所有文章
 钛媒体 · 价值星球Planet
钛媒体 · 价值星球Planet
 36氪
36氪在中国,男性群体终于也可以打HPV(人乳头瘤病毒)疫苗了。 1月8日,默沙东旗下的四价HPV疫苗“佳达修”正式获国家药监局批准,新增9-26岁男性接种的适应症,成为国内首个且唯一获批的男性HPV疫苗。诸多国外内厂商的围猎战中,终究仍是老牌外企拔得头筹。 放眼海外,男性HPV疫苗算不得一个新市场。毕竟,甚至都有70多个国家将其纳入免疫规划接种疫苗名单(政府付费,强制接种)。但在中国,它仍是HPV疫苗赛道内一个货真价实的新故事。 2018年,智飞生物独家代理的默沙东九价HPV疫苗进入国内市场,饥饿营销之下,自费大几千的产品一度供不应求到“42万人摇号打针,中签率不足1.7%”。但随着几款国产二价产品相继上市,HPV疫苗市场迅速进入微利时代。到2024年,在一些省份,单支疫苗的政府采购价已降至不到30元。 对疫苗厂商来说,既然女性市场已经卷成了“白菜价”,拓展男性用户是个再合理不过的逻辑。按照沙利文数据,2020年时,国内9-45岁适龄打针的男青年就有3.44亿人,按每人三针的完全剂量算,就有近10亿针。 这块蛋糕很难不让人心动。当前,默沙东虽尚未对外披露“佳达修”的价格,**但在获批首日,一些电商平台上就已经可以预约这款产品,三针定价2885元。有客服表示,“已备现货”**。 一片繁荣的预期中,卖家们似乎唯独回避了“男性HPV疫苗怎么卖”问题:国内的男同胞们,真的愿意打针吗?  电商平台上的男性HPV疫苗预约界面 ## **推广男性HPV疫苗,先“说服”他的伴侣?** 说服男性打HPV疫苗,在全世界范围内都不是一件容易事。 这一点,海外市场其实就曾给出过答案。2023年,《中华全科医师杂志》一项研究援引的海外数据提到,自2014年海外部分国家开始同时针对男性和女性推广HPV疫苗后,直至2019年,男性的接种率和完成率“仍很低”,分别只有5%和4%。对比之下,这两个数字在女性群体中分别达到20%和15%。 此外,整体来看,男性接种HPV疫苗的成本效益也存在争议。该研究提到,如果疫苗价格和覆盖率较低,将青春期男孩纳入接种计划具有成本效益。但如果女性覆盖率已经超过了75%,现有证据就“不够充分”。 这固然与厂商们过去普及HPV疫苗接种的“市场教育”有关。过去,HPV疫苗俨然已被大众当作了一款“女性产品”,关注自我健康、有自我保护意识的女性就应该去主动接种疫苗。但另一个无法忽视的原因也在于,**尽管男性是HPV病毒因子的主要传播者,但相比于女性会患宫颈癌,男性自身直接患病的几率要小得多**。 和君咨询医药医疗事业部业务合伙人陈建国长期关注疫苗产业,他提到,在接种疫苗预防HPV感染及其潜在风险的意识上,目前“男性整体弱于女性”。一方面,国外接种现状也表现为女性市场为主,男性有所提高,但占比有限;另一方面,尽管男性感染后,也有引起阴茎癌等癌症,或尖锐湿疣等疾病的可能,“但整体较轻”,且早期感染后的处理方法相对成熟,花大价钱打针预防的必要性相对不高。 换句话说,直接用原来那套“打针保护身体健康”的营销策略来感动男性群体,可能难度略大。一个更合理的逻辑,或许是**用现有的女性接种者这个“存量市场”,来“撬动”男性用户**。 两年前,Abby就曾“push”自己的男友去打HPV疫苗。彼时,相关产品尚未于国内获批,两人都是在去美国留学时,在校医院里预约打针的。但据她观察,周围男性友人对HPV疫苗的认知至多停留在“男女都能打”的层面,也很少有人会特意去了解疫苗能预防哪些男性疾病。 “除了被伴侣告知打疫苗有利于健康,影响他们决策的最重要原因。大概就是学校强制上缴的学生保险要1万美元,为了‘薅羊毛’,大家几乎把能打的疫苗都打了。”Abby分析。 近两年,这种“为了她的健康”的声音,也不乏出现在国内的社交媒体上。一些去港、澳地区,或在海外接种疫苗的男性博主纷纷晒出攻略,分享预约渠道或靠谱的医疗机构名单。甚至有网友打出口号: “HPV疫苗,男人最好的嫁妆”。 陈建国认为,**相关产品开始正式推广后,存在利用女性用户带动男性市场的可能性,但转化效率取决于企业的市场推广能力**,若推广教育不够,市场可能未必很高。“此外,这也取决于产品的定价和供给情况,过往针对女性市场的饥饿营销策略,是不适合当前男性市场推广的。” 与此同时,行业内亦有另一种声音认为,近几年,伴随着世界卫生组织(WHO)和国内相继发布推行加速消除宫颈癌行动计划,HPV疫苗被纳入我国免疫规划,或许也是拓展男性市场的有效方式之一。 比如,北交所挂牌企业、较早布局男性HPV疫苗的国产厂商康乐卫士,就在2024年半年报中乐观预测,未来,HPV 疫苗在中国“亦可能被纳入国家免疫规划”,从而提高公众接种意识和疫苗覆盖率。 对此,多位疫苗行业受访者给出了较为一致的看法,即短期内较难实现这个目标。更有可能的情况是高、低价HPV疫苗市场呈现两种分化的市场格局,低价疫苗主要用于政府采购的儿童预防接种,高价疫苗则以成人自费接种为主。 此前,开源证券研报也曾提到,考虑到区域流行病学特征、疫苗可及性、经济发展水平及财政支付能力等因素,WHO“推荐品种与我国正式将该疫苗品种纳入国家免疫规划可能存在较长的时间差距”。 ## **国产厂商蓄力,又是一个价格战的轮回吗** 把希望寄托到男性市场上,HPV疫苗厂商的确多有无奈。 2018年至今不过短短七年,在医疗行业,这原本正应是一个“爆款”药物的当打之年。但国内的女性HPV疫苗,在2024年时已隐隐呈现出卖不动的趋势。 先来看默沙东,中国市场基本可以为其贡献60%-70%的HPV疫苗国际销售额。今年前三季度,HPV疫苗整体销售额23.06亿美元,同比下降约10%。主要原因就是中国市场需求减少,而除此之外,全球其他地区基本都保持在两位数增长。目前,尽管默沙东已降低向智飞生物的HPV疫苗出货量,但总体库存仍然很高。 此外,“价格战”和政府免费接种项目之下,国内疫苗厂家集中布局上市的女性二价HPV疫苗,也很难称得上是好生意。以代表性企业沃森生物为例,2022年,其二价HPV疫苗获批后,公司全年营收也达到近年来的顶点,逼近51亿元。但到了今年前三季度,公司仅实现21.41亿元的收入,同比下降32.19%,主要就是因为“疫苗产品销售收入减少”。 另一家万泰生物也是如此。虽然公司还有多款疫苗在研,但收入主要靠二价HPV疫苗驱动。今年前三季度,万泰生物收入为5.82亿元,同比减少60.79%。公司对外表示,疫苗板块受市场调整、政府集采和九价类产品扩龄接种等影响,销售收入较去年同期有所回落。 陈建国分析,面对女性HPV疫苗市场竞争出现如今的白恶化情况,HPV企业从业者是时候该调整产品医学策略和市场策略了。 如今,各企业面对市场积极转向男性疫苗方向,不妨视为一种新的机会。“佳达修”之后,排队做临床、等上市的男性HPV疫苗还有许多,且以九价类产品为主。 进展快者,除默沙东旗下的九价HPV疫苗已进入上市申请受理阶段外,万泰生物、康乐卫士和博唯生物的九价疫苗均已进入三期临床阶段。其中,康乐卫士曾在招股书中称,男性九价HPV疫苗预期于2028年上市。 整体而言,**头部企业的男性HPV疫苗产品研发进展相对统一,在未来或许会迎来集中上市期**。 值得注意的是,HPV疫苗的获批基本都会经历从小范围年龄人群向更大群体扩围的过程,就像默沙东的女性九价疫苗,也是在上市4年后,适用年龄才从16-26岁转为9-45岁。而男性群体的HPV疫苗接种意识本就不强,加之目前刚刚批准的9-26岁年龄段人群,多不具备自主付费能力,真正开始“放量”,或许也要等到26岁之后年龄段的适应症获批之后。 只是不知,届时女性HPV疫苗市场上的“价格战”故事,是否又会在男性疫苗市场上演?

In addition to establish new datacenter in India, Microsoft plans to train and skill 10 million people by 2030, reinforcing its commitment to partnering with India on its journey to become an AI-first nation. It also strikes cloud and AI led strategic partnerships with industry leaders from across key sectors of the country.

Salesforce是否能够凭借Agentforce或更新一代的AI产品实现增量业务收入,还要打个问号。

FO.COM正逐步构建起一个覆盖生活各个方面的Web3生态系统,致力于成为Web3时代的微信、支付宝。
 机核 · YT17
机核 · YT17 阿狗社(Astrolabe Games)本日宣布,由其负责发行的手绘叙事解谜游戏《生肖纪 鸡哥和他的朋友们》正式公开并宣布登陆PC Steam平台,全新宣传影片亦正式亮相。该作意在用轻松可爱的表达展现生肖文化。在精美的国风手绘世界中,玩家可以体验到美食烹饪、恋爱模拟、剪纸园艺等诸多趣味玩法。随酉鸡"鸡哥"一起穿越回古代,粉墨一场关于家庭与爱的人生故事。 <内嵌内容,请前往机核查看> 故事背景——生肖联欢闹翻天! 十二生肖在新年夜聚会,傲气的鸡哥实在闹过头了,最终导致其他生肖忍无可忍——他竟然弄哭了兔大厨!忍无可忍的龙决定施展魔法,将鸡哥送回古代,让他好好反省。  在游戏中,你将随酉鸡“鸡哥”一起,与叫“小鸽”的凡人相遇。在小鸽的人生之路上,帮他解决各式各样的问题,其中每件事都潜藏着和生肖伙伴和解的契机。相信只要有你的明智,生肖们还是能欢聚一堂,共庆佳节! 游戏特色——最重要的是把爱融进细节! 我们在美术上采用了可爱版的水墨画风格,同时设计了大量灵动的动画和效果与之搭配,力图为大家带来温馨轻松的游戏体验。  人一生的烟火故事总是有笑有泪,即便平凡,也有值得铭记的种种时刻。虽然是休闲题材,我们还是选择结合生肖文化,用尽可能的用更多的故事和情节来创作这款生肖纪,希望这能抚慰到每一位玩家。  另外,请不要担心会在哪一步卡住,团队鼓励用才智征服鸡哥遇到的种种谜题。但也忘记加入无障碍设计和必要的小提示,确保每位玩家都能愉快的享受游戏。 游戏玩法——人生关,关关难过关关过! 寻找物品、推理、猜谜、烹饪、剪纸、园艺……甚至是塔防和恋爱模拟,生肖纪为大家带来休闲玩法的一大桌年夜饭!  生肖伙伴们都有自己的独到的特质,当然也有不同的象征,鼠的财富,牛的勤劳,兔的善良,蛇的冷静…… 每个关卡都会在此基础上展露创意,并灵活融入生活中的小难题,十余关玩法各不相同!  鸡哥最后能否顺利和众生肖重归于好,最大的难关又要具备什么才能从容应对。经历一整遭人间烟火,相信大家都能找到自己的答案。
 每个人心里总藏有个自己的「最强」超级英雄。从三国到隋唐,从足球到篮球,无论武力还是智力,不管荣誉还是技术。只要涉及到孰强孰弱的话题,大家心中都有一个不容被小觑的“One Pick”。 这个春节,如果在这个事儿上说不服别人,你可以试试将对方打服。  专门解决关公战秦琼问题的分歧终端机,欢乐沙雕的“赛博斗蛐蛐”物理引擎战争模拟游戏《全面憨憨战争模拟器》,将于1月16日在TapTap和苹果商店正式上线手机版。游戏为买断制收费,原价18元,首发前两周限时优惠价12元。 <内嵌内容,请前往机核查看> 《全面憨憨战争模拟器》基于Steam上好评如潮游戏作品TABS的原版进行移植,由开发商Landfall官方授权心动代理。 在这样一款无所不能,欢乐满满的战争模拟器里,你可以通过游戏强大的自定义功能,将无数只存在于梦想里的中二对决化为实际。无需费力操作,只要脑洞够大,大家便可以饶有兴致地全方位观赏到欢乐搞笑的“赛博斗蛐蛐”。  #脑洞有多大,节目效果就有多大 在《全面憨憨战争模拟器》里,你可以在游戏中安排一场超人与一拳超人的披风侠互殴。  极致的强者,只需要最朴素的抡拳方式 又或者是让天命人与大圣残躯在黑风山的塔顶展开一场乱斗。  在真实物理引擎的支持下,你可以慢动作看闪电侠如何帮人类实现光速倒立螺旋升天。  (你有被光速踢过吗?) 心有多大,舞台就有多大。根据官方消息,作为TABS正版手游,《全面憨憨战争模拟器》不光首发将带来原版游戏的所有地图与战役,以及海量可解锁的隐藏彩蛋。与此同时,他们还将不断把PC版本玩家社区中的热门mod搬运移植到手机版中,玩家只需一次买断付费,便可持续畅享游戏中海量欢乐玩法与新鲜内容。 随时随地,把谁是谁的爹捋清 与原版TABS对比,《全面憨憨战争模拟器》针对手游玩家习惯,重新设计了手游的操作UI,尽可能减少了按键对游戏画面的遮挡,呈现精彩的战斗演出效果。  除一键放兵、时停及子弹时间等使用功能以外,手游版还加入了让战争更为热闹的联机功能 —— 玩家还可以在联机大厅创建房间,随机快速匹配对手,或者邀请自己的好友一同切磋各种脑洞大开的玩法。  当然,不论面对怎样的敌人,在《全面憨憨战争模拟器》里,所有事件可未必会按大家预想的方向去走……  抽象永远是TABS的底色,就好像诸葛亮可以带上500把AK47北伐中原,但要面对的对手可能不光戴着至尊魔戒,胯下还骑着条龙……  《全面憨憨战争模拟器》热闹欢乐的无厘头氛围始终在线,在抽象夸张的镜头中,它让人们忘记紧张的战场胜负,只留下流泪与肚子疼等因爆笑导致的副作用。 即便自己没能打败敌人,大家也尽可以淡然一笑,并把诸葛丞相的经典名言敬送给对面那离谱却有趣的阵容。 物理引擎战争模拟游戏《全面憨憨战争模拟器》,将于1月16日在TapTap和苹果商店正式上线手机版。游戏原价18元,首发前两周限时优惠价12元,感兴趣的朋友们可以前往预约! >[iOS预购入口](https://apps.apple.com/cn/app/%E5%85%A8%E9%9D%A2%E6%86%A8%E6%86%A8%E6%88%98%E4%BA%89%E6%A8%A1%E6%8B%9F%E5%99%A8/id6443786927)<>[TapTap安卓预约入口](https://www.taptap.cn/app/229435)<

