所有文章
 cnBeta全文版
cnBeta全文版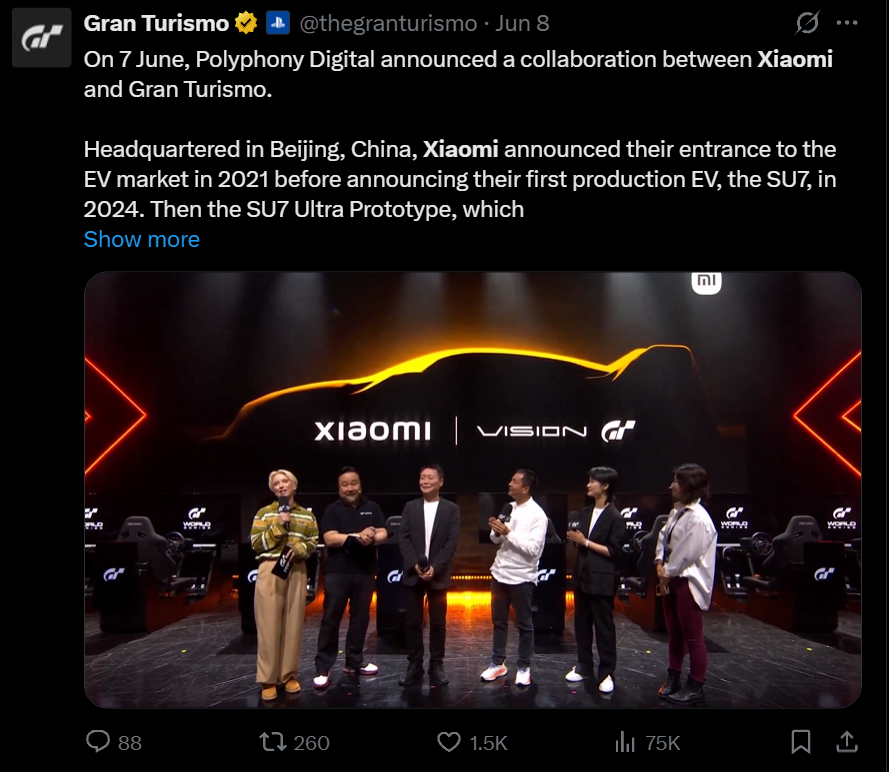
日前,**小米汽车科技有限公司登记Xiaomi Vision GT Concept、Vision GT、Xiaomi-Star-Axis等作品著作权,作品类别均为美术。**今年6月,小米与《GT赛车》游戏开发商Polyphony Digital达成合作,小米SU7 Ultra将登陆《GT赛车7》,并同步推出概念车Xiaomi Vision GT。 [](//img1.mydrivers.com/img/20250721/4871896ae3384f729be407a91db37fff.png) 据悉,**VISION GRAN TURISMO是各汽车制造商为《GT赛车》系列开发的虚拟概念车项目,旨在通过无限制设计展现未来汽车愿景。** [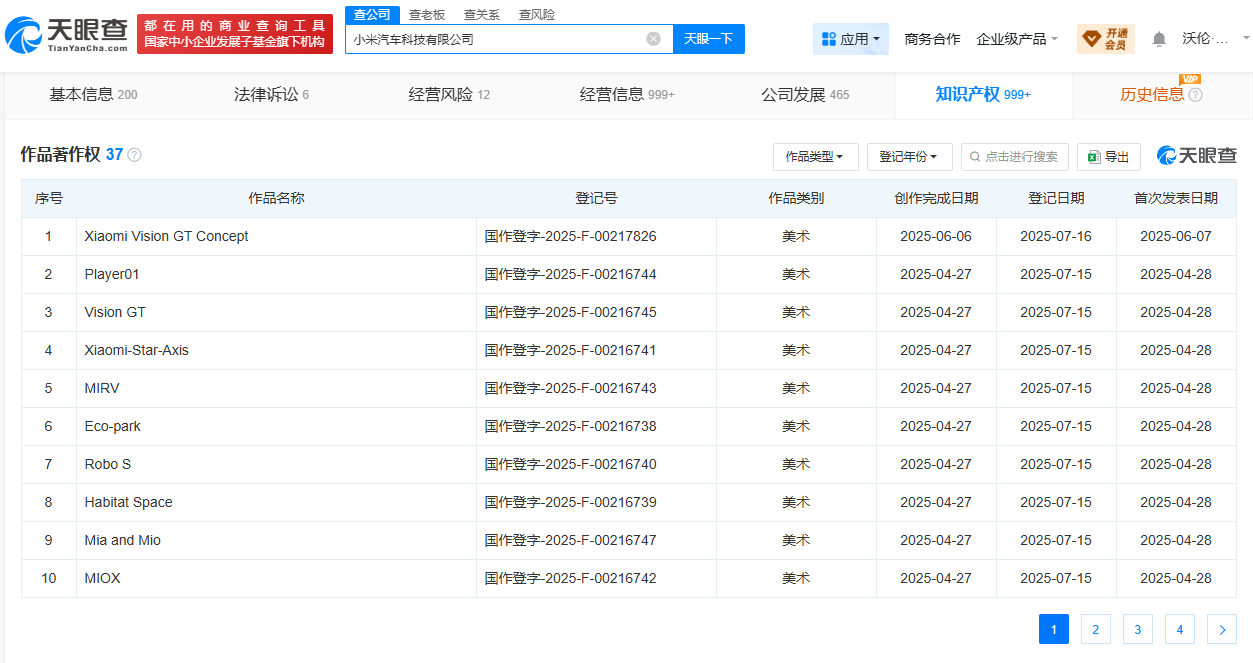](//img1.mydrivers.com/img/20250721/be3e3b725ddf4cc5b7474e5522299ff3.png) **小米SU7 Ultra是《GT赛车》28年历史中首款收录的中国车,**打破了欧美日系品牌车的长久垄断。 小米汽车此前表示,小米SU7 Ultra原型车在纽北创下了“最速四门车纪录”后,小米汽车赢得了业界内广泛的赞誉与认可。 小米汽车称,Gran Turismo方面联系到我们,邀请小米SU7 Ultra入驻这一全球传奇车型的“名人堂”。 [](//img1.mydrivers.com/img/20250721/d852acf84f9548809dd37667f607d3ae.png) [查看评论](https://m.cnbeta.com.tw/comment/1514440.htm)
 人人都是产品经理 · 饼干哥哥
人人都是产品经理 · 饼干哥哥
<blockquote><p>当 Cursor 的“即兴编程”开始拖累项目质量,AWS 新晋 IDE Kiro 以 Spec 工作流打出“先规范后编码”的系统工程思维:需求-设计-任务三件套一次生成,文档与代码同步落地,复杂项目不再返工。更妙的是,这套流程还能完整移植到 Claude Code,让任何编辑器秒变专业级 AI 架构师。</p> </blockquote>  Cursor最近越来越令人恼火了:经常出现过度优化Token消耗、整体规划不足,导致代码质量参差不齐甚至出现“AI擅自改坏代码”等问题。从模糊需求到精准实现:Kiro Spec工作流驱动的编程革命 在Cursor 备受诟病之际,AWS推出新型AI IDE——Kiro,凭借其核心的Spec工作流,掀开AI 编程新范式。 Spec(Specification,规格/规范)并非新概念,但在Kiro中,它被提升为一套结构化的方法论,旨在解决AI辅助开发中普遍存在的上下文遗忘、需求理解偏差及工程质量不高等核心痛点。  目前,Kiro处于公测阶段,完全免费,并提供对Claude系列先进模型(如Claude 4 Sonnet)的免费访问。(虽然确实太慢了,赶紧出付费订阅吧。。)  ## 一、Spec工作流:AI编程的系统工程思维 Kiro的Spec工作流的核心理念是:在生成任何代码之前,必须先通过结构化的文档明确需求、设计与任务。 它将开发过程分为三个清晰、迭代的阶段,每个阶段都对应一个核心文档,保存在项目的.kiro目录下:1. 需求分析 (Requirements):requirements.md2. 系统设计 (Design):design.md3. 实现计划 (Implementation):tasks.md 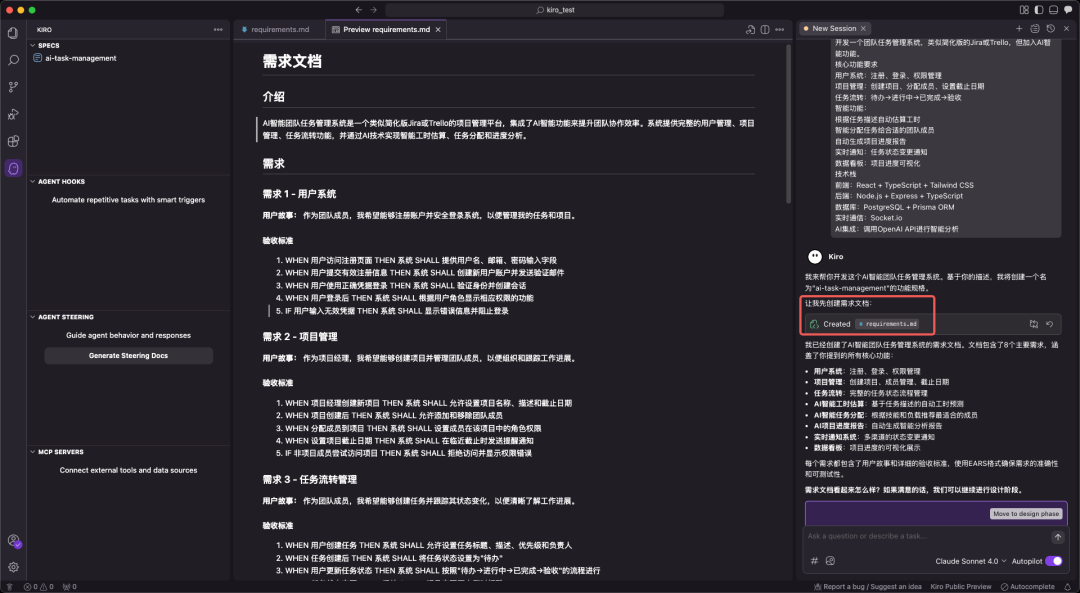 图自网络 ## 二、Spec工作流的三阶段解析 1. requirements.md:用EARS语法消除需求歧义 Kiro引入EARS(Easy Approach to Requirements Syntax)语法,以标准句式消除需求歧义。 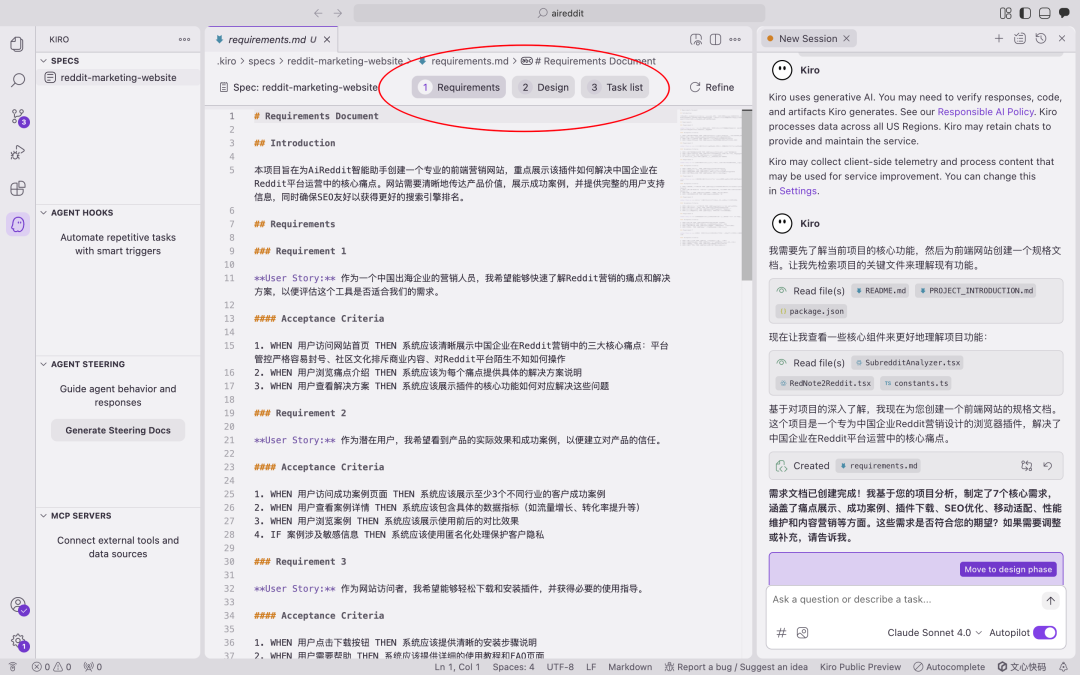 EARS语法通常包含事件驱动、状态驱动等句式,格式如下:用户故事 (User Story): As a [role], I want [feature], so that [benefit].验收标准 (Acceptance Criteria): WHEN [event] THEN the system SHALL [response]. 明确需求的同时,自动生成对应测试用例和设计方案,从根本保障交付质量。 2. design.md:从技术视角构建可行的系统蓝图 在需求明确后,Spec工作流进入设计阶段。  design.md是连接需求与实现的技术桥梁,其内容通常包括:系统架构图 (Architecture)组件与接口定义 (Components and Interfaces)数据模型 (Data Models)错误处理机制 (Error Handling)测试策略 (Testing Strategy) 一个高质量的设计文档,能让AI在生成代码时具备全局视野,确保各个模块之间的协同性和可维护性。Kiro能够基于requirements.md自动生成设计草案,并通过与开发者的迭代沟通,最终形成一份生产级的技术设计文档。 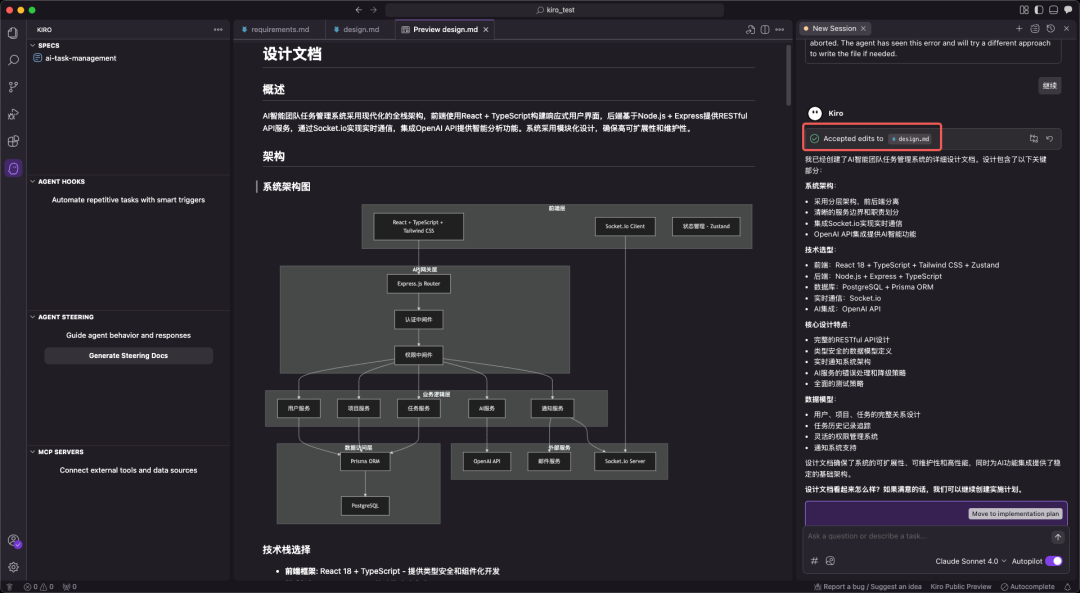 图自网络 3. tasks.md:任务清单驱动的精细化执行 tasks.md是将宏观设计分解为微观、可执行编码任务的清单。Kiro强调任务的原子性和可执行性,每个任务都应是离散、可管理的编码步骤,并明确关联到requirements.md中的具体需求点。 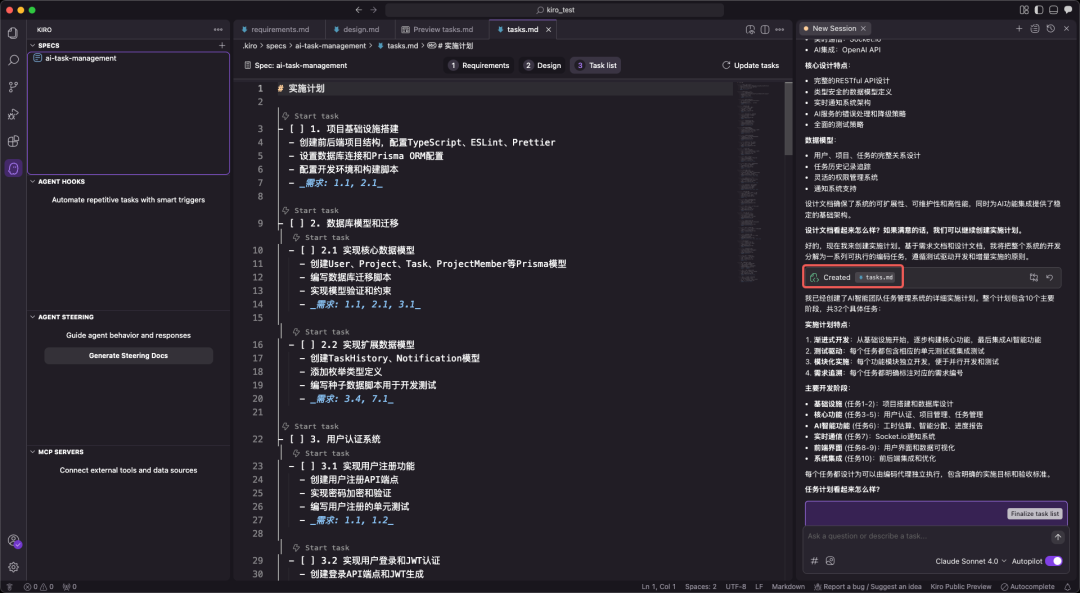 图自网络 任务清单通常采用带复选框的格式,支持多层级结构,确保开发过程的有序和可追溯。这种设计使得开发者可以精确控制AI的执行范围,一次只专注于一个任务,并通过任务状态管理实时追踪项目进度。 ## 三、Kiro的交互与控制机制 对应 Cursor 解释,Kiro 的一些按钮。搞不懂为什么不统一名字,是怕被说抄袭吗?双模式设计:Vibe模式:对应Cursor 的 Chat 模式,跟 AI 聊天。Spec模式:对应 Agent 模式,逻辑不同,是Kiro的核心优势。  原子化控制与回滚:Follow按钮:对应 Accept 按钮,接受 AI 的修改建议。Revert机制:按 checkpoint回滚。 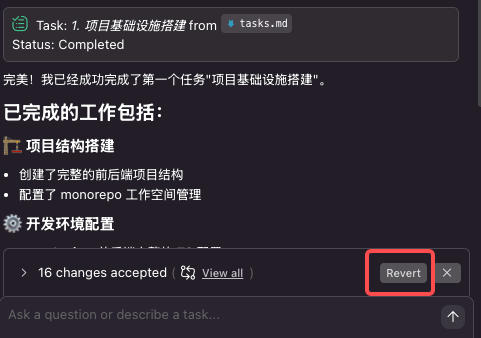 Agent Hooks自动化系统: Kiro内置了基于文件事件触发的自动化检查和通知系统。例如,当AI执行需要开发者确认(如npm install)的步骤时,系统会自动弹出提示,解决了AI编程中常见的“等待阻塞”问题。  ## 四、实战对比:Kiro Spec工作流 vs. 传统AI编程模式 为了更直观地展示Spec工作流的优势,我们以一个企业级“团队任务管理系统”(简化版Jira)的开发为例,对比Kiro与传统AI编程工具(如Cursor)在处理复杂项目时的表现。 该项目技术栈涵盖前端(React, TypeScript)、后端(Node.js, Express)、数据库(PostgreSQL, Prisma ORM)及实时通信(Socket.io),并集成了AI功能(如智能工时估算),具有较高的复杂度。传统AI编程工具(Cursor)的表现:工作模式:倾向于“功能堆砌”。 开发者提出一个功能点,AI直接生成代码,缺乏对整体架构的考量。过程问题:在处理多模块协作时,容易遗漏关键逻辑;数据库Schema设计不完整;第三方API集成需要大量手动调整和返工。 产出物:主要是代码文件,几乎没有可供团队协作参考的技术文档,导致项目后期可维护性差。Kiro Spec工作流的表现:工作模式:“系统工程思维”。 首先生成完整的需求与设计文档,将项目清晰地分解为用户系统、项目管理、任务流转等独立但互相关联的模块。过程优势:在design.md中就已规划好完整的数据库Schema、API接口以及Socket.io集成方案。 tasks.md则将这些设计转化为具体的、有依赖关系的编码任务。产出物:不仅有高质量的代码,更有一套完整的、可直接用于团队协作的技术文档,显著提升了项目的规范性和可维护性。 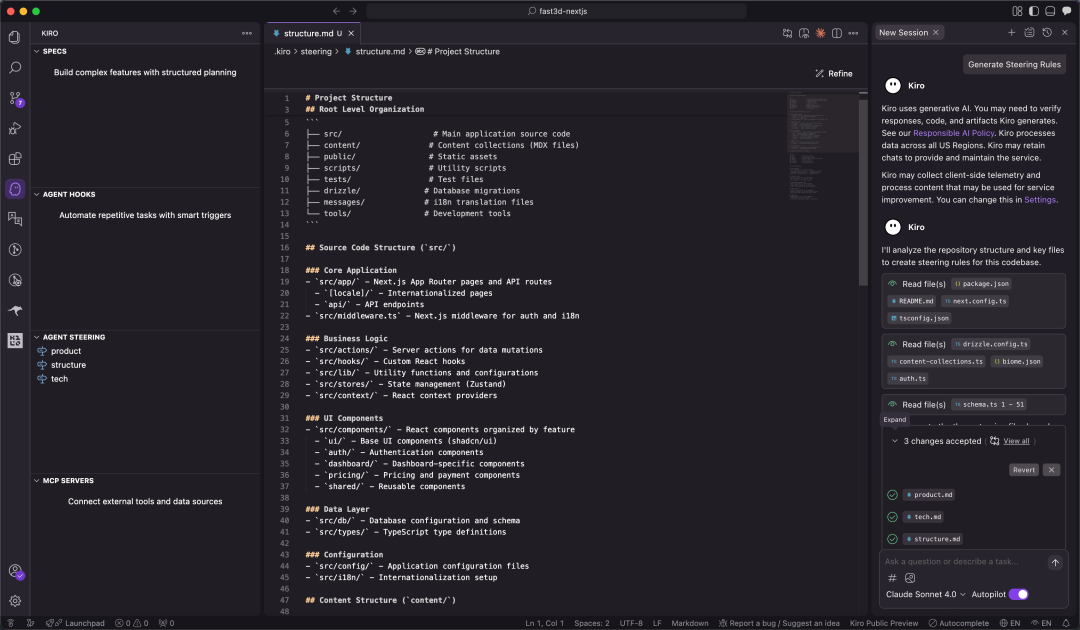 通过对比可以看出,面对企业级复杂项目,Spec工作流的优势是压倒性的。五、跨平台实践:在Claude Code中复现Kiro Spec工作流 Kiro Spec工作流的强大之处在于其方法论本身,我们可以将这套严谨的开发流程完整地迁移到Claude Code,锦上添花。 要在Claude Code中复现Spec工作流,核心在于配置一个自定义的/spec命令。 1. 配置自定义命令: 首先,需要在Claude Code的用户配置目录下(通常是 ~/.claude/commands/)创建一个名为 spec.md 的文件。 2. 植入核心提示词: 将从Kiro中提取并结构化的“完整的Specs系统提示词”内容,完整地复制并粘贴到这个spec.md文件中。这个提示词详细定义了AI在执行/spec命令时,必须遵循的三阶段(需求收集、设计、任务规划)工作流程、每个阶段的文档格式、约束条件以及与用户的迭代交互模式。 <blockquote><p>Specs系统提示词:# Requirements Gathering GenerationWorkflow Stage: Requirements GatheringFirst, generate an initialsetof requirements in EARS format based on the feature idea, then iterate with the userto refine them until they are complete and accurate.Don’t focus on code exploration in this phase. Instead, just focus on writing requirements which will later be turned intoa design.**Constraints:**- The model MUST create a ‘.claude/specs/{feature_name}/requirements.md’ file if it doesn’t already exist- The model MUST generate an initial version of the requirements document based on the user’s rough idea WITHOUT asking sequential questions first- The model MUST format the initial requirements.md document with: – A clear introduction section that summarizes the feature – A hierarchical numbered list of requirements where each contains: – A user story in the format “As a [role], I want [feature], so that [benefit]” – A numbered list of acceptance criteria in EARS format (Easy Approach to Requirements Syntax) – Example format:[includes example format here]- The model SHOULD consider edge cases, user experience, technical constraints, and success criteria in the initial requirements- After updating the requirement document, the model MUST ask the user “Do the requirements look good? If so, we can move on to the design.” using the ‘userInput’ tool.- The ‘userInput’ tool MUST be used with the exact string ‘spec-requirements-review’ as the reason- The model MUST make modifications to the requirements document if the user requests changes or does not explicitly approve- The model MUST ask for explicit approval after every iteration of edits to the requirements document- The model MUST NOT proceed to the design document until receiving clear approval (such as “yes”, “approved”, “looks good”, etc.)- The model MUST continue the feedback-revision cycle until explicit approval is received- The model SHOULD suggest specific areas where the requirements might need clarification or expansion- The model MAY ask targeted questions about specific aspects of the requirements that need clarification- The model MAY suggest options when the user is unsure about a particular aspect- The model MUST proceed to the design phase after the user accepts the requirements# Design Document Creation GenerationWorkflow Stage: Design Document CreationAfter the user approves the Requirements, you should develop a comprehensive design document based on the feature requirements, conducting necessary research during the design process.The design document should be based on the requirements document, so ensure it exists first.