎使用) ### 2. top_p(核采样) 取值范围:0-1 原理:限制模型只考虑累积概率达到top_p值的最小词集合,从这个动态大小的词集合中采样。当top_p为0.1时,模型只会从累积概率达到10%的词库中选择下一个词。 设置建议: - 0.1-0.3:适合精确的、确定性强的回答 - 0.5-0.7:适合一般对话 - 0.8-1.0:适合创意生成 ### 3. frequency_penalty(频率惩罚) 取值范围:-2.0到2.0 原理:减少已出现词语再次出现的概率,控制重复程度。频率惩罚会根据token在生成内容中出现的频率来惩罚,出现次数越多,惩罚越大。值越高,模型就越不可能重复使用同一词语。 设置建议: - 0:不惩罚重复 - 0.5-1.0:减少重复,增加多样性 - 负值:增加重复(特殊场景下使用,如需要强调某些概念) ### 4. presence_penalty(存在惩罚) 取值范围:-2.0到2.0 原理:减少所有已出现过的token再次出现的概率,无论出现次数多少。与frequency_penalty不同,presence_penalty只关心token是否出现过,不考虑出现频率。值越高,越可能引入新话题和新内容。 设置建议: - 0:不惩罚已出现内容 - 0.5-1.0:鼓励模型引入新内容和话题 - 负值:鼓励重复已有内容(特殊场景下使用) ### 5. logit_bias(Token偏好) 取值:{token_id: bias}字典 原理:增加或减少特定token出现的概率,bias值在-100到100之间。正值增加概率,负值减少概率。 设置建议:用于鼓励或禁止使用特定词汇,需要先通过tokenizer获取词汇对应的token_id。 ### 6. response_format(响应格式) 取值:{“type”: “text”} 或 {“type”: “json_object”} 原理:指定模型生成的内容格式,尤其是需要结构化数据时很有用。 设置建议:需要结构化数据时使用JSON格式,可以大大简化后续处理。 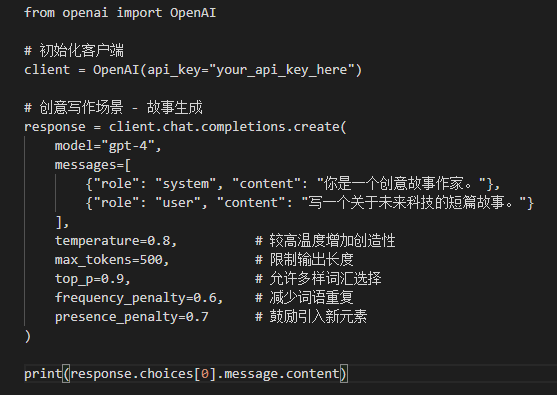 ## 其他方法:选择更好的大模型 如何选择大模型,也是需要仔细思考的。 ### 1.通过自己的业务场景判断 通过看自己的业务对应的是大模型哪一个方面的能力,数学/推理/代码生成。不同模型往往是各有所长,claud-3.7-sonnet可能代码生成能力较强。Gemini-2.5可能推理能力较强。所以要去思考自己的业务属于哪些方面,再从细分的方面去找最强的模型。 ### 2.看评价方式和测评重点 有些是通过数学题目,有些事测评各个领域的知识,有些甚至考的是博士题,那么根据你的业务场景要去思考,你到底是要一个各个领域知识都懂的大模型,还是需要解决搞复杂性的数学题目和博士题目,还是要代码生成能力。同时也要参考英语考试和中文考试 比如下面这个中文的测试 CEVAL https://cevalbenchmark.com/static/leaderboard.html 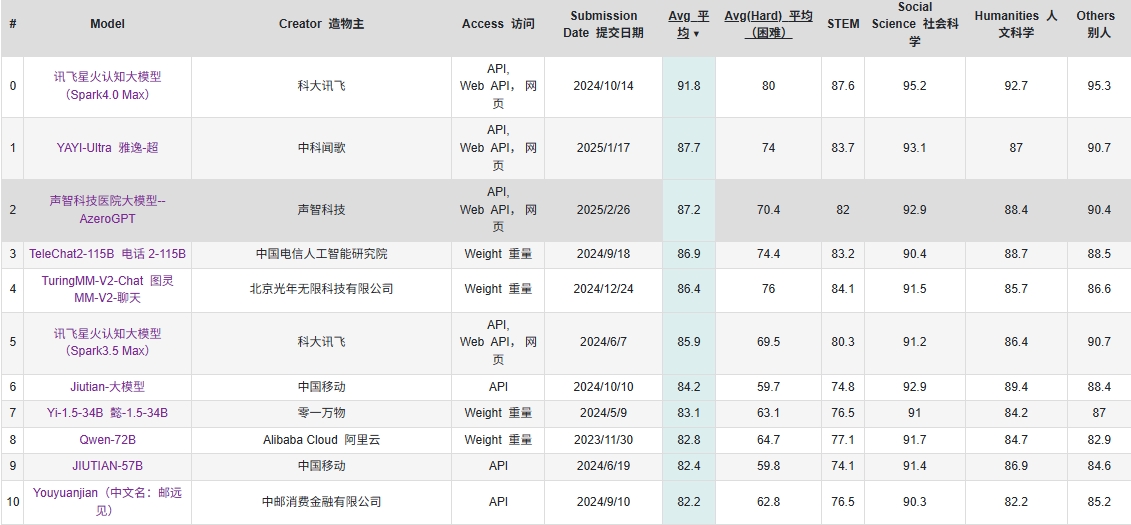 ### 3.对于自己的业务问题做AB测试 发送同样的提示词给不同的大模型API,然后通过脚本不断地传输这些问题,让大模型反复出答案,最后对于问题有一个excel表格,然后人工对于这些问题的答案做打分,从而得出更好的大模型。 本文由 @青阳-AI 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

<blockquote><p>从技术的快速迭代到客户需求的精准把握,再到性价比的极致优化,信息差成为产品成功的关键。对于产品经理和创业者来说,本文提供了一种全新的视角,帮助他们更好地理解市场动态,提升产品的竞争力。</p> </blockquote>  如果我问你,你的产品为什么能卖得动/卖不动?客户为什么要买你的产品?你产品的核心竞争力是什么? 你可能会噼里啪啦说出各式各样的答案:产品用到了AI有技术门槛,产品的创意符合客户需要,产品的性价比超高,公司的销售人员能力强,销售跟客户的关系好….. 不过呢,咱要是把这些五花八门的答案都扒拉扒拉,好好“洗一洗”“筛一筛”,就会发现最最核心的东西,就是一个词儿:信息差! 没错,就是信息差! 换句话说,产品的终极竞争力其实就是:我懂的,你不懂;或者你懂的,客户压根儿不知道! ## 首先,咱们来聊聊产品技术含量高那点事 去年有个晚上,我跟前阿里一个技术大拿S总煲了足足一个多小时的电话粥。聊啥呢? 因为我们产品要用到他们做的OCR服务,虽然这玩意儿算是一种常见的AI引擎,但我们公司庙小养不了算法工程师,于是,只能寻求外购。 正好,身处大厂的“总”们有着强烈的职业焦虑,工作之余也想把自己的技术换成钞票,于是咱们就有了这次业务合作。 那次打电话,主要聊的是前期采购的OCR服务要升级的事儿。 升级啥呢? 得针对表格识别样式来个“格式还原”。我跟S总磨破了嘴皮子,就为了砍价。人家一开口就要十几万,我心里直喊“乖乖”,我这预算可就5万啊。 我就坚持一个观点,技术不值钱,特别是这种已经“过气”的技术。 最后,S总妥协了,报价几万块。对他们来讲,都是半成本,稍微改吧一下能收入几个w,也算是一个可以接受的买卖。 你看,现在这AI技术啊,那真是跟坐了火箭似的,一天一个样儿。 各种开源的大模型跟雨后春笋似的往外冒,昨天还算是前沿技术的玩意儿,没过几天就“白菜价”了,甚至直接开源免费给大家用。 咱撇开那些大企业花大价钱搞底层技术研究不说,就咱商用产品用到的那点技术,真没啥了不起的门槛。 所谓的“门槛”,无非就是我家先发现了这个技术,而你家还在四处寻找。 这样,我的产品就能先声夺人,拥有竞争优势。在客户还没弄清楚这是啥黑科技之前,我赶紧卖个好价钱,顺便收点“智商税。等过几年,这个技术就会开始烂大街,产品也会被打到地板价。 再举个例子来说,前几年看起来“高大上”的NLP技术,其实用正则表达式也可以达到类似的文书数据提取的效果。而正则表达式技术门槛相对NLP来讲就低得多,对应的开发周期和人力成本也要低得多。 为什么之前我们不用正则表达式去做提取,而要选择用NLP呢? 说白了,之前不知道正则表达式就可以做到。 话说回来,如果你能比别人快一步掌握某项技术,那你就能享受到技术的红利,把产品包装得高大上,趁别人还没回过神儿的时候,狠狠赚上一笔! ## 其次,所谓的产品创意好,不就是我比你更懂客户吗? 接着咱再唠唠这所谓产品创意好。 说一个具体的例子: 去年有一次找客户交流某款产品,客户就给我总结了两个非常好的产品价值: 第一,能用AI技术提取文书里的关键词,减轻业务人员使用系统的工作负担,这样大家就更愿意使用; 第二,这个系统,不光能做A阶段的业务评估,连B阶段的必要性审查这些业务场景都能搞定,实现全流程的智能评估。 我一听,这信息可太有价值啦! 一方面呢,我赶紧拿这些信息去完善产品功能,让产品变得更强大,在市场上更有竞争力。另一方面呢,把这些信息提炼成产品卖点,准备去“普惠”更多客户。 后来我去给一个新客户汇报的时候,把这两点一说,你猜怎么着? 那新客户眼睛都直了,感觉我就是他们单位的业务人员,觉得我们的产品简直就是为他们量身定制的,还一个劲儿地惊叹:“你们咋这么懂我们呢?” 其实啊,所谓的产品有创新,所谓的更懂客户,说到底不就是你接触的客户多嘛? 从他们那儿获取到别人不知道的信息,然后就像变魔术一样,把这些信息巧妙地加到产品功能和宣传里。等遇到另一个客户的时候,就让他们为自己的“无知”(其实是不了解这些信息)买单。 ## 最后,再来说一说产品的性价比高的事 性价比这东西,说白了就像是一场“比武大赛”,你得跟竞品比比,看看是你的价格更接地气,功能更牛掰,效果更炸裂。 要说最能体现性价比高的,那就是产品价格低到让竞争对手直呼“伤不起”,他们就算绞尽脑汁想模仿你的产品,一算账,哎呀妈呀,不划算呐,只能干瞪眼。 那么问题来了,你的产品凭什么能定低价呢? 从商业那点事儿来看哈,要么就是咱判断这产品市场空间大得像宇宙,薄利多销也能赚得盆满钵满;要么就是长远来看,这市场规模就跟吹气球似的,越来越大,那咱就牺牲点短期收益,用低价把竞争对手打得落花流水 当我们看到一款产品,在市场的激烈“厮杀”中活了下来,还一路高歌猛进,靠低价横扫市场。我们会敬佩这家企业有战略、有眼光,有格局。 但实际情况呢,很有可能人家是提前拿到了行业的“内部消息”,就像开了天眼一样,轻松预判到市场的发展趋势。 就好比说,咱给某个客户做了一个项目,客户拿着这成果去向上级汇报,上级领导一看,嘿,不错啊,全国推广! 这消息要是让你知道了,你是不是心里就有底了,能准确预判市场规模,然后大手一挥,把产品价格定得低低的,把潜在竞争对手都堵在门外。 关起门来说,市面上有一大部分产品,其实就是赢在了发令枪响之前,获知到有效信息提前抢跑。 那些看似高明的营销策略,其实也就是基于一些“关键信息”做出来的决策。 为什么说做销售出身的人,更容易创业成功,更大概率会自己当老板? 因为这些人获取信息的能力比其他人更强,更善于搞人物关系,人物关系的背后就是“关键信息”,就是产品的核心竞争力。 **站在产品经理视角来讲,如何提升产品的竞争力呢?** **就是得有意的去提升学习、总结、提炼信息的方式,积累可以获取到关键信息的资源。当你掌握的信息越多,获取信息的成本越低,拿到信息的速度越快,自然,你做出来的产品就会越值钱。** 明白了这个逻辑,你才会不抗拒出差,甚至喜欢出差去见客户;才会有意的加上客户的微信,保持长期的联系;才会主动的找销售沟通,了解市场的反馈;才会去做政策信息的解读,提炼出有价值的信息。 这样,你才能够摆脱“原型仔”、“工具人”的标签,成为一个更值钱的“信息人”。 ## 最后的话 说一千道一万,产品的竞争力、创意、性价比这些看似复杂的要素,归根结底都离不开“信息差”这个魔法词汇。 就像玩扑克,谁手里的牌最好,谁就是赢家,而牌的好坏,就取决于你掌握的信息有多少。 所以啊,想要产品卖得动,就得比客户知道得多,比竞争对手更懂行。这就是咱们产品经理的秘诀:做个“信息人”,用信息差来打造产品的核心竞争力。 作者:武林,公众号:肖武林 本文由@武林 原创发布于人人都是产品经理,未经作者许可,禁止转载。 题图来自Unsplash,基于CC0协议。 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
 钛媒体 · Chelsea_Sun
钛媒体 · Chelsea_Sun
Tencent will first use GPUs "for the applications that will generate immediate returns for us", and the training of LLMs is the company's second priority, Martin Lau said. He said software optimization and other ways can help Tencent fulfill the expanding and growing inference needs.

