所有文章
 钛媒体 · 杨亚茹
钛媒体 · 杨亚茹
 cnBeta全文版
cnBeta全文版
几乎是一夜之间,“来自东方的神秘力量”又一次震撼海外人士心脏。1月27日,由国产大模型公司杭州深度求索开发的Deepseek应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。  苹果美国区应用商店  苹果APP Store中国区免费榜 据界面新闻,1月27日,DeepSeek官网显示,DeepSeek网页/API不可用。昨日(26日),DeepSeek曾出现短时闪崩现象。对此,DeepSeek回应称,当天下午确实出现了局部服务波动,但问题在数分钟内就得到了解决。此次事件可能是由于新模型发布后,用户访问量激增,服务器一时无法满足大量用户的并发需求。  Deepseek来自国产大模型公司深度求索,系量化巨头幻方量化旗下大模型公司。1月20日,该公司正式发布推理大模型DeepSeek-R1。一经推出,DeepSeek-R1便凭借其“物美价廉”的特性在海外开发者社区中引发了轰动。 今年1月20日,据新闻联播,国务院总理李强主持召开专家、企业家和教科文卫体等领域代表座谈会,听取对《政府工作报告(征求意见稿)》的意见建议。 DeepSeek创始人梁文锋参加此次座谈会,梁文锋既是深度求索(DeepSeek)创始人,也是头部量化私募幻方的创始人,创业范畴横跨金融和人工智能领域。 (央视新闻截图,左一梁文锋) 据潮新闻客户端,梁文锋,1985年出生于广东省湛江市。2002年,这位对数学建模充满热情的年轻人考入浙江大学电子信息工程专业,并在随后的几年里继续深造,最终于2010年获得信息与通信工程硕士学位。 在校期间,他对金融市场产生了浓厚的兴趣。特别在2008年全球金融危机之际,他带领团队探索了机器学习技术在全自动量化交易中的应用潜力,这一经历为他日后的职业生涯奠定了坚实的基础。 毕业后,梁文锋将目光转向更广阔的金融市场。 2013年,他与浙大同学徐进共同创立了杭州雅克比投资管理有限公司,两年后又成立了杭州幻方科技有限公司,致力于通过数学和人工智能进行量化投资。2015年的市场波动中,幻方依靠先进的高频量化策略取得了令人瞩目的成绩。 2016年是幻方的重要转折点。这一年,公司推出了首个基于深度学习的交易模型,并实现了所有量化策略的AI化转型。2018年,幻方正式确立了以AI为核心的发展战略。然而,随着业务的快速扩展,算力瓶颈逐渐显现。 为解决计算资源不足的问题,2019年,梁文锋带领团队自主研发了“萤火一号”训练平台,总投资近2亿元,搭载了1100块GPU。两年后,“萤火二号”的投入增加到10亿元,搭载了约1万张英伟达A100显卡。 2021年,幻方的资产管理规模突破千亿大关,跻身国内量化私募领域的“四大天王”之列。2023年,他宣布将正式进军通用人工智能领域,并创办了深度求索DeepSeek,专注于做真正人类级别的人工智能。 2024年5月,DeepSeek发布混合专家语言模型DeepSeek-V2。同年12月,DeepSeek-V3问世,这款性能优越且性价比极高的大语言模型,被硅谷同行誉为“来自东方的神秘力量”。 DeepSeek之所以被科技圈关注,在于DeepSeek-V3的出现极大地降低了大模型训练和应用的成本,DeepSeek-V3训练成本仅557.6万美元,而OpenAI训练ChatGPT-4o所花费的成本高达7800万美元甚至是1亿美元,双方的成本至少是10倍的差距。 在性能上,DeepSeek-V3在数学、代码能力和中文知识问答方面还超过了ChatGPT-4o,行业震惊于这一性价比,DeepSeek-V3开源给全世界的技术开发团队。 在团队配置上,DeepSeek团队只有139名研发人员,对比ChatGPT的OpenAI团队则有1200名研究人员,团队规模是DeepSeek的近乎9倍之多。近期热门话题“雷军千万年薪挖95后天才AI少女”,这位AI少女就是DeepSeek团队的研发人员,但小米和当事人并未就此回应。 通过招聘网站注意到,深度求索公司的北京子公司正在招人,现共放出了52个岗位,包括深度学习研究员、核心系统研发工程师以及资深ui设计师等,均为14薪。 其中,薪资最高的为核心系统研发工程师(校招),薪资范围为6万元-9万元;除此之外,大部分岗位的起薪在2万元及以上。 值得一提的是,该公司正在招聘实习生,AGI大模型实习生的工资为500元/天-1000元/天,数据百晓生实习生为500元/天-510元/天。  1月27日,DeepSeek概念股表现强势,截至发稿,每日互动、华金资本、浙江东方涨停,并行科技、卓创资讯、拓尔思等涨幅居前。 消息面上,此前AMD宣布,已将新的DeepSeek-V3模型集成到Instinct MI300X GPU上,该模型旨在与SGLang一起实现最佳性能。 华经产业研究院报告显示,2023年国内智能体市场规模达59.81亿元,预计2024年突破百亿元。中国工程院院士邬贺铨在2025年ICT行业趋势年会上表示,2025年不仅是智能体的元年,也将是AI终端的元年。 [查看评论](https://m.cnbeta.com.tw/comment/1474302.htm)

Meta推出了一项新举措,通过“突破奖金计划”(Breakthrough Bonus Program)提供高达5000美元的奖金,以吸引TikTok创作者加入其平台。TikTok目前无法从苹果和谷歌在美国的应用商店下载,Meta正在抓住这个机会,向更多用户推广其社交媒体Instagram。  该计划旨在鼓励创作者在Facebook和Instagram上发帖,以吸引TikTok的一部分用户。根据Meta的说法,该项目向在其他社交媒体平台上已有存在并愿意在申请过程中链接该平台的美国创作者开放。 符合条件的参与者必须在Instagram和Facebook上创建一个专业账户。一旦被接受,创作者必须在每30天的奖励期内在Facebook上发布至少20个Reels,在Instagram上发布10个Reels。 在此期间,他们还必须至少在10天内共享内容。创作者在90天内最多可以赚到5000美元,报酬是根据对他们社交形象的评估而定的。 据知情人士透露,这家社交媒体公司还根据受众规模提供了不同的交付量和报酬条款。 Instagram向在TikTok上拥有大量粉丝的创作者提供每月1万至5万美元不等的现金奖励,奖励创作者将他们的视频转移到Instagram Reels上。 Meta表示,它还宣布了几项针对创作者的新功能,包括一款名为Edits的视频创作应用,将视频时长延长至三分钟,以及一项针对创作者货币化的新奖励计划。 平台抢夺创作者 Instagram的这一努力突显了社交媒体领域的高风险,各平台都在竞相吸引数百万用户的注意力,而TikTok的未来则悬而未决。 上周,在美国最高法院支持前总统乔·拜登今年4月签署的一项法律后,TikTok在美国关闭了几个小时。根据这项法律,苹果和谷歌还将TikTok从美国的应用商店下架 然而,在特朗普总统表示他将推迟禁令后,该应用程序又开始在美国恢复使用。特朗普周一签署了行政命令,将禁令的执行推迟了75天。 对Meta来说,在近年来TikTok的受欢迎程度超过Instagram之后,向创作者付费来推广Instagram可能是一种有效的策略,可以重新夺回Instagram作为青少年和年轻人中最受欢迎的社交媒体平台的地位。 根据皮尤研究中心2023年的一项调查,63%的13至17岁的青少年说他们使用TikTok,而使用Instagram的比例为59%。 许多TikTok创作者将品牌交易作为创收的主要方式,支付方式往往取决于他们的粉丝数量。由于TikTok的未来前途未卜,各大品牌正在暂停或修改协议,以纳入竞争平台。 “广告已经暂停,这造成了很多焦虑和大量收入损失,”管理许多顶级互联网创作者的经纪公司Underscore Talent的联合首席执行官 Dan Weinstein表示。 Weinstein表示,在不确定的情况下,广告商和创作者都在观望,各品牌正在将Instagram和YouTube Shorts等平台纳入协议,使其社交媒体战略多样化,而不仅仅是TikTok。 从一个平台跳到另一个平台并不能保证创作者成功。许多在TikTok上很受欢迎的人,可能很难在其他应用上获得受众。 社交媒体咨询公司Social4TheWin的创始人兼首席执行官雅各布•瓦拉赫表示:“TikTok上的许多创作者很难转向传统的YouTube或Instagram。”“你有YouTube Shorts,也有Instagram Reels。你可以在这些平台上重新利用这些内容,但算法是不同的。” Meta并不是唯一一家希望抓住那些寻找新收入来源的创作者的公司。 Substack周四宣布了一项2000万美元的创作者加速器基金,以帮助创作者转移和增加他们的付费订阅。Substack是一个允许作家和创作者发布时事通讯并通过订阅为其内容产生收入的平台。 [查看评论](https://m.cnbeta.com.tw/comment/1474300.htm)