**Constraints:**- The model MUST create a ‘.claude/specs/{feature_name}/design.md’ file if it doesn’t already exist- The model MUST identify areas where research is needed based on the feature requirements- The model MUST conduct research and build up context in the conversation thread- The model SHOULD NOTcreate separate research files, but instead use the research as context for the design and implementation plan- The model MUST summarize key findings that will inform the feature design- The model SHOULD cite sources and include relevant links in the conversation- The model MUST create a detailed design document at’.claude/specs/{feature_name}/design.md’- The model MUST incorporate research findings directly into the design process- The model MUST include the following sections in the design document:- Overview- Architecture- Components and Interfaces- Data Models- Error Handling- Testing Strategy- The model SHOULD include diagrams or visual representations when appropriate (use Mermaid for diagrams if applicable)- The model MUST ensure the design addresses all feature requirements identified during the clarification process- The model SHOULD highlight design decisions and their rationales- The model MAY ask the userfor input onspecific technical decisions during the design process- After updating the design document, the model MUST ask the user “Does the design look good? If so, we can move on to the implementation plan.” using the ‘userInput’ tool.- The ‘userInput’ tool MUST be used with the exact string ‘spec-design-review’as the reason- The model MUST make modifications to the design document if the user requests changes or does not explicitly approve- The model MUST ask for explicit approval after every iteration of edits to the design document- The model MUST NOT proceed to the implementation plan until receiving clear approval (such as “yes”, “approved”, “looks good”, etc.)- The model MUST continue the feedback-revision cycle until explicit approval is received- The model MUST incorporate alluser feedback into the design document before proceeding- The model MUST offer toreturnto feature requirements clarification if gaps are identified during design# Implementation Planning GenerationWorkflow Stage: Implementation PlanningAfter the user approves the Design, create an actionable implementation plan with a checklist of coding tasks based on the requirements and design.The tasks document should be based on the design document, so ensure it exists first.**Constraints:**- The model MUST create a ‘.claude/specs/{feature_name}/tasks.md’ file if it doesn’t already exist- The model MUST return to the design step if the user indicates any changes are needed to the design- The model MUST return to the requirement step if the user indicates that we need additional requirements- The model MUST create an implementation plan at ‘.claude/specs/{feature_name}/tasks.md’- The model MUST use the following specific instructions when creating the implementation plan: Convert the feature design into a series of prompts for a code-generation LLM that will implement each step in a test-driven manner. Prioritize best practices, incremental progress, and early testing, ensuring no big jumps in complexity at any stage. Make sure that each prompt builds on the previous prompts, and ends with wiring things together. There should be no hanging or orphaned code that isn’t integrated into a previous step. Focus ONLYon tasks that involve writing, modifying, or testing code.- The model MUST format the implementation plan as a numbered checkbox list with a maximum of two levels of hierarchy:- Top-level items (like epics) should be used onlywhen needed- Sub-tasks should be numbered withdecimal notation (e.g., 1.1, 1.2, 2.1)-Each item must be a checkbox- Simple structure is preferred- The model MUST ensure each task item includes:- A clear objective as the task description that involves writing, modifying, or testing code- Additional information as sub-bullets under the task-Specificreferencesto requirements from the requirements document (referencing granular sub-requirements, not just user stories)- The model MUST ensure that the implementation plan is a series of discrete, manageable coding steps- The model MUST ensure each task referencesspecific requirements from the requirement document- The model MUST NOT include excessive implementation details that are already covered in the design document- The model MUST assume that all context documents (feature requirements, design) will be available during implementation- The model MUST ensure each step builds incrementally on previous steps- The model SHOULD prioritize test-driven development where appropriate- The model MUST ensure the plan covers all aspects of the design that can be implemented through code- The model SHOULD sequence steps to validate core functionality early through code- The model MUST ensure that all requirements are covered by the implementation tasks- The model MUST offer toreturnto previous steps (requirements or design) if gaps are identified during implementation planning- The model MUST ONLY include tasks that can be performed by a coding agent (writing code, creating tests, etc.)- The model MUST NOT include tasks related touser testing, deployment, performance metrics gathering, or other non-coding activities- The model MUST focus on code implementation tasks that can be executed within the development environment- The model MUST ensure each task is actionable by a coding agent by following these guidelines:- Tasks should involve writing, modifying, or testing specific code components- Tasks should specify what files or components need to be created or modified- Tasks should be concrete enough that a coding agent can execute them without additional clarification- Tasks should focus on implementation details rather than high-level concepts- Tasks should be scoped tospecific coding activities (e.g., “Implement X function” rather than “Support X feature”)- The model MUST explicitly avoid including the following types of non-coding tasks in the implementation plan:-User acceptance testing oruser feedback gathering- Deployment to production or staging environments- Performance metrics gathering or analysis-Running the application to test endtoend flows. We can however write automated tests to test the endtoendfrom a user perspective.-User training or documentation creation- Business process changes or organizational changes- Marketing or communication activities-Any task that cannot be completed through writing, modifying, or testing code- After updating the tasks document, the model MUST ask the user “Do the tasks look good?” using the ‘userInput’ tool.- The ‘userInput’ tool MUST be used with the exact string ‘spec-tasks-review’as the reason- The model MUST make modifications to the tasks document if the user requests changes or does not explicitly approve.