<blockquote><p>自然界中的“群体智能”现象,如蜜蜂、蚂蚁等群体通过局部互动完成复杂决策,为我们提供了新的思路。本文将探讨如何通过特定的“群体智能”触发词,让AI模拟这种群体决策模式,从而生成更全面、更有创意且更贴近实际需求的答案。</p> </blockquote>  你看看蜜蜂,一只蜜蜂其实没啥脑子,嗡嗡飞来飞去也就那样,但是一万只蜜蜂在一起,能找到最好的花朵,还能决定在哪安新家。 这个叫“群体智能”,不止蜜蜂,蚂蚁、鸟群、鱼群都这么干,全凭大家的“局部互动”搞定复杂决策。 你也许会问,那能让我们的AI也这么“团结”吗?答案是:绝对可以! 通过一些小技巧,能让AI像蜜蜂一样,搞个小团队辩论、投票、合作,弄出比你问一次就完事儿更牛的答案,既全面又有创意,甚至还能挖出一些你压根儿没想到的东西。 今天我就跟你聊聊怎么用这种“群体智能”法子,让AI的回答立马提升几个档次。 ## 一、什么是AI的“群体智能”模式? 平常你问AI一个问题,它就是个单一模型,老老实实给你找一个答案。但是在“群体智能”模式下,玩法变了: **1.AI分裂成多个“角色”** ——就好像一群演员,每个都有自己剧本。 **2.设定辩论规则** ——你说,来吧,你们来辩一辩,看谁有理。 **3.大家合议得出最终答案** ——所有的视角一综合,诶,出来的答案往往超出你想象。 比如说,普通提问深度算三星,到了群体智能这儿,能奔五星去,创新性也能多个一星半星的,还不容易带有偏见。 简单打个比方: ### 普通提问 vs 群体智能模式 **普通提问:** <blockquote><p>“怎么解决气候变化啊?”</p></blockquote>  AI随便给你整点常见的答案,什么新能源这些的。听上去挺对,但好像也挺普通,没啥特别。 群体智能模式触发: <blockquote><p>“假设你有10个不同领域的专家,比如气候学家、经济学家、政治家啥的,让他们开个会辩论一下,最后投个票,挑出三个最靠谱的解决气候变化的方案。”</p></blockquote>  结果每个人从自己角度出发,有的说搞碳交易市场好,有的主张全球公平优先,还有人坚持搞技术突破最管用。 一听,大家的意见一结合,哇塞,出来的东西确实比你自己单一思维靠谱多了。 ## 二、具体怎么操作?四种“触发词”搞定 想让AI搞群体智能,关键在于你会不会下指令。下面我给你几个具体方法,屡试不爽。 ### 1. 角色分裂法 让AI分身,进入多个角色。比如说: <blockquote><p>“假设你是个哲学家、科学家、艺术家和工程师,一个个来说说这个问题,然后再比较一下你们的答案有啥不同。”</p></blockquote> 结果AI立刻生成四种完全不同的思路,有时能一下子戳中你的思维盲区。视角多了,问题自然也就解得更透彻了。 ### 2. 辩论赛模式 给AI搞个辩论赛,让它们对抗性地给答案。 <blockquote><p>“咱们整两派,支持的和反对的,各自甩出三个解决XXX的理由,最后让裁判来拍板哪个论点更好。”</p></blockquote> 这类对抗模式特像AlphaGo 的自我对弈,越辩越明,答案就在冲突中清晰出来了。 ### 3. 投票共识法 简单,让一堆AI生成的答案进行投票,最后保留最受欢迎的。 <blockquote><p>“给我弄5个可以解决XXX的不同的解决方案,然后假设有100个人参与投票,把那些得票超过70%的挑出来。”</p></blockquote> 这个法子特别有效,那些稀奇古怪或者特立独行的意见基本就被筛掉了,留下大众认可的智慧,简直就是挑精华。 ### 4. 蚁群算法模拟 模拟蚂蚁找食物的套路,让多个AI尝试不同路径,最后找出最有效的那个。 <blockquote><p>“我想解决XXX,请你像蚂蚁觅食一样,让10个AI分头去找路,逐步淘汰掉那些不够好的路线。”</p></blockquote> 这特别适合那些需要找最优解的复杂问题,不容易陷在一个不好的答案里。 ## 三、让“群体智能AI”更厉害的高阶玩法 这里有些稍微复杂点的小技巧,效果特好,能让AI的表现直接上一个台阶。 ### 技巧1:给不同角色加点“人味儿” 让每个AI都有自己独特的个性,那样辩论起来争论才激烈,意见才真实。 <blockquote><p>“我想解决一个XXXX的问题,请你派一个自由派经济学家、一个保守派政治家和一个激进环保主义者来争论,记住得明确他们的立场。”</p></blockquote> 保准争论得更凶,但最后出来的结论也许一综合,比那些不疼不痒的回答妙得多。 ### 技巧2:人为“信息差”制造讨论的悬念 给AI点“偏差数据”,模拟现实世界那种“有些人知道得多,有些人知道得少”的情形。 <blockquote><p>“这5个专家啊,每人掌握不同信息,A只能用2020年以前的数据,B倒是手里有份内部机密报告,看看他们之间的辩论咋样。”</p></blockquote> AI对话马上就真实不少,最后的答案也不会太过片面,反而多了点不一样的思考维度。 ### 技巧3:把一次搞定,变成多次“进化” 可以先让AI弄一堆备选方案,接着通过层层淘汰和进化,逼出那个最优秀的解法。 <blockquote><p>“第一轮让AI搞10个方案,第二轮干掉5个,第三轮让剩下的再交配进化下。”</p></blockquote> 整个进化过程,答案精度就会慢慢逐步提高,越来越接近最优解。 ## 四、这些玩法在哪些场景用最好? OK,可能你要问了,这些玩法究竟适合哪些场景中的问题呢?来,举些例子—— **1.争议性话题** 气候变化、相关争议的问题这种,各派有不同意见的,能让群体智能高度模拟,众人之智高于个别人。 **2.创意发散** 故事创作、产品设计,让一大堆不同AI脑袋风暴一通,搞点不寻常创意。 **3.复杂决策** 诸如商业战略或公共政策这种特复杂的问题,多听几方意见出错少。 ### 不适合的场景 那总也有些问题是不合适这种套路的场景: **1.简单事实问题** 比如“珠穆朗玛峰多高?”这类有固定答案的,用这法子多了反而累赘。 **2.单一标准答案的问题** 类似“1+1等于几?” 这种就别折腾了,越折腾越离谱。 本文由人人都是产品经理作者【抖知书】,微信公众号:【抖知书】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。
