所有文章
 机核 · 单梦蛙
机核 · 单梦蛙 《生化危机》系列衍生手游《生化危机生存小队》举办了最新发布会,本作将于2025年内登陆移动平台,支持中文。  全程视频: <内嵌内容,请前往机核查看> 游戏的制作人为川田将央,游戏的时间线将从《生化危机2&3》开始,并逐渐发展为一个平行世界的剧情设定,另外本作的怪物设计将由天野喜孝担任。
 人人都是产品经理 · DesignLink
人人都是产品经理 · DesignLink
<blockquote><p>在数字化时代,表单作为用户与系统交互的重要桥梁,其验证机制直接影响用户体验与数据质量。本文深入探讨了表单实时验证的技术细节与行为模型,从验证触发机制、节奏与输入行为,到客户端与服务端的协同配合,全方位解析了如何打造高效、友好且安全的表单验证流程。通过科学策略与优化技巧,助力开发者提升用户满意度,确保数据准确性与系统安全性。</p> </blockquote>  ## 一、验证触发机制详解 实时验证,顾名思义,就是边填边检查。但“边填”到底是指什么时候呢?系统到底该在用户做什么操作时跳出来说话?这就是触发机制的问题。我们先来看看几个常见的触发点,它们虽然看起来只是一行事件绑定,其实背后都藏着不同的“沟通语境” onInput:这是最激进的方式,用户每输入一个字符就触发验证。这种方式容易让用户感到被监视,体验上非常打断式,如用户输入邮箱时刚打完一个字母就提示格式错误,会让人觉得添堵。 **案例**:用户想输入邮箱 james@example.com,刚打完 j 系统就提示“格式错误”……这不是在帮忙,是在添堵。 onChange:在用户每次改完输入框的内容时触发验证,节奏比 onInput 慢一些。搭配节流/防抖机制,如等用户停下输入 300 毫秒后再验证,既不会太打扰,又能保持反应迅速。 案例:帮助用户创建高安全性密码,实时反馈强度,避免提交后因密码太弱被驳回。 onBlur:用户离开输入框时才触发验证,不会边输边打扰,但反馈延迟较大,可能会错过及时提示的机会,如电商网站让用户输入手机号后按 Tab 跳到下一个字段才提示号码格式错误,会给用户带来不便。 **案例**:有些电商网站就喜欢 onBlur,你输入手机号,填完按 Tab 跳到下一个字段,系统才告诉你“号码格式错了”——这时候你已经开始填地址了,来回跳不累吗? onSubmit:所有字段在用户点击“提交”时一起验证,属于事后型处理,体验上类似于“你都交卷了才告诉你填错了名字”,无法及时发现并纠正错误。 <blockquote><p>患者在线提交预约表单,比如填写了姓名、身份证号、手机号、症状描述、预约科室、就诊时间。点击提交后,系统瞬间完成验证:例如身份证号格式、手机号有效性验证、症状描述是否≥20字…</p></blockquote> **触发机制的选择并非单纯的技术问题,而是人机沟通策略。不同的用户有不同的输入习惯和需求,如打字飞快的用户可能会觉得onInput太唠叨,新手用户可能会觉得onBlur太迟钝。因此,一个聪明的验证机制往往是混合策略加上防抖优化,懂得在合适的时机“说话”或“闭嘴”。** ## 二、验证节奏与输入行为 ### 2.1 用户输入节奏 用户打字是有速度和停顿节奏的,而反馈系统如果“插话”节奏不对,就会打断用户认知流程。用户输入节奏呈“波浪型”,有些字段是连续输入节奏快,有些字段需要思考中间有停顿,还有些字段习惯输完直接按 Tab 跳下一项。这些行为决定了验证系统不该“一刀切”,而应根据字段类型、用户行为自动调整反馈时机。 用户打字节奏呈“波浪型”: - 有些字段是连续输入(如手机号),节奏很快; - 有些字段需要思考(如密码、地址),中间会有停顿; - 有些字段习惯输完直接按Tab跳下一项。 这些行为决定了验证系统不该“一刀切”,而应根据字段类型、用户行为自动调整反馈时机。 ### 2.2 可接受的反馈延迟范围 研究表明,反馈延迟控制在 200ms~800ms 是最合适的区间。少于 200ms 容易给人“边打边挑错”的压力,多于 800ms 用户可能已经在看别的字段,提示被忽略或觉得反应迟钝。 优秀的实时验证会结合用户输入节奏做防抖处理,如在用户停止输入 300ms 后再触发验证,这样既不打断输入节奏,又能及时给出反馈。原理是在频繁触发的事件中延迟执行函数,等待设定的时间间隔后执行最后一次触发的操作,若期间重复触发则重新计时。 典型应用如搜索框输入实时查询优化,避免每次输入都请求接口,以及表单提交按钮多次点击合并为一次有效操作。 - 少于200ms:容易给人“边打边挑错”的压力; - 多于800ms:用户已经在看别的字段,提示被忽略或觉得反应迟钝。 ### 2.3 合理做法 优秀的实时验证,一般会结合用户输入节奏做防抖处理(debounce)。比如在用户停止输入300ms后再触发验证,这样既不打断输入节奏,又能及时给出反馈。 原理:延迟执行函数,在频繁触发的事件(如输入、点击)中,等待设定的时间间隔后执行最后一次触发的操作。若期间重复触发则重新计时。 典型应用:搜索框输入实时查询优化,避免每次输入都请求接口。表单提交按钮多次点击合并为一次有效操作。 ## 三、客户端 vs 服务端 客户端验证和服务端验证,职责完全不同。客户端验证主要负责即时反馈和格式校验,如邮箱格式是否正确、密码长度是否足够、电话号是否为纯数字等,这部分验证轻巧快捷,适合边输边查,给用户一个“安全感预览”。而服务端验证则是安全兜底和数据校验,如用户名是否重复、邀请码是否合法、地址是否合法合规等,这些需要访问数据库、第三方接口甚至风控系统判断,只能由后端完成,是真正的“最终裁判”。 ### 一致性机制:双重验证是标配,不是多余 很多开发者一开始觉得“前端已经验证过了,后端就别重复了”。但真这样做,就等于机场安检只查了一次身份证——太冒险了。双重验证是标配,不是多余。客户端先排除格式错误,提高体验;服务端再兜底核查,确保数据安全。例如,注册账号时,前端提示用户名可用,但若两个用户几乎同时提交,服务端需再做“唯一性检查”来避免冲突,这就是双重验证的意义所在。 最稳妥的做法是: - 客户端先帮你排除格式错误,提高体验; - 服务端再兜底核查,确保数据安全。 **案例**:比如你注册一个账号,前端告诉你“用户名可用”,但你和另一个用户几乎同时提交,服务端就必须再做一遍“唯一性检查”来避免冲突。这就是双重验证的意义。 本文由 @ DesignLink 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自 Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
 钛媒体 · 三言科技
钛媒体 · 三言科技

<blockquote><p>WMS系统中,上架与补货也是仓库人员在日常工作中用的比较多的两个功能,为了大家更好理解上架与补货功能,现将WMS中上架与补货的区别做一个主题单独分享。</p> </blockquote>  ## 1.核心区别总结 **上架**:解决新到货物“放在哪里”的问题(入库流程)。 **补货**:解决已有库存“如何移动到需要的位置(通常是拣选区)”的问题(库内补货流程)。 ### 1.1. 上架 **定义**:将外部进入仓库的货物(如采购到货、退货、调拨入库等)放置到系统指定的存储位置(库位)的过程。 **目的**:将新接收到的货物(从供应商、生产线下线、退货等)从收货暂存区移动到仓库中合适的、长期的存储位置。完成货物的 “入库闭环”,确保新到货物被正确存储,为后续的拣货、盘点等操作提供基础。 **触发时机:** - 收货完成(验货、贴标等之后)。 - 系统根据预设规则(如商品属性、ABC分类、存储策略、库位状态、路径优化)计算并推荐最佳存储库位。 **起点**: 收货暂存区/码头。 **终点**:指定的存储库位(可能是储备区、拣选区、或二者合一的库位)。 **涉及货物**:新入库的、未在系统存储位上有记录的货物。 **本质**:入库流程的关键环节,是货物进入仓库存储状态的开始。 **系统关注点**:空间利用率最大化、货物属性匹配(如温度、危险品)、存储策略执行(如先进先出FIFO)、路径优化。 **简单说:上架是“新货入库,找个地方存起来”。** ### 1.2. 补货 **定义**:当拣货位(或前端存储位)的货物数量低于设定阈值时,从后端存储位(如整箱存储区)向拣货位补充货物的过程。 **目的**:将货物从储备存储区(通常是大容量、不易直接拣选的区域)移动到前端拣选区(或直接拣选库位),以确保拣选区的库存量足以满足即将到来的订单拣选需求,避免拣货时缺货。保障拣货位有足够库存,避免因缺货导致拣货中断,提高订单处理效率。 **触发时机:** - 基于触发点:拣选区库存低于预设的最小安全库存量或补货点。 - 基于波次:在生成大型拣货波次前,系统预测拣选区库存不足,提前触发补货。 - 基于任务:特定订单需要大量某种货物,拣选区库存不足。 **起点**:储备存储区。 **终点**:前端拣选区。 **涉及货物**:仓库内已有的、已上架存储在储备区的货物。 **本质**:库内库存转移,是订单履行流程的支撑环节,确保拣选高效顺畅。 **系统关注点**:库存水平监控、补货规则执行(触发点、补货量)、任务优先级、补货路径优化。 **简单说:补货是“库内移库,把大库的货搬到小库(拣选区)准备卖”。** ### 1.3. 关联与协同 - **上架是补货的前提:**只有先完成上架,货物进入存储区,后续才有补货的“货源”。 - **部分场景下,上架可直接补充拣货位:**例如新品预售,已产生销售订单,待新品入库后进行发货,上架时可以直接分配部分至拣货位,减少后续补货操作。 ## 2. 关键区别对比 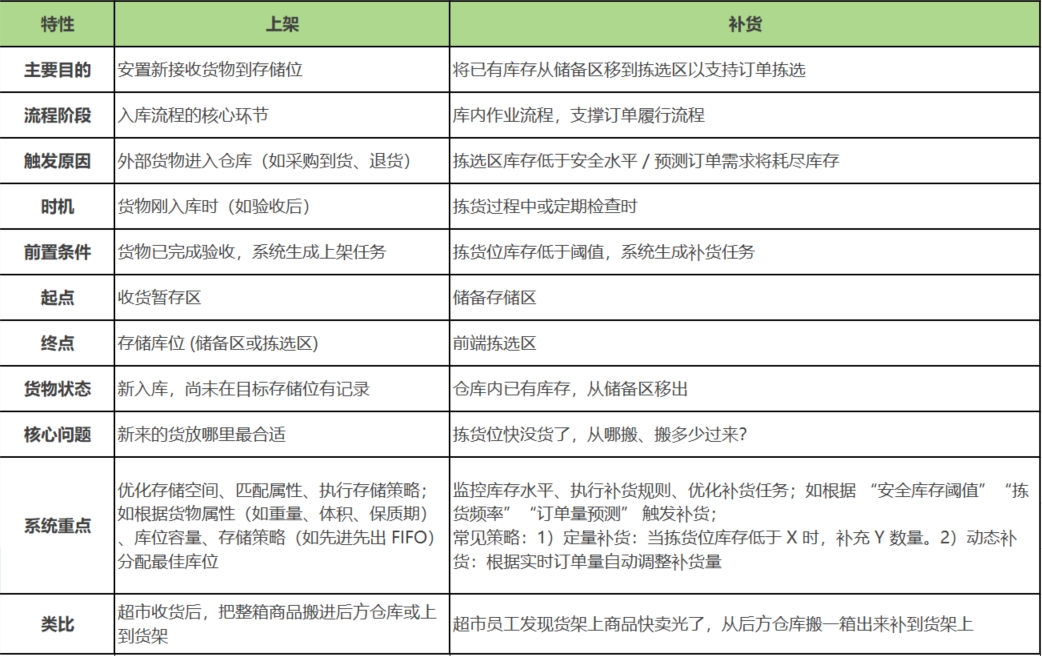 ## 3. 为什么需要区分 - **流程清晰:**明确不同操作的责任人和步骤。 - **系统逻辑**:WMS需要不同的规则引擎来驱动(上架规则vs补货规则)。 - **绩效衡量**:分别考核上架效率和补货及时性。 - **库存准确性:**正确的起点和终点记录对库存账务至关重要。上架错误影响基础库存位置;补货错误影响拣选效率和订单履行。 - **优化目标不同**:上架优化存储,补货优化订单履行。 ## 4. 总结 - **上架是入库的“终点”**:解决新货存放问题。 - **补货是拣货的“起点”**:确保有足够的货在正确的位置等待被拣走。 下篇文章继续为大家分享**上架与补货的具体功能及原型图**。 本文由 @刚哥 原创投稿或者授权发布于人人都是产品经理。未经许可,禁止转载。 题图来自 Unsplash,基于 CC0 协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
 cnBeta全文版
cnBeta全文版