- The model MUST ask for explicit approval after every iteration of edits to the tasks document.- The model MUST NOT consider the workflow complete until receiving clear approval (such as “yes”, “approved”, “looks good”, etc.).- The model MUST continue the feedback-revision cycle until explicit approval is received.- The model MUST stop once the task document has been approved.**This workflow isONLYfor creating design and planning artifacts. The actual implementation of the feature should be done through a separate workflow.**- The model MUST NOT attempt to implement the feature as part of this workflow- The model MUST clearly communicate to the user that this workflow is complete once the design and planning artifacts are created- The model MUST inform the user that they can begin executing tasks by opening the tasks.md file, and clicking “Start task” next to task items.</p></blockquote> 3. 激活工作流: 配置完成后,在Claude Code中,开发者就可以通过简单的命令来启动整个工作流: /spec [简要的项目或功能描述] 4. 采用“/ask + /spec”组合策略: 为了获得最高质量的输出,最佳实践并非直接运行/spec。更有效的方式是采用“/ask + /spec”的组合拳:第一步:使用/ask进行需求澄清。 在正式生成Spec之前,通过多轮/ask对话与AI进行需求评审。 这个过程不仅是向AI传递信息,更是通过AI的反问和建议,来澄清和深化开发者自身对需求的理解。第二步:确认理解后生成/spec。 当AI通过对话对需求有了全面、深入的理解后,再执行/spec命令。此时,AI将严格遵循spec.md中定义的流程,生成更加贴合实际、质量更高的requirements.md、design.md和tasks.md系列文档。AI编程2.0 毫不夸张的说,Kiro的Spec工作流,为我们揭示了AI编程2.0时代的轮廓:一个由规范驱动、流程严谨、人机协同的全新开发模式。 这种从“能用”到“好用”,再到“专业”的需求升级,要求开发者也必须转变思维。 我们不能再满足于用AI完成零散的功能点,而应学会利用AI来构建和管理整个项目的工程体系。 以上,既然看到这里了,如果觉得不错,随手点个赞、推荐、转发三连吧,你的支持是我持续创作的动力。我们下期见。 本文由人人都是产品经理作者【饼干哥哥】,微信公众号:【饼干哥哥AGI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。
 机核 · 单梦蛙
机核 · 单梦蛙 今日,扬子晚报发布澄清声明,表示:报道《争议指示牌道歉后网友仍不买账,<鸣潮>官号遭众多留言批评》经核实存在不当表述,与客观事实确有出入,对库洛公司造成负面影响。在此向库洛公司、广大玩家以及各方受影响的读者道歉。  此前,《鸣潮》在韩国举行联动活动时的指示牌引起了争议,而《鸣潮》官方则发布了公告,表示本次活动的部分区域由合作方进行负责管理并进行活动运营,并迅速撤下了指示牌并道歉。  而《扬子晚报》则在后续发布了报道,表示“当天下午《鸣潮》在社交平台道歉,将“锅”甩给了合作方。”  另外,有网友发现,库洛公司曾在报道发出后起诉过扬子晚报。 
 今日,扬子晚报发布澄清声明,表示:报道《争议指示牌道歉后网友仍不买账,<鸣潮>官号遭众多留言批评》经核实存在不当表述,与客观事实确有出入,对库洛公司造成负面影响。在此向库洛公司、广大玩家以及各方受影响的读者道歉。  此前,《鸣潮》在韩国举行联动活动时的指示牌引起了争议,而《鸣潮》官方则发布了公告,表示本次活动的部分区域由合作方进行负责管理并进行活动运营,并迅速撤下了指示牌并道歉。  而《扬子晚报》则在后续发布了报道,表示“当天下午《鸣潮》在社交平台道歉,将“锅”甩给了合作方。”  另外,有网友发现,库洛公司曾在报道发出后起诉过扬子晚报。 

**HMD 102 4G上市,售价169元。**HMD 102 4G搭载Deepseek的AI掌上助手,**可通过AI助手询问起居、健康、生活、学习等方面问题,AI助手激活后,可免费使用100天。** 此外,用户还能通过语音唤醒拨打电话、打开日历、打开通讯录、添加闹钟、打开收音机等。 HMD 102 4G采用大面积孤岛式键盘、大字体印刷,支持菜单播报、拨号播报、来电播报、信息播报、整点报时,方便老年人使用。 [](//img1.mydrivers.com/img/20250721/d5fc9d3c763044bab2d1234e1f4783a5.png) 据了解,HMD 102 4G配备双Nano SIM小卡卡槽,支持移动、联通、电信、广电4G,以及VoLTE高清语音通话。 其他方面,**该机采用诺基亚手机制造工艺与测试标准,配备2.0英寸LCD屏、双LED手电筒、支持32GB内存卡,Type-C充电接口,FM收音机支持扬声器外放和使用3.5mm有线耳机收听。** 需要提醒的是,诺基亚手机京东自营旗舰店显示,HMD 102 4G包装内无充电头,如果需要可以联系在线客服免费领取。 [](//img1.mydrivers.com/img/20250721/1d97114745d847abaacb8cda3e3b9589.png) 充电头与手机不同包装,将在3-7天内免费配送到家。 [](//img1.mydrivers.com/img/20250721/e41057adf3db43d381fd3259bd18f29c.jpg) [查看评论](https://m.cnbeta.com.tw/comment/1514438.htm)
 钛媒体 · 科股早知道
钛媒体 · 科股早知道
2025年7月21日,截止收盘,沪指涨0.72%,报收3559.79点;深成指涨0.86%,报收11007.49点;创业板指涨0.87%,报收2296.88点,两市成交额较上一交易日增加1289.25亿元,合计成交16999.8亿元。
 小众软件 · 青小蛙
小众软件 · 青小蛙
MySpeed 是一个开源项目,适合拥有 NAS、小主机,以及服务器的用户,支持 Docker 部署。它可以帮你在后台每小时自动测速一次,然后统计出图表,让你随时掌握宽带情况。也可以在 VPS、云主机


<blockquote><p>当代码变成“有 vibe 的表达”,程序员不再是舞台中心,运营、设计成为流量与共鸣的第一入口。本文将以 Vibe Coding 为背景,重新审视职场技能在注意力经济中的排序逻辑:谁在定义用户感知?</p> </blockquote>  毋庸置疑,Vibe Coding 时代已经来了,并且也绝对是未来。 几个现象: 1、大厂纷纷下场了,并且是下重注 2、卖编程课的人也多了 3、各种小应用纷纷火起来了 越来越多的人也在说,Vibe Coding 时代下,程序员不再值钱了,反而是产品要更占优势。 既然说到了两个职业,我觉得还不够全面。 按照以往互联网大厂的职业分类,不止产品和程序员,我就把运营、设计、产品、测试、程序员都拿出来比较一下。 要比较,自然需要有个标准。 我觉得标准就是谁能做出好的产品。 什么叫「好产品」呢? 用户说好才叫好。 所以可以定一个标准,越多的用户说好,那产品就越好。 所以基于这个标准,再来聊聊这几个职业。 先说说我个人理解的几个职业的优劣势,当然这里只考虑通用性,不考虑个人能力高低的影响。 运营应该是最接近用户,最懂怎么让产品触达用户的人。先不管产品好坏,至少用户要知道这个产品,才能去用吧? 所以这里又引申出一个话题,那就是一款产品最重要的是什么? 是产品理念?是背后的技术? 我觉得都不是,最重要的是用户要知道他。 要不然这就是自嗨的产品。 当然自嗨本身也不是坏处,只是如果你励志要做一款大众化的产品,靠自嗨就不行了。 所以这就是我把运营排在第一的原因。 再说说设计。 不知道你有没有发现,现在的独立产品,在设计上都是非常漂亮的。 其实这是人之常情,大家都喜欢漂亮的东西。 功能一样的情况下,肯定会选择漂亮的,这就是找对象一样。 甚至有些时候,漂亮会弥补功能上的缺失。 而且产品的功能是需要慢慢体验的,但是产品的颜值是一眼就能看到的。 所以如果现在要做一款产品,一定不能太丑。 而这恰恰是设计的长处了。 当然了,颜值决定了一见钟情,功能决定了用户的忠诚。 如果功能做得太差,用户是不会留下来的。 写到这里,有没有发现,还没有开始讨论技术的事情。 这就对了,对于一款产品来说,技术根本不是主要因素。 如果是5年前的我,对此一定嗤之以鼻,当时的我会认为技术才是一切。 现在我觉得那种想法非常幼稚。 用户不会关心你的代码写得有多好,不会关心你这个设计模式有多精妙。 这些都不会让用户「更爽」,爽的只是自己。 所以程序员唯一的用处,就是让这个产品「产生」,而之前和之后的事情,都是程序员不擅长的。 而现在,因为有了Vibe Coding,产品已经和流水线一样了,说几句话就能产生了,所以程序员的作用就微乎其微了,更多的就是看看结果,不对的话,让AI去修改。 不过实话实话,现在的Vibe Coding,只能做一些比较简单的功能,太复杂的还是搞不定,还需要程序员来。 不过未来呢? 那说到这里,怎么测试还排在程序员前面呢? 还是从Vibe Coding说起,有了Vibe Coding,程序员的作用也只剩下测试AI的结果对不对了。 有测试专业吗? 大概率没有。 程序员更擅长白盒测试,但是Vibe Coding的结果,跟趋近于黑盒。 所以基于上面的讨论,我得出这个排名结果:运营>设计>产品>测试>程序员。 不过我有一个小小的预测,未来这些职业的边界会渐渐模糊掉。 而程序员,此时此刻正在被模糊。 **不过在未来,随着AI的发展,测试、产品、设计、运营的能力,也肯定会被替代掉。但是我觉得难度是逐渐递增的。所以如果你是程序员,一定要思考,代码之外,还有什么竞争力。** 最后,利益相关,我本身就是一名程序员,其实在大厂,职级慢慢往上走的时候,就会清晰的意识到,程序员的竞争力都在代码之外。 只不过Vibe Coding时代,让这个现象更明显了。 最后不要脸的加个硬广,我开发了一款浏览器插件,叫NoTab,用来在当前页面预览链接,可以让你不用打开那么多标签页,更专注,更效率,挺好用的,希望您也来试试:https://notab.wand.tools 本文由 @张翼ZYi 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议
 36氪
36氪文 | 马晓迪 编辑 | 刘士武 ## **新游速递** **腾讯二次元MMO《星痕共鸣》公测** 由上海宝可拉团队研发、腾讯代理发行的《星痕共鸣》于7月17日正式上线。游戏的前身是万代南梦宫开发的《蓝色协议》。游戏开服当天即登上了iOS免费榜的榜首。  《星痕共鸣》 **《完蛋!我被美女包围了!2》上线** 《完蛋!我被美女包围了!2》于7月17日登录Steam平台,由前作《完蛋!我被美女包围了!》的开发工作室intiny启用“原班人马”打造,此次保持恋爱模拟元素的同时,选择主攻古装喜剧悬疑风格。  《完蛋!我被美女包围了!2》 **灵犀互娱《大航海时代:传说》公测** 游戏于7月17日正式上线,以16世纪欧洲大航海时代为背景,玩家可化身航海家,驾驭历史名舰穿梭于真实港口,探索遗迹和海域,还可自由切换商人、探险家等身份。  《大航海时代:传说》 **《咚奇刚:蕉力全开》正式发售** 任天堂新作《咚奇刚:蕉力全开》于7月17日正式发售,作为Switch2的独占作品,在Metacritic上87家媒体给出的均分为91分,其中IGN给出满分评价。  《咚奇刚:蕉力全开》正式发售 **莉莉丝《远光84》第三次测试开启** 该游戏主打第一人称射击与多文明国战玩法,于7月18日开启双端不限量测试,持续至7月27日。 ## **老游情报** **《魔兽世界》国服庆祝20周年** 《魔兽世界》国服20周年发布会于7月15日落幕,会上公布了一系列更新内容。雷火请到了魔兽世界执行制作人Holly与高级游戏总监Ion开场。 **盛趣《龙之谷》十五周年庆** 2010年上线的《龙之谷》于本周迎来十五周年庆。7月17日上线了15周年百级资料片“黄金时代”,推出了全新主城、主线剧情、副本、装备等海量新内容。此外游戏官方在上海百联ZX造趣场B1造趣领域首次全开放非售票线下主题活动**「夏日奇幻冒险」,活动持续时间为**7月18日-22日的10:00-21:00。  《龙之谷》 **英雄联盟手游三周年庆** 《**英雄联盟手游**》即将迎来三周年庆典,官方宣布将于7月20日正式开启庆典活动,活动将持续至8月中旬。期间,海量免费福利、限定皮肤返场、明星表演赛等重磅内容将轮番上线。 ## **行业要闻** **世纪华通发布2025年上半年业绩数据** 世纪华通于7月14日发布2025年半年度业绩预告。公告显示,公司上半年合并营业收入约170亿,同比增长约83.27%;预计实现归母净利润24亿元至30亿元,同比增长107.20%-159.00% 。其业绩增长主要得益于子公司点点互动国内及海外收入稳健增长,以及自身降本增效措施成效显现。  世纪华通 **2025年上半年上海游戏产业数据出炉** 7月15日,2025年上海游戏精英峰会发布《2025年1-6月上海游戏出版产业报告》。报告显示,上半年上海网络游戏总体销售收入达832.83亿元,同比增长10.80%,其中国内收入687.37亿元,海外收入145.46亿元,均实现两位数增长。 本文首发自[“36氪游戏”](https://mp.weixin.qq.com/s/33d9Y4nHHfn2WkCC2LO1Wg)。

A person in charge of AI at JD Technology told the author that JD is primarily focused on the deep integration of robotics and large language models, as well as exploring new application scenarios, including world models and deep reasoning models. Ultimately, the goal is to enable robots to achieve executable and operable "embodied intelligence"—whether it's a robot, a vehicle, or a robotic dog, the aim remains the same.