1月25日,雷军开启龙年收官直播。不过,下午1点48分,雷军的抖音直播间突然遭到封禁。有网友表示其举报了雷军,举报理由是“一边开车,一边直播”。第二天,雷军称“昨天端到端智驾直播非常顺利,给我们的智驾团队点赞!”。此外,雷军还发文:“给大家拜个早年,提前祝大家新年快乐,开车一定注意安全!”疑似回应抖音直播被封。   昨天,余承东预告了自己“自驾回安徽老家过年”的直播活动,直播平台包括微博、抖音等。 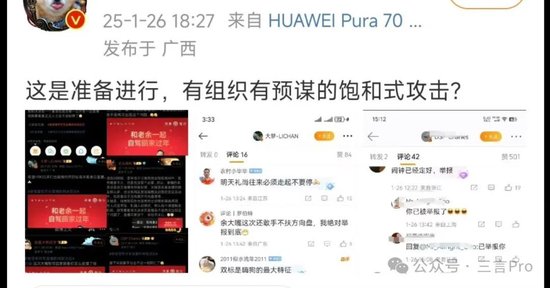 有不少网友准备像举报雷军开车直播那样举报余承东。 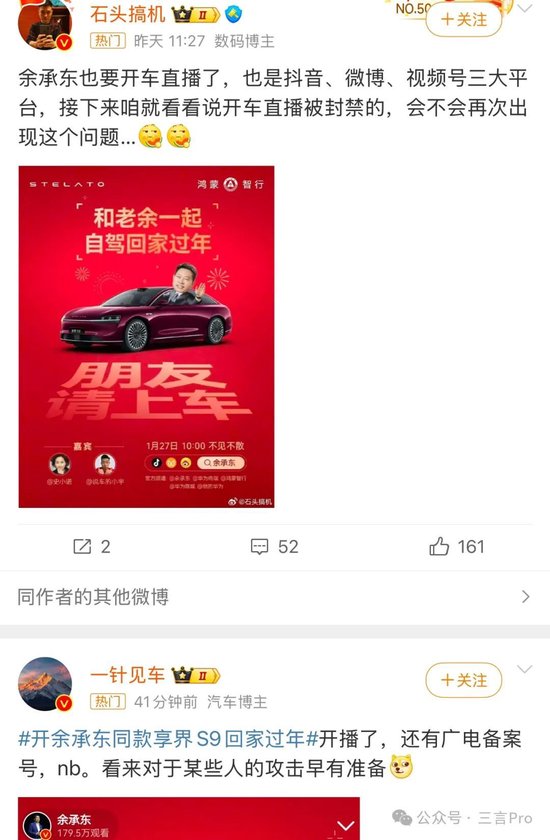 有博主也等待看直播是不是再次出现“雷军被封禁”的情况。 今天上午,余承东直播如约开启,但是三言Pro发现,直播画面备注了广电备案号、“固定机位拍摄,内容提前录制,安全驾驶,非直播”。 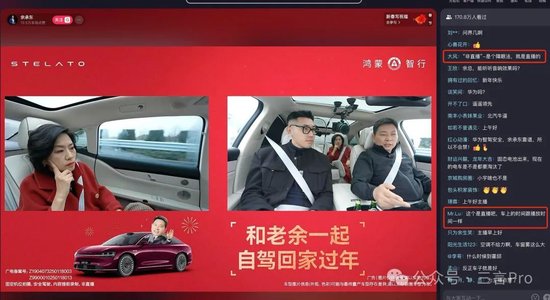 有网友发现,“这个是直播,车上的时间跟播放时间一样”,称“非直播”是障眼法。 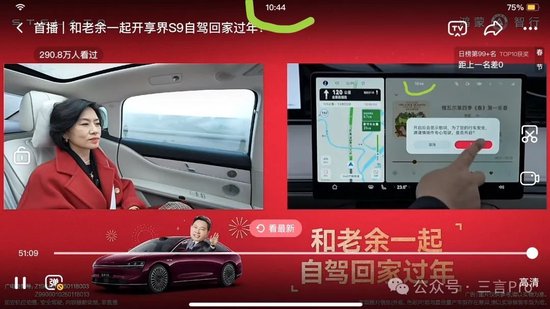 三言Pro也发现,画面切到中控屏时,屏幕上的时间跟实时时间是一样的。 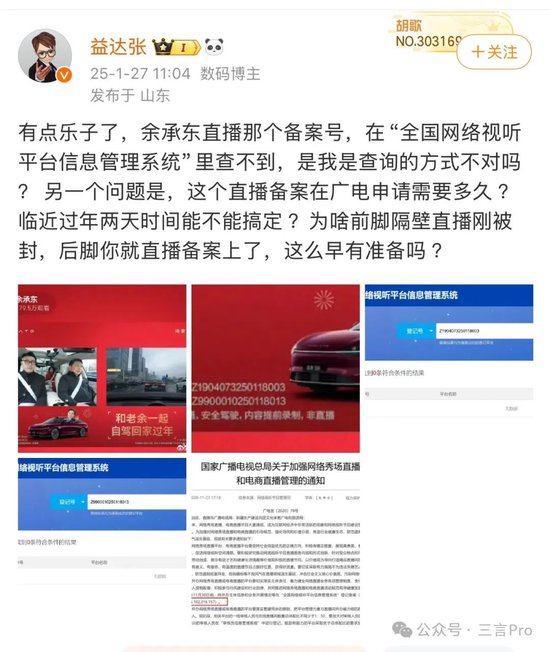 有博主查询发现,余承东直播画面标注的备案号在“全国网络视听平台信息管理系统”里查不到。 目前余承东的直播正常,没有被封禁。 不管是否是真的开车直播,雷军开车直播被封禁给大家习以为常的、车企常规宣传方法“开车直播”以警醒,以后的开车直播都会有应对措施。 那到底能不能开车直播? 抖音官方客服表示,“开车的时候,这个开车的人不要直播就好了。可以标注一下,直播人非驾驶员就可以了。只要驾驶人不是本人就可以(直播),然后直播间标注一下就行,一定要在安全的情况下直播。” [查看评论](https://m.cnbeta.com.tw/comment/1474298.htm)

DeepSeek,彻底出圈了。1月27日,DeepSeek应用登顶苹果美国地区应用商店免费App下载排行榜,在美区下载榜上超越了ChatGPT。同日,苹果中国区应用商店免费榜显示,DeepSeek成为中国区第一。它是否会颠覆大众对于搜索的认知?答案是肯定的。  近日,新浪科技发起了一项名为“你日常主要使用哪些搜索工具?”的微博调查,数百人参与的调查结果显示:占比59%的网友,明确表示主要使用AI搜索工具;而使用百度等传统搜索工具的用户,占比仅为22%。 虽然以百度为代表的搜索巨头也在积极布局GPT产品,但不可否认的是,其市场份额已经被蚕食,百度的财报也间接反映了这一现实——最近两个季度以来,百度的营收和利润增幅出现了增长停滞甚至下滑。 业内人士认为,伴随着一波接一波的GPT和AI搜索产品的浪潮,尤其是DeepSeek等新型产品的发布,众多玩家已经将百度等国内传统搜索公司,推向了悬崖边。 中国搜索行业,恐怕真要“变天了”。 **强得可怕:DeepSeek出圈的核心因素** 数天前,DeepSeek宣布,DeepSeek-R1模型发布并开源,在数学、代码、自然语言推理等任务上,R1模型性能比肩OpenAI o1正式版。  在定价上,DeepSeek-R1 API 服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16 元。相比OpenAI o1-mini、o1-preview以及o1模型,DeepSeek-R1在输入输出价格上均有着数倍的价格优势。 接连发布两款性能比肩世界一流水平且更具价格优势的模型,而且全部开源,DeepSeek这一举措快速引起了全球AI圈——尤其是美国头部科技公司领导人及顶尖AI学者的盛赞。 其中,微软CEO萨蒂亚·纳德拉(Satya Nadella)直言:“我们应该非常非常认真地对待中国的发展。”Meta创始人兼CEO扎克伯格则赞道“DeepSeek非常先进”,并认为“中美之间的AI差距非常小。” 在业内人士看来,DeepSeek快速“火热出圈”,有两个最为核心的因素。第一,在技术层面,DeepSeek背后的模型技术具有了比肩OpenAI 4o和o1模型的能力,且成本更低;第二,DeepSeek把这一系列技术全部开源了,这让全球开源大模型的技术水平,拔高到了与OpenAI 4o和o1模型同等能力水平,且成本更低,这让更多的AI团队,能够基于最先进的模型开发更多的AI原生应用。 **六成受访用户抛弃:百度面临的四大困境** 一个可以预见的趋势是,伴随DeepSeek模型开源带来的AI普惠效益爆发,越来越多创新玩家将快速涌现,将对在场景竞争中逐步落后的公司造成巨大的冲击。 其中,传统搜索行业便是一个典型案例,百度作为国内最大的互联网时代传统搜索企业,必将受到更为明显的冲击。 在上述微博调查中:59%的网友选择正在使用豆包、夸克、Kimi等新AI搜索工具;19%选择使用小红书、抖音等搜索,另外22%选择百度等传统搜索。由此可见,不仅是新AI搜索工具的冲击,小红书等另类搜索也在抢占百度等传统搜索的份额,且比例基本达到持平。 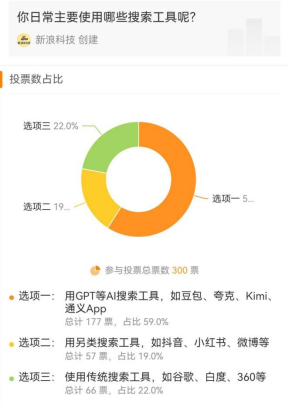 对此,有业内人士分析指出,新一轮的AI搜索、对话式AI产品快速抢占传统搜索市场,让百度面临众多困境: 第一,用户流量被分流了。 AI产品的高效精准回答必将吸引更多用户的关注,这直接导致百度搜索的流量下滑,进而影响其广告展示量和点击量。 第二,对广告营收的冲击。 众所周知,百度搜索的主要盈利模式是广告,随着用户流量的递减,广告主很可能会调整投放策略,转而投向其他搜索渠道,这将直接导致百度的广告营收面临压力。 第三,用户搜索习惯的改变。 一个尴尬的事实是,当你在搜索一个问题时,百度传统搜索呈现的结果往往掺杂了众多广告,这是百度SEM竞价商业模式的机制所致,也是其被诟病的主要原因。而对话式AI,会直接给出你想要的答案。长此以往,用户新的搜索和信息获取习惯将被改变。值得一提的是,百度也有众多积极应对的举措,例如先后发布了文心一言等搜索产品,且拥有亿级下载量。面对众多新选手,一场AI产品力的“隔空较量”正在进行。 第四,衍生产品增多竞争加剧。 可以预见的是,越来越多的玩家基于DeepSeek开源的模型能力,将快速创建出自己的AI搜索、对话式AI产品,这将加剧整个搜索行业的竞争,百度的份额或将进一步缩小。 **窘态已现:百度在线营销收入连续下滑** 这些产品对于百度的影响,或许已经反映在财报中。最近两个季度以来,百度的营收和利润增幅出现了增长停滞甚至下滑。 以2024年第二、第三季度为例:在第二季度,百度实现营收339.31亿元,同比增长0%;同期,归母净利润(非公认会计准则)73.96亿元,同比下滑8%;第三季度,百度实现营业收入335.57亿元,同比下滑3%;归母净利润(非公认会计准则)58.86亿元,同比下滑19%。 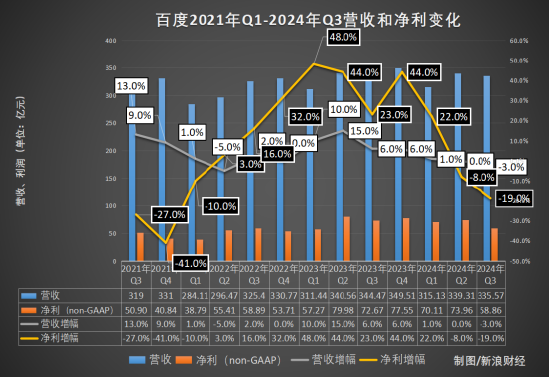 具体到搜索业务层面,2024年第三季度,以百度搜索为主的百度核心收入为265亿元,较去年基本持平,在线营销收入为188亿元,同比减少4%。这也是百度2024年以来连续第二次在线营销收入同比下滑。 从市场环境看,在过去的一年间,以字节跳动、腾讯、阿里巴巴等互联网大厂为代表,和月之暗面、昆仑万维等为代表的AI派搜索玩家,均先后推出自家AI搜索、AI对话问答助手。 据媒体不完全统计,以独立AI浏览器插件或App形式的AI搜索产品已超过16个。另外,目前整体涉及AI搜索赛道的公司超14家,产品超过23个。 大量新玩家出现背后,属于百度传统搜索玩家的市场份额正在被蚕食,地位正在动摇。中国搜索行业,恐怕真要“变天了”。 彩蛋:文心一言如何看待DeepSeek对百度的冲击? 在去年11月的百度世界2024大会上,百度首席技术官王海峰公布了“文心一言”的用户规模已经达到4.3亿。那么,如果将问题抛给“文心一言”(后升级为“文小言”),它又将如何作答? 以下为“文心一言如何看待DeepSeek对百度的冲击?”的回答: DeepSeek对百度的冲击主要体现在AI领域,尤其是搜索引擎市场。随着DeepSeek与小红书等平台的合作,其先进的AI技术为用户提供了更加智能、个性化的搜索服务,这对百度传统的搜索引擎地位构成了挑战。 DeepSeek凭借其创新的技术和高性价比的产品,打破了AI行业原有的平衡。其独特的模型架构和训练算法,使得DeepSeek在模型训练成本大幅降低的同时,性能却不逊色于传统巨头的产品,如百度等。这种技术突破为行业发展提供了新的方向,让其他企业认识到即使在资源有限的情况下,也可以通过技术创新来提升竞争力。 在应用市场中,DeepSeek凭借出色的性能和高性价比,迅速吸引了大量客户,包括一些中小企业。这些企业原本可能因预算有限而难以使用百度等巨头的高端AI服务,但DeepSeek的出现为他们提供了新的选择,从而直接威胁到百度的市场份额。 为了应对竞争,百度可能需要进一步优化产品、降低成本,并保持技术创新以保持市场竞争力。同时,百度也可以借鉴DeepSeek的开源策略,加强与开发者和企业的合作,共同推动AI行业的发展。 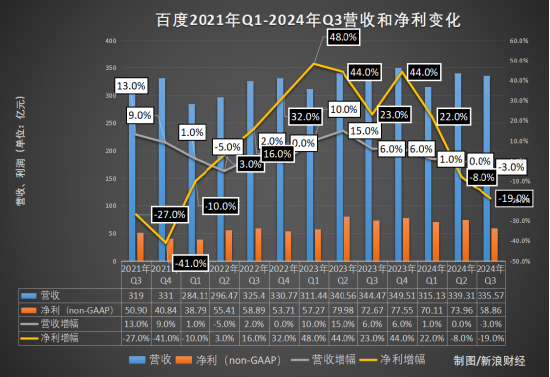 [查看评论](https://m.cnbeta.com.tw/comment/1474296.htm)

