所有文章
 钛媒体 · 正见TrueView
钛媒体 · 正见TrueView

Japan scrapped the annual security talks due on July 1 after the Trump administration abruptly asked its Asian ally to raise the defence budget to 3.5% of GDP, higher than its previous request of 3%. Japan's top trade negotiator said negotiations remained "in a fog" despite both sides seeking to make a deal.
 cnBeta全文版
cnBeta全文版
近日,**大众式发布高尔夫GTI 50周年特别版官图。**新车对外观升级不多,依旧采用标志性的红色涂装,并对外后视镜、前后包围以及侧裙等处进行熏黑处理,尾部扰流板则增加了专属标识。   换装了19英寸锻造轮圈、Akrapovic钛排气管、以及普利司通半热熔轮胎等等,整体减重30公斤。   **另外还将针对底盘系统进行升级,高度降低20mm,并配备DCC自适应底盘控制系统,强化操控能力。**  新车配备红色安全带、深色门把手以及GTI 50专属标识,座椅依旧保留方格图案,并采用天鹅绒和真皮材质进行包裹。     动力部分,**该车搭载2.0T EA888 evo4发动机,最大可输出320马力,峰值扭矩420牛·米,匹配7速双离合变速箱,前轮驱动,0-100km/h加速时间仅需5.5秒,0-200km/h加速时间为16.8秒。** 值得一提的是,前不久,大众就是用了高尔夫GTI Edition 50成功征战纽北,仅用时7分46秒13完成纽北全程。 凭借该成绩,它比高尔夫R 20周年纪念版快了超1秒,更比上一代高尔夫GTI Clubsport S快了3秒多,**一举成为成为大众品牌在纽北“绿色地狱”赛道上圈速最快的量产车型。**  [查看评论](https://m.cnbeta.com.tw/comment/1508192.htm)
**根据微博平台显示,“大疆ROMO”官方账号已经上线,认证为深圳市睿炽科技有限公司。**据此前爆料,大疆扫地机器人产品上个月就已开始量产,预计本月发布。 [](//img1.mydrivers.com/img/20250621/11d846c950454628b15cd026c17db174.png) 消息称大疆研发扫地机器人已超过四年,即将上市的产品是扫拖一体机器人。 此前Igor Bogdanov曾展示了这款扫拖机器人的应用界面,**显示该机有望配备升降式LiDAR传感器。** **作为全球无人机行业领头羊,大疆在无人机领域积累的路径规划、视觉/激光雷达识别避障能力、高性能电机等,与扫地机器人的技术需求高度契合。** 这些相似的技术点,为大疆进军扫地机器人市场提供坚实技术基础。 [](//img1.mydrivers.com/img/20250621/0577bcbd-87f5-478c-9ee6-d2df8e69a597.png) 据IDC数据显示,全球智能扫地机器人市场2024年全年出货2060.3万台,同比增长11.2%,全年销额达93.1亿美元,同比增长19.7%,平均单价上涨7.6%至452美元,高端化升级持续深化。 其中第四季度全球扫地机器人市场出货591.8万台,同比增长7.8%,增速较前三季度放缓。 伴随2025年初头部厂商密集推出搭载AI导航、机械臂等技术的旗舰新品,今年行业市场将加速向智能化、一体化方向演进,大疆的加入或许会给科沃斯、石头科技等头部品牌带来一些压力。 [查看评论](https://m.cnbeta.com.tw/comment/1508190.htm)

自打沾上 AI 和大模型推理训练之后,在这个领域没啥对手的老黄,高端显卡眼瞅着越卖越贵。到头来,连带着我们这群臭打游戏的也遭了秧,想要高性能的显卡就得加钱……但是最近看到一条新闻,让我感觉摆脱老黄的统治,买上便宜的显卡,也不是没有可能。  事情是这样的,澳大利亚有家公司叫 Cortical Labs,推出了一台能将人类脑细胞与硅芯片结合的生物计算机,用人类神经元处理数据,直接 “ 活体计算 ”。 这个技术再发展发展,恐怕下一步就是培养出更接近大脑的器官,是不是感觉黑客帝国要上演现实版了?  但先别急,相信有不少人看到这里的第一反应,是质疑这件新闻的真实性,以及好奇这个事情的原理。接下来咱们一个个慢慢聊。 想要搞懂这个颠覆咱们认知的事情,得先确立几个基本的概念。 首先,将成熟的体细胞重新编程为多能干细胞,技术已经非常成熟了。早在 2012年,英国科学家约翰・格登(John B. Gurdon)和日本科学家山中伸弥(Shinya Yamanaka),就发现了 iPSC( 诱导性多能干细胞 )技术。  根据这个技术,理论上可以在体外大规模培养人体干细胞,还可以利用干细胞的全能特性,定向去诱导分化出具备特定功能的人体细胞。 而且利用 iPSC技术培育类器官( 如微型肝脏 ),或者修补受损组织等相关的医疗用途,可以说是很常见了。  其次,通过主动向细胞发送电信号、再收集记录细胞发出的电信号,可以实现硅基芯片与细胞之间的信息传递。 也就是,我们可以通过放电,告诉细胞目前发生了啥,还可以通过监测记录细胞的放电,搞明白它想表达啥。  明白这两点之后,接下来咱们就可以正式讲讲生物计算机的事了。 开头提到的 Cortical Labs 团队,将提取的人体细胞重新编程为干细胞,随后将它们诱导分化成了神经细胞,然后培养成有着真正神经轴突和树突的细胞集合,并且证实了这个“迷你大脑”是有智能的。 相关的论文,已经发表在神经科学领域极具权威性的期刊《Neuron》上。  简单来说,他们尝试让这个体外合成的人工智能玩经典的乒乓球游戏《Pong》。 如果球板击中乒乓球,那么系统就会产生一个可以预测的、规律的电刺激奖励;反之,就会产生一个不和谐的随机电流。结果发现,迷你大脑会为了追求可预测的电信号,自己琢磨明白了游戏规则。  当然世超本身并不是从事这方面研究的,还是看了 B 站 up 主@K形态生命科学关于实验的解析,才明白 Cortical Labs 团队具体都干了啥—— 他们用不同位置的电极刺激神经网络,用来代表乒乓球的位置;同时电极的刺激频率,代表着球距离球板的距离。同时微电极阵列还会感应神经网络的电流变化,以此来操控小球。  随着电刺激的反复进行,迷你大脑开始尝试移动球板,击中小球。并且球板并不是来回无意义地反复移动“碰运气”,而是恰好能出现在小球的移动路径上。  也就证明,这个迷你大脑意识到自己在玩游戏,而且随着时间的推移玩得越来越好了。 并且,团队也用电脑人工智能模拟了这个游戏,发现生物计算机的效率是电脑的500倍以上……  相较于电脑人工智能大模型,靠海量的数据运算和参数优化,才能模拟真实的神经网络,迷你大脑在自我学习的情况下,直接掌握了游戏逻辑。 这也意味着,丢给迷你大脑别的课题,它极有可能表现得比电脑人工智能更好。 正是在这个实验的基础上,Cortical Labs 团队推出了生物计算机 CL1。每台 CL1 装有大约 80 万个人类神经元,以及与它们交互的阵列电极。当然为了维持神经元的活性,还有配套的生命维持系统,负责调节温度、供给氧气等等。  那说了这么多,生物计算机到底有啥优势呢? 首先,相比较传统计算机,效率更高这一点,刚才的实验环节其实已经足够说明问题了。但是最新的 CL1 能发挥啥样的效果,世超这里也不好下定论。 毕竟售价也不是一般人能够负担得起的:单台 CL1 售价为 3.5w 美元( 约 25.1 万人民币 ),30 台起购,每台也要 2w 美元。目前看来,最主要的用途还是医学和 AI 相关的研发。 不过 CL1 也提供远程租赁的方案,每周 300 美元,就可以远程访问一台 CL1。目前已经正式开启租用服务了,如果哪位差友从事相关研究,用上了这台设备的,记得在评论区给世超解疑答惑一下……  另一个优势在于,生物计算机的功耗极低。单个 CL1 单元的功耗仅为 30 瓦,一个包含 30 个 CL1 单元的机架也仅消耗 850-1000 瓦的能量,远低于传统 AI 服务器。 其实再举一个直观的例子,会更方便大家理解,人脑平均功耗仅仅为 20 瓦左右,但与柯洁对弈的 AlphaGo,TPU 集群运行的功耗大约 160 瓦,而为了训练它所消耗的功耗,足够驱动上万个大脑连续运行…… 那么是不是可以畅想一下,未来的生物计算机,能开发出脑神经专用编程语言,效率直接起飞;或者通过神经细胞的自适应学习能力,补齐电脑人工智能在模糊感知任务上的短板。这样的话,也许训练AI,可以多一个选择,就不用上赶着找老黄买显卡了…… 但是生物计算机的发展,也面临一些道德伦理问题—— 虽说目前 CL1 系统的神经元数量,与人脑 860 亿的神经元规模相比不值一提……但是当类人脑器官的规模到一定程度后,是否会产生自我意识?所以,生物计算机能实现什么样的效果,这条路能不能走得通,还是让子弹再飞一会吧。 [查看评论](https://m.cnbeta.com.tw/comment/1508188.htm)

近日,爱尔兰政府宣布,位于戈尔韦郡图阿姆小镇原“仁爱之家”机构旧址的法医挖掘工作将于本月启动,一段被岁月尘封多年的黑暗历史即将重见天日。这一切的揭开,离不开当地历史学家凯瑟琳·科勒斯的执着坚持。 几十年来,她不断登报宣称自己的重大发现:**该镇“仁爱之家”的化粪池下埋葬着796名儿童的遗骨,这些孩子都是当年被教会以强制手段与家人分离后留下的。** 然而,她的发声却引来了爱尔兰政府和当地民间的攻击与骚扰。**直至2021年,爱尔兰政府才为这段不堪回首的历史正式道歉。** 本月开启的挖掘工作预计最长将持续两年。届时,这些孩子将得到体面的重新安葬,这段阴暗过往也将被正式铭记。 **凯瑟琳研究发现,1925年至1961年间,近800名幼童在“仁爱之家”不幸夭折。** 其中,仅有2名儿童被合法安葬在附近公墓并登记在册,其余796名儿童的遗骨竟被随意丢弃在化粪池中。 凯瑟琳的妹妹也被认为是受害者之一,她满心期盼能见到妹妹的遗骨重见天日。 事实上,“仁爱之家”并非个例,而是爱尔兰历史的一个残酷缩影。**在20世纪的大部分时间里,爱尔兰存在众多类似机构,它们有权强制收容未婚怀孕的女性,这些女性在当时被社会视为“堕落分子”。** 在机构中,她们被迫从事繁重劳动,产下的婴儿则被转卖。凯瑟琳的研究表明,这些机构内的儿童死亡率极高,许多孩子因营养不良和疾病离世。 [](//img1.mydrivers.com/img/20250621/b7590082b03a4ad486f95a5c09805580.png) [查看评论](https://m.cnbeta.com.tw/comment/1508184.htm)
据博主定焦数码爆料,**华为Pocket 2优享版即将上市,将换装全新处理器,价格有所降低,预计在6000元以内,支持国补。**此前华为Mate 70 Pro也曾推出过优享版,换装了麒麟9020A,性能略微有一些降低,同样降价并且支持国补。 [](//img1.mydrivers.com/img/20250621/f070f54831d144c1aba05eb1bdf2846c.png) **预计华为Pocket 2优享版也会搭载麒麟9020A,这是降频版麒麟9020处理器,前者规格为1*2.40GHz+3*2.00GHz+4*1.60GHz,后者为1*2.50GHz+3*2.15GHz+4*1.60GHz。** 参考华为Mate 70 Pro优享版,Pocket 2优享版其他配置也会继续保持不变。  **屏幕尺寸为6.94英寸,分辨率为2690*1136,支持1-120Hz帧率自适应刷新,440PPI。** 后摄采用全焦段XMAGE四摄,拥有5000万像素超感知主摄、超广角微距镜头、3倍光学变焦长焦,这也是业界首款支持3倍变焦的小折叠。 支持超强灵犀通信,并且还是首款支持双向北斗卫星消息的小折叠。  [查看评论](https://m.cnbeta.com.tw/comment/1508180.htm)

据京东方面消息,6月18日,京东物流举办沙特落地配送业务起网仪式,宣布在沙特推出全新自营B2C快递品牌“JoyExpress”。据悉,“JoyExpress”推出之后,当地消费者在电商平台购物后不仅可享受送货上门、货到付款,以及最快当日达、次日达等高时效快递服务,专业的本地客服团队也可随时提供咨询和服务支持。 此前京东物流旗下海外供应链服务品牌“JoyLogistics”已亮相, “JoyExpress”在沙特开启服务后,意味着京东物流在沙特已建立完整的从仓储到转运、分拣,再到“最后一公里”的物流网络,能为各类型客户提供快递、一体化供应链等全链条物流解决方案,这也是京东国际化战略的重要一步。  京东618JoyExpress送出沙特首单资料图 公开资料显示,目前“JoyExpress”在沙特不仅可提供地址修改、退货暂存、预约派送、逆向产品上门揽收、保价服务等,还可提供跨境运输、清关服务、海外本土运输服务等多种服务,可覆盖沙特大多数地区并将持续拓展服务范围,团队包含专业快递员、司机、仓储、阿拉伯语客服等各类型员工。 京东物流中东区相关负责人表示:“JoyExpress的推出是京东物流国际化进程中的一个重要里程碑,也与沙特阿拉伯的‘2030愿景’战略相契合。我们将秉持‘成本、效率、体验’的服务理念,将持续加强在沙特业务布局,并结合沙特的物流痛点,将我们的创新性和优质服务带到沙特,并持续提升我们在服饰、电子产品和生鲜商品等领域的行业供应链物流能力。” 根据Mordor Intelligence的数据,预计2025年至2030年,沙特的快递、速递和包裹 CEP市场规模将以6.48%的复合年增长率增长。同时,沙特也在建设全球物流强国。 [查看评论](https://m.cnbeta.com.tw/comment/1508174.htm)
 机核 · 核聚变游戏嘉年华,西蒙
机核 · 核聚变游戏嘉年华,西蒙 京西电竞节 x 核聚变游戏嘉年华即将开幕,热门新游试玩、精彩舞台活动、限定周边收集、沉浸式体验最热烈的玩家氛围!6 月 28、29 日,我们北京首钢国际会展中心见! [<获取核聚变2025北京站门票>](https://show.bilibili.com/platform/detail.html?id=102863) 感谢大家对本次活动的支持! 核聚变游戏嘉年华 2025 北京站首日门票(6 月 28 日周六场次)现已全部售罄,目前活动第二日门票(6 月 29 日周日场次)仍在销售中,门票余量有限,请想来核聚变现场的小伙伴,提前制定出行计划并购买门票。 如有购买 6 月 29 日周日场次门票需求,请访问“核聚变游戏嘉年华 2025”唯一票务合作平台“哔哩哔哩会员购”,通过线上售票页面,了解最新门票信息。   # 展会详情 展会时间: - 2025 年 6 月 28 日(周六)9:00-17:00(16:00停止入场) - 2025 年 6 月 29 日(周日)9:00-17:00(16:00停止入场) 展会地点: - 北京石景山·首钢国际会展中心 1/2 号馆 票务信息: - 单日票:全价 139 元/人 | 优惠票价 129 元/人 - 票务平台:哔哩哔哩会员购 - 特别说明: 凡在哔哩哔哩会员购购买核聚变门票的玩家们可以到现场兑换「实体纪念票」,本次门票为纪念品,不具备入场功能,现场入场请以“电子票”为依据携有效身份证件入场哦~ [<获取核聚变2025北京站门票>](https://show.bilibili.com/platform/detail.html?id=102863) 
 人人都是产品经理 · PM维他命
人人都是产品经理 · PM维他命
<blockquote><p>在供应链管理中,“负库存”常常被误认为是一个系统错误或异常情况。然而,它背后可能隐藏着复杂的业务逻辑和策略选择。本文将从产品经理的视角,系统性地拆解“负库存”的概念、产生的原因、不同系统中的处理方式以及它对财务核算的影响。</p> </blockquote>  最近经常有一些朋友在产品交流群或者是私聊咨询我关于“负库存”的一些知识,刚好之前没写过这一块的内容,所以就趁此机会写一篇文章来拆解一下“负库存”,聊聊我对它的一些理解,也顺带解答一些朋友的疑惑。 早期我在刚入行的时候,我会认为“负库存”是一种很离谱的,很匪夷所思的东西,库存怎么会是负数的呢?所以,当时的第一印象就是:尽量规避,一定要让库存数量不为0。 但是随着工作时间越来越长,接触的业务场景和模式越来越多,我逐步理解和认同了“负库存”这件事情,并不会把它当做是一种一定要及时解决的问题。因为它的出现是有一定的道理,是有合理的业务诉求和场景的,并不是大家第一印象上的“BUG”或者“异常”。 负库存这个现象远比大家想象的复杂,它背后涉及的不仅仅是技术问题,更多的是业务逻辑和业务策略的抉择。这篇文章我会从产品经理的视角,最基础的概念开始,逐步深入到导致负库存的原因,对应的财务处理机制,以及不同系统间的差异化处理方式,系统性地拆解负库存这个话题。 ## 什么是负库存 简单来说,负库存就是指系统中某个商品的库存数量显示为负数,一般是因为销售的时候,销售数量大于系统的库存数量,所以导致剩余库存为负数了。 <blockquote><p>负库存实际上反映的是企业在某个时间点上,对特定商品库存的需求超过了现有库存量,同时又必须要满足需求量,以免阻塞业务。</p></blockquote> 这个定义听起来很抽象,让我举个例子来说明,这是引起负库存的最高频的原因之一。 比如在线下实体的业务场中,客户想要购买某款商品,但是商品当前在库存的库存是0,你先去找附近的同行或者供应商那边借了部分商品,然后先给客户开了一张销售出库单(销售数量为10件),系统库存就变成了-10件。等送走客户之后,你才有空回过神来,把采购入库单补录进去(采购数量为15件),此时库存的库存变成了5件。 从这个场景中来看,“-10件”就是负库存,它代表的不仅仅是一个负数,而是企业对这10件商品的销售承诺和未来的补货需求。 如果企业是严格遵循先入库,然后再出库的规则,理论上是不会产生负库存的。但是在实际的业务场景中,这种先出库,再入库的场景也比较常见,因为各种原因下需要先完成销售,再后置去做采购入库。所以很多进销存系统、ERP系统等都会支持这种业务模式,于是“负库存”也就变得比较常见,并非是异常。 ## 负库存产生的原因 理解负库存的产生原因,是设计有效解决方案的前提,库存的原因可以分为两大类:主动的业务策略和被动的管理问题。根据出现频率,我把这些原因进行了排序,希望能帮你快速识别问题的优先级。 ### 1. 销售业务导向的”先销售后采购”模式 这是最常见的负库存原因,也是有一定的业务合理性的。在某些特殊的业务模式中,负库存的场景是很频繁的。 典型场景包括: - 贸易公司代销:接到客户订单后立即确认,然后向上游供应商采购。 - 制造业按单生产:收到订单后才开始采购原材料并组织生产。 - 经销商紧急调货:为满足客户需求,先销售,然后从其他仓库调货。 某服装贸易公司代理多个品牌,当大客户下单购买某款冬季大衣100件时,公司库存可能只有30件。但为了满足客户需求和保持合作关系,他们会先接单,系统扣减库存100件,产生了-70件的负库存,然后紧急向品牌方采购70件补货。这种模式在服装、3C数码、家居等行业非常普遍。 ### 2. 系统间数据同步延迟或失败 这是技术层面引发的一个问题,在多供应链系统协同的业务场景中,由于并发的问题或者是数据同步失败的问题,经常会出现类似的“负库存”问题。 常见的同步问题: - 多渠道销售同步延迟:线上商城、门店POS同时销售,库存扣减信息同步有时间差。 - 网络故障导致数据丢失:接口调用超时或失败,导致库存变动未及时反映。 - WMS库存变动回传ERP:WMS发生了库存异动,需要回传异动结果给ERP,但是因为ERP和WMS库存有差异(ERP库存不足),导致负库存。  ### 3. 业务单据处理顺序错误,人为操作错误 在实际业务中,物理操作和系统单据处理往往不同步,这种时间差很容易造成负库存。同时人为操作的失误,例如说填写错数量,按实物出库而不是按单据出库等,也会导致负库存。 常见的问题: - 先实物后单据:货物已经出库,但出库单据还在审批流程中,未扣减系统库存。 - 退货处理延迟:客户退货已到达仓库,但退货入库单据处理滞后,实物已经加了,但是系统未增加库存。 - 调拨业务时差:A仓库已发货,B仓库已收货,但系统中调拨单据还未完全处理。 - 人为操作问题:采购入库的时候数量填少了(实物多于系统),但出库的时候按实际数量出库,就会出现负库存。 某服装企业的门店调拨场景:上午10点总部ERP生成调拨出库单,A门店库存扣减100件;下午2点货物运输到B门店;下午5点B门店确认收货,但由于系统维护,入库单未及时处理。此时如果A门店又有客户购买(实物已到店,但是未录入系统),就可能导致负库存。 ### 4. 系统BUG或程序错误 负库存的出现,也有可能和产品方案、技术方案设计有很大的关系,如果系统逻辑本身有BUG或者错误,那么就会导致库存不准确,出现负库存也就是很正常了。 常见的BUG或错误: - 库存计算逻辑错误:代码逻辑bug导致库存计算不准确 - 重复执行操作:同一个出库单被重复处理数据库 - 事务处理异常:事务回滚不完整或死锁问题 ## 负库存在不同系统中的意义和处理方式 在不同的供应链系统中,负库存的表现形式和含义会有很大差异,我们要先理解哪些系统出现负库存是合理的,哪些系统出现负库存是不合理的,这样才能更好地理解为什么有些系统要坚决控制负库存,而有一些则是要支持负库存。 在现代供应链体系中,进销存、ERP、WMS、POS等不同系统承担着不同的职责,它们对负库存的处理策略和容忍度也截然不同。 ### 1.ERP系统:有条件支持,灵活策略 ERP系统对负库存相对包容,主要因为它管理的是账面库存和业务流程,而非具体实物。当ERP中出现负库存时,往往反映的是企业的业务策略选择,比如预售模式、代销业务、先售后采等。 ERP会通过灵活的规则引擎来控制负库存:按商品类别设置不同策略(预售商品允许大幅负库存),按逻辑仓类型来设置不同策略(A仓库支持负库存,B仓库不支持负库存),同时ERP也会配备比较完善的成本核算机制处理负库存导致的财务问题。 ### 2.进销存系统:有条件支持,单据导向 进销存系统同样支持负库存,但侧重点是业务单据的流转。它的核心价值在于记录采购、销售、库存变动等业务活动,特别适合中小企业”先销售后采购”的操作习惯。 进销存的控制策略相对简单直接,一般是全局启用负库存、或者是按仓库、商品来控制是否启用负库存,然后可以配置某些单据下支持负库存,某些单据下不支持负库存。而在成本核算方面,一般都是采用先进先出或移动加权平均等方式,如果要准确核算负库存的成本,则需要在这一块做一些特殊处理。 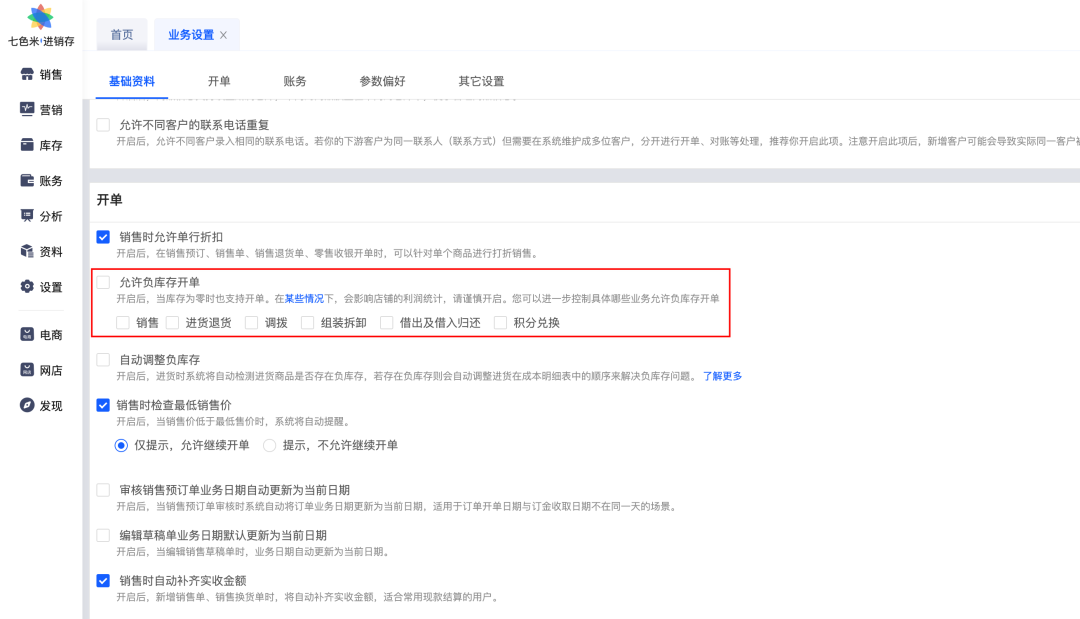 七色米:全局控制负库存  金蝶·星辰:按仓库控制负库存 ### 3.WMS系统:严格控制,零容忍 WMS对负库存采取”零容忍”态度,因为它直接管理实物库存。在WMS的逻辑中,每一次出库都必须有真实货物支撑,每个库位都要真实反映实物状态。 所以,当程序计算库存的时候,如果发现会导致库存为“负数”,那么就应该直接报错,拦截这种情况,不允许出现负数的库存。 ### 4.POS系统:严格控制为主,适度灵活 POS系统介于严格控制和灵活支持之间,需要平衡风险控制和客户体验。因为POS是直接面对终端客户,随意的负库存销售可能导致在线的O2O客户买了商品却拿不到货,影响品牌形象。但是在某些情况下,在收银端,如果客户已经拿着实物来结账了,那么此时系统中即使没有库存,也应该支持负库存开单销售。 所以对于POS系统来说,需要结合自身的实际业务场景来控制是否启用“负库存”,例如说在收银端的开单是支持负库存的,而其他出库、调拨出库、O2O出库等业务场景下,则不支持负库存操作。 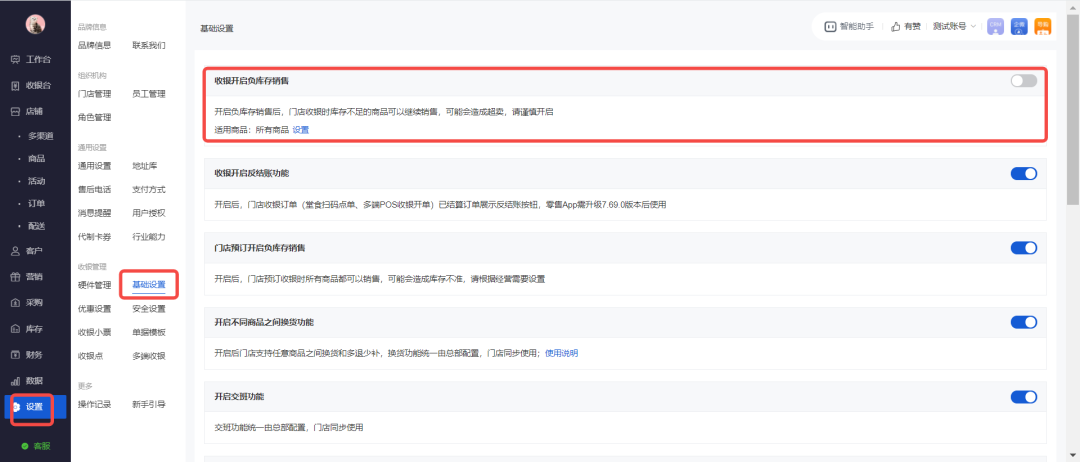 有赞:收银开启负库存销售 总体而言,要判断一个供应链系统是否支持“负库存”,可以遵循这样的一个原则:越接近实物操作的系统,对负库存容忍度越低;越偏向业务管理的系统,支持度越高。系统职责定位决定了负库存的处理策略。 ## 负库存带来的成本核算问题 很多产品经理在设计负库存功能时,往往只关注库存数量的变化,而忽略了背后的财务影响。但实际上,负库存对财务模块(成本核算)的冲击可能比你想象的更大。 ### 1. 成本核算的复杂性 当企业出现负库存销售时,财务系统面临的最大挑战是:不知道销售出库商品的实际成本是多少。这看起来是个简单的问题,但在实际操作中却相当复杂。 假设你目前的门店POS中某款手机壳当前库存为0件,由于开启了负库存销售,这时有客户购买了100件,系统扣减库存后显示为-100件。现在问题来了:这100件手机壳的销售成本应该如何计算? 很多零售公司会采用的移动加权平均法来处理负库存的成本核算。具体做法是:当出现负库存销售时,系统使用历史加权平均成本(最近一笔没有负库存的销售成本)作为暂时的销售成本,等到后续采购入库后,再根据实际采购成本进行差异调整。这种方法相对科学,既满足了会计准则的要求,又保证了日常业务的连续性。  ### 2. 成本差异的处理机制 负库存带来的另一个财务挑战是成本差异的处理。当企业使用预估成本进行负库存销售,后续实际采购时发现成本有差异,这个差异应该如何处理?  在实际操作中,通常有两种处理方式:一是直接调整销售成本,将差异计入当期损益;二是设立专门的成本差异科目,定期分析差异原因并进行管理优化。选择哪种方式主要取决于企业的会计政策和差异金额的大小。 负库存的财务处理必须与企业的财务团队充分沟通,确保符合会计准则和审计要求。我见过一些对财务逻辑不太敏感的产品经理在设计负库存功能时,完全没有考虑财务影响,结果在系统上线后引发了很多财务数据的问题,搞得特别难受。 ## 对负库存的常见误区和解决方案汇总 经过上面对负库存的拆解,相信大家对负库存的概念和业务场景,还有对应的产品方案要注意的细节有了一定的了解。 最后我总结一下,关于“负库存”最常见的几个误区,希望能帮你避免踩坑。 ### 误区一:把负库存当作纯技术问题 很多新手PM看到负库存的第一反应是”这肯定是程序bug,赶紧让开发修复”。这种认知是完全错误的。 正确认知:负库存首先是业务问题,其次才是技术问题。你需要先理解业务场景,判断这个负库存是合理的商业需求还是异常的管理问题,然后再决定技术解决方案。 ### 误区二:认为所有系统的处理策略应该一致 另一个常见误区是认为ERP、WMS、POS等系统对负库存的处理策略应该保持一致。 正确认知:不同系统有不同的职责和定位。ERP关注业务流程和财务核算,可以有条件地支持负库存;WMS关注实物管理,应该严格控制负库存;POS关注客户体验,需要在控制风险和提升体验之间找平衡。 ### 误区三:忽视财务影响 很多产品经理只关注库存数量的变化,完全没有考虑负库存对财务系统的影响。 正确认知:负库存会直接影响成本核算、毛利计算、现金流预测等财务指标。在设计负库存功能时,必须与财务团队充分沟通,确保符合会计准则要求。 ### 误区四:技术万能论 认为只要写好代码就能解决所有负库存问题,忽视了管理流程和业务规范的重要性。 正确认知:负库存管理需要技术手段和管理机制的结合。技术可以提供工具和平台,但具体的业务规则、处理流程、风险控制等仍然需要管理层面的支持。 ### 误区五:用户体验考虑不足 在设计负库存控制功能时,只考虑业务逻辑,没有充分考虑用户体验。 正确认知:当用户遇到库存不足的情况时,不应该简单地提示”库存不足”,而应该提供智能化的解决方案,如推荐替代商品、提供到货通知、显示预计到货时间等。 避免这些误区的关键在于:始终站在业务角度思考问题,用技术手段解决业务需求,而不是用技术逻辑替代业务逻辑。 作为供应链产品经理,理解和处理负库存问题是你的基本功之一。 希望这篇文章能帮你在这个复杂的领域建立正确的认知和方法论。 本文由人人都是产品经理作者【PM维他命】,微信公众号:【PM维他命】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。