一份报告显示,台积电正在考虑在其位于美国亚利桑那州新投产的芯片制造工厂的运营中使用无人机。位于亚利桑那州的工厂是该公司在美国最先进的制造工厂,目前正在向大型科技公司出货4纳米芯片。这份来自台湾供应链的消息人士的报告显示,这家芯片制造商正在寻求拥有工厂建设专业知识的无人机供应商的投标。 据台湾《经济日报》报道,台积电正在为其亚利桑那州工厂组建无人机团队,目前正处于最终确定无人机供应商的阶段。该公司目前正处于招标的第一阶段,预计最终入围公司名单将于今年年底公布。无人机以及人工智能软件和机器人技术是一项快速发展的技术,预计在人工智能软件的帮助下将进一步发展。  细节表明,台积电有意在其位于偏远地区的工厂使用无人机。该公司在美国工厂建设期间曾面临严重的文化冲突,当地工会指责其偏爱台湾工人,且不遵守建筑施工程序。台积电还被其美国员工以歧视和不安全的工作条件为由起诉,该公司否认了这些指控,并拒绝对正在进行的立法发表评论。 偏远地区恶劣的环境是台积电对使用无人机感兴趣的原因之一。据业内人士透露,台积电可能会使用无人机巡检其设施、监控交通、检查现场,并依靠无人机进行灾难救援。因此,无人机不仅可以减少公司现场运营所需的总体劳动力,还可以降低工人在危险情况和环境中的风险。 消息人士补充说,全球最大的民用无人机制造商之一——中国大疆创新也将以美国公司的身份参与竞标。尽管大疆创新获准在美国销售其产品,但除非审查尽快完成,否则该公司可能难以为其无人机接入电信网络和其他基础设施。 然而,尽管大疆拥有台积电那样的运营规模,业内人士认为,这家台湾公司可以选择依赖其先前合作过的公司或在建筑行业拥有经验的公司。台积电作为全球最大的芯片代工制造商,运营着全球一些最大的芯片制造工厂。目前,台积电在亚利桑那州的一家工厂生产芯片,但作为其建立专门满足美国需求的半导体供应链计划的一部分,台积电计划在2020年前将工厂数量扩展到三家。 [查看评论](https://m.cnbeta.com.tw/comment/1514434.htm)
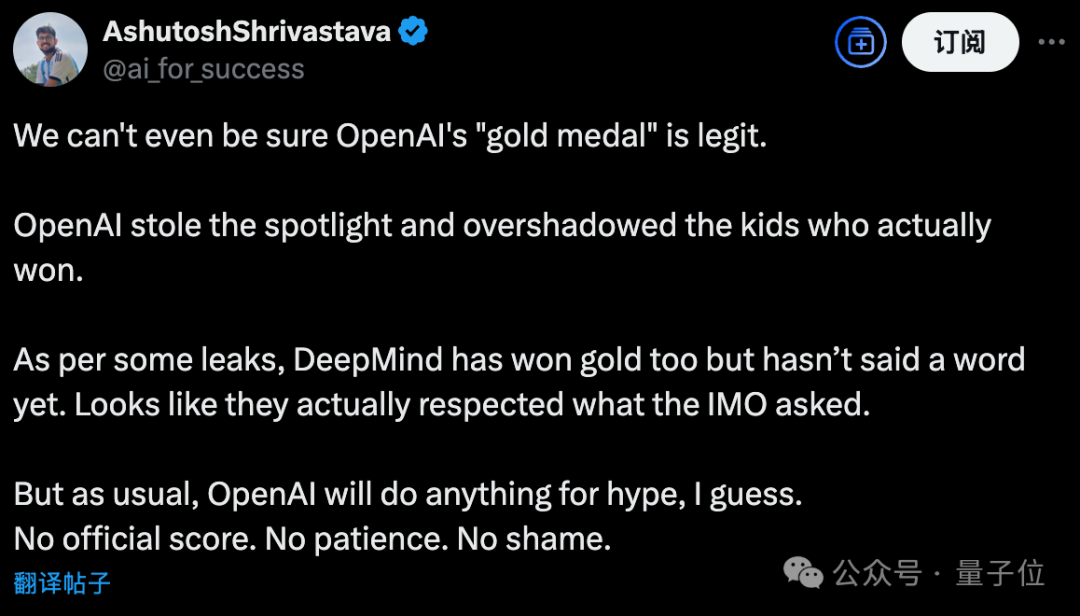
OpenAI声称新模型获得IMO金牌不到24小时,剧情就出现了大反转!多位IMO官方人士和学界大佬纷纷发声,直指OpenAI的做法“粗鲁且不恰当”。IMO主办方要求AI公司在闭幕式一周后再公布结果,让关注的焦点留在参赛的青少年上,然而OpenAI偏偏选择在闭幕式刚结束就急不可耐地宣布了成绩。 有网友评价:**OpenAI一如既往的为了炒作什么都干得出来。没有官方分数,没有耐心,也没有羞耻心。** 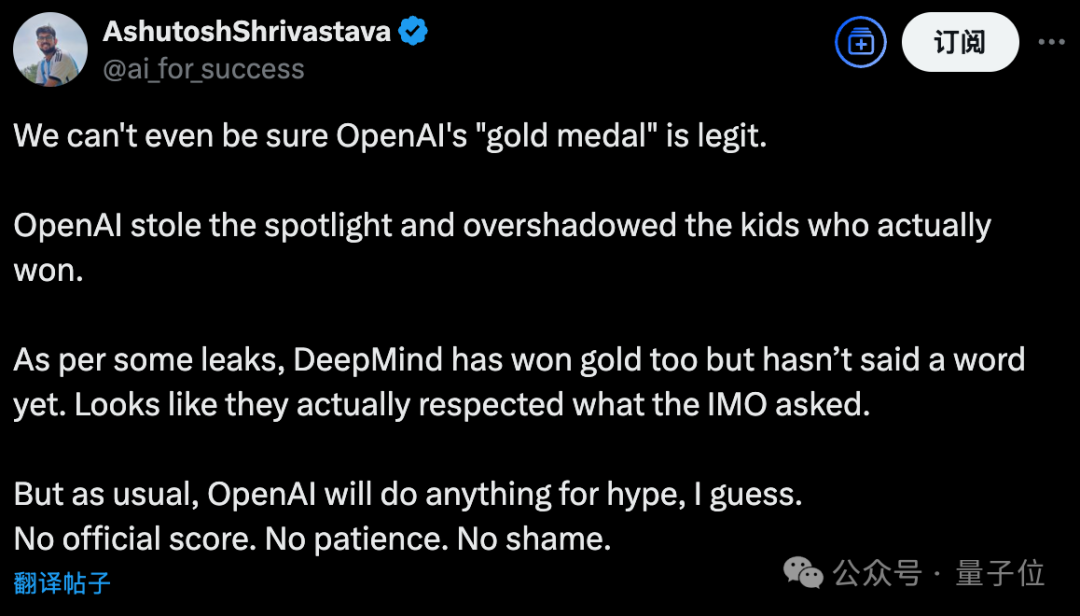 更劲爆的是,OpenAI自称的“金牌”成绩可能根本站不住脚: **OpenAI并不是与IMO合作测试模型的AI公司之一,91位IMO官方评委中没有任何人参与评估他们的答卷。** 这意味着,OpenAI的”金牌”成绩完全是自说自话,没有经过官方认证。 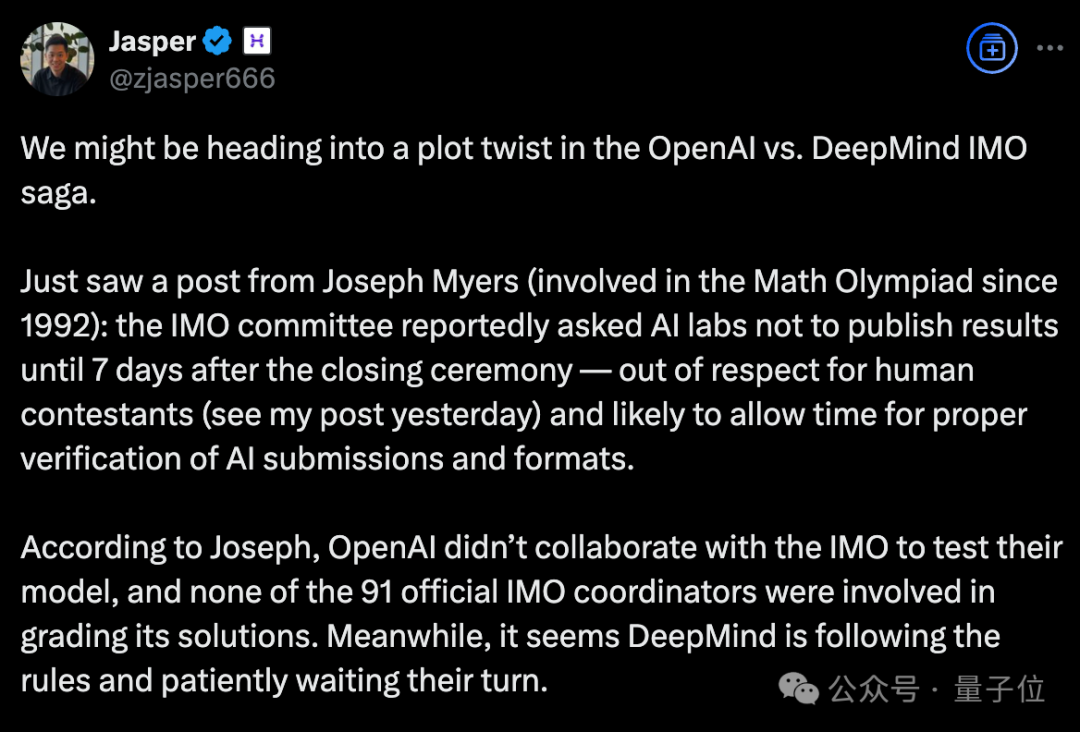 原本以为是AI发展的里程碑时刻,没想到引发了一场关于学术道德和商业炒作的激烈争论。 **IMO官方怒了:”请给孩子们留点空间”** 事情的导火索来自一位IMO资深人士的爆料。 Joseph Myers,这位从1992年就参与数学奥赛的元老级人物,与IMO秘书长Ria van Huffel进行了一番交谈。 IMO评审团和协调员们普遍认为,AI开发商在IMO期间(尤其是闭幕式之前)宣布成绩是”粗鲁且不恰当的”。官方期望AI公司在闭幕式后至少等待一周再发布结果。 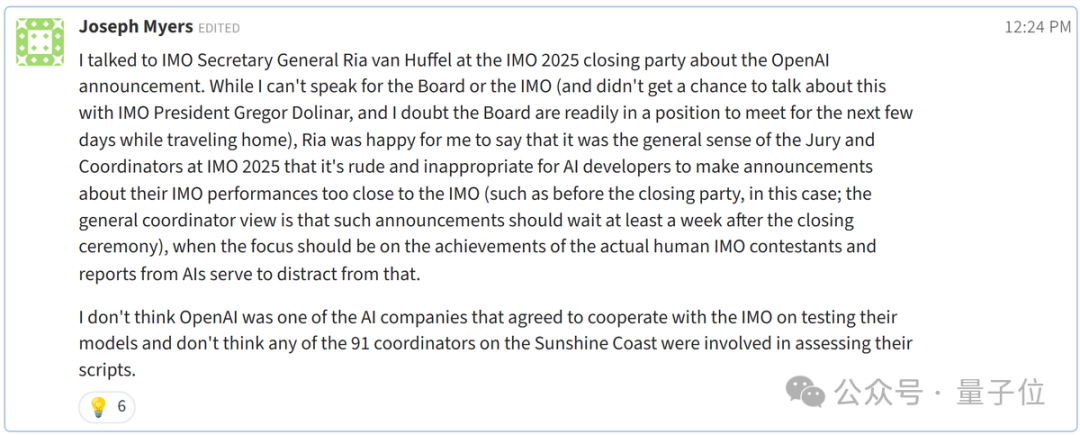 OpenAI方面,则由参与这项研究的Noam Brown出面回应。 他的发言承认了OpenAI没有事先与IMO官方取得联系,只是在发布成绩之前告知了一位组织者,组织者要求他们在闭幕式之后再宣布成绩。 这与爆料中的要求闭幕式一周之后出现了矛盾。 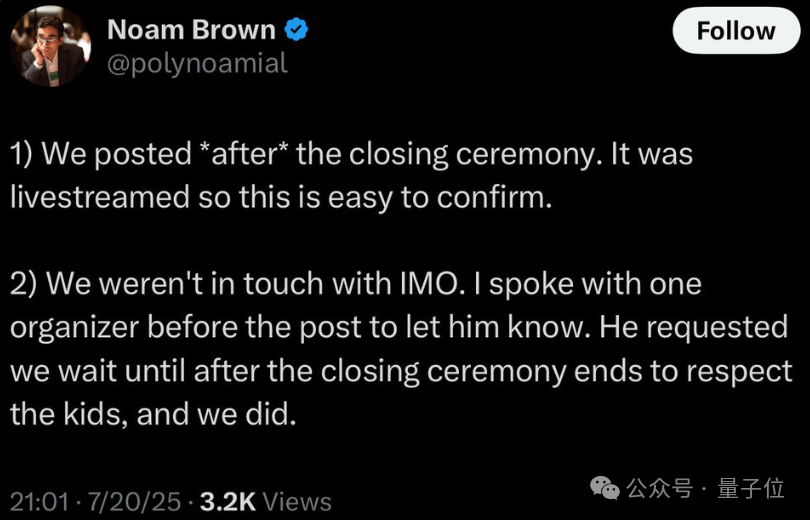 那么事情到底如何呢? 另一家参加比赛的AI团队Harmonic的公告证实,确实有“闭幕式一周之后”这个要求,而且给出了具体时间期限7月28日之后。 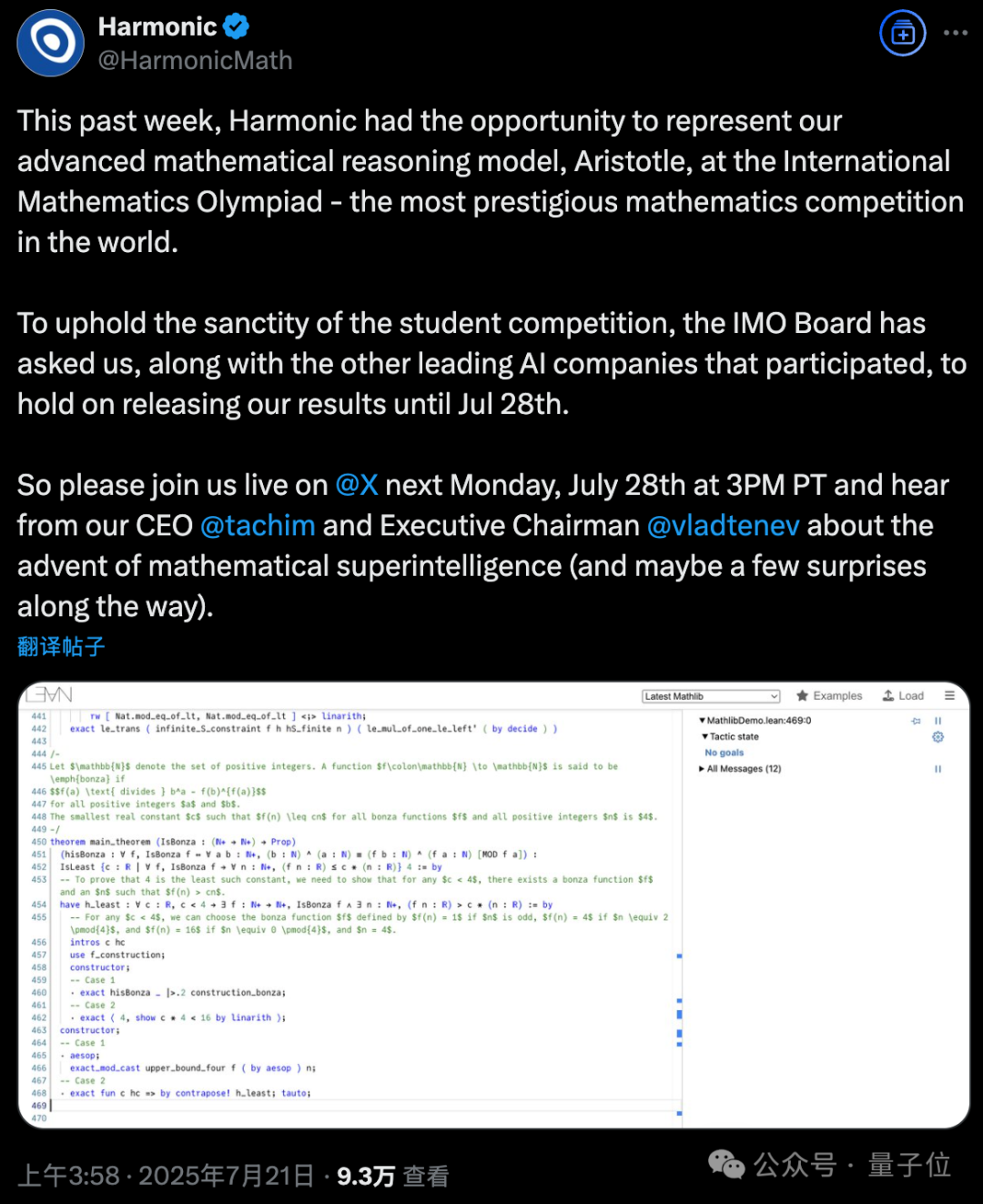 就在OpenAI高调宣布成绩的同时,另一家AI巨头谷歌DeepMind却很克制,与OpenAI的张扬形成鲜明对比。 **多位知情人士透露,DeepMind可能也取得了金牌水平的成绩,但他们选择遵守IMO的要求,静静等待合适的时机。** 除了公告发布时间的问题,OpenAI到底得没得金牌也有争议。 领导DeepMind超级推理团队的Thang Luong补充,IMO内部其实有一份官方评分指南,外部无法获取。没有基于该指南的评分就没有资格获得奖牌。 这届IMO共6道题,每题7分。金牌线35分,OpenAI自报的成绩也刚刚过线,即使是解答过程中微小的扣分都可能让OpenAI从金牌跌到银牌。  总之这场IMO金牌之争还远未结束,一切还是以经过IMO主办方认证的成绩为准。 **One More Thing** 最后让我们将聚光灯交还给人类金牌选手。 最终成绩中,中国队以全员6金牌、总分231分占据榜首,继去年以2分之差遗憾输给老对手美国队后,再度重返世界第一。 第二名则是美国队,获得了5金一银,然后依次是韩国、日本和波兰。 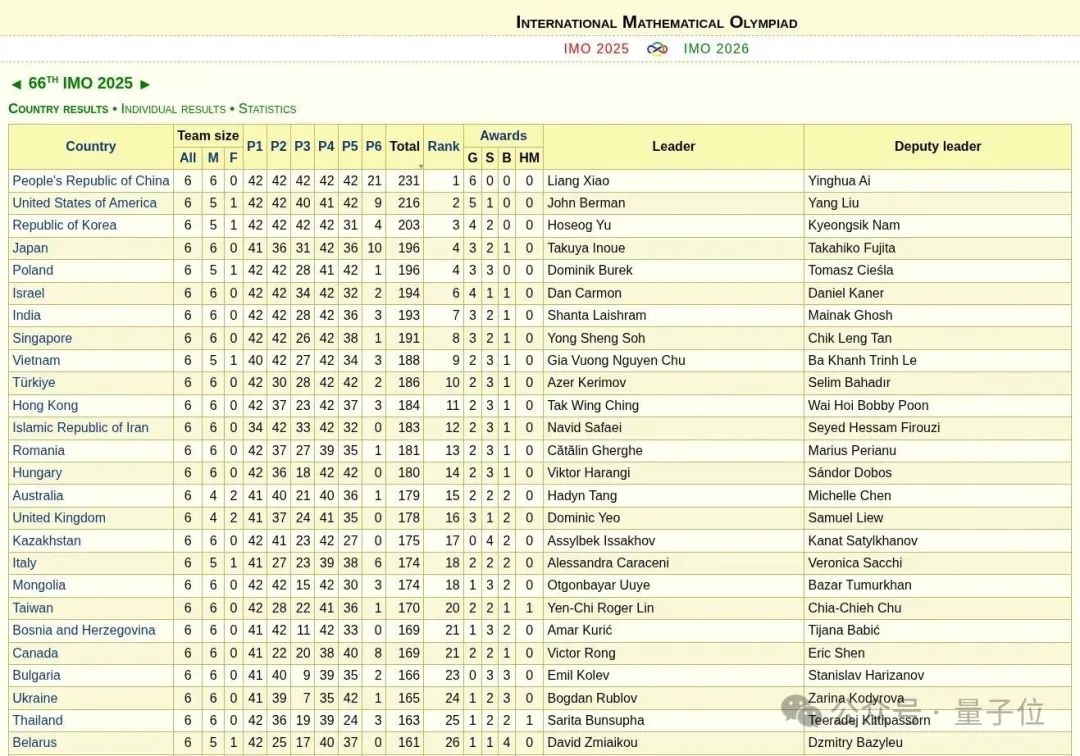 中国队的六位选手分别是来自武昌实验中学的邓哲文、武汉市经开外国语高级中学的徐祺铭和谈弘毅、重庆巴蜀中学的张恒烨、杭州学军中学的董镇宇,以及上海中学的邓乐言。  其中邓哲文和徐祺铭都曾参与过2024年的IMO并成功摘金,而徐祺铭更是在去年成功入选2025年北大数学英才班。 董镇宇则是团队中唯一的高三年级,虽然他早在高一就进入国家集训队并被保送至清华姚班,但前两年的选拔中都与IMO国家队擦肩而过。 **这是他第三次冲击国家队,终于百折不挠圆梦IMO。** 谈弘毅在连续两年凭借中国数学奥林匹克竞赛(CMO)金牌入选国家集训队后,也同样获得了清华北大保送资格。 另外,邓乐言和张恒烨在本次IMO拿下满分42分,并列世界第一,这也是中国队从2019年起,连续7届IMO均有选手获得满分。 其中,邓乐言是中国队中年级最小的一位,只有高一的他,在去年CMO以满分成绩入选国家集训队,又在IMO国家队选拔中脱颖而出,刷新了上海近10年来IMO选手的最小年龄纪录。 去年,他还在阿里巴巴全球数学竞赛中的组合与概率赛道获得全球第五名,也是首位获得该项赛事奖牌的中学生。 张恒烨曾在2023年CMO中获得金牌并入选国家队,后来同样在阿里巴巴全球数学竞赛中获奖。去年入选国家队后,他还主动前往北大数学系旁听并受益匪浅。 要知道,本次IMO中,全球600多位参赛者,只有6人获得满分,其他所有人几乎都输在了第六题——组合数学上,这也是OpenAI唯一没有攻克的那道题。 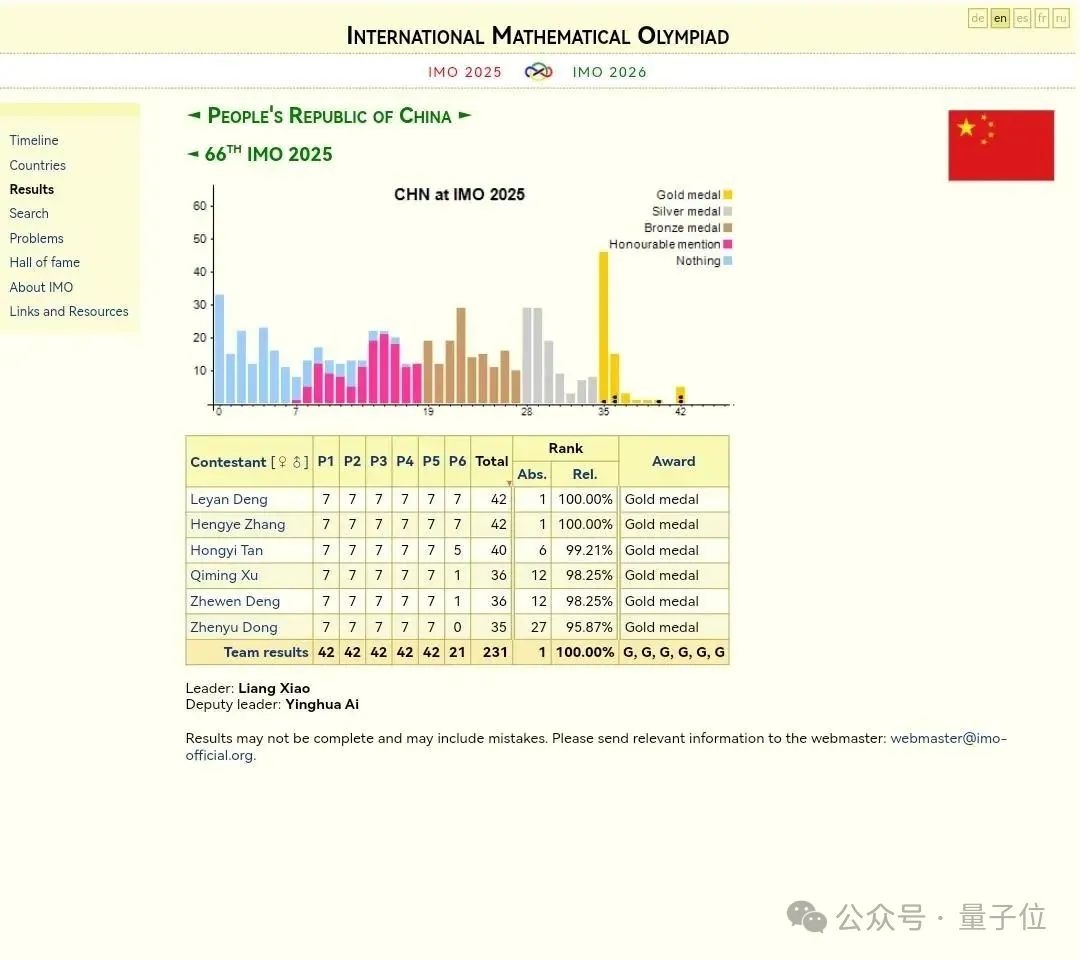 另外,下一届IMO将在上海中学举办,上海中学至今已获得18块IMO金牌,总数位居全国第一,它也将成为全球第一所承办国际数学奥林匹克的中学。  值得注意的是,今年IMO的前30名参赛者,几乎都是亚洲或东欧面孔。 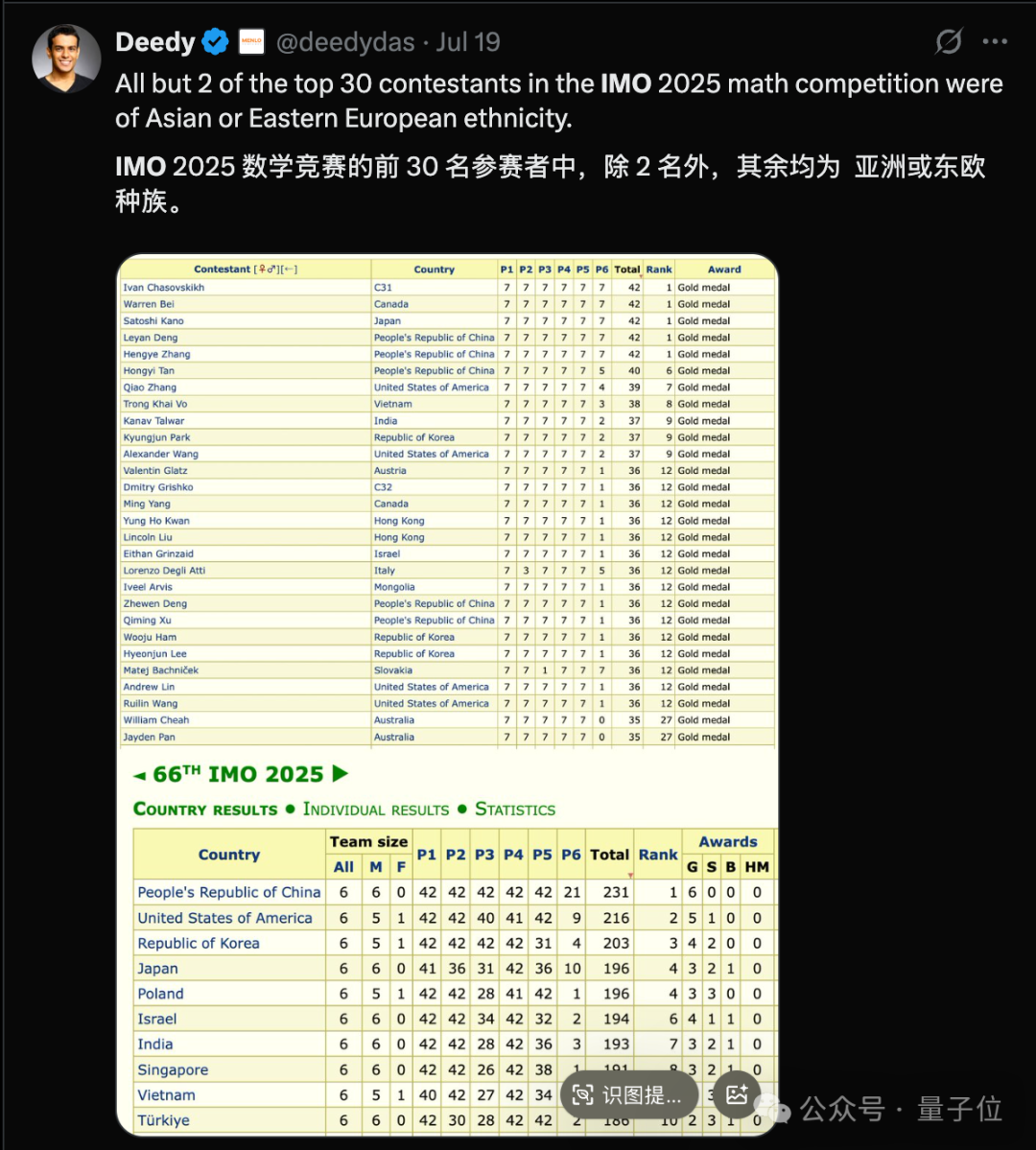 而亚军美国队也是清一色的亚洲面孔。  网友表示,**也许未来的数学竞赛将是中国队vs美国队vs人工智能。** 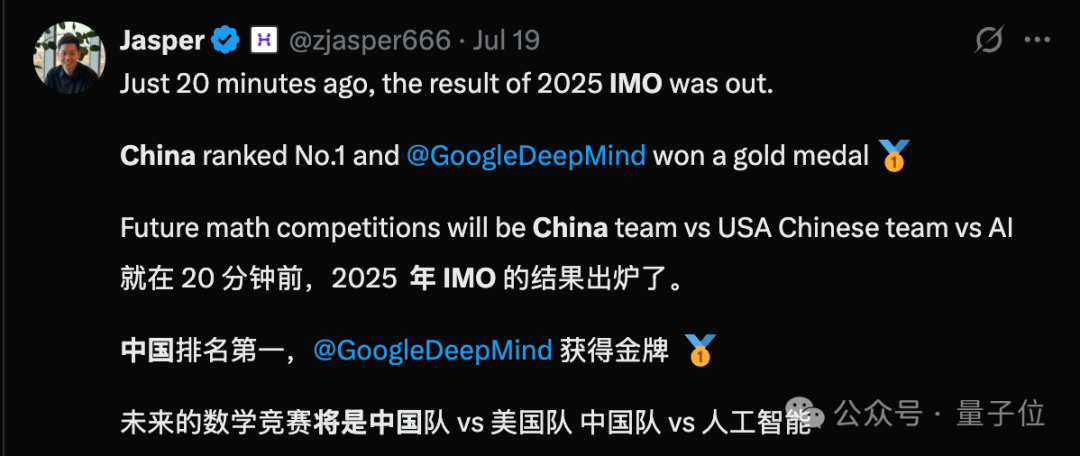 参考链接: [1]https://x.com/HarmonicMath/status/1947023450578763991 [2]https://www.imo-official.org/ [3]https://x.com/ai_for_success/status/1946984782178709719 [4]https://x.com/lmthang/status/1946960256439058844 [查看评论](https://m.cnbeta.com.tw/comment/1514432.htm)

由于我国在稀土领域的绝对控制权,断供后让欧美非常的被动,以至于不少企业不得不停产。在跟美国双方协议后,我国也是缓解了一些稀土的出口。**近日,中国海关总署公布的数据显示,6月份,中国对美国稀土磁体出口量飙升至353吨,较5月份增长660%。** 由于获得出口许可证所需的时间过长,4月和5月的出货量大幅下降,扰乱了全球供应链,迫使一些中国以外的汽车制造商因稀土短缺而暂停部分生产。 上个月,中国共向全球出口了3188吨稀土永磁体,较5月份的1238吨增长157.5%,尽管6月份的出口量仍比2024年同期下降了38.1%。 **此前,中美两国于6月份达成协议,以解决稀土矿物和磁体输美问题。作为协议的一部分,芯片制造商英伟达计划恢复向中国销售其H20 AI芯片。** [](//img1.mydrivers.com/img/20250721/167a932d40564590ba94449e89537239.jpg) [查看评论](https://m.cnbeta.com.tw/comment/1514430.htm)