1月27日,DeepSeek应用登顶苹果美国地区应用商店免费App下载排行榜,在美区下载榜上超越了ChatGPT。同日,苹果中国区应用商店免费榜显示,DeepSeek成为中国区第一。DeepSeek究竟厉害在哪里?  今日,中国工程院院士、清华大学计算机系教授郑纬民及多位AI圈人士在与新浪科技沟通中,指出了DeepSeek其成功出圈的关键所在。 目前,业界对于DeepSeek的喜爱与赞美,主要集中在三个方面。第一,在技术层面,DeepSeek背后的DeepSeek-V3及公司新近推出的DeepSeek-R1两款模型,分别实现了比肩OpenAI 4o和o1模型的能力。第二,DeepSeek研发的这两款模型成本更低,仅为OpenAI 4o和o1模型的十分之一左右。第三,DeepSeek把这一两大模型的技术都开源了,这让更多的AI团队,能够基于最先进同时成本最低的模型,开发更多的AI原生应用。 那么,DeepSeek是如何实现模型成本的降低的呢? 郑纬民指出,“DeepSeek自研的MLA架构和DeepSeek MOE架构,为其自身的模型训练成本下降,起到了关键作用。”他指出,“MLA主要通过改造注意力算子压缩了KV Cache大小,实现了在同样容量下可以存储更多的KV Cache,该架构和DeepSeek-V3模型中FFN 层的改造相配合,实现了一个非常大的稀疏MoE 层,这成为DeepSeek训练成本低最关键的原因。” 就技术层面而言,KV Cache是一种优化技术,常被用于存储人工智能模型运行时产生的token的键值对(即key- value数值),以提高计算效率。具体而言,在模型运算过程中,KV cache会在模型运算过程中充当一个内存库的角色,以存储模型之前处理过的token键值,通过模型运算计算出注意力分数,有效控制被存储token的输入输出,通过“以存换算”避免了多数大模型运算每次都是从第一个token开始运算的重复计算,提升了算力使用效率。 此外,据郑纬民透露,DeepSeek还解决了“非常大同时非常稀疏的MoE模型”使用的性能难题,而这也成了“DeepSeek训练成本低最关键的原因”。 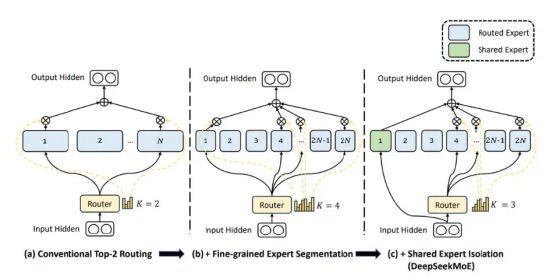 目前,通过MoE混合专家模型提升AI大模型的专业认知能力正成为业界公认的有效手段,而且一个大模型的专家模型数量越多,模型就越稀疏,效率也越高,但专家模型变多可能导致最终生成的结果不太准确。 据郑纬民介绍,“DeepSeek比较厉害的是训练MoE的能力,成为公开MoE模型训练中第一个能训练成功这么大MoE的企业。”新浪科技了解到,为保证大规模MoE专家模型的均衡运行,DeepSeek使用了先进的、不需要辅助损失函数的、专家加载均衡技术,保证每个token下,少量专家网络参数被真正激活的情况下,不同的专家网络能够以更均衡的频率被激活,防止专家网络激活扎堆。 此外,DeepSeek还充分利用专家网络被稀疏激活的设计,限制了每个token被发送往GPU集群节点(node)的数量,这使得GPU之间通信开销稳定在较低的水位。 [查看评论](https://m.cnbeta.com.tw/comment/1474294.htm)
华为常务董事、终端BG董事长、智能汽车解决方案BU董事长余承东今天上午10:00开启“自驾回安徽老家过年”的直播,直播平台包括微博、抖音等。 当时直播画面备注了广电备案号、“固定机位拍摄,内容提前录制,安全驾驶,非直播”。有网友发现,车上中控屏时间比实际时间快了7分钟。今天12:00左右,余承东自驾到达终点一门店,这时其抖音直播间被封禁,直播停止。 关于开车直播的问题,抖音客服表示,为了安全考虑,不建议在开车的时候直播,并称“可以标注一下,直播人非驾驶员就可以了。只要驾驶人不是本人就可以(直播),然后直播间标注一下就行,一定要在安全的情况下直播。”  [查看评论](https://m.cnbeta.com.tw/comment/1474292.htm)


行业发展日新月异,品牌在浪潮中迎风而上、破浪前行。接下来我们会继续和品牌同路,关注中国品牌的升级成长与全球化进程。

如何在内卷中寻找到新价值与差异点,如何在创新和规模之间寻找到平衡,如何让护城河更深一点,也更广一点,是品牌必须要面临的挑战。我们整理出了2024年茶饮咖啡行业年度内容精选,欢迎持续交流。

 FreeBuf网络安全行业门户
FreeBuf网络安全行业门户GamaCopy模仿Gamaredon战术,针对俄罗斯实体展开网络间谍活动,利用UltraVNC远程控制主机,威胁国家安全。
 机核 · 雪豆
机核 · 雪豆 作为光荣特库摩旗下GUST工作室的招牌系列“炼金工房”,在许多玩家心中一直都有着非常重要的地位,而系列前作《莱莎的炼金工房》的出圈,也让更多人认识到了这一历史悠久的经典游戏系列。伴随《优米雅的炼金工房 ~追忆之炼金术士与幻创之地~》的公布,GUST似乎有意要将这一系列打造成更加亲民,更具现代感的作品。  前不久,应光荣特库摩的邀请,我们采访到了《优米雅的炼金工房》的制作人细井顺三和导演安彦信一,作为缔造了前作“莱莎三部曲”的两位关键人物。这次采访中,他们为我们回答了一些关于本作开发理念方面的问题。 # 以下为采访正文: <blockquote> Q1. 我们知道,“炼金工房”系列的开发速度其实一直都算比较快的。请问本作是从什么时候开始制作,以及开发团队的规模是怎样的?</blockquote> 细井:大家都知道《莱莎的炼金工房 3》是2023年发售的,而本作开发的开始时间大概是《莱莎3》发售前的半年。本作项目的整体规模可以说是整个“炼金工房”系列以来以来最大的。  <blockquote> Q2. 本作中有着类似“射击”这样比较偏热兵器的游戏模式,同时在之前的采访中也提到过类似“摩托车”之类的现代化载具系统,请问采取这样的世界观描绘的初衷是什么?</blockquote> 细井:我们最主要的想法,其实是想要让这个系列成为一部在世界范围内都可以被玩家所接受的作品。其实早在《莱莎3》公布的时候我们就已经发现,从当时玩家的反应来看,过去系列的很多特点早就已经过时了。所以我们想在下一部中为大家呈现出一些不一样的新东西,以此为基础考虑到全世界的流行趋势,最终设计出了这样的世界观。  <blockquote> Q3. 本作加入了许多系列未曾出现过的全新游戏系统,比如战斗系统采用了即时制,那么请问这个战斗系统是否会导致策略趣味性方面的降低?又或者说,开发团队希望能给玩家们带来怎样的战斗体验呢?</blockquote> 安彦:正如您所说,本作和前作的最大差异就是在于这种偏即时制的,加入了许多动作要素的战斗系统,但从策略层面上来说,我们仍然是基于JRPG那种攻防转换来进行设计的,比如前作大家在战斗中会使用怎样的道具,在这一部中也同样可以采用相同的行动。面对不同的敌人,也需要采取不同的应对方式。 细井:另外,每个角色在本作即时制下的表现,能更好地展现角色的特性和魅力,通过战斗方面的改动,也可以给大家带来“炼金工房”战斗中独特的那一面。  <blockquote> Q4. 在之前的游戏预告演示中,我们可以看到本作的开放世界里有相当多的可玩要素,那这是否意味着本作的游玩核心会和以往不同,更侧重于解谜、收集与探索呢?</blockquote> 细井:从根本上来说是没有变的,我们想做的依然是一个比较有特色的“炼金工房”,所以它的基础会是调和系统。在此基础之上,为了让大家更多地享受到游戏的乐趣,才丰富了探索系统里面的一些要素。 <blockquote> Q5. 本作中玩家在探索高浓度的“玛那领域”时,需要玩家考虑能量的管理,请问这样设计是想要给玩家们带来怎样的游戏体验呢?制作人觉得玩家对这一系统的接受度如何?</blockquote> 安彦:首先,玛那领域会与游戏故事有紧密的联系,所以在设计这部分的过程中会考虑将它作为本作的特色之一。之前玩RPG的时候,大家可能会考虑在探索时,什么时候会回到据点休息补充资源,所以本作的这个系统也会让玩家在探索过程保持的适当紧张感,和迄今为止的”炼金工房“中的系统都不大一样。为了让玩家避免在探索中压力过大,我们也设计了许多能量的恢复点,可以让玩家顺利游玩这一部分的内容。  <blockquote> Q6. 刚才提到本作的战斗系统会突出角色性格,我注意到主人公优米亚,她的高跟鞋的设计其实非常特殊,不但似乎与炼金挂钩,同时也很好突出了主人公之于臀部的刻画,选择高跟鞋来进行设计,是本作的人设べにたま自己的想法,还是制作人的想法呢?</blockquote> 细井: 可以说是两者意见结合的结果,本作在设计角色的时候一个很重要的点,就是希望玩家在进行游戏的时候,可以体会到“角色因服装的变化而更加彰显魅力”这个要素上。 <blockquote> Q7. 