 36氪
36氪作者 | 黄绎达 编辑 | 郑怀舟 5月14日港股盘后,腾讯控股(以下简称:腾讯)发布了2025Q1的财务报告。 2025Q1,受益于AI战略持续加码,增值服务、营销服务、金科与企服等核心业务收入与利润齐增长。财报显示,腾讯在本季度实现收入1800.2亿元,同比增长13%,大超市场预期。 在收入稳健增长的同时,利润方面延续了之前的强势表现,同期毛利录得1005亿元,同比增长20%;同期Non-IFRS经营利润为693亿元,同比增长18%。值得注意的是,毛利和经营利润的增速已连续十个季度领先收入增速。 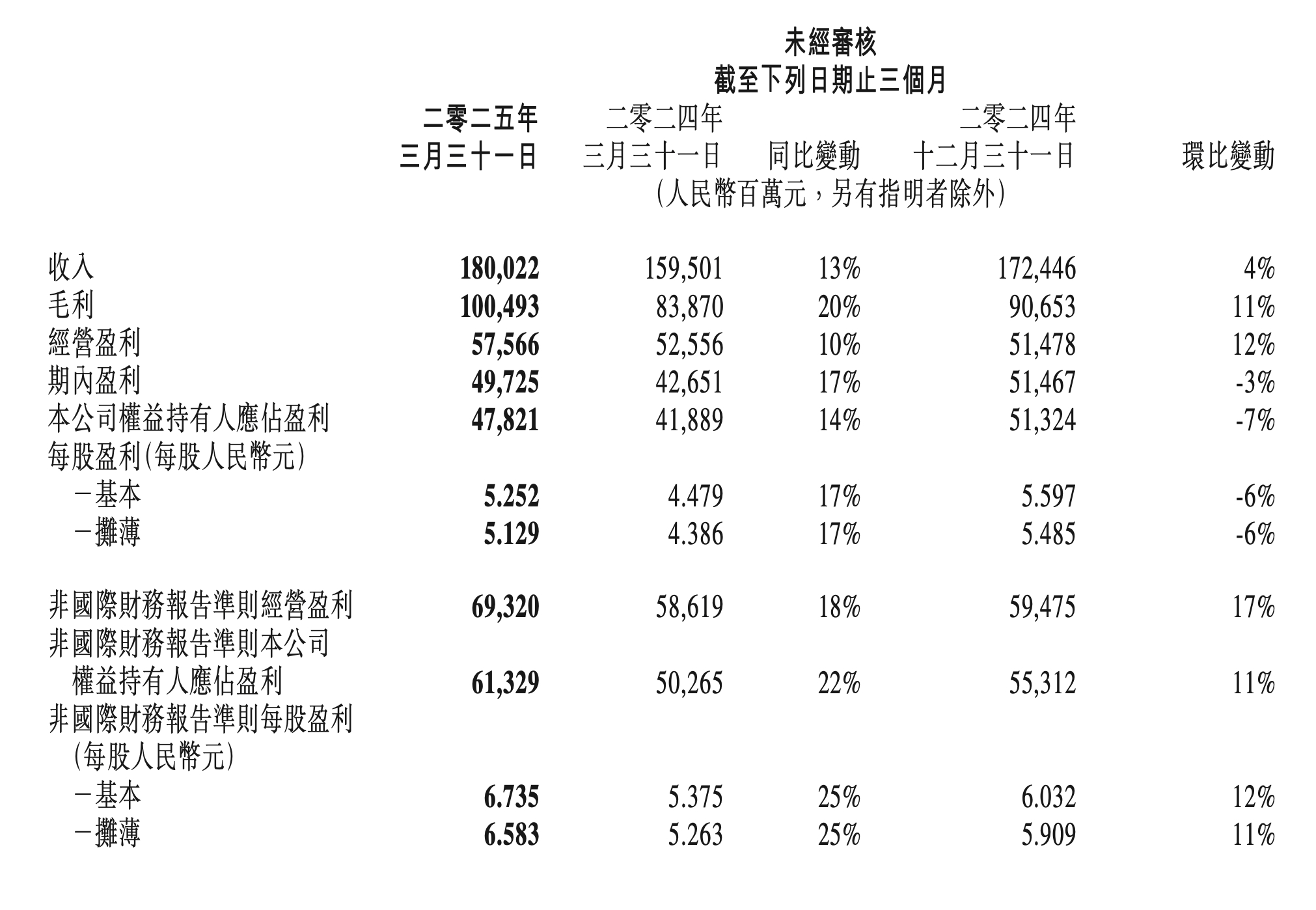 图:腾讯控股财报摘要;资料来源:公司财报,36氪 AI方面,腾讯研发上依旧保持了较高强度,本季度研发投入同比增长21%,资本开支同比增长91%。受益于AI技术持续赋能核心业务,业务端的高质量增长又能反哺研发,由此形成良性循环。董事会主席兼首席执行官马化腾表示:“在AI战略投入阶段,现有高质量收入带来的经营杠杆,将有助于消化这些AI相关投入产生的额外成本,保持财务稳健” 在经济弱复苏的大背景下,腾讯业绩增长强劲作为核心驱动因素,叠加AI赋能核心业务带来的想象空间,截至5月14日,腾讯港股在最近一个多月的时间里持续反弹,区间涨幅录得25%。 那么,本季度腾讯财报有哪些亮点?AI in All战略会给公司带来怎样的想象空间? ## **01 增值服务:AI强化造血能力** 腾讯的增值服务业务在2025Q1实现收入921亿元,同比增长17%,增值服务在本季度的收入占比约51%,环比2024Q4提升了5pct。 从业务结构来看,国内游戏在同期实现收入429亿元,同比增长24%;国际游戏同期收入录得166亿元,按固定汇率计算的同比增速为22%;同期的社交网络收入(包括音乐、游戏直播、视频直播等细分业务)326亿元,同比增长7%。 国内游戏在本季度的收入暴涨,除了受益于去年的低基数之外,在产品端,新游戏与长青游戏对收入增长均有贡献。长青游戏方面,包括《王者荣耀》、《穿越火线手游》在内的多款长青游戏在本季度的流水刷新历史新高。 新游戏方面,《三角洲行动》带来的增量收入为国内游戏在本季度的收入暴涨提供了强支撑,从运营数据来看,《三角洲行动》的用户人数在本季度再创新高,DAU峰值在2025年4月突破1200万,而且《三角洲行动》是近三年发布的游戏中平均DAU最高的游戏。 国际游戏方面,《PUBG MOBILE》、《荒野乱斗等》、《部落冲突:皇室战争》等游戏延续了此前的强劲表现,是驱动国际游戏收入增长的核心动力。 AI赋能对游戏业务的收入增长起到了至关重要的作用,通过AI技术应用来提升用户体验与产品活跃度,强化游戏业务的造血能力,其典型案例是在《和平精英》引入DeepSeek大模型,推出AI助手和AI队友为玩家提供游戏指导,还可以与玩家对局,用户体验的提升有助于增强长青产品的用户黏性。 利润方面,增值服务业务分部在本季度实现毛利549亿元,同比增长22%,业务分部毛利的增长,主要由国内游戏业务及小游戏平台服务费的增长所驱动。盈利能力方面,本季度增值服务业务分部的毛利率录得60%,同比和环比提升了3pct和4pct。 ## **02 营销服务:AI升级和提升视频号广告负载支撑收入增长** 营销服务业务分部在本季度实现收入319亿元,同比增长20%,收入增长加速,且增速水平超市场预期;营销服务在本季度的收入占比约18%,环比2024Q4降低了2pct。 本季度广告业务的收入增长主要由视频号、小程序和微信搜一搜广告收入共同拉动;从广告主的维度来看,大多数重点行业的营销服务收入均有增长。根据腾讯业绩会披露的信息,本季度广告业务收入增长的一大内生动力,是适当提升了视频号广告的负载,目前视频号广告的负载依然在低个位数,相比友商未来还有很大的提升空间。 广告业务的内生增长另一大动力,是源于对广告平台的AI升级和微信交易生态系统的优化。本季度,腾讯在升级广告技术平台的主要工作是提升生成式AI的相关技术能力,比如为了加速广告制作,进一步改进了图像生成和视频编辑功能,推出数字人解决方案来助力直播,继续深化对用户的兴趣学习,从而提升推广效果。 利润方面,营销服务业务分部在本季度实现毛利177亿元,同比增长22%;业务分部毛利的增长,主要由高毛利率的视频号广告、微信搜一搜广告等细分业务的收入增长拉动。盈利能力方面,广告业务分部本季度的毛利率录得56%,同比提升1pct,环比下降2pct。 ## **03 金融科技与企服:收入增速小幅反弹** 金融科技与企服业务分部在本季度实现收入549亿元,同比增长5%,相比2024Q4,增速水平有所反弹;金科与企服业务分部在本季度的收入占比约31%,环比2024Q4降低了2pct。 从长周期的维度来看,腾讯金科与企服业务收入在近一年的收入增长相比之前出现明显放缓,主要是受到了当下经济持续弱复苏的影响。从短期来看,金科与企服业务在2025Q1出现的收入增速小幅反弹,主要是由消费贷服务和理财服务的收入增长,与云服务收入和商家技术服务费的增长所共同驱动。 利润方面,金科与企服在本季度实现毛利276亿元,同比增长16%;业务分部毛利增长的核心动力,包括支付服务和云业务盈利能力的提升,叠加消费贷和理财服务的收入的增长。盈利能力方面,金科与企服业务分部在本季度的毛利率为50%,同比与环比分别提升了4pct和3pct。 ## **04 核心业务的AI叙事是未来估值腾讯的核心点** 目前,腾讯的业务生态发展平稳,而且随着AI技术的渗透,腾讯的业务版图已经在被逐步重塑,所以在这样的背景下,判断腾讯的投资价值,除了基于宏观经济以及行业发展规律来预期未来各业务分部的业绩增长外,还要充分考量AI相关应用对其业绩增长的支撑能力。 在基建方面,为了让旗下全业务线加速AI化迭代,腾讯正在推进的AI in All战略。