6月21日,据《纽约时报》报道,今年2月,当美国总统特朗普签署行政令,因为调查以色列战争罪行制裁国际刑事法院(ICC)首席检察官时,软件巨头微软公司一下子卷入了一场地缘政治冲突中。  荷兰海牙的国际刑事法院 多年来,微软一直在为国际刑事法院提供包括电子邮件在内的数字服务。该法院位于荷兰海牙,负责调查和起诉侵犯人权等其他引发国际关注的罪行。然而,特朗普的行政令突然打乱了这种合作关系,因为该命令禁止美国公司向检察官卡里姆·汗(Karim Khan)提供服务。 不久后,微软协助关闭了卡里姆·汗在国际刑事法院的电子邮件账户,使他无法与同事进行联系。就在几个月前,国际刑事法院才因以色列在加沙的行动,对该国总理内塔尼亚胡发出逮捕令。 **欧洲震惊** 微软迅速遵守特朗普行政令的举动,令欧洲各国政策制定者震惊。这给欧洲敲响了警钟,因为这个问题远不止一个电子邮件账户那么简单,它引发了欧洲的担忧:特朗普政府可能会借助美国在科技领域的主导地位,惩罚反对者,即便像荷兰这样的盟友国家也是如此。 “国际刑事法院的遭遇说明,这种事真的会发生,”荷兰国防部前网络安全主管、现任欧洲议会议员巴特·赫鲁特赫伊斯(Bart Groothuis)表示,“这不再是幻想。” 赫鲁特赫伊斯曾经支持美国科技公司,但他说自己现在的立场已经发生“180度转变”。“我们必须站在欧洲的立场上采取更多行动,捍卫我们的主权。”他表示。 据三位知情人士透露,国际刑事法院的一部分人目前已开始使用瑞士公司Proton提供的加密电子邮件服务。  微软冻结了卡里姆·汗的邮件账户 微软表示,冻结卡里姆·汗电子邮件账户的决定是与国际刑事法院协商后作出的。该公司还表示,在该事件发生之前,公司就已在筹划政策调整,现在已实施以便今后在类似地缘政治情况下更好地保护客户。微软补充称,本月,特朗普政府又对四名国际刑事法院法官实施制裁,但这些人的账户并未被停用。 微软总裁布拉德·史密斯(Brad Smith)表示,这起事件所引发的担忧只是美欧之间“更大信任裂痕的一个表现”。“国际刑事法院的问题只不过是火上浇油。”史密斯称。 目前,卡里姆·汗正因不当性行为接受调查,自上个月起已被暂停职务。他否认了指控。 国际刑事法院发言人表示,法院正在采取措施“降低可能影响法院工作人员的风险”,并“采取广泛行动,确保在面临制裁的情况下所有相关业务和服务能够持续运作”。 **科技争执雪上加霜** 这起事件在整个欧洲引发了警觉,从中可以看出欧洲各国政府、企业和人民在关键数字基础设施方面对微软等美国科技公司的依赖程度之深,以及想要摆脱这种依赖有多么困难。欧洲担心,特朗普可能会利用科技霸权来获取政治优势,促使该地区加快了开发替代方案的步伐。 曾任丹麦外交官及欧盟外交官、并在微软工作过的卡斯珀·克林厄(Casper Klynge)表示,从很多方面来说,这起事件正是“许多欧洲人一直在寻找的确凿证据”。也就是证明美国可能滥用科技霸权的证据。 “如果美国政府要针对某些组织、国家或个人采取行动,美国公司可能就必须配合,这令人担忧,”现任职于一家网络安全公司的克林厄表示,“这已经产生了深远影响。” 科技领域的争议,导致美欧在贸易、关税以及乌克兰战争等问题上本就日益紧张的关系愈发对立。特朗普与美国副总统万斯曾批评欧洲对美国科技公司的监管方式,而美国官员则已将数字监管和纳税纳入正在进行的贸易谈判中。 欧洲监管机构则表示,他们需要有能力在本国监管大型数字平台,而不必担心会遭受外国政府的政治施压或报复。 “如果我们不在欧洲内部建立足够的能力,那么我们将无法再做出政治决策。”欧洲议会议员亚历山德拉·盖泽(Alexandra Geese)表示。 自2013年斯诺登曝光美国“棱镜”监听丑闻以来,欧洲人一直在努力减少对美国科技的依赖。欧洲立法者与监管机构将苹果、Meta、Google等企业视为打击目标,批评它们存在反竞争商业行为、侵犯隐私的服务,以及散布虚假信息和其他具有分裂性的内容。 然而,由于缺乏可行的替代方案,欧洲各国机构仍不得不依赖美国的数字服务。根据研究公司Synergy Research Group的数据,亚马逊、Google、微软等美国公司控制了欧洲超过70%的云计算市场,而云计算正是储存文件、检索数据和运行各类程序的必要方式。  微软CEO纳德拉 据一位不愿透露姓名的国际刑事法院律师称,国际刑事法院长期以来一直是微软的客户。微软为该法院提供Office办公软件套件、证据分析与文件存储软件等服务。微软还向该法院提供了网络安全软件,以帮助其抵御来自俄罗斯等对手的网络攻击。 今年2月,在特朗普对卡里姆·汗实施制裁后,微软与国际刑事法院官员会面,商讨如何应对。他们最终决定,微软对法院的整体服务可以继续,但卡里姆·汗的电子邮件账号应被冻结。据一位与他有通信往来的人士透露,他随后将通信转移至另一个电子邮箱账户。 专门研究制裁合规问题的律师萨拉·伊丽莎白·迪尔(Sara Elizabeth Dill)表示,特朗普政府越来越多地利用制裁和行政命令来打击国际机构、大学以及其他组织,迫使企业在合规方面做出艰难选择。 “这简直是一片泥潭,把这些公司置于极为困难的境地。”迪尔表示。她还指出,全球化科技公司如何应对尤其重要,“因为人们和各种组织最担心的正是它所产生的广泛而又深远的影响”。 **寻找替代服务** 微软与其他美国公司一直试图安抚欧洲客户。周一,微软CEO萨蒂亚·纳德拉(Satya Nadella)访问荷兰,并宣布为欧洲机构推出新的“主权解决方案”,其中包括在“地缘政治动荡时期”提供法律和数据安全保护。亚马逊与Google也已宣布了面向欧洲客户的相关政策。 尽管如此,许多机构仍在寻求替代方案。荷兰内政部数字化事务国务秘书埃迪·范·马鲁姆(Eddie van Marum)在一份声明中表示,“数字自主与主权议题已引起中央政府的高度重视”。他说,荷兰正与欧洲服务商合作,开发新的解决方案。 在丹麦,数字事务部正在测试可替代微软Office的工具。在德国,北部的石勒苏益格-荷尔斯泰因州也在采取措施,减少对微软产品的依赖。 在欧盟,官员们已宣布计划投资数十亿欧元,用于建设新的AI数据中心和云计算基础设施,以减少对美国公司的依赖。荷兰籍欧洲议会议员赫鲁特赫伊斯表示,欧盟立法者正在讨论政策调整,以鼓励各国政府优先采购来自欧盟本土公司的科技服务。 “目前的局面难以为继,我们看到欧洲各国政府正大力推动提高独立性和韧性。”Proton CEO严育铨(Andy Yen)表示。 这也让欧洲科技公司看到了从美国竞争对手那里夺取客户的机会。荷兰云服务提供商Intermax集团和瑞士Exoscale公司表示,他们在近期获得了大量新业务。 “几年前,大家还在说,他们(美国科技公司)是我们值得信赖的伙伴。”Intermax CEO卢多·巴乌(Ludo Baauw)表示,“但现在已经发生了根本性变化。” [查看评论](https://m.cnbeta.com.tw/comment/1508172.htm)
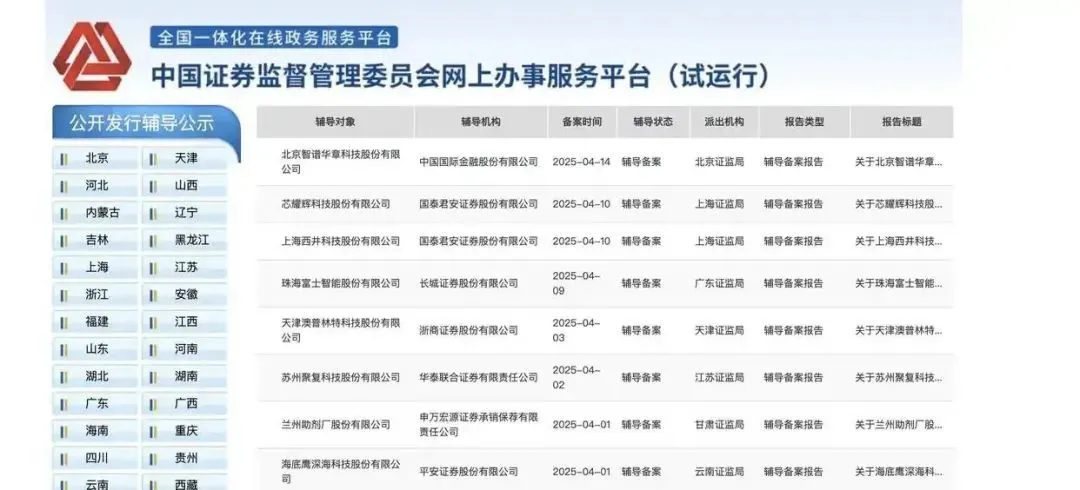
“六小龙里已经有五家在筹备上市了。”某头部创投机构合伙人李铮(化名)向字母榜透露了这个消息。继智谱传出IPO消息之外,近日媒体爆料稀宇科技(MiniMax)正考虑在香港进行首次公开募股(IPO)。根据澎湃新闻报道,接近MiniMax的知情人士表示,MiniMax内部确实有类似想法,但目前仍处于初步筹备阶段。 但其实“六小龙里五家都早已开始接触投资机构募资,规模都在五亿美金以上,都进入初步筹备阶段了。”李铮表示。 MiniMax和智谱并非唯二筹备上市的大模型创企,而随着国内上市标准的进一步放宽,六小龙中五家争抢“大模型第一股”的局面也势必形成。 根据路透社报道,在2025陆家嘴论坛上,中国证监会宣布计划在上海以科技股为主的科创板设立新板块,以容纳尚未盈利的成长型企业。其中不仅重点提到人工智能企业,更提及将重启未盈利企业适用科创板第五套标准上市,“也就是说,即使现在仍在亏损、盈利不足的大模型创企也有机会上创业板了。”李铮补充道。 根据《智能涌现》报道,一名百川智能员工记得,百川创始人王小川去年就曾在他在内部会上说,2025年目标把业绩做到上市门槛(10亿元),拿到绿通(绿色通道名单)就随时能上市。对于六小龙而言,先敲钟者是谁或许还未落定。 无论是港股还是A股,对六小龙来说,眼下无疑是争夺“大模型第一股”的绝佳机遇。对于仍在筹备期的后来者而言,先传出IPO的智谱,似乎未必是最后的赢家。 2025年,挣扎求生的AI六小龙都在等一个“鲤鱼跃龙门”的机会——上市。 4月14日,智谱正式向北京证监局提交上市辅导备案,由中金公司担任辅导机构。成为六小龙中首家启动IPO进程的企业。 创建于2019年的智谱最早传出上市消息,一个关键因素就是满足了基本条件,即企业连续经营3年以上。紧随其后在6月被爆筹备上市的MiniMax创建于2021年12月,也因为成立日期较早,满足了这项基本条件。而由于其余几家都创建于2023年中后到2024年年初,因此并不满足“创建3年”的要求。 不过,抢跑的智谱未必能成为“大模型第一股”。 近半年来,字母榜从不同机构的投资人处分别得知,六小龙中,已有五家还未明确推进IPO,但已经频繁接触投资人,释放出上市的信号。其中智谱最先传出了备案的消息。  但论抢时间,智谱未必有先发优势。根据智谱的备案计划,智谱的上市辅导分三阶段推进:4月完成摸底调查与方案制定;5月至7月聚焦规范整改与持续尽调;8月至10月进入冲刺期,筹备上市申请文件。也就是筹备IPO,再加上路演等等必要程序,智谱也得再拖半年到一年的时间。 而同样的功夫,六小龙中的五家也都在下。等走完这些必要的上市程序,剩下的几家也都将满足创建三年的基本条件。 同时,这个条件现在也有了松动的可能性。 根据路透社报道,在2025陆家嘴论坛上,中国证监会宣布计划在上海以科技股为主的科创板设立新板块,以容纳尚未盈利的成长型企业。根据证监会官网发布的指导意见,具备 “重大技术突破、商业前景广阔、研发投入高” 特点的企业可在新板块上市。 证监会主席吴清表示,中国证监会将新设科创成长层,创业版正式启用第三套标准,重启未盈利企业适用科创板第五套标准上市,支持优质未盈利创新企业上市,人工智能企业被画了重点。 宽松政策之下,不仅创建未满3年的大模型明星创企们有了希望,就连一向被投资人诟病的盈利问题,都拿到了赦免书。 对几家尚未盈利的大模型创企而言,重启未盈利企业适用科创板第五套标准上市后,盈利不足的压力也可暂缓,对于六小龙来说,今年无疑正是决胜“大模型第一股”之年。 需要注意的是,“大模型第一股”的Title对六小龙的意义并不只是“好听”而已。 “中国互联网的上市逻辑,在AI大模型一样通用,是赢家通吃。” 某位曾从事FA业务的投资人告诉字母榜,无论是互联网还是AI大模型,都是充分竞争的行业,奉行着胜者为王的逻辑,作为前无古人后无来者的第一股,往往会因为没有参照,而能享受极高的估值溢价,也就能挤占其他创企的生存空间。 对于六小龙来说,扎堆寻求上市并不奇怪。这不仅来自于创企自身对资金巨大的需求缺口,还会受到投资人的压力。 “早期投资人都在等着回收部分资金,六小龙的投资协议里恐怕也难以避免有上市时限的要求。”上述该投资人补充道。 但争夺“大模型第一股”,却不单单是为了拿钱。 这个问题,或许前几年在“AI四小龙时代”,争夺“第一股”的商汤、旷视、依图、云从能够回答。 2021年,彼时AlphaGo掀起了大众对人工智能的关注热情,以商汤、旷视、依图、云从为首的四家企业也趁势争夺首个上市敲钟的资格。虽然商汤三年半亏损242.72亿,但最终流血上市,成为“第一股”。 IPO时,商汤的发行价3.85港元是发行价区间的下限,上市首日,商汤冲高回落,收涨7.27%,次日,商汤股价涨幅33.17%,交易最高点为9.7港元,也一度使得商汤的最高市值超过3200亿港元。而四家企业中,首先上市的商汤正是靠着市场的持续输血,在大模型时代跟上了步伐。反观旷视转向智能驾驶,原有业务几乎裁撤完全;云从等公司的业务则大规模收缩,以云从为例,2024年进行大裁员,其中研发人员占比高达51%。 “大模型第一股”在市场的号召力是切切实实的,对于六小龙而言,“大模型第一股”不仅是一个现成的可以讲给投资人的新故事,也能够在实际上为他们增加生存的时间和空间。 争夺大模型第一股,也就意味着六小龙中最先得到投资者的认可,不仅容易获得相应的溢价,也能够成为后上市者的价格锚点。 同时,对于迫切需要输血的六小龙而言,上市最直接的好处就是可以为企业引入最直接的资金支持。 进入2025年,无论是腾讯、阿里、字节等科技大厂押注AI的技术布局,还是DeepSeek后来居上的技术领先,都让六小龙面临巨头在前、技术故事难讲的尴尬局面,同时,如今的大模型创企想从外部拿钱,越来越难。 即便是上半年仍然融资的智谱,单次融资额都不超过10亿元人民币。3月,智谱宣布完成三笔战略投资,金额分别为超10亿元,5亿元和3亿元。而天眼查数据显示,智谱在2024年已经披露的融资金额共计接近70亿元,去年12月,智谱单笔融资数额为30亿元。 对于需要持续烧钱追上技术迭代的六小龙来说,融资太难了。那么钱从哪来呢?或许对于如今的六小龙来说,只能从股市中来。 不过,六小龙争上市,还有很多功课要补。 无论是港交所还是科创板,盈利能力不足的六小龙,迫切需要外界看到自己的盈利能力。 科创板要求以市值为中心,综合考虑收入、净利润、研发投入、现金流等因素,尽管港交所的主板上市,为特专科技公司引入上市制度,未商业化公司的门槛由100亿港元降至80亿港元。但创业板(GEM)的市值+收益+现金流量测试的要求,则是上市时市值不低于20亿港元,近一年收入不少于5亿港元,过去近三年经营活动现金流入净额不低于1亿港元。 而跻身六小龙的明星创企,都早早在去年就通过多轮高额融资冲到了200亿元的估值。但如此高估值之下,各家的盈利数据却颇为惨淡,至今仍没有一家公司的年收入达到10亿元人民币。 从去年齐做TO C的聊天工具人,到今年发力B端,单次预训练成本三四百万美元的AI六小龙,即便是最先冲刺IPO的智谱,据《财经杂志》报道,尽管2024年收入达3亿元,亏损约20亿元。 据The information预估,2024年,OpenAI的成本主要分成推理成本、训练成本和人工成本三大块,加起来在85亿美元左右。对标OpenAI,六小龙研发费用和商业化收入规模之间的差距,短期内难以弥合。 希望跃入龙门的六小龙,如今迫切需要的让外界看到收入增长的新故事,展示自己的造血能力。 做好数据的首要似乎正是节流。 此前在投流获客上颇为激进,月投流数额超亿元的月之暗面已暂停大规模投流;阶跃星辰也在最近爆出旗下AI 社交工具“冒泡鸭”业务缩减调整,决心与汽车、具身智能等头部企业合作开发垂类Agent;MiniMax此前B端业务的负责人魏伟也被爆离开;百川智能裁撤了负责金融、教育等领域的B端组,理由是集中资源,聚焦在医疗核心业务。 当C端的故事不好讲。B端成为新的突破口。不过,当DeepSeek、通义千问、字节豆包等争相把API价格打到地板价,在移动互联网时代就通过云服务积累起忠实客户的大厂,早已搞起了“云服务和大模型的叠加优惠”活动,甚至六小龙原有的B端客户也存在被大厂撬走的可能。 “API价格卷不过阿里和百度,也没有和云服务绑定的老客户,去年几家几乎都是贴钱开发中小规模的企业用户,只为了老板给投资人的报告里有业务想象力。”某大模型创企市场人员表示。 在《智能涌现》的采访中,几名百川智能员工也表示,去年以来,不少医院科室都有AI落地的指标,客户愿意签单,“一是为了自己的政绩,二是为了能发AI医疗相关的论文,最后是为后续医疗产品的销售。” 以专注B端医疗市场的百川为例,尽管早早定位医疗领域,抢到窗口期签下不少B端的医院客户,3月中旬,华为传出组建医疗卫生军团的消息,当下,如何避免与“B/G收割机”华为的直接竞争,是百川内部抓紧讨论的新命题。 此外,六小龙还必须面对一个问题,上市如果不成功呢? 同样作为科技创企,曾与商汤争夺第一股的旷视,经历五年的艰难筹备,最终几次冲击上市均失败。有市场分析指出,虽然旷视科技在人脸识别、智能安防等领域技术领先,但迟迟未能盈利。此外,AI行业的投融资环境趋于冷静,投资者对AI企业的估值回归理性。这些都成为了旷视迈不过去的坎。 而在投资人“FOMO”情绪逐渐冷却的当下,先行者曾经上市遇到的门槛,也是如今六家需要向外界交的答卷。是否能够成功敲钟,六小龙还得各凭本事。 [查看评论](https://m.cnbeta.com.tw/comment/1508170.htm)