在之前的采访中您提到过本作的炼金系统会比系列前作稍微简单一点,是一部比较适合新玩家上手的作品。请问具体的简化在哪里呢?</blockquote> 安彦:正如所说,本作的调和系统比以前简单了一些,与以前的调和系统比较不太一样的点,就是只要玩家根据配方收集材料,然后进行调和就可以了。那么本作中的配方本身也是可以进行强化的,玩家要考虑如何强化配方,使用更好的素材来达到更强的效果。但是整个调和过程是比较简单的,无论新老玩家都能够很快上手。 <blockquote> Q8. 从之前透露的一些信息来看,本作的故事基调比之前的作品完全不同,比较严肃。请问为什么会想要做出这样的改变?玩家会感受到哪些不一样的地方呢?</blockquote> 细井:这个想法的初衷是因为我们收集了很多海外玩家的意见,很多玩家觉得炼金工房系列的故事不够厚重,想要一些比较严肃的剧情展开,比如主人公与描绘比较立体的反派角色进行对峙的类似剧情。出于这样的考虑,我们撰写出了本作的剧情。但请放心,很多系列玩家喜欢的那种温馨治愈的日常故事在本作中还是存在的,并不是完全消失了,主线故事可能更偏厚重一些而。 与此同时,大家希望的“和反派角色进行对峙”的故事也会出现在本作中。本作在讲述故事的时候,是从两个视点入手的:一方面是主人公团队看到的这个故事,另一方面则是反派角色他们的视点,两个视点相互交织,可以更加深刻地展现出本作剧情的精髓。  <blockquote> Q9. 官方之前有提到,“记忆”是本作故事的核心概念之一,除了故事以外,“记忆”是否会影响游戏的其它方面,例如游戏机制之类的呢? </blockquote> 安彦:是这样的。记忆在故事之外也会反映在游戏的其他系统中。比如说游戏中的遗迹,也就是小型迷宫,其中储存了一些旧文明的记忆,大家在探索的过程中收集这些记忆,就能够了解过去旧文明的一些背景故事。另一方面,一些调和系统的配方,也可以通过玩家在收集了记忆之后回想起来。 <blockquote> Q10. 本作制作了一个相当完整的房屋自定义系统,除了最基本的建造与调和外,这个系统还会带给玩家其他什么特别的机制吗?会有允许玩家之间通过联机来分享各自的设计吗? </blockquote> 安彦:关于分享功能,开发组起初的确是曾经考虑过,但最后没有实装在游戏中,我们会在今后的作品中再考虑这个问题。虽然没有分享功能,但在其他方面这一系统是可以提供一些比较特别的支援效果。比如说玩家操作的角色就可以通过建造系统获得强化,或者通过建造一些建筑之后,触发专门的任务,让大家可以在游戏中充分体验这个系统的乐趣。  <blockquote> Q11. 请问本作主角优米雅手持的法杖还融合了传统火枪的元素,请问为什么会想出这样一种特别的设计呢? </blockquote> 细井:迄今为止,炼金工房的主人公都用的是法杖,所以最初也想让本作的主人公用法杖。但除此以外,我们还想让她在原野上探索的时候能够做到更多的事情,比如当成射击武器等等,出于这个考虑,我们为法杖增加了枪的元素以及功能。玩家可以使用枪的功能,在探索解谜的过程中,收集素材、道具,或者是用它来突破一些障碍物等等。 <blockquote> Q12. 请问对制作人而言,即时战斗和开放世界哪个在开发层面上起来会觉得更困难一些?本作在开发过程中遇到的最大难题是哪一方面呢?</blockquote> 安彦:我觉得开放世界的开发工作会更难一些,这也是整款游戏开发时最困难的一点。因为在开放世界中,玩家会体会到身处原野中的距离感,我们需要重视玩家在原野上的探索体验。探索机制要如何调整平衡,为了实现这种平衡又要实装哪些功能,这些都是比较困难的地方。  <blockquote> Q13. 请问,本作新加入的变化会成为之后整个系列的常态吗?如果有玩家喜欢过去传统的玩法或者剧情,那会不会考虑再做一些跟之前差不多的作品? </blockquote> 细井:首先,本作的定位是一个次世代的炼金工房,本作中所展示的变化今后会不会继续沿用,还是要看本作在发售之后的反响来决定。与此同时,大家也知道2025年我们也会发售《红白炼金工房》,这就是一部比较具备传统意义的炼金工房 —— 它采用的是回合制系统。所以说实际上我们在开发中一直在进行两种尝试,一种是次世代的《炼金工房》,另一种是比较传统的《炼金工房》,两者都在进行开发。 <blockquote> Q14. 主人公优米雅是按照全世界玩家的审美视角去设计的,她的战斗动作相比其他作品的女主角来说也显得特别突出,那么制作人是否对优米雅能比《炼金工房》系列女主更受欢迎,充满信心呢? </blockquote> 细川:当然,我们本来就是这么打算的。(笑)  <blockquote> Q15. 请问本作的通关时间大概是多长?会比前作长一些吗?会包含新的挑战或是二周目限定的新难度吗?</blockquote> 安彦:根据大家游玩方式的不同,通关时间其实是有很大浮动的,大概40 ~ 60小时能够通关。二周目中,玩家可以在继承一部分数据物品的情况下进行游戏,另外一个比较大的特点是二周目中,玩家可以看到剧情的分歧点,能够比较清晰的了解到整个故事的来龙去脉。  <blockquote> Q16. 最后请二位对中国的玩家们说句话吧!</blockquote> 细川:首先,非常感谢各位海外玩家一直以来对于《炼金工房》系列和对于Gust品牌的支持,本作《优米雅的炼金工房》旨在成为一部次世代的《炼金工房》系列,为此,我们启用了迄今为止最大规模的开发团队,想以此来扩大《炼金工房》系列的影响。目前开发进度已基本结束,我们对这部作品“能够让玩家享受它的乐趣”这一点上充满了自信,所以请各位玩家务必亲自来体验一下,谢谢大家。 安彦: 非常感谢各位海外玩家一直以来对于《炼金工房》系列的支持,我们这次想为大家提供迄今为止从未有过的游戏体验,也比以往更加重视全球各地玩家的想法与感受,所以无论新老玩家,都希望能体验这部《优米雅的炼金工房》。我们也非常期待听到大家游戏之后的感想,也充满自信地认为我们做出了能让大家感到满意的作品,希望大家能够享受这部作品的乐趣,请多多关照。 <内嵌内容,请前往机核查看>
 极客公园
极客公园
今天,如果你问创业者 2025 年 AI 赛道最大的机会在哪?**那么 10 个人里至少有 5 个会回答:多模态。** 过去一年,我们见证了多模态模型领域的飞速发展:从 Sora 到 4o,从生成到感知,从图片、视频再到 3D,各种模态的基础模型在短短一年内完成了革命性的进化。 就像多点触屏催生了智能手机,推荐算法催生出头条、抖音,GPT-3.5 催生出 ChatGPT……每一轮基础技术的进步,都将在不久之后解锁创新的应用。而随着多模态模型的快速发展,越来越多从业者相信,2025 年多模态领域有望诞生出新的 Super App。 但真正置身其中,就会发现一切并没有那么简单,在这个赛道上有至少三个关键问题需要搞清楚: - 多模态模型的技术能力进步有多大,到底是革命还是噱头?具体哪些模态是真正颠覆性的进步。 - 多模态到底解决的是什么问题?给用户创造的价值是什么。 - 多模态模型如何落地?什么领域适合原生应用,什么领域适合原有产品改造,还有大厂和创业者的边界在哪里。 带着这些问题,我们不久前参加了火山引擎 Force 大会。在字节跳动内部,火山引擎是承担技术 ToB 的组织,涵盖豆包模型能力的调用以及云计算相关业务。众所周知,字节在 AI 上投入巨大,模型能力和基础设施快速提升,进而带来了国内 AI 应用创业者在火山引擎上的密度迅速提升。  _图片来源:火山引擎_ 从这些创业者的实践上,我们最明显的感觉就是大家正在形成共识:**多模态技术在快速进步,而充分运用好多模态的 ****AI ****应用,正在接近****用户体验****突破和用户价值突破的临界点。** ## **01 ****2024 年,多模态确实「卷」出了进展** 基础技术的进步会解锁应用的创新,但能否真正实现应用创新,其实也取决于基础技术的进步幅度。多模态模型这个赛道也不会例外,只有理解了多模态模型的发展现状、未来走向,摸清楚这些「新武器」的能力与边界,才能找到多模态应用创新的方向。 过去一年,图片生成、视频生成、视频理解、音乐生成、3D 生成等迎来了不同程度的突破,但在业内人士看来,**目前技术已经成熟,未来一年最有可能的落地的,还是图片生成和视频生成。** 对开发 AI 应用来说,主要考验模型技术在三个维度的能力:**生成质量、生成速度、和可控性。**按照这个标准,图片生成模型比视频生成模型的能力更成熟,现在能解锁的应用也更多。 图片生成领域起步时间早,2022 年 8 月就出现了 Stable Diffusion(第一款文生图开源模型),并在一定程度上解决了图片生成的可控性和质量问题、做到了可用的程度。随着模型算法全面向 DiT 架构转换,图像领域的可控性越来越好。同时,生成图片的效果和推理速度也在持续提升。随着工具层打造出更多的能力,图像生成领域已经能够做到在严肃场景实现高度个性化的图像生成效果。  _图为豆包图像大模型生成的图片,无论是精细程度、美感、光影都越来越自然和真实。|图片来源:字节跳动_ 在越来越丰富多样的场景驱动下,**图片生成的需求正在由开源模型承接为主,转变到以定向优化的闭源模型及其生态为主,从而满足更多样、更个性化的行业需求。