于C端生态,腾讯已实现AI应用的全场景覆盖,元宝、ima等原生AI产品表现亮眼,除了自有平台的快速迭代更新外,元宝还通过混元、DeepSeek双驱模式来驱动用户增长。同时,腾讯正在推动其核心C端产品的AI化升级,微信、QQ、腾讯文档、腾讯会议、QQ浏览器等产品正在陆续上线AI新功能,意在提升用户体验与黏性。 于B端,腾讯加速对相关业务的AI技术渗透,特别是通过API、SDK等形式开放AI、云计算等核心技术,帮助客户提效,为客户提供企业智能化转型方案,并持续推动产业创新。其典型案例包括助力一汽丰田将客服机器人解决率提升至84%,为大参林构建立首个医药零售行业AI知识库提供相关技术支持等。 在AI in All战略的驱动下,腾讯核心业务的内生增长能力得以大幅提升。在广告业务中,由AI驱动的智能化投放系统显著提升了广告的投放精度,由此带动多个行业广告主投放的同比增长;游戏业务中,通过推出AI助手、AI队友增强了部分长青游戏的产品活跃度和用户黏性;金科与企服业务中,核心的云服务是AI应用的重点,在业绩方面也带来了立竿见影的效果。 AI in All战略在驱动业务全面AI化的同时,持续提升自身AI技术能力是重中之重。为了夯实技术底座,腾讯本季度的资本开支高达275亿元,同比增长91%,约占同期收入的15%;研发费用支出189亿元,同比增长21%,上述数据都表明腾讯正在加大AI布局的力度。 虽然腾讯在研发端的资本支出力度大超市场预期,但其资本开支态度仍以需求驱动为主,会根据市场变化来进行动态响应。由此可见,旺盛需求依然驱动腾讯大幅提升了资本开支,考虑到腾讯对资本支出的态度并不激进,预计未来腾讯的资本开支还将保持与下游需求、收入等多方面相平衡的状态。 估值方面,目前腾讯股价相比2024年初的低点已经翻倍,截至5月14日,腾讯港股PE-TTM约23x,处于近5年来的81%分位。在经历了一轮估值修复后,虽然股价相比此前的高点还有很大空间,但考虑到估值分位,投资者需要注意当下的安全边际。腾讯在未来能否打开估值的向上空间,则主要看其核心业务AI化之后所呈现出的内生增长能力,这也是腾讯长期投资价值所在。 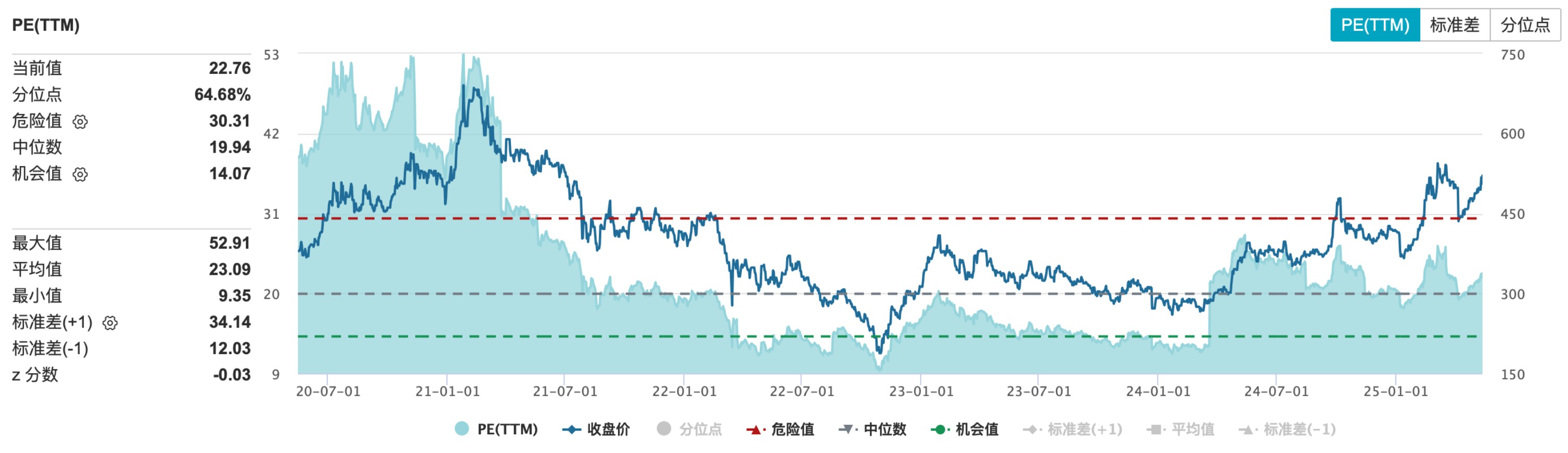 图:腾讯PE-TTM分位数;资料来源:Wind、36氪整理 *免责声明: 本文内容仅代表作者看法。 市场有风险,投资需谨慎。在任何情况下,本文中的信息或所表述的意见均不构成对任何人的投资建议。在决定投资前,如有需要,投资者务必向专业人士咨询并谨慎决策。我们无意为交易各方提供承销服务或任何需持有特定资质或牌照方可从事的服务。
 香港任天堂My Nintendo Store现已开放「Nintendo Switch 2」以及 「Nintendo Switch 2 马力欧卡丁车世界 主机组合」 的会员优先预购,Nintendo Switch Online会员可以直接进行购买,无需抽选,每个Nintendo Account限购件数一件。 「Nintendo Switch 2」售价为3450港币(折合人民币3185元) 「Nintendo Switch 2 马力欧卡丁车世界 主机组合」 售价3750港币(折合人民币3462元) 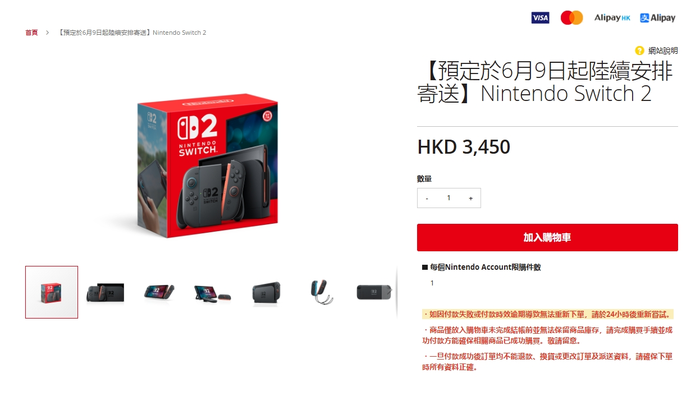 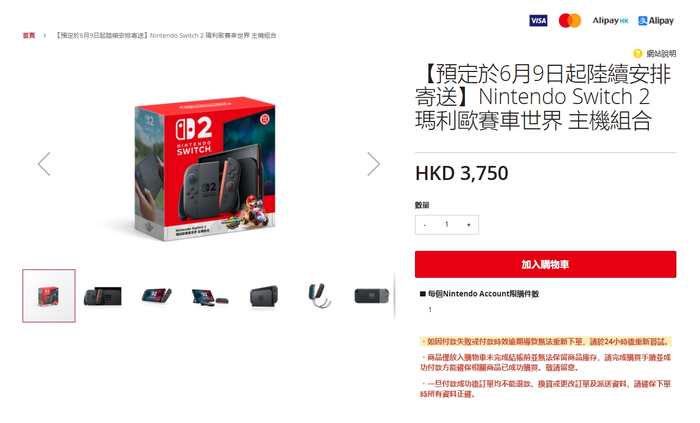 购买时必须加入有效的Nintendo Switch Online(付费)。以免费体验的方式加入的帐号无法购买。帐号的地区须设定为香港。  预购可享有免运费优惠派送至香港顺丰站,预定于6月9日起陆续安排寄送。  (你怎么知道我已经买到了())

<blockquote><p>在 2025 罗技大师系列智「简」大赛中,MX KEYS S 键盘凭借其卓越的设计与智能化体验,成为众多创作者的理想之选。本篇文章将深入评测这款键盘的核心功能、使用体验及创新亮点,帮助你了解它如何提升工作效率,实现“化繁为简,击少成多”的理念。</p> </blockquote>  ## 一、设计语言与人体工学 MX Mechanical延续了罗技大师系列的极简商务风,84键紧凑布局节省桌面空间的同时保留了独立方向键。铝制磨砂上盖与球面凹槽键帽设计兼顾质感与指腹贴合度,底部可调倾角支架(约10度)适应不同打字姿势,但矮轴结构相比传统机械键盘仍需要搭配腕托缓解手腕压力。506g的重量和296mm长度使其便携性优于全尺寸键盘,适合多场景切换。  ## 二、轴体与输入体验 采用矮轴机械结构,提供茶轴(段落感)、红轴(线性)等选择。茶轴触发力度适中,轻微段落感和降噪设计使其成为办公场景的平衡之选,噪音控制在45dB左右,优于传统青轴。1.5mm短键程带来快速触发响应,但习惯传统机械键盘的用户可能需要适应其较浅的按压反馈。弧面双色键帽的防滑表现优异,连续打字4小时未见明显疲劳感。 ## 三、生产力功能亮点 - **多设备切换**:支持蓝牙/LogiBolt三设备配对,Easy-Switch按钮实现跨系统(Win/macOS/Linux)无缝切换; - **智能背光**:6级亮度调节+人体感应技术,手部接近时自动点亮,续航与实用性兼得; - **快捷键生态**:Fn组合键支持表情调取、截图、语音输入等操作,与MX Master 3S鼠标联动可进一步提升效率; - **续航能力**:Type-C接口充电15分钟满足8小时使用,关闭背光后续航可达10个月。 ## 四、适用场景与局限性 优势场景: - 数字内容创作(文案/代码/设计)需高频输入且追求静音的环境; - 多设备协作的跨平台办公人群。 争议点: - 矮轴手感更接近笔记本键盘,机械轴爱好者可能认为其缺乏传统轴体的「灵魂」; ## 总结 MX Mechanical在商务场景中实现了机械手感与静音需求的平衡,其多设备管理和智能交互设计彰显罗技对生产力工具的深刻理解。若预算充足且追求高效极简办公体验,它仍是当前矮轴键盘中的标杆产品。 本文由 @阿呆❤ ℡ 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