The EU could reach an arrangement "a little bit along the model of" the U.S.-Britain agreement, rather than a full trade agreement, as EU member states fear the economic consequences and the risk of internal disagreements on taking countermeasures. The EU now expects a 10% tariff rate to the starting point for trade talks with U.S., according to a report.

<blockquote><p>今年的618不仅是史上最长的一次,更是充满了混乱与无奈。商家们在复杂的促销规则和漫长的活动周期中疲惫不堪,消费者对价格不透明和虚假优惠的吐槽声不断,而电商平台则在努力寻找新的增长点。本文将带你深入剖析今年618背后的乱象与变化,以及它对电商行业未来发展的启示。</p> </blockquote>  中国互联网独有的大促包小促、小促偷涨价的 618 年中购物节在一片寂静之中结束了。 除了各家平台发布的口径不一但都一片向好的战报之外,更多普通用户唯一能感受到的或许只是终于能摆脱恼人的开屏跳转广告了。而对于更多参与其中的电商从业者们来说,如果说今年这场又一次史上最长 618 最后带来了什么启示的话,那可能就是坚定了他们逃离的决心。 每年的电商大促期间,市场上总有声音在讨论大促是否还有存在必要,到今年甚至连讨论的声音都没有了。一位从业十年的服饰品类电商商家说,他经历过许多次危机,但这次是真觉得利润做不到预期、看不到希望又感到无比绝望。“整个活动期间日销售额低于平销……最可怕的是持续一个月。” “我比往年投入了更多的推广、人力、精力、物力和费用,但实际上对我们整体的销售额几乎没有提升。拉不上去,最多也就是和去年打个平手。”一位美妆商家说。 社交平台上,中小商家保持了一贯的诉苦水风格,几乎看不到什么对于大促正面的评价。消费者端同样如此,多家媒体都在 618 期间发布了大促期间电商商家先涨后降的虚假套路。商家的涨价行为直至 618 高潮当天也没能停歇——原因是部分商家在大促中途选择退出活动。 受益于国补政策以及大促周期的再度拉长,第三方机构统计的今年 618 总体 GMV 仍处于上涨之中。星图数据称今年 618 综合电商销售总额(天猫、京东、拼多多、抖音及快手)为 8556 亿元,同比增长 15.2%。他们同时强调今年 618 大促周期与去年有较大差异,同比增长数据仅供参考。易观给出的数据是综合电商平台(淘天、京东、拼多多)GMV 同比增长 9.4%。 阿里巴巴集团副总裁、天猫总裁刘博向晚点透露,今年 618 全周期天猫剔除退款后的 GMV 同比增长了 10%,是阿里三年来最大幅度的增长。这是一个新的统计口径,阿里认为这样的数据更加真实,只是不知道为何他们过去从未使用过。刘博在采访中强调,平台购买用户数也实现双位数增长,同时他们的同比数据严格对比去年同期,言外之意是今年阿里平台收获了实实在在的增长。   京东对外公布的数据同样也是增长的。618 前一天公司创始人刘强东阔别多年后再度面对媒体,对外展示完全回归的信号。当天刘强东谈了很多,但唯一没提及的就是 618。第二天京东在总部举行了盛大的 618 收官发布会,对外宣布下单用户数翻倍增长、京东零售线上线下及京东外卖总体订单量超 22 亿单。 其他平台拼多多、抖音、快手等发出的战报也是一片火红景象。但每家平台拉出的数据维度都不同,基本上没有什么横向对比的空间,完全可以看作是 618 的“难忘今宵”,只充当着收尾作用。 今年 618 另一个更值得市场关注的变化是即时零售开始真正下场参与大促,美团闪购首次发布了他们的 618 战绩,称超 1 亿用户在美团闪购下单,整体成交额创下新高。京东和阿里也都在强调即时零售对电商的带动作用。 漫长而混乱的 618 终于结束了,消费者、商家以及加了一个多月班的电商平台牛马或许都能长舒一口气。但他们休息不了多久,马上更大规模的双十一大促也要开始筹备了。 ## 01 混乱与无奈 美妆品牌商家伍耐(化名)对于今年 618 最大的感受是“混乱”。倒不是因为大促没给他们的销量带来什么增长,而是他越来越搞不懂平台的玩法——混乱的促销节奏、频繁变动的优惠设计以及让人摸不着头脑的平台规则,“太荒谬了。” 客观来说,经历了去年 618 期间激烈而无底线的低价大战之后,今年各家平台都在致力于简化促销规则,强调对商家的扶持和减负,真正让利消费者。比如天猫、京东和抖音等平台都喊出了官方立减的口号,不用凑单,不用跨店满减,降低消费者决策成本。 商家们对于立减的态度不一。上述服饰品类电商商家说,过去在满减规则下,虽然有一定退款订单,但总体成交单量依然要比现在的立减规则更多,满减的利润也更高一些。他同时也在担心大促结束恢复正常价格之后,店铺的销售额会受到影响。 伍耐一开始认为像 618 这样的大促,最终仍然要回归到满减,他对于平台坚持立减规则感到惊讶,因为立减对于销售的提升不如满减。但很快他就无暇顾及立减的影响,因为平台两三轮的促销活动之后他已经疲惫不堪。 “平台的策略一直在变。”伍耐说。最早天猫第一波 618 促销在立减 15% 的基础上,88VIP 优惠券仍需凑单满减,但第二波规则变成了立减使用,无需凑单即可使用折扣。“平台只会告诉我第一波的活动是什么,第二波活动规则怎么样、什么时候开始都不知道。” 规则的变动带来的另一负担是他们需要频繁地向消费者解释,“昨天平台还我们发了一个新的客户服务规范,需要我们向客户解释什么退款哪些会退、这些优惠是怎么来的。”伍耐说,这些频繁变动的优惠规则让商家变得十分疲惫,有时候甚至连他自己都搞不清楚优惠的计算规则。 伍耐同时在经营小红书电商,今年小红书的 618 活动更让他摸不着头脑。小红书今年在 618 期间没有进行常规的促销活动,取而代之的是“友好市集”。按照小红书的表述,友好市集不是一个活动,而是一种产品形态和运营标准。友好市集在 6 月 1 日正式上线,小红书计划长期运营。 伍耐完全听不懂这个名字表达的含义,他一开始听到这个名字还以为是什么线下活动,后来也看不懂小红书对于“友好”的种种形而上学的表达,看到友好市集也有 15% 的立减、满减优惠券,他就权当这就是小红书的 618 大促换了个名字。  小红书友好市集 伍耐在友好市集规则下做了一场直播,但行至中途发现许多客户没有满 300-50 的优惠券。跑去询问平台运营,运营称他们对于发放优惠券有一套自己的逻辑和标准,“有的人给有的人不给。”至于标准是什么运营没有给他解释。伍耐觉得无法理解,这让他们在设计优惠价格时无法统一,也没办法做宣发。至于小红书今年与淘天、京东先后达成的外链合作,他至今尚未享受到。 “活动周期太长了。”一位家居品类商家对《山上》说,太长的活动周期消解了消费者的购买欲望。“618 活动刚开始那几天还好一点,之后基本上和平常日销没什么差别。”伍耐也表达类似的感受,他们从第一阶段的信心满满到第二阶段的疲惫,等到活动第三阶段,已经完全是平销期了,“和没有活动的时候几乎没有区别。” 今年 618 从 5 月 13 日一直持续至 6 月 20 日,时间拉长到 39 天,比去年的史上最长双十一还要多上一周,已经足够特朗普和他的亲密战友马斯克上演两次完整的和好-分手-又和好的狗血剧情。活动周期的拉长助推今年 618 累计 GMV 再创新高,但同时日均消费金额却在走低(以星图数据公布的 2024 年及 2025 年 618 数据计算),消费者对于大促的感知度持续下降,很少再有人通宵守着下单。 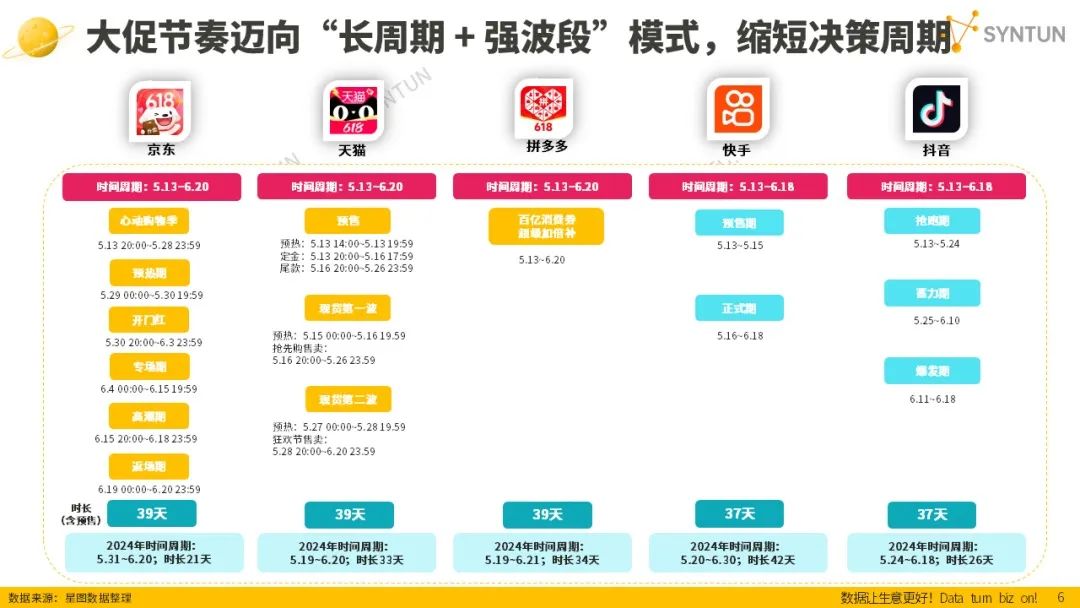 星图数据报告 电商的整个链条似乎都处在一种疲惫的情绪之中,越来越像是互联网上的一场集体行为艺术。消费者吐槽价格优惠不透明,商家吐槽销量下滑利润微薄,就连电商平台工作人员们也在社交平台上不断发帖表达对 618 的不满,因为他们不得不忍受更长时间的加班。 界面新闻在报道中称,今年 618 的中小商家开始了“集体躺平”,因为平台将越来越多的资源倾斜到头部品牌,他们也无法享受到国补等政策红利,对大促的重视程度越来越低。 伍耐算是中小商家中已经建立品牌的代表,他对于大促的态度有些无奈。今年他们已经将 GMV 的 40% 都用于平台投流,但带来的效果微乎其微。平台的投入也更大,“今年平台的投入肯定比以往多,真金白银砸了很多钱”,但他从销售数据上并没有感知到什么提升。 ## 02 消失与变化 唯一在 618 期间变得清闲起来的,或许只有各个平台的头部主播们。今年 618 无论是阿里、京东等传统电商平台,还是抖音、快手等短视频电商平台,头部大主播似乎都集体开启了隐身模式,阿里和京东的官方战报中已经没有了直播电商的身影。 快手平台的一哥辛巴今年 618 只进行了两场直播,分别是 5 月 24 日和 5 月 31 日,6 月份一场直播都没进行,连个新闻头条都没上。 过去每年的大促前后,辛巴总会整出点节目来,上演一波王者回归的戏码。去年 618 前他怒骂快手,宣称要到香港证监会举报快手,双十一前他手撕小杨哥、怒喷广东夫妇,一来一回都赚足了眼球,从来没像今年这么“安分”过。 抖音当下的绝对头部主播董宇辉在 618 期间基本保持着一周 2-3 场的直播频次,每周直播时长不过 6 小时,更多的直播都由与辉同行旗下其他主播完成。 董宇辉出现更多的场合已经不是手机镜头中,而是出现在参加各类的官方活动和新闻中。整个 6 月,董宇辉在抖音上发布的动态都是和新华社合作综艺节目的《向新而行》,他和新华社记者张扬一起体验宁夏地区的风土人情。618 当天他发布的一则动态是自己参加央视新闻的采访,“电视新闻上这小伙人是挺帅的。” 淘宝的头部主播李佳琦倒是仍兢兢业业地出现在直播中。美 ONE 团队对外称李佳琦在 6.1-6.18 期间共计参与了 13 场直播,但媒体统计后发现较往年李佳琦的直播在场时长还是频率均有所下降。李佳琦今年更大的变化是推出更多垂类直播间,瞄准包括中老年人等其他用户群体。 过去一两年来,几乎所有的头部大主播都在试图降低个人对直播间的影响,隐居幕后,他们开始培育更多主播、建设更多垂类账号,试图走向规范化和平台化运营。毕竟,小杨哥和薇娅的前车之鉴才过去没多久。618 期间,市场监管总局发布的《直播电商监督管理办法(征求意见稿)》正式对外公开征求意见,直播电商进入更规范化治理时代。 薇娅及谦寻控股今年仍然有新动作,618 期间他们推出了一款名为“谦寻超级会员”的小程序,试水小程序带货。和依托于平台的直播相比,小程序更能将用户积累在 MCN 自己手中,抵御风险的能力也更强。 和直播电商在舆论场上的隐退相比,今年 618 更被市场关注的变化是即时零售的加入。美团闪购在经过几年的水下生长之后今年终于开始正式向电商平台发起挑战,京东和阿里先后推出京东外卖和淘宝闪购应对,以期从外卖场景打开即时零售市场。 美团闪购发布的第一条宣传片就直白地表露了他们的野心,他们的口号是“下一代购物方式”,用种种对比来强调闪购之于传统电商的优势。今年是美团闪购参与的第一届 618,他们发布的战报称超 1 亿用户下单、整体成交额创下新高,但没有对外披露具体成交数据。星图数据统计称今年 618 即时零售总体 GMV 为 296 亿元,和综合电商平台相比仍有较大差距。 阿里和京东则不约而同地对外强调即时零售对于电商的带动作用。刘强东称京东外卖的消费者中有 40% 的人会交叉购买京东的电商商品,他们补贴给外卖的钱比去抖音、腾讯买流量要更划算。京东相关负责人称外卖带动京东 Plus 会员单月注册量超 40 万。 天猫总裁刘博接受晚点采访时称,淘宝闪购为他们的用户活跃度带来了很好的增长,为淘宝天猫各核心品类在未来发掘新的商业模式、触达新的商机带来了很大可能性。 更早之前,新上任阿里电商事业群 CEO 的蒋凡说,他们短期内重点是将更多淘宝用户转化为即时零售用户,长期来看他们认为近场电商可以和远场电商有很多结合的可能性。但由于淘宝闪购 5 月才正式推出,618 他们并没有非常刻意地将淘宝闪购与电商业务做很强的打通。 作者|何简 编辑|蒋浇 本文由人人都是产品经理作者【山上Hillvue】,微信公众号:【山上】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。
 FreeBuf网络安全行业门户
FreeBuf网络安全行业门户