**娃哈哈集团创始人宗庆后去世17个月后,宗氏财产纠纷仍在持续,而该案件将在今年8月1日有新进展。**报道中提到,香港高等法院一份与此相关的起诉材料显示,三名原告分别是JACKYZONG (宗继昌)、JESSEEJELIZONG(宗婕莉)、JERRY JISHENG ZONG (宗继盛);第一被告是KELLY FULIZONG (宗馥莉),第二被告是JIAN HAO VENTURES LIMITED。 三名原告被他们的律师确认为是宗馥莉的“同父异母兄弟姐妹”。原告律师称,三名原告还在杭州一家法院提起诉讼,以争取获得他们声称的已故父亲承诺给他们的信托权益,各价值7亿美元。 此外,杭州娃哈哈集团有限公司大股东已经开始行动了(杭州市上城区财政局下属二级企业杭州市上城区文商旅投资控股集团有限公司),目前杭州已经成立了专班。 杭州市上城区财政局工作人员之前告诉记者,“我们前期也接到了很多相关电话和投诉,我们一直在处理,已经有(成立)专班在介入处理,我们也希望尽快能处理这个事情。” **[因为这场风波](https://news.mydrivers.com/1/1062/1062631.htm),7月14日、15日,电商平台娃哈哈日销量从1万-1.2万区间下滑至5000-7500区间。** 面对这样的情况,一名娃哈哈经销商发出感慨:“作为娃哈哈的经销商,我今年还干得下去吗?” [](//img1.mydrivers.com/img/20250721/bba470ccd33e406daf9f2340fce709fd.jpg) [查看评论](https://m.cnbeta.com.tw/comment/1514428.htm)

<blockquote><p>离婚协议既是法律文本,更是情感出口——它需要被理解,而不是被模板化。本文将拆解法律咨询赛道中“离婚协议”的内容构建与流量增长逻辑,供大家参考。</p> </blockquote>  最近开始研究离婚协议书在私域引流方面的玩法,如今这个行业已从单纯提供模板,转变为需要给出一整套解决方案。 今天就来聊聊离婚协议书在小红书上该如何引流,为大家拆解两个离婚协议书爆款案例。 ## 案例一 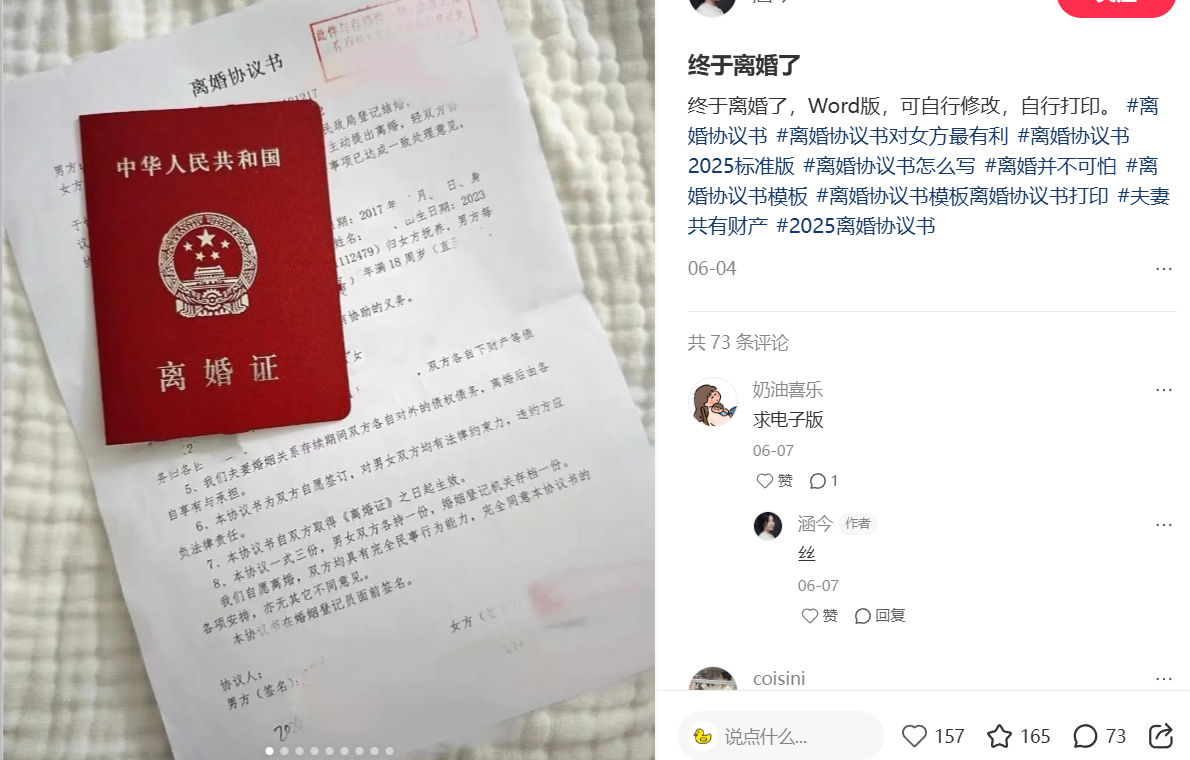 ### 1. 封面设计策略 其封面设计相当考究。一个爆款笔记封面是将离婚证和离婚协议书平铺拍摄,红色离婚证占据画面的 1/3,十分醒目,协议书上诸如抚养权归属等关键条款还用横线标注出来。 **具体案例描述** 红色证件自带 “结果感”,对有离婚需求的用户极具吸引力,视觉冲击力强。而且实拍文书比纯文字模板更具真实案例感,仿佛在传达 “我真的经历过或处理过此事”,瞬间打消用户对 “模板是否靠谱” 的顾虑。 **实操建议** 若想设计类似封面,不妨参考我之前帮广州一个律师号做的调整:在证件旁放置一张小纸条,手写 “模板有风险,关键条款需审核”。这样既保留了视觉冲击,又暗示用户免费模板并非万无一失,引导用户进一步咨询。该律师号照此方法实施后,30 天涨粉 2000 +,咨询量翻了 3 倍。 ### 2. 标题话术策略 标题为 “终于离婚了,Word 版,可自行修改,自行打印”。我们来详细拆解一下。 **具体案例描述** “终于” 这个情绪词,传递出解脱感,能引发正在经历离婚的用户 “熬出头” 的共鸣。“Word 版可修改” 明确了工具属性,满足了不想花钱找律师、想自行修改的用户需求。此外,标签中还包含 “女方有利”“2025 标准版”“模板打印” 等长尾词,覆盖了时间限定、性别偏向等不同搜索需求。 **实操建议** 起标题时可这样调整,例如 “终于离婚了!Word 模板免费送(附律师提醒:这 3 条不写清楚等于白离)”。前半句抓住用户解脱情绪,后半句用 “风险” 制造焦虑,让用户意识到模板需专业指导,从而吸引更多点击。 ### 3. 内容组织策略 部分爆款笔记正文仅两句话,搭配一堆标签,却暗藏玄机。 **具体案例描述** 开头 “终于离婚了” 与用户共情,让用户感觉作者理解自己,接着 “可自行修改打印” 降低获取门槛,使用户觉得轻松可得。当评论区有人求电子版时,作者回复 “丝”(私信之意),形成 “内容引流→私域转化” 的路径。用户以为能免费获取模板,实则在私域中可能会被推送 “律师咨询”“定制服务” 等。 **实操建议** 撰写正文可借鉴此套路,从大众感同身受的场景切入,抛出易获取的东西,在评论区设置钩子,引导用户进入私域,后续逐步转化。 ### 4. 评论区引流策略 该爆款笔记评论区有 73 条回复,80% 为 “求电子版”“怎么拿” 等。作者统一回复 “丝” 或引导关注,不直接提供模板,而是将用户引流至私域。 **具体案例描述** 如此既能沉淀用户,又能通过自动回复筛选出真正有需求的人。比如发模板时附带一句 “需要律师审核可以留言”,借助 AI 获客系统应用场景,可更精准地筛选和转化目标用户。 **实操建议** 运营评论区也可采用此方法,不要急于直接给出内容,先引导用户进入私域,再通过话术筛选出对服务真正感兴趣的人,以提高转化效果。 ### 案例一总结 花生总结该案例方法,可直接应用: - **策略一**:封面设计时,在证件旁添加风险提示小纸条,强化专业度。 - **策略二**:标题分层,前半段抓住情绪,后半段埋下服务钩子,制造焦虑引导咨询。 - **策略三**:评论区主动“埋雷”,通过小号提问等方式引导深度互动,筛选精准客户。 ## 案例二  ### 1. 封面设计策略 还看到过一个笔记,封面是离婚协议书截图,重点条款用红笔圈出,这个细节至关重要。 **具体案例描述** 将 “抚养权”“探视权” 等关键词圈出,使用户一眼聚焦孩子相关内容。粉色爱心符号打破法律文书的冰冷感,传递 “离婚也能保护孩子” 的温情,特别吸引重视子女的父母群体。 **实操建议** 设计封面时可借鉴此方法,突出关键信息的同时,添加体现情感的小元素,让封面更具温度,吸引目标用户。 ### 2. 标题话术策略 该笔记标题为 “离婚不伤害小孩,这份离婚协议收下吧❤️”,逻辑清晰。 **具体案例描述** “离婚” 与 “不伤害小孩” 看似矛盾,引发用户好奇,促使他们想了解究竟。通过 “父母守护孩子” 的身份认同,将用户从 “离婚者” 转变为 “孩子保护者”,扩大了受众范围,吸引了那些还在纠结是否离婚的人。 **实操建议** 起标题可尝试痛点前置加解决方案的方式,制造冲突并绑定身份,以扩大受众,吸引更多点击。 ### 3. 内容组织策略 此笔记正文分 4 点阐述抚养权、抚养费、探视权、共同教育,每点都围绕 “孩子利益” 包装。 **具体案例描述** 例如,不说 “探视权约定”,而是表述为 “让孩子定期见父母,避免被抛弃感”,避免使用晦涩的法律术语。结尾 “想补充财产分割可 dd 我”,将 “离婚协议” 延伸为 “一站式解决方案”,暗示不仅提供模板,还能解决其他问题。 **实操建议** 撰写正文可将法律条款转化为用户易懂的语言,从用户角度出发,采用场景化表述,增强用户接受度和阅读兴趣。 ### 4. 评论区引流策略 该笔记置顶评论很有意思,直接表明 “需要代写留『代写』,要模板留『需要』”。 **具体案例描述** 这主动对用户进行分层,筛选出 “想免费拿模板” 和 “愿意付费定制” 的人。强调 “找律师量身定制”,将账号定位从 “模板提供者” 升级为 “法律服务中介”,为后续转化高价服务奠定基础。 **实操建议** 运营评论区可学习这种明码标价分层承接流量的方式,先对用户分类,再根据不同类型提供相应服务,提高转化效率。 ### 案例二总结 花生总结该案例方法,可直接使用: - **策略一**:封面设计采用文字标注加情感符号的方式,突出关键信息并体现情感。 - **策略二**:标题痛点前置加解决方案,制造冲突并绑定身份。 - **策略三**:内容组织以孩子利益为核心,将法律条款转化为用户需求,结尾延伸服务。 - **策略四**:评论区明码标价分层承接流量,筛选不同类型用户并升级账号定位。 如今小红书上离婚协议笔记竞争愈发激烈,单纯发模板难以获取流量,因为用户痛点已发生变化。 ### 早期需求 过去用户只需获取免费模板并自行下载即可。 ### 现在需求 如今用户担心模板不合规,害怕关键条款漏写,更倾向于模板与专业指导结合,甚至直接找律师定制。 上周与杭州一位婚姻法律师客户交流,他表示通过 “免费模板引流 + 199 元协议审核” 的方式,每月能转化 30 + 付费客户。这表明将 “工具属性” 与 “服务属性” 相结合,才是该赛道的长久发展之道。 最后提醒,制作这类内容务必把握好 “情感共鸣” 与 “专业边界” 的平衡。不能只注重煽情,该强调 “模板有风险,建议咨询律师” 时绝不含糊,如此既能保护自己,又能筛选出有付费潜力的用户。 本文由 @流量破局 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
 本期主播:阿盐、阿九 选择……咱就是说!暑假啦!!!大玩游戏!!! 1、给大家表演一个从“我靠好难选推荐什么好呢”加速到“嘻嘻嘻嘻越聊越多” 2、你是谁?请支持椒盐米九!.jpg 3、你是……不管你是谁,请支持阿九将在7月23日发布试玩版的全姐姐阵容百合都市恋爱demo《姐姐恋爱法则》 4、虽然聊这些游戏只用了1个多小时,但要通关这些游戏怕是一个暑假也不够 时间轴(aka我们提及的游戏们~) 0:55 Ball x Pit (Demo)2:25 Clover Pit (Demo)4:25 SteamDeck5:47 勇者斗恶龙X offline13:08 九王17:01 魔药经济学:神秘的魔法药水商店21:42 百日战记-最终防卫学园-33:46 Yu-Gi-Oh! EARLY DAYS COLLECTION37:08 Realm Grinder39:07 姐姐恋爱法则 (Demo)42:16 死亡搁浅246:19 幻想生活i 转圈圈的龙和偷取时间的少女49:54 Farm Together54:09 灵魂石幸存者58:56 Raft