Llama惨遭抛弃!**Meta**工程师透露,现在Meta内部开发都已经换掉了自家的Llama,**改用Claude Sonnet**写代码。不过,Llama 4自发布的那天开始确实是风评就没好过,先是发布36小时差评如潮,后来又陷入大模型竞技场刷榜风波。  现在连Meta内部都不用了,于是就有人开始怀疑,Llama 5真的还会有吗?  更何况,扎克伯格又新成立了**MSL**(Meta SuperIntelligence Labs),要与原本的GenAI团队**并行**开发下一代大模型。 Llama 5 or 其它?我们只能拭目以待了。 小扎:Llama-4.1和4.2正在开发 扎克伯格的MSL天团几乎组建完毕,这个团队将启动下一代模型的研究,并称争取在未来一年左右达到前沿水平。 不过,他们并没有透露下一代模型是否沿用Llama这个产品名,或许将进行品牌重塑。 虽然目前还不清楚会不会有Llama 5,但在小扎泄露的挖角备忘录中称,**Llama-4.1和4.2正在开发中**  然而,一位即将离职的Meta员工在一篇内部文章中尖锐批评了公司的文化缺陷,他认为这是阻碍LLaMA等项目成功的因素。 <blockquote>几乎没有人相信Meta的人工智能使命</blockquote> 这位员工认为Meta的生成式AI团队中充斥着恐惧文化、缺乏愿景和破坏性的竞争思维这些缺陷,甚至大多数团队成员并不在意AI使命。 尽管投入了数十亿美元并吸纳了很多杰出的成员,但他认为这些问题仍是项目成功的阻碍。 来自The Information 鉴于Meta在Llama产品上投入巨大,这次换掉自家的Llama,改用Claude Sonnet写代码相当于承认Llama的表现不佳。  尽管Meta会加大投入,加强下一代Llama的性能,但在此之前,它不想阻碍工程师们的工作效率,于是做出了更换决定。 据内部人员透露,自换成Claude以来,代码能力确实明显变得更好了。  实际上,Claude最新的一代的模型的写代码能力在目前确实处于一流水平。 不仅网友纷纷好评:  甚至连**苹果开发者**还用它写了几乎一整个MacOS应用程序,这个应用程序叫**Context**,是一款用于调试MCP服务器的开发者工具。  这位开发者称:在这个**20000行**代码的项目中,我亲手编写的代码估计**不到1000行** 不得不说,Claude还是有实力的。 据最新消息,Claude背后公司**Anthropic**的年化收入已达到**40亿**美元(月收入3.33亿美元),较年初增长近四倍,约占OpenAI 6月宣布的100亿美元的40%。 但同时,Claude用户仅占OpenAI的**1/25** 有人表示这样惊人的数据都是少部分开发者的贡献。  确实,Anthropic收入快速增长的动力之一就是其在今年2月推出的编程工具Claude Code。  One More Thing FAIR研究员朱泽园明确了**FAIR与GenAI、MSL的区别** <blockquote>FAIR ≠ GenAI or MSL</blockquote> FAIR是由**Yann LeCun**等人创立的小型世界级实验室,他们的工作是受好奇心驱动,利用公开数据开展长期的开放研究,并不训练产品级规模的大模型。 朱泽园强调,FAIR与GenAI、MSL在数据、代码、基础设施及计算集群上**完全独立**,GenAI/MSL的成功、失败或网络热梗,都不代表FAIR的工作情况。  同时,LeCun解读了研究、技术开发与产品开发的区别: - 产品开发的周期通常是3个月到1年。 - 技术开发的周期一般是1到2年。 - 研究的周期跨度为2到10年甚至更久。 而他从事的是研究工作,并表示: <blockquote>我关注的内容,往往比人工智能专家们当下痴迷的方向超前3-5年。</blockquote> [1]https://x.com/swyx/status/1943017429430604115 [2]https://x.com/kimmonismus/status/1943060343263236227 [3]https://x.com/Yampeleg/status/1942592878342963379 [4]https://x.com/ZeyuanAllenZhu/status/1942156231558488563 [查看评论](https://m.cnbeta.com.tw/comment/1512366.htm)

据汽车网站Electrek报道,美国总统特朗普已提名乔纳森·莫里森(Jonathan Morrison)出任美国国家公路交通安全管理局(NHTSA)局长。莫里森之前在NHTSA任职期间曾批评特斯拉,双方还发生过争执。  特朗普与马斯克关系恶化 在特斯拉CEO埃隆·马斯克(Elon Musk)与特朗普发生冲突的背景下,这项提名引人关注。下周,莫里森预计将参加参议院的任命确认听证会,不久后可能就正式履职。 莫里森是一位律师,曾在特朗普的第一任期内担任NHTSA首席法律顾问,并与特斯拉发生过几次争执。 2018年9月,NHTSA公布了针对特斯拉Model 3的碰撞测试结果,这款电动汽车在所有测试类别中都获得了五星安全评级。随后,特斯拉根据测试数据宣称,Model 3“是NHTSA测试过的所有车型中受伤概率最低的车型”。 对此,时任NHTSA首席法律顾问的莫里森向特斯拉发出了一封律师警告函,指责其说法具有误导性。NHTSA律师还传唤了特斯拉,要求其提供与2019年一起特定交通事故相关的数据资料。 马斯克近期一直在批评特朗普及其盟友刚刚通过的预算和税收法案。该法案预计将大幅增加联邦政府债务,几乎全面取消对电动车和可再生能源的补贴,冲击特斯拉业务。 特朗普则警告马斯克,他完全可以直接对其公司“动手”,而NHTSA将成为他对付特斯拉的首选工具。这些年来,NHTSA已对特斯拉展开多项调查,其中规模最大的一项针对的是特斯拉的完全自动驾驶(FSD)系统,以及多起与其高级辅助驾驶系统(ADAS)相关的致命车祸。 [查看评论](https://m.cnbeta.com.tw/comment/1512364.htm)

7月11日消息,彭博社发表评论称,**当下AI领域最贵的资产是什么?不是芯片,也不是数据中心,而是人。**据报道,为了一名资深员工,Meta不惜开出1亿美元的签约奖金。这场激进的“挖角”让OpenAI高管感觉“像家里遭了贼”,而最新的“战利品”,是刚刚从苹果跳槽至Meta的核心高管庞若鸣。  一个显而易见的事实是,**在美国科技巨头们夸耀招入麾下的众多“超级巨星”中,有大量华裔面孔。**包括庞若鸣在内,Meta超级智能实验室团队新招募的12名成员中,有8位毕业于中国大陆高校,之后才在海外开启职业生涯。**这意味着,全球AI竞赛的命门,已然攥在了“中国大脑”的手中。谁能赢得这批主力军,谁就可能赢得未来。** 本国人才为其地缘政治对手(美国)开发AI系统所扮演的超常角色,不太可能被中国方面忽视。 因此,美国决策者现在必须采取更多措施,吸引来自中国及其他地方最优秀、最聪明的人才,并创造一个他们可能留下来的环境,而不是一味打击移民。 但美国商界高管们不应想当然地认为,单靠高薪就能赢得这场国际人才竞赛。哈佛大学研究人员上月表示,从高影响力科学出版物的数量来看,中国在“人工智能原始人力资本”方面占据主导地位。尽管美国在算力和投资上占优,但**人力资本优势有助于推动中国本土的人工智能研究。顶尖人才或许也热衷于在海外赚钱,但他们当中的大批人还是会选择留在中国国内。** 今年5月,斯坦福大学的研究人员分析了DeepSeek论文上列出的200多位作者的数据。他们发现,这家公司的成功“本质上是一个本土人才的成功故事”。**DeepSeek一半的团队成员从未出国留学或工作,而那些出过国的人最终也选择回国投身于人工智能的研发**。这对于美国的政策具有启示意义。 斯坦福的报告指出,中国看待人才出国经历的视角,并非单纯视为人才流失,更多是将其视为他们获取知识后回国效力的途径。美国“可能错误地认为自己拥有永久性的人才优势”。 其他数据也佐证了美国作为顶级人工智能研究人员首选目的地的吸引力正在下降。在2022年,仅有42%的顶级人工智能研究人员在美工作,而2019年这一比例为59%。同期,中国正迅速缩小差距,占比从11%跃升至28%。 与此同时,作为产业政策的一部分,**中国一直在资助高校的人工智能实验室和研究项目。无论这项投资的回报如何,它都确实帮助孵化了人才,继而为企业的技术突破提供了有力支持。**例如,DeepSeek的一篇关键性论文就是由清华大学、北京大学和南京大学的学者共同撰写。通过这种方式,中国正在构建一个不依靠挖角个别明星人才的创新生态系统。 相比美国企业,中国本土企业在招募顶尖人才方面远没有那么财大气粗。一项分析显示,美国在人工智能领域的私人投资额几乎是中国的12倍。今年早些时候,有报道称DeepSeek的“高薪职位”年薪可达约154万元人民币。这在中国城市已属可观,但与硅谷动辄造就百万富翁的薪酬相比,仍相去甚远。 尽管如此,**DeepSeek正在积极招兵买马,其目的是吸引更多身处海外的中国人工智能研究者回国。**公司甚至在招聘平台LinkedIn上发布了大量职位。这不仅仅是钱的问题,更是为了让这些人才相信,他们的贡献“将在历史长卷中留下浓墨重彩的一笔”。DeepSeek或许希望,这样的愿景能打动那些思乡心切的中国人才。 归根结底,**全球将近一半的顶尖AI研究员来自中国,而来自美国的则为18%。许多人可能会到海外寻求机遇,但在美国并未释放出热情欢迎信号的当下,中国正力求说服至少一部分人才留在国内。**硅谷令人咋舌的签约奖金或许足以赢得一场跨国人才争夺战,但能否赢得长期博弈还有待时间来检验。 [查看评论](https://m.cnbeta.com.tw/comment/1512356.htm)

美国总统唐纳德·特朗普在Truth Social上发文称,将对美国从加拿大进口的商品征收35%的关税。该关税将于8月1日起生效。美国官员稍后称,特朗普势将维持对美墨加协定项下商品的关税豁免。 [](https://n.sinaimg.cn/tech/transform/96/w550h346/20250422/91a9-312fa053f02123c6dd5591defa2b1203.png) 特朗普周四在接受NBC News采访时表示,他还计划对多数贸易伙伴征收15%或20%的统一关税,并补充正在研究具体税率。目前的统一关税税率为10%。 上述措施表明特朗普并未收敛其标志性经济政策。他接受NBC采访时表示,尽管有对主要贸易伙伴提高关税的计划,但美国股市近期仍在上涨。 特朗普本周一直在向贸易伙伴发出公函,告知其若无法协商达成更优的条件,新关税将于8月1日生效。预计很快还将致函欧盟成员国。 [查看评论](https://m.cnbeta.com.tw/comment/1512354.htm)