<blockquote><p>在大模型盛行的时代,能高效处理海量文档的 RAG(检索增强生成)方案正成为企业的刚需。但现实是:高延迟、高成本、低吞吐,拦住了大多数人。而 Google 最新发布的 Gemini 2.0 Flash,用一次性能的“降维打击”,让 PDF 转文本、并行摄取、快速问答不再遥不可及。</p> </blockquote>  首先将每个 PDF 页面转换为图像,然后将它们发送以进行 OCR,只是为将原始文本转换为可用的 HTML 或 Markdown。接下来,您仔细检测并重新构建每个表,将内容切成块以进行语义检索,最后将它们全部插入到矢量数据库中,整个成本是非常高。 **Google 的 Gemini 2.0 Flash** 就可以简化整个过程。 在一个步骤中捆绑 OCR 和分块,而成本只是其中的一小部分。这篇文章恰恰探讨这种可能性。我将展示 Gemini 2.0 Flash 如何一次性将 PDF 转换为分块的、可用于 Markdown 的文本,让您摆脱冗余的多步骤。然后,我们将这些数据存储在可扩展矢量数据库,用于快速矢量搜索。 本指南介绍如何: - 使用 **Gemini 2.0 Flash** 将 PDF 页面直接转换为分块文本; - 将块存储在矢量数据库,用于快速搜索; - 在 RAG 工作流程中将它们全部联系在一起; 这是目前的模型价格 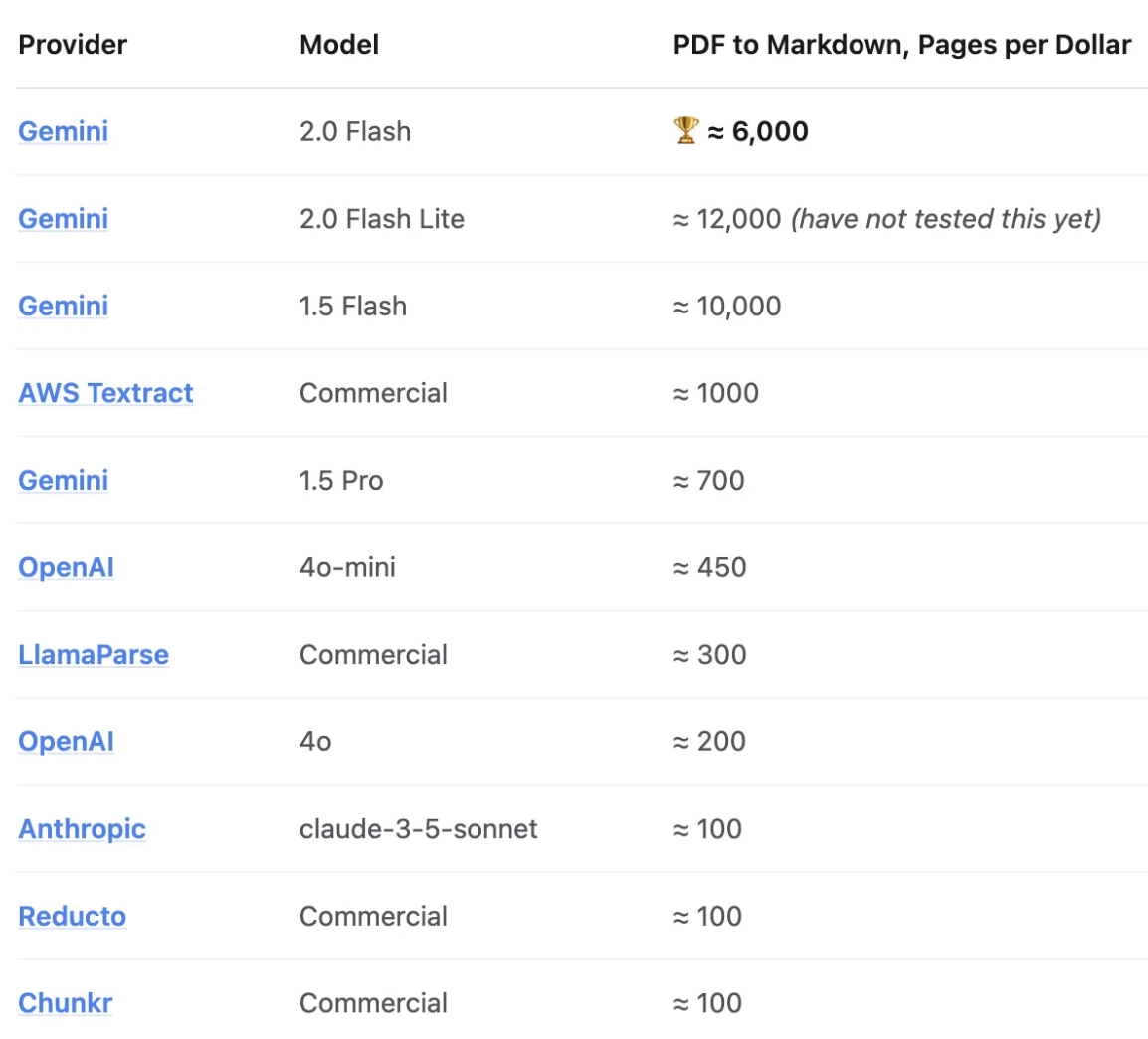 如果您不需要原始 PDF 中的边界框,这种方法比旧的 OCR 管道简单得多,成本也低得多。 ## 传统的 PDF 摄取问题 **为什么 PDF 摄取如此困难?** - **复杂布局 **:多列文本、脚注、侧边栏、图像或扫描的表单。 - **表格提取 **:传统的 OCR 工具通常会将表格展平为杂乱的文本。 - **高成本 **: 使用 GPT-4o 或其他大型 LLM 会很快变得昂贵,尤其是在您处理数百万个页面时。 - **多种工具 **:您可以运行 Tesseract for OCR、用于表检测的布局模型、用于 RAG 的单独分块策略等。 许多团队最终会得到一个脆弱且昂贵的巨大管道。新方法是:“只需将 PDF 页面作为图像显示给多模态 LLM,提示它分块,然后看着奇迹发生。” 这就是 **Gemini 2.0 Flash** 的用武之地。 ## 为什么选择 Gemini 2.0 Flash? **成本 **:~6,000 页/美元(使用批量调用和最少的输出令牌)。这很容易比许多其他解决方案(GPT-4、专门的 OCR 供应商等)便宜 5-30 倍。 **准确性 **:标准文本的保真度令人惊讶。大多数错误是微小的结构差异,尤其是对于表格。 最大的缺失部分是边界框数据。如果您需要将像素完美的叠加层重新覆盖到 PDF 上,Gemini 的边界框生成仍然远非准确。但是,如果您主要关心是基于文本的检索或摘要,那么它更便宜、更快、更容易。 ### 端到端架构 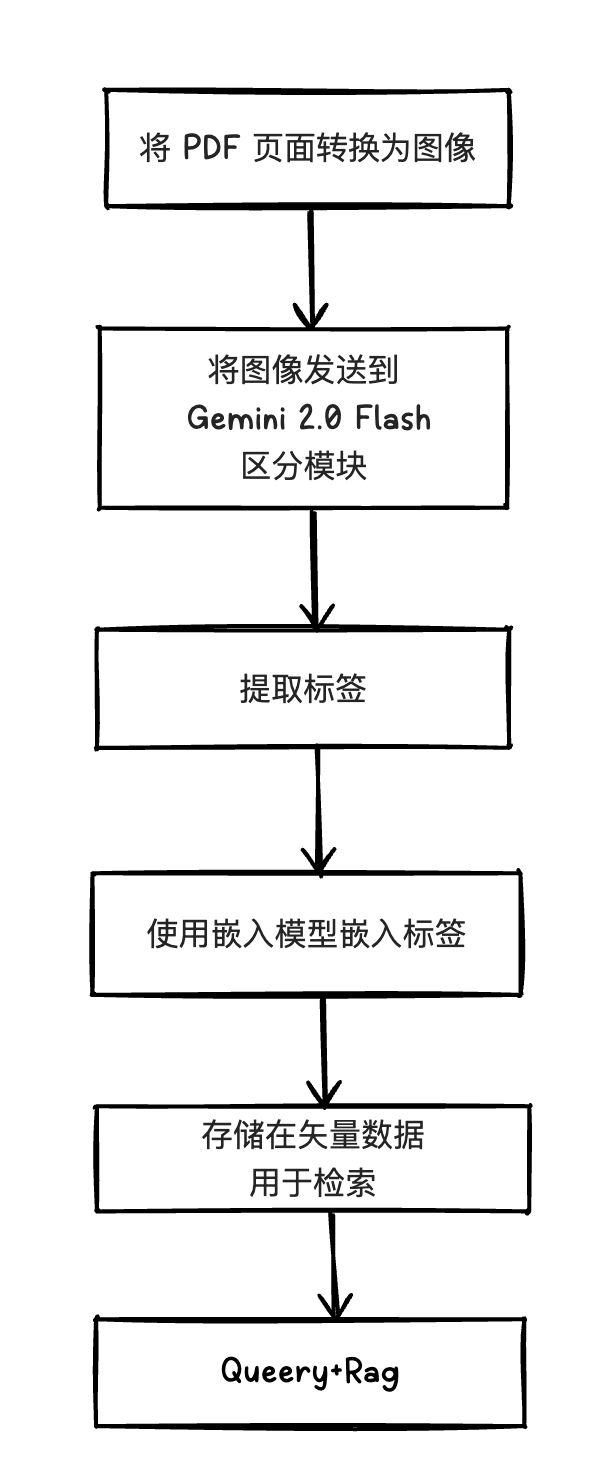 ### 分步代码 **1)安装依赖并创建基本表** <blockquote><p>!apt-get update</p> <p>!apt-get install -y poppler-utils</p> <p>!pip install -q google-generativeai kdbai-client sentence-transformers pdf2image</p> <p>import os</p> <p>import kdbai_client as kdbai</p> <p>from sentence_transformers import SentenceTransformer</p> <p># start session with KDB.AI Server</p> <p>session = kdbai.Session(endpoint=”http://localhost:8082″)</p> <p>db = session.database(‘default’)</p> <p>print(“Connected to KDB.AI:”, db)</p></blockquote> 您可以注册矢量数据库。免费 AI 服务器在这里: [https://trykdb.kx.com/kdbai/signup/](https://trykdb.kx.com/kdbai/signup/) **2)创建 Vector Table** <blockquote><p># Define KDB.AI table schema</p> <p>VECTOR_DIM = 384 # we’ll use all-MiniLM-L6-v2 for embeddings</p> <p>schema = [</p> <p>{“name”: “id”, “type”: “str”},</p> <p>{“name”: “text”, “type”: “str”},</p> <p>{“name”: “vectors”, “type”: “float32s”}</p> <p>]<br/> # Build a simple L2 distance index</p> <p>index = [</p> <p>{<br/> “name”: “flat_index”,</p> <p>“type”: “flat”,</p> <p>“column”: “vectors”,</p> <p>“params”: {“dims”: VECTOR_DIM, “metric”: “L2”}</p> <p>}<br/> ]</p> <p>table_name = “pdf_chunks”</p> <p>try:</p> <p>db.table(table_name).drop()</p> <p>except kdbai.KDBAIException:</p> <p>pass</p> <p>table = db.create_table(table_name, schema=schema, indexes=index)</p> <p>print(f”Table ‘{table_name}’ created.”)</p></blockquote> **3)将 PDF 页面转换为图像** <blockquote><p># Convert PDF to images</p> <p>import requests</p> <p>from pdf2image import convert_from_bytes</p> <p>import base64</p> <p>import io</p> <p>pdf_url = “https://arxiv.org/pdf/2404.08865″ # example PDF</p> <p>resp = requests.get(pdf_url)</p> <p>pdf_data = resp.content</p> <p>pages = convert_from_bytes(pdf_data)</p> <p>print(f”Converted {len(pages)} PDF pages to images.”)</p> <p># We’ll encode the images as base64 for easy sending to Gemini</p> <p>images_b64 = {}</p> <p>for i, page in enumerate(pages, start=1):</p> <p>buffer = io.BytesIO()</p> <p>page.save(buffer, format=”PNG”)</p> <p>image_data = buffer.getvalue()</p> <p>b64_str = base64.b64encode(image_data).decode(“utf-8”)</p> <p>images_b64[i] = b64_str</p></blockquote> **4)调用 Gemini 2.0 Flash 进行 OCR + 分块** <blockquote><p># Configure Gemini & define chunking prompt</p> <p>import google.generativeai as genai</p> <p>GOOGLE_API_KEY = “YOUR_GOOGLE_API_KEY”</p> <p>genai.configure(api_key=GOOGLE_API_KEY)</p> <p>model = genai.GenerativeModel(model_name=”gemini-2.0-flash”)</p> <p>print(“Gemini model loaded:”, model)</p> <p>CHUNKING_PROMPT = “””\</p> <p>OCR the following page into Markdown. Tables should be formatted as HTML.</p> <p>Do not surround your output with triple backticks.</p> <p>Chunk the document into sections of roughly 250 – 1000 words.</p> <p>Surround each chunk with <chunk> and </chunk> tags.</p> <p>Preserve as much content as possible, including headings, tables, etc.</p></blockquote> **5)使用一个 prompt 处理每个页面** <blockquote><p># OCR + chunking function</p> <p>import re</p> <p>def process_page(page_num, image_b64):</p> <p># We’ll create the message payload:</p> <p>payload = [</p> <p>{<br/> “inline_data”: {“data”: image_b64, “mime_type”: “image/png”}</p> <p>},</p> <p>{<br/> “text”: CHUNKING_PROMPT</p> <p>}<br/> ]</p> <p>try:</p> <p>resp = model.generate_content(payload)</p> <p>text_out = resp.text</p> <p>except Exception as e:</p> <p>print(f”Error processing page {page_num}: {e}”)</p> <p>return []</p> <p># parse <chunk> blocks</p> <p>chunks = re.findall(r”<chunk>(.*?)</chunk>”, text_out, re.DOTALL)</p> <p>if not chunks:</p> <p># fallback if model doesn’t produce chunk tags</p> <p>chunks = text_out.split(“\n\n”)</p> <p>results = []</p> <p>for idx, chunk_txt in enumerate(chunks):</p> <p># store ID, chunk text</p> <p>results.append({</p> <p>“id”: f”page_{page_num}_chunk_{idx}”,</p> <p>“text”: chunk_txt.strip()</p> <p>})</p> <p>return results</p> <p>all_chunks = []</p> <p>for i, b64_str in images_b64.items():</p> <p>page_chunks = process_page(i, b64_str)</p> <p>all_chunks.extend(page_chunks)</p> <p>print(f”Total extracted chunks: {len(all_chunks)}”)</p></blockquote> **6)在矢量数据库中嵌入块和存储** <blockquote><p># Embedding & Insertion</p> <p>embed_model = SentenceTransformer(“all-MiniLM-L6-v2”)</p> <p>chunk_texts = [ch[“text”] for ch in all_chunks]</p> <p>embeddings = embed_model.encode(chunk_texts)</p> <p>embeddings = embeddings.astype(“float32”)</p> <p>import pandas as pd</p> <p>row_list = []</p> <p>for idx, ch_data in enumerate(all_chunks):</p> <p>row_list.append({</p> <p>“id”: ch_data[“id”],</p> <p>“text”: ch_data[“text”],</p> <p>“vectors”: embeddings[idx].tolist()</p> <p>})</p> <p>df = pd.DataFrame(row_list)</p> <p>table.insert(df)</p> <p>print(f”Inserted {len(df)} chunks into ‘{table_name}’.”)</p></blockquote> **7)查询和构建 RAG 流程** 相似度搜索 <blockquote><p># Vector query for RAG</p> <p>user_query = “How does this paper handle multi-column text?”</p> <p>qvec = embed_model.encode(user_query).astype(“float32”)</p> <p>search_results = table.search(vectors={“flat_index”: [qvec]}, n=3)</p> <p>retrieved_chunks = search_results[0][“text”].tolist()</p> <p>context_for_llm = “\n\n”.join(retrieved_chunks)</p> <p>print(“Retrieved chunks:\n”, context_for_llm)</p></blockquote> **8)最终生成** <blockquote><p># SNIPPET 8: RAG generation</p> <p>final_prompt = f”””Use the following context to answer the question:</p> <p>Context:</p> <p>{context_for_llm}</p> <p>Question: {user_query}</p> <p>Answer:</p> <p>“””</p> <p>resp = model.generate_content(final_prompt)</p> <p>print(“\n=== Gemini’s final answer ===”)</p> <p>print(resp.text)</p></blockquote>  ## 最后的思考 - **用户反馈 **:真实用户已经用 Gemini 取代了专门的 OCR 供应商进行 PDF 摄取,从而**节省了时间和成本 **。 - **当边界框很重要时 **:如果您必须精确跟踪 PDF 上每个块的位置,您将需要一种混合方法。 - **可扩展性 **:制作数百万个页面?确保批量调用和限制令牌。这就是您达到 ~6,000 页/美元的最佳位置的方式。单页调用或大型输出的成本更高。 - **简单**性:您可以跳过六个微服务或 GPU 管道。对许多人来说,仅此一项就是一种巨大的解脱。 本文由 @来学习一下 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
 极客公园
极客公园
华为在 AI 领域,这次看起来是要全面发力了。 6 月 20 日下午,华为开发者大会 HDC 2025 开幕。两个多小时的主题演讲,AI 成了绝对的主角:不仅华为云拿出新一代昇腾 AI 云服务和全面升级的盘古大模型 5.5,华为终端也首次推出鸿蒙智能体框架,目标直指端侧智能体生态。 过去两年,高端 AI 芯片的「卡脖子」确实让华为在 AI 浪潮里显得有些被动。华为虽然构建了以盘古大模型为基础的 AI 技术体系,但实事求是地说,整体能力并没有达到最顶尖那层。 但经过两年的沉淀与发展,随着自研 AI 算力体系的快速进步,盘古大模型的核心能力,正一步步追近 GPT、Gemini、Deepseek 等全球第一梯队的玩家。更重要的是,华为正在通过鸿蒙、盘古的体系,将大模型的能力融入千行百业的应用,推动用户体验与行业生产力的智能化升级。 # 盘古大模型 5.5:昇腾底座训出「世界级」选手 在 HDC 2025 上,华为云带来了两项关于 AI 的核心发布:能力显著提升的新一代盘古大模型 5.5,以及支撑其训练的新一代昇腾 AI 云服务。 盘古大模型 5.5 对其五大基础模型——自然语言处理(NLP)、计算机视觉(CV)、多模态、预测、科学计算——进行了全面升级。  盘古大模型 5.5 丨来自:HDC 2025 首先是盘古自然语言处理NLP大模型。全新的 718B 深度思考模型是一个由 256 个专家组成的 MoE 大模型,它在知识推理、工具调用、数学等关键能力上有显著增强。 模型本身也进行了优化,提升了高效长序列处理、降低幻觉、融合快慢思考、增强 Agent 能力。一个关键创新是自适应快慢思考合一技术:通过特定训练方法,模型能根据问题难度自动切换模式——简单问题快速回答,复杂问题则深度思考。华为表示,这使整体推理效率提升了 8 倍。  盘古大模型5.5丨来自:华为云 同时还推出了深度研究 DeepDiver,通过长链难题合成、渐进式奖励等关键技术,可以在网页搜索、常识性问答等应用上获得很高的执行效率,如可以在 5 分钟内完成超过 10 跳的复杂问答、生成万字以上的专业调研报告等,大幅提升工作效率。 除了 718B 深度思考模型,盘古还推出了 72B 的 Pro MoE 大模型,以及更轻量的 7B 级小模型盘古 Embedding。 值得一提的是 Pro MoE 模型还首次代表盘古模型家族参与了第三方跑分测试,在刚刚发布的五月底 SuperCLUE 榜单上,盘古 Pro MoE 在知识推理、工具调用、数学、对话、代码、自然科学六大领域,其跑分成绩已经接近甚至在部分领域超过了 GPT、Gemini、Deepseek 的顶尖模型。 华为诺亚方舟实验室主任王云鹤和他的团队是盘古系列模型主要的研发者,他认为打榜成绩谁是第一不重要,更重要的是,过去所有的顶尖模型都来自英伟达芯片的训练,而盘古证明了基于全华为自研的 AI 服务器,可以训练出同等水平的大模型。 会上,基于 CloudMatrix 384 超节点,华为云发布了新一代昇腾AI云服务。其架构创新在于:将 384 颗昇腾 NPU 和 192 颗鲲鹏 CPU 通过全新高速网络 MatrixLink 全对等互联,形成一台超级「AI 服务器」,单卡推理吞吐量跃升到 2300 Tokens/s,与非超节点相比提升近 4 倍。  CloudMatrix 384 超节点丨来自:华为云 超节点架构能更好地支持混合多专家 MoE 大模型的推理,可以实现「一卡一专家」,一个超节点可以支持 384 个专家并行推理,极大提升效率;同时,超节点还可以支持「一卡一算子任务」,灵活分配资源,提升任务并行处理,减少等待,将算力有效使用率(MFU)提升 50% 以上。 对于万亿、十万亿参数的大模型训练任务,在云数据中心,还能将 432 个超节点级联成最高 16 万卡的超大集群;同时,超节点还可以支持训推算力一体部署,如「日推夜训」,训推算力可灵活分配,帮助客户资源使用最优。 从单一芯片的计算性能来看,目前昇腾、鲲鹏与英伟达的顶尖芯片还有差距。但凭借新的架构,昇腾 AI 云服务也可以支持训练出顶尖的模型,这意味着国产打破 AI 算力垄断迈出了重要一步。华为云透露,目前昇腾 AI 云服务已为包括科大讯飞、新浪、硅基流动、面壁智能、中科院、360 等超过 1300 家客户提供算力服务。 除 NLP 外,盘古的预测大模型、科学计算大模型、视觉 CV 大模型也都迎来升级。此外,华为云还在会上发布了全新基于盘古多模态大模型的世界模型。该模型可以生成数字物理空间,将其用于智能驾驶、具身智能机器人的训练。 # 鸿蒙重塑用户智能,盘古赋能千行万业 随着 AI 基础设施和模型能力逐步接近全球顶尖水平,华为的 AI 战略路径也变得清晰起来。 简单说,就是基于华为云的 AI 底座,用鸿蒙给 C 端用户带来更好的智能体验,用盘古助力 B 端行业提升生产力。 面向 C 端用户,智能体是构建生态的关键。HDC 2025 期间,华为终端发布了鸿蒙 6.0 开发者 Beta 版,并首次推出鸿蒙智能体框架(HMAF)。这不仅仅是一个开发工具,而是构建在鸿蒙系统和华为 AI 底座上的一整套 AI 生态系统。 在分发上,开发者做出来的智能体,既可以通过鸿蒙系统分发,也能集成到鸿蒙 AI 助手小艺里。用户想点外卖或者查天气,直接告诉小艺,它就能调用相关的智能体来服务,比如推荐餐厅、预报天气,甚至提醒你天冷加衣。 在开发上,鸿蒙智能给开发者提供了 50 多个鸿蒙系统插件和多种开发模式,还开放了小艺对话、小艺建议等 240 多个标准意图框架,帮助应用更准地理解用户想要什么、目的是啥或者什么情绪;同时开放了 11 项核心语音识别 AI 能力。开发者不用自己组建底层算法团队或者投入大笔研发资金,就能开发出智能应用或智能体。  50+鸿蒙智能体即将上线丨来自:HDC 2025 据悉,已有高德、大众点评、京东、微博等超过 50 个鸿蒙智能体即将上线鸿蒙平台。 除了服务 C 端用户,用AI提升 B 端生产力是华为 AI 战略的另一核心,这也是盘古大模型的根本任务。 几年前盘古刚发布时,它的基础模型就瞄准了医疗、金融、政务、工业等领域的痛点,推出了一系列行业解决方案。现在随着盘古大模型 5.5 发布,基础能力更强了,盘古也在更多行业找到了用武之地。 比如盘古预测大模型,已被应用于钢铁、有色金属、供热等多个行业。如宝武钢铁高炉大模型正式上线运行以后,出铁温度合格率稳定在 90% 以上,每吨铁水可节省 2 公斤燃料,一个高炉每天就可节省 20 吨燃料。天津能源使用盘古预测大模型,精准预测了供热需求,在刚结束的供暖季,实现了 100% 的均衡供热,能耗降低了 10%。 还有盘古科学计算大模型,被深圳气象局用于升级「智霁」大模型,做出更精准的天气预报。重庆市气象局针对成渝地区降水局地性强,且降水强度大的特点,打造了「天资·12h「气象大模型,提升灾害天气的日内预报预警能力。 而最新的盘古世界模型,则通过构建无数字物理空间,辅助智能驾驶、具身智能机器人的训练。例如,在智能驾驶领域,输入首帧的行车场景、行车控制信息和路网数据,盘古世界模型就可以生成每路摄像头的行车视频和激光雷达的点云,能够为智能驾驶生成大量的训练数据,而无需依赖高成本的路采。 而在当下最火的具身智能领域,华为云也基于盘古大模型的多模态能力及思维能力,正式发布 CloudRobo 具身智能平台。该平台整合了数据合成、数据标注、模型开发、仿真验证、云边协同部署以及安全监管等端到端能力,提供具身多模态生成大模型、具身规划大模型、具身执行大模型三大核心模型,加速具身智能创新。同时,面对具身智能领域机器人品类多、传感器类型多、接口协议多等挑战,华为云提出了机器人到云的联接协议 R2C(Robot to Cloud)。  CloudRobo丨来自:华为云 # 结语 曾经受限于高端 AI 芯片的华为,在 2025 年的 HDC 开发者大会上,用盘古大模型 5.5 的全面升级和昇腾 CloudMatrix 384 的算力突破,清晰地宣告了其 AI 能力的进阶——核心模型能力已追至全球第一梯队,并构建了能支撑顶尖大模型训练的国产算力底座。 更重要的是,华为的 AI 布局已走出实验室,清晰地指向两端:一端是鸿蒙智能体框架(HMAF),它将 AI 深度融入鸿蒙生态,通过小艺和开发者生态,让普通人简单获得更好的智能体验;另一端是盘古大模型,它正深入钢铁、气象、能源、自动驾驶乃至具身智能等广阔领域,实实在在提高千行百业的生产效率。 从「悄悄发育」到「全面发力」,华为 AI 的这关键一步,不仅在于技术指标的追赶,更在于它正将「根深」的自研能力,转化为赋能千行万业智能化升级的「叶茂」。这场由「端」(鸿蒙)与「云」(盘古)协同驱动的 AI 实践,才刚刚拉开序幕。