同时,像 ComfyUI 这样能够让用户自己调整工作流和生图模型特定能力的中间层工具正在发挥关键作用。** 火山引擎 AI 开放平台产品总监傅鹭翔介绍,目前在互动娱乐、分享陪伴、小说配图、二创影视剧解说、儿童绘本等等场景下,图片生成模型都已经开始被广泛应用。 「现在的需求是多样化的,比如我要 A 风格的图片,你想要 B 风格的图片,他想要把某一个元素(比如一瓶水、一台车)融进图片里,这就很强调满足个性化需求的能力,同时这样的场景对图片生成效果的可控性要求也非常高。」傅鹭翔表示,「在这样的条件下,火山引擎把工具层的能力开放出来,比如把图像、视频前后的控制组件、基于豆包大模型的 Lora 精调等能力开放,再把搭载 ComfyUI、搭建 workflow 的能力开放给用户,避免 100 个用户提 100 个需求,一个一个排期来做定制化。」 **如果说上述图片生成模型的最新进展是由需求驱动,那么视频生成大模型的进展则主要靠供给方们「卷得有质量」。** 年初 Sora 横空出世,此前采用 U-Net、GAN 等算法架构的技术路线快速向 DiT 架构收敛,之后一年里,谷歌、快手可灵、字节即梦、爱诗科技等大厂和创业公司相继推出比肩 Sora 效果的视频生成模型。 值得一提的是,在这个领域国内公司已经快速实现了技术赶超,今天国内顶尖视频生成模型的质量公认达到全球第一梯队,甚至已经被 Meta 等大厂拿来作为跑分对比的标杆。明势资本夏令认为,这是由于当技术路线和竞争点收敛成为明牌后,就进入比拼工程和产品能力的阶段,这也正是中国创业者最擅长的地方。 <iframe src="https://player.youku.com/embed/XNjQ1MzIwOTc5Ng==" width="510" height="498" frameborder="0" allowfullscreen="allowfullscreen"></iframe> _这是一位戏剧学院老师、编剧小文通过「即梦 AI」及其背后的「豆包视频生成大模型」制作的一位女明星的奇幻旅程,还原了电影的发展史,从默片时代到有声时代。可以看出,视频生成模型已经可以在商业场景下做到如此精细的程度。|来源:字节跳动_ 很多尝鲜者都是被社交媒体上的 AI 视频惊艳,但自己上手以后却发现做不出同样的效果,这是因为今天 AI 生成视频的质量不够稳定,业内将这种现象称为「抽卡率」,即输入同一条 Prompt 后生成多少条视频中能有一条可用,目前业界常见的抽卡率是「8 抽 1」「10 抽 1」,更别说想要拿到效果特别好的,就需要抽更多次卡。 过去一年,我们可以看到各种社交媒体上人们分享的惊艳 AI 视频,这种效果就是 AI 生成视频已经「可用」的最好例证,但从「可用」到「商用」,短期内视频大模型还有一个必须解决的关键问题,就是「可靠性」。在尝鲜的使用场景这不是太大的问题,用户只是拿来分享社交媒体的话完全可以花上一天生成几百条并从里面选择最好的一两条发布,但对于效率、质量、成本要求更高的商用场景,稳定性就成了一个必须解决的问题。今天业内不少团队都在尝试通过工程化的方式来提升生成视频的稳定性,也就是所谓的「技术不够,产品来凑」。 ## **02 ****多模态到底解锁了什么?** 关于多模态模型的意义和价值,一个言论在业界广为流传:**每多一种模态的解锁,意味着用户渗透率的进一步提升。** 这句话背后的意义是:**只有文字的人机交互是单一的,是被限制的。人机交互的未来必然是多模态的,AI 需要多模态理解真实世界和真实的人,人也需要 AI 提供文字以外的输出。** 最典型的就是语音交互之于 ChatBot 这个今天使用最广泛的 AI 场景。今天越来越多 ChatBot 类的产品都已经加入语音交互功能,而在一些特定的使用场景下(比如用豆包等 AI App 学英语),语音交互就能极大地提升用户的使用体验。  _造梦次元上,用户可以选一个故事进入,与故事角色交互|截图来源:造梦次元官网_ 最近大火的造梦次元是一个典型的案例,在这个平台上,用户可以按照自己的想象创作「角色」,并让其他用户与自己创作的角色「互动」——聊天、咨询、调情、网恋都不在话下。 从各种乙女游戏、二次元游戏的火热中不难发现,与虚拟角色在一定的故事背景下,通过对话聊天、养成挑战等玩法形成情感连接,这种需求其实一直存在。造梦次元创始人、CEO 沈洽金向极客公园表示,「造梦次元解决的是一个已经存在了很长时间的需求。现在有了 AI 之后,我们这个互动体验就可以交给 AI 去解决,于是就做了现在这个公司,我们称之为——想法流。」 而 AI 能力的持续进步,实际上也在解锁造梦次元的体验边界。比如大语言模型的对话能力,以及构建智能体的技术,形成了造梦次元的产品基石;图片、音乐生成的技术,进一步解放了创作的技术门槛,让更多比「动手」更擅长「动嘴」的普通人也能做出高质量的虚拟角色。 而语音交互的加入,则进一步改善了用户体验。打开对话框,符合你对霸总、学霸、御姐等人设想象的声音自然流出,相比文字更容易让人产生在与真人交流的真实感。而过去要做到这一点,需要一名在专业学校培养数年的职业声优,花上数天或者数周时间熟悉角色、调整声线,还无法实时交互,而现在只要定好人设,AI 就能帮创作者完成一切。 据极客公园了解,使用多模态能力提升产品体验后,造梦次元的获客成本、用户时长、次日留存以及付费率四个关键业务指标提升明显,其也获得了锦秋基金和明势创投等多家 VC 的联合投资,成为当下 AI 应用领域的热门初创公司。 **除了利用多模态的交互形式创造用户价值,多模态应用的另一条路径是:用产品补基础模型的不足。** 就像上文提到的视频生成领域的可靠性问题,今天多模态模型直接用到生产环境存在各式各样的问题,针对特定的场景做产品层面的优化,反而能给用户更好的交互体验。 现在,Fotor 作为一个在图片生成赛道上跑出来的产品,在全球两百多个国家和地区提供 11 种语言,一共有接近 7 亿用户,月活 2000 万上下。Fotor 几乎已经把所有模态的模型嵌入到了产品工作流。 Fotor CTO 颜河向我们分享了 Fotor 利用多模态能力获得高速增长背后从 0 到 1 的过程,其中最行之有效的一个方法论就是「核心技术固本,优质产品拓新」。  _围绕视觉图像处理场景,Fotor 通过将生成式 AI 的能力整合到产品工作流中,带来了更好的图像编辑体验。|截图来源:fotor.com_ 比如用户上传了一张自己的图片,想对这张图片做一定的风格上的转换。从上传图片的那 1 秒开始,Fotor 会先利用图像识别模型的能力进行精准识别,识别出来的结果是一个结构化的数据,中间包含了这张图片的构图是什么样的、有没有人物、主体是什么等等。接着根据这些细分的意图利用模型的能力对这个图片进行一定的分割,再到下一步使用大模型进行相应的生成,再到下一步,通过视频模型让生成的图片动起来,最后再给到用户一个结果。 像造梦次元和 Fotor 所代表的 AI 互动内容平台和生产力产品也是当前用到多模态技术最多的主要场景。火山引擎方舟解决方案负责人冯书云告诉我们,**就所有模态的 AI 应用来看,当前主要有四个场景把产品做到了接近 PMF(产品市场匹配)。** - 第一类是泛娱乐,主要提供情绪价值。这类产品基于「类人」的互动体验,为用户提供情绪价值,比如社交、陪伴、内容等。比如阅文旗下「AI 男友平台」筑梦岛,为女性用户提供沉浸式虚拟陪伴的体验。 - 第二类是生产力场景,帮助用户提高工作效率、创造价值或者完成任务的工具或软件。由于生产力场景要求 AI 能够在特定任务上达到相对高的完成度,所以当国内模型达到 GPT-4 水平的时候,生产力应用开始大规模落地。 - 第三类是教育场景,以在线教育为核心,包括 K12、成人教育、职业教育,整个教育的全流程从教学大纲、出题、讲题、解析、互动陪练等等一个系列,基于大模型不同模态的能力,现在已经能形成一些很完整的解决方案。 - 第四类是终端或者叫硬件,包括手机、汽车、PC 这样有比较强的智能 OS 的产品,或者是一个点读笔、小的玩具、智能音箱,已经能进行一些自然互动、完成一些具体的任务。 作为字节跳动平台对内对外服务的大模型一站式服务平台,火山引擎 MaaS 平台火山方舟在过去两年的时间服务了字节内部所有的应用大模型的需求以及外部所有的客户。2024 年,火山引擎成为大模型调用量增长最猛的云厂商,半年里增长了数十倍。 火山引擎 V-Start 加速器负责人程子莹认为,随着豆包相继发布了视频生成、音乐视频、视觉模型,多模态模型供给越来越丰富,2025 年多模态一定会掀起第二波大模型应用的浪潮,会有相当多的 Token 消耗和算力发生在图片理解、视频理解、生图、生视频、语音等方面。随着模型能力变强、模态变多,也会解锁越来越多的新场景。 ## **03 ****看清边界,选对技术,做好产品** 「多模态模型技术会如何影响 2025 年做 AI 应用的走向」,当我们分别向模型厂商从业者、应用创业者、投资人提出这一问题时,三种不同角色身份的实干家们给出了几乎同一个答案: **不担心被模型吃掉、不担心大厂进入、不担心模型成本、多模态也成不了护城河。