<blockquote><p>在内容创作领域,如何让作品实现“自热”,吸引更多用户关注?本篇文章将深入解析打粉的核心逻辑,探讨作品自传播的关键因素,并提供实用策略,帮助创作者提升内容影响力,实现更高效的用户增长。</p> </blockquote>  今天咱来聊聊作品自热。啥叫作品自热呢?简单说啊,就是作品靠自然流量上热门,就像咱平时发短视频那样。这“作品自热”可是打粉行业里的行话。 这个方法啊,基本上能适用于 99% 的行业,除了那些违规不让发的。咱的思路就是做一个有潜力能自热的作品,或者找个模板批量做作品。要是效果不错,咱还能付费放大流量,这就是投流,后面咱会详细说。 既然是入门教程,我先给大家提个醒。要是你想进入引流打粉这个行业,交友粉、兼职粉和创业粉这三种粉最好做。为啥呢?不是因为技术简单,而是它们受众广。  先给大家举几个例子。 就说男交友粉的作品,一张图写上“06 年,找个什么男朋友”,它的后端其实是做红娘匹配,给你介绍对象,收个 99 或者 199 块钱。 有人就问了,这些图片从哪找呢? 简单,淘宝一块钱能买好多素材,或者去小红书搜“素颜”这样的话题,里面图片多的是。 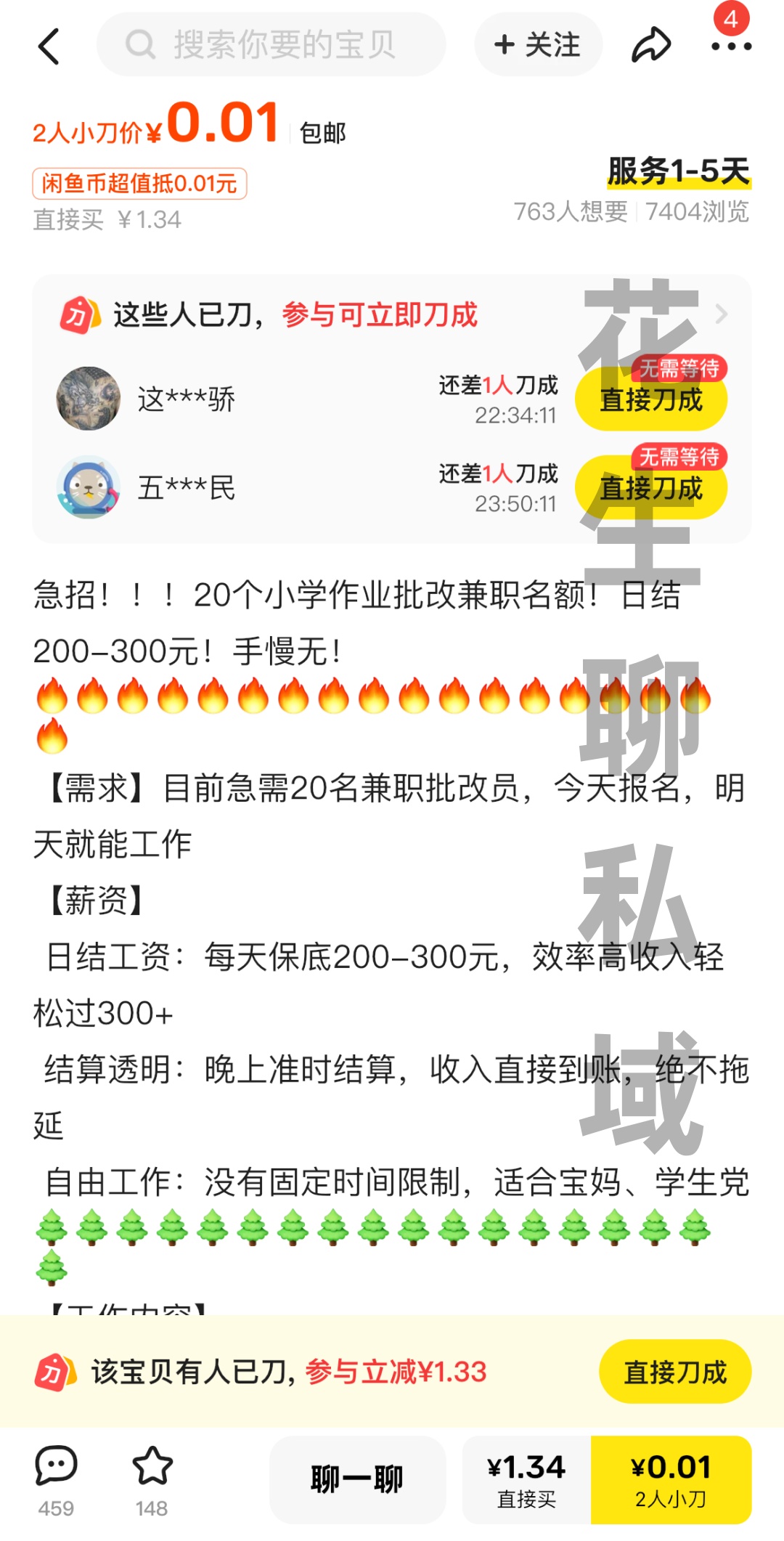 再看看兼职粉。 你瞧闲鱼上发的那种帖子,流量可好了,七千多的流量,有七百多人咨询呢,这就属于作品自热。  小红书也一样,像那种抄书的内容,针对的就是兼职人群,流量也超多。快手、抖音上也都是类似的内容,这些粉丝很容易找。 还有创业粉,好多人问创业粉和兼职粉有啥区别。其实这界限挺模糊的,我这么说吧,兼职粉就是没钱的创业粉。兼职粉是想找份工作,靠出卖劳动力赚钱;创业粉是想找个赚钱的门道。比如说抖音上那个后端做无人直播培训的短视频,跟你讲播甄嬛传一天能赚多少钱,流量大得很。 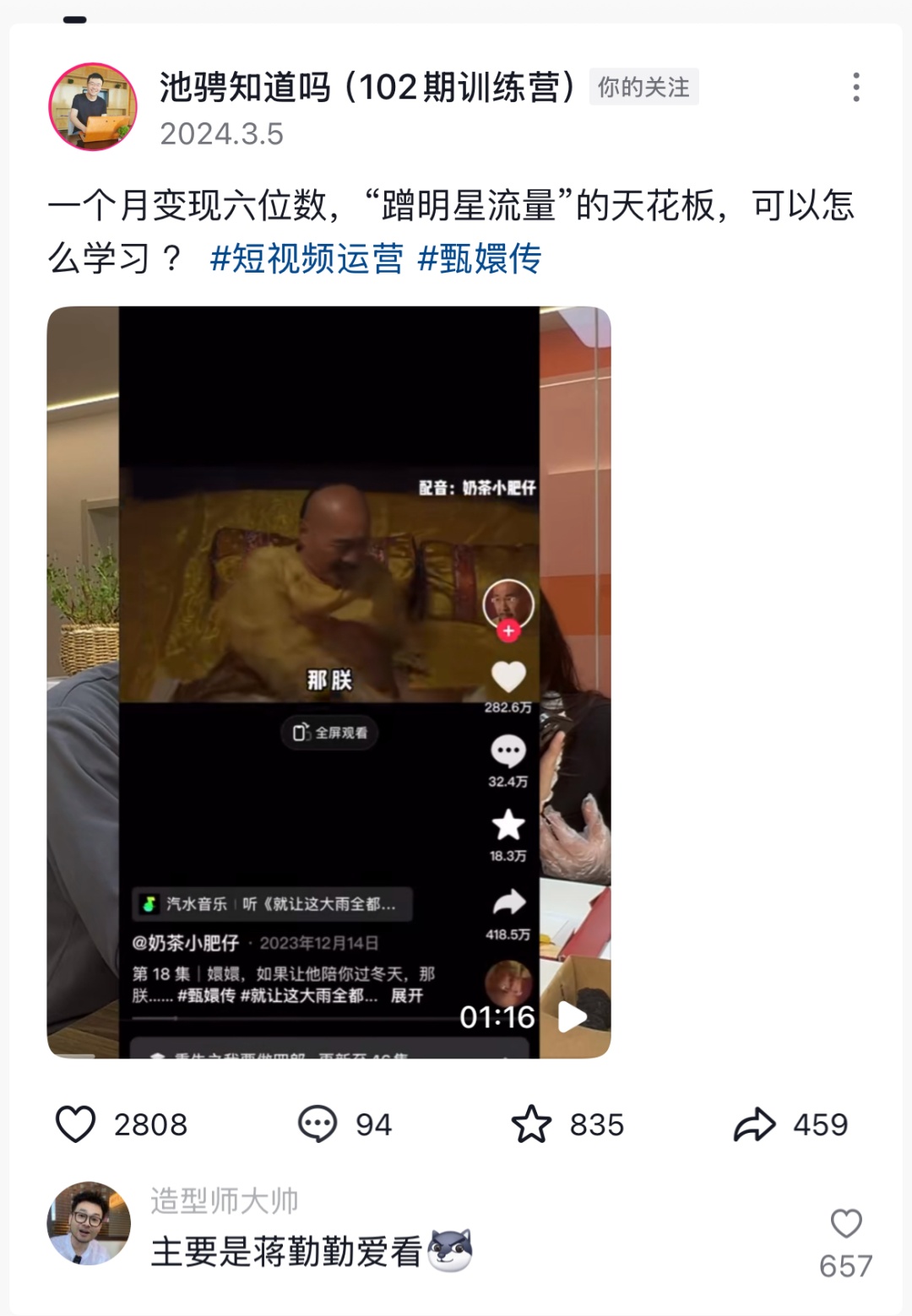 现在大家应该明白啥叫作品自热了吧,就是发图文、发短视频来获得流量。肯定有人会说:“这太难了,我不会做视频,不会拍摄,也没有演员,找不到灵感,还怕制作成本高,创作内容也不会。”别担心,我送大家三个字:看、搬、抄。同行就是我们最好的老师,99% 的行业问题都能靠这三个字解决。 接下来咱说说作品自热的整体操作逻辑。好多人觉得要自己原创,其实不是。第一步,我们得看看同行最近有哪些爆款作品。记住这句话:火过的视频再发一次、再做一次,还能火。这里要强调啊,我们做自热作品,不是做那种很有个人特色的 IP 或者真人口播,就是把东西拼拼凑凑,很简单的。 做自热作品,就是要把简单有效的事情重复做、大量做。 找到爆款作品后,我们要对它进行去重,然后重新发布。要是你不会去重,网上搜搜简映课程或者视频制作课程。 作品发布之后,一定要在评论区做引导。可以找些小号或者兼职号,发一些跟你变现目的相关的内容。在行业里,这叫“鱼塘”,也就是带节奏,做和不做区别可大了。  重复发大量的作品去引流,这是作品自热很重要的操作逻辑。大家可以去快手、抖音上搜搜“创业笔记”这四个字。你会发现有好多账号,可能是一个团队做的,甚至可能是一个人做的。他们就是把赚钱的文字内容换个背景,重新剪辑一下,其实内容都一样,但每条流量都还不错,这就是简单有效、重复大量做的效果。 要是作品爆了,点赞、评论、留言、关注的数据都不错,那一定要做投流,趁热打铁,扩大战果。各个平台都希望你付费买流量,这样他们能赚钱。对你来说,作品数据已经被证实不错了再去推广,你和平台就是双赢。后面文章我会详细讲投流,大家可以关注我的公众号,别错过。 看完这篇文章,你只是懂了逻辑,还得去实践。实践中遇到问题,你才能去改进、去解决。 本文由 @流量破局 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
 全新《蓝精灵大电影》发布最新预告。蓝精灵村庄每日载歌载舞一片欢乐,直到蓝爸爸被格格巫绑架打破了平静,蓝妹妹带领蓝精灵勇闯现实世界,用魔法和智慧开启冒险。欧美音乐天后 Rihanna 蕾哈娜为主角蓝妹妹配音并担任制片人,还将为影片创作全新主题曲。 <内嵌内容,请前往机核查看> 配音阵容还有尼克·奥弗曼、娜塔莎·雷昂、丹·莱维、詹姆斯·柯登、汉娜·沃丁厄姆、吴珊卓、尼克·克罗尔、奥克塔维亚·斯宾瑟、库尔特·拉塞尔、约翰·古德曼等。克里斯·米勒执导,暂定7月18日北美上映。 
<blockquote><p>对于数据分析师来说,找到一套真正实用且系统化的数据分析方法,就像在茫茫数据海洋中找到了一座灯塔。本文从实际业务需求出发,详细解读如何在不同业务阶段运用恰当的数据分析方法。</p> </blockquote>  很多同学会困惑:到底什么才是数据分析方法?因为网上对于数据分析方法的描述,有些抄袭自营销学书本,比如4P、PEST;有些则抄袭自统计学书本,比如相关分析,回归分析。可真到做分析的时候就傻眼了:眼前的问题到底该P一下还是回归一下? 想真正理解&掌握数据分析方法,当然不能这样“拿着锤子找钉”。 工作中的数据分析,要紧密结合业务,服务业务需求。因此理解业务需求,围绕问题找答案,才能理解各种数据分析方法有什么用,该怎么用。 ## 6大类典型的业务需求 一个完整的业务活动,分为六个步骤:**了解现状→设定目标→制定计划→监控走势→诊断问题→复盘结果。**在每个阶段,业务掌握的信息,想解决的问题是不一样的,因此对数据的需求会不一样(如下图)。 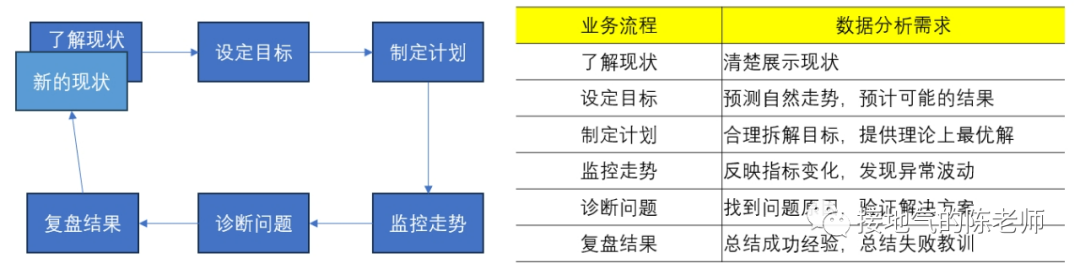 如果是从制定年度经营计划开始,数据分析师就参与到工作中,那么就会完整地经历这6个步骤。 但是,很多同学是中途入职/半道接手工作,最常见的是: - 从监控开始,先输出日常报表,再发现问题 - 直接接到一个分析任务,就XX问题输出报告 - 事情已经做完了,事后补一份复盘报告 这个时候,很有可能数据分析师对业务都不熟悉,匆忙赶鸭子上架,肯定毫无思路了。此时,至少得把第1步:了解业务现状补齐,然后再对症下药。 ## 了解现状的方法 了解现状阶段,更多是系统地呈现数据指标,让业务看清楚情况。数据指标体系本身有3种结构:**并列式、流程式、总分式。** 一些常见的分析方法与这三种形式对应。