<blockquote><p>在产品面试中,如何评估产品功能是否成功是一个经典且极具挑战性的问题。它不仅考验产品经理的系统性思维和数据分析能力,还体现了其对业务目标和用户体验的理解深度。本文将为你详细解析如何系统性地评估产品功能的成功与否,从目标设定到结果评估的完整闭环思维,帮助你在面试中脱颖而出。</p> </blockquote>  今天给大家带来一道产品经理必考题:**如何评估一个产品功能是否成功?请举例说明。** 这个问题看似简单,但回答好它需要系统性思维和数据分析能力,是区分初级与高级产品经理的重要指标 ## 面试官为什么问这个问题? 面试官通过这个问题主要考察以下几点能力: - **评估框架**:你是否有系统化的方法评估功能 - **数据思维**:你是否能从定性、定量两个维度进行分析 - **目标导向**:你是否理解产品功能与业务目标的关联 - **实践经验**:你在实际工作中是否有落地经验 这个问题本质上是在考察你作为产品经理的”闭环思维”能力 — 从目标设定到结果评估的完整过程。 ## 常见误区:大多数候选人怎么答错的? - **仅关注单一维度**:”看用户数据增长了就是成功” - **缺乏评估框架**:零散列举指标,没有系统性思考 - **脱离业务目标**:没有将功能评估与产品战略、业务目标关联 - **忽视用户体验**:只关注商业指标,忽略用户层面的成功 - **缺乏具体案例**:无法结合实际案例说明评估方法 ## 答题框架:OKR-ME评估法 回答此类功能评估问题,我推荐使用OKR-ME框架: - **O – Objectives (目标)**:功能设计的初衷和目标是什么 - **K – Key Results (关键结果)**:预期的量化指标和成功标准 - **M – Metrics (核心指标)**:实际监测的数据指标表现 - **E – Experience (体验反馈)**:用户反馈和体验评估 ## 内容深度:核心要点必须覆盖 评估产品功能成功与否,必须涵盖以下关键点: - **目标导向评估**:与初始设定的业务目标和用户目标对比 - **多维度指标**:覆盖用户、业务、技术三个维度 - **短期vs长期**:区分短期指标和长期价值 - **定量与定性**:结合数据分析和用户反馈 - **相对基准比较**:与竞品、历史数据或A/B测试对比 ## 加分项:如何脱颖而出 想要让回答更加出色,可以考虑: - **设计思路回顾**:将评估与最初的设计决策关联 - **不同阶段评估标准**:区分上线初期、稳定期、成熟期的不同评估重点 - **失败修正机制**:提及如何基于评估结果进行功能调整 - **团队协作视角**:提及不同角色(开发、设计、运营)的评估视角 - **投入产出比**:引入资源投入与产出效果的比较分析 ## 资深产品总监参考答案 评估产品功能是否成功,我会使用OKR-ME框架进行系统评估。 **目标分析**: 首先明确功能上线的初衷是解决什么问题,服务于哪些业务目标。功能目标通常分为用户目标(提升体验、解决痛点)和业务目标(提升转化、增加收入)两大类。评估成功与否,必须回到初始目标。 **关键结果**: 在功能设计阶段,我们应该明确设定预期的成功标准,如’功能上线后30天内,用户活跃度提升10%’。这些预设的关键结果是评估的基准线。 **核心指标**: 我从四个层面收集和分析指标: - 功能使用指标:使用率、触达率、完成率等 - 用户行为指标:停留时长、互动深度、路径转化等 - 业务影响指标:收入、转化率、客单价等变化 - 技术性能指标:加载时间、错误率、兼容性等 **体验反馈**: 通过用户访谈、NPS评分、应用商店评价、客服反馈等渠道,收集定性反馈,与定量数据结合分析。 **实际案例**: 以我负责的电商App商品详情页改版为例。改版目标是提升转化率和用户体验。我们设定的关键结果包括:加购率提升15%,页面停留时长增加20秒,用户反馈满意度提升10%。 上线后,我们通过以下方式评估: - 设置A/B测试,比较新旧版本的核心指标差异 - 监控关键漏斗转化率:浏览-加购-购买的各环节指标变化 - 通过热力图分析用户点击行为变化 - 开展用户访谈,了解主观体验改善情况 结果显示,新版本加购率提升了18%,超出预期;页面停留时长增加了25秒;用户满意度提升12%。但我们也发现,虽然加购率提升,但加购到购买的转化率略有下降。通过进一步分析,我们发现是因为商品推荐区块位置调整导致用户分心。基于这一评估,我们在后续迭代中优化了推荐区块的位置和展示逻辑,最终实现了完整漏斗的转化提升。 总结来说,功能评估不是简单看某个指标的增长,而是要回到初始目标,综合多维度指标和用户反馈,在此基础上持续优化迭代。 本文由 @Kris 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议
 **变现目标** 做媒体,肯定是为了变现为最终目的,没有谁为爱发电,如果前期他是为爱发电,如田一鸣,纯折磨,但知名度和人设起来后,一个广告几十万。不止于此,有了流量和人设,他可操作的地方有很多,譬如:文旅推广合作、接广、带货、咨询、精选计划变现、链接更多人脉资源、影响力等等等等 所以,做媒体,要有人设定位,要有变现目标,即使没有明确的变现目标,也可以像我一样,瞎写瞎发,纯粹是为了活跃脑子,或是帮助一些人,我是有私心的,人无完人,帮人也可以说是帮自己。具体为了什么?目的也是营造我自己的人设,想要媒体知识付费,那就得先做出点免费利他的东西,这种东西得用价值去衡量,是否能够帮助到他人。 之前辅助了一个人,我是觉得她人还可以(当然不是好色哈哈),是对方很会给情绪价值,毕竟不能给钱就给情绪嘛,社会是价值交换的利益场。她是有一点基础的,至少我说的例子和方法她能听得懂,去执行,不断修改迭代,告诉她怎么改,怎么剪,怎么卡点配音,如何做故事等等,之前的不温不火,一条视频爆了几万赞,其他的视频全都拉起来了。虽然几万赞还是比较少的,不过重在迭代,因为视频是需要生长起来的,如同树木一样,生根发芽。 帮她做,其实就是帮我做,我能有这个背书。虽然我也是百万博主的编导,但想着为自己以后谋取新的路径,总不能帮别人当编导,给自己也当个编导好一些。 好,说了这么多,进入主题,说那些目的也是叠个buff。这篇文章其实也有一些细节点,虽然前长了些,就是筛选那些妄想走捷径的人的手段。 还有另一个用意,就是加上我的履历,这样写也有一种好处,比如你看视频,一开头那个博主就说自己多厉害多厉害,花了多少钱,给你多少价值,人的心理是有厌恶损失的. 这是心理学效应 ,意思是:人看到了一样东西觉得对他是有价值的,如何不看好像亏了,像是丢了东西一样,也就是xhs里常说的,不要视别人的得为自己的失,一样的道理。所以我这样写,你们也可以尝试如此,利用人性的心理来做开头,5s完播和2s跳出会少一些,不过现在机制改革了,光有这样的开头也没用,需要其他的设计,也就是内容为王了。 进入正题 ## 一、首先辟谣一些自媒体玄学 **封面** 教你做封面的,各种细节什么的,都是扯淡,内容不好,什么封面都没用,根本没这么重要,只要不太乱就行,即使再乱也没事,像pxx那样的封面我都见过,流量也一样好,为什么?因为他善,不是,因为他内容做的好。还有的封面,就一个人在上面,啥也没有,照样也有流量。 **定时发布** 说让你定时发布的,也是玄学,内容,内容,还是内容,其他都扯淡。 **日更限流?** 还有,日更不限流,周更也不限流,月更也不限流,内容,还是内容。 **隐藏修改限流?** 隐藏修改也不限流,不频繁删除和修改就好。 **主页4件套?** 还有的说主页四件套什么的,扯的比天都高,都重要,但其实真没这么重要。 简单的头像,你喜欢的头像,简介是你喜欢的价值观或者说要帮助别人xxx的愿心,发心,都可以。封面可以按照你喜欢的来做,做成一个风格也行,乱七八糟的也行。个人主页背景也随意,这些不重要!!! 简介四件套有用但不多,让别人知道你是干嘛的就行了,还是要看内容的好坏,不然是本末倒置。 **投流?** 还有人说投dou+怎么样?你买来的不是真的喜欢你的,其实没啥用,而且你内容本身就不好,买过来是看你视频的,但是不好看,也就划走了。其实任何投流,都是从那些卡播放的博主那里买过来的,比如某音是有个机制的,会卡在1.2w和1.8w的播放量之间,系统认定你的内容算是普通人发布的作品,还没算真正的创作者,把卡住的那些流量卖给了那些投dou+ 的人。别妄想买流量了,以后投入产出比只会越来越低,好好做内容,内容就是流量。 对了,如果你内容不错,倒是可以在后期跑起来的时候投流,是用来包装数据接广的,这是小技巧。 **其他玄学?** 连赞,换号,评论区活跃,都是玄学,没啥用,只会让你内容,数据焦虑,都是为了让你买他们课的。还是那两个字,内容!!没有权重账号这一说,都是扯淡的。 **呈现方面** 不要恶意,不要低俗,不要踩着别人往上爬,不要搞那些有争议的话题,因为不持久。要符合社会价值观,不然等着被封和限流吧。国家不允许那种东西存在,太多负能量的,反社会的,是不行的,因为这种内容一旦多了起来,会形成连锁反应,我不能多说了,等会给我封了。 **固定流程?** 很多机构都是模版化的,流水线的,拿些固定的流程交给你了,你做不起来就甩锅给你,反正机构没问题,甩锅给你什么都是你的错。 这个很像一些运营,问老板喜欢什么,老板说喜欢那个,就按照那个给他对标复刻,没流量就是没投流,有流量就是运营和老板选的对,反正什么责任都甩不到运营身上,和那些机构是一样的。 **抄?** 教你抄,低俗的,low的,都是扯淡的,机制改了,同质化过多只会不断被限流,有的甚至只有1个流量,1个小眼睛。你还是得做好你本身的内容,别想着复刻和弄那些花里胡哨的。 **为什么发产品的限流?** 所有平台都不支持商业广告,除非通过他们的平台接广才支持,一律自己打广的,都会被限流,甚至有些直播间直接被封禁。因为平台要注重用户体验,不能全是广,否则这个平台就失去商业价值了。 **钩子有用吗?** 有用,但是旧的可能没用了,自媒体是不断更新的,但凡有人说给你固定的流程和一套模板给你做起来,你大嘴巴抽他就行。素材、内容、钩子、音乐、音效什么的,都是要定期更新的,思维也是。 **打标签?** 标签是观众看你的视频,并且系统根据观众的反应,给你打上标签的,不是你自己先打标签,而是平台根据你的内容给你打标签,不要本末倒置。是观众和平台系统给你打的。 ## 二、目标 不管你多少粉丝,做之前先确定自己的表现目标,是卖课?还是接广?短视频带货?还是直播带货?或是你有自己的产品? 比如:我做个宝妈账号,我不仅局限于宝妈这个内容,宝妈是妈妈的孩子,也是他老公的伴侣,是妈妈的女儿,是喜欢美妆的、穿搭的、影视剧的、漂亮玩意的人,以及她也可以旅行,是律师,是会计,是产品经理,也喜欢玩梗,喜欢做手工等等。 总之别把自己限制在一个宝妈的身份里,你可以是宝妈,也可以是分享美妆和穿搭的女人,也可以是教育孩子或者是孩子的朋友的人设,也可以是旅行中的自由人,你可以在这里面选择你的变现目的。 如:你是产品经理离职带娃,你可以用产品经理的视角讲人设,讲感情,讲穿搭和通勤美妆,变现内容就藏在里面,你可以知识付费,可以咨询,可以卖你自己的产品或者帮忙卖其他人的产品,,,,,,, 如果没有目标,也没事,先做着,做你认为有价值的内容,一定是跟钱相关来衡量价值的内容。 比如你做个美妆账号:你可以分享化妆技巧、情侣见面的穿搭和妆容、出席场所的妆容、情感、成长和你的变现思维等等,没有价值就没有分享的必要,除非你像我之前写的那些思考写着玩的,也行。 这个价值可以是情绪上的,也可以是物质上的,有时候情绪上的价值对一些刚好受挫的人有着天然的吸引力,就因为一条内容视频或图文,就粉上你了。 ## 三、人设 人设最好是放大本有的特点而不是虚假包装的,得看这个人的观众缘适合哪个赛道,赛道和人设要测试,一个人身上有多种人格、人设的,演观众爱看的。 譬如:你本身就不是幽默搞笑的料,你非要去装出来,这样不持久的。尊重自己的心理和状态,放大你本来就有的特点。如:你很理智,温柔,超级自恋爱美,热爱分享,社恐内向。 以及你有些奇奇怪怪的行为和习惯,都可以放大,自媒体是个人化的,是极度自我的平台,你越个性,越有人喜欢你爱你,它不像是现实社会,现实需要伪装,但媒体给你释放真实,不过有一点,不要反社会反人性,和负能量,这是最忌讳的,即使你释放无数负能量有很多播放量,也没多少人关注你,因为人即使过得再不好,也渴望温暖和理解,这是人性。 **人设是什么?** 人设是一个独特的标签,是观众对你的评价,是你自我对自我的评价,是外人给你的反馈。人设并不是我说我是谁,你说你是谁那是你的身份,我说我是个阳光的,但是观众说我是闷骚的,对,那我就是闷骚的。观众怎么接受你,和看你,这个才重要。 但标签是多个的,这个社会是标签社会,人都是看第一印象才看往后的发展的,譬如你长得帅和美,长得有特点,说话有温度,有觉悟,幽默风趣等等,才会接着往下了解你。他们也是视觉动物 所以,标签是多个的,但做媒体也分阶段,你一开始得把你最独特的标签和特点放出来,先让观众认识你,接受你,后面再慢慢的在内容中加入你的其他人设,这是生长式的路径,不是线性的,而是结构化的。 不要把自己给简化了,可以先放大某个特点,某个标签,即使只有一个也没事,因为算法会把你送达到观众面前。以前看过费孝通的《乡土中国》一书,里面的《家文化》很有意思,就是:你出门在外,只要找到另一个人,你说你们认识,或者说祖上也是有关系的,就攀上关系了。然后他再给你介绍其他人,继续重复,只需要6个人,你就能认识全世界的人了,比如这个人说那是我哥们,这个哥们的哥们说那是我哥们,如此循环,可能那个人认识川普,那么间接的我也是川普的哥们了哈哈哈哈哈。 开玩笑,算法是这样的,把你的单个标签推送到所有和你有相似标签点人面前,国内有十四亿人,而人有无数的标签,只要和你相似,就会推给那个人,但是推了不代表就爱看你,而是你的内容能不能把他给抓住,所以最后还是内容的问题。 **方法论** 有人可能还不会,比如,**人设:帅哥+抽象+舞蹈,直女+拉子演绎剧情,宝妈+穿搭+情感,情侣+搞笑/文学**。当然,不一定要帅哥美女什么的,你有什么特点都可以加上去。律师讲背叛,中介带你看那些乱到离谱的房子,工厂组织员工过六一,你看着五大三粗但是很温柔,看着粗犷但是你是男绿茶等等。 你可以从身上的形象找,从你的过往找,你有什么品格,朋友对你的评价,他人对你的评价,你是否特别爱装,特别稳重,特别安静或者走走路就抽风几下,和朋友在一起疯疯癫癫的,和陌生人在一起就脚趾抠地的等等。 比如:一个宝妈在夜晚,搭建了一个温馨的或者怀旧的,或者以前小时候跟奶奶在一起的画面,给孩子讲故事,讲财经,讲你的人生故事等等,营造一个可以和观众对话的共情的场景,你是个暖心的妈妈也是个温暖的大姐姐,分享着你的过往和经历,看似对着孩子讲,实际上是对着观众袒露心声。在讲的过程中植入你的爱好,兴趣,你做过的东西,**如你是个产品经理,开发过xx,你帮助过朋友面试上了某大厂,这是你的变现内容植入,懂我意思吧嘿嘿**。 所以,你的画面,语音语调,配乐选择,说话风格和轻重,剪辑,场景打光等等,要符合你营造出来的人设。 <blockquote><p>举个坏的例子:你本来搭建好了温馨的场面,你一上来搞怪,或者讲些不着边际的东西,这种不叫反差,这叫做瞎玩。有时候调性得符合你才行,你要的是变现,不是搞怪当乐子。当然,这是其一,不代表全部赛道。</p></blockquote> 在这个基础上创造标签,标签就是人设,个人特点。不要刻意凹人设。在做自己的基础上,**放大个人特点和标签**,比如说话,你不一定要讲普通话,因为大家听腻了,但你可以讲陕西话,湖南话,河南话等等。 <blockquote><p>比如你很内向,你就放大它。你很社恐,就去反大它。比如你社恐是吧,怯生生的莫样,但是你偏偏去找到别人合照,做一些比较反差的事情,也可以,你的调性可以是这样。比如你很社恐,就像那个谁来着,忘记了,去到大街上找各种人做些尴尬的采访,表演,求偶之类的。太多可以玩的了。</p></blockquote> 比如结合起来:内向社恐的美女+一口川普+反差找人合照或者表演,演一个反差人设。(不过得是你愿意的情况下,认可的情况下才行,不然做不好,表演不好,容易耷拉着脸。) 多拍多实践,年轻人闯世界最重要的是先出去。拍了就知道你的视角如何,机位如何,剪辑如何,说话和表情动作等等。 心理准备:在自媒体就得放开,前期必然会被人评价,后期更多。你做这行,就必须承受别人的眼光和评价,你默认出丑的状态就行。互联网上不能有你在乎的人,你连自己都不能在乎。 语气和表演:多练,多看,多拍,一定要做到自然。 ## 四、什么内容涨粉? 能够植入你人设的视频涨粉,稍微长一点的视频涨粉,有深度有娱乐的涨粉,你的人设越强,故事感越足,活人感越真实的容易涨粉。 你得基于你的喜怒哀乐,爱恨情仇,价值获得感,解决对方的需求,慕强和共情等内容来做。 <blockquote><p>比如:同样是讲母婴教育的,凭什么那个人能涨粉,明明数据差不多。但其实。她植入了她的强背书,独特情感和观点,比如“985毕业,大厂p7裸辞,回到向往的生活中”,这种就是软植入。观众大多是第一印象的,有这些信息与否,可能就决定涨粉与否。(不过还是内容的问题哈)</p></blockquote> 有的博主赞比播放很高,但就像是科普,像是一个视频版说明书,看完了,确实有所收获,但是为什么关注你?因为没有一个关注你的理由。未来在你这不知道能获得什么,至少你有剪辑教学,有知识分享,有帮他们成长的内容等等。 你会发现,现在很多“大博主”,作品点赞比下滑严重,为什么?内容太过重复,观众看腻了。ta得更新选题和内容,不只是有期待感的内容,得是跟得上自媒体趋势发展的内容。以前内容好做,爱看,但不代表现在的观众买账。 有些博主早期做的内容确实吸引人,或者那时候没有那么多竞争者的时候,涨粉相对容易。现在是卷内容的时代,内容创作能力没跟上,凉了是注定的。 某音99%的百万粉博主的内容和粉丝都在下滑,就是因为内容创作能力跟不上趋势发展了,一直在做那些烂账,没有一点新意。“总是-90后农村妇女的一天都在做什么、住在xx有什么体验、自律xx 的一天” 总在摆弄那些旧的东西,早该换人了。竞争力很大,你不上就下,这么多博主卷入,不提升就等着被取代。 有人问我,为什么你不自己做号?却给别人做号呢?我长得一般,而且不太想出镜是其一,现在没有这么多精力去做:还没找到自己喜欢的方式,我觉得得更深刻的课题,市面上太多竞争者,想做一个东西最好是有自己的独特点,才能更好的在市场上杀出来,否则为什么选择你呢? <blockquote><p>而且我才23岁,我认为有些东西是需要沉淀的,而不是教那些或做那些“烂”内容,不只是宣传那些“玄学”的东西。