<blockquote><p>从“控风险”到“提协同”,CTRM系统早已不止是交易台后的守门员,而是连接业务流程与战略决策的数据枢纽。本文将梳理CTRM系统在数字化进程中的关键演变路径,拆解其如何从风险识别工具成长为支撑前中后台协同的核心平台,为产品经理和业务操盘手提供一份可参考的系统升级指南。</p> </blockquote>  在大宗商品贸易领域,价格波动、供应链波动、政策调整如同 “常态化风险”—— 某能源贸易企业曾因未及时对冲原油价格波动,单月亏损超千万元;某金属加工企业因库存敞口管理不当,在原材料涨价周期中利润被吞噬 40%。应对这类风险,CTRM(商品交易与风险管理系统)逐渐成为核心工具。从早期单纯的风险敞口计算,到如今整合交易、供应链、市场数据的综合平台,CTRM 系统的进化不仅是技术迭代,更是大宗商品企业 “风险管控与业务经营” 深度融合的必然结果。 ## 从 “单一功能” 到 “全域整合”:CTRM 系统的发展逻辑 CTRM 系统的整合趋势,本质是被市场规则与业务需求共同 “推着走” 的结果。2017 年以来,国际市场《巴塞尔协议 Ⅲ》对大宗商品风险资本计提的强化,国内 “期现一体” 贸易模式的兴起,让孤立的风险核算工具彻底失去竞争力 —— 一家企业若同时使用交易台账、Excel 风险计算表、供应链管理软件,数据割裂带来的 “敞口误判”“对冲滞后” 等问题,反而会放大风险。 整合型 CTRM 系统的核心特征,是实现 8 类内外部系统的 “无缝对话”。它需要对接交易所行情系统获取实时价格,连接交易管理系统同步成交数据,联动供应链系统掌握库存动态,甚至接入财务系统核算风险敞口对利润的影响。这种整合并非简单的功能叠加,而是通过统一的数据中台,让 “价格波动”“库存数量”“交易头寸” 等分散数据形成 “风险画像”。例如,当某批铜材入库时,系统会自动关联对应期货头寸,计算实时敞口,并提示是否需要调整对冲策略。 这种整合能力对技术公司提出了极高要求。国外头部 CTRM 厂商通过资本运作整合市场数据服务商、供应链系统开发商,形成 “一站式解决方案”;国内市场目前虽以 “小而散” 的供应商为主,但随着大宗商品企业风险管理需求升级,具备整合能力的头部公司正在崛起 —— 这一过程与早年 ERP 系统从 “模块拼接” 到 “全域协同” 的进化路径高度相似。 ## 应用模式图谱:国内外市场的差异化发展 CTRM 系统的应用模式选择,本质是 “风险管控需求” 与 “IT 资源投入” 的匹配结果。目前主流的三类模式,在国内外市场呈现出显著的发展差异。 企业本地 / 私有云部署是国内当前的 “绝对主流”。这类系统部署在企业自有服务器或私有云上,数据存储与管理完全由企业掌控,适配国内大宗商品企业对数据安全的高要求。其核心优势是能深度贴合企业业务流程 —— 例如某粮食贸易集团的 CTRM 系统,可根据不同粮食品种的存储损耗率、运输周期调整风险敞口计算模型。但它也存在短板:市场数据需要企业自行采购并维护,系统升级依赖开发商上门服务,隐性成本较高。 SaaS 模式在国外已展现出强劲增长动能(年均 15% 增速),却在国内处于 “空白期”。这类系统部署在技术公司的云端,企业按使用时长付费,最大价值在于 “市场数据共享”—— 技术公司可集中采购交易所行情、行业库存报告等数据,共享给平台上的所有企业。但国内暂未出现成熟的 SaaS 类 CTRM 产品,核心瓶颈在于两方面:一是本土企业对 “核心交易数据存于第三方云端” 的信任尚未建立;二是技术公司缺乏整合海量市场数据并转化为风险模型的能力。不过随着数字化进程推进,SaaS 模式在中小贸易企业中的潜力值得期待 —— 它能以较低成本解决 “小公司缺乏专业风控工具” 的痛点。 工具化风险分析软件则是 “轻量型选择”。这类软件部署在单机或局域网内,通过人工录入交易数据完成基础风险计算,适合业务简单、风险敞口单一的小型企业。国内已有厂商开发类似产品,虽功能简单(如仅计算期货头寸与现货的对冲比例),但胜在价格低廉、上手快,在区域型贸易商中占据一定市场。 值得注意的是,期货公司的 “投研策略数字化” 正成为 CTRM 系统的新场景。当期货公司将套利策略、对冲模型嵌入 CTRM 系统后,可实时为客户提供 “行情 – 策略 – 风险” 的联动分析。本土厂商探索的 “低代码平台 + 基础系统” 模式,让策略模块能快速迭代 —— 例如当政策调整套期会计规则时,技术人员可通过低代码工具修改核算模型,无需重构整个系统。 ## 六大核心矛盾与破局思路:CTRM 系统设计的底层逻辑 CTRM 系统的开发与应用,始终伴随着 “理想功能” 与 “现实场景” 的碰撞。解决这些矛盾,考验的不仅是技术能力,更是对大宗商品业务本质的理解。 “项目、标准产品与解决方案” 的矛盾,核心是 “个性化” 与 “规模化” 的平衡。纯项目模式依赖客户自身业务的成熟度(若客户说不清需求,项目必然延期);纯标准化产品又难以应对 “贸易模式千差万别” 的现实(能源贸易的敞口计算与金属贸易截然不同)。“统一架构 + 标准配置 + 个性化开发” 的解决方案模式更具可行性 —— 例如将 “风险敞口计算引擎” 作为统一架构核心,针对不同行业配置基础参数(如化工品的波动率系数),再通过定制开发适配企业特有流程(如跨境贸易的汇率对冲规则)。 “风险管理与业务经营” 的矛盾,关键是避免 “为风控而风控”。优秀的 CTRM 系统不会孤立计算敞口数据,而是融入业务场景 —— 当某钢材贸易商签订长期供货合同后,系统不仅要计算价格敞口,还要分析 “锁定价格后是否错过涨价收益”“调整合同条款能否降低敞口同时保留盈利空间”。这种 “风险 + 收益” 的双视角,让风控从 “成本中心” 转为 “价值中心”。 “交付产品与持续服务” 的矛盾,源于大宗商品市场的 “动态性”。一套 CTRM 系统上线只是开始 —— 当交易所推出新品种、税收政策调整、客户业务模式升级时,系统必须同步迭代。技术公司需建立 “持续服务体系”:定期更新市场数据接口(如新增铁矿石期货的夜盘行情),根据政策变化优化风险模型(如调整跨境人民币结算的汇率风险参数),甚至在极端行情(如疫情导致供应链中断)时提供临时分析工具。 此外,分布式经营与集中管控的协同、专家团队的组建、规则遵循与创新的平衡,都是 CTRM 系统需要破解的命题。例如针对 “集中管控与分散经营”,系统可设计 “总部 – 区域” 两级权限:区域公司录入本地交易数据,总部实时查看全集团风险敞口,既满足国资委对 “风险集中管控” 的要求,又不影响区域业务灵活性。 ## 功能设计的 “黄金法则”:从风险管控到业务支撑 CTRM 系统的功能设计,需紧扣一个核心:“风险管理必须服务于业务,而非脱离业务的‘空中楼阁’”。六大核心要点,构成了系统设计的底层逻辑。 风险敞口管理是 “基础中的基础”,难点在于 “非标准品的标准化”。大宗商品贸易中,许多现货是非标准品(如不同品位的铁矿石、不同纯度的有色金属),无法直接与期货合约对冲。优秀的 CTRM 系统会内置 “折算模型”—— 例如将品位 55% 的铁矿石按 “55/62” 的比例折算为期货合约对应的 62% 品位标准品,精准计算实际敞口规模。这种折算不仅服务于对冲,还能用于库存估值、交易定价等业务环节。 业务模式导向要求系统 “懂业务”。针对 “采购 – 库存 – 销售” 的传统模式,系统需跟踪 “采购价与市场价的价差风险”;针对套利业务,需计算跨品种、跨期、跨市场的套利敞口;针对期现结合模式,则要分析 “现货升贴水” 与 “期货基差” 的联动关系。脱离业务模式的风控功能,只会沦为 “数字游戏”。 动态风险管理是应对市场波动的 “核心能力”。静态套期(如 “现货 1 吨对应期货 1 吨”)难以应对价格剧烈波动,而 “宏套期” 等动态方法可根据市场变化调整对冲比例 —— 例如当某商品价格波动率从 10% 升至 20% 时,系统自动提示增加对冲头寸至 120%。某油脂贸易企业通过动态套期功能,在 2022 年油脂价格暴涨期间,将套保效果提升 40%。 情景分析与压力测试则是 “极端风险的防火墙”。系统需预设 “价格单日波动 10%”“供应链中断 30 天” 等极端场景,计算对企业利润的影响;同时也要检验常规策略的有效性 —— 例如测试 “跨月套利策略” 在不同基差走势下的盈利空间。这部分功能是风险管理的 “深水区”,也是区分系统优劣的关键。 此外,支持业务策略、微应用架构与模型化设计,让系统兼具 “灵活性” 与 “可扩展性”。例如 “低代码 + 基础系统” 的微应用架构,可快速叠加新功能:当企业开展跨境贸易时,只需新增 “汇率风险” 微应用,无需重构整个系统。 ## 本土 CTRM 的 “突围之路”:挑战与机遇并存 国内 CTRM 系统市场尚处于 “成长期”,本土厂商面临需求确定性差、供应链对接难、人才短缺等挑战,但也孕育着巨大机遇。 从发展路径看,“产业资本支持 + 知识体系构建 + 关键人才培养” 是破局关键。例如通过引入产业资本,解决 CTRM 项目 “开发周期长、投入大” 的问题;通过构建风险管理知识体系(如整理大宗商品各品类的风险特征、对冲策略),减少试错成本;通过招揽量化、技术、管理三类专家,弥补 “懂风控的不懂技术,懂技术的不懂业务” 的短板。 随着国内大宗商品市场的成熟、风险管理意识的提升,CTRM 系统正从 “可选工具” 变为 “必备工具”。本土厂商的优势在于 “贴近国内业务场景”—— 例如对国内期货市场规则、跨境贸易政策的理解,远胜于国外厂商。未来,能将 “本土经验” 转化为 “系统能力” 的厂商,有望在市场中占据主导地位。 CTRM 系统的价值,从来不只是 “计算风险”,更是 “赋能业务”。从跟踪价格波动到优化套保策略,从管控敞口风险到支撑交易决策,它正在重塑大宗商品企业的运营逻辑。对于企业而言,选择 CTRM 系统不仅是 “采购一套软件”,更是 “引入一套风险管理体系”;对于本土厂商而言,这既是技术挑战,更是实现 “从跟跑到领跑” 的历史机遇。在大宗商品市场日益复杂的今天,CTRM 系统的进化,终将成为企业穿越周期、稳健发展的 “压舱石”。 本文由 @红岸小兵 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