比如: - 杜邦分析法对应总分式指标体系。主要用于评估经营情况好坏,拆解财务指标,监控业务行动结果。 - UJM方法对应流程式指标体系。主要用于梳理用户行为路径(互联网企业使用的尤其多),看清楚用户转化方式。 - RFM方法对应并列式指标体系,主要用于对用户消费行为进行分类,区分高中低消费+待唤醒的紧急程度。 (如下图) 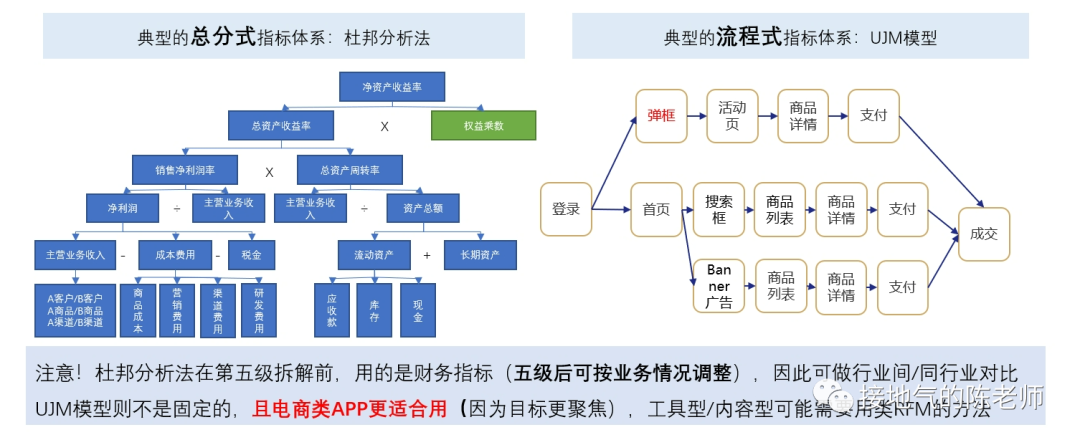 需要注意的是:单纯地展示指标并不能得出任何分析结论。至少**要展示指标+不同个体间进行对比。** 比如: - 杜邦分析法:两个同行业公司进行比较 - UJM方法:两个不同路径进行比较 - RFM方法:两类用户群体间比较 因此,在了解现状阶段,不要光想着罗列一大堆指标出来,而是思考下:到底选取谁进行对比,才能更好发现业务之间差异性,从而启发业务部门思考。 ## 设定目标的方法 在设定目标阶段,很有可能业务部门想了解: - 如果不做任何改变,自然情况下业务会发展成啥样? - 如果增加/减少某项资源投入,业务会发展成啥样? - 如果改变一种业务做法,业务会发展成啥样? 此时就涉及到预测问题。预测自然发展趋势,一般会运用到时间序列法,根据数据走势的不同,有平滑法、自回归、季节性回归、带季节趋势的回归等方法可用。如果考虑改变资源投入,可以考虑带因果关系回归。因为投入产出之间一般都有函数关系,可以通过数据拟合投入产出曲线,从而模拟调整结果。 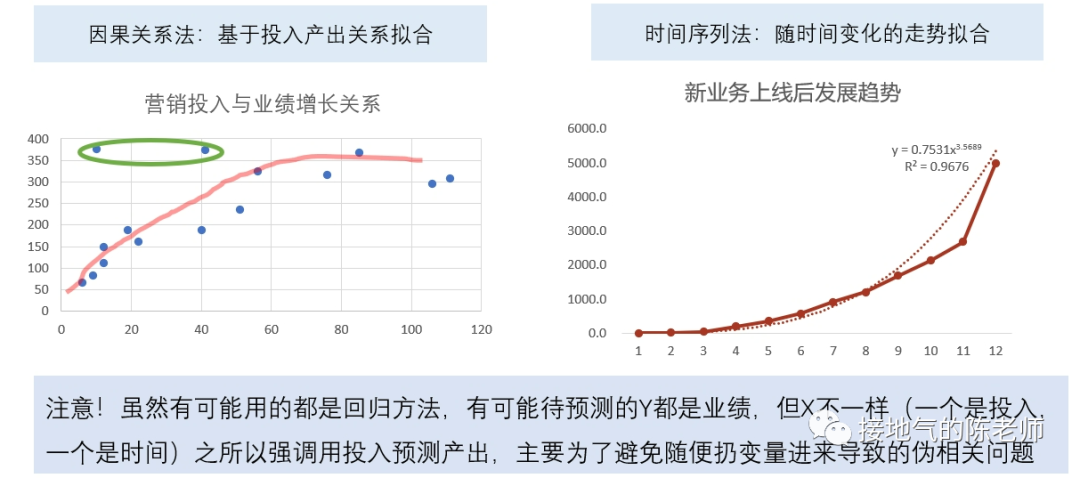 如果要改变业务做法,则要先看:业务是否有采取同类措施。如果已有同类做法,则可以参考同类做法的投入产出情况进行推算。如果连做都没做过,那就得先做测试,不然没数据就是空拍脑袋。 需要注意的是:设定目标很多时候要体现领导想法,数据本身只是参考。所以很有可能在做完自然情况预测后,业务部门就会开始拍脑袋了。此时可能不需要复杂的分析方法,而是利用数据指标体系,拆解KPI指标,之后根据领导们的要求增减相关,模拟可能的结果。 ## 制定计划的方法 在制定计划阶段,很有可能业务想把一个大目标拆解下去,落实到具体执行工作中。此时可以使用OGSM方法,这是一套标准的把定性目标落实为定量目标,把定量目标拆解为执行步骤,再监控执行的方法(如下图)。 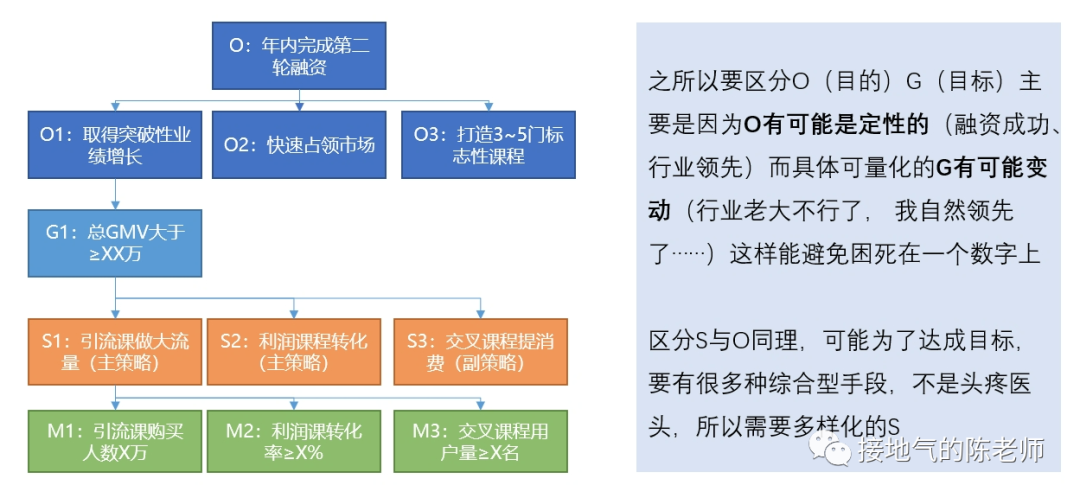 还有可能,业务想先不自己动手拆,而是看在现有投入产出水平下,理论最优解是什么。此时可以构建投入成本函数,利用本量利分析/线性规划方法,计算理论最优解,供业务参考(如下图)。 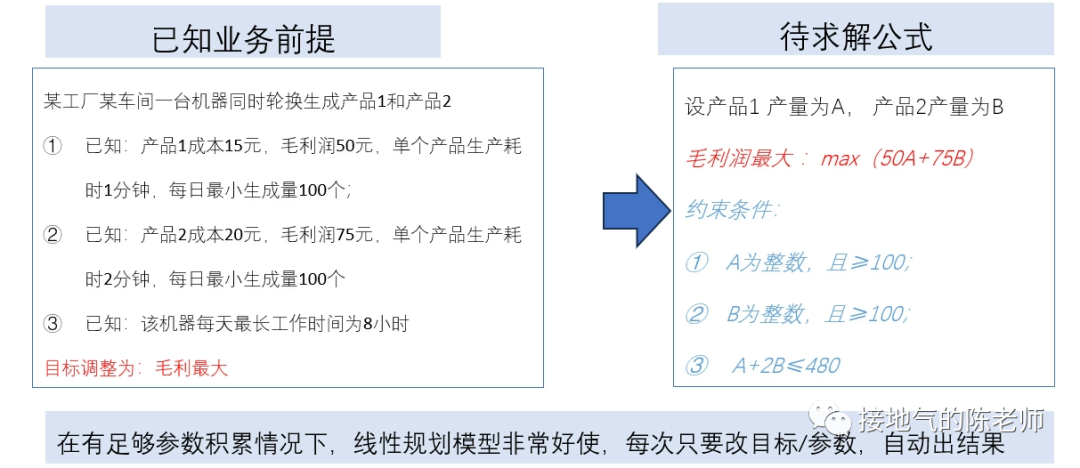 同目标设定一样,做计划的时候,很有可能业务完全凭经验,自己估摸一个数字就开干了。过于粗糙的计划,会导致:执行安排不合理、临时调来调去、缺少后备方案,这些都会导致执行过程的问题。 数据分析师如果能提前了解情况,就能在下一步监控走势的时候轻松很多。 ## 监控走势的方法 在监控走势阶段,核心任务是:观察业务是否在预期内发展,是否有异常波动。因此需要数据分析方法,判断业务是否正常。 此时有周期性分析法、投入产出分析、结构分析法、分层分析法、矩阵分析法五种方法可用。 - 周期性分析法,是根据业务特点,拆解出业务发展随季节变化/生命周期变化/投入产出变化而产生的规律。通过和常规走势对比发现问题。 - 投入产出分析,则是根据业务行动投入力度+过往数据经验,预判可能效果,如果排查:是否因本次业务执行不力,导致数据异常 - 结构分析、分层分析、矩阵分析,则是通过多个业务之间对比,发现被平均数掩盖的问题。还有些常见的说法,比如ABC分类、二八分类,其实都是分层分析的特殊形态(如下图) 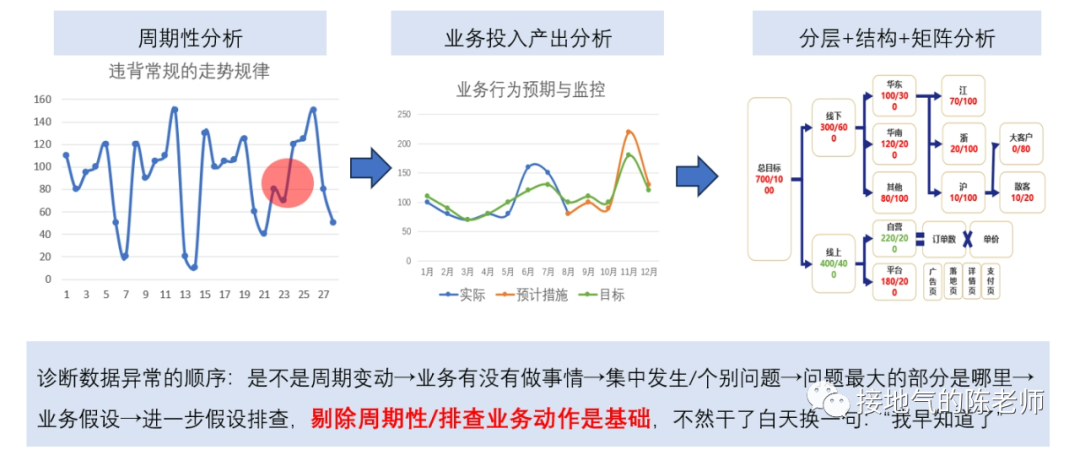 在监控走势的时候,这些常规方法,完全可以和监控指标做到一起,做成同一张监控数据看板,在观察到主指标异常以后,直接从总体到具体查看数据情况,看看是哪个部分出了问题,从而极大提高发现问题的效率。 ## 问题诊断的方法 在诊断问题过程中,是否有业务假设是最关键的。 - 如果业务啥都没有,那就只能构建分析逻辑树,层层排查问题 - 如果业务有一个明确假设,可以直接做排除法,验证假设是否成立 - 如果业务已经有应对方案,可以直接做实验,测试方案可行性 虽然一提起问题诊断,人们本能会想到:构建逻辑树。但构建完整的逻辑树太过费时费力,且很多假设需要收集外部数据检验,现实工作中不是时时刻刻都有这么充足的数据供应。因此诊断问题时,尽可能先找业务假设,快速输出结论。 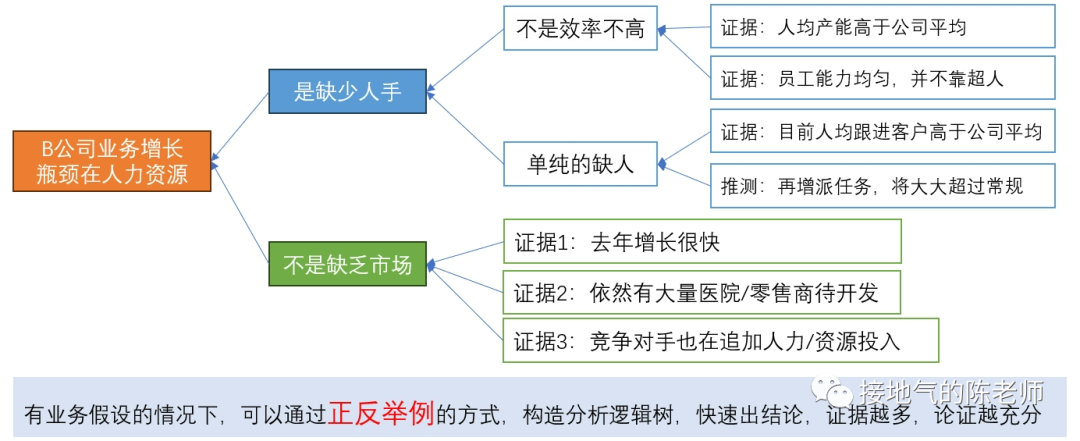 验证业务假设的时候,是否做实验是最关键的区别: - 如果完全不能做实验,那么只能通过标杆分析(对比好/坏个体),过程诊断(分析业务过程中最拉胯的环节)来输出分析结论。 - 如果能做实验,但不能做抽样测试,那么只能做改进前后对比分析。 - 如果能做实验,且能做抽样测试,那么可以采用统计学方法,检验实验效果。 ## 结果复盘的方法 如果前边5步做到位了,在结果复盘的时候就非常轻松: - 对比目标、实际差距,下判断:到底做得好不好 - 调取过程监控数据,看执行过程中是否有问题 - 调取问题诊断数据,看问题发生原因及处理的结果 这样综合各项结果的复盘是非常全面的,即包含了结果陈述,又包含了经验总结。 很多同学觉得复盘特别麻烦,是因为没有参与到全流程的工作中,活动结束了才被指派任务要复盘。此时一不了解目标,二不了解过程,自然得从头到尾梳理一遍才能出结果。如果碰上业务自己都没有设定清晰的目标,没有监控过程数据,那就更两眼一抹黑了。 本文由人人都是产品经理作者【接地气的陈老师】,微信公众号:【接地气的陈老师】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。

 极客公园
极客公园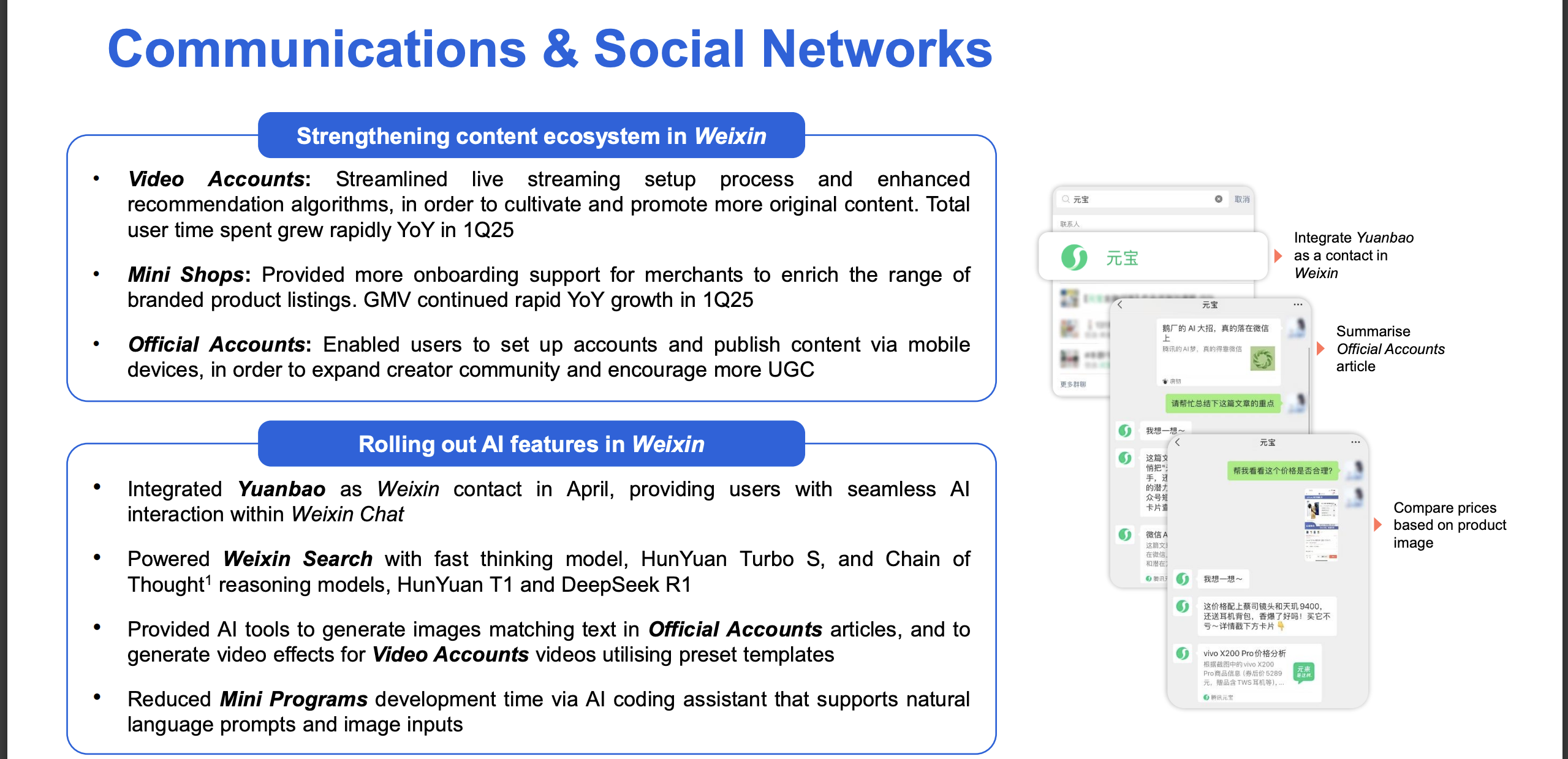