** 「最重要的事情只有一件,围绕目标用户,越来越好地解决需求;但前提一定是要了解 AI 技术的最新边界。」这是大家对新的一年如何做好多模态 AI 应用的一致判断。 「做 AI 应用的产品节奏要与模型技术发展的节奏同频。否则,产品上不仅会做无用功,也可能会做不好」。这是沈洽金在过去一年的实践中得到的教训,「最重要的是节奏,根据对当下、未来模型技术的判断,做应用的迭代」。 2025 年,多模态模型整体上一定还是在可控性、一致性、渲染力、生成速度上做持续的能力提升。尤其是视频生成模型的可控性和一致性,亟待进一步提升来降低废片率。 但具体不同模态的模型在不同场景里,各项性能表现发展到什么程度、可以被优化到什么程度,只能在场景中反复探索、调试。Fotor 颜河表示,哪怕是同一个技术路线如都是 DiT 架构,不同公司做出来的模型表现也差别巨大,而且同一个模型在不同场景里的表现也差别巨大。「同一个场景、同一批用户,同一个时间同一个内容我们接两个模型,最好的模型跟最差的模型的数据差距可以差到 10 倍,非常夸张,这与模型参数、数据配比、做研究实验的轮次等等都有关系」。 这时候,创业者探测模型边界、找到最匹配模型的经验都是 A/B Test,同一个能力在用模型的时候会反复嵌套,不停地在背后收集用户反馈(比如人均互动次数、漏斗率等指标),谁效果好就用谁,其次才是考虑模型成本,因为后者是早晚一定可以实现的事情。 **对于 2025 年,多模态会解锁哪些新应用的可能,冯书云更期待在内容消费和硬件上能打开更多空间。** 作为火山方舟解决方案负责人,过去一段时间,冯书云观察、走访了各个行业最活跃的多模态模型的应用创新者。在她看来,视频生成能力再进化,可能会解锁内容消费的新场景,给更多人带来更好的创作形式。 现在,视觉内容的巅峰是电影,大模型显然在效果上还比不过电影,但是围绕电影成片的整个工作流已经有大模型介入的机会。比如,一部电影其实是上百上千个镜头的拼接,在每个镜头从布景到实现的过程中,要做很多类似于 demo 的东西,如果视频生成模型进一步成熟,可以让导演用更简单、更高效的方法去将自己的创意灵感分享给剧组。 但她最期待的还是视频理解模型的突破,比如豆包 VLM 模型,可以输入文字、图片、视频到模型让它理解,这会给 AI 硬件带来更大的新空间。  _2024 年 12 月 18 日,火山引擎发布豆包视觉理解模型时,总结了其能解锁的新场景|图片来源:火山引擎_ 对于硬件来说,大语言模型可能只是一个大脑,而视频理解模型则是眼睛,能看「我」看到的东西,再去发挥它智力,会在很多场景中发挥作用。 比如现在看到的一些落地场景,工厂的监测、安保的巡逻,或者孩子拍了一道题,视觉理解模型加语言模型就可以帮着孩子一步一步去解题。 甚至有一些创业者认为,未来再做硬件创业时,那些简单的小机器人不需要嵌入式工程师了,人可以告诉大模型说,「根据你对世界的理解做一些动作」「如果做高兴的动作,胳膊的扭矩是多少,可以摆动多少度」,像这样通过一些比较基础的、人完全可以理解的指令去控制硬件,交互会变得非常自然,脑子变得越来越聪明,同时还有了眼睛可以理解世界。 过去几年,从 GPT-3.5 到 GPT-4,再到 Claude-3.5,每一次基础模型的迭代都引领了一波 AI 应用的爆发。展望未来,随着视频生成和视频理解模型的不断成熟,2025 年无疑将成为 AI 多模态领域的关键节点。一场新的技术浪潮正在酝酿,新一批现象级 AI 应用的诞生,势必会为这个领域注入更多可能性和想象力。
新威胁组织GamaCopy模仿俄罗斯Gamaredon APT,针对俄语目标发起攻击,使用军事诱饵文档和UltraVNC进行远程控制,欺骗安全厂商,威胁俄罗斯国防和基础设施领域。
 人人都是产品经理 · Robbie
人人都是产品经理 · Robbie
<blockquote><p>需求评审是产品经理日常会议的形式之一,也是一个“公开处刑”的时刻。这篇文章,我们看看作者分享的如何做好一次需求评审的经验,供大家参考。</p> </blockquote>  前段时间有小伙伴留言,想聊一下关于需求评审面向不同角色如何处理,以及产品不同生命周期产品工作上有什么区别。我结合自己工作经验,分两期内容来展开聊一下。 ## 01 首先来聊聊需求评审 需求评审对于产品同学来说再熟悉不过了,每次在进行新的迭代之前,我们一定会经历需求评审这个环节。如果按每2周一次小迭代,2个月一次中迭代,半年一次大迭代,那至少我们1年要经历32次需求评审。 但这是非常非常理想的状态,真实情况可能要乘以2倍,甚至3倍的次数。 即便是很稳定的迭代频次,不同的产品,不同的团队,也会产生不同需求评审的次数。 我们来看下,大家有没有遇到以下这几种情况: - 参会人员需求不明确,思维发散,没有任何反馈 - 因为某个功能观点不一,大家僵持不下 - 会上开始探讨技术方案,对问题点无限延展 - 需求文档遗漏点过多,需求产生变更 我想大家多多少少都遇到过,这种情况就会导致需求评审质量低,评审频次增加,进一步导致团队资源浪费,成本增加,同时可能会造成团队的信任危机 IBM研究表明,需求阶段的错误,在开发后期进行修复,成本可能会增加10-100倍。 ## 02 一个好的需求评审 首先我们先达成一个共识,需求评审的意义是什么? ### 统一认知,对齐目标 通过跨部门(产品、研发、设计、测试等)协作,确保所有干系人对需求的理解一致,避免因信息偏差导致的执行错误。例如:若产品未明确“用户登录功能”是否支持第三方账号,开发团队可能默认仅实现基础登录,导致后续返工。 ### 发现并规避风险 提前识别需求中的逻辑漏洞、技术难点或资源冲突,降低后期开发中的不确定性。**典型风险**:需求超出技术实现能力、时间节点不合理、合规问题(如数据隐私)。 ### 优化需求优先级 结合业务目标与资源限制,筛选高价值需求,避免资源浪费在低优先级功能上。 ### 增强团队协作与责任感 通过公开讨论明确各方职责,减少推诿,提升团队对需求的承诺感。 这样看下来,需求评审的重要程度就不言而喻了吧。 ## 03 那如何进行一个好的需求评审呢? 我们把需求评审分为三个阶段:会前准备/会中控制/会后跟进 ### 会前准备 - 文档规范:提供清晰的 PRD,包含流程图、原型图等内容。 - 预审沟通:提前与关键干系人沟通技术可行性。无论哪条业务线,技术侧都有相对话语权的负责人,我们在需求评审前都可以先把内容与其同步,确认方案的技术上可行性。 - 同步目标:提前与业务线成员同步本次评审目的/时间/需求大致范围。 ### 会中控制 - 把控节奏:把控节奏和会议时间,保证评审高效,不要因为个别问题延展,导致僵持不下。 - 聚焦问题:时刻聚焦评审核心内容,避免讨论偏离主题。 - 及时反馈:评审过程,遇到关键问题,需要及时给予反馈。 ### 会后跟进 - **输出结论**:会议结束后,明确需求调整项、责任人,将更新后的文档同步所有参与人员。 - **排期时间**:确定迭代周期,各参与者需要明确具体排期工时。 ## 04 面向不同角色,如何讲解需求 这里我们把面向的角色大致分为三类:业务方(外部客户/内部商务等)/UED团队/研发团队不同的角色工作职能不同,看待问题角度不同,所以同样的需求文档他们想要的结果也是不同的。 ### 业务方 - 需求价值:产品方案是否匹配业务痛点,投入与回报是否合理 - 交付承诺:是否能按期交付,保证交付质量 对于业务方来说,更注重的是结果,在可接受的时间范围内能否上线,是否匹配他的诉求,能给他带来多少业绩的提升。所以在跟业务方沟通,需要展示需求与 **OKR/KPI**的关联性,以及提供风险评估(如技术难度,政策变化,可能带来的风险) ### UED团队 - 用户体验一致性:视觉风格是否同意,交互流程是否符合用户体验 - 可行性验证:设计稿是否匹配多端,部分动效是否能实现 对于UED团队,更注重的是表现层内容,主视觉是否同意,交互流程与动效技术限制等。所以在跟UED团队沟通,要明确原型交互点,与技术限制(如H5动效性能边界) ### 研发团队 - 技术可行性:依赖技术方案(如新算法,三方API) - 细节与边界:是否有性能要求(如并发量、响应时间) - 自动化支持:是否需要定制化测试工具 对于研发团队,更注重技术可行性及边界范围等。所以在跟研发团队沟通,尽量提供完善的流程图(包含数据流),明确技术范围(如引用大模型技术),提供功能可能带来的来量级等(如活动推广范围,可能带来多少用户) 同样的需求文档,针对不同的角色,侧重点不同,需要的沟通的方式,提供的内容也是各不相同的。 需求评审虽然是产品同学习以为常的事情,但要做到高效高质量,其实也是件很难的事情。 希望这篇内容能给大家带来启发和帮助。 本文由 @Robbie 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
2025 could be a watershed year for AI agents, positioning them as a key area of technological growth.