学媒体一定得有系统的知识框架,不然做久了会发现,你没有东西可做了。这就是我想做的和教的。</p></blockquote> 我也有私心,谁都有私心,没人会真正教你什么,我写的这些也是一些片段的内容,能给人启发,但绝不是系统的。因为我没义务免费教你,换做是你也一样。而且我也尽量在回私信,有的会感激,有的会不屑一顾,有的在我给他答复的时候不再理我,有的xxx,什么人都有。我也知道这是一种交换,但我也依然回复,我知道,这是链接的机会,也是帮助自己完善知识的过程。 好了,下期分享选题、内容和视频呈现的方式,怎么写本,有哪些注意点和记忆点等等。写的有点多,但是只有在枯燥的文本中才能帮助人思考、发现。 ## 五、附带一个账号分析 某音-战凌云账号分析: 他抓住大众对钱的渴望,在经济下行时期,社会低迷郁郁形成反差,积极向上执行,对钱的渴望更是止不住的幻想,刚好有这样一个人,把抽象的欲望变成具象的符号,也就是执行力教你赚钱,实践去摆摊,产生了体验感+干货+过程揭秘,以及这群人心中的向往,幻想自己也能成为他一样,或者他能帮助人们找到方向,类似精神支柱。 他最后的结果呈现,确实赚到了很多人一天赚不到的钱,而且时间很短,短时间赚快钱是每个人的欲望和不劳而获,更是放大了焦虑,抓住了人性。 加上他是当兵退伍军人,人设更上一层楼,执行力人设和做事的方法,自信且昂扬,他的内在人设是刚劲,执行,内心强大,有智慧头脑的,外在人设则是欧豪的外表,兵哥哥的外形,穿着很普通人,但是有想法有执行,接触过后才发现这么有头脑,拼劲很大,给人动力和积极。 跟观众产生互动,教怎么赚,什么细节,互动对话和他与外人的对话,还展现了推销方式,为什么这么摆摊?怎么算成本和利润等等,就是不知道这个赛道能玩多久,很卷,后续可能会被打压。 ok就到这。下一期更新选题、赛道、内容等。 ## 六、选题 **宝妈怎么选题?拍孩子怎么选题?一个人拍什么?有什么方法吗?有,其实适用于所有赛道。** 有的人做口播,但不能纯口播,**纯口播必然做不起来**。那要怎么做?比如:”你写好一篇文章出来,或者去书籍,电影上面去找那些经典话语,写下来结合你的经历,把你放进去。你讲自己在职场遇到的事情,可以在职场讲,也可以在地下车库讲,可以在昏暗路灯下讲,就是不能在专业的环境下讲,因为不真实,没感觉,这个叫做代入感。And,如果你会拍摄,可以找个风格适合你的调性的去拍,比如王家卫风格,杜琪峰风格,以及一些外国大导演的风格都可以,当然这只是锦上添花,锦是你的内容,风格是添花。” 什么是调性?加入你是个沉稳的人,你本身就不想去做那些搞笑揶揄的东西,那么你的场景设计,氛围,感觉,音乐,就得符合你沉稳的样子。比如比较文艺的,比较安静艺术的,环境也是那种看起来高级的,至少你要在观众面前展示你要给他看到的画面,这是他们对你的第一印象。 举个例子:周鸿祎,为什么他不去演剧情,他这么大个老板去演剧情拍搞笑的,不符合身份。所以他访谈,对着镜头口播,这才符合调性。 如果你是老板,面对的客户是b端的,那么可以讲你们行业的内幕,讲最新的资讯,利润,规模,以及b端商家都感兴趣的话题,具体是什么,你应该比我更清楚你的行业。譬如:有个老板是做电器的,但他每次讲的东西都是结合他自己出发,偶尔在视频里加上他跟源头的关系,跟xx人的关系,以及他去研究,发现,谈论,跟某个大老板合作,在里面体现他对行业的洞察,展示给b端商家看到你的诚意,结果和过程,与他们有关的种种。 <blockquote><p>如果你是个媒体人,讲知识的,那么就去搜集一些“早就存在的真理”,你看到一些看似活得通透的词句,视频,你点进去听了一会,觉得“卧槽”好有道理,对,就是这种,他们是巩固大家的固有认知的,其实你也知道那些道理,只不过经过他的口中说出,会给你一种“你懂我的感觉”,你就给他点赞,共鸣了。比如:“我们总在强调婚姻中的紧密,甜蜜,亲密有多重要,但实际在婚姻中适度的空间距离才是最重要的。”</p></blockquote> 其实算是一种空话,但你又觉得它有道理。再比如:”不要用30年前的锁开现在的门“,很有道理,但只不过换了个角度,世界上没有绝对真理,只有不同角度的阐述,认真想这句话。 **Ok,那么选题还有什么方法吗?** ### 1、记录你的感触 记录开心快乐的事情,自己看着也高兴的,或者也深有感触的东西,然后编成剧情,写成文案。 比如:你对于朋友之间这样的做法感到很不适,可以记录下来,你感到不适的东西,别人也会感到不适,你分享出来,结合你的经历,这就是你独有的视角来阐述的事情。也就是他们常说的普世陌生化。 再比如:你和孩子之间的矛盾加剧,为什么别人家的孩子总是你喜欢的样子呢?你把其中的利弊写出来,感受写出来,去问孩子,去谈心,去问别人家的孩子,实际上并不是如你所想的那样,各有各的烦恼,这也是一种选题,选题”我误解了我的孩子“。 其实也可以在某音热点,热点挑战,在社会实事中找内容,演绎出来,表达出来,你看到的很多大v,后面是有编导团队帮他们出谋划策写剧本的,你也可以成为自己的编导,因为你比谁都了解你自己。 但是,你得在枯燥的长文和视频中汲取知识,别老去看那些碎片化的东西,即使看,也要整合信息出来,不然知识左耳进右耳出,没什么用,做事不由东,累死也无功。 ### 2、”对标“ 这个对标不是一直复刻别人,抄别人的,前期你不会,先1:1复刻,分析他里面的内容如何呈现的,如果他那个流量不错,你把他的选题拔下来,放到你自己的选题库,积累起来,对你后来的持续创作很有帮助。之后学会了,那你就可以根据选题做你自己的内容,不用再抄别人的,而是找到了自己的风格,内容。 ### 3、选择 选题:剧情,美食,穿搭,吃播,搞笑,选一个你想做的,然后在这个基础上创造反差,或者放大你的特点,比如你很e,就放大他,去到人群找人访谈,表演节目,做节目的过程中,其实你的人设就已经出来了。再比如:你是宝妈,母婴赛道,你可以结合穿搭,给孩子穿搭,给你自己穿搭,刚好你自己也是个开服装店的女老板,这不两全其美吗? 你可以讲孩子的穿搭,将自己和孩子的穿搭,讲你们之间穿搭好了之后出去找人拍照,旅游,或者你带着孩子去给别人家的孩子们穿搭,这也是做节目,你给地方的妈妈和孩子穿搭,或者你找人演出来,也是一样的效果,但效果没有真实的那么好,除非你是演员。 ## 七、选题写本 **1、正向引导** 不要恶意,不要低俗,不要踩着别人往上爬,不要搞那些有争议的话题,因为不持久,即使你发泄负能量获得了再多的流量,那也只是把你当个乐子或者在这发泄,这种流量是没用的,这叫做流量的陷阱,看似几百万几千万,实际上涨粉寥寥无几,也没实际的粘性。 而且 如果你的内核本身是下剑的,那么吸引来的观众也是下剑的,这个是你要考虑好的,你要什么样的观众?要什么样的粉丝,取决于你的内容。 <blockquote><p>酒鬼大人的校园系列,小熊的姐弟系列,大瑶和孜罗拉的家庭系列,派小轩的职场系列,陈星越的职业病系列和东北人系列和大情种系列,任志达,邢三狗,或者其他的一人分饰多角色的,还有微剧情演绎的,这些角色都有一个共同点,只要差之毫厘这里的内容就会变成负面的激起讨论的有争议的角色,但是要把角色努力的往温情、搞笑的方向去演,这里面没有好人和坏人区分。</p></blockquote> 博主构建的应该是符合社会价值观的,天真快乐的,传递美好的,负面的某音和xhs,以及社会都不允许。 你的回忆和分享:把观众当朋友,分享那些你人生中的幸福时刻,回忆,悲伤以及最后怎么走出来的,失恋之后怎么做的?坐月子期间遇到的趣事,老公和老婆之间的话题,婆媳之间的问题等等。。 大学生日常,带娃日常,职场日常,美术生的日常,搬砖和外卖的日常等等,你觉得没什么可拍的,是你困住自己的信息茧房了,你的生活的有趣的事情别人不知道,有趣的生活和情绪是大家共有的,拍这些共鸣的。 **2、该怎么展示?** 过往,现在,未来。 从时间的角度去描述你的生活,你的过去没人参与,你的现在也是别人的现在,你的未来没人知道,但是会幻想这样的一个未来。这里面的内容必须是精彩的,有共鸣点,痛点的,不要流水账的拍vlog。 <blockquote><p><strong>也就是说:有人对你的生活即将但还未经历的;已经经历过但无法在经历的,到你这找共情的和怀念的;是此生没有机会经历你的生活的</strong></p></blockquote> 比如:我是个外卖小哥,想象一下外卖小哥的日常有什么:原来小哥可以中午才去送外卖,可以随时停止,不用坐班,只是工资会少一些,自由多一些,这样是不是也能营造一种感觉?自由的感觉,在视频里。再比如:小哥的三餐原来都在这家店吃的,还会邀请一些同是外卖小哥的人一起吃,聊些生活,人生,美女美腿,国家大事,还会因为某些争吵,这也很有意思,只是你困在里面不觉得有意思。 再比如:外卖小哥每次都会遇到奇葩的商家和客户,这就可以记录他们的对话,奇葩的事情。这不也是一种方法吗? **再比如**:原来外卖小哥每天穿的衣服是有好几套一样的,穿的鞋子是拖鞋,没想到外卖小哥也会化妆?还会弹钢琴?假设你是个会唱歌的外卖小哥,你送外卖途中去到那些在路上卖唱的地方,你上去献唱一首,你也会火起来,这是反差,也是真实生活带来的活人感。 这些都是别人好奇的,在这里面还可以做反差,夸张的工具箱和大神的工具箱等等,还有比如外卖小哥的一些偷窥,装饰,也都是一种装饰,给观众吐槽的点和喜欢的点,不要局限于一种方式。 其实你换成任何一个行业都适用,看你脑筋会不会转起来,比如换成宝妈的:带着孩子出去玩,遇到的趣事,带孩子去跳舞?练瑜伽?练瑜伽的时候孩子乱跑,和姐姐们聊天,逗她们笑哈哈的,还是个超级e的小孩呢,这不,人设就出来了。 ## 八、视频问题 **1、视频节奏问题:** 留白,表演内容,缓和前面紧凑的笑点,或者给观众联想,停顿、间隙,把内容交给观众,让他们参与其中。最美好的画面是由观众联想出来的。 **比如怎么演?** 有一场戏是这样的,姜文还是谁来着,在雨中对宁静饰演的女主表白,xxx我喜欢你,但是雨声太大,女主没听见,然后再问他说了什么?姜文沉默了好一会,说没有没什么。这是停顿,也是留白,算是给观众联想,以及观众可能也会想到自己吧。 还有另一种,比如我写个台词:走,去网吧。去网吧干嘛?打瓦,瓦是什么?瓦是xxx。这样太墨迹了,改成:走去网吧,去网吧干嘛?打瓦,瓦是xx(还没说出口的时候)你马上大叫:瓦罗兰特(或者大叫里面的经典台词和梗也行),然后另一个人有点懵,他的表情是疑惑的,吓一跳的,就是不说话,用表情帮他说话,这叫做留白。当然,这只是语言和表情的留白,还有摄影留白,结局留白等等,这里不赘述了。(意思是,没用的节奏删了,节奏要快要准) **2、vlog呈现:** vlog是要拍出远离我的生活的,不是零帧起手从头拍到尾的无聊生活。比如外卖小哥的一天,幼师的一天,宝妈旅游的一天,别人就很好奇,拍的时候要有你自己和别人的差异化,信息差。你有自己独特的视角,记录的生活不是流水账,而是你遇到的趣事,有感触的事,这才是vlog。比如你是个带孩子的妈妈,孩子在熟睡,孩子嘴上念叨着妈妈,吐泡泡,刚好是悠闲的夏天,阳光明媚,父子睡在床上的温馨时刻,你在看,在笑。你要记录的是这样东西,而不是记录儿子的每个日常,要发现美,记录美,任何平台都死记录美的,稀缺的生活,不是你稀松平常的生活。 **3、做自己?** 一般来说,人都是带着面具的,在互联网上也是带着各种面具,最好是你有自己喜欢的那一份面具,不要带着别人的面具,不然你做不长久,因为你压根不喜欢那个面具。比如你是个内向敏感的人,非要装很e的人,坚持不久的。 没做到百万粉之前,或者甚至更多粉之前,都不要做自己。因为还没有粉丝粘性,还没认识你的各方面特点和缺点。没人在乎你是谁,做什么的,但是你要差异化。到了那个体量之后就知道什么是有趣的无趣的,可拍的,什么事无趣也可以被你表达的有趣。(但是粉丝越多越不可能做自己,人设定了,所以一开始就要放大自己的你喜欢的那个面具,即使后面变了,也可以慢慢的转变。) **4、视频拖沓:** 比如标题要知道你接下要做什么,有期待感,3s言简意赅表达视频内容,概括不了就抛一个令观众疑惑的点,或者笑点,引人继续往下看,比如:大家好,我是xxx,我要去那边花费了,看看花了多少钱。很墨迹,改成:李狗蛋0元探店,用才艺换吃的。或者:大学生勇闯新德里,一天花多少rmb。 简单高效的表达核心内容。 **5、互联网通病玄学:** 连赞限流、换号、评论活跃度这都是玄学!神金!别信!内容好就有流量。 ## 九、记忆点 当博主要有记忆点:比如jc勾导总说:shift,damn,中式西海岸;比如张若宇,以前总戴着面膜。比如李宗恒,表情和动作也基本定型了。比如盖亚奥特曼,一出场比怪兽动作还大,还有其他奥特曼,总是用L的手势发出光线。 记忆点,我第一时间想到十日终焉燕知春的自述那一段,白羊敲了敲桌子给自己制造记忆点。(小说主角也有自己的记忆点) 比如剑来的那一段:“剑来”,比如雪中悍刀行的“剑来”,再比如海贼王路飞的戴帽子扶着帽子,不留出眼神的时候,那就是怒了。 比如索隆三刀流也是他的标志、长鼻子乌索普、乔巴大小变等等。火影的萨斯给和那路多的魔性名字,以及他们的标注动作。凡人的韩立将众人护至身前等等。 太多了,你也要有自己的记忆点,这是强人设的关键。 比如你偶尔暴了一条:你得跟上,后面发的那些都是视频版朋友圈,别人不爱看,要在你的爆款里面提取内容来创作。要做一个系列出来最好**(剧情演绎类的,符合你人设和你所见所闻的,要有自己的差异)** 这时候你爆款的那条,你就可以去看评论区和弹幕他们怎么评价你的,取其精华,去其糟粕,留下观众爱看的,不好的去掉,慢慢的你就找到自己的专属记忆点了。 ## 十、注意点 能不能先去做其他抽象赛道吸粉,然后再换赛道?肯定不能,这不是背刺观众吗? 搞噱头吸引黑粉?也不行,没把观众当人,自以为是,他们是活生生的人,不是单纯的数字,尊重观众,观众才尊重你。 有自己的想法喜好,不是你想怎么支配就怎么支配的,你算个球啊。 你因为穿搭而关注她了,但是三个月之后她不教穿搭了,她开始拍剧情了,能不能取关她?能! **个人ip的框架:** 很多演绎的账号既拍美妆,测评,搞笑和美食,变装,但是她的框架没变,她的人没变,吸引别人的是那个她,有才华和颜值的她。 也是喜欢她的剧情演绎带来的情绪感和共鸣感等等。透过表达看灵魂,越真实的真人感, 才能看到灵魂,所以越红的人你越看不到她的活人感。 比如: 你平时本来就是个幽默搞笑的有点内向的自言自语的,但是一面对镜头就露怯,表现得端庄,声音突然放大,表达刻意,表情比平时更稳重,那就不是你了。 举个例子:平时你面对朋友都是嘻嘻哈哈大大咧咧的,面对镜头其实也是面对你的“朋友”,你突然端庄了,不好意思了,那这不是你了,就好像你手里拿着鞭炮,旁白有坨牛粪,你不去炸它,那你都不是你了。 **你得大大咧咧,要向对朋友一样对“观众”,这样你才真实可信,所谓的活人感就是如此。** 互联网上塑造真实的你,比真实的你更加真实,放大你的特点和人设,就像下暴雨很想去淋雨一样,你平时是不敢的,但是在网上,你要释放你的情绪和真实感想。 在此刻你放大自己的情绪,表达你的内心的真实,观众才会感到共鸣,产生情绪。 共情感和灵魂(活人感真实感)是互联网的本质:普通vlog能火不是专业的剪辑和美妆,不是什么商务舱和劳斯莱斯,而是我的情绪和感受。 比如真实的哭泣,开怀的大笑等等。不要模板化的表达,比如:今天第一次去做商务舱,看看今天有什么喜欢的点赞收藏,我们出发把,这样没用。(毫无情绪) 不要别人拍什么你就跟着抄袭模仿拍什么,而是找到自己的灵魂和人设,赛道。 你只是跟着别人拍你才拍,但那是你吗?不是你,没有自己的灵魂。 拍vlog的人不是一个性格的和模板化的,无悲无喜的,而是要记录情绪和冲突互动瞬间。 举个例子:你第一次做飞机,你记录你真实的感受,情绪,哭出来或者眼睛红了,想到以前的什么,想到父母之类的,表达最真实的你。 有时候内容不重要,重要在初心和真切的表达,重要在成为自己,只有真实,只有你面对某件事谈露出你真实的内心,这才是大家共鸣的点。 估计讲到这,还有人不会。 **那我就好人做到底,给你几个分析的具体的例子:** 家居和瓷砖怎么拍? 比如你是个美女哈,你懂行业的内幕,有相关的知识干货,行业内的实战派,有自己的人格魅力如:真诚,负责,励志,搞笑美女,幽默中输出知识等等。你还有深层次的认知,讲家居和瓷砖,不只是讲这些业内知识,你讲这个沙发,联系到小时候没有沙发客人来了也不知道怎么做,显得家里空落落的,客人若有若无的眼神刺痛了你,然后xxx,这联系到了你的过往和人生经历,话题又扩大了,有人说,这会不会不垂直呀?不会,垂直是个伪概念,有人要买就早买了,但是你的坦诚,真诚,会更愿意来你这边买。人都不傻,想买不知道去搜索吗对吧? 好了,那我们根据这个选题:“云朵沙发是我此生的执念”“齐边床和我父母一样齐了一辈子”,“小孩子圆头该选择的床和枕头”等等,那么你怎么拍呢? 这个我教不了,除非线下一对一的教,这个你需要去找拍摄的交差,剪辑的教程。看一些好的内容,看他们里面的框架是怎么样的,你可以挪用框架来用,不过最好是能体现你自己的风格和类型最好。比如你的拍摄风格是日常Vlog类型的,一边口播,一边讲述过往和产品,中间穿插其他素材来论证,日常对话等等,加入旁白,加入同期声。 有的人则可能用某个导演的叙事风格去拍,拍出高级感的感觉,中景,远景,近景,以及特写,转场,都用上。打光,场景搭建等等,想办法形成他喜欢的风格。 没有标准答案,拍摄和风格不如内容重要,你的内容是吸引人看下去的关键。 选题和你的方向都有了,你应该会拍了吧?如果连拍都不会的话,去学,别问,先去学。 **宝妈母婴怎么拍?** 和上述一样的,你先找出你孩子的特点,找出你的特点,缺点,优势,大家都有的痛点,比如怎么防止孩子扁头。 选题呢则多了去了。如“带着孩子旅游,实际上是弥补我小时候缺失的部分”,“几个月大的小孩环游世界“,”孩子是个物理天才“,“1个月大就会背诗了”,“以孩子的视角看世界” 比如用“孩子的视角看世界”戴上拇指相机,全景相机,给他来个惊世骇俗的视角,用孩子的眼光看世界,后期配音录旁白,加上同期声。这样一个选题和内容就出来了。当然,其中的内容细节你得自己雕琢,这个说不明白,讲不清楚,你去看别人的好内容应该就知道了,先去分析和看,多看多练才是王道。 有了流量,先别急着变现什么的,流量是为了塑造你的人设,占据用户心智,或者在市场上留下你的印象给到观众,之后做广告,投流什么的就方便了,而且有了流量和人设,有账号和粉丝,你想找谁合作一甩出来不就好说话了嘛,流量时代,相当于以往在电视上看到的广告一样。这是流量,也是钱。 为什么不急着变现?你不得先稳固一下吗?不然观众会眼红的,人性如此。至少你得给足够的价值给到观众,之后才考虑变现。 本文由 @王富贵儿本人 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务