 近日KRAFTON(CEO CH Kim)在世界最大IT·电子展会“CES 2025”上展示了其与NVIDIA共同开发的AI技术 - CPC(Co-Playable Character)。据悉,这是与NVIDIA合作研发的创新型AI技术,为全球游戏产业刻下了新的里程碑。 KRAFTON深度学习部负责人Kangwook Lee负责进行了AI模型“CPC”的发表。他表示“CPC是一种能通过NVIDIA ACE技术构建的游戏专用设备端小型语言模型(On-device SLM for Gaming)与游戏玩家进行互动的新概念角色”,并解释道“CPC不同于现有的NPC(Non Player Character),它的特点是能与玩家进行对话、协作,灵活地理解情况并做出应对” 。  随后Kangwook Lee还提到“KRAFTON将会把CPC应用到包括《PUBG》IP系列作品和《inZOI》在内的多款游戏上,对用户体验进行持续革新”,并表明“我们的计划是加紧进行优化和标准化工作,争取让CPC成为游戏行业的新基准”。他还补充说“我们相信AI技术会为游戏行业带来巨大变化,并将持续与NVIDIA保持长期合作关系” 。 KRAFTON还在本次活动中公开了应用CPC后的《PUBG》IP系列作品和《inZOI》的试玩视频。首先公开的《PUBG》IP系列视频中展示了名为“PUBG Ally”的CPC,它能与玩家进行日常对话,并做出根据情况制定战略、对玩法风格进行细节调整等高级操作。  《inZOI》的视频中则介绍了“Smart Zoi”。它是一位像人一样拥有性格特色和感情的CPC,能通过与玩家的深度互动为玩家带来具有高度沉浸感和生动感的模拟体验。 此外,KRAFTON还为现场的与会人员准备了首个体验CPC的机会,并得到了出席人士的热烈反响。
 爱范儿 · 李华
爱范儿 · 李华
Model Y,回不到 2019 年。 #欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。 [爱范儿](https://www.ifanr.com) |[原文链接](https://www.ifanr.com/1611798) ·[查看评论](https://www.ifanr.com/1611798#comments) ·[新浪微博](https://weibo.com/ifanr)