 《杯杯倒满》全新章节更新,第六章-国风水果茶来啦!白墙青瓦、莲池回廊,在这样美好的国色风景下制作美味的水果茶,谁不想喝呢?快喊上朋友们一起来杯杯倒满吧~最多支持在线4人联机,本地双人!还有新的房间、新的家具,以及新的收藏品。更多新内容等你去发掘! <内嵌内容,请前往机核查看> 这是一款带有Roguelite元素的模拟饮品制作游戏,将使玩家身入其境的体验一家饮品店的点点滴滴。玩家可以使用不同种类的动物角色在各式各样的饮品店中工作,根据顾客的需求尽可能正确地制作饮品,同时还要管理库存与进货,避免资金短缺,以及管控角色所能够承受的“压力”。  在游戏中,需要根据所销售的饮品类型,进行提前准备材料、然后为顾客点单、制作饮品、完成出杯。就仅仅是这样吗?当然不!甚至还要打扫店铺卫生、赶走小偷、应对市监局审查等等。  游戏中所包含的饮品种类繁多,豆制,茶类,奶类,咖啡,气泡,苏打等等会随着关卡的推进逐步呈现。让你体验到真实的开饮品店过程。偷偷透露一句,这是开发者根据亲身经历改编的哦!做游戏之前先去开了三年奶茶店,然后才做出来这个让玩家都能尝尝开饮品店的酸甜苦辣的《杯杯倒满》。  支持2-4人联机合作,本地双人。当然了啦,多人模式也会有各自的“杯币”结算,不会给房主当黑心老板,让大家打白工的!快点喊上朋友们,一起来做奶茶吧~游戏特点: - -拟真的饮品店模拟经营,从开店的进货、备料到为顾客点单、制作、出杯 - -数百个不同种类的饮品制作过程,勾兑饮品、奶茶、咖啡、苏打水、水果茶等等 - -风格多样的饮品店,完全不同的店内布局,适当调整机械以应对各种需求的顾客  - -经营周期内,遭遇随机的代价和事件,抽取种类中随机的配方,每次都是截然不同的体验 - -购买角色装备和升级店铺设备,获得增强的效果,应对各种经营状态 - -开启顾客赠送的礼物,选择不同效果的卡片,获得强力的玩法加成,赚取更高营业额 - -各式挑战难度,打扫清洁,齐声呐喊“欢迎光临”等等带来有趣的沉浸式开店体验 - -解锁和扮演拥有独特能力的小动物,使用角色经营来提升职位,解锁更多技能 - -赚取的营业额,回家升级房屋购买各式各样的家具,提供更强的经营能力 - -可单人游玩、本地双人同屏、线上2~4人联机合作 - -根据玩家人数,游戏难度会动态调整。多人游戏需要分工合作,好好配合

朱啸虎表示,DeepSeek登顶美区App Store,一是技术理想主义者的胜利,二是行业技术迭代周期远快于资本支出的回报周期,三是给民营经济生长的缝隙。
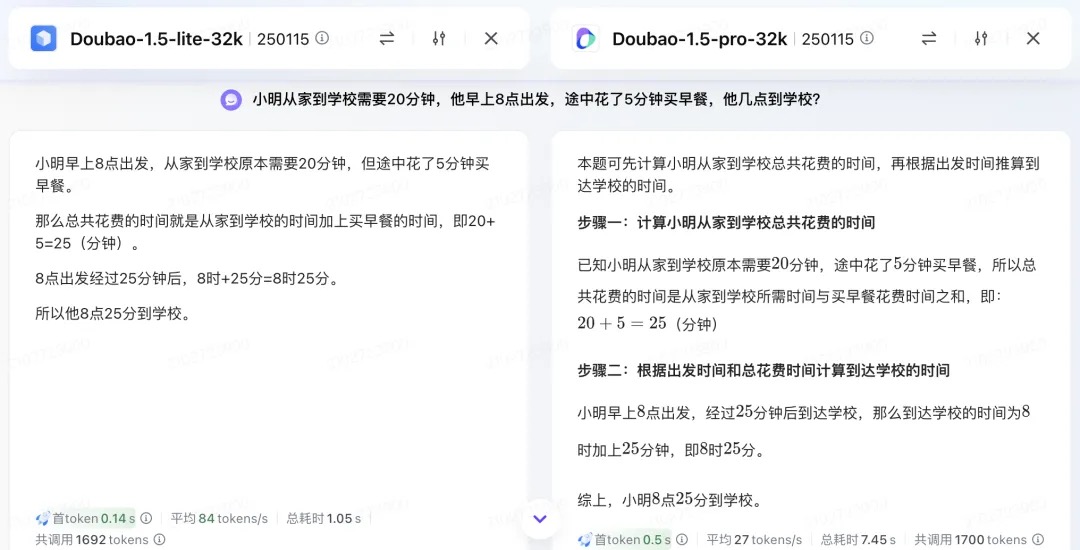
2025 开年,AI 领域有重回「卷模型」的架势,堪比两年前「百模大战」般热闹。短短一周内,先是 MiniMax 加入开源的队伍并表示坚定探索模型的上限;接着 DeepSeek、Kimi 接连更新推理模型;阶跃、混元在多模态上也有新动作。 创新是「密度」和「浓度」的产物,越来越多中国模型厂商继续探索模型边界、开放地交流技术进展,决定了 2025 年中国的基础模型势必会由「跟随者」逐渐转向「创新者」的姿态。 最新的例子是 1 月 22 日上线的豆包大模型 1.5。 通过模型架构和 AI Infra 层面的技术创新,豆包大模型 1.5 在性能与推理成本上再一次突破了平衡的极限,这也让它能在性能超过 GPT-4o、Claude 3.5 Sonnet 等业界一流模型的同时,模型调用价格不变。更重要的是,豆包大模型 1.5 在训练过程中,未使用任何其他模型生成的数据,这让豆包大模型 1.5 上线即引发热议。 在此之前,从一个大而复杂的预训练模型中蒸馏数据,来训练一个更小更高效的模型,是更普遍的做法。这也是很多模型能够迅速缩小与 OpenAI 模型能力上的差距的主要手段之一。 显然,豆包大模型选择了一条更难的路径。对此,行业人士称,像豆包大模型这样构建完全自主的数据生产体系,意味着模型可探索的天花板更高,字节跳动不用说也要无限探索 AGI 的边界。 拉远看,其实自 2024 年 5 月正式对外推出以来,豆包大模型便不断带来更强模型、一并保持价格竞争力和初始并发。目前,它已经成为国内使用量最大、应用场景最丰富的大模型,在火山引擎去年底公布的最新数据中,豆包大模型日均 tokens 使用量超过 4 万亿,火山引擎也因而成为大模型时代最积极的一朵 AI 云。 ## **01 ****不使用任何其他模型数据,****豆包大模型 1.5 怎么样?** 在这次豆包大模型 1.5 的升级发布中,豆包通用模型 pro、豆包通用模型 lite、豆包·视觉理解模型均有大幅增强,新发布的豆包·实时语音模型也在拟人化、低时延上有独特优势。目前,豆包大模型 1.5 已全面上线火山方舟。 我们也在火山方舟平台官网,第一时间体验了这几个新模型的实际能力。   在同时向 Doubao-1.5-lite 和 Doubao-1.5-pro 提出数学和逻辑问题时,豆包通用模型 lite 主打一个快且准、没有废话,也几乎不需要等待。所以在一般的简单场景下,你甚至会更喜欢简单直接的它。 这一点官方报告中也有提到,Doubao-1.5-lite 可以比肩 9 月份的 Doubao-pro-32k-0828 的模型效果,客户在众多场景中,可以直接用 lite 模型成本,获得过去 pro 模型的效果。 但在更精巧复杂的一些题目上,豆包通用模型 pro 就会展现出它更强大的推理能力,比如:  显然,Doubao-1.5-pro 模型综合能力显著增强,尤其它已经在一些场景里展现出了一定的复杂推理能力。在豆包大模型 1.5 的评测中,Doubao-1.5-pro 的综合得分也优于 GPT-4o、Claude 3.5 Sonnet 等业界一流模型,模型效果达到全球领先水平。 豆包·视觉理解模型,测试了几个看图提问题,基本上半秒到 1 秒就可以识别图像并做出回答。且大体上也是准确的。   火山引擎官方发布的评测案例,专门测试了豆包·视觉理解模型对不同尺寸、分辨率下图像的适应性,以及复杂指令遵循的能力。火山引擎表示,豆包·视觉理解模型在多模态数据合成、动态分辨率、多模态对齐、混合训练上进行了全面的技术升级,视觉推理、文字文档识别、细粒度信息理解、指令遵循方面的能力均得到了提升,并让模型的回复模式也变得更加精简、友好。 <iframe src="https://player.youku.com/embed/XNjQ2MDU5MzM2NA==" width="510" height="498" frameborder="0" allowfullscreen="allowfullscreen"></iframe> <iframe src="https://player.youku.com/embed/XNjQ2MDU5MzM2OA==" width="510" height="498" frameborder="0" allowfullscreen="allowfullscreen"></iframe> 最印象深刻的是豆包·实时语音模型,现在已经可以通过手机端豆包 App 来体验它的「端到端语音聊天」能力。 打开豆包 App 右上角「打电话」功能,你可以跟它悄悄说话、可以跟它讲方言让它模仿、跟你对唱流行歌曲、它也懂你的戏精体质,不需多言就可以陪你「角色扮演」,你会感觉跟你讲话的「豆包」是一个有灵魂通人性的小机灵,将豆包 App 升级至 7.2.0 版本即可解锁这些奇妙的新体验。 <iframe src="https://player.youku.com/embed/XNjQ2MDU5ODA0MA==" width="510" height="498" frameborder="0" allowfullscreen="allowfullscreen"></iframe> _依托豆包·实时语音大模型,用户在豆包 App 中跟它唱歌、说悄悄话、角色扮演等等,它都能秒懂并作出最恰当的回应。|视频来源:火山引擎_ 作为一款语音理解和生成一体化的模型,豆包·实时语音大模型在语音表现力、控制力、情绪承接方面的体验惊艳,并且对话中可随时打断、整个交互过程几乎感受不到时延。 从小红书上网友在豆包 App 实测的 AI 语音聊天功能的反馈来看,大家对这一模型的整体满意度还要高于 GPT-4o,哪怕天天用 GPT-4o、第一次切换到用豆包 App 的网友,也会对它的「拟人化」有很深刻的印象,因为豆包·实时语音大模型的语音语气自然度和情绪饱满度更高,也贴合中国用户实际需求。 体验了一番新模型,总体感觉被豆包大模型推着、在智能的边界上又向前迈了一步,丢给它实测的问题越多,你就更能感受到哪怕是非常微妙的进步,也会带给你解决问题后的满足感。同时,它也越来越懂我们的喜怒哀乐,让你忍不住想跟它多聊几句。尤其是在豆包 App 中,常常边写作业,边挂着「电话」,想起来问它一嘴,聊上几句,它始终就在那里陪伴你。 以豆包大模型家族中的最强代表——Doubao-1.5-pro 为例,豆包大模型团队首次披露了其中的技术创新点,给行业带来了「高效模型结构,但超低成本」的另一种思考。 这首先体现在模型架构和训练算法优化上,豆包大模型 1.5 采用大规模稀疏 MoE 架构,并通过训练-推理一体化设计,使得 Doubao-1.5-pro 仅用较小激活参数,即可等效 7 倍激活参数的 Dense 模型性能,远超业内 MoE 架构约 3 倍杠杆的常规效率。 值得注意的是,豆包大模型 1.5 在训练过程中,未使用任何其他模型生成的数据,而是构建了完全自主的数据生产体系,以标注团队与模型 self-play(自提升)技术相结合,高效优化数据质量,提升数据标注多样性和难度,确保数据来源的独立性和可靠性。团队介绍称,「坚持不走捷径」的扎实数据原则体现在后训练、微调、奖励模型、强化学习的各个阶段。 而在这之前,获取高质量数据更常见的方法是通过知识蒸馏技术,把高质量数据快速获取并转移到更小更高效的模型中。只是这样做也有局限,不少论文研究得出,过度蒸馏可能会导致同质化、降低模型多样性,并削弱它们稳健处理复杂或新任务的能力。换言之,蒸馏而来的「学生模型」无法超越「教师模型」,这对于做产品来说可以快速实现模型适配,但对探索 AGI 的上限来说显然是不合适的。 豆包大模型 1.5 发布后,豆包大模型团队在公众号发文称,依托字节在推荐、搜索和广告领域的 A/B Test 经验,他们研发了基于用户反馈的高效 Post-Training 全流程,基于豆包的大规模用户反馈,构建了从问题发现、数据挖掘、人机结合标注到快速迭代的闭环优化系统,实现大模型的数据飞轮。 今天,豆包 App 的 MAU 超过 7500 万,同时豆包大模型还通过火山引擎的大模型服务平台火山方舟提供给千行百业的企业用户,其去年底的日均 tokens 调用量超过 4 万亿,与去年 5 月相比增长了 33 倍。海量的真实数据,结合基于用户反馈的高效 Post-Training 全流程,让豆包大模型在过去一年里飞速进化,成为国内落地进展最快的大模型。 ### **02 ****大模型落地进展最快的一朵「云」** 去年都在找 AI 的超级应用,也在探索中逐渐形成共识,聊天机器人形态的 App,显然不是 AI 落地的唯一场景。