头图来源:腾讯 5月14日,腾讯发布2025年第一季度财报。一季度,腾讯实现营收1800.2亿元同比增长13%,毛利1004.9亿元同比增长20%,经营利润(Non-IFRS)693亿元同比增长18%;微信及WeChat合并月活跃账户数增至14.02亿。 毛利与利润增速双双跑赢营收,已是连续第十个季度,反映出腾讯在提质增效方面的长期定力和短期成效。 不仅如此,腾讯在AI基础设施和应用生态上的投入也显著提速:一季度资本开支同比激增91%至274.8亿元,研发投入达189.1亿元,同比增长21%。AI正成为撬动公司全业务系统进化的核心杠杆。 管理层在财报电话会上大篇幅谈及「Agent AI」,明确释放出公司在下一代AI形态上的战略意图:不仅要构建通用型智能助手,更要打造深度融合微信生态的「特有型Agent」,将社交关系、小程序体系与AI连接,形成腾讯独有的产品体验。 ## 1 AI布局走向深水区,Agent战略初露端倪 腾讯的AI战略进入深水区,从模型训练和通用问答的底层能力构建,逐步向产品与生态的深度融合迈进。 尽管财报未披露AI业务的具体营收数据,但管理层在电话会上大篇幅谈及Agent AI(代理式人工智能),释放出明确信号:腾讯正在推进一套更具长期想象力的AI路径。 腾讯董事会主席兼首席执行官马化腾在电话会上指出,目前AI Agent大致可以分为两类:一类是通用型Agent,另一类则是深度绑定微信生态的「特有型Agent」。 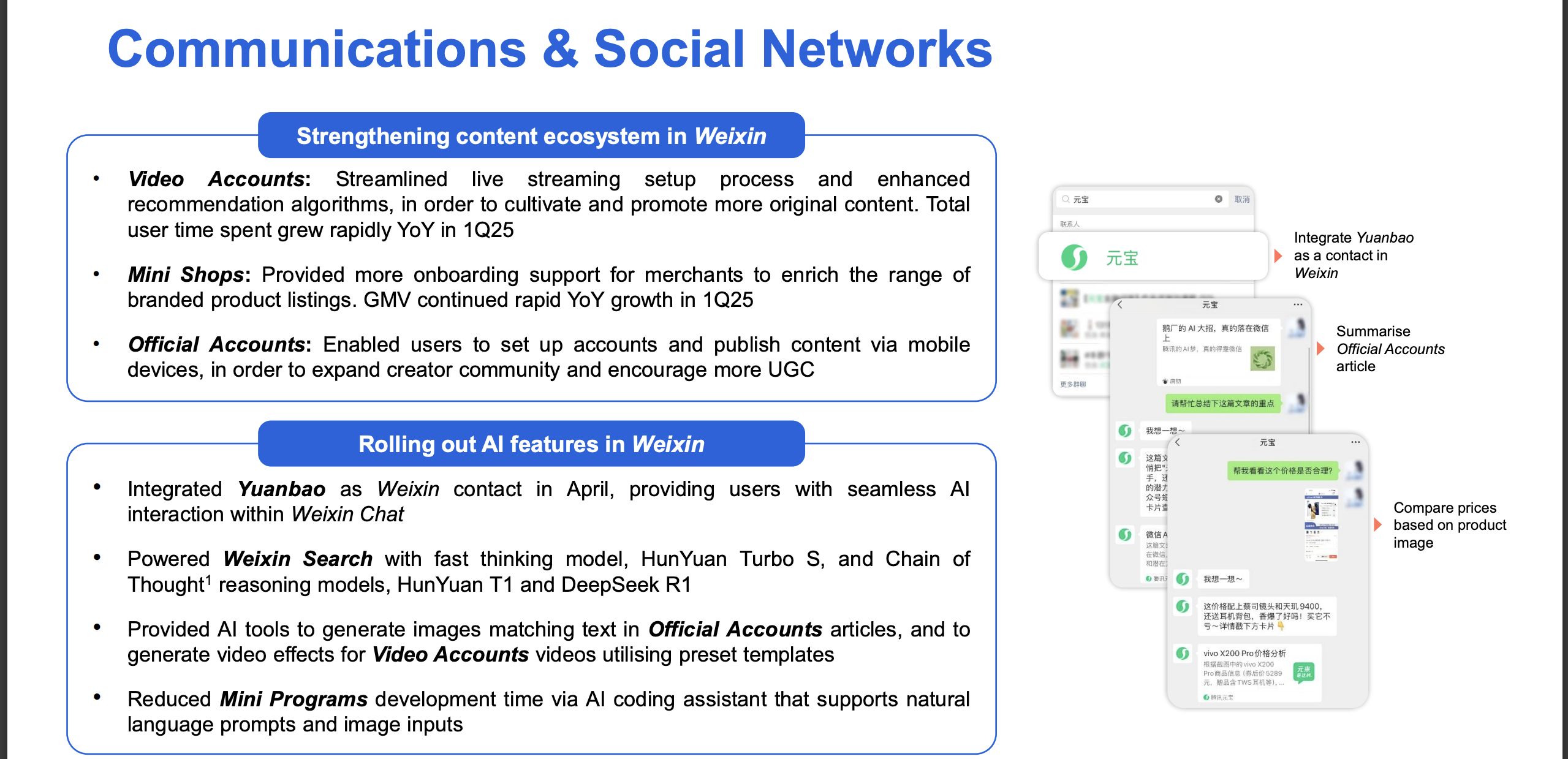 元宝已入驻微信|图片来源:腾讯财报 通用型Agent已开始在「元宝」「ima」等AI原生产品中落地,并正从简单问答逐步演进为具备复杂任务执行能力的助手——它们能够与其他程序或外部API打通,帮助用户完成实际操作。这一模式与行业内其他公司的Agent形态基本类似。 「特有型Agent」则依托微信的社交关系链、小程序体系和内容生态。马化腾谈到,「在微信生态系统中,我们有机会创建一个非常独特的Agent AI。它可以连接微信生态系统以及数百万个小程序。这些小程序涵盖了各种信息以及跨多个应用领域的交易和操作能力。因此,与更通用的Agent AI相比,这将是非常独特的,属于腾讯的一种差异化产品。」 目前,AI应用的发展重心目前仍集中在聊天交互,但未来形态正在悄然发生变化。腾讯总裁刘炽平表示,随着更多功能的上线,用户界面和交互方式将不再局限于传统的简单对话框。 「当我们尝试帮助用户完成更复杂的任务时,单纯的聊天界面已经难以满足需求,用户需要更长时间的深度参与,这就要求我们针对不同功能设计专属的使用场景和体验。」他强调。 目前,腾讯的元宝AI正处于扩展用户规模和提升用户活跃度的关键期。过去已证明,元宝能够留住用户,带给他们足够优质的体验,促使用户反复回访。下一步,将通过增加更多实用功能,激活现有用户的使用频次,同时吸引新用户加入。 更重要的是,腾讯将依托独特的社交、内容、小程序生态,尝试打造与传统AI聊天机器人截然不同的综合体验。与此同时,腾讯持续强化「混元」双模型架构,不断提升底层AI能力,为未来的多样化应用场景提供技术支撑。 这意味着,腾讯未来的AI不仅是「聊天工具」,而是一个多场景、多功能的智能助手,能够在社交、创作、工作等多领域实现无缝连接和高效支持。 与此同时,在底层资源层面,腾讯在芯片和算力方面也展现出更强的战略主动性。刘炽平透露,公司已提前储备大量高性能芯片,优先用于广告、内容推荐等具备短期ROI的应用场景,同时训练大模型仍是第二优先级。 刘炽平提到在过去几个月里,「我们摆脱了美国科技公司所谓的「扩展定律」,不再依赖不断扩展训练集群。现在我们发现,即使使用较小的集群,也能取得非常好的训练效果。训练后的优化潜力巨大,不一定需要非常大的集群。这让我们有信心,现有的高端芯片库存足以支持我们未来几代模型的训练。」 在推理阶段,腾讯也在通过软件优化、自研小模型、使用合规国产芯片等方式降低成本、扩展能力,这意味着腾讯的AI战略正在从「能力准备」向「规模化部署」过渡。 整体来看,腾讯的AI战略正在从「能力准备期」过渡到「部署执行期」,从通用AI走向更贴近实际需求的生态型AI。 ## 2「双轨并行」,AI 已开始在财务数据中「显形」 在C端市场,AI已全面渗透腾讯用户场景,呈现出「双轨并行」的态势。 原生AI产品元宝借助混元+DeepSeek双引擎驱动,用户规模显著增长;同时,腾讯的核心产品也纷纷借助AI技术升级,微信、QQ、腾讯文档、QQ浏览器、腾讯会议、理财通等产品已通过AI能力深度整合,智能化体验持续升级。 在微信生态内,AI应用正加速落地。搜索场景不再局限于关键词匹配,而是向「理解用户意图+生成深度内容」的复合型搜索体验演进;公众号与小程序引入 AI 助力,提高内容创作与服务开发效率;视频号算法不断优化,分发更精准、用户粘性更强,同时始终扎根在微信「熟人社交」土壤之上。 而在产业端,腾讯也正将 AI 能力系统化输出。腾讯将混元模型与自研算力、知识引擎打包为API和SDK向外输出,覆盖从零售、汽车到医疗等多个行业。典型案例如一汽丰田通过AI客服提升解决率至84%,大参林构建医药行业首个AI知识库,已经体现出大模型在企业端的实际应用价值。 从底层能力来看,腾讯 AI 也在持续进化。今年推出的深度思考模型T1和快思考基座模型Turbo S,在多项国际基准测试中取得优异成绩。同时,腾讯混元在生成式AI领域持续创新,图片、视频及3D生成模型迭代升级,最新版本 3D 模型在几何表现与建模精度上提升超过 10 倍。 而AI技术也为腾讯自身带来了实实在在的业绩回报。在广告业务中,腾讯基于AI优化的投放系统,让广告主与用户之间的匹配更精准,多个垂类行业(如电商、本地生活、互联网服务)投放意愿明显上升,推动一季度网络广告收入同比增长26%至265亿元。 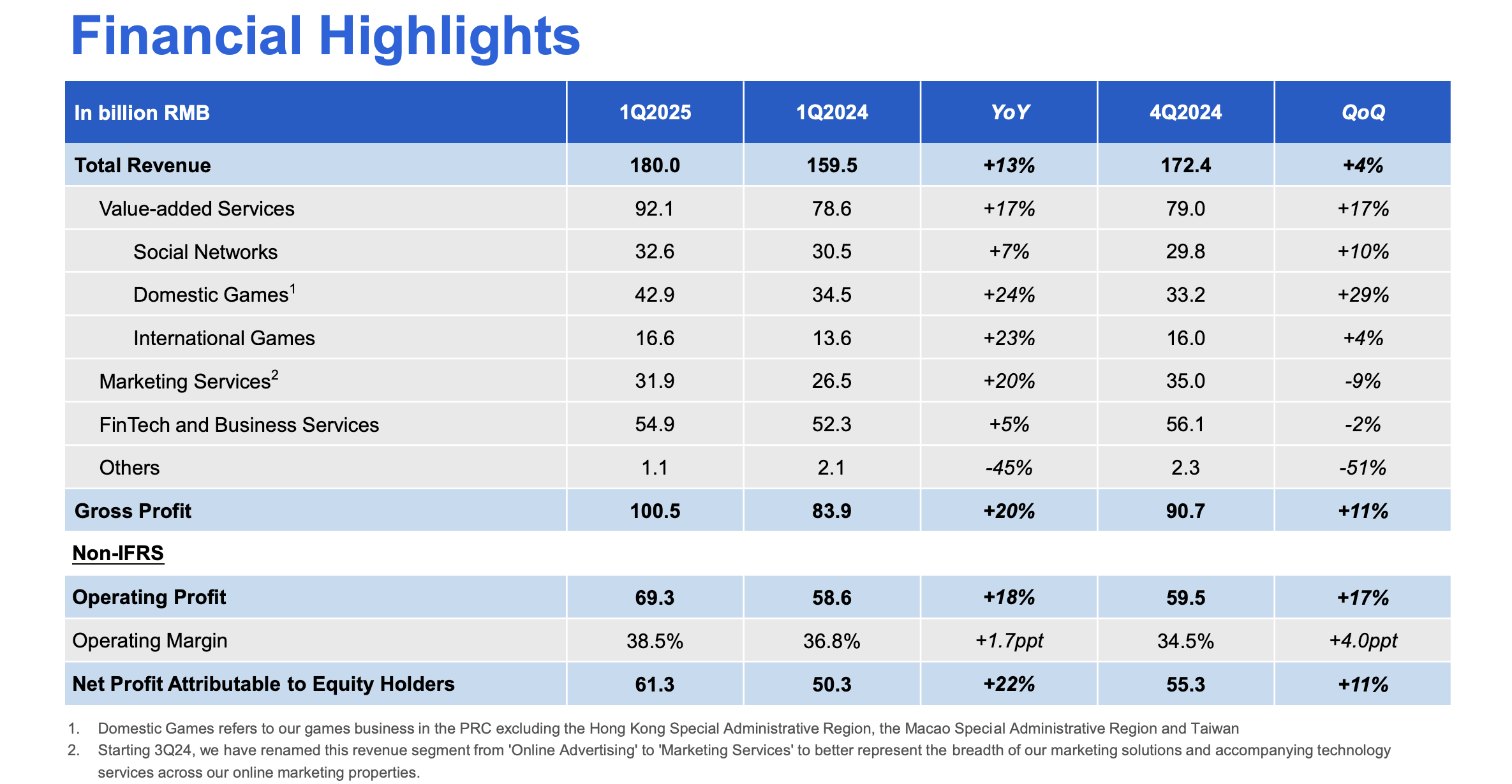 图片来源:腾讯财报 马化腾在财报中强调,「一季度,AI能力已经对效果广告与长青游戏等业务产生了实质性的贡献。我们正在加大对元宝与微信内 AI 功能的投入,相信高质量收入所形成的经营杠杆,有助于消化这些AI相关投入产生的额外成本,保持财务稳健。