海螺 AI,让每个想法都是一部大片 #欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。 [爱范儿](https://www.ifanr.com) |[原文链接](https://www.ifanr.com/1611808) ·[查看评论](https://www.ifanr.com/1611808#comments) ·[新浪微博](https://weibo.com/ifanr)
 在备受期待的开放世界Rogue-Lite游戏《光明破坏者》即将于2025年1月15日登陆Steam抢先体验版之际,Arc Games与Heart Machine带来了两项重磅公告!详情请见下文。  <内嵌内容,请前往机核查看> 在一系列短篇“破坏者”预告片依次展示了《光明破坏者》抢先体验版中的可玩角色后,我们终于迎来了完整版预告片!该预告片不仅汇总展示了所有可操作的“破坏者”,还首次揭晓了玩家在抢先体验版中将迎战的“冠卫”(boss)战斗场面。  抢先体验开启后,玩家将可从三名独特的“破坏者”——朱砂,拉碧斯和五郎中选择一位,并挑战两位强大的“冠卫”——斧头恐狼和埃瑟斯。值得一提的是,每位“破坏者”都拥有自己独特的“僚机”——小型机器人伙伴,类似《光明旅者》中的伙伴!它们是角色构建的核心,提供专属增益效果和属性调整。  此外,玩家可以自由自定义每位“破坏者”的装备配置([请查看有关配装的更多细节](https://steamcommunity.com/app/1534840/eventcomments/4630359023402653609?snr=1_2108_9__2107))。无论你的配置如何,斧头恐狼和埃瑟斯这两位“冠卫”都绝不会轻易示弱。 完整的“冠卫”(Boss)战斗预告片将于明日(1月11日)在Arc Games社交媒体账号上(微博与B站)正式公布……敬请期待!  为了让玩家全面体验《光明》系列,Heart Machine 与 Arc Games 将于 1 月 15 日(《光明破坏者》抢先体验版上线当日)至 1 月 29 日限时推出 《光明破坏者》捆绑包。 该捆绑包售价152元人民币,将赠送一份 《光明旅者》 的 Steam 数字版(若玩家的 Steam 库中尚未拥有该游戏)。购买该捆绑包的玩家不仅可以畅玩经典 2D 动作冒险 RPG 《光明旅者》,还可通过 《光明破坏者》 踏入一个全新的开放世界 Rogue-Lite 冒险,该作的故事背景设定在《光明旅者》事件发生的数十年前!
作者 | 范亮 编辑 | 丁卯 2024年以来,盲盒龙头泡泡玛特股价不断突破新高,区间涨幅超过三倍,市值一度突破1200亿港币。其股价的飙升背后,一方面得益于2024年上半年利润的翻倍增长,另一方面则是资本市场对“谷子经济”概念的热烈追捧。 恰逢其时,12月15日,**拼搭玩具品牌商布鲁可通过港交所聆讯,距离IPO仅一步之遥。** 毫无疑问,**布鲁可刚好赶上了“谷子经济”这波热潮。**根据招股说明书显示,2021年4月布鲁可完成A轮融资后,其估值就达到了72亿元人民币。而公司招股结束后,最终以60.35港元/股价格,发行2773.83万股,最终募得资金16.74亿港元,对应发行估值约150亿港元,较上轮估值接近翻倍。 **2025年1月10日,布鲁可成功登陆港交所,截至目前涨幅超50%,市值达到220亿港元,最高涨幅80%,市值超260亿港元。**那么,布鲁可究竟是一家怎样的公司,上市之后其估值能否凭借“谷子经济”热潮更进一步? ### **收入接近2020年的泡泡玛特** 根据产品线划分,布鲁可主要拥有**拼搭角色玩具、积木玩具**两条产品线,**二者均属于拼搭类玩具**,原材料与生产流程类似,主要的**区别在于拼搭角色玩具一般有确定的形态且体积较小,拼搭难度低;**而积木玩具则可以任意搭配。 **2016—2021年间,布鲁可的产品主要以积木玩具为主,2022年推出拼搭角色玩具,并主要以盲盒销售,此后公司业绩正式步入爆发期。** 根据招股说明书显示,2021—2023年,布鲁可的收入分别为3.30、3.26、8.77亿元,其中拼搭角色玩具收入占比为0%、36%、88%。2024上半年,布鲁可的收入为10.46亿元,同比增长超200%,其中拼搭角色玩具同比增长更是超过3倍,收入占比高达98%。产品形态上,2022到2024H1,布鲁可**盲盒销量在总销量占比从73%提升至88.3%,在总收入占比从34.8%提升至73.9%。** 售价方面,布鲁可2024上半年拼搭角色玩具均价为18元/件,积木为97元/件,价格构成主要为经销商批发价。 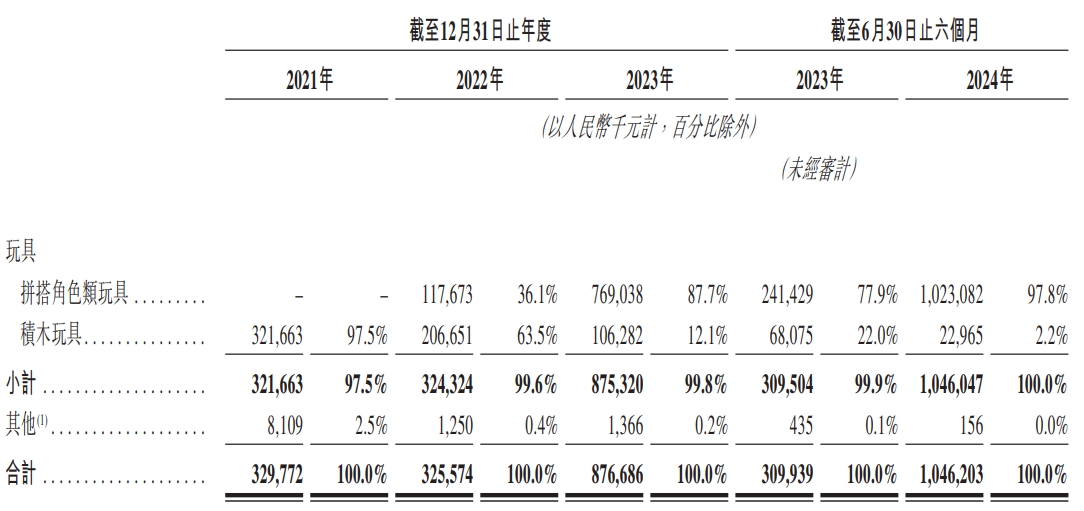 图:布鲁可营收(按产品结构划分) 资料来源:公司公告,36氪整理 **一个很明显的趋势是,布鲁可在2022年后将业务重心放在了增长潜力更大的拼搭角色类玩具。目前看,**这是一个明智的选择。从2022年后公司的毛利率、费用率等数据也得以佐证,拼搭角色类玩具各项财务数据的表现均远优于积木类玩具。 从拼搭角色类玩具的构成上,布鲁可**以授权IP(奥特曼、变形金刚等)为主,自有IP(英雄无限)为辅,并逐步提高自有IP产品销售比例。受众人群上,布鲁可核心授权IP对应的人群主要是青少年群体,且以男性为主。** 自有IP的搭建上,布鲁可近年来**陆续推出百变布鲁可、英雄无限等动画片**,以强化自有IP认知。2023年,布鲁可拼搭角色类玩具中,授权IP玩具收入占比92%(奥特曼IP占比72%),自有IP玩具收入占比仅8%。而**到2024上半年,自有IP收入占比达到17%,授权IP占比则下降至83%。** 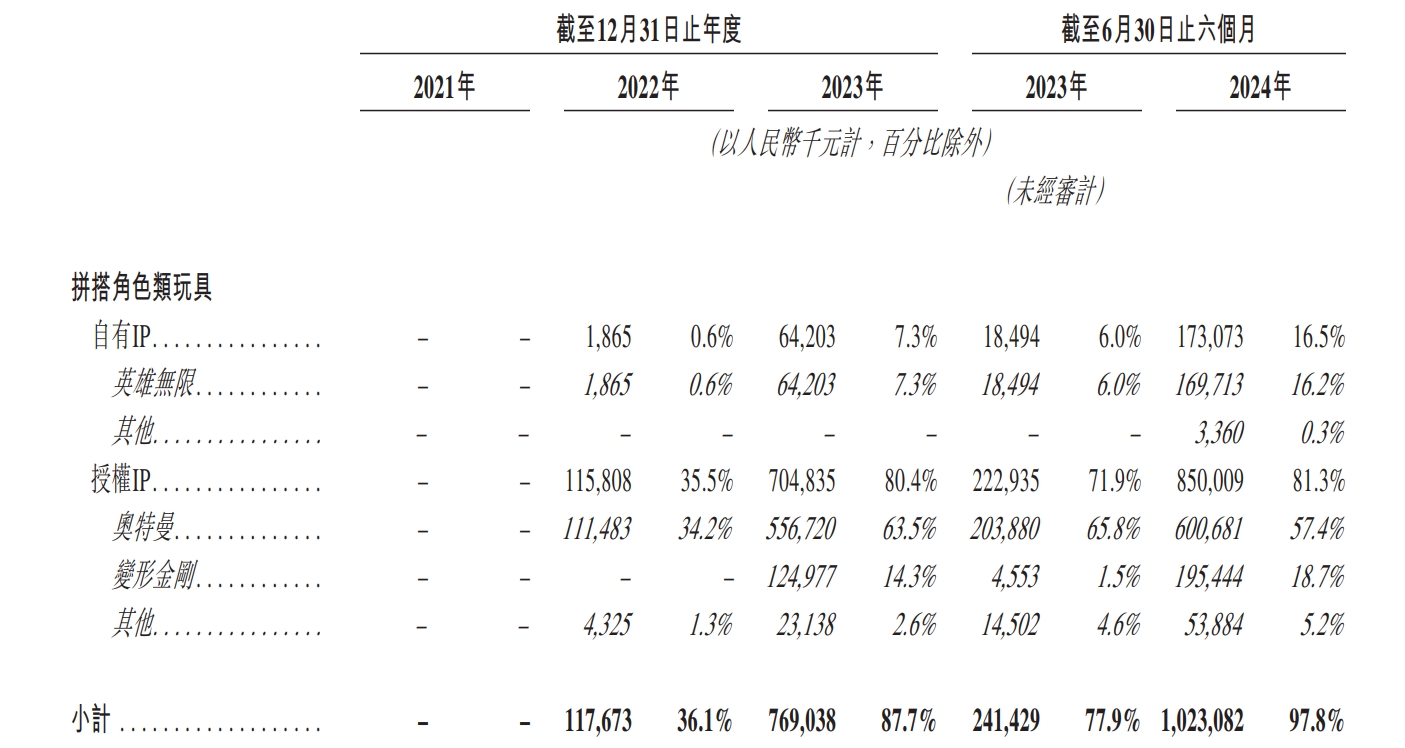 图:布鲁可营收(按IP结构划分) 资料来源:公司公告,36氪整理 **在经营模式上,布鲁可主要经历了线上直销向线下经销的转变,这与公司主营产品的变化相关。** 2021到2024上半年,**公司线下经销商收入占比从34.2%提升至90%以上,经销商数量从225家提升至511家,约70%分布在二线城市以上。**从业绩贡献度来看,2021—2023年布鲁可经销商数量净增84%,但公司对应营收增量为166%,因此布鲁可的业绩扩张不只是单纯依靠经销商数量的扩张,其向**单个经销商的平均销售额从2021年的50.14万上升至2023年的143.39万元**。对经销商的管控方面,布鲁可整体处于强势地位,如对经销商设置最低购买量、要求普通经销商货到前付款等。 关于布鲁可为何转变销售渠道,原因可能有以下几个方面:**一是主推产品从积木转向拼搭角色玩具,面向的直接付款方可能从“家长”转向“青少年”,因此需要通过线下渠道增加曝光度,降低达成交易的难度,开拓线下渠道就相当于开拓线下市场;**二是拼搭角色产品加入盲盒属性,相较线上,**消费者通过线下购买更容易获得沉浸式体验**,如泡泡玛特2020线下收入占比80%+,2023年依然在60%以上。 总的来说,**如果将布鲁可2024上半年营收简单乘以二,那么其2024年的总营收大概接近于2020年的泡泡玛特。如果以GMV为核算口径,布鲁可大概相当于2021年的泡泡玛特。** 最后,在行业地位上,根据弗若斯特沙利文数据,以2023年**拼搭角色类玩具零售GMV**为例,布鲁可产品全球GMV为18亿,全球市占率6.3%,排名第三,第一和第二分别为万代、乐高,二者市占率均在30%以上。国内市场GMV17亿,排名第一,市占率30.3%,在国内超过万代的20%、乐高的15%。 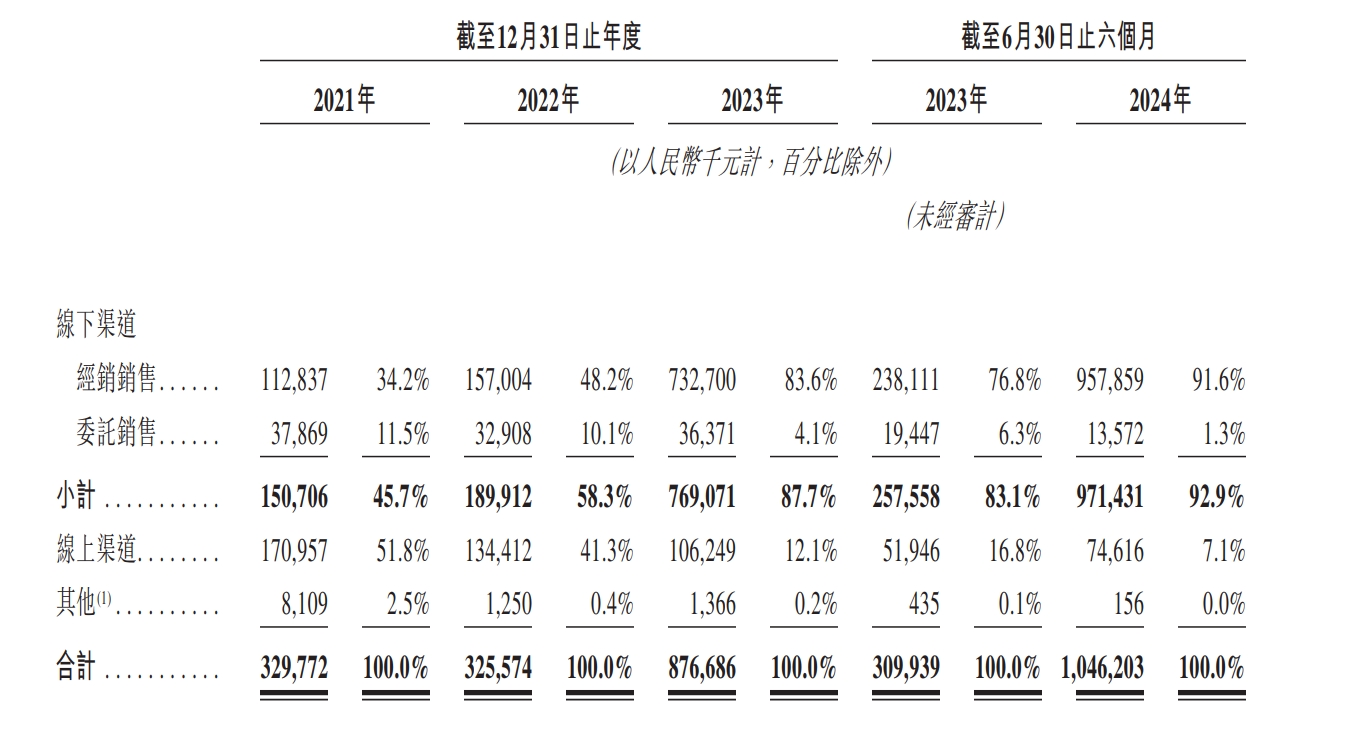 图:布鲁可营收(按销售渠道划分) 资料来源:公司公告,36氪整理 ### **IPO资金如何规划?** 从布鲁可的IPO资金投向,也可以看出公司未来的战略规划。根据招股书,布鲁可预计净募集的资金中,投向主要是五个方向: (1)25%用于**产品研发**。(2)25%用于模具采购和**自有产能建设**。(3)20%用于**自有和授权IP建设**。(4)20%用于营销。(5)10%用于日常运营。 布鲁可把**研发放在募集资金投向的首位,原因在于其盲盒产品要不断推出新品**,才能满足下游市场需求。毕竟盲盒能快速扩张,**关键在于消费者的持续复购**。而且,由于布鲁可的授权 **IP 不是独家拥有的,所以也需要增加 SKU 来形成产品差异**。根据布鲁可披露,截至2024年6月30日,布鲁可共有431款在售SKU,包括主要面向6岁以下儿童的116款SKU、6至16岁人群的295款SKU,以及16岁以上人群的20款SKU。 **自有产能建设和模具采购排在第二,是因为布鲁可目前还没有生产能力,**其拼搭玩具产品主要依靠委外加工。随着公司销售规模扩大,布鲁可自然不愿意在生产端“受制于人”,根据布鲁可披露,公司**2024上半年月均销量约为930万件,自有工厂建成后月产能900万件**,因此自有工厂建成后产能已经可以满足2024年需求。 排在第三位的是IP相关的支出,布鲁可预计**在**自有IP建设上使用6500万港币,与三方授权IP相关的资金投入大约为1.79亿港币。