据了解美国官员初步评估情况的人士透露,针对6月份印度航空(Air India)坠机事故的调查目前集中于这架飞机上的飞行员行为,目前尚未指向波音787梦想飞机(Dreamliner)存在问题。上述知情人士称,初步调查结果显示,控制这架飞机上两台发动机燃油流量的开关被关闭,导致飞机起飞后不久明显失去推力。 飞行员使用这些开关来启动和关闭飞机发动机,或在某些紧急情况下重置发动机。这些知情人士说,这些开关在飞行过程中通常是打开的,目前尚不清楚它们是如何或为何被关闭的。 这些知情人士还表示,目前还不清楚此举是意外还是故意,也不清楚是否有人试图重新打开这些开关。如果这些开关当时被关闭了,或许可以解释为什么飞机的应急发电机,即冲压空气涡轮(RAT),似乎在飞机坠入附近一所医科学生宿舍楼前的片刻启动了。 此次事故共造成260人死亡,其中包括该机上除一人外的所有人员。领导此次调查的印度航空事故调查局(Aircraft Accident Investigation Bureau)预计最早将于当地时间周五发布一份初步报告。  [查看评论](https://m.cnbeta.com.tw/comment/1512352.htm)

在海辰储能IPO的关键时刻,宁德时代以“不正当竞争纠纷”为由起诉了海辰储能。目前,该案件已由福建省宁德市中级人民法院已立案,将于8月12日开庭审理。海辰储能董事长吴祖钰再次成为被告。  文 | 《能见派》栏目 刘丽丽 《能见派》查阅有关资料发现,早在2023年的一起案件中,宁德时代的代理律师在法庭直指海辰储能创始人吴祖钰,称其“对宁德时代造成的损失早已不可估量。” 时隔两年后,宁德时代又起诉了吴祖钰。在业内人士看来,此次诉讼本质是第三代电芯知识产权之争。对此,接近海辰储能的人士对《能见派》表示,此次诉讼无关技术,也不会影响所谓的技术路线定义权,这次诉讼对海辰储能IPO没有太大影响,即使败诉,赔偿金对海辰储能的经营也不会构成实质性影响。 就有关问题,截至发稿时,宁德时代方面暂无官方回复。  **董事长再成被告,涉及重复起诉?** 这次宁德时代发起的不正当竞争纠纷诉讼,被告除了海辰储能,以及海辰储能董事长吴祖钰之外,被告方还包括厦门稀土材料研究所、珠海市海辰新能源技术有限公司、天津安洁环保科技有限公司、厦门诚博旺咨询管理有限公司、福建省宏桐建设工程有限公司。 被告名单中,有些名字似曾相识。 2023年11月,中国庭审公开网公示了一件涉及宁德时代的竞业限制纠纷案。案件原告是原宁德时代资深电芯系统工程师张敏,被告是宁德时代,诉讼请求是依法判决原告无需向被告支付违约金100万元。张敏2021年底从宁德时代离职,之后加入厦门稀土材料研究所,从事电化学储能与器件相关研究。2020年6月,厦门稀土材料研究所与海辰储能签约,为海辰储能提供引才、育才、研发等服务。 公开庭审录像显示,宁德时代拍摄到张敏曾多次佩戴海辰储能工牌进出海辰储能厂区,张敏被认为在厦门稀土材料研究所期间,实际上服务于海辰储能,违反了竞业限制义务,因此被宁德时代要求支付违约金100万元。 庭审过程中,宁德时代的代理律师还提到,海辰储能创始人吴祖钰“不仅自己违反竞业限制协议,还利用其在宁德时代的工作经验及人脉关系,大量挖角宁德时代的核心技术人才,两年迅速抢占储能市场,对宁德时代造成的损失早已不可估量,不是区区100万足以弥补的。” 这个案件开庭之前,海辰储能董事长吴祖钰已向宁德时代交了违约金——因违反竞业限制协议,2023年9月,仲裁委裁决吴祖钰向宁德时代支付100万元违约金。9月23日,吴祖钰通过其妻子林秀华向宁德时代支付了违约金。 海辰储能的核心管理层和宁德时代确有渊源。 招股书显示,吴祖钰于2011年8月至2015年12月担任宁德新能源科技有限公司的工程师,2016年1月至2019年2月担任宁德时代的工程师。有数据显示,2012年7月至2018年11月期间,吴祖钰在宁德时代作为第一发明人申请了多项专利,共有专利署名67项,涉及储能领域的集流体、极片及电池等。2018年吴祖钰还曾作为技术骨干成为宁德时代授予期权的195名中层管理人员之一。 2019年,吴祖钰从宁德时代离职,一年多后创业。目前,海辰储能高管团队中,执行董事兼副总经理庞文杰、执行董事兼副总经理易梓琦都有宁德时代的工作经历。 2023年已有裁决的案件,2025年被告吴祖钰再次出现在诉讼中,原告都是宁德时代,这是否违反了“禁止重复起诉”原则? 知识产权专业律师对《能见派》表示,虽然两个案件案情有关联,但一个是劳动争议,一个是侵权,不算重复起诉,而且这次的被告方也更多。 此外,厦门稀土材料研究所也被直接列为被告,综合各方面信息看,此次宁德时代发起的不正当竞争纠纷诉讼大概率仍将指向挖角行为。 **诉讼焦点:核心利益是电芯技术路线之争** 事实上,业内人士普遍认为,宁德时代和海辰储能两家当事企业,最在意的核心利益还是第三代电芯技术路线之争。 之前宁德时代也曾多次诉讼竞争对手,如蜂巢能源、中创新航等。外界有传言称,此次诉讼也涉及因技术路线相似性引发的知识产权之争。对此,接近海辰储能的人士对《能见派》表示,此次诉讼无关技术,也不会影响所谓的技术路线定义权。 法律专业人士分析,这次的诉讼是宁德时代以“不正当竞争纠纷”为由发起,在宁德市中院立案,应该不涉及技术秘密。因为根据《福建省高级人民法院关于调整第一审知识产权民事、行政案件管辖的公告》,发明专利、实用新型专利、植物新品种、集成电路布图设计、技术秘密、计算机软件的权属、侵权纠纷以及垄断纠纷第一审民事、行政案件由福州市、厦门市和泉州市中级人民法院分别集中管辖。而宁德中院只能受理一般知识产权案件。 宁德时代(587Ah电芯能量密度434Wh/L)与海辰储能(415Wh/L)的技术参数差异,实为“高成本高性能”vs“低成本长寿命”路线之争。 之前有传言称,海辰储能主打产品(如587Ah电芯)与宁德时代的产品技术参数高度重叠,能量密度偏差仅4.4%,远低于行业10%的技术代差红线。 对此,接近海辰储能的人士对《能见派》表示,所谓双方产品“参数高度重叠”与事实不符,在尺寸、能量密度、循环次数、商业策略等方面,海辰储能和宁德时代的三代电芯产品核心参数有本质差异。另外,储能电池需综合评估能量密度、循环寿命、安全性、成本等多维指标。仅以能量密度偏差推断技术重叠,违背产业常识。 上述人士指出,宁德时代587Ah的尺寸是73.05x274.6x218.1mm,海辰储能587Ah的尺寸是73.5x286.0x216.3mm;在能量密度方面,宁德时代587Ah的能量密度是434Wh/L,海辰的则是415Wh/L;循环次数方面,宁德时代是8000次,海辰是10000次。宁德时代的商业测量是优先能量密度,海辰的商业策略是优先可制造性和长寿命。 对于“10%的技术代差红线”,上述人士表示,属于主观杜撰,无任何权威依据。“经核查国际电工委员会(IEC)、国际标准化组织(IS0)、中国储能电池产业创新联盟等权威机构标准,以及彭博新能源财经(BNEF)、Wood Mackenzie等全球知名行业研究报告,储能电池领域从未定义“10%技术代差”量化标准。另外,技术代差需基于电化学体系、循环衰减机制、安全防护等级等复杂体系综合判定,非单一参数可概括。” **接近海辰储能人士:对IPO没有太大影响** 虽然此次诉讼表面上没有直接打专利官司,但三代电芯竞争正如火如荼。 业内人士对《能见派》表示,587电芯目前还没有定论,系统集成商也在观望,宁德时代和海辰储能确实是争夺定义权的对手,海辰储能是通过改造既有生产线去生产587电芯,成本会相对更低一些,目前还没有量产,计划今年下半年量产,宁德时代是在新建的济宁基地生产,目前已经宣布量产,双方都希望能抢先一步占领市场。 根据灼识咨询的资料,全球锂离子储能电池出货量将由2024年的314.7GWh增至2030年的1,451.3GWh,2024年至2030年的年复合增长率为29.0%。海辰储能正在为提高产能而战。招股书显示,海辰储能上市募集的资金将主要用于提升储能电池产能、拓展海外产能、研发、搭建全球销售服务网络等。 此次诉讼正值海辰港股IPO聆讯阶段,是否会干扰投资者信心,甚至直接影响IPO? 接近海辰储能的人士表示,这次诉讼对海辰储能IPO没有太大影响,对基石投资者也不会有太大影响,因为他们都是相对专业的。此前,宁德时代也曾有同类诉讼,多以和解或赔偿收场,比如蜂巢能源赔偿了500万元。如果海辰储能败诉,赔偿金对海辰储能的经营也不会构成实质性影响。 [查看评论](https://m.cnbeta.com.tw/comment/1512350.htm)
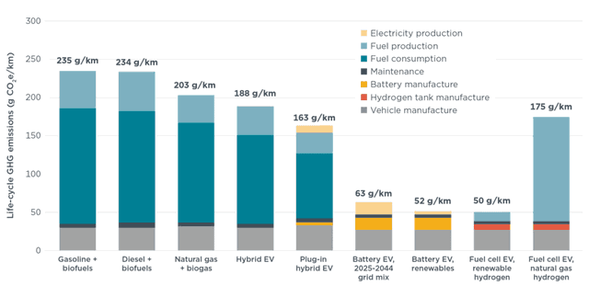
一直有一种论调(为这事网友各种抬杠),吐槽电动汽车不够环保(特别是生产锂电池环节),不过最新的研究狠狠的反驳了这样的说法。**国际清洁运输委员会(ICCT)发布的最新研究表明,欧洲市场上的电动汽车在整个生命周期中的温室气体排放量比传统燃油车低73%。** **更重要的是,上述数据涵盖了包括电池生产在内的所有制造和使用环节,远超此前的普遍预期。** 报告中指出,电动车初期制造阶段由于电池生产,碳足迹通常高于燃油车约40%。但研究显示,这种差距在行驶约17000公里后即可被抵消,相当于大多数车主一到两年的日常使用时间。 研究中还显示,在2025年至2044年期间,以欧盟预测电力结构运行的中型电动车,其平均碳排放约为每公里63克二氧化碳当量;而同级别燃油车则高达每公里约235克二氧化碳当量。这不仅包括尾气排放,还涵盖燃料生产和车辆制造等间接排放。 相较之下,混合动力车型表现不佳。普通油电混合汽车仅实现约20%的排放削减,插电式混合动力车型则为30%左右。 [](//img1.mydrivers.com/img/20250711/9dbc2923667847f88e8fbc3c879f7782.png) [查看评论](https://m.cnbeta.com.tw/comment/1512348.htm)