Canada said it will adjust its existing counter-tariffs on steel and aluminium products on July 21, to levels consistent with progress that has been made in the broader trading arrangement with the U.S.

首批参与跨境支付通的内地机构包括工商银行、农业银行、中国银行、建设银行、交通银行和招商银行;香港机构则包括中银香港、东亚银行、建银亚洲、恒生银行、汇丰银行和工银亚洲。未来,参与范围将逐步扩大。

<blockquote><p>作为在智能客服领域摸爬滚打五年的产品经理,见过太多通用智能客服的失败案例。电商大促时被咨询量冲垮的系统、金融客服因话术不合规引发的监管预警、教育场景里通用答疑被家长吐槽 "答非所问"——这些问题见多了才明白:行业差异才是真正决定智能客服生死的关键变量。今天就从一线实战视角,聊聊三大行业智能客服那些 "看似相同,实则天差地别" 的设计逻辑。</p> </blockquote>  ## 一、行业痛点:被业务模式重塑的客服战场 ### 电商:双 11 凌晨三点的系统生死战 记得去年负责某头部电商客服系统升级时,预售期第一天就遇到了 “地狱级” 考验:每秒 2.3 万笔订单涌入,售后咨询量同比暴涨 400%,传统 FAQ 库在 “定金能不能退”” 跨店满减怎么算 “的问题洪流下直接瘫痪。最惊险的是凌晨两点,物流查询接口因并发过高出现超时,当时整个团队盯着监控屏冷汗直冒 —— 这让我深刻意识到,电商客服的核心战场从来不是” 答对问题 “,而是” 活下来 “。 **核心要解决三个硬骨头**: - **订单物流的实时穿透能力**:必须像手术刀一样精准对接 OMS/WMS/TMS 系统。我们当时用 Kafka 搭建消息队列,把物流轨迹查询接口的响应时间从 3 秒压到 800 毫秒,还做了三级缓存策略(浏览器缓存 + CDN+Redis),才扛过峰值期 - **促销规则的平民化翻译**:双 11 那套 “满 300 减 50 + 品类券 + 店铺券” 的叠加逻辑,连内部运营都算不清。后来我们做了个 “促销计算器” 功能,用户只要截图购物车,系统就能用整数规划算法算出最优组合,再用 “三步省钱法” 的口语化话术解释 - **全渠道的记忆延续性**:有个典型案例:用户在 APP 咨询退货没解决,转头在微信小程序用不同账号追问,结果客服让重复描述问题,直接引发投诉。后来我们用 OneID 体系打通全渠道,用户不管从哪个入口进来,系统都能显示历史会话记录,转接人工时还会自动生成 “问题摘要卡片” ### 金融:每句话都可能踩雷的合规钢丝 在对接某城商行智能客服项目时,合规审核团队给我们上了震撼一课:一句 “这款理财近期收益不错” 就可能被认定违规,因为没同步提示风险。更棘手的是不同业务线合规要求差异极大:信用卡客服和理财客服的话术库完全是两套体系,甚至同一产品在不同地区的宣传口径都有细微差别。 **构建合规防线需要三层防护**: - **实时话术扫描引擎**:我们用 Neo4j 搭建了金融监管知识图谱,把《商业银行理财业务监督管理办法》等法规拆解成 5000 + 条规则节点。当客服输入 “预期收益” 时,系统会立即标红,并弹出 “必须搭配 ‘ 不构成投资建议 ‘ 话术” 的提示框 - **军工级身份验证链**:记得有次测试修改银行卡密码场景,传统短信验证码方案被合规部门否决,最后落地了 “短信验证码 + 活体检测 + 动态令牌” 的三重验证。更麻烦的是审计留痕,每个敏感操作都要生成包含时间戳、操作人、IP 地址的区块链式日志,满足监管 7 年可追溯要求 - **专业知识的推理闭环**:处理 “组合风险评估” 类问题时,我们发现简单问答根本不够。后来做了个 “智能投顾助手”,能关联用户持仓的 15 只基金,调用市场实时行情数据,用简化版蒙特卡洛模型计算 VaR 值,最后生成带图表的风险简报,这种深度服务让客户满意度提升了 37% ### 教育:每个错题背后都是不同的认知地图 在跟进某 K12 教育客服项目时,一个细节让我印象深刻:两个学生都卡在 “鸡兔同笼” 问题,A 是没理解假设法逻辑,B 则是混淆了头数和脚数的计算。但传统客服统一回复 “假设全是鸡…” 的标准答案,结果 A 听懂了,B 更懵了 —— 这让我们意识到,教育客服的本质不是给答案,而是做 “认知 CT 扫描”。 **个性化需要数据驱动的三层架构**: - **学习诊断引擎**:我们整合了 LMS 系统里的 200 万条答题记录,用贝叶斯知识追踪模型构建每个学生的知识漏洞图谱。比如发现某个学生 “三角函数诱导公式” 的掌握度只有 32%,系统会自动推送 3 分钟微课切片和 5 道靶向练习题 - **招生季的智能应答矩阵**:开学季咨询量暴增时,我们做了个 “课程顾问助手”。当家长问 “初二数学怎么提分”,系统会先分析孩子的测评数据(假设几何证明题错误率 65%),然后匹配对应课程(如 “几何专题突破班”),再调取授课老师的提分案例和排课时间,形成完整的推荐方案 - **效果可视化桥梁**:家长最关心的是 “有没有效果”。我们用 ECharts 开发了知识点热力图,红色区域代表薄弱点,绿色是优势项。每周生成的学习报告里,会用 “你家孩子本周在 ‘ 二次函数图像 ‘ 进步显著,建议接下来攻克 ‘ 函数与方程结合题 ‘” 这样的表述,让抽象的学习效果变得可感知 ## 二、功能设计:场景化落地的实战武器库 ### 电商版:效率至上的自动化作战系统 在设计某生鲜电商客服系统时,我们把 “秒级响应” 作为第一原则。最得意的是那个 “物流应急处理插件”:当系统检测到某区域快递大面积延迟,会自动触发三个动作:①给该区域用户发送安抚短信 ②在客服界面置顶解决方案 ③生成批量退款的 RPA 流程。这套组合拳让大促期间的投诉量下降了 62%。 **三个核心功能的落地心得**: - **订单穿透查询模块**:别做简单的 API 调用,我们当时踩过坑:直接调 OMS 接口在峰值期扛不住。后来做了分级处理:常用状态(已发货 / 派送中)走 Redis 缓存,异常状态(丢件 / 破损)才穿透查数据库,还加了熔断机制,当错误率超过 20% 自动切换到降级模式 - **促销规则引擎**:Drools 规则引擎虽然强大,但促销逻辑复杂时容易崩。我们做了个 “规则测试沙盒”,运营可以先在测试环境模拟各种组合(比如 “满 299 减 50” 叠加 “新人券”),系统会自动生成规则覆盖度报告,确保没有逻辑漏洞 - **智能路由策略**:单纯按技能分组不够,我们加了三个维度:①用户画像(VIP 客户直接走专属通道) ②问题紧急度(退货问题优先分配) ③客服状态(根据历史解决率和当前会话数动态调整)。这套算法让平均处理时长缩短了 41% ### 金融版:安全与专业并重的双引擎 服务某股份制银行时,合规部门提出了 “零风险话术” 要求,逼得我们把话术审核做到了极致。最有成就感的是那个 “合规知识库动态更新系统”:每当银保监会发布新文件,我们的爬虫系统会自动抓取,AI 团队用 2 小时就能完成知识点拆解和规则映射,确保客服话术永远符合最新要求。 **三个关键模块的设计要点**: - **实时合规防火墙**:别只用关键词匹配,我们吃过大亏:用户问 “这个产品保本吗”,客服回复 “非保本,但历史收益稳定”,结果因未完整提示风险被警告。后来升级成语义理解模型,能识别 “隐性风险遗漏”,比如检测到 “收益” 关键词时,自动校验是否包含 “不保证” 等必备表述 - **多因子认证链**:活体检测要考虑用户体验,我们做了个 “分级验证” 设计:普通查询用静态人脸比对,大额转账才启动活体检测。为了防攻击,还加了 “环境风险评估”,当检测到非常用设备或异常 IP 时,自动提升验证级别 - **金融知识图谱应用**:构建图谱时踩过术语标准化的坑,比如 “久期” 在不同部门有不同解释。后来我们联合行内专家做了三个月的术语对齐,建立了包含 8000 + 节点的金融图谱,现在用户问 “美联储加息对我的债券基金有什么影响”,系统能关联到持仓产品的久期数据,生成影响分析图 ### 教育版:数据驱动的个性化学习助手 在某职业教育项目中,我们发现传统客服只能解决 “课程什么时候开始” 这类表层问题,而 “学习效果不好怎么办” 才是深层需求。于是开发了 “学习诊断工作台”,客服能看到学生的完整学习轨迹:哪些视频反复观看,哪些习题总是做错,甚至能看到注意力曲线(比如在第 12 分钟后注意力明显下降)。 **三个创新功能的落地经验**: - **知识漏洞定位系统**:别迷信单一算法,我们试过 BKT 和 KST 模型,发现各有优劣。后来做了个 “混合诊断模型”,简单知识点用 BKT 快速定位,复杂概念用 KST 深度分析。为了验证准确性,我们让 50 个学生做测试,系统诊断结果和老师人工分析的吻合度达到 89% - **智能课程推荐引擎**:别只看历史成绩,我们加入了 “学习风格” 维度:视觉型学习者推荐图文课件,听觉型学习者优先推荐直播课。还做了个 “课程匹配度雷达图”,从难度、内容、老师风格等五个维度展示推荐理由,让家长一目了然 - **学习报告自动化生成**:别用模板化表述,我们收集了 1000 条老师评语,用 NLG 技术生成个性化建议。比如 “你在 ‘Python 函数 ‘ 部分进步很快,但 ‘ 异常处理 ‘ 还需加强,建议下周重点练习 3 类异常场景”。这种报告让家长满意度提升了 53% ## 三、落地心法:从方案设计到价值变现的关键跨越 ### 电商实施:在洪峰中淬炼系统韧性 做某跨境电商项目时,我们经历了黑色星期五的极限考验。提前三个月做的压测显示系统能扛 10 万 QPS,但实际流量达到 15 万时还是出了问题。紧急扩容后,我们总结出三个关键: - **弹性架构的三层设计**:应用层用 Kubernetes 做自动扩缩容,数据层用分库分表 + 读写分离,缓存层用多级架构(本地缓存 + 分布式缓存)。现在这套架构能应对 20 万 QPS 的突发流量 - **知识库的敏捷更新机制**:大促前两周,我们会组建 “知识库突击队”,和运营团队一起梳理 500 + 促销规则,用思维导图拆解后导入系统。还开发了 “规则冲突检测工具”,能自动识别 “满减门槛重叠” 等问题 - **人机协作的黄金比例**:通过数据分析发现,机器人解决率在 75% 时整体效率最高。高于这个值会导致用户体验下降,低于这个值则成本过高。我们据此设置了智能切换机制,当机器人连续三次无法解决问题时,自动转接人工 ### 金融落地:合规是生命线,专业是竞争力 服务某头部券商时,合规审批流程之严格超出想象。光是身份验证模块就改了 12 版,最后落地的方案包含七个安全组件: - **纵深防御体系构建**:网络层用 WAF+IPS,数据层用国密算法加密,应用层用 RBAC+ABAC 双重权限控制。最关键的是审计模块,每个操作都记录到区块链,确保不可篡改 - **合规知识库的动态运营**:组建了 5 人专职团队,每天监控监管动态,每周更新知识库。还开发了 “合规影响分析工具”,当新法规发布时,能自动评估对现有话术的影响范围 - **专家审核的闭环机制**:建立了 “模型输出 – 专家审核 – 数据反馈” 的闭环。每周金融专家会抽查 200 条 AI 回复,错误案例用于优化模型。这套机制让合规准确率从 85% 提升到 99.2% ### 教育落地:数据打通是基础,持续进化是关键 在某国际学校项目中,我们花了四个月打通了 12 个系统的数据,最终建成的教育数据中台包含三类核心数据: - **统一数据中台架构**:用 Delta Lake 构建数据湖,存储原始学习行为数据;用 Snowflake 搭建数据仓库,做结构化分析;通过 API 网关为各业务系统提供数据服务。现在客服能看到学生的完整学习画像 - **知识图谱的迭代优化**:先构建基础学科本体,再通过 “人工标注 + AI 挖掘” 不断完善。比如数学学科,我们细分到 182 个知识点,每个知识点关联 3-5 个典型例题和 2 个微课资源 - **个性化引擎的持续进化**:建立了 A/B 测试平台,每周测试 2-3 个推荐策略。比如对比 “基于错题推荐” 和 “基于学习目标推荐” 的效果,用转化率和完课率作为评估指标。这套机制让学习资源的利用率提升了 47% ## 行业 Know-How 才是智能客服的灵魂 五年产品经理生涯,最深的体会是:智能客服不是技术的堆砌,而是行业认知的外化。电商需要的是 “毫秒级响应的效率机器”,金融要求 “滴水不漏的合规卫士”,教育则渴望 “因材施教的学习伙伴”。 记得有次和某教育机构 CEO 聊天,他说:”你们做的不是客服系统,是教育服务的数字化分身。” 这句话点醒了我:真正优秀的智能客服,是能把行业的专业知识、服务逻辑、用户心理都融入代码的产品。 所以别再迷信 “通用解决方案”,当你准备为某个行业设计智能客服时,先花三个月泡在业务里:跟着电商客服处理大促咨询,坐在金融合规部门学习监管细则,陪着教育顾问做学情分析。只有把行业的 “味道” 闻透了,做出来的系统才不会 “水土不服”。 这三个行业的智能客服就像三棵树:电商树需要发达的 “根系”(系统集成能力),金融树要有坚硬的 “树干”(安全合规架构),教育树则需要茂密的 “枝叶”(个性化服务网络)。而浇灌它们的,从来不是通用的 AI 技术,而是深入骨髓的行业理解。 AI智能客服系列文章: [AI 智能客服落地实战:从需求调研到 ROI 评估的全周期复盘](https://www.woshipm.com/ai/6232493.html) [智能客服知识库从数据清洗到动态优化的实战全流程](https://www.woshipm.com/pd/6230588.html) [智能客服多轮对话设计:用户意图识别与业务转化的系统化实践](https://www.woshipm.com/pd/6229885.html) [从 0到1搭建AI智能客服系统:踩坑经验与实战架构选型指南](https://www.woshipm.com/pd/6229811.html) 本文由 @阿堂聊产品 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议

<blockquote><p>在杭州的杭钢公园散步时,作者意外地领悟了泡泡玛特旗下潮流玩具Labubu“丑萌”却爆火的秘密。这两个看似毫不相关的现象——工业遗存的美学复兴与潮流玩具的爆火——背后都蕴含着康德所说的“无目的的合目的性”这一美学原理。本文将带你从哲学、心理学和商业的角度,深入剖析“丑萌”设计背后所隐藏的审美密码,以及它如何在现代社会中引发广泛共鸣和商业成功。</p> </blockquote>  周末去逛了一圈杭州的杭钢公园,才慢慢理解康德所说“无目的的合目的性”,进而,开始理解泡泡玛特创始人王宁所说的“无用”的东西才是真正永恒的。 杭钢公园的那些昔日冰冷的钢铁巨构,如今摇身一变,成了城市里独特的工业美学地标;一个是风靡全球的潮流玩具 Labubu,它那副“丑萌丑萌”的样子,却让无数年轻人为之疯狂;。两个看似不搭边儿的现象,存在共同之处。 ## 杭钢公园:工业遗存的“无目的”转生 杭钢公园。  这座曾经轰鸣的钢铁厂,那些高耸入云的高炉、密布的管道、蜿蜒的运输轨道,它们被设计和建造的唯一目的,就是为了高效炼钢,追求耐久、安全和产能。它们是典型的**“客观目的性装置”**。 当工厂停产,这些钢铁巨构就失去了它们原本的、外在的、生产性的功用。它们一度被视为城市更新中的“闲置废墟”,甚至面临被拆除的命运。 然而,家琨老师却选择了另一种方式,巧妙地保留了这些钢铁结构的锈蚀肌理和宏大尺度,将昔日的高炉改造成了观景台,将铸铁机房变成了露天剧场。这些操作,彻底消解了它们原有的生产功能。 我们漫步其中,不再关心钢铁的熔炼指标,也不再思考机器的生产效率。我们被那些粗犷的线条、斑驳的锈迹、以及巨大的体量所震撼。当站在高炉脚下,仰望那直插云霄的工业巨人时,人们体验到了一种介于恐惧与敬畏之间的**崇高情绪**。这种体验,正对应着康德所谓“心灵对自我能力的意识”——在巨大且无法被完全把握的形式面前,我们感受到自身的渺小,但又同时意识到自己作为理性存在者,能够超越这种渺小,从而产生一种内在的愉悦。这份崇高感,正是源于形式之宏大,而非实用之功效。 园区内还举办各种音乐会、快闪活动和艺术展览,这些赋予了工业遗存新的社会互动功能,但其核心魅力,依然是那些宏大、独特的钢铁形式本身所带来的自由想象和审美体验。它们从“目的性”的工具,转生为“无目的”的艺术品。 ## 什么是“无目的的合目的性”? 康德在他的《判断力批判》里,对“目的性”做了区分。他把“目的性”分成了两种:一种是**“客观目的性”**,另一种是**“主观合目的性”**。  - **客观目的性**,很好理解,就是指一个对象是为了某个外部功用而存在的。比如一把椅子,它的目的是为了让人坐;一台炼钢炉,它的目的是为了炼钢。它有明确的、外在的、实用的功能。 - 而**主观合目的性**,就比较抽象了。它指的是,当我们在欣赏一个对象时,我们并没有去考虑它的实用功能,它的形式本身却能在我们主体的“心灵”中,激发一种**“自由的合奏”**。康德认为,这种合奏,指的是我们的想象力与知性(理解力)之间的一种和谐而自由的互动。 当我们的审美判断摆脱了功利性的束缚,也就是不去考虑这个对象“有什么用”的时候,这个对象就呈现出一种**“无目的”**的状态。但奇怪的是,虽然它没有外在目的,它的形式却又恰好符合我们想象力与知性自由玩耍的需求,所以康德把它叫做**“无目的的合目的性”**。 在这种状态下,我们产生的审美快感,不依赖于任何概念(比如“这是个可爱的玩具”或“这是个宏伟的建筑”),也不依赖于任何功利(比如“这个玩具能赚钱”或“这个公园能纳凉”)。这种快感,仅仅是基于对象形式给我们的感受,而这种感受,康德认为具有“主观普遍性”,也就是说,虽然是主观体验,但这种体验是可以被大多数人所理解和分享的,因此能够引发情感上的共鸣。 ## 丑,为何被狂热追捧? 理解了杭钢公园保留下来的底蕴,套到 Labubu 身上,你会发现,一切都变得清晰起来。 Labubu 的设计非常有意思:它有着夸张的大耳朵、尖尖的牙齿,看起来有点凶,但同时它的体态又很软糯、圆润,整体比例也打破了传统意义上的“美学规整”。这种**“反差萌”**在视觉上制造了一种强烈的**“陌生化”**效果。当人们第一次看到它时,往往会感到一丝惊奇,甚至是有点“丑”的感觉。 这种“丑怪”感,恰恰迫使我们放弃了平时习惯的审美尺度,比如“漂亮—规整”的功利性衡量标准。我们无法用常规的“可爱”或“美”的概念去框定它,也无法从它身上立即找到一个明确的实用功能(它只是个摆件)。 当这种功利性的审美框架瞬间崩解时,我们不再被“它应该是什么样子”所限制,而是让想象力在“丑陋”和“可爱”之间自由穿梭,尝试理解这种矛盾的美感。丑陋的尖牙与可爱的体态,在我们的想象力中彼此补偿,最终生成了一种全新的、独特的审美秩序——“丑萌”。 更有趣的是,Labubu 作为一个 IP,它有自己的角色设定和家族叙事。这种叙事,为消费者提供了情感投射的入口。不同的人,可以在 Labubu 身上投射出自己童年的记忆、对叛逆精神的向往,或是寻求一种被治愈的情感。这种能够引发**主观普遍性共鸣**的特质,进一步强化了社群的认同感和传播力。  而盲盒机制的随机性,更是将这种“自由游戏”的时间无限延长。消费者在抽取、猜测、收集和交换的过程中,反复体验着那种不带功利目的的**期望与快感**。每拆开一个盒子,都是一次审美和惊喜的“自由游戏”。至于二级市场的高溢价,看似是纯粹的功利行为,但它恰恰反证了 Labubu 作为一种“社交货币”所带来的形而上快感的稀缺性与可分享性。人们愿意为这种被群体认可的、能引发共鸣的“美”支付溢价。 ## 美学密码的共通之处 现在,我们可以清晰地看到 Labubu 和杭钢公园之间存在的**同构性**: **1)从“目的性装置”到“无目的的合目的性”:** Labubu 最初在绘本中是一个捣蛋的角色,有其特定的叙事功能。杭钢的设备更是纯粹为了炼钢而生。它们都是服务于某个明确“目的”的装置。 但当它们被置于新的文化语境中(潮玩市场、城市公园),其原始目的逐渐退场。Labubu 的“丑萌”不再是为了吓人或某种情节,杭钢的钢结构不再是为了生产。此时,它们的形式美感开始凸显,进入了“无目的的合目的性”阶段。 **2)形式的“陌生化”与心灵的“震颤”:** Labubu 夸张的尖牙和另类的笑容,如同高炉上斑驳的锈蚀皮肤,都因为超出我们日常生活的比例和认知,而引发了观者心灵的独特震颤。这种“异样”感,促使我们放弃功利判断,进入纯粹的审美体验。 **3)主观普遍性的传播:** 消费者在社交平台分享购买 Labubu 的喜悦和收藏心得,游客们则热衷于在杭钢公园打卡拍照,分享巨构带来的震撼体验。这都是将个体的主观快感,通过社交媒体外化,并完成主观普遍性的传播。 **4)新的“外在目的”围绕原初魅力展开:** Labubu 的二次创作、联名鞋款等,以及杭钢公园举办的音乐会、沉浸式剧场等,都是在原初形式魅力基础上被赋予的新的“外在目的”。但这些新的商业和文化活动,之所以能够成功,始终是围绕着其独特的、能够引发“无目的审美”的原初形式魅力而展开。这证明了其核心的审美价值才是持久吸引力的源泉。 ## 合目的性带来的未来启发 Labubu 的“丑萌奇迹”与杭钢公园的工业美学复兴,这两个看似风马牛不相及的现象,最终在康德的“无目的的合目的性”框架下,找到了共通的底层逻辑。它们共同证明了,审美快感不必依赖于传统的美学范式,而可以源自于形式与心灵之间自由而和谐的对接。 在这个A快速变化的时代,当外在功能和实用价值变得越来越容易被复制和超越时,真正持久的竞争力,可能恰恰来自于这种合目的性的创新。 本文由 @乔伊 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