可以看出,目前布鲁可并未以激进的态度推动自有IP建设,其**依然将授权IP放置在比较重要的位置。** **这与泡泡玛特通过直营强势推广自有IP的策略有所不同,直营渠道下,自有IP在店内核心位置呈列后,可以集聚消费者注意力,强化IP认知。但在经销渠道下,自有IP产品往往与其他热门IP产品同时呈列,进店消费者注意力会被热门IP分散,不容易达成销售,也会影响经销商库存周转。** **因此,在渠道束缚、自有IP势能不足的背景下,我们判断未来数年布鲁可的玩具产品都会以授权IP为主,同时以渐进方式推动自有IP建设。自然,授权IP的稳定性对布鲁可的经营就显得至关重要,这也是布鲁可愿意在三方IP投入大量资金的主要原因,预计未来布鲁可将着力于均衡各IP对公司收入的贡献,从而分散授权IP的续约风险。** **总的来说,布鲁可的募集资金投向计划还是比较清晰反映了公司未来的战略规划。**从资产负债表数据来看,截至2024上半年,布鲁可账面现金约5.5亿人民币,其中相当部分为拉长供应商付款期限而来。因此,通过IPO资金对布鲁可而言可以说是一笔“巨款”,对公司快速扩大业务规模相当重要。 ### **账面巨亏,实际已有造血能力** 布鲁可将业务重心放在拼搭角色玩具,并加大自有IP建设,一方面原因是可**以盲盒形式低单价规模扩张**,另一方面则是相关产品在成规模后**有较高的盈利能力**。 招股说明书数据显示,**2024上半年拼搭角色类玩具毛利率整体为53.3%**,呈持续上升趋势,积木类玩具则仅为38.1%。按IP分类,拼搭角色玩具中,**授权IP产品毛利率为51.5%,自有IP毛利率则为61.9%,**原因也很简单,自有IP无需支付授权费用,因此成本也更低。此外,布鲁可披露,其支付的IP费用计算方式为固定金额,或者按销售比例结算二者孰高,公司相关产品销量增加也无法摊薄IP支出费用。 关于拼搭角色类玩具毛利率为何远高于积木类玩具,原因主要就是前述的规模效应。前文提到,布鲁可当前几乎没有自有产能,相关产品主要委外生产,采购量增大后公司议价能力也可增强。 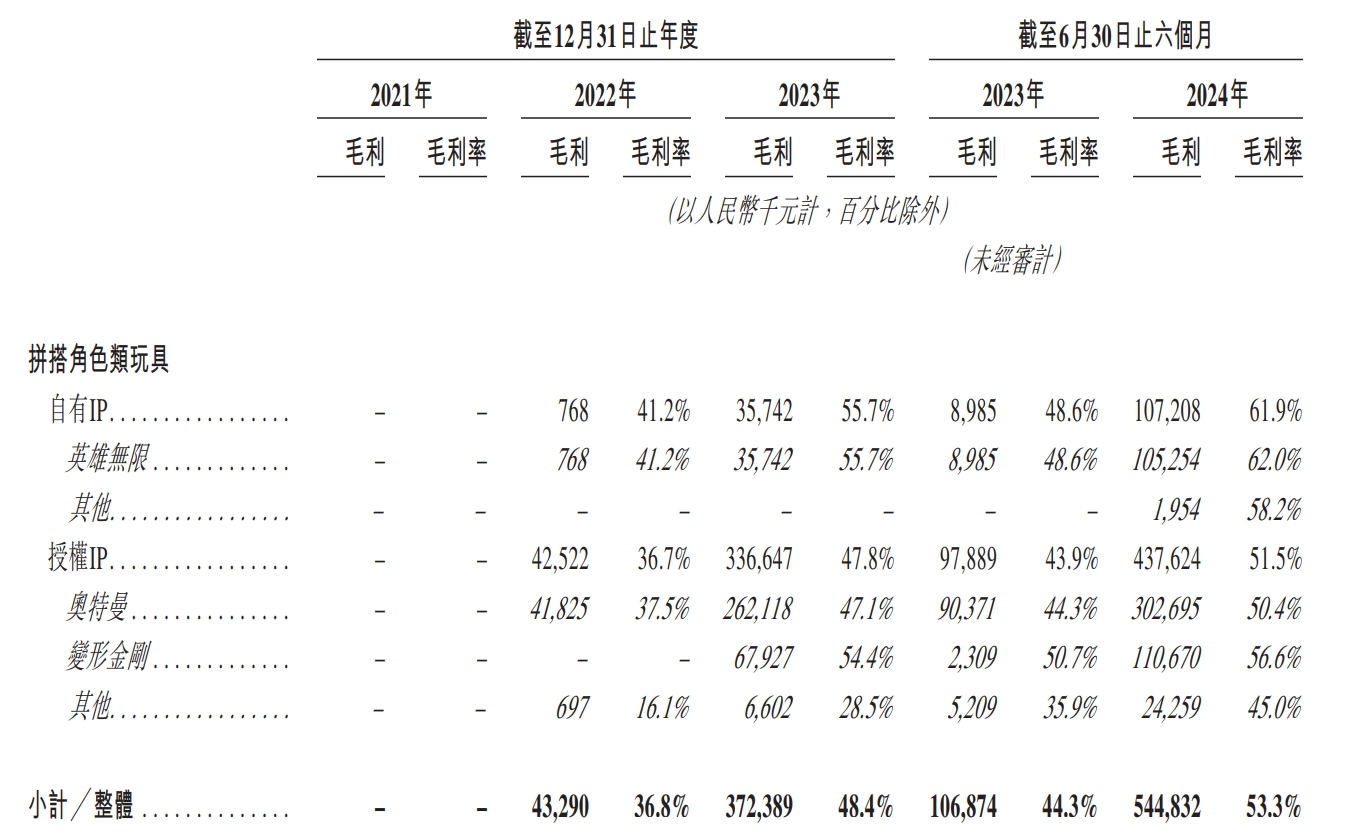 图:布鲁可拼搭角色玩具毛利率 资料来源:公司公告,36氪整理 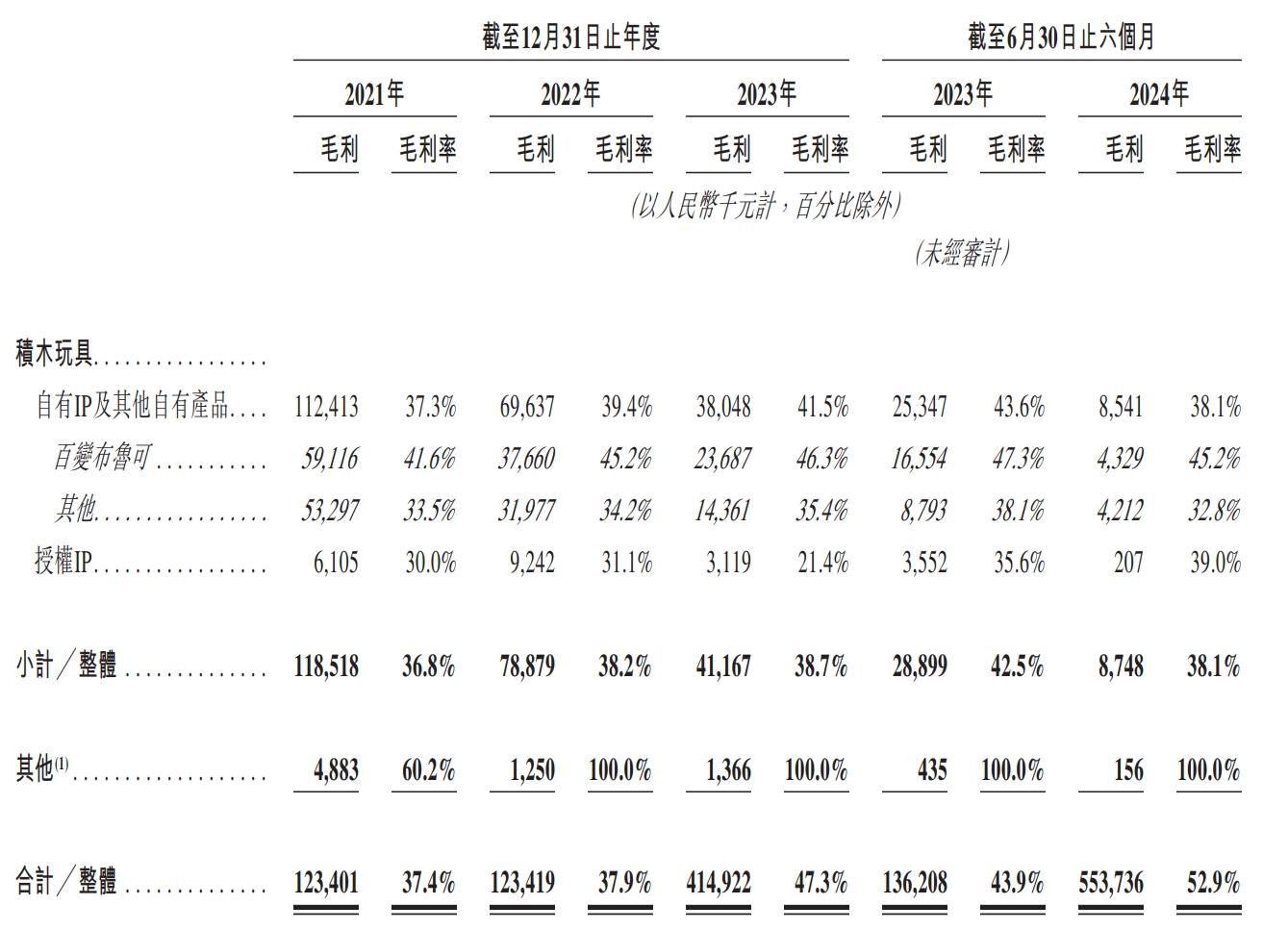 图:布鲁可积木玩具毛利率 资料来源:公司公告,36氪整理 再看费用结构。2021年时,布鲁可业务以积木玩具为主,**其为积木玩具进行的营销推广费用就高达2.73亿,但公司当年营收规模仅3.3亿,推广投入与收入回报不配比。**当年公司销售费用率117.9%、管理费用率17.7%、研发费用25.2%,期间费用率合计160.8%,严重入不敷出,**这可能也是布鲁可逐渐放弃积木业务的主要原因。** 2022年拼搭角色业务崛起后,布鲁可的营销模式从“**重资金、堆推广**”转向**“重内容、促分享”**,如建立消费者交流社区布鲁可积木人Club,在各大平台邀请达人进行内容营销等,同时大幅增加经销商数量,增加线下消费者触达。 **随着布鲁可拼搭角色销售收入大幅提升,其销售费用不升反降**,到2023年销售费用下降至1.89亿元,对应销售费用率21.6%,同时规模效应导致公司研发费用、管理费用率同步下滑至5.6%、10.8%。2024上半年,布鲁可营收同比增长超200%,销售费用率、研发费用率进一步下降至11.5%、7.3%,管理费用率因计提3.64亿股权激励费用上升至38.6%,但剔除股权激励费用后仅3.8%,调整后期间费用率合计22.6%。 站在利润角度,布鲁可2021到2024上半年均处于亏损状态,但若**剔除可转换可赎回优先股公允价值变动损失、股权激励费用计提,公司在经营层面已经于2023年实现盈利**,**其2023和2024上半年的经调整利润分别为0.73、2.92亿元,**且2024H1经调整利润率达到27.92%。 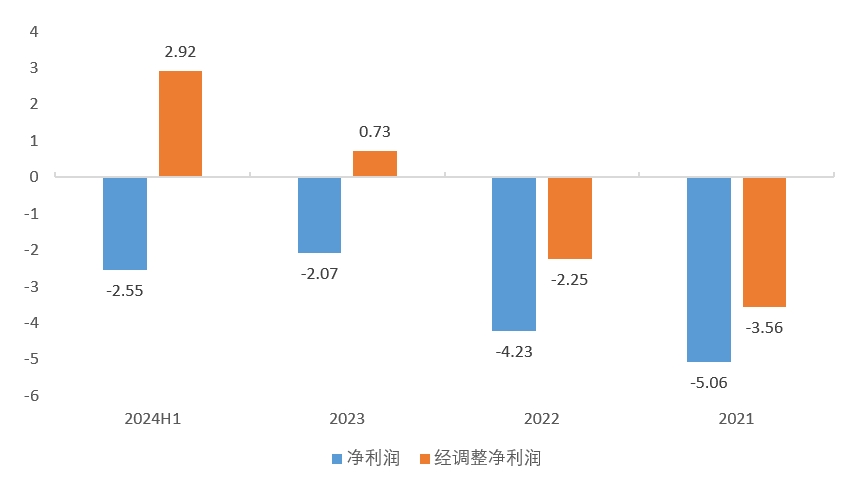 图:布鲁可净利润、经调整净利润 资料来源:公司公告,36氪整理 现金流角度,**布鲁可也从2023年起拥有造血能力。其2022、2023、2024H1的经营活动净现金流分别为-1.69、2.85、5.08亿元,**,其中2024上半年经营净现金流激增主要系应付账款上升所致。 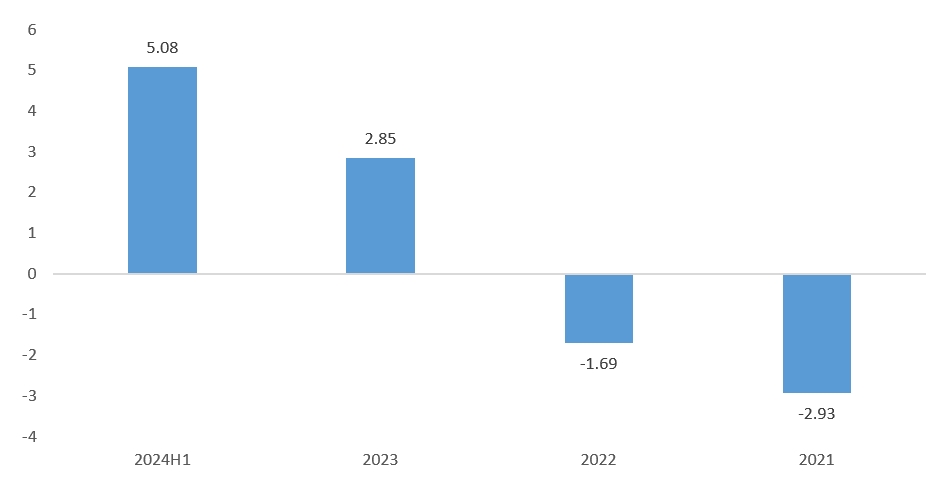 图:布鲁可经营活动净现金流 资料来源:公司公告,36氪整理 关于“可转换可赎回优先股公允价值变动”,可作如下简单理解:这是一笔带有对赌协议的借款,如果布鲁可成功IPO,则债权人有权选择将借款转为固定数量的普通股,从债权人身份转为股东身份。若未来股价(估值)上升,那么这部分普通股的股权价值会超过未转换前的债权价值,对原始债权人有利,而对布鲁可无益,因此布鲁可会在利润表计入公允价值变动损失。**由于布鲁可估值近年来处于持续上升状态,因此其相应计提的公允价值变动损失也更多,这也是公司巨额亏损,净资产偏低的主要原因。** ### **估值可以对标泡泡玛特吗?** 对于布鲁可的对标企业,市场往往选择泡泡玛特、万代作为比较对象。实际上,**布鲁可更像是万代和泡泡玛特的集合体,且其发展方向在向泡泡玛特靠拢。** 与万代相比,在IP端,布鲁可与万代类似,热销产品主要为知名动漫IP,如奥特曼、变形金刚、火影忍者、小黄人等。但与万代不同的是,布鲁可只拥有上述动漫的授权IP,万代则手握高达、魔神英雄传等动漫IP自有版权。在产品形态上,与万代的传统手办相比,布鲁可的拼搭角色玩具产品体积更小、单价更低,方便盲盒销售。 与泡泡玛特相比,在IP端,泡泡玛特的重心在自有IP,收入占比80%左右,布鲁可自有IP最新占比约17%左右,处于持续提升状态。在产品形态上,二者核心产品同样拥有体积小,单价低的特点,且主要以盲盒形式销售。但与泡泡玛特不同的是,布鲁可的产品在购回后需要手动拼搭,泡泡玛特则是成品。 2024年以来,泡泡玛特股价涨超300%,市值再度破千亿,动态市盈率超60倍。那么,布鲁可估值可以与其对标吗? **就稀缺性、独特性而言,布鲁可相较泡泡玛特仍有欠缺**。盲盒类产品无论是手办还是拼搭玩具,生产难度都不高,核心的壁垒在于IP和产品丰富度。IP方面,**布鲁可手中的授权IP并非独占, 这意味着其未来会面临比较大的同业竞争压力,如在部分线下经销门店中,奥特曼盲盒会同时呈列布鲁可、万代、灵动创想等多个品牌的产品,一定程度上削弱了布鲁可产品的竞争力。**而在自有IP方面,布鲁可主要通过动漫化等形式推广IP,而无法像泡泡玛特通过直营店快速强化自有IP形象。 **授权IP产品在营收中占比过高,也给布鲁可带来了一定的经营风险,被市场提及最多的就是IP续约风险。**目前,布鲁可核心的奥特曼IP在国内的到期年份为2027年,变形金刚在2028年,火影忍者、漫威、宝可梦等IP则在2025就到期。从各方利益来看,IP授权方通常会依据布鲁可的销售情况按比例提取分成。当布鲁可营收大幅增长时,授权方也能从中获益,理论上双方是相互依存的关系。然而,**如果同一授权 IP 下的产品竞争太过激烈,而授权方又处于强势地位,那么在续约时就可能提高授权价格**,这样就会增加布鲁可的成本压力。尽管当前授权IP成本占布鲁可营业成本比例约18.5%,占营业收入比例不到10%,处于较低水平,但不排除后续授权IP成本变高而影响毛利率。因此,授权IP风险也需要在估值中给予反应。 **最后从发展阶段看,二者当下分处于不同阶段,难分高下。**泡泡玛特海外业务扩张迅速,目前已跨入第二增长曲线,布鲁可仍以国内市场为主,尚处于初期增长阶段,因此难言哪家公司业绩增长更快。但从行业竞争角度来看,布鲁可非独占授权IP产品会比泡泡玛特自有IP面临更高的竞争压力。因此,反应到估值上,**布鲁可在稀缺性、未来经营的确定性方面,均要弱于泡泡玛特,因此,其上市后估值上限大概率就是泡泡玛特当前的动态市盈率水平**。目前,泡泡玛特动态市盈率约为60倍,按布鲁可上半年经调整净利润2.92亿元,全年6亿元估计,60倍市盈率对应估值已经达到360亿元人民币。 从布鲁可招股阶段发行市盈率看,其140亿港币估值对应动态市盈率约20倍+,定价实际上相对保守,目前其公开发行股份的认购倍数已经达到6000倍,如此火热的认购也间接证明了布鲁可发行估值偏低,布鲁可上市首日的大涨也证明了这一点。 但正如前文所述,**偏低的稀缺性以及经营模式所引发的一系列经营风险,使得泡泡玛特的PE成为了公司当下的估值天花板。** 因此,**公司上市首日大涨后的估值波动,就体现出了市场的纠结状态**,如其市值一度上涨80%突破260亿港元,但目前又回落至220亿附近,涨幅约50%,对应经调整净利润约37倍的市盈率,低于发行市盈率与泡泡玛特市盈率的平均数。**总的来说市场情绪偏冷静,布鲁可也不存在明显的低估和高估。未来,布鲁可的走势短期内取决于谷子经济概念热度,长期则在于自有IP产品销售是否火热。** *免责声明: 本文内容仅代表作者看法。 市场有风险,投资需谨慎。在任何情况下,本文中的信息或所表述的意见均不构成对任何人的投资建议。在决定投资前,如有需要,投资者务必向专业人士咨询并谨慎决策。我们无意为交易各方提供承销服务或任何需持有特定资质或牌照方可从事的服务。