**三星Galaxy S26系列现身GSMA数据库,**该系列将在明年上半年登场。GSMA数据库显示,**三星Galaxy S26系列有3款机型,分别是Galaxy S26、Galaxy S26 Edge和Galaxy S26 Ultra,**其型号分别是SM-S942、SM-S947、SM-S948,**这意味着Galaxy S26+已被砍掉。** 这跟苹果的策略如出一辙,今年9月登场的iPhone 17系列不再推出Plus版本,取而代之的是iPhone 17 Air,主打超薄设计。三星也加入了超薄赛道,今年上半年开售的Galaxy S25 Edge便是一款超薄机型,与此同时,Plus系列产品线明年停更,Edge取而代之。 作为三星最强旗舰,Galaxy S26系列将首发鸡血版骁龙8 Elite 2移动平台,预计命名为“骁龙8 Elite 2 for Galaxy”,它在骁龙8 Elite 2的基础上再度提频,跑分和性能都将再创新高。 此前Galaxy S25系列便首发骁龙8 Elite鸡血版,型号是SM8750-AC,CPU主频高达4.47GHz,标准版骁龙8 Elite的CPU主频是4.32GHz(型号是SM8750-AB)。 [](//img1.mydrivers.com/img/20250711/9c44df1a284c4ed88dbe4ab2a4399330.png) [](//img1.mydrivers.com/img/20250711/a4ec589844184045b034e742f64e2743.png) [](//img1.mydrivers.com/img/20250711/e5994b3262c649ea9bdf6d7fa84edb2e.png) [查看评论](https://m.cnbeta.com.tw/comment/1512346.htm)
 Epic 游戏商城为玩家带来了最新的福利喜加一活动。即日起至7月17日晚11时,所有玩家均可免费领取《星空网球》《虚构世界2》。其中,《星空网球》是一款融合了街机时代两种经典游戏类型:射击与打砖块的游戏。在一个你无法攻击的世界里,用你的球拍击退敌人的子弹是你唯一的选择!将子弹弹回你的敌人并拯救银河系! [<《星空网球》免费领>](https://store.epicgames.com/zh-CN/p/sky-racket-4cf23a) [<《虚构世界2》免费领>](https://store.epicgames.com/zh-CN/p/figment2-creed-valley) 《虚构世界2》则是一款以人的思想为舞台的动作冒险游戏。噩梦在这片曾经平静的土地上肆虐,四处散布着混乱。和思想的勇气担当——Dusty 一起,解开谜题、加入音乐头目战、游历别具一格的场景。

<blockquote><p>未来趋势: 终极的“提示工程师”将是另一个AI。人类角色转变为“系统设计师”和“目标定义者”,AI负责探索和优化提示空间。</p> </blockquote>  手动设计和优化提示词是一个需要专业知识和反复试验的迭代过程,可能非常耗时 。为了应对这一挑战,一个更前沿的领域应运而生:**元提示(Meta-Prompting)**,将LLM本身用作优化器,用自然语言描述优化任务,大模型自动迭代生成和改进提示词。 ## 为什么要进行自动化提示词优化? **提升效率**:手动设计提示词劳动密集、耗时,AI优化提示词的效率和效果远超人类。能加大减少人力和时间成本。 **超越人类直觉**:LLM能够探索和发现人类可能想不到的、非直观但效果更优的提示词结构和措辞。 一个著名的例子是通过自动化方法发现的“Let’s think step-by-step”这一零样本思维链提示,其效果超越了许多人工设计的复杂提示 。 **系统化优化**:元提示将提示词设计从一门“手艺”转变为一个可以被算法驱动和系统化改进的“工程问题”,使得大规模优化提示词成为可能 。 ## 如何自动化设计提示词 对于产品经理和业务人员来说,虽然元提示的底层技术(如APE框架)可能很复杂,但其核心思想可以通过一种“与AI协作”的对话式工作流来实现。这意味着你从“提示词作者”转变为“提示词总监”,指导AI为你构建最佳工具。 以下是一个简单实用的方法: ### 第一步:清晰定义你的目标 像任何项目开始时一样,首先要明确你希望最终的提示词能完成什么任务。这个初始指令要简洁明了。 **示例**:“我需要一个生产级的提示词。它的功能是:扮演一名顶级的市场营销文案专家,为一款新的移动端笔记应用生成5个吸引人的广告标题。目标用户是大学生和年轻职场人。” ### 第二步:让AI生成初始版本的提示词 现在,你可以要求LLM为你草拟第一个版本的提示词。为了得到一个高质量的起点,你的指令应该包含对提示词本身的要求。 <blockquote><p><strong>示例元提示</strong>:“请基于我上面的目标,为我生成一个详细、结构化的生产级提示词。请在这个提示词中,使用<strong>角色提示(RolePrompting)和少样本(Few-shot)技巧。请使用Markdown</strong>格式来组织结构,包含明确的‘角色’、‘规则’、‘任务’和‘示例’部分。”</p></blockquote> ### 第三步:提供反馈,迭代优化 LLM会返回一个结构化的提示词草稿。现在你的工作是像评审原型一样,对这个草稿提出具体的、可执行的修改意见。通过对话,引导AI不断完善。 **示例迭代对话**: **你**:“这个初稿不错。但在‘规则’部分,请补充一条规则:‘标题必须包含一个强有力的动词’。另外,‘示例’部分只给了一个好例子,请再补充一个‘坏例子’,并解释为什么它不好,这样模型能更好地学习。” **AI**:(生成修改后的版本) **你**:“现在,我们来优化‘角色’定义。‘市场营销文案专家’有点宽泛。请把角色修改得更具体:‘你是一名专门为90、00后消费者撰写社交媒体广告文案的专家,风格风趣、用语新潮’。” **AI**:(再次生成更新版本) ### 第四步:测试并最终确定 将AI优化后的提示词投入实际测试,使用一些真实的输入数据来检验其输出效果。如果发现问题,可以继续回到第三步的反馈循环中,直到你对结果满意为止。 这个协作过程的背后逻辑是,它结合了人类和AI各自的优势: **人类(产品/业务经理)**:提供战略方向、业务背景、最终目标的定义以及对产出质量的最终评判标准。 **大型语言模型(LLM)**:基于其对语言模式的深刻理解,提供战术层面的实现,即具体的、最能有效引导其自身行为的措辞和结构 。 这种人机协同的方式,使得非技术人员也能够系统地、高效地创造出原本需要深厚技术背景才能设计的复杂提示词,是提示词工程领域一个重要的发展方向。 ## 彩蛋:自动化提示词模版 ### 1. 用于提示词评估和优化的模版 **用法:**用这个提示词创建一个简单的对话智能体,然后输入你起草的提示词,让大模型对你起草的提示词进行评分和调优  ### 2. 完美提示词生成模版 **用法:**用这个提示词创建一个简单的对话智能体,然后输入你的要求,让大模型根据你的要求直接设计提示词。 **注意:这个提示词很长,以下全文都是提示词内容**  本文由 @Mrs.Data 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
 《美洲卡车模拟》艾奥瓦州 DLC 于今日正式发售。 驾车穿越 I-80,前往州首府得梅因,以及密西西比河沿岸的其他城市。一路上,你将经过风景如画的乡村小镇,以及与蜿蜒的河流交织的古雅山丘。充分把握在鹰眼之州的旅程,享受每一刻:  - 驾驶卡车穿越12座城市,包括得梅因、锡达拉皮兹、迪比克、伯灵顿、艾奥瓦城,以及更多! - 探索精美重现的艾奥瓦州议会大厦、历史悠久的雪松廊桥、路中间的树、世界上最大的粮仓等地标。 - 运送货物至新的货场或从那运出 - 农业工厂和农业经销商。 - 参观我们在80号州际公路上建造的 ATS 最大的卡车停靠站!  - 成为将鹰眼之州的农产品运往美国各地的重要一员。 - 在旅途中探索超过15个优美的城镇(定居点),例如斯潘塞、克利尔莱克、戴尔斯维尔、奥斯卡卢萨、特雷尔! - 在铝厂接取和运送设备及货物,这是一个具有定制设计的资产的全新预制货场。 - 欣赏艾奥瓦州震撼的连绵起伏的山丘,以及梯田和风景如画的农场。  - 确保货物在艾奥瓦州的大型乙醇工厂货场不断进出流动,支撑其在美国乙醇生产中的领先地位。 - 探索艾奥瓦州的隐秘珍宝,发现隐藏的道路、观光点及更多内容! <内嵌内容,请前往机核查看>
 《远征:泥泞奔驰游戏》 第三季“冰雪海岸”内容更新现已上线。玩家再次踏上喀尔巴阡山之旅,年票持有者将解锁位于特兰西瓦尼亚高地的新地图、新卡车和更多专家角色。所有玩家现在都可以免费部署两款新型轮式无人机,并享受众多便利优化——包括为所有卡车提供的自定义涂装功能。 <内嵌内容,请前往机核查看> 在“冰雪海岸”中迎战春日融雪 随着春日气候渐暖,冰雪开始消融,新的地图将带你重返喀尔巴阡 — 探索特兰西瓦尼亚阿尔卑斯山脉,一同穿越泥泞的山坡、湿滑的河岸与幽深的洞穴,深入古老遗迹,展开科学考察。第三季还带来了三辆全新载具。灵活的 TUZ 302 Capricorn 适合前哨侦察,试验型 Haukka NS-420 可开辟全新越野路线,而强悍的 KRS 63 Pathfinder 能轻松穿越泥泞与融雪。为了协助你适应新区域,两位新专家角色将加入远征队伍:一位技师可减少无人机及附加组件的电力消耗;另一位经理人将帮助你在远征中获得更多资金收益。    新无人机与游戏优化,全体玩家可用 除了高级年票内容,第三季还为所有玩家带来了令人期待的免费内容,包括新工具、系统优化与多项便利改进。新增两款轮式无人机,以扩展玩家工具箱: - · 4-NCR 锚定无人机,可作为固定锚点以连接绞盘 - · SCT-6 侦察无人机,可为其他无人机建立网络覆盖区  在修复大量错误的同时,多项系统也进行了全面的优化升级。摩擦物理更加真实,雷达系统现需电力驱动,合作模式、共享进度及 UI 界面也得到全面优化,以提供更佳游戏体验。此外,现在你可为所有卡车自定义涂装,自由选择颜色、调整色调、亮度与饱和度,打造独一无二的外观。   《远征》第三季“冰雪海岸”现已登陆 PlayStation 5、PlayStation 4、Xbox Series X|S、Xbox One、Nintendo Switch 以及 PC 平台。欲了解更多详情,请前往 [Focus Together 内的补丁说明](https://community.focus-entmt.com/focus-entertainment/expeditions-a-mudrunner-game/blogs)。
 雷峰网