我们预期,这些战略性的AI投入将为用户与社会创造价值,并为我们产生长期、可观的增量回报。」 ## 3 游戏稳步推进,探索长期护城河 在大盘稳定、AI布局深化的同时,腾讯也没有放松对游戏这一长期业务线的打磨。 腾讯游戏业务在2025年一季度延续强劲势头,收入595亿元,同比增长24%,成为营收增长的重要支柱。 其中,本土市场收入429亿元,同比增长24%,国际市场收入同比增长23%至166亿元,连续三季度创历史新高。得益于「长青战略」深化和国际化布局提速,腾讯在全球游戏市场展现出强劲竞争力。 腾讯的「长青战略」在一季度再显威力。《王者荣耀》《和平精英》《穿越火线:枪战王者》等旗舰产品不仅稳住基本盘,还创下流水新高。以《王者荣耀》为例,春节期间推出的新版本内容引发热潮,Sensor Tower数据显示,1月收入同比增长94%,创近42个月最高纪录。《和平精英》则通过引入DeepSeek大模型,推出AI助手与队友功能,为玩家提供个性化指导和对局陪伴,QuestMobile统计显示其3月用户时长同比增长16%。  图片来源:《三角洲行动》官网 新游《三角洲行动》成为一季度黑马,平均日活跃账户数位列本土市场第六,是近三年国内游戏中DAU最高的新作。 FPS品类的崛起是背后推手,刘炽平在财报电话会上指出,中国玩家对FPS游戏的偏好已从过去的10%-20%市场占比跃升至与全球接轨的40%-50%。新模式「提取射击」在《三角洲行动》和《和平精英》中大获成功,吸引了大量年轻玩家,显著扩大了市场边界。 端游《无畏契约》同样火爆,一季度网吧热度排行射击品类第一,4月在线人数峰值突破200万,6月还将推出手游版《无畏契约:源能行动》,进一步拓宽用户群体。 国际市场方面,《PUBG MOBILE》《荒野乱斗》《部落冲突:皇室战争》表现抢眼,驱动收入增长提速。166亿元的国际收入已接近本土市场四成,显示出腾讯全球化布局的深远成效。储备新作如《异人之下》《沙丘:觉醒》蓄势待发,预示着国际市场的更大潜力。 生成式AI也在逐步介入游戏内容创作。腾讯正在尝试用AI提升内容型游戏的制作效率,探索中长期下的用户生成内容(UGC)潜力。 刘炽平坦言,AI在竞技游戏的应用尚处早期,但潜力巨大,未来可能实现动态内容生成,让游戏体验随玩家选择而变。这种前瞻性尝试,正为腾讯的长青战略注入新的生命力。 ## 4 新一轮「谨慎扩张」开始 一季度,腾讯资本开支达274.8亿元,同比增长91%,占营收15%;一般及行政开支同比增长36%至336亿元,此增长主要由于一笔40亿元的海外收购,以及为支持AI相关业务而增加的研发开支。 此外,腾讯在一季度加大了对元宝的推广,在部分营销投入增长被新游戏发布的广告开支减少所抵消的情况下,整体销售及市场开支增长4%至79亿元,占收入的百分比从去年同期的5%下降至4%。 回顾去年,腾讯全年资本开支达到了历史最高的767亿元。今年3月的财报电话会上,腾讯总裁刘炽平宣布将在2025年进一步增加资本支出,研发方面将继续投资于自研模型,并加速各业务集团AI应用的开发,同时也将加大市场营销投入,推动「元宝」的用户认知与使用转化。  图片来源:视觉中国 资本开支上升的另一面,是AI人才战略的持续升级。数据显示,截至一季度末,腾讯员工总数同比增长4627人,总人数达到109,414人,其中大部分增量来自技术岗位的扩张。 值得注意的是,在财报发布的前一天,微软WizardLM项目创建者徐灿在 X 平台上发文表示已经和团队离开微软,加入了腾讯混元(Hunyuan)大模型团队,「我们将继续我们的使命,推动大模型技术的发展,构建更强大的AI模型。」 这一消息在科技圈引发了广泛关注——WizardLM项目自成立以来,一直致力于高级大模型的研发,在自然语言处理(NLP)领域表现尤为亮眼。徐灿及其团队在微软期间,参与了多个AI项目,积累了丰富的实战经验和技术储备,这次转投腾讯,或许将为混元大模型注入新的活力。 而在更广阔的人才布局上,腾讯也在同步提速。此前在4月17日,腾讯宣布启动史上最大就业计划,三年内将新增 2.8万个实习岗位并加大转化录用,其中仅 2025年,就将迎来1万名校招实习生,其中约60%为技术岗位。 腾讯方面表示,随着大模型快速推进,腾讯加大了人工智能、大数据、云计算、游戏引擎、数字内容等技术类岗位的招聘力度,技术类岗位更是「扩招」力度空前。

Q1 saw "our high-quality revenue streams sustained their solid growth trajectory. AI capabilities already contributed tangibly to businesses, such as performance advertising and evergreen games," said Tencent CEO Pony Ma.




 CESA公布了东京游戏展2025(以下简称TGS2025)的预告视频、主视觉图及新Logo。 <内嵌内容,请前往机核查看>  今年的主视觉由以细腻画风与独特世界观备受瞩目的插画师「座敷童子」(ざしきわらし)操 刀。画师表示:“此次有幸以插画形式参与东京游戏展对我这个从小在游戏陪伴下成长的人来说,是莫大的荣幸。我以「玩不尽、无限的游乐场」为主题、倾注热情完成了创作。虽然这是首次尝试预告画的形式,但我在有限的画面信息中精心构图,希望能让观众感受到期待与兴奋。未来即将公开的主视觉图也请大家多多期待!我个人也对东京游戏展的到来充满期待!”  而TGS的Logo也将从今年迎来全面革新,新设计以时尚风格诠释了"汇聚进化的游戏体验 与次世代娱乐的全新TGS时代"。 TGS会场周边将设置采用新Logo设计的巨型主题纪念牌,自展会首日起即可作为绝佳拍照打卡点。欢迎以这一象征TGS全新"门面"的标志为背景,留下您的精彩瞬间!  (Logo纪念碑效果图) TGS2025展商目前正在招募中,截止时间为5月30日。本届TGS的举办时间为2025年9月25~28日(前2日为商务日,后2日为公众开放日),地点仍为幕张展览馆。

对于新季度财报,马化腾表示:AI能力已经对效果广告与长青游戏等业务产生了实质性的贡献。