 人人都是产品经理 · 瑾益
人人都是产品经理 · 瑾益
 ## 一、店铺优化 ### 1. 店铺装修 在美团平台上,店铺装修是吸引顾客、提升品牌形象的重要环节。优秀的店铺装修不仅能够**提高进店率**,还能显著**增加订单转化率**。以下是几个关键要素的设计要点和最佳实践: **1)店铺招牌** 店铺招牌是顾客第一眼看到的部分,因此设计时需要格外用心。以下是几个关键点: - **提炼进店理由**:明确展示店铺的独特卖点,如“干净卫生”或“低卡健康餐” - **显眼性**:避免使用白色背景,选择鲜明的颜色以吸引眼球 - **美观与恰当**:确保LOGO设计既吸引人又符合品牌形象  **2)海报设计** 海报是展示店铺活动和促销信息的有效工具。设计时应注意以下几点: - **主题明确**:快速传达核心信息 - **视觉冲击力**:使用高质量图片和醒目配色 - **行动号召**:明确引导顾客参与活动或下单 **3)内容布局** 合理的店铺内容布局可以提高用户体验,增加下单可能性: - 将新品、套餐系列放在前面,方便顾客凑单 - 控制首页菜单分类数量在6-7个,避免过多复杂性 - 使用4字分类名称,简洁明了 **4)工具与模板** 美团平台提供了多种工具和模板,帮助商家轻松实现店铺装修: - “店客多经营神器”提供多样化的模板,商家可直接套用 - “经营神器”内置海报店招模板,简化设计过程 **5)成功案例** 以“格格外卖店”为例,通过以下优化措施实现了显著的业绩提升: - 更换LOGO和背景墙,使店铺更具识别度 - 利用banner位展示折扣套餐、辅食和甜品,满足顾客需求 - 优化引导栏,增加套餐、专场活动和折扣菜选项 这些改进不仅提高了用户体验,还促进了订单转化。数据显示,经过装修后的店铺**点击率增加了30%,订单量提升了20%**。 通过精心设计的店铺装修,商家可以在竞争激烈的外卖市场中脱颖而出,吸引更多潜在顾客,最终转化为忠实客户。记住,店铺装修不仅仅是美化外观,更是提升品牌形象和用户体验的战略举措。 ### 2. 菜单设计 在美团平台上,有效的菜单设计不仅能吸引顾客,还能显著提高下单率。为了打造一个高效且吸引人的菜单,我们需要关注以下几个关键方面:  **1)菜品分类** 合理的分类可以帮助顾客快速找到他们感兴趣的菜品。建议将菜单分为6-8个分组,每个分组的名称应控制在4个字以内,简洁明了。例如:“招牌菜”、“人气推荐”、“经典主食”等。这种结构既能展现店铺特色,又能满足不同顾客的需求。 **2)菜品描述** 精准而富有吸引力的描述可以激发顾客的购买欲望。描述应包含以下要素: - 主要食材 - 口感特点 - 特殊烹饪方法(如适用) - 营养价值(如适用) 特别值得注意的是,对于高端菜品,在描述中加入食材的特殊来源或产地信息,可以有效提升其价值感。例如:“精选澳洲进口牛肉,肉质鲜嫩,口感绝佳”。 **3)菜品排序** 合理的排序可以引导顾客的浏览行为,促进特定菜品的销售。通常采用以下顺序: - 热卖菜品 - 特价菜品 - 招牌菜品 - 常规菜品 这种方法可以充分利用顾客的浏览习惯,提高热销菜品的曝光率,同时也为新推出的菜品创造机会。 **4)价格策略** 灵活的价格设置可以满足不同层次的消费需求。可以考虑以下几种定价方式: - **渗透定价**:对新推出或主打菜品采用较低价格,吸引顾客尝试 - **组合定价**:设计套餐组合,提供不同价位的选择 - **评价定价**:根据顾客反馈和市场竞争情况动态调整价格 **5)引流品设置** 巧妙设置引流品可以延长顾客在店铺的停留时间,提高下单率。建议设置3-4个引流品,价格宜低于市场价,但需保证质量。例如,可以设置0.88元的小鸡腿,既能吸引顾客注意,又不会大幅影响利润率。 **6)招牌推荐设置** 突出展示店铺的招牌菜品不仅可以提高销量,还能塑造品牌形象。可以在菜单顶部设置专门的“招牌推荐”区域,使用醒目的图标或文字标记,配合精美图片展示,吸引顾客点击。 通过综合运用这些技巧,商家可以打造出一个既吸引人又实用的菜单,从而提高在美团平台上的竞争力。记住,菜单设计是一个持续优化的过程,需要根据顾客反馈和市场变化不断调整,以保持最佳效果。 ## 二、商品管理 ### 1. 引流商品 在美团平台上,引流商品是吸引顾客、提升店铺曝光度的关键策略之一。为了最大化引流效果,商家需要全面考虑商品的选择、定价、推广和库存管理等多个方面。 **1)商品选择** 引流商品的选择应基于以下标准: - **日常高销量**:选择店铺中最受欢迎的热销产品,确保广泛的顾客基础。 - **成本可控**:确保商品成本在可接受范围内,避免过度侵蚀利润。 - **代表性强**:选择能代表店铺特色和品质的商品,有助于塑造品牌形象。 **2)定价策略** 定价是引流商品的核心。常见的策略包括: - 设置极低价格:如0.01元或1元特价商品,吸引顾客点击。 - 组合销售:采用“首件低价,后续恢复原价”的方式,鼓励顾客购买多件。 **3)推广方式** 有效的推广能放大引流效果: - 平台活动参与:积极参与美团组织的各类促销活动,如“神抢手品类日”。 - 多渠道推广:利用美团提供的多种推广渠道,如官方直播、专题营销等。 **4)库存管理** 合理的库存管理至关重要: - **限量供应**:防止过度亏损,同时营造稀缺感。 - 动态调整:根据销售情况和市场反应,及时调整库存量。 **5)运营数据提升** 通过精心设计的引流策略,商家可以显著提升多项关键指标: - 订单量:麦当劳参与活动后,订单量同比增长179.9% - 用户活跃度:瑞幸咖啡的日活跃用户同比提升248.8% 这些数据充分证明了引流商品策略的有效性。然而,商家在实施过程中还需注意平衡短期引流效果与长期利润之间的关系,确保可持续发展。 ### 2. 价格策略 在美团的商品管理体系中,价格策略扮演着至关重要的角色。美团采用了多层次、动态的定价方法,根据不同阶段和市场需求灵活调整,以维持竞争优势。 美团的价格策略主要包括以下几个方面: - **竞争定价**:根据市场情况和竞争对手的定价,制定具有竞争力的价格,吸引消费者。 - **会员制度**:推出会员制度,会员可以享受更多的优惠和特权,提高客户忠诚度。 - **差异化定价**:针对不同的用户群体和需求,制定差异化的定价策略。例如,对于高频消费的用户,提供更多的优惠和会员制度;而对于低频消费的用户,则可能采取相对较高的定价。 - **动态定价**:利用大数据和算法,实现动态定价能力。通过分析历史交易数据、市场供需情况、竞争对手价格等信息,快速调整价格,以适应市场变化和优化用户体验。 - **低价策略**:在特定时期或针对特定产品,采用低价策略吸引消费者。例如,“拼好饭”业务就是通过低价优势抢占更多场景的流量入口。 - **下沉市场策略**:针对县域等下沉市场,采用更具竞争力的价格策略。2024年1月至8月,美团在县域等下沉市场的即时零售订单量同比增长54%,体现了这一策略的效果。 - **组合定价**:通过组合销售和捆绑销售等方式,实现收益最大化。例如,提供套餐组合,或者将不同服务打包在一起销售。 - **心理定价**:采用零头定价等心理定价策略,如将价格设为9.99元而非10元,给消费者造成价格更低的心理暗示。 通过这些多元化的定价策略,美团能够在激烈的市场竞争中保持优势,同时也能满足不同用户群体的需求,提高用户满意度和忠诚度。然而,美团也面临着价格敏感性、竞争压力和成本控制等方面的挑战,需要在保证用户体验和平台收益之间找到平衡点。 ## 三、营销活动 ### 1. 满减优惠 在美团平台上,满减优惠是一种广泛使用的营销策略,旨在刺激消费、提高订单量和客单价。随着平台规则的变化,满减活动的设置也需要相应调整,以确保商家利益和用户体验的平衡。 **1)设置技巧** 满减优惠的设置需要考虑多个方面: - **多档位设置**:提供不同消费层级的优惠选择,如“满50减5,满100减15,满200减40” - **合理门槛**:门槛应贴近商品价格分布,便于顾客通过选购1-2件主餐和附加品达成 - **阶梯式优惠**:鼓励顾客增加消费,如“满100减10,满200减30” - **周期性安排**:如每周固定时段或每月第一周,培养顾客消费习惯  **2)类型策略** 不同类型店铺的满减策略有所不同:  **3)搭配方式** 满减优惠可与其他营销活动结合使用: - 满减+折扣商品:如“满100减20,部分商品额外8折” - 满减+赠品:如“满200减50,加赠特色小吃一份” - 满减+积分奖励:如“满300减80,获双倍积分” **4)影响评估** 满减活动对订单量和利润的影响因店铺而异: - **订单量**:通常会显著增长,尤其在活动初期 - **客单价**:可能因顾客凑单而提高 - **利润**:短期内可能受影响,但可通过精算和调整实现双赢 通过合理设置满减优惠,商家可在美团平台上有效提升竞争力,吸引顾客下单,同时优化订单结构,实现长期可持续发展。 ### 2. 限时折扣 在美团平台上,限时折扣是一种高效的营销工具,旨在刺激即时消费和提高订单密度。商家可通过美团后台的活动中心轻松设置此类活动,通常选择热门商品作为折扣对象,设置1-2小时的短促时间,以制造紧迫感。成功案例包括: - **每日闪购**:每天固定时段推出超值折扣,培养用户习惯 - **周末狂欢**:周五至周日晚高峰期间,全场8折吸引休闲消费人群 - **节日特惠**:结合传统节日,推出主题折扣,如中秋节月饼买一赠一 这些策略不仅提升销量,还能培养用户粘性,为店铺带来长期效益。 ## 四、顾客服务 ### 1. 评价管理 在美团平台上,评价管理是提升店铺竞争力的关键环节。良好的评价不仅能吸引新客户,还能提高复购率,直接影响店铺的排名和曝光度。为此,商家需要采取一系列策略来优化评价管理: **1)好评获取策略** - **邀请评价**:利用美团后台的自动邀请功能,在订单完成后向顾客发送评价邀请。 - **优质服务**:确保产品和服务质量,从根本上减少负面评价。 - **奖励机制**:适度提供小礼品或优惠作为评价激励,但需遵守平台规定。  **2)差评应对方法** - **及时响应**:尽快回复差评,表明解决问题的态度。 - **礼貌沟通**:保持专业态度,避免争执。 - **问题解决**:提出具体解决方案,必要时提供补偿。 - **跟进反馈**:确认问题是否得到解决,询问顾客是否满意处理结果。 **3)评价规则** 美团平台制定了严格的评价管理规则,包括: - 禁止利益诱导好评 - 杜绝虚假评价 - 规范评价内容 违规行为可能导致不同程度的处罚,如禁止评价、评价隐藏、星级隐藏等。 **4)评价对店铺运营的影响** 评价直接影响店铺的排名和曝光度。研究表明:**好评率每提高10%,店铺订单量平均增长约5%-8%。** 此外,积极回复评价可显著提高用户满意度和复购率。数据显示:**及时回复评价的店铺,其复购率比未回复的高出约15%-20%。** 通过有效管理和优化评价,商家可以在美团平台上建立良好口碑,吸引新客户,留住老客户,从而实现持续增长。 ### 2. 投诉处理 在美团平台上,投诉处理是一项关键的顾客服务流程。美团设立了专门的投诉处理系统,以确保及时、有效地解决用户问题。以下是投诉处理的主要流程和原则: - **投诉接收**:美团客服每个工作日至少接收质量投诉8小时,服务投诉接收时限为3小时,详细投诉时限为24小时。 - **问题分析**:投诉处理人员准确分析投诉问题,了解原因并给出分析结果或预估解决方案。 - **解决方案**:采取有效措施,最大限度帮助消费者解决实际问题,满足消费者期望。 - **跟踪处理**:实时跟踪投诉处理情况,直至消费者获得满意答复。 - **反馈结果**:处理完成后,及时将结果反馈给消费者,并控制投诉结果的不良影响。 投诉处理遵循“理性原则”,要求处理人员以客观心态评估和处理投诉。整个过程强调理解、灵活和诚实守信,确保服务质量的可靠性和稳定性。处理时长因投诉性质而异,但美团致力于尽快解决用户问题,以维护平台声誉和用户体验。 ## 五、数据分析 ### 1. 销售数据 在美团平台上,销售数据分析是商家优化运营策略的关键环节。通过深入分析订单量、营业额和客单价等关键指标,商家可以全面把握店铺经营状况,为决策提供有力支持。  美团销售数据分析主要包括以下几个方面: - **订单量分析**:通过分析订单量的走势,商家可以识别销售高峰期和低谷期,从而制定针对性的营销策略。例如,在订单量较低的时段推出限时优惠活动,以刺激消费。 - **营业额分析**:营业额反映了店铺的整体销售收入。通过比较不同时期的营业额数据,商家可以评估营销活动的效果,优化产品定价策略。 - **客单价分析**:客单价是衡量店铺盈利能力的重要指标。通过分析客单价的变化,商家可以了解顾客消费水平和偏好,从而调整产品结构和促销方案。 - **转化率分析**:转化率反映了店铺将访客转化为实际买家的能力。通过分析转化率,商家可以评估店铺装修、菜单设计等因素对销售的影响,从而优化用户体验。 - **复购率分析**:复购率反映了顾客对店铺的忠诚度。通过分析复购率,商家可以了解顾客满意度和忠诚度,从而制定相应的客户维系策略。 美团平台提供了强大的数据分析工具,如“经营神器”,帮助商家轻松获取和分析这些关键数据。通过这些工具,商家可以: - 实时监控销售数据 - 分析销售趋势 - 发现潜在问题 - 优化运营策略 例如,通过分析订单量的周期性变化,商家可以预测高峰期的到来,提前做好备货和人力调配。同时,通过对比不同时段的客单价,商家可以发现价格敏感度较高的时段,从而调整定价策略。 通过深入分析销售数据,商家可以全面了解店铺的经营状况,及时发现问题,优化运营策略,从而在竞争激烈的市场中保持优势。 ### 2. 客户洞察 在美团平台上,客户洞察是优化运营策略的关键环节。通过分析用户的消费行为数据,美团能够精准识别不同类型的客户群体,从而提供更有针对性的产品和服务。具体而言,美团主要通过以下数据维度来进行客户洞察: - **消费频率**:分析用户的下单次数和间隔,识别高频用户和潜在流失用户。 - **消费金额**:研究用户的平均消费额度,确定不同消费层级的用户群体。 - **喜好偏好**:收集用户的搜索关键词和浏览记录,了解用户的口味偏好和需求倾向。 - **地理位置**:利用LBS技术,分析用户的居住和工作地点,为本地化营销提供依据。 通过整合这些数据,美团能够构建详细的用户画像,实现精准营销和个性化推荐。例如,针对高频用户,可能会推出会员专享优惠;而对于潜在流失用户,则可能通过定向推送重新激活。这种基于数据驱动的客户洞察方法,不仅提高了用户体验,也为商家创造了更大的商业价值。 ## 六、配送管理 ### 1. 配送时效 在美团的配送管理系统中,配送时效是影响用户体验的关键因素。美团采用了先进的算法来估算送达时间,该算法考虑了多个变量,包括: - **城市特性**:反映不同城市的交通状况和地理特征 - **配送过程分段累加**:考虑取餐、配送等各环节所需时间 - **距离**:计算餐厅与目的地之间的直线距离 为确保准确性,算法还设置了“三层保护时间”,选取四个计算结果中最长的一个作为预估时间,以降低骑手压力,提高预测可靠性。这种多维度的考量使得美团能够更精确地估算送达时间,从而提升整体配送效率和用户体验。 ### 2. 品质保证 在美团的配送管理体系中,品质保证是确保用户满意度和品牌信誉的关键环节。为实现高品质的配送服务,美团采取了一系列措施: - **配送员培训**:强化食品安全意识,规范操作流程 - **餐品保护**:采用保温材料和防漏包装,确保食品新鲜完整 - **配送设备**:配备专用保温箱和智能温控系统,维持适宜温度 - **全程监控**:引入GPS追踪和温度监测,实现实时监管 这些措施共同构成了一个全方位的质量保障体系,有效提升了配送服务的整体质量和用户体验。 作者:瑾益 公众号:瑾益 本文由 @瑾益 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自 Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