雷峰网**要闻提示** 1.去年中国销量仅1228辆!玛莎拉蒂新车降至30多万,门店回应:是真的! 2.罗马仕中层曝光问题充电宝内幕:公司完全以毛利为导向 3.刘艳钊现为长城汽车公关一号位,不再担任魏牌&坦克CEO 4.百川智能联合创始人谢剑将离职 5.网传7万硕士、30万本科生在美团送外卖,美团:没有事实依据 6.被沈腾问“为何先有车后有车标”?余承东笑答:这个问题挺尴尬,刚批准生效 7.黄仁勋计划再次访华!中国特供AI芯片曝光:最快9月推出 8.Grok-4系列模型已开放使用!马斯克:它几乎所有学科都比人类研究生聪明 **今日头条** **去年中国销量仅1228辆!玛莎拉蒂新车降至30多万,门店回应:是真的!** 曾经动辄百万的玛莎拉蒂,如今也放下身段“跳水促销”。近日,一则来自“上海浦东玛莎拉蒂”账号的海报引发震动:玛莎拉蒂SUV Grecale限时尊享价38.88万元起,相比官方65.08-103.88万的指导价,起售价直降超过26万!更有汽车平台显示上海经销商最低报价已杀到36.96万元,相比指导价降幅近43%,近乎“腰斩”。据悉,上海浦东玛莎拉蒂门店的销售人员确认了 38.88 万活动的真实性,但属于由经销商独立举办的包销行为,玛莎拉蒂品牌并未直接参与。 玛莎拉蒂大幅降价背后,是尴尬的销量情况。数据显示,玛莎拉蒂在华销量在2017年达到巅峰的1.44万辆后便一路滑坡。2024年销量仅1228辆,同比暴跌71%;今年前五个月累计销量更是低至384辆, 今年5月单月进口销量107辆。 据悉,2025年前五个月,宾利在华销量884辆,同比减少20%;劳斯莱斯在华销量289辆,同比减少23%;法拉利在华销量300辆,同比减少14%;兰博基尼在华销量157辆,同比减少39%;阿斯顿·马丁在华销量120辆,同比减少2%;迈凯伦在华销量虽同比增长111%,但仅有19辆。 而作为对比,小米YU7标准版售价25.35万元、小米YU7 Pro售价27.99万元、小米YU7 Max售价32.99万元。7月10日,小米汽车宣布,小米汽车上市15个月,交付已超过30万台。(快科技、电动内参)  **国内资讯****** **罗马仕中层曝光问题充电宝内幕:公司完全以毛利为导向** 7月10日消息,近日,充电宝行业一哥罗马仕轰然倒塌,广东商人雷桂斌用十年缔造出的商业传奇在短短几个月就停工停产了。多款产品爆燃、北京高校禁用、3C认证暂停,多个电商平台已经关闭,罗马仕的负面新闻如潮水般迅速淹没了其曾经积累的品牌声誉,让这个昔日巨头在行业浪潮中摇摇欲坠。 据媒体报道,近日,据一位罗马仕中层爆料:“现在出问题的产品,大部分都是几年前开发立项的,那时候老板深度参与公司,完全以毛利为导向。”他还透露,很早就隐约觉得安普瑞斯的电芯有问题,在其他厂商工作的同事告诉他,安普瑞斯产能有问题,因为产线是固定的,但是给出了超过产能的电芯数量。他表示,用安普瑞斯电芯的厂商,不止罗马仕一家。 他还称,在整个处理过程中,老板们都没有出现过,一直是下面的人跟大家沟通。老板态度太消极了,在危机公关的时候,“滚雪球”似的得罪了很多人,所以才出现了枪打出头鸟。(快科技) **刘艳钊现为长城汽车公关一号位,不再担任魏牌&坦克CEO** 雷峰网独家获悉,刘艳钊已升任长城汽车副总裁,主管公司传播中台,为长城汽车公关体系一号位,不再担任魏牌&坦克品牌CEO。目前,魏牌、坦克CEO分别由冯复之、常尧接任。刘艳钊是长城汽车内部培养的一名技术高管。2004年加入长城汽车后,刘艳钊曾负责哈弗皮卡及H3/H9等多款车型研发,并于2023年11月起统筹魏牌与坦克两个高端品牌的整体运营。 冯复之于2023年底加入长城汽车,担任副总裁,此前曾在小鹏汽车和理想汽车任职。据了解,魏牌品牌公司现已划入智选架构,由冯复之全面负责。而今年5月,冯复之以魏牌CEO身份亮相蓝山焕新版发布会,标志其已接手魏牌运营。坦克品牌现任CEO常尧,2005年本科毕业于约克大学,2022年任长城汽车用户运营高级总监,负责坦克品牌的用户运营工作;2024年4月,他升任坦克品牌副总经理,分管长城汽车的用户运营中台;2025年5月,常尧再度升任为坦克品牌CEO。 让具备To C经验的冯复之与常尧分别执掌魏牌与坦克,正是长城汽车近年持续推进To C战略的体现。作为该战略的核心承载品牌,魏牌与坦克承担着品牌转型落地的关键任务。自2024年5月起,长城汽车启动直营渠道建设,目前已开设超过400家直营门店,预计到2025年底将拓展至600家。一位内部员工向雷峰网透露,长城汽车推行直营模式,既希望提升销量,更重要的是借此推动品牌高端化。 本文作者长期关注整车品牌及供应链,对车企动态、智驾技术有兴趣的行业人士,欢迎添加作者微信 Hu**gh-wangruihao **交流讨论。 **百川智能联合创始人谢剑将离职** AI 科技评论独家获悉,百川智能技术联合创始人谢剑将离职。其离职原因尚未公开,下一步动向也暂无明确消息。 谢剑硕士毕业于武汉大学人工智能方向,2012年获得硕士学位后加入百度。在百度期间,谢剑深度参与并推动了凤巢广告、搜索、智能助手等核心 AI 业务的发展。2023年3月,谢剑与王小川共同创立百川智能,自公司成立之初便担任技术联合创始人。他所带领的团队已申请超过35项国内外专利,并在 AAAI、EMNLP、ICDM、ACL 等国际顶级 AI 会议上发表多篇论文,研究方向覆盖对话系统、预训练模型、推荐与搜索等核心技术领域。 此次谢剑的离开,也不过是百川智能近期高管动荡中的又一幕。商业化负责人洪涛早在 2023 年便已悄然离职。进入 2024 年 3 月,医疗业务负责人李施政与金融业务负责人邓江相继离开。据了解,李施政目前去向尚未披露,而邓江已经加入 AI 基础设施企业北电数智,担任行业副总裁。同月,联合创始人焦可也正式离开公司。另一位核心技术骨干陈炜鹏则于 3 月启动离职流程,筹备以 AI Coding 为核心方向的新项目。截至目前,创始团队中仅王小川与茹立云仍在公司任职。(AI 科技评论) 欢迎添加作者微信 **LIFACAI_888 **,一起交流更多信息。 **网传7万硕士、30万本科生在美团送外卖,美团:没有事实依据** 7月10日消息,针对网传“广州美团满员,历史上第一次,本科率接近30%”“7万硕士,30万本科生在美团送外卖”等消息,美团回应称,任何关于骑手学历的总量数据都没有事实依据,是为博流量而随意推理并传播的虚假信息。 据了解,此事源于短视频账号“丁X昭频道”。视频中,丁X昭自述今年39岁,2004年参加高考,是清华本科、北大与牛津双硕士、南洋理工大学博士,曾任新加坡国立大学博士后研究员,目前在送外卖。诸多名校光环与“骑手”身份形成反差,引发“丁X昭为什么送外卖”等高热话题。 对此,美团回应称,“关于学历信息,必须通过学信网、教育部留学服务中心以及海外高校等官方正规渠道才能查询到最准确的信息,小团无法查证丁X昭所说是否真实。”美团还表示,在丁X昭的视频爆火后,不少自媒体开始扩散“广州美团满员,历史上第一次,本科率接近30%”“7万硕士,30万本科生在美团送外卖”等不实信息。(快科技) **被沈腾问“为何先有车后有车标”?余承东笑答:这个问题挺尴尬,刚批准生效** 7月9日消息,“为什么我们先有车后有车标” ?在近日的享界品牌之夜上,享界体验馆沈腾的一句“灵魂发问”,逗笑了不少现场观众,也让余承东直呼“尴尬”。“这个问题问得挺尴尬呀”,余承东笑称,他随即解释道,我们本来是想(几个界)搞一个车标,但是国家政策不允许这么做,每个品牌要有独立的车标,但是车标从申请、批准到允许使用,项目周期相当长。其实华为早已经注册,然后转让给北汽,但是从批准到生效需要一个周期,所以到现在才出来。 7月8日晚,鸿蒙智行正式发布了享界汽车的车标LOGO,享界汽车的英文名字“STELATO”被放在了LOGO的正中央。针对享界S9新车标,享界体验馆沈腾评价称:“车标设计得也很好。一个是设计者的审美,还有一个是决策者的审美,双重审美加起来才能设计出来这好看的车标。”余承东则调侃道:“沈腾老师给我戴高帽子了。” 除了享界之外,鸿蒙智行兄弟品牌智界也公布了全新车标。智界产品总监海蓝天晒出车标样品,并且回复“车标免费送给老车主,正在加紧生产”。(快科技)  **小米全力攻克!曝玄戒自研5G基带有突破了** 7月10日消息,据博主数码闲聊站透露,小米新一代自研基带进展还不错,有突破。不过目前来看,下一代SoC还不确定是否能赶得上,玄戒O2是否能用上自研基带还存在悬念。 值得注意的是,前段时间小米联合创始人林斌曾经短暂晒了一张通话界面的截图,之后火速删除。很多人推测,这就是在测试小米玄戒5G基带,应该是取得了一些关键突破。 从目前玄戒O1的表现来看,其实整体完善度已经很高,性能上也足以立足第一梯队。只是还有两大遗憾,一方面是外挂基带导致的发热和续航等问题,虽然说通过优秀的CPU方案有所弥补,但是如果能补足这个部分,整体表现会更好。另一大遗憾就是SLC缓存缺失了,导致整体GPU表现低于目前主流第一梯队。如果玄戒O2能够补齐这两大遗憾,将真正的与高通、联发科、苹果站在同一水平线。(快科技)  **上汽大众南京工厂正式关闭!员工可获“N+1”补偿** 近日,据多家媒体报道,上汽大众南京工厂正式关闭。这座投产于2008年的工厂,曾是帕萨特和斯柯达速派的重要生产线。运营17年后,如今彻底谢幕。关停前,该厂年产能高达36万辆,属于上汽大众核心产能之一。这是上汽大众两年内关闭的第二座整车工厂。此前,上海安亭第一工厂也关闭了。企业回应称,基地调整属于正常经营决策,目的是顺应市场变化和公司战略转型。 据悉,上汽大众年销量自2019年起一路走低,2024年仅卖出114.89万辆,较巅峰期直接腰斩。加之南京工厂地处城市核心区,受限于土地、电力、智能化改造等资源瓶颈,已不适配新能源战略所需的“智电底座”。此次关厂,也涉及大量员工安置。据知情人士透露,公司提供了多种选项:年过50岁的员工可选择内退,每月拿85%基本工资;部分工人可调岗至其他基地,甚至有机会调往海外岗位,待遇不变;也可选择“N+1”补偿方案解除合同。 面对销量下滑与产能浪费的双重压力,上汽大众加快了电动化和智能化转型步伐。6月ID.3 GTX套件款上市,抢占纯电运动改装赛道;ID.ERA增程概念车亮相,目标2026年量产。上汽大众6月终端销量9.6万辆,同比增15.1%;前6月累计零售52.3万辆,逆势增2.3%。(电动内参) **广汽华望已规划两款新车,预计明年发布** 7月10日消息,据媒体报道,广汽集团与华为合作打造的华望汽车目前规划了两款车型,一款轿车与一款 SUV,动力形式包括纯电与增程,预计明年面世。两款新车的风格接近目前 20 万以上市场热度最高的品牌,但定位可能更高端,广汽曾披露华望主要面向 30 万级的市场。针对上述信息,华望汽车表示以此前官方发布信息为准。 广汽从 2017 年起就与华为建立合作关系,曾是第一批与华为开展 HI 模式合作的车企。去年起双方合作明显深化,先是官宣传祺新车将采用华为的鸿蒙座舱与乾崑智驾,又于去年 11 月签署智能汽车战略合作,随后广汽于今年 3 月成立华望公司,并表示是广汽与华为共同打造的项目。 由于华为车 BU 团队在华望项目里参与了整车定义、产品设计、研发及营销,也因此被看作近似于阿维塔的 HI PLUS 模式,“含华量” 接近鸿蒙智行 “五界”。据悉,广汽在华望项目上给予华为较大话语权,内部以尊重华为意见为工作原则,华望两款新车的内外饰、三电、智能化与底盘等都将带有华为的 “影子”。广汽集团董事长冯兴亚也曾公开表示,华望详细的产品定义、产品定位主要由华为主导,广汽支持、保持华望团队的决策权限,保证他们产品开发、产品定义的权利和责任。(晚点LatePost) **3倍罚款!未许可制售米哈游《原神》卡牌,侵权方被罚57万元** 7月10日,据米哈游法务部日前发文,国家市场监督管理总局公布了一批侵权假冒典型案例,其中“侵犯《原神》注册商标专用权卡牌案”入选。