<blockquote><p>在仓储管理系统(WMS)的复杂业务流程中,入库管理是核心环节之一。本文将带你深入了解WMS系统中入库管理的原型图设计及业务逻辑实战。</p> </blockquote>  之前文章与大家分享了[WMS产品架构图](https://www.woshipm.com/share/6211894.html)、[预约入库管理](https://www.woshipm.com/share/6215187.html)、[收货管理](https://www.woshipm.com/share/6215364.html)、[质检管理](https://www.woshipm.com/pd/6219896.html)部分,今天继续为大家分享WMS系列中的原型图设计及逻辑实战部分:入库**管理**。 ## 场景 1、质检完成后,将质检合格的产品进行入库。 2、入库完成后增加实际库存,并自动触发补货上架任务。 ## 入库管理 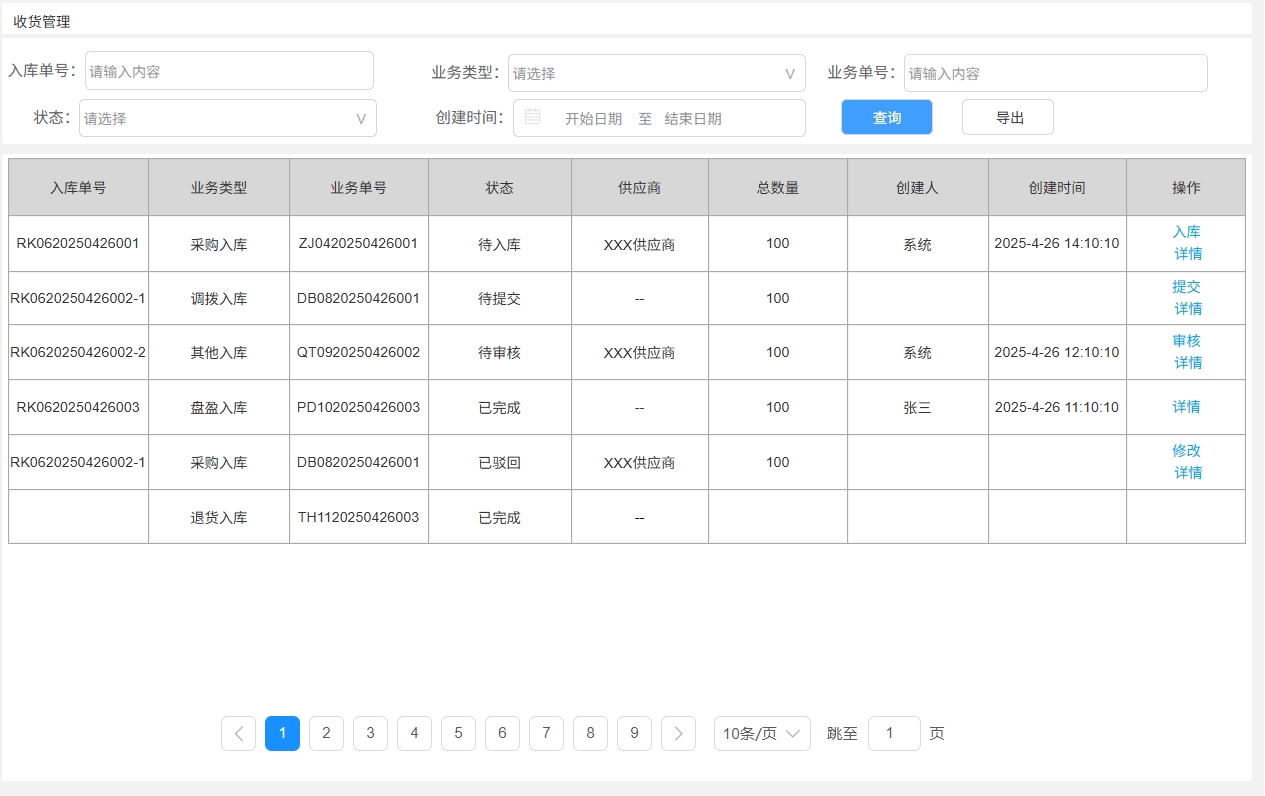 ### 状态说明 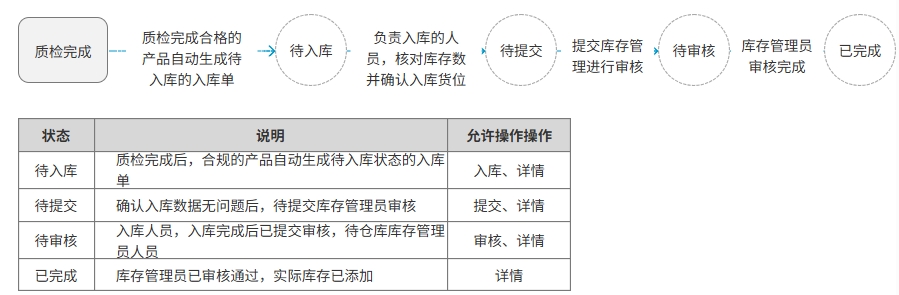 ### 业务类型说明 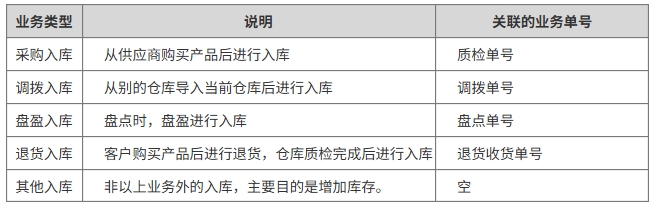 ### 页面属性详情 **查询区关键信息说明** 入库单号:精确查询。 业务类型:单选,可选值详情业务类型说明。 业务单号:精确查询。 状态: 单选,可选值详见状态说明。 创建时间:精确到天,包含两边日期。 导出;导出符合查询条件的数据,导出的列同步列表中展示的数据。 **列表关键信息** 排序:按创建时间倒序。 入库单号:生成规则:RK+06+年月日+三位流水号,如SJ0520250521001。 业务类型:具体业务生产的入库单,详见业务类型说明。 业务单号:具体业务单号,详见业务类型说明。 总数量:入库数量。 创建人:当前单据创建人,若是质检完成后自动创建的单据,创建人为系统。 **主要操作** 入库:点击后弹出入库页面。 详情:点击后弹出详情页 提交:点击后弹出二次提醒框“确定提交吗,提交后将不能修改” 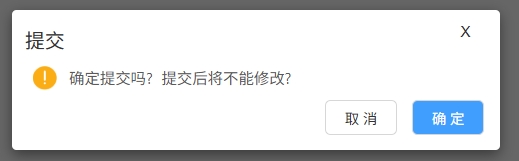 修改:点击后弹出修改页面。 ## 入库 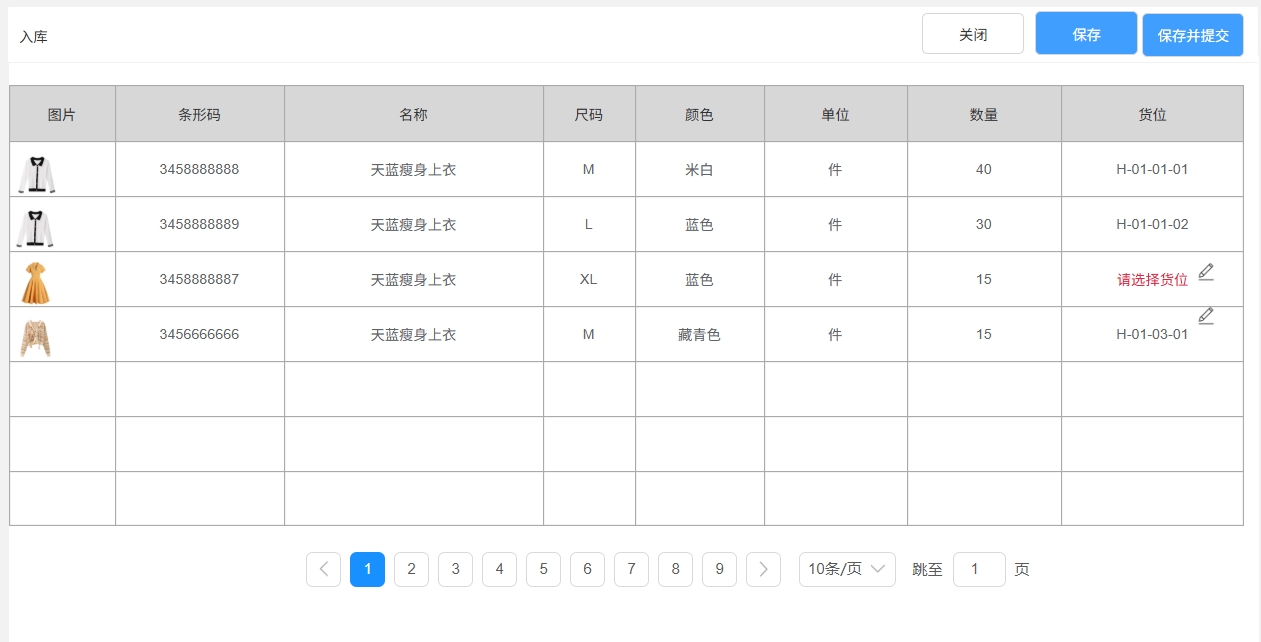 **场景:** 满足库存入库人员核对库存数量、分配入库货位。 **货位默认逻辑为**:当前产品在存货区剩余库存数是否大于0 大于:取当前产品所在存货区的货位为当前货位,且不允许修改。 小于等于0:显示空,并支持修改。点击修改图片时,弹出选择货位选择页面 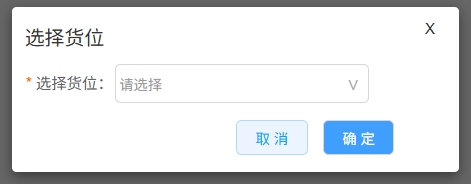 可选择的货位为:存货区已启用&未被占用的货位。 **主要操作** **保存**:仅保存当前入库单。保存时校验“是否存在货位为空”的情况 存在为空的产品:提示“请选择货位”,并将为空的产品现在是前面 不存在为空的情况:操作后状态为“待提交” **保存并提交**:保存并提交审核。保存并提交时校验“是否存在货位为空”的情况 存在为空的产品:提示“请选择货位”,并将为空的产品现在是前面 不存在为空的情况:提示“操作后将不能修改,是否继续?”,确定后状态更新为待审核。 ## 修改入库信息 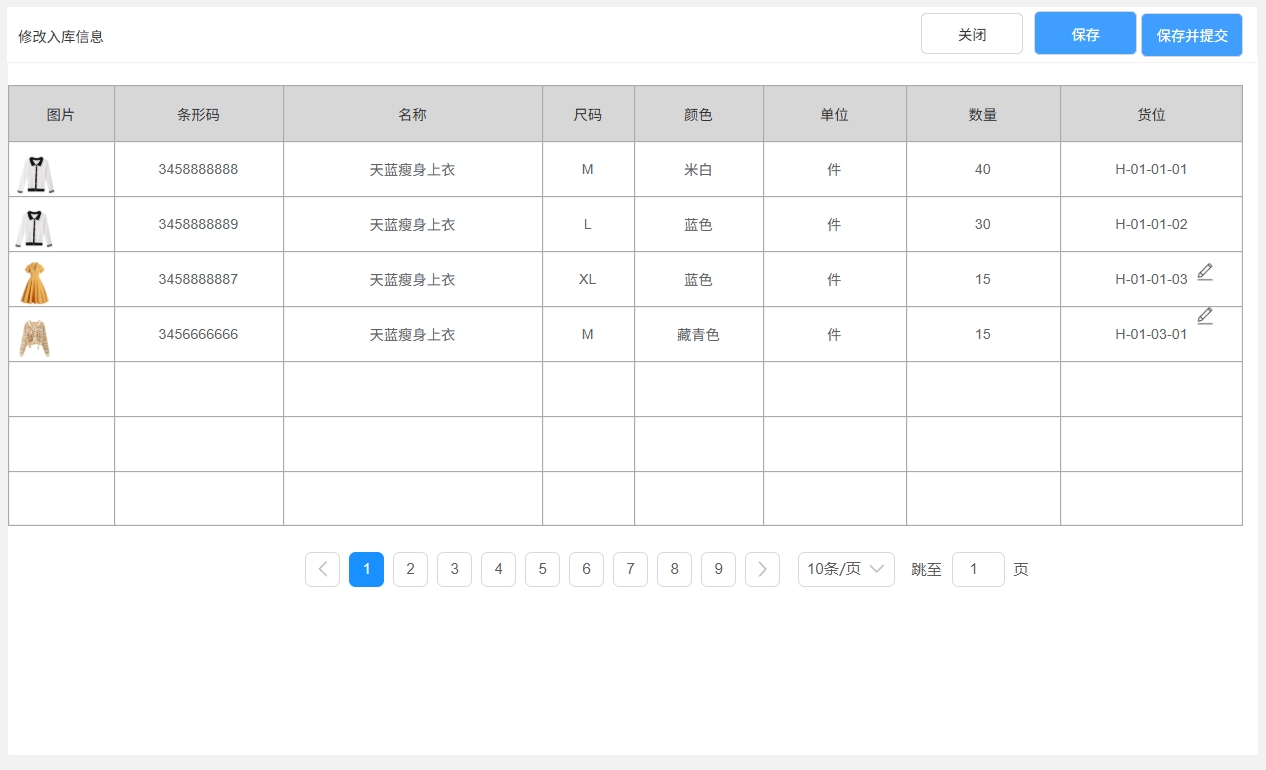 **场景:**满足库存入库人员核对库存数量、修改入库货位。 其他功能及操作同入库页。 ## 审核入库 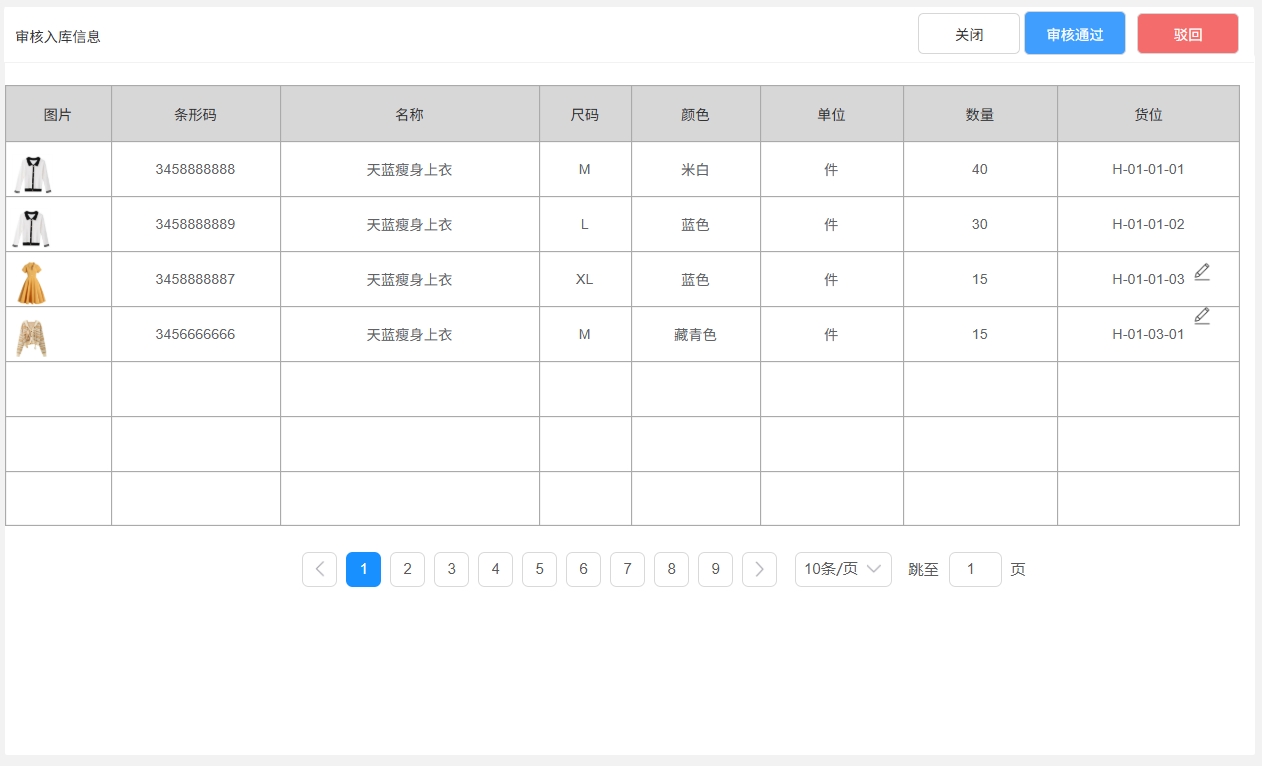 **场景** 满足库存管理员审核入库的数量及货位。无异于可以进行审核通过,有医院支持进行驳回,并需要填写驳回原因。 **主要操作** 驳回:点击驳回后,弹出驳回原因输入框,且驳回原因必填。  审核通过:点击审核通过后,提示“审核通过后将不能修改,确定审核通过吗?”;  确定后 1)更新单据状态为已完成。 2)增加实际库存、可用库存。 3)自动回传入库状态给其他业务。 如通知预约业务,将预约单更新为已完成;通知补货业务,根据补货规则自动触发补货任务;通知预售业务,根据预售规则,自动下发拣货单。 本文由 @刚哥 原创投稿或者授权发布于人人都是产品经理。未经许可,禁止转载。 题图来自 Unsplash,基于 CC0 协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。

人能闯多大的祸?有人在博物馆里坐塌了镶满水晶的“梵高椅”,落荒而逃,有人则硬生生掰断兵马俑的拇指,还偷偷带回家。近日,意大利马费宫博物馆的一个展品被游客破坏的新闻很出名,说的是一对夫妻在参观的时候,为了出片,不顾周围的警告,男子擅自坐在了镶有施华洛世奇水晶的椅子上,导致椅子倒塌。  看到此情此景,这对夫妻选择仓皇逃跑,行迹恶劣,最后被博物馆发视频挂网上“通缉”了。 其实,展品被破坏,类似的新闻实在太多了。有的是熊孩子顽皮,有的确实是巧合,例如摔倒时撞坏展品,但有的是真的天生存有恶意,就是故意破坏。 这让我想起之前特别轰动的一个案例:在美国展出的兵马俑拇指被盗案。  △ 拇指被掰断 450万美元的兵马俑被破坏,6年后才定罪 可以说,这个案子就是故意损坏,当事人也承认了,但没想到要定罪,很难。 2017年12月21日,美国男子罗哈纳正在费城的富兰克林科学博物馆里参加一个周末派对——圣诞节前派对,途中罗哈纳和2个朋友偷偷溜进了已经闭馆的展厅,而这个展厅里出展的正是借调到美国的10个兵马俑。 2朋友看了一会就走了,但罗哈纳对兵马俑很感兴趣,左看右看研究了一会,还上手了。手臂搭在其中一个兵马俑肩膀上,拍了一张自拍照,离开时意犹未尽,竟直接掰断了兵马俑左手的拇指,塞口袋里带回家了。 几个星期后,博物馆才发现拇指不见了,然后报警,很快警察就找到了罗哈纳,罗哈纳本人也承认了,从他卧室的抽屉里拿出拇指归还。  本来案子是非常清晰的,被破坏的兵马俑预估价值高达450万美元,有2000年的历史。我们的态度也很坚决,借调这么多次,第一次发生这么恶劣的事情,因此要求“严厉惩罚”。 如果以“盗窃和藏匿文物”来定罪,罗哈纳是真的很“刑”,刑期可达30年。 意想不到的是,经过三次法院审理,时隔6年,也就是2023年9月,罗哈纳才判:5年缓刑,5000美元罚款、100小时社区服务,还有赔偿金额(具体数额没找到)。 但根据新闻报道,我们修复花了2.5万美元,对方博物馆零零总总花了5万多美元,赔偿金应该也大差不差了。罗哈纳有收藏球鞋的爱好,据说他的球鞋就价值3.2万美元,他可以卖掉球鞋凑一部分。  为何前后差距这么大呢?因为罗哈纳最终罪名是:跨州贩运文物——该罪名轻很多,最高只需服刑2年和罚款2万美元。 前两次的审判迟迟没有结果,是在下面这些事情上有争议: 1、罗哈纳的行为是否属于严重盗窃文物行为? 律师坚称,罗哈纳只是一个喝醉了的年轻人,不是恶意要盗窃,顶多是“年轻人的破坏行为”,不应该用盗窃文物来定罪。 而且认为博物馆安保措施也有过错,明明闭馆了,却还能进去。  △ 游客跳入兵马俑坑 2、被盗拇指价值多少? 这是争论最多的一项,撇开雕塑本身,拇指本身究竟值多少钱? 双方意见不一致,控方觉得拇指价值是整个兵马俑的5%,差不多是15万美元(兵马俑价值也说法不一),而辩方请的专家则认为拇指顶多值1000美元,因为出土的时候,拇指本身就是断的,展示的是修复后的成品。 如果金额没有超过5000美元,就不能用艺术品盗窃来定。 也就是因为这原因,第二次审,法院以“出土文物,没有参考市场交易价格”为由,没做出判决,陪审团也解散了。 原本是2020年要再审的,因为疫情又延期了,直到2023年才重启,双方达成认罪协议,罗哈纳以“跨州贩运文物”定罪。  △ 某平台截图:爆料自己的作品遭到破坏 最后 不过有一说一,像这样喜欢对展品动手的,全世界都有,比我们想象得要普遍。 大到珍贵文物,即使有保护罩,免不了要上手敲一敲、拍一拍的;小到毕业生作品展示,明令禁止触摸,也会被破坏。 看展,也是一种人性考验! [查看评论](https://m.cnbeta.com.tw/comment/1508168.htm)

韩国雇佣劳动部决定从今年起全面改革劳动工时制度,并推广每周4.5天工作制,工作时间由每周52小时缩短至48小时(工资保持不变)。韩国媒体报道称,政府提出明确目标:计划到2030年,将2024年基准的年均劳动时间从1859小时缩短至经合组织(OECD)平均水平1717小时以下。 **此外,为切实缩短实际工作时间,政府计划优化年假与弹性工作制度。2025年底至2026年间,将年假获取资格从"工作满1年"放宽至"满6个月",同步引入年假储蓄制度、按小时休假机制,并禁止企业对休假员工实施差别待遇。** [](//img1.mydrivers.com/img/20250621/04a762c2e7b34b17ae2f32f858c3b31a.jpg) 同时将构建弹性工作制度体系。通过立法确立"弹性工作申请权",允许劳动者在满足条件时向雇主提出弹性工作安排申请,雇主无正当理由不得拒绝。远程办公、错峰上下班等多样化工作方式将正式纳入制度范畴,政府正在研究对采用企业给予行政及财政激励的方案。 [查看评论](https://m.cnbeta.com.tw/comment/1508166.htm)
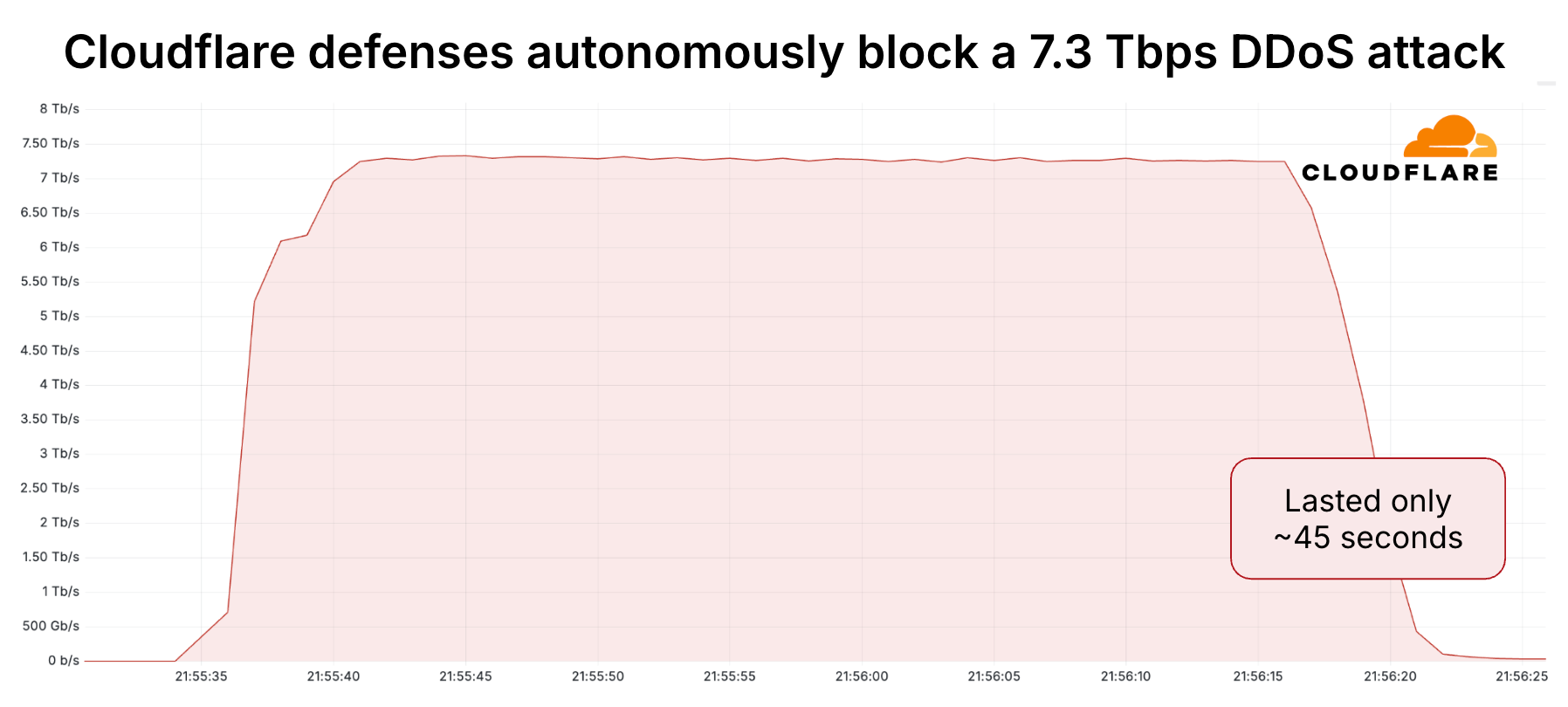
大规模攻击旨在通过向互联网服务发送超过其处理能力的流量来使其瘫痪,其规模越来越大,迄今为止最大的一次攻击流量达到每秒 7.3 太比特,这是互联网安全和性能提供商 Cloudflare 于周五报告的。 此次攻击的目标是 Cloudflare 的客户,一家使用Magic Transit保护其 IP 网络的托管服务提供商。  此次 7.3Tbps 的攻击总计 37.4TB 的垃圾流量,仅用 45 秒就击中目标。这几乎是一个难以想象的数据量,相当于在不到一分钟的时间内传输了超过 9300 部完整高清电影或 7500 小时的高清流媒体内容。 Cloudflare[表示,](https://blog.cloudflare.com/defending-the-internet-how-cloudflare-blocked-a-monumental-7-3-tbps-ddos/)攻击者“地毯式轰炸”了目标 IP 地址平均近 22000 个目标端口,而该 IP 地址仅被确认为 Cloudflare 客户。总计有 34500 个端口成为攻击目标,这表明此次攻击的彻底性和精心策划的性质。  此次攻击的绝大部分内容是以用户数据报协议 (UDP) 数据包的形式进行的。合法的 UDP 传输通常用于对时间特别敏感的通信,例如视频播放、游戏应用程序和 DNS 查询。UDP 通过在数据传输前不正式建立连接来加快通信速度。与更常见的传输控制协议 (TCP) 不同,UDP 不会等待两台计算机通过握手建立连接,也不会检查对方是否正确接收了数据。相反,它会立即将数据从一台计算机发送到另一台计算机。  UDP 洪水攻击会向目标 IP 上的随机或特定端口发送大量数据包。此类洪水攻击可能会导致目标的互联网链路饱和,或使内部资源因数据包数量超过其处理能力而不堪重负。 由于 UDP 无需握手,攻击者可以利用它向目标服务器发送大量流量,而无需事先获得服务器的传输许可。UDP 泛洪攻击通常会向目标系统的多个端口发送大量数据报。目标系统则必须发送相同数量的数据包,以表明端口无法访问。最终,目标系统不堪重负,导致合法流量被拒绝。  一小部分攻击(占比仅为 0.004%)是通过反射攻击发起的。反射攻击会将恶意流量导向一个或多个第三方中介,例如用于同步服务器时钟的网络时间协议 (NTP) 服务。攻击者会伪造恶意数据包的发送方 IP,使其看起来像是由最终目标发送的。当第三方发送响应时,响应会被发送到目标,而不是原始流量来源的目的地。 反射攻击为攻击者提供了多重好处。首先,此类攻击使得 DDoS 攻击从各种各样的目的地发起。这使得目标更难抵御攻击。此外,通过选择已知会生成比原始请求大数千倍的响应的中间服务器,攻击者可以将可用的攻击火力放大千倍甚至更多。Cloudflare 和其他公司经常建议服务器管理员锁定服务器,以防止它们响应欺骗数据包,但不可避免的是,许多人并没有听从这些建议。 Cloudflare 表示,创纪录的 DDoS 攻击利用了各种反射或放大向量,包括前面提到的网络时间协议、每日报价协议(它在 UDP 端口 17 上监听并以简短的报价或消息进行响应)、Echo 协议(它使用接收到的相同数据进行响应)以及用于识别通过远程过程调用连接的应用程序可用资源的 Portmapper 服务。 Cloudflare 表示,此次攻击还通过一个或多个基于 Mirai 的僵尸网络发起。此类僵尸网络通常由家庭和小型办公室路由器、网络摄像头以及其他已遭入侵的物联网设备组成。 过去三十年来,DDoS 规模持续稳步攀升。今年3 月,诺基亚报告称,一个名为 Eleven11bot 的僵尸网络发起了一次峰值流量达 6.5Tbps 的 DDoS 攻击。5 月,KrebsonSecurity[表示](https://krebsonsecurity.com/2025/05/krebsonsecurity-hit-with-near-record-6-3-tbps-ddos/)其遭受了一次峰值流量达 6.3Tbps 的 DDoS 攻击。 [查看评论](https://m.cnbeta.com.tw/comment/1508162.htm)