在所有商业公司的扩张中,加盟商模式几乎是最成熟且最快的扩张方式。截至2023年12月31日,加盟店占中国现制茶饮连锁店总数的91.9%。

China earlier this week renewed the auto trade-in program that allows consumers trading in old cars for electric and plug-in hybrid vehicles to be each entitled to a 20,000-yuan subsidy, higher than the 15,000-yuan subsidy given to those opting to replace their vehicles with new, fuel-powered cars.


 cnBeta全文版
cnBeta全文版
毫无征兆,今日特斯拉焕新Model Y正式上线中国官网。**官方对新Model Y相当自信,称“尽管对比”**。雷军也非常应景的回应了一句:好的。足见焕新Model Y的关注度,以及小米YU7的直接对标对象。 在外观方面,焕新Model 借鉴了赛博越野旅行车、赛博无人电动车中的设计灵感,整车造型更硬朗,线条更流畅。**新车的前脸造型、前后大灯、尾部扩散器、轮毂及后视镜均为全新设计,其中尾部搭载了全球首创的漫反射式尾灯。** **此次焕新Model Y提供了两个版本:** **后轮驱动版26.35万元,593公里续航里程(CLTC 预估)、5.9秒0-100 公里/小时加速、201公里/小时最高车速。** **长续航全轮驱动版30.35万元,719公里续航里程 (CLTC 预估)、4.3秒0-100公里/小时加速、201公里/小时最高车速。** 特斯拉表示,**焕新Model Y是史上续航最长的Model Y,长续航全轮驱动版续航最高719公里(CLTC预估),能耗低至11.9kW·h/100km,开1000公里中途只充1次电,15分钟可补充约250公里续航。** 首发版车型专属免费延保2年货4万公里,还有尾门徽章、迎宾踏板标识、手机充电底座文字标识、迎宾灯徽章投影等。 **舒适性配置方面,全新调校的悬架系统,配合车身稳定系统,粗糙路面滤振效果提升51%。** 焕新Model Y增加了**前后座椅加热、前排座椅通风**以及人体工学头枕。同时新增了环绕式氛围灯、后排座椅电动调节,**后排坐垫再加长15mm**。“一键折叠”后可实现2130+升储物空间;新增镀银涂层的全景玻璃车顶,防晒隔热能力升级。 音响采用16个扬声器,中音更饱满,沉浸感更强。同时新增全新静音系统,搭载双层声学玻璃,大幅降低胎噪路噪。 安全方面,除了标配的超大缓冲区、远端安全气囊,大比例使用的高强度车身选材与一体压铸工艺打造的超强刚性车身,让焕新Model Y车身刚性再提升。 新车上线当天,特斯拉还为Model Y/3新车主推出充电权益:Cybervault家充桩2.5折,或3年3万公里(以先到者为准)超充,1299元可二选一。 **按照特斯拉的说法,焕新Model Y将有以下卖点:** 超高颜值:贯穿式漫反射尾灯,忍不住多看一眼 超强操控:4.3秒百公里加速,操控丝滑又顺手 超长续航:开1000公里,只充1次电 超级舒适:座椅通风+静谧座舱+环绕式氛围灯 超级智能:常常OTA,月月开“新车” 安全满配:超强车身结构+比人类安全10倍的辅助驾驶功能 首发纪念:多处专属徽章标识+2年免费延保 [](//img1.mydrivers.com/img/20250110/853459b9fd444544963f1ae789eab2b1.jpg) [](//img1.mydrivers.com/img/20250110/b9ef2f0b9c454d2ab7a170c29d70c79b.jpg) [](//img1.mydrivers.com/img/20250110/55c0eb2b5a4a4cab9e6c23cb370363cd.jpg) [](//img1.mydrivers.com/img/20250110/8c7400ca699243aebf4a0f6487d02089.jpg) [](//img1.mydrivers.com/img/20250110/a8da5d1b55b24bc8a5dc0d4cb7c77a95.jpg) [](//img1.mydrivers.com/img/20250110/7676f9cac2d84a039ef2fb1c72fc31c4.jpg) [](//img1.mydrivers.com/img/20250110/c6dd64bfe5ea4a4e98712699344e0850.jpg) [](//img1.mydrivers.com/img/20250110/73310fbd808a45c19f89a480fc0ce918.jpg) [](//img1.mydrivers.com/img/20250110/9c65cb6df17a49ff85ce8eb35cca91b9.jpg) [](//img1.mydrivers.com/img/20250110/65e9be1a871f4b24a4954fc0734e3541.jpg) [](//img1.mydrivers.com/img/20250110/12a3c3e94ac34fed999ab34ae0d61c50.jpg) [查看评论](https://m.cnbeta.com.tw/comment/1470020.htm)

 FreeBuf网络安全行业门户
FreeBuf网络安全行业门户


马力和智力的生态化反。 #欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。 [爱范儿](https://www.ifanr.com) |[原文链接](https://www.ifanr.com/1611724) ·[查看评论](https://www.ifanr.com/1611724#comments) ·[新浪微博](https://weibo.com/ifanr)