米哈游方面透露,侵权人方某某未经许可,组织设计、生产并销售侵权卡牌产品,非法使用“原神”“GENSHIN IMPACT”“枫原万叶”等注册商标。 自2023年6月起至案发,方某某共生产侵权卡牌4031盒,共计11.1万余包,通过电商平台销售,违法经营额达14.3万余元。 徐汇区市场监管局依法责令其停止侵权行为,并处以违法经营额3倍的罚款,共计42.9万余元。同时,上海某文化传播有限公司因为其设计侵权产品提供便利,被处以违法经营额1倍的罚款,达14.3万余元。(鞭牛士) **红果、快手发布违规短剧整治处理:百部短剧被拦截或下架** 7月10日,红果发布6月份违规内容治理公告。6月期间,红果短剧累计拦截下架《奶娃》、《婚易》、《妈***生》等违规微短剧153部,主要为审核阶段拦截未上线播放,部分为回查下架。 红果短剧方面表示,根据国家广播电视总局和北京市广播电视局的部署要求,平台持续加强微短剧内容和片名治理,从严打击含有不良价值观导向、违反公序良俗、低俗“擦边”以暴制暴等违规内容的微短剧。 同日,快手公布一则关于7月份违规微短剧的治理公告。公告内表示,近期,平台在审核及巡查中发现,有部分微短剧片名及内容低劣、情节雷人有害、价值导向偏差,并存在违规剧“换马甲”传播行为,破坏社区健康生态。依据网络视听管理相关要求及社区规则,平台累计前置拦截、整改、下架违规短剧百余部,处置违规账号70余个。同时,违规严重的剧目已上报至网络微短剧“黑名单”。(鞭牛士、新腕儿) **微信严厉打击外挂:朋友圈能看访客记录是假的** 7月10日,微信发布关于打击外挂相关违规行为的公告,并称所谓“定制V”等售卖及使用交流信息,以及“微信朋友圈能看访客记录”的教程都是虚假的。微信在公告中表示,平台持续打击非法使用外挂行为,进一步强化外挂营销信息治理,根据《腾讯微信软件许可及服务协议》《微信个人账号使用规范》等,平台将视违规程度对账号进行阶梯性处罚,如限制功能、封停等。 另外,微信方面还辟谣称,外部存在所谓“定制V”等售卖及使用交流信息,以及“微信朋友圈能看访客记录”的虚假教程,微信严厉打击各类外挂行为,为进一步维护用户合法权益,将持续进行外挂相关违规信息的巡查发现,不断强化对外挂行为的打击力度。(鞭牛士) 小米回应小折叠未搭载玄戒O1:立项之初规划总量比较有限 7月10日,小米回应了关于网友关注度较高的“小米MIX Flip 2为什么没上玄戒O1”问题。小米官方称:“玄戒O1作为玄戒的第一代SoC,主要是做技术验证,我们立项之初规划的总量比较有限,不能满足小折叠产品大规模量产的需求。” 据悉,这款小米自研的玄戒O1芯片仅搭载于小米15S Pro手机、小米平板7 Ultra、小米平板7S Pro等产品。 雷军此前曾表示,做玄戒O1的时候,小米完全没有想到O1做得这么好。“我真的没想到,所以整个O1的芯片总量定的就不够,规划是做了4款产品。”雷军还强调,特别感谢朱丹领军的整个芯片团队为小米做出的巨大贡献,我自己用的也是玄戒手机,体验特别好。(快科技) **国际资讯****** **黄仁勋计划再次访华!中国特供AI芯片曝光:最快9月推出** 7月10日消息,据外媒报道称,英伟达CEO黄仁勋(Jensen Huang)正计划再次访问中国,重申公司对中国市场的承诺,并计划与中国政府高级官员会面。有记者向商务部新闻发言人何咏前求证,其回应表示,目前没有可以提供的信息。 据悉,英伟达计划最快在今年9月推出专为中国市场设计的新型AI芯片。按照消息人士的说法,这款针对中国的特供芯片,是英伟达对现有Blackwell RTX Pro 6000处理器的版本进行了修改而来,为符合美国前总统特朗普政府加强的出口管制规定而特别设计。 据悉,该产品将被剥离掉一些最先进的技术,如高带宽内存(HBM)和NVLink。此前美国禁止对华出口H20特供芯片,这导致英伟达损失55亿美元并股价暴跌,不过全球人工智能快速发展的大背景下,英伟达显然是最大受益者,这也让公司股价重新走高,市值一举突破4万亿美元。 中国市场对英伟达的重要性不言而喻,之前的财报显示,中国贡献英伟达全球约20%的营收(2024年达171亿美元),但华为昇腾芯片、寒武纪等本土竞品快速崛起,替代威胁加剧。不知道恢复芯片供应后,会不会对华为等国产端产生冲击吗,而不少国内互联网大厂也都在等待这款英伟达新的定制芯片。(快科技、九派新闻) **Grok-4系列模型已开放使用!马斯克:它几乎所有学科都比人类研究生聪明** 7月10日消息,马斯克旗下xAI公司宣布推出最新的Grok-4系列AI模型。据马斯克介绍,该模型几乎在所有学科领域都比人类研究生更聪明。据悉,Grok-4能够进行超人级别的推理,并且在MMLU-Pro、LiveCodeBench等多项高难度基准测试上,实现了对现有顶尖模型的超越。下一步还将推出代码编写、多模态Agent、视频生成等多项能力。 发布会现场,马斯克与xAI研究人员展示了Grok-4的语音对话能力,相较于上代Grok-3模型对话速度快了2倍,端到端延迟更低,并且支持5种语音。据悉,新增的Grok角色Eve和Sal现在已经可以在iOS端Grok中使用。在更侧重于评估智能体在真实物理世界中复杂操作任务能力的Vending-Bench基准测试中,Grok-4较Claude Opus 4、Human、Gemini 2.5 Pro、o3等取得了更加出色的成绩。 据悉,Grok-4支持256K tokens的上下文窗口,目前已经开放使用,价格与Grok-3一致。(新浪科技) **TikTok正开发仅面向美国用户的独立应用?TikTok回应** TikTok发布公告称,外媒最近发布的一篇基于匿名、不知情信源的“独家”报道与事实不符。上述报道称,TikTok正在开发一款仅面向美国用户的独立应用程序,将“使用与全球版本不同的算法和数据系统”。TikTok没有在回应中做详细说明。 此前,有外媒报道称,TikTok正为美国用户开发一款新应用程序,并计划于9月5日在美国应用商店上线。根据目前的时间表,旧款应用将于2026年3月停止服务。TikTok的美国用户必须下载新应用才能继续使用其服务。 (界面新闻) **外卖大战打到了英国:速卖通英国站上线小时达服务** 7月10日消息,据英国媒体报道,阿里旗下的跨境电商平台速卖通AliExpress,本月起在英国推出“小时达”外卖服务。大伦敦地区的消费者打开AliExpress首页,就能看到“Hourly Delivery”的标志,配送的商品包括零食、饮料、厨房调料及日用品等。 据公开信息显示,AliExpress英国站从去年开始就在布局本地发货。目前Hourly Delivery主要由英国本土的Hungry Panda外卖公司提供,而Hungry Panda最擅长的正是餐饮配送。(新浪科技)  **曝三星自研GPU:AMD GPU将退场** 7月10日消息,博主定焦数码爆料,Exynos 2500是三星最后一款使用AMD GPU的Exynos芯片,下一代Exynos 2600将会首发搭载三星自研GPU,放弃与AMD共同开发的Xclipse GPU方案。 据悉,基于AMD RDNA架构打造的Xclipse GPU首次在Exynos 2200中亮相,Xclipse是由代表Exynos的X和eclipse(日食)组合而来,三星希望,Xclipse就像日食一样结束移动游戏的旧时代,同时标志着激动人心的新篇章的开始。基于高性能AMD RDNA 2架构打造的Xclipse GPU继承了以前仅在PC、笔记本电脑和游戏机上可用的硬件加速光线追踪和可变速率着色(VRS)等高级图形功能。 当时三星对Xclipse GPU寄予厚望,希望能跟高通公司的Adreno GPU进行正面竞争,但从Exynos的市场表现来看,三星似乎对双方的合作不太满意,从前年开始,三星内部开始自研GPU方案。按照计划,三星Exynos 2600将首发自研GPU,这颗芯片基于三星2nm工艺制程制造,是全球首款2nm芯片,预计由明年上半年的Galaxy S26系列首发搭载。(快科技)  **Intel以色列大规模裁员!甚至考虑关闭Fab 28晶圆厂** 7月10日消息,种种迹象表明,Intel又开始了新一轮大裁员,重点波及晶圆制造、汽车、市场营销三大业务部门。据最新报道,Intel在颇为倚重的以色列也开始了裁员,而此前Intel一直避免这么做,因为以色列政府给了Intel极大的支持。其中在Kiryat Gat地区的Fab 28晶圆厂,至少会有200人左右丢掉饭碗,包括中层管理人员、一线总监、远程运营中心技术人员等。 Intel目前在以色列一共有9000多名员工,Fab 28晶圆厂就有大约4000人。此番裁员后,Intel以色列员工将下降至8500人左右,也就是共裁员约500人。 2023年底,以色列政府承诺补贴Intel 32.5亿美元,用于在Fab 28晶圆厂旁边兴建一座新的Fab 38,但此计划已经在2024年中暂时搁浅。甚至有说法称,Intel正在考虑彻底关闭Fab 28晶圆厂,这简直有点难以想象,以色列方面肯定不会愿意。Intel发言人对此拒绝证实或否认,只是很官方地表示:“一如今年早些时候宣布的,我们正在努力成为一家更精简的、更快速的、更高效的公司。”(快科技) **转型最成功的传统车企:大众前六月累计交付441万台,新能源增长47%** 7月10日消息,2025年上半年,大众汽车集团在全球一共交付了441万辆新车,比去年同期增长了1.3%。虽然整体增幅不大,但新能源车型的表现却非常亮眼,纯电动车交付量达到46.55万辆,同比增长高达47%,在总销量中的占比也从去年同期的7%提升到了11%,可见大众在电动化转型上的投入开始逐渐见效。 在欧洲市场,大众的纯电动车销量同比增长了89%,稳居欧洲电动车市场第一的位置,在美国市场也实现了24%的增长,整体订单量同比增长约20%,其中纯电动车的订单增长超过60%。在中国市场,大众上半年共交付了131万辆新车,虽然同比小幅下降了2.3%,但在6月单月却实现了24.7万辆的销量,同比增长9%。 从品牌来看,大众汽车品牌(含捷达)上半年累计交付99.6万辆,同比增长1.1%,其中速腾和帕萨特继续领跑各自细分市场,6月单月销量达18.73万辆,同比增长15.1%,奥迪品牌在高端市场也稳居前三。大众表示,他们始终坚持盈利能力优先,不会为了市场份额而盲目降价。从2025年下半年开始,大众将在中国市场交付新一代智能网联汽车,包括纯电动的奥迪E5 Sportback、奥迪Q6L e-tron等车型。(快科技)