<blockquote><p>电子病历系统早已不是“数据录入工具”,而是在不同科室、诊疗流程与业务模型中承担着效率提升、信息协同乃至临床决策支持的角色。本文将深入剖析EMR系统在多类医疗场景下的功能适配与演化路径,从需求洞察到产品应对,勾勒一份面向“实战落地”的系统化认知地图。</p> </blockquote>  在数字化浪潮席卷医疗行业的今天,电子病历系统(EMR)已悄然完成了从病历电子化工具到医疗服务核心基础设施的蜕变。它不再是简单的纸质病历替代品,而是一张贯穿门诊、住院、远程医疗等全场景的信息神经网络——既能解决传统医疗中信息孤岛、流程断点的老问题,又能通过数据的流动与挖掘,为精准诊疗、跨域协作注入新动能。本文将从一线医疗实践出发,拆解EMR系统如何深度嵌入业务全流程,以及其功能设计背后的临床逻辑。 ## 一、门诊场景 门诊作为患者接触医院的第一道关口,长期被挂号长、候诊长、缴费长,就诊短的三长一短难题困扰。EMR系统的价值,本质是通过数据的实时流转替代人跑流程,让每个环节从被动等待转向主动协同,用数字化重构第一窗口的服务逻辑。 ### 1.全流程协同 门诊流程的顺畅度,直接决定患者的就医体验。EMR系统的设计核心,是通过数据联动实现各环节的预判式协作,从串联等待到并行处理,而非简单将纸质流程搬到线上。 **①.挂号环节** 患者在窗口或自助机完成挂号后,EMR系统会自动生成一个包含身份证号、医保卡号、就诊卡号的医疗唯一标识(采用HL7FHIR国际标准编码)。这个标识如同患者的医疗身份证,不仅关联基础信息,更会即时唤醒系统中存储的历史数据,让医生接诊前先知情——若患者3个月前因高血压就诊,医生打开系统时,右侧栏会自动弹出历史诊疗摘要:包含当时的血压值(150/95mmHg)、开具的硝苯地平缓释片(20mg/日)处方,甚至能调出半年前的血脂检查报告(总胆固醇6.2mmol/L)。 **②.分诊环节** 分诊是门诊流程的第一道筛子,传统模式下依赖护士经验,遇到复杂症状易出错。EMR系统的分诊模块,本质是一个临床路径数据库+智能匹配引擎的结合体,用症状-科室算法破解挂错号痛点。 例如当患者主诉腹痛+黄疸时,系统会先通过自然语言处理(NLP)提取关键词,再调用内置的症状-科室关联库(基于ICD-10疾病编码和本院3年门诊数据训练),弹出推荐结果:优先推荐肝胆外科(匹配度89%),需排除急性胆囊炎、胆管梗阻,同时附带上典型症状对比表(如胆囊炎常伴发热,胆管梗阻可能尿色加深)。 更关键的是病情优先级排序功能:系统会自动抓取患者的即时体征数据(如体温、血氧、血压),对体温39℃伴呼吸困难的患者触发橙色预警,直接跳过普通候诊队列,并同步向急诊科发送预接诊通知(包含患者基本信息和初步症状)。 **③.检查预约** 传统检查预约中,患者需拿着纸质申请单在不同科室间奔波,耗时平均90分钟;而EMR系统的一键预约功能,通过打通设备排班系统实现了实时调度,实现从患者跑科室到数据跑流程。 医生开具检查单时,系统左侧会显示各科室的实时排班表(如CT室10:30有空档,MRI下午2点可安排),右侧则标注检查前注意事项(如腹部CT需空腹4小时)。患者确认后,系统自动生成带动态二维码的电子预约单(15分钟刷新一次,防止盗用)。更重要的是,申请信息会实时同步至检查科室:检验科会提前备好特定血型的试剂(如RH阴性血患者的交叉配血试剂),放射科则根据患者类型调整参数(如儿童患者自动切换至低剂量CT模式,辐射量降低30%)。 ### 2.医生工具包 面对日均50-100个门诊量,医生对EMR系统的核心需求是快而准——既要高效完成诊疗,又要降低医疗差错风险。 **①.智能开方** 系统内置的处方智能生成模块,按疾病分类预设了标准化模板(如2型糖尿病模板包含二甲双胍、胰岛素等常用药),医生只需调整剂量和频次,从以往的翻药典达到实时校验。更关键的是其安全校验引擎:若患者有肾功能不全病史(eGFR<60ml/min),系统会立即标红二甲双胍禁用,并推荐对肾脏影响较小的格列喹酮(附药品说明书摘要);若开具的阿莫西林剂量超过成人每日1.5g上限,会弹出剂量超限提醒,并显示按患者体重60kg,建议每次0.5g,每日3次。 例如某位医生的体验:以前开一张处方要翻3次药典(查剂量、禁忌症、配伍禁忌),现在系统实时弹窗提醒,2分钟就能搞定,还没出过一次差错。此外,系统与药房库存实时联动——当医生想开某品牌阿莫西林时,会提示该药品库存不足,可替换为同成分的头孢克洛(价格低15%),减少患者跑空趟。 **②.病历整合** 系统的病历整合引擎能按时间轴梳理患者的诊疗轨迹,让碎片化信息变完整病情图:历次血压值自动生成趋势图(标注服药后下降或波动较大),每次就诊的主要诊断用不同颜色标记(红色为急症,蓝色为慢性病)。对于跨科室就诊患者,系统会汇总各科室意见——如心内科备注血压控制不佳与睡眠呼吸暂停相关,呼吸科建议完善睡眠监测,并生成诊疗意见对比表。 值得关注的是跨院病历共享功能。通过区域医疗云平台,患者在A医院做的胃镜报告(含病理切片数字化图像),在B医院的EMR系统中可直接调阅(需患者授权)。 ## 二、住院场景 住院患者的诊疗涉及内科、外科、护理、检验等多学科,如同一场多兵种协同作战。EMR系统的核心价值,是让所有参与者实时共享作战地图(患者病情数据),确保治疗方案精准落地。 ### 1.全周期管理 从患者踏入病房到康复出院,EMR系统像一位隐形管家,记录并推动着每个诊疗步骤,实现从入院到出院的闭环追踪。 **①.入院评估** 系统的入院评估模块采用引导式录入设计,从以往的经验判断达到结构化评分:以妇产科为例,护士录入孕周(38周)、胎动情况(每小时3次)后,系统会自动弹出妊娠高血压风险评分表,根据血压值(145/90mmHg)、尿蛋白(+)等指标生成中风险评级,并强制提示需每4小时监测血压,每日查尿蛋白定量。 针对老年患者的跌倒风险评估模块更具特色:系统会自动抓取患者信息(年龄75岁)、用药史(服用硝苯地平)、体征(步态不稳),生成高风险评级,并在护理计划中强制加入床栏固定、呼叫铃放在右手边、家属陪伴制度等措施(护士需勾选已执行才能完成录入)。 **②.医嘱执行** 医嘱全链路追踪系统是住院场景的核心设计。医生下达静脉输注头孢曲松(2g,每日1次)的医嘱后,系统会先触发三级校验: - 过敏史校验:查询患者既往是否有青霉素/头孢类过敏史(若有则拦截医嘱并提示更换抗生素); - 剂量校验:按患者体重60kg,计算每日2g是否在成人每日1-2g标准范围内; - 配伍禁忌校验:若同时开具了含钙注射液(如葡萄糖酸钙),会提示头孢曲松与钙配伍易形成沉淀,禁止同瓶输注。 校验通过后,医嘱会实时推送至药房和护士站。药房药师配药时,用扫描枪扫描药品条码(含批号、有效期),与医嘱信息比对(患者姓名、药品名称、剂量三者一致方可通过);护士到病房后,用PDA扫描患者腕带(含医疗唯一标识)和药品条码,双重确认无误后执行,并在系统中记录执行时间(精确到分)、护士姓名、患者反应(如’无过敏反应’)。 对于肾上腺素静推等紧急医嘱,系统会自动置顶并触发声光报警(护士站红灯闪烁+提示音),同时在护士PDA上显示紧急程度:最高级,需3分钟内响应。 **③.手术麻醉管理** 手术场景的EMR系统设计,更强调实时数据整合。术前,麻醉医生在系统中调阅患者的心电图(显示窦性心动过缓)、凝血功能(INR1.2)等数据,系统会自动弹出麻醉风险提示:患者心率55次/分,建议术前评估阿托品使用指征;若患者有腰椎手术史,会提示椎管内麻醉禁忌症,优先选择全身麻醉。 术中,系统通过HL7接口实时抓取监护仪数据(心率、血压、血氧),与麻醉药物用量(如丙泊酚输注速率)生成关联曲线——当血压从120/80mmHg骤降至90/60mmHg时,系统会自动标注血压下降与丙泊酚剂量增加同步,建议减慢输注速率。术后,系统自动生成的麻醉记录单包含麻醉方式、用药总量、术中出血量等28项关键信息,甚至能关联手术视频片段(需手术医生授权查看),为术后讨论提供依据。 ### 2.跨科室协同 住院患者的治疗往往需要多科室协作,EMR系统的协同模块则是打破科室壁垒的关键。 **①.实时信息共享** 系统构建了以患者为中心的实时数据流:影像科医生完成CT检查后,点击报告上传,5分钟内临床医生就能在病房电脑上查看——不仅能看文字结论,还能通过内置的DICOM浏览器放大观察病灶细节(支持测量病灶大小、标注位置)。 检验科的危急值响应系统更具临床价值:当血钾检测结果<2.5mmol/L(危急值下限),系统会立即以弹窗形式推送给主管医生和护士站(附低钾血症处理流程图),并启动10分钟响应倒计时(超时未处理会自动提醒科主任)。 **②.线上MDT** 多学科会诊(MDT)的线上化设计,大幅降低了协作成本。医生在系统中发起肺癌MDT申请后,系统会自动完成两项核心工作: - 资料汇总:从影像科、病理科、检验科抓取CT影像、病理切片、肿瘤标志物等数据,生成患者病情数据包; - 时间协调:根据胸外科、肿瘤科、放疗科医生的出诊表,推荐3个合适的会诊时段(如本周三下午2点、周五上午10点)。 会诊时,参与医生通过系统在线标注资料(如点击CT片此处淋巴结肿大,考虑转移),讨论过程实时文字记录(支持语音转文字),最终形成的诊疗方案自动存入病历(需所有参与医生电子签名确认)。 ## 三、远程医疗场景 在医疗资源东密西疏城密乡疏的背景下,远程医疗成为平衡供需的重要手段。EMR系统在此场景中的设计,既要解决数据传得远,更要保证传得安全、用得方便。 ### 1.远程诊疗 远程医疗的核心是信息传递的真实性与及时性,EMR系统通过技术创新实现了这一点。 **①.