消息显示,1月8日,淘宝宣布已面向所有用户上线新功能“送礼”。唐辰注意到,淘宝App内,支持该功能的商品页面底部新增“送礼”选项。目前,可用于“送礼”的商品基本覆盖整个淘宝货盘,能满足多元化的送礼需求,货架形式也更适合用户挑礼物。或许是为鼓励用户尝鲜体验,天猫年货节大促期间,若送礼商品为参与年货节满减活动的商品,单件即可享受85折直降优惠。  根据个人体验,在点击商品页面底部的“送礼”按钮,下单购买礼物后,可自定义四位数的安全口令。随后就可以将安全口令和淘口令发送给收礼方,即为送出礼物。礼物时效为24小时,收礼人在这个期间复制淘口令,在淘宝App内打开,填写收货地址(可选择默认地址),并输入安全口令,即可收下礼物。  此外,在完成收礼物的步骤之前,收礼人还可以根据自己的喜好,自行更改同一价格商品的不同规格。而且,“淘口令+安全口令”的组合,不仅保障安全,还让淘宝“送礼”不局限于“好友关系链”,还可以通过微信、钉钉、短视频平台私信、短信等方式送给粉丝、同事等。 得益于2024年互联网巨头间的“拆墙”,淘宝“送礼”在微信上实现,消费者在微信内点开淘口令,可以直接唤起H5界面,并在微信端内收下礼物。但体验还是没有微信“送礼”丝滑,这是淘宝在“熟人社交场景”上的短板。 **淘宝此举被部分媒体解读是对微信小店的战略跟随。**因为半个月前,微信小店官方宣布灰度测试“送礼物”功能,除了珠宝首饰、教育培训类目以及原价高于1万元的商品外,其余微信小店商品将默认支持“送礼物”功能。 根据微信小店的规则,赠送方每次只能给一位朋友赠送一件商品,赠送后不支持转赠给其他朋友。而且一旦送出礼物后,不论朋友是否收下礼物,赠送方在24小时内都无法主动取消赠送或取消订单。若朋友超过24小时未收下礼物,订单将自动取消并退款给赠送方。 有最新消息透露,微信小店“送礼物”功能已经顺利完成灰度测试,已经正式面向用户推出。并且该功能的推荐权重大幅度提升。 目前,微信小店已经将“送礼物”功能提升至商品页Tab栏,与“加入购物车”和“购买”功能并列。这点和淘宝“送礼”的界面设置十分相似。**区别于微信“送礼”的“小蓝包”,淘宝“送礼”还是传统喜庆的“小红包”。** 唐辰曾在《微信小店上线,腾讯重做电商也不只为了做电商》一文中表示,腾讯手握着友商羡慕不来的社交流量,但多年来,始终没有能跑通其商业路径。 微信小店也就成了腾讯电商“全村的希望”,它将微信生态内分散在各个场景的电商流量串连起来,也就是打通了公众号、视频号、小程序、搜一搜等多个微信内部场景。通俗点说,微信生态内信息流与商品流,都在微信小店内形成闭环。 这相当于腾讯重新再做电商业务。**马化腾更大的野心在于,通过升级视频号电商,也就是微信小店,搭建出新的商业底座,打造微信的“电商生态系统”。** 业内普遍观点认为,依托微信强大的社交生态,以及中国传统的节日“送礼”需求,“送礼物”或将成为微信在电商业务上崛起的重要关口。 **微信“送礼物”之所以被广泛关注,最重要的价值点在于它的社交流量,微信 电商也成为行业最有价值的洼地,并且很有希望冲出来自成一极。** 但微信试图通过“送礼物”分食电商蛋糕,达到微信红包“奇袭”移动支付的效果,并没有那么容易。 **首先,电商和支付是两码事,对应的微信“送礼物”和微信红包也是完全不同的两个场景的产物,前者所需要的资源和专注远超后者。**除非腾讯下定决心,不设上限的投入,打通微信生态内的电商基建,“送礼物”才有可能成为抖音短视频内容那类的“核武器”,在已经板结的电商格局中,撬开一块市场。但目前看,微信对电商的期望很高,但动作一直很缓慢,也很佛系。 还有一个无法忽视的关键点:微信太重了。小程序、公众号、视频号等堆加在一起,就是“抖音+微博+图文内容平台+X”的巨型综合体。各类交易场景,已经很难做到纯粹,对用户的打扰,也是在所难免。 **其次,过高地预估了“送礼物”的作用。****该功能的优势不在交易,而是微信生态以及其社交流量。**如果“送礼物”的商品单价过高,那就是定向送礼。除了社交情绪的增益,也就是晒朋友圈或者截图“炫耀”,其对交易的拉动作用并不会太明显。 被多次引用的一组“送礼物”的数据来自抖音,2024年春节活动期间共有73万用户使用该功能,送出84万单礼品,总金额超过4000万元。 换算下来,单个礼品的价格在47元左右,这个门槛已经远远高于微信红包了。 微信红包也更像社交游戏,低门槛低限制,互动性高,社交壁垒的穿透性更强。比如“一分也是爱”的调侃,能吸引更广泛的用户参与。加之支付宝、抖音等平台加入,赋予中国传统意义的红包以科技含义。 **在唐辰看来,微信“送礼物”更实际的作用,是充当微信的一个流量或者营销工具,串联起营销、广告、增值等业务。这对碎片化的微信 电商场景来说,更具意义。** 一个可以肯定的判断是,**微信“送礼物”对淘宝的压力,还远远达不到初代微信红包的强度,但淘宝也不得不防。淘宝开通送礼,最大的意义在于,给商家和用户提供了更多的互动工具,激活更多的消费群体。** 淘宝多年来建立起的大促心智,相对应商家也在淘宝上形成了“送礼”的商品和服务能力体系,过节上淘宝买“礼物”是消费者的习惯。根据我掌握的数据,淘宝平台上平均每日有约140万用户搜索送礼相关词条,节假日时点送礼需求更是井喷。 **这比微信送礼更具场景价值,背后是更纯粹的货盘和消费生态,还有全面的支付、物流、售前售后等电商基础实施及能力保障。** 就在此刻,美团也加入“春节送礼”大战。显然,各大巨头都有自身的业务考量,至于最终效果,还得看用户买不买单。 对于平台来说,还有一个更好的产品功能改进思路,它来自速途网的一位老师:**“要礼物”可能比“送礼物”更有市场。** [查看评论](https://m.cnbeta.com.tw/comment/1470014.htm)