英特尔首席执行官似乎对公司近期的处境不太乐观,声称其已不再是顶尖的半导体公司之一,而且已经大幅下滑。毫无疑问,英特尔如今已远不如其作为芯片和科技行业顶级公司昔日的辉煌,在这之前,不仅被视为美国芯片行业的一颗明珠,而且该公司在计算机领域也拥有深厚的根基。 不幸的是,英特尔目前处境艰难,其新任首席执行官陈立武(Lip-Bu Tan)在与公司员工交谈时([通过 OregonLive](https://www.oregonlive.com/silicon-forest/2025/07/intels-ceo-we-are-not-in-the-top-10-of-leading-chip-companies.html))承认了这一点,并声称为了确保公司业务可持续发展,还有很多工作要做。 <blockquote><p>二三十年前,我们确实是领导者。现在我觉得世界已经变了。我们已不再是十大半导体公司之一。</p></blockquote>  简而言之,英特尔未能抓住人工智能的炒作机会,也未能在消费市场取得多大进展,最重要的是,代工部门未能达到预期。当这些损失累积起来时,公司就陷入了困境,不仅是运营亏损,还有大量客户流失到竞争对手手中。 陈立武意识到,维持现有的员工规模和战略并非良策,并决定进行彻底的变革。其中最重要的一项举措就是裁员,因为他认为“规模较小的英特尔行动速度更快”。除此之外,与前首席执行官基辛格一样,他也承认英特尔在人工智能领域难以有所作为,主要是因为竞争对手凭借其解决方案迅速占领了这一领域。我们将在英特尔看到的唯一的人工智能业务形式是边缘人工智能,它基本上是将人工智能功能集成到消费级处理器中。 陈立武强调18A工艺的外部应用范围有限,并表示他们正在评估18A工艺是否适合内部客户,然后再决定是否可以对外销售。目前,IFS与台积电竞争的希望基本破灭,如果14A最终成为一个乐观的项目,英特尔计划利用它增强竞争力。 [查看评论](https://m.cnbeta.com.tw/comment/1512332.htm)

Razer宣布推出一款全新游戏鼠标,售价 169.99 美元的DeathAdder V4 Pro 。这款广受欢迎的无线鼠标的全新版本承诺比其前代V3 Pro速度更快、更轻,而且更节能。  Razer 的新款鼠标看起来与之前的 V3 Pro 型号非常相似,但机身更轻,内部采用了新技术 V4 Pro 的左右键现在都采用了光学微动,额定点击次数可达 1 亿次。这也是雷蛇首款采用光学传感器而非机械滚轮的机型。雷蛇声称,光学滚轮传感器的精度更高,“即使在激烈的游戏环境下,也能提供三倍的耐用性和始终如一的触感控制”。 [](https://platform.theverge.com/wp-content/uploads/sites/2/2025/07/https___medias-p1.phoenix.razer_.com_sys-master-phoenix-images-container_haf_hb6_9931937021982_250710-deathadder-v4-pro-white-1500x1000-7.jpg?quality=90&strip=all&crop=0,0,100,100) 选择白色意味着您的鼠标重量将增加1g 得益于 HyperSpeed Wireless Gen 2 连接技术,新款 DeathAdder Pro 在无线和有线模式下均支持高达 8000Hz 的轮询率。然而,要达到雷蛇宣称的长达 150 小时的电池续航时间,您必须以低得多的 1000Hz 轮询率使用鼠标(公平地说,这仍然相当快)。 这款鼠标专为高手如云的电子竞技比赛而设计,其 45K 光学传感器支持高达 45000 DPI 的追踪精度。新款 DeathAdder 黑色版重量仅为 56 克,白色版则重 1 克。 承诺的规格令人印象深刻。但缺点是,DeathAdder 鼠标仍然采用非对称设计,不适合惯用右手的用户。此外,其略大的外形也迎合了手掌较大的用户,方便他们握持而不会感到不适。DeathAdder V4 Pro 现已在 Razer 官网开放预订,预计 7 月 24 日发货。 [查看评论](https://m.cnbeta.com.tw/comment/1512330.htm)
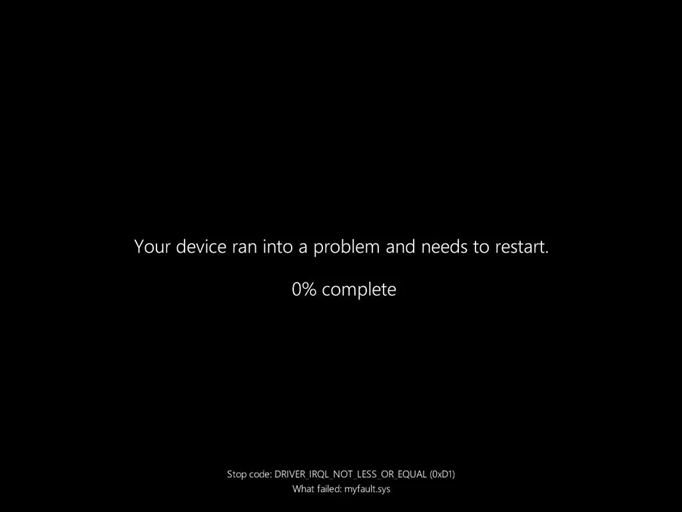
微软现在开始将其蓝屏死机 (BSOD) 更改为全新设计的黑色版本。这是自微软在 Windows 8 中添加悲伤表情以来对 BSOD 的首次重大更改,删除表情和二维码后转而采用更简化的黑色屏幕。 新的 BSOD现已向 Windows 11 Release Preview 用户推出,这意味着它将在几周内出现在所有 Windows 11 用户面前。简化的 BSOD 看起来很像您在 Windows 更新期间通常会看到的黑屏。  Windows 11 中新的死机黑屏 它会列出停止代码和故障系统驱动程序,方便 Windows 用户和 IT 管理员追溯电脑蓝屏死机 (BSOD) 的根源。“这实际上是为了更清晰地提供更准确的信息,让我们和客户能够真正了解问题的核心,以便更快地解决问题,”微软企业和操作系统安全副总裁 David Weston在 6 月份时表示。 微软在 2021 年 Windows 11 测试版中曾短暂地将 BSOD 改为黑屏,但这次是永久性的。BSOD 的改变是 Windows 11 更新的一部分,该更新还包含微软新的快速机器恢复(QMR) 功能,该功能旨在快速恢复无法正常启动的机器。QMR 是微软在去年 CrowdStrike 事件后为提高 Windows 弹性而采取的更大努力的一部分。 [查看评论](https://m.cnbeta.com.tw/comment/1512328.htm)

据 Yuri Bubliy(又名 1usmus,Hydra 调优软件和现已停产的 Ryzen DRAM 计算器的作者)称,AMD 正在向平台设计公司和原始设备制造商 (OEM) 等行业密切合作伙伴提供其基于“Zen 6”微架构的下一代 Ryzen 台式机处理器的样品。 Bubliy 又名 1usmus,是 Ryzen 专用 DRAM 计算器的开发者。他表示,AMD 将更新该处理器的电荷耦合器件 (CCD) 和客户端 I/O 芯片。 AMD 已确认正在台积电 N2(2 纳米)节点上构建“Zen 6”CCD,该节点已于今年早些时候进入风险生产阶段。预计该节点将于今年晚些时候准备好量产 2 纳米芯片。2 纳米节点的晶体管密度较目前的台积电 N4P 节点显著提升,AMD 的 8 核“Zen 5”CCD 正是基于该节点构建的。1usmus 和其他消息来源称,AMD 将利用该节点来增加每个 CCD 的 CPU 核心数量。  消息人士指出,AMD 可能会将每个 CCD 的核心数量增加到 12 个,并为 CCD 配备 48 MB 的 L3 缓存。目前我们尚不清楚所有 12 个核心是否会排列在一个 CCX 中,并配备 48 MB 的 L3 缓存;或者是否会采用双 CCX 布局,每个 CCX 包含 6 个核心,每个核心共享 24 MB 的 L3 缓存。 “Medusa Ridge”的另一项重大升级是其客户端 I/O 芯片 (cIOD)。AMD 预计将基于更新的 EUV 节点(例如 5 nm N5 或 4 nm N4P)构建其新一代 cIOD,这比目前的 6 nm N6 有了明显升级。  1usmus 表示,AMD 更新其 cIOD 的最大原因是内存控制器架构。AMD 预计将为“Medusa Point”配备全新的双内存控制器架构。每个插槽仍然有两个 DDR5 通道,但经过重新设计,以提高内存速度,使 AMD 能够在这方面赶上英特尔。至于 CPU 频率提升技术,例如 PBO 和 Curve Optimizer,预计不会有更新,1usmus 认为 Hydra 支持应该很简单。  [查看评论](https://m.cnbeta.com.tw/comment/1512326.htm)
去年12月,英特尔前首席执行官帕特·基辛格(Pat Gelsinger)结束了自己在这家半导体巨头40多年的职业生涯。许多人都对基辛格的下一步走向充满好奇。周四,这位英特尔前首席执行官透露了他的下一个篇章:努力确保人工智能模型能够支持人类的繁荣发展。   基辛格与他大约10年前首次投资的“信仰科技”公司Gloo合作,推出了一项新的基准——蓬勃发展的人工智能(Flourishing AI,简称FAI),以测试人工智能模型与某些人类价值观的契合程度。 FAI基准基于哈佛大学和贝勒大学主导的一项名为“全球蓬勃发展研究”(The Global Flourishing Study)的调查,旨在衡量全球人类的福祉。   Gloo 从研究中选取了六个核心类别——性格与美德、亲密社会关系、幸福与生活满意度、意义与目的、心理与身体健康、财务与物质稳定性——并增加了一个类别——信仰与精神,用于测试法大语言模型。 在[接受 The New Stack 采访](https://thenewstack.io/former-intel-ceos-new-ai-benchmark-focuses-on-human-flourishing/)时,基尔辛格表示,他“一生都生活在信仰与科技的交汇处”。 [查看评论](https://m.cnbeta.com.tw/comment/1512324.htm)
 极客公园
极客公园
 ## 乐道 L90 发布,三排 SUV,租电定价 19.39 万起 7 月 10 日,蔚来公司旗下品牌「乐道」发布了第二款车型乐道 L90。车长 5145mm、轴距 3110mm,比蔚来主品牌旗舰车型 ES8 还要再大一点,是目前蔚来集团里尺寸最大的一款车。  乐道 L90 没有小米 YU7 那样超级吸睛的外观,但李斌表示,得益于蔚来多年的技术积累,L90 可以解决传统三排 SUV 无法解决的痛点,将成为这个细分市场产品中的「变革者」。发布会上,李斌扮演了超级劳模的角色,单人演讲超过 160 分钟。 L90 定价 27.99 万元起,依托于蔚来的换电体系,这台车的起售门槛还可以进一步下探。如果采取电池租用方案购买,这辆车的起售价仅 19.39 万元,跌破 20 万元门槛。(来源:极客公园)  ## YouTube 将更新政策,打击 AI 批量生成低质内容牟利行为 7 月 10 日消息,YouTube 正准备更新其平台政策,进一步限制创作者通过「非真实」内容获取收益的能力。这类内容包括批量生成的视频和其他重复性内容,随着 AI 技术的发展,此类内容的制作门槛大幅降低,数量也迅速增长。  根据 YouTube 官方帮助页面的说明,新的政策将于 7 月 15 日正式生效,届时 YouTube 合作伙伴计划(YouTube Partner Program, YPP)的变现规则将加入更明确的内容规范,帮助创作者更清楚地了解哪些内容可以变现,哪些则不符合标准。 尽管具体的政策条文尚未公布,但 YouTube 强调,平台一直要求创作者上传「原创」且「真实」的内容。此次更新旨在帮助创作者更清晰地识别当前环境下何为「非真实」内容。