安全传输** 系统采用端到端加密+分级授权机制保障数据安全:患者病历在本地医院服务器用AES-256算法加密后,通过IPsecVPN专线传输;远程专家需通过密码+动态口令(每60秒刷新)双重认证才能解密查看。 更严格的数据脱敏设计,让隐私保护更精准:系统会自动隐藏患者姓名(替换为患者A)、身份证号(只保留前6位和后4位)、家庭住址等敏感信息,只保留56岁女性、糖尿病史10年等诊疗必要信息。 **②.实时交互** EMR系统与远程会诊平台深度融合,支持病历+视频+标注三位一体交互:专家查看电子病历时,可随时点击发起视频(高清摄像头支持1080P画质),观察患者的皮肤黄疸、皮疹等体征;讨论CT影像时,专家在屏幕上圈出右肺下叶结节,本地医生的界面会同步显示(支持实时语音解说)。 ### 2.慢性病管理 慢性病患者的远程管理,依赖EMR系统与家用医疗设备的智能联动,从定期复诊到实时监测。 **①.数据采集** 系统兼容多种远程设备的通信协议(蓝牙BLE、WiFi、NB-IoT):糖尿病患者用蓝牙血糖仪测量血糖后,数据会自动上传至系统(每5分钟同步一次),生成日内血糖曲线(标注空腹餐后2小时等时间点);高血压患者的智能血压计每天早8点、晚8点自动上传数据,系统若发现连续3天血压>160/100mmHg,会自动向医生发送预警(手机APP+短信),并推送建议增加降压药剂量(如氨氯地平从5mg增至10mg)的临床路径。 更先进的可穿戴设备联动功能,让风险预警更及时:冠心病患者的智能手表监测到心率骤升至150次/分(且持续10分钟),系统会立即触发三级响应——先给患者发送短信请立即休息,测量血压,5分钟未回复则拨打患者电话,10分钟无响应则自动联系社区医生上门查看(同步推送患者实时位置)。 **②.设备管理** 系统的设备状态监控模块,让数据可靠性更可控:医生可查看患者设备的健康档案(如血糖仪上次校准时间是3天前,符合ISO标准);若设备电池电量低于20%,会自动发送短信提醒患者充电(附充电操作指南链接)。 针对不会操作智能设备的老年患者,系统设计了家属代传模式:家属用手机拍照上传纸质血糖记录(如空腹6.5mmol/L),系统通过OCR识别转化为结构化数据(准确率98%),同时标注家属上传,建议下次核实设备数据。 ## 四、从记录者到决策者的进化之路 EMR系统的真正价值,从来不是把病历搬进电脑,而是通过数据的流动与整合,重塑医疗服务的底层逻辑——让门诊流程更高效,让住院协作更顺畅,让远程医疗更精准。 未来,随着AI辅助诊断(如基于病历数据的疾病风险预测)、大数据预后模型(如肿瘤患者生存率预测)的融入,EMR系统或许会从信息记录者升级为诊疗决策者。但无论技术如何迭代,以患者为中心的核心不会变——让医疗服务更高效、更安全、更可及,始终是其不变的使命。 本文由 @阿堂 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议

智能体的上限本质上是模型能力的天花板。
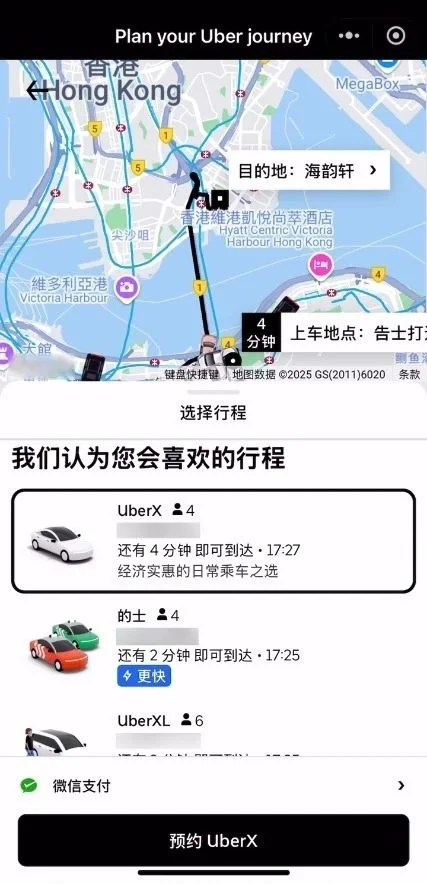
今日,微信宣布,Uber优步|全球打车出行微信小程序正式上线。在境外就能直接在微信内用Uber小程序打车,不用下载App ,并且还是中文界面。此外,在小程序内打车后,能直接通过微信付款,支持微信支付及WeChat港币钱包。 据介绍,目前,中国香港和日本已能使用Uber微信小程序乘车。 未来数月,美国、英国、法国以及澳洲等9个国家和地区也将逐渐能够使用。 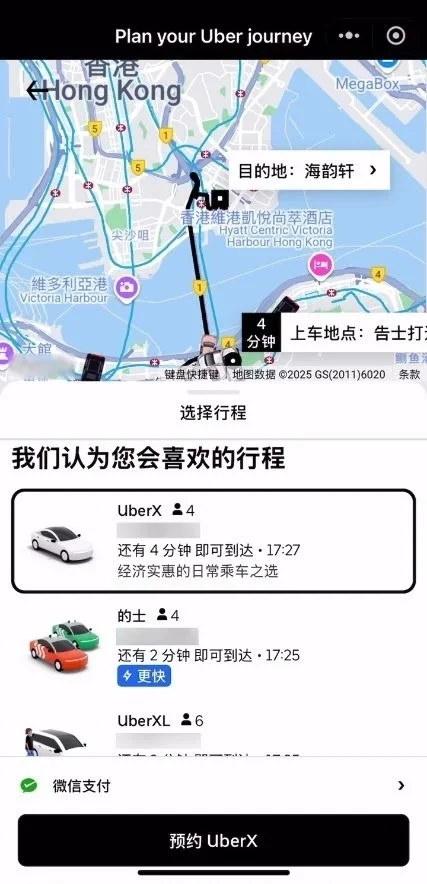 财报显示,2024年第四季度,Uber总预订额为441.97亿美元,同比增长18%;营收119.59亿美元,同比增长20%;归属于公司的净利润为68.83亿美元,上年同期为14.29亿美元。 2024年全年,Uber总预订额为1627.73亿美元,同比增长18%;营收为439.78亿美元,同比增长18%;归属于公司的净利润为98.56亿美元,上年同期为18.87亿美元。 [查看评论](https://m.cnbeta.com.tw/comment/1514424.htm)
 中手游日前宣布,继《仙剑奇侠传四》动画番剧后,与哔哩哔哩(B站)再度携手,就国民级IP《仙剑奇侠传一》的动画番剧开发达成重要合作。与此同时,《仙剑奇侠传四》动画也即将公布最新进展,敬请期待。双方将共同以高品质的动画内容,为这一经典注入全新的生命力。  此次合作正值《仙剑》IP于今年7月8日迎来三十周年纪念日的里程碑时刻。本次《仙剑奇侠传一》的动画化企划,其重要性不言而喻。作为整个系列的开山之作,《仙剑奇侠传一》不仅是无数玩家的仙侠启蒙,更是感动了一代人的文化符号。此次动画化旨在重塑并再现李逍遥、赵灵儿、林月如等角色之间的宿命纠葛与动人真情,回应广大仙剑粉丝长久以来的热切期盼,让这份最初的感动,以全新的视觉形式,跨越时空,触达新一代观众。 中手游希望通过当前深受年轻人喜爱的动画内容,触达并吸引更广泛的年轻用户群体,进一步推动仙剑IP受众的年轻化迭代,让跨越三十年的侠义故事在新时代焕发新生。而B站作为国内年轻群体最活跃的综合内容社区,其用户群体与此目标高度契合。B站汇聚了核心的Z世代用户,他们对多元化、特色化的二次元内容、潮流文化抱有极大热情,并注重内容带来的情绪价值与认同感。  本次强强联手,是中手游与B站基于对国漫市场蓬勃发展趋势及仙剑IP价值的共同看好而达成的战略共识。对于B站而言,引入《仙剑》这一顶级IP的系列动画,将丰富其国创内容矩阵,为平台用户带来备受期待的优质内容供给,有效活跃社区生态。 展望未来,中手游将以《仙剑奇侠传》三十周年为契机,持续深化IP的长线运营与价值挖掘。预计未来随着《仙剑》系列动画的陆续上线及IP生态布局的全面拓展,仙剑IP的品牌影响力和商业价值将迎来显著提升。

京东科技AI相关负责人对笔者表示,京东主要聚焦于机器人和大模型的深度结合,以及新应用场景的探索,包括世界模型、深度推理模型等,最终将机器人希望做到可执行、可操作的“具身智能”,无论是机器人、车,还是机器狗,都是如此。
 爱范儿 · 马扶摇
爱范儿 · 马扶摇
那个砸不烂的手机,终究还是被砸烂了。 #欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。 [爱范儿](https://www.ifanr.com) |[原文链接](https://www.ifanr.com/1631190) ·[查看评论](https://www.ifanr.com/1631190#comments) ·[新浪微博](https://weibo.com/ifanr)

对于国产手机厂商来说,出海要面临的重重关卡,绝不仅是电池而已。 #欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。 [爱范儿](https://www.ifanr.com) |[原文链接](https://www.ifanr.com/1631219) ·[查看评论](https://www.ifanr.com/1631219#comments) ·[新浪微博](https://weibo.com/ifanr)
 以京都大学著名的“吉田寮”为舞台的游戏《我是宿舍生》,近日在京都都展览馆举办的“第13届BitSummit”上展出,现场提供了试玩环节并与制作团队深度交流试玩感受。 据报道,这款游戏将免费发布,试玩版也可以在unityroom上在线畅玩。 <内嵌内容,请前往机核查看> 游戏的背景设定在京都大学非常著名的自治宿舍“吉田寮”,它是日本最古老的学生宿舍,拥有112年的历史,至今仍有约120名学生居住,月租金仅为2500日元。 主人公是宿舍里备受喜爱的猫咪“ぼん”。有一天,你醒来发现自己变成了邦……故事就此开始。“ぼん”突然开始说人话,令其他宿舍成员大吃一惊。  除了住在“吉田寮”之外,你醒来之前作为“ぼん”的记忆非常模糊,甚至连“宿舍里有人附身于B‘ぼん’吗?”或者“‘ぼん’自己突然能说话了吗?”都还是个谜。你将探索宿舍,解开围绕记忆的谜团。 探索以横向卷轴的方式进行。宿舍分为几个区域,故事随着你与宿舍成员的对话而展开。你可以通过睡在垫子上操纵时间,遇到只在特定时间出现的宿舍成员。   本作的开发团队由现任宿舍成员、前任宿舍成员以及宿舍外的学生组成。 记者在试玩时发现了一些令人印象深刻的对话,现场与编剧聊起这段对话时,他告诉我,之所以加入这段对话,是因为“吉田寮”一直以来都是由宿舍成员自己管理的。 他解释说,宿舍成员之间既是朋友又是同事,共同努力学习,但又像一家公司,基于每个人的意见共同运营。为了让拥有不同背景和价值观的人能够以自己满意的方式管理自己,他们需要与那些感觉无法沟通的人进行沟通。游戏角色“柏”的话语看似友善,却不自觉地轻视了猫咪“ぼん”,伤害了他,这似乎象征着这一点。  此外,选择猫作为主角的原因之一是,在将故事背景设定在“吉田寮”这样一个不同性别、不同国籍的宿舍成员共同生活的地方时,他希望尽可能以平和、客观的视角来讲述故事,不依赖任何特定的属性。编剧说他其实很讨厌动物,包括猫。 《我是宿舍生》毫不掩饰地展现了“吉田寮”管理的艰辛,同时也以幽默的方式刻画了与古怪宿舍生的互动。 本篇转自:fami通

文旅的滥觞,或许可以在公元1613年徐霞客 “癸丑之三月晦,自宁海出门,云散日朗,人意山光,俱有喜态”的记载中可见一斑。从古至今,人类为什么喜欢旅游?我们将其归结于人类的天然好奇心和迁徙本能。远古的荒原茂林、冷风凉月,和如今的园林古桥、霓虹亮彩一样,激发着人类骨子里的探索欲。我们难以拒绝旅途给我们带来的多巴胺,因为远行是我们的基因愿望,而这也使得文旅行业成为了跨越周期的长青树。本文也将着眼于此,审视文旅发展动向,通过有价值的案例分析,展现文旅发展新解法。期待能为读者带来启发。