特斯拉焕新Model Y于中国大陆开启预售,同时上线首发版车型,预售价26.35万元起。新车拥有更长的续航、更低的能耗、更强劲的加速性能、更舒适的座舱,更安静的驾驶体验、更多更便捷的用车细节,同时安全、智能等硬核产品实力进一步提升。  **在性能上,**焕新Model Y百公里加速提升至最快4.3秒;结合整车多项优化,新车实现30多公里的续航里程提升,续航里程最高达719公里(CLTC预估),带来11.9Wh/km(CLTC工况) 的能耗表现。 **在座舱部分,**焕新Model Y**整车静谧性****大幅提升,**在前后侧车窗搭载双层声学玻璃的基础上,整车密封条、隔音材料等均进行了优化,有效隔离外部道路噪音,让车辆的路噪降低 22%,风噪降低 20%。**新增环绕式氛围灯****,**多色氛围灯从中控台延伸至侧门板,车里“看起来”更宽敞。**新增前排座椅通风****,**采用特斯拉专利的风道设计,可通过手机应用程序提前开启前排座椅通风功能,或设置为根据温度控制系统,自动调整风量。 此外,在原款Model Y后排座椅加长30mm的基础上,焕新版车型再加长15mm,持续优化座椅软硬度与支撑性,搭配加宽17mm的更优头枕,造型更贴合,减缓长途乘坐过程中的疲劳感。**新增后排8英寸控制屏****,**标配前15.4 英寸触摸屏+后8英寸触摸屏,支持蓝牙连接。可以在任意座椅位置听歌、放电影、玩游戏,还能控制座椅加热、调节空调风量等。焕新Model Y**自研音响系统升级****,**配有包括1个低音炮在内的16个扬声器(焕新Model Y长续航全轮驱动版车型),采用隐形扬声器设计,中音区的声音效果有所提升,带来更多的声音细节和更清晰的声学方向感。后排设置两个USB-C快充接口,支持快充,可同时为两台Macbook充电。 **在****智能安全****上,**进一步提升整车车身刚性,通过大比例使用高强度钢,结合一体压铸后底板,打造出坚固强壮的车身“骨骼”,配合超大缓冲区,更好地吸收事故撞击中产生的能量,显著降低车内乘客在碰撞中受到直接冲击的风险。其中,一体压铸式车身后底板将所需零件数量从 70 个减少到 1 个。同时前后排安全带位置进行了优化,前排安全带位置降低27mm,后排安全带位置优化,主动安全功能可以在事故中帮助降低碰撞严重程度,甚至避免碰撞事故发生。前撞预警、自动紧急制动、车道偏离防避等主动安全功能均为标配。 全车共搭载8个摄像头,包括前保险杠下方新增1个盲区摄像头。在车内中控屏幕上可以直接看到车头下方的盲区,驾驶时可以直观且清晰地看到车前影像,还支持自清洗功能。 此外,Model Y全系配备特斯拉最先进的自动辅助驾驶硬件(AI 4),看得更远、看得更清、算得更快。目前,搭载AI 4硬件的Autopilot自动辅助驾驶,开启后让行车安全达到普通车辆的10倍以上。还新增了盲点监测功能,车门内侧搭载盲点警报灯,配合触摸屏中的可视化图像,安全检查周围环境。  [查看评论](https://m.cnbeta.com.tw/comment/1470012.htm)
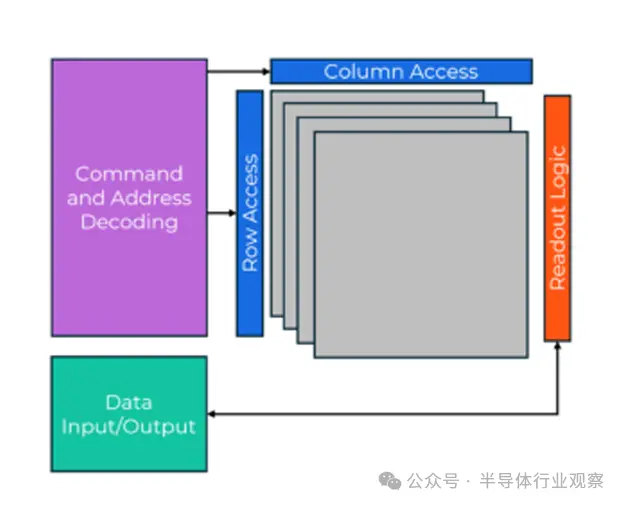
在本届的CES,黄仁勋又一如既往地成为了明星。凭借着一系列全新的新产品,这家最炙手可热的公司成为了大家讨论的热点。那些能够与英伟达扯上关系的厂商,也希望借着这个机会大展所长。其中,来自韩国的三星和SK海力士无疑是最紧张之一。这一方面与他们作为存储龙头,所提供的HBM会否被黄仁勋所领导的英伟达采用,会成为影响他们公司未来发展的关键因素;另一方面,公司能否在英伟达新产品中获得机会,也会影响未来的走势。 本届CES上,就发生了一个“小波折”。 黄仁勋在介绍新款显卡(GPU)RTX 50 系列时提到“采用了美光 GDDR”。由于包括英伟达在内的半导体公司在推出新芯片组时通常不会指定内存供应商,这一不寻常的举动引发了极大的兴趣和争议。 随后,在一场新闻发布会上,一名韩国记者向黄询问为何专门选择美光科技。黄回应称,“据我了解,三星电子和SK海力士不生产图形内存。”(原文:"I understand that Samsung Electronics and SK Hynix do not manufacture graphic memory,"),这引起了轩然大波,因为三星电子是全球第一家开发 GDDR7 的公司。 随后,黄仁勋发布官方声明澄清情况:“GeForce RTX 50 系列配备了各个合作伙伴制造的 GDDR7 显存,首先是三星。”(原文:The GeForce RTX 50 series is equipped with GDDR7 memory manufactured by various partners, starting with Samsung。)这一更正解决了最初的说法,即美光科技(而不是三星电子)将提供最初的数量。 那么,这个GDDR ,又是什么呢? **GDDR,是什么?** GDDR是Graphics Double Data Rate的简称,也就是双倍数据速率 (DDR) 内存。 作为一种专门用于图形卡 (GPU) 上的快速渲染技术。GDDR 于 2000 年推出,是目前使用的主要图形 RAM。GDDR 在技术上是“GDDR SDRAM”,取代了 VRAM 和 WRAM。每一代 GDDR 都速度更快,并包含增强功能;但是,尽管基于 DDR 内存,但 GDDR 版本在数字上并不与 DDR 相对应。例如,GDDR3 基于 DDR2 芯片;GDDR5 基于 DDR3 等等。 虽然GDDR借鉴自DDR,但它与 DDR 的主要区别在于内存总线大小和带宽。GDDR 是针对现代显卡使用的带宽进行优化的内存,例如 GDDR6 和 GDDR6X,仅在高端消费级 NVIDIA GPU(如 4090)中发现。GPU 处理大量重复和线性工作负载(如数学计算)并并行传输数据;需要更大的位总线和更高的带宽来防止出现瓶颈。否则,我们的视觉资产将无法加载,或者依赖数据的 AI 训练必须等待模型参数更新。 DDR内存广泛用于传统计算系统,主要用于支持 CPU。它针对通用计算进行了优化,可执行需要快速访问时间和最低延迟的任务,是运行应用程序和操作系统进程等活动的理想选择。 另一方面,GDDR内存专门用于图形处理单元 (GPU)。GDDR 主要关注带宽而非延迟,专注于由 GPU 管理的并行任务,这些任务使用精简指令集计算 (RISC)。RISC 架构通过管理重复的线性工作负载来简化处理,非常适合图形渲染和 3D 模型计算。这种设计使 GDDR 能够处理大量数据传输,这通常是图形密集型应用程序所必需的。  总而言之,GDDR 的优势在于其更宽的内存总线和更高的带宽: **内存总线大小和带宽:**GDDR 更宽的内存总线可容纳 GPU 操作所需的大量数据传输,处理游戏图形、高分辨率视频渲染和深度学习模型等工作负载。NVIDIA RTX 4090 等 GPU 中的高级 GDDR 版本(如GDDR6 和 GDDR6X)通过扩大带宽来实现这一点,从而在视觉计算任务中提供更流畅、更强大的体验。 **并行处理能力:**由于 GPU 擅长并行处理(同时在多个内核上执行大量计算),因此 GDDR 经过优化以支持这一点。如果带宽不足,GPU 可能会面临瓶颈,从而降低帧速率并延长渲染时间。GDDR 的高带宽使 GPU 能够满足 3D 渲染、图像处理等数据需求,从而避免这些瓶颈。 **高端应用:**在 AAA 游戏和 VR 等高性能图形应用中,对高带宽的需求非常巨大。GDDR 的高速数据访问和宽内存总线可满足这一需求,使其成为保持高帧率和精细视觉效果的关键。 GDDR 7,则是2024年三月发布的最新版本规格标准。  **GDDR 7,新一代标准** 据介绍,最新一代 GDDR 带来了内存容量和内存带宽的结合,后者主要由内存总线上切换到 PAM3 信号驱动。最新的图形 RAM 标准还增加了每个 DRAM 芯片的通道数量,增加了新的接口训练模式,并引入了片上 ECC 以保持内存的有效可靠性。 如前所述,GDDR7 最大的技术变化在于内存总线从 2 位不归零 (NRZ) 编码转换为3 位脉冲幅度调制 (PAM3) 编码。这一变化使 GDDR7 能够在两个周期内传输 3 位数据,比以相同时钟速度运行的 GDDR6 多传输 50% 的数据。因此,GDDR7 可以支持更高的整体数据传输速率,这是使每一代 GDDR 都比其前代产品更快的关键因素。 第一代 GDDR7 预计以每针 32 Gbps 左右的数据速率运行,内存制造商之前曾表示,高达 36 Gbps/针的速率很容易实现。然而,GDDR7 标准本身为更高的数据速率留出了空间——高达 48 Gbps/针——JEDEC 甚至在其新闻稿中宣称 GDDR7 内存芯片“每台设备高达 192 GB/s [32b @ 48Gbps]”。值得注意的是,这比 PAM3 信号本身带来的带宽增加要高得多,这意味着 GDDR7 的设计有多个级别的增强。  深入研究规范,JEDEC 还再次将单个 32 位 GDDR 内存芯片细分为更多通道。GDDR6 提供两个 16 位通道,而 GDDR7 将其扩展为四个 8 位通道。从最终用户的角度来看,这种区别有点随意——无论如何,它仍然是一个以 32Gbps/pin 运行的 32 位芯片——但它对芯片内部的工作方式有很大影响。特别是因为 JEDEC 保留了 GDDR5 和 GDDR6 每通道 256 位的预取,使 GDDR7 成为 32n 预取设计。  所有这些的净影响是,通过将通道宽度减半但保持预取大小不变,JEDEC 有效地将 DRAM 单元每个周期预取的数据量增加了一倍。这是扩展 DRAM 内存带宽的一个相当标准的技巧,基本上与 JEDEC 在 2018 年对 GDDR6 所做的一样。但它提醒我们,DRAM 单元仍然非常慢(大约数百 MHz),并且不会变得更快。因此,为更快的内存总线提供数据的唯一方法是一次性获取越来越多的数据。 每个内存芯片的通道数变化对多通道“clamshell”模式在更高容量内存配置中的工作方式也有轻微影响。在翻盖式配置中,GDDR6 从每个芯片访问单个内存通道,而 GDDR7 将访问两个通道 - JEDEC 称之为双通道模式。具体来说,此模式从每个芯片读取通道 A 和 C。它实际上与翻盖式模式对 GDDR6 的行为方式相同,这意味着虽然最新一代内存仍然支持翻盖式配置,但除了不断增加内存芯片密度之外,没有任何其他技巧可以提高内存容量。 就此而言,GDDR7 标准正式增加了对 64Gbit DRAM 设备的支持,是 GDDR6/GDDR6X 32Gbit 最大容量的两倍。非 2 的幂容量也继续得到支持,允许使用 24Gbit 和 48Gbit 芯片。对更大内存芯片的支持进一步将具有 384 位内存总线的理论高端显卡的最大内存容量推高至 192GB 内存——这一发展无疑会受到大型语言 AI 模型时代的数据中心运营商的欢迎。 对于其最新一代内存技术,JEDEC 还加入了几项新的 GDDR 内存可靠性功能。最值得注意的是片上 ECC 功能,类似于我们在推出 DDR5 时看到的功能。虽然我们无法从 JEDEC 获得关于他们为什么现在选择加入 ECC 支持的官方评论,但考虑到 DDR5 的可靠性要求,加入 ECC 并不令人意外。简而言之,随着内存芯片密度的增加,生产出没有瑕疵的“完美”芯片变得越来越困难;因此,添加片上 ECC 可让内存制造商在不可避免的错误面前保持芯片可靠运行。 在新标准发布之后,传统DRAM三巨头也发布了相应的产品。 **DRAM三巨头角逐** 因为GDDR7的需求大增,在2024年7月,全球先进内存技术领导者三星电子宣布,已开发出业界首款 24 千兆位 (Gb) GDDR7 1 DRAM。除了业界最高的容量外,GDDR7 还具有最快的速度,将其定位为下一代应用的最佳解决方案。 三星电子内存产品规划执行副总裁 YongCheol Bae 表示:“继2023年开发出业界首款 16Gb GDDR7 之后,三星凭借这一最新成果巩固了其在图形 DRAM 市场的技术领先地位。我们将继续引领图形 DRAM 市场,推出符合 AI 市场日益增长的需求的下一代产品。” 24Gb GDDR7 采用第五代 10 纳米 (nm) 级 DRAM,使单元密度增加 50%,同时保持与前代相同的封装尺寸。 除了先进的工艺节点外,三级脉冲幅度调制 (PAM3) 信号有助于实现业界领先的 40 千兆位每秒 (Gbps) 图形 DRAM 速度,比上一代提升 25%。根据使用环境的不同,GDDR7 的性能可进一步提升至 42.5Gbps。 通过将以前用于移动产品的技术首次应用于图形 DRAM,电源效率也得到了提高。通过实施时钟控制管理和双 VDD 设计等方法,可以显著减少不必要的功耗,从而使电源效率提高 30% 以上。 为了提高高速运行时的运行稳定性,24Gb GDDR7 采用电源门控设计技术来最大限度地减少电流泄漏。 三星表示,24Gb GDDR7 凭借其高容量和强大性能,将广泛应用于数据中心、AI工作站等需要高性能内存解决方案的各个领域,超越显卡、游戏机和自动驾驶等图形 DRAM 的传统应用。 在2024年六月,美光公司本月初开始提供 GDDR7 芯片样品,并表示这种新型先进内存将显著提升下一代图形处理器的性能。新幻灯片提供了有关预期性能提升的更多细节。 美光的GDDR7 内存预计将取代目前用于现代 GPU 游戏和 AI 工作负载的 GDDR6 和非标准 GDDR6X 芯片。这家总部位于爱达荷州的公司声称,采用 GDDR7 构建的显卡将在三种最常见的游戏分辨率(1080p、1440p 和 4K)下为光线追踪和光栅化渲染提供每秒超过 30% 的帧数。  根据美光的一份官方幻灯片(见上文),玩家可以期待下一代游戏的“无缝视觉效果”和显著更好的性能。幻灯片显示,GDDR7 内存芯片的性能比 GDDR6 应用程序高出 3.1 倍,比“同类最佳”的 GDDR6X 应用程序高出 1.5 倍。 美光还提供了一些“标准化 FPS”游戏基准测试,将当今的视频内存技术与 1080p Ultra、1440p Ultra 和 4K Ultra 设置下的 GDDR7 与未命名的游戏标题进行比较。 GDDR7 硬件似乎在光线追踪渲染场景中表现出色,与 GDDR6 相比,1080p Ultra 分辨率下 FPS 提升了 2.3 倍,4K 分辨率下提升了 3.1 倍。光栅图形的标准化 FPS 性能也得到了改善,1080p Ultra 分辨率下提升了 1.2 倍,4K Ultra 分辨率下提升了 1.7 倍(我们假设此类游戏中的设置是 Ultra,内存速度可能是一个更重要的因素)。 同样在2024年,SK 海力士宣布推出 GDDR7 图形内存,并声称这是“业界最好的 GDDR7”。它提供 32 Gbps 的运行速度,比当前一代 GDDR6 内存(限制在 24 Gbps 左右)快 60%。它还承诺将电源效率提高 50%,从而有可能降低使用这种新内存的下一代显卡的功率要求和产生的热量。 该公司通过使用新的封装技术实现了功率效率的飞跃。例如,它将散热基板层数增加了 50%(从四层增加到六层),使芯片能够更快地释放其累积的热能,而无需增加其使用的 PCB 面积。 除了游戏之外,SK 海力士还预计 GDDR7 内存将应用于其他行业,如 3D 图形、AI 加速任务、高性能计算、自动驾驶等。SK 海力士 DRAM 产品规划与支持负责人 Sangkwon Lee 表示:“我们将继续努力,进一步加强高端产品线,提升我们作为最值得信赖的 AI 内存解决方案提供商的地位。” **写在最后** 其实,韩国芯片行业对于黄仁勋说话表示的担忧,是非常容易理解的。毕竟在他说了一句量子计算还可以需要20年以后,与之相关的概念股IonQ 的股价一夜之间在纽约证券交易所下跌了 39%。其他量子计算机相关股票,如QuantumComputing下跌43.34%、RigettiComputing下跌45.41%、D-Wave Quantum下跌36.13%。 但是,从另一个角度看,整个行业都如此依赖一个厂商,我们是否需要思考一下原因和寻找更多的机会呢? [查看评论](https://m.cnbeta.com.tw/comment/1470010.htm)

韩国现代汽车集团周五宣布,与美国英伟达公司达成了战略合作伙伴关系,以开发与未来移动相关的先进人工智能(AI)技术。现代汽车集团表示,通过当地时间周四在美国拉斯维加斯签署的合作协议,将加强软件定义车辆和机器人技术等核心移动解决方案,并扩大人工智能技术在整个事业领域的应用。  具体来说,现代汽车计划利用数字孪生技术,在虚拟环境中模拟新工厂的建设和运营。通过这种方法,现代汽车将利用英伟达的数字孪生平台Omniverse来提高制造效率,提高质量并降低成本。 此外,现代集团将利用英伟达的加速计算硬件和生成式AI开发工具,建立具有大量数据的AI模型安全训练框架。 该汽车集团还计划使用英伟达的机器人平台Isaac开发AI机器人,并创建机器人训练所需的虚拟环境。 现代汽车集团全球战略办公室负责人Kim Heung-soo表示,“集团正在利用人工智能技术,在机器人、自动驾驶、智能工厂等多个领域进行创新。” 他补充说:“通过与英伟达的合作,我们的目标是巩固和加速这些创新,将自己定位为未来移动出行领域的领先公司。” [查看评论](https://m.cnbeta.com.tw/comment/1470008.htm)

韩国LG新能源公司(LG Energy Solution Ltd.)周五表示,已与美国电动汽车初创公司Aptera Motors Corp.签署了一份为期七年的电池供应协议。LG新能源在一份新闻稿中表示,该公司与Aptera Motors和韩国电池组制造商CTNS签署了一项三方协议,将在2025年至2031年期间向这家美国公司提供总计4.4 GWh的圆柱形电池。  LG新能源表示,这种圆柱形锂离子电池将安装在Aptera的太阳能电动汽车Aptera上,该电动汽车将于今年在美国市场上市。 CTNS将把LG新能源生产的圆柱形电池组装成电池组,供应给Aptera公司。 该公司透露提供合同的价值。 Aptera是一款双座三轮太阳能电动汽车,一次充电可行驶643公里。据新闻稿称,它有望成为首选的通勤车辆,因为它每天仅靠太阳能就能行驶64公里。 [查看评论](https://m.cnbeta.com.tw/comment/1470006.htm)