(来源:搜狐科技) ## 蚂蚁国际计划把 Circle 的稳定币纳入其区块链平台 北京时间 7 月 10 日消息,据知情人士透露,蚂蚁集团正与 Circle Internet Group 合作,拟在蚂蚁区块链平台上采用其稳定币。知情人士表示,蚂蚁集团旗下的蚂蚁国际计划在 Circle 的稳定币 USDC 于美国合规后,将其纳入自己的区块链平台,但具体时间表尚未确定。 美国参议院 6 月份通过稳定币法案,为与美元挂钩的加密货币设立监管规则。这标志着稳定币越来越受到认可。今年 6 月份上市的 Circle 受益于种乐观情绪,也是少数几家自己发行稳定币的上市公司之一。今年 4 月,Circle 宣布将推出一个支付网络,帮助金融机构使用代币结算跨境交易。 据知情人士透露,蚂蚁去年处理了超过 1 万亿美元的全球交易,其中三分之一由其区块链处理。知情人士 6 月份时就表示,蚂蚁国际寻求在香港和新加坡申请稳定币牌照,还计划在卢森堡申请许可。(来源:新浪科技) ## 裁员 9000 人后微软高管表态:想留下,就得学会 AI 7 月 10 日消息,据 The Information 报道,在微软上周宣布将裁员 9000 人,启动今年第二次大规模裁员后,该公司便要求剩余的销售人员借助人工智能提高工作效率。 据与会者透露,微软美洲地区中小企业销售业务主管特拉维斯·沃尔特(Travis Walter)在周一的员工会议上表示:「我们都需要使用 AI 工具。」 沃尔特向员工推荐了微软内部的人工智能工具,旨在帮助销售人员更快地掌握客户账户信息,并自动生成销售方案。他强调:「这是投资自身学习 AI 技能的绝佳机会。」 尽管微软高层的这番表态并不令人意外,但也再次提醒我们,随着越来越多的企业加速拥抱 AI 工具,白领工作正迅速发生改变。(来源:IT 之家)  ## AI 机器人自主完成复杂胆囊切除手术,准确率 100% 7 月 10 日消息,美国约翰·霍普金斯大学研究人员称,他们训练出一个能利用人工智能自主完成胆囊切除手术的机器人。这标志着人类向自动化医疗迈出一大步。这一系统不仅能完成特定手术任务,更能「理解」手术流程,具备自主决策和应变能力。 研究团队将该机器人系统命名为 SRT-H,并通过一种名为「语言引导模仿学习」的人工智能框架进行训练。尽管 SRT-H 在手术中实现了 100% 的准确率,但其完成手术所需的时间仍略长于人类外科医生。研究人员指出,随着技术的进一步优化,这一差距有望缩小。(来源:新浪科技) ## 罗马仕中层曝问题充电宝内幕:完全以毛利为导向 7 月 10 日消息,罗马仕 6 月 18 日宣布召回近 50 万台移动电源,引发关于自燃风险充电宝的热议,该公司也在 7 月 7 日停工停产,多个电商平台店铺关门。  据报道,一位来自罗马仕的中层透露,现在出问题的产品,大部分都是几年前开发立项的,那时候老板深度参与公司,完全以毛利为导向。他表示,「其实,我很早就隐约觉得安普瑞斯的电芯有问题,我在其他厂商工作的同事告诉我,安普瑞斯产能有问题,因为产线是固定的,但是给出了超过产能的电芯数量。」 目前,罗马仕在京东、淘宝、拼多多的官方旗舰店均已关闭。此外,罗马仕京东自营旗舰店也已经下架了所有充电宝产品,仅剩下数据线、充电头品类在售。(来源:IT 之家) ## 谷歌 Gemini 接入 Veo 3 AI 模型:可将照片转换为带音频的视频 7 月 10 日消息,谷歌今天在 Gemini 应用中上线了基于 Veo 3 模型的图像转视频功能,用户可以将照片变成带有背景音效、环境声、语音的 8 秒钟短视频。 谷歌表示,这项视频功能现已在部分地区向 AI Ultra 和 AI Pro 用户开放,今起先在网页版推出,移动端将在本周逐步上线。 使用时,Gemini 用户只需点击提示栏的「工具」,选择「视频」,上传照片并添加提示词,描述希望照片如何动起来。用户还可以加入对白、音效或环境声等音频描述,谷歌表示音频和画面会实现「完美同步」。最终视频为 720p、16:9 横屏的 MP4 格式。(来源:IT 之家)  ## 主推亮蓝色,苹果最薄 iPhone 17 Air 四种颜色曝光 7 月 10 日消息,科技博客 majinbuofficial 发文曝料称,苹果正研发 iPhone 17 Air,以超薄设计重新定义 iPhone 产品线,并可能提供四种颜色选项。  据介绍,iPhone 17 Air 可能会包含以下 4 种颜色:黑色、银色、亮金色、亮蓝色。其中亮蓝色非常浅,与苹果之前推出的蓝色有所不同,呈现出一种柔和的色调。这种颜色清新现代,令人联想到晴朗的天空,完美地衬托了 iPhone 17 Air 的极简设计,与 MacBook Air M4 的「天蓝色」相似。 该博文还表示苹果将重点推广亮蓝色,将其作为 iPhone 17 Air 的标志性颜色。(来源:IT 之家) ## 传 OpenAI 入局浏览器,围绕 AI 构建独特体验 北京时间 7 月 10 日消息,据路透社报道,OpenAI 正计划推出一款浏览器产品,通过各项专属 AI 功能,从而挑战谷歌 Chrome 浏览器的市场主导地位。 据报道,这款浏览器目前已初具雏形,OpenAI 计划在未来几周内推出。在界面上,该浏览器不再采用点击进入网站的传统方式,而是将部分用户交互保留在一个类似 ChatGPT 的原生聊天界面中,但目前尚不清楚具体细节。 功能上,这款浏览器的另一个亮点,就是集成 Operator 等 AI 智能体,可以代表用户执行任务。通过直接在浏览器的核心中构建人工智能,OpenAI 也能提供一些第三方浏览器扩展无法实现的独特功能。(来源:新浪科技)  ## 邓紫棋首部科幻小说开启预售:通往内心的启示路 北京时间 7 月 10 日,邓紫棋发布动态。今天是她出道 17 周年的纪念日,也是她首部长篇科幻小说开启预售的大日子。这么多年,先是创作完《启示录》专辑的 14 首词曲,紧接是当上自己 14 集 MV 连续剧的编剧,然后是完成同系列 14 首西班牙语版本的创作,再到如今小说也终于面世了。  这部科幻小说《启示路》已在淘宝、天猫、京东、B 站、小红书等多个渠道开启预售,定价为平装版 89 元,恒藏版 298 元。 邓紫棋表示,小说之所以定名《启示路》,是因为她深信──每个人其实都走在一条「启示路」上。(来源:cnBeta)



今年的第二届 Unpacked 大会已经落下帷幕,三星与往年不同的是在会上推出了三款可折叠手机而不是两款。除了Galaxy Z Flip7和Galaxy Z Fold7,还推出了价格较低的Galaxy Z Flip7 FE。  在您还在犹豫是否购买新款折叠屏手机之际,我们为您准备了 Galaxy Z Flip7 和 Galaxy Z Fold7 的全部原装壁纸和动态壁纸。这些壁纸由[X 用户 Razer_the_Raven](https://x.com/Razar_the_Raven)提供。 **您可以从这里获取最新 Galaxy Z Fold7 和 Galaxy Z Flip7 壁纸,包含内外屏:** [https://quickshare.samsungcloud.com/ftSmGAbQqgfy](https://quickshare.samsungcloud.com/ftSmGAbQqgfy) **下载动态壁纸:** [https://drive.google.com/drive/folders/17NfqXFjRhQG4Mrhxn5uzGN3nVRcQvIOG?usp=sharing](https://drive.google.com/drive/folders/17NfqXFjRhQG4Mrhxn5uzGN3nVRcQvIOG?usp=sharing) 新款可折叠手机有很多升级。首先,Galaxy Z Flip7 现在配备了类似于 Moto Razr 手机的全屏翻盖显示屏。它也是三星所有翻盖手机中最薄的一款。已推出至今。 尺寸和重量也是 Galaxy Z Fold7 的主要升级。这款书本式折叠屏手机是三星所有折叠屏手机中最薄的。折叠屏手机中,它也是目前最轻的。有趣的是,它的重量仅为 215 克,甚至比三星 Galaxy S25 Ultra 还要轻。它也是首款配备 2 亿像素主摄像头的折叠屏手机。 Galaxy Z Flip7 提供炫黑、幻影蓝和珊瑚红三种配色,薄荷绿为线上独家配色。Galaxy Z Fold7 提供炫黑、幻影蓝和幻影银三种配色,薄荷绿为线上独家配色。 [查看评论](https://m.cnbeta.com.tw/comment/1512320.htm)

据彭博社的马克·古尔曼 (Mark Gurman)报道,苹果不打算在 2025 年为任何 Mac 更新 M5 芯片。目前计划在 2026 年上半年推出升级版MacBook Air和MacBook Pro机型。  古尔曼此前曾表示,苹果将在 2025 年底推出 M5 MacBook Pro 机型,但他的最新报告表明,苹果正在“考虑”将其推迟到 2026 年。据说苹果现在“内部计划”在明年年初推出。 目前的 M4、M4 Pro 和 M4 Max MacBook Pro 机型于 2024 年 10 月发布,并于 2024 年 11 月上市,因此将 M5 机型推迟到 2026 年将意味着苹果将不再进行年度更新。新款 Mac 通常会在 9 月iPhone发布会后,于 10 月或 11 月上市。 古尔曼没有说明苹果可能“推迟”推出 M5 MacBook Pro 机型的原因,但他表示时间尚不确定,因此我们仍有机会在年底之前获得新款 Mac。 除了 M5 芯片更新外,M5 MacBook Pro 机型几乎没有变化,因为苹果计划在 M6 MacBook Pro 上进行更大的改动。下一代 MacBook Pro 机型预计将过渡到 OLED 显示屏和新的外壳设计。有传言称 OLED MacBook Pro 将于 2026 年上市,但如果苹果计划在 2026 年推出 M5 MacBook Pro 机型,这可能意味着 OLED 机型将推迟到 2027 年。或者,苹果可能会在 2026 年初推出 M5 MacBook Pro,并在 2026 年底推出 OLED 版本,但这很不寻常。 苹果还计划在 2026 年推出 M5 MacBook Air 机型,以取代目前的 M4 机型。其他传言称,苹果正在研发一款搭载 A18 Pro 芯片的 MacBook,预计在 2026 年上市,但古尔曼并未提及。 M5 MacBook Pro 和 MacBook Air 机型可能会配备苹果正在研发的一款新显示器。苹果正在开发一款外接显示器,预计将作为 2022 年 Studio Display 的后续产品。该显示器预计将于 2026 年初上市。 [查看评论](https://m.cnbeta.com.tw/comment/1512316.htm)