字节跳动也把豆包大模型的能力外溢给千行百业,共同探索并加速 AI 在各个场景的渗透。 火山引擎作为承载这一使命的云与 AI 服务平台,在 2024 年成为大模型落地进展最快的 AI 基础设施。过去两年,它在更好的模型、更低的价格、更低门槛更易用的工具上持续发力,成为迭代最快、最贴近市场需求的基础设施。 这首先体现在 8 个月里多次迭代的豆包大模型家族上。 2024 年 5 月,包括豆包通用模型 pro 和 lite 版在内的 9 个模型正式推出;2024 年 9 月,发布豆包·视频生成模型;2024 年 12 月,豆包·视觉理解模型首次亮相;2025 年 1 月 22 日,豆包大模型 1.5 以及豆包·实时语音模型来了。 在贴合用户需求和使用场景上,豆包大模型家族一方面发布了不同尺寸、性能、推理能力的模型;另一方面,还基于字节跳动多年来的积累和优势场景,发布了语音、角色扮演等方面的专有场景模型。  _豆包大模型家族成员|来源:火山引擎_ 除了模型的全面、多样,火山方舟作为一站式大模型服务平台也在让大模型开发更友好、更专业、更高效上持续发力。 过去一年,火山方舟先后推出了 AI 搜推引擎、更灵活的批量处理方案、应用实验室、RAG 技术和上下文缓存技术等等多种能力,并在高并发算力保障、安全可信会话无痕方案等方面持续升级,有力支撑 AI 大模型从开发到落地应用的全生命周期,降低 AI 应用开发周期和门槛。 还有价格,豆包大模型从服务器集群到 AI Infra 层面的不断迭代,通过算法、软件、工程和硬件结合的方案实现成本的优化,使得豆包大模型在每次面向市场时都做到了同一时间里最低的价格,而且仍然能够获得可观的毛利。 随着火山方舟一站式大模型服务平台在模型效果、性能、最优推理成本、易使用这几方面不断提升,随之而来地,平台上客户调用豆包大模型的 tokens 使用量也在不断攀升。  _截止去年 12 月 18 日,豆包大模型的日均使用量达 4 万亿 tokens,与去年 5 月 15 日相比,翻了 33 倍。|图片来源:火山引擎_ 根据量子位统计的市场数据,2024 下半年国内大模型商用落地日均 tokens 消耗量翻了近 10 倍,从 1000 亿级规模到 10000 亿规模,只用了 6 个月,月复合增长率达到 45%。 其中,只有 1 家云厂商——火山引擎的商用 Tokens 日均消耗量的月均复合增长率超过 60%,近期日均 Tokens 市场份额占比更是超 50%,超过其他玩家份额总和。 增长如此迅猛背后,越来越多 AI 应用选择火山引擎,从 ToC 应用到垂直行业的客户,都通过火山引擎实现了 AI 落地。 此前,AI 内容互动平台——造梦次元创始人、CEO 沈洽金和 AI 图形图像处理软件——Fotor CTO 颜河向极客公园表示,模型选型就是两句大白话:哪个模型成本低就用哪个、哪个模型在场景里的效果好就用谁。 这个标准下,火山引擎成为 Fotor 多云部署、多模型调用的策略下,增长最快的一家供应商,「我们是全球部署,火山一定不是唯一的选择,但哪怕跟火山合作时间不长,其用量增速是有史以来最快的,是其他云厂商的大约十几倍增速」,颜河称。 具体到使用上,他们会在同一个场景里接不同的模型不断做 A/B Test,根据不同模型下的用户反馈指标(比如互动率),决定用哪个模型。 沈洽金举例称,在同一个场景、同一个时间、同一批用户的情况下,不同模型表现之间的差距甚至有 10 倍。但在做了大量的 A/B Test 之后也会发现,基本上性能更好的模型在整个场景里大部分时候都表现优秀,除非和专门做了场景定向调优的模型比。在他看来,这背后是也因为基础模型足够聪明,模型的泛化性当然也会更好。 这样的例子还有很多,在去年底火山引擎发布会上,火山引擎总裁谭也介绍过豆包大模型调用量的高速增长背后,市场的真实反馈与使用分布。 他举例称,在信息处理场景,3 个月内豆包大模型的调用量增长了 39 倍,帮助了企业更好地分析和处理内外部数据;在客服与销售场景,豆包大模型的调用量增长 16 倍,帮助了企业更好地服务客户、扩大销售;在硬件终端场景,豆包大模型的调用量增长了 13 倍,AI 工具增长 9 倍。 而随着模型能力变强、模态变多,也会解锁越来越多的场景。 金融、汽车、教育、互联网、智能终端等等垂直行业中的众多企业都在过去一年通过火山引擎实现了 AI 落地的大发展。 5 年前立项时定位为「你的下一朵云」的火山引擎,正在利用 AI 书写最积极的「超级进化论」,不到一年时间,成为越来越多 AI 实干家们的下一朵云。



政策层面,分布式光伏管理新规出炉;八部门联合发布2024版《绿色技术推广目录》;特朗普上台首日宣布美国退出巴黎协定;事件层面,中国“人造太阳”创造“亿度千秒”世界纪录;宁德时代、晶科能源、晶澳科技斩获中东光储大单;2024年中国风电、光伏装机增速放缓。
 史克威尔·艾尼克斯(Square Enix)咖啡餐厅(简称SE咖啡)东京店宣布将于2025年3月31日闭店,在闭店前的最后一期联动主题已正式定为《尼尔》系列。  本次“人类最后的SE咖啡”联动自2月1日开始,持续到3月31日结束(分上下两期),将推出共计十二款餐品及十二款饮品,同期还将上架多款餐厅先行贩卖的周边等。  (随餐赠送的餐垫)  (随饮料赠送的杯垫) SE咖啡官网发布的闭店公告中这样说道: <blockquote>感谢您到访史克威尔艾尼克斯咖啡馆。 很抱歉这是一则很突然的通知,我们决定于2025年3月31日星期一关闭位于东京秋叶原的Square Enix Cafe Tokyo。 自2016年10月1日星期六开业以来,经过8年零6个月的时间变迁,它一直作为游戏宣传的基地,并让玩家以不同于游戏玩法的方式享受Square Enix的IP。作为享受美食的地方,前来光顾的顾客也络绎不绝。无法用语言来表达我们对大家一直以来的惠顾的谢意。 关于咖啡馆选址的未来,我们计划在装修期过后,让迄今为止一直管理该咖啡馆的Taito为史克威尔艾尼克斯官方商品设立一个空间。 关于咖啡厅等重新开放的日期,请等待正式公告。 虽然所剩时间不多,但我们全体员工依然期待着您的光临。</blockquote>

据 DeepSeek 首席执行官称,中国人工智能实验室 DeepSeek 可以使用数万个 NVIDIA H100 AI GPU 进行训练。DeepSeek R1 是世界上最先进的 AI 模型之一,可与 OpenAI 的新 o1 和 Meta 的 Llama AI 模型相媲美。 在接受 CNBC 的最新采访时,Scale AI 创始人兼首席执行官 Alexander Wang 表示,DeepSeek R1 在其公司最具挑战性的 AI 测试中达到或击败了所有表现最佳的 AI 模型。 [](https://static.cnbetacdn.com/article/2025/0124/ea733f82fddcb93.webp) CNBC 的 Andrew Ross Sorkin 采访了王,谈到了 DeepSeek 的新 AI 测试,名为人类的最后考试,其中最难的问题是由数学、物理、生物、化学教授提出的,与最新研究相关。 在测试了所有最新的 AI 模型后,王的团队发现 DeepSeek 的新模型实际上是表现最好的,或者大致与美国最好的模型相当,而美国最好的模型是 o1。 当被问及中美之间的人工智能竞争时,王教授补充道:长期以来,美国一直处于领先地位。但他指出,DeepSeek 的新模型确实试图改变这一现状,他认为中国实验室在圣诞节发布惊天动地的模型具有象征意义,因为大家都在庆祝圣诞节。 [](https://static.cnbetacdn.com/article/2023/0809/998fa2a63ae8c07.webp) DeepSeek 使用 NVIDIA 的 Hopper AI 架构和 H100 和 H200 AI GPU 来训练他们的 AI 模型,而拜登政府实施了限制措施,以阻止强大的 AI GPU 进入中国。但将先进的 AI 芯片引入中国似乎并不那么困难,王告诉 CNBC:现实是肯定的,也是否定的。你知道中国实验室拥有的 H100 比人们想象的要多。 王先生表示,据他了解,DeepSeek 拥有大约五万个 H100 ,并且他们不能谈论这个,显然因为这违反了美国实施的出口管制,并补充说他们拥有的芯片比其他人预期的要多。 未来,对于中国获得先进的人工智能芯片,王先生表示:但从长远来看,它们也将受到我们现有的芯片管制和出口管制的限制。 研究中国创新的悉尼科技大学副教授 Marina Zhang 表示:与许多严重依赖先进硬件的中国人工智能公司不同,DeepSeek 专注于最大限度地优化软件驱动的资源。DeepSeek 采用开源方法,汇集集体专业知识并促进协作创新。这种方法不仅可以缓解资源限制,还可以加速尖端技术的开发,使 DeepSeek 从更孤立的竞争对手中脱颖而出。 [查看评论](https://m.cnbeta.com.tw/comment/1474286.htm)

**“ 一件 90 鸭绒羽绒服**( 绒子含量 90% )**正常生产,光成本都不止两百。那些只卖两百的羽绒服,百分之七八十应该都是质量不过关的,经不起检测的。 ”**某羽绒服厂商业务经理李旭( 化名 )这样跟知危说道。 [](https://static.cnbetacdn.com/article/2023/1128/3368e227e7fa990.png) 尽管劣质羽绒服现象年年都有,但今年似乎尤为严重。**一边是假羽绒服系列事件不断登顶热搜,另一边是今年羽绒服普遍价格上涨,**某些店铺甚至平均提价 500 元。 为了探究羽绒服又贵又造假的原因,知危找到羽绒服产业链上下游数名从业人员,试图去理清这背后的门道。 首先,据李旭介绍,**业内一般把羽绒服分两种,一种称为品牌货,一种称为市场货。** 两者的区别在很多方面,比如品牌货基本是都是做订货的,品牌方会提前一到两个季度就下单预订,甚至还会自己提供羽绒之类的原料交给工厂,在验收方面品牌货也会有一套标准,而市场货则是厂家到季节自行按照款式生产,然后卖给批发市场,或者某些电商直播间。 在成本上两者也有区别,**品牌货的人工成本会高一些,一件一百五到两百五,市场货的话,一件人工成本在八十到一百之间。** 当然,最大的区别肯定在于定价。 “ 现在基本上品牌都是以倍率定价的,好一点的**品牌在一线城市大商场卖的价格都是成本价的 8-10 倍,**比如我供货价 500 块,它要定 8 倍的售价,就是 4000 块,而在**二线卖得比较多一点的品牌,那也得卖 4-5 倍,**就是 2000 块以上了。我们线上也在供货,**线上基本上只卖到 2-3 倍,**短款最终售价在 500 多,正常长款的话要在 800 以上。 ” 李旭这样说道。 羽绒服的高倍率定价模式,主要跟产品特性有关,它毕竟是强季节产品,**一年只卖这一季,但品牌们的人力成本、工厂的设备成本、仓储成本等都是贯穿全年的。** 高倍率定价之下,成本的波动会造成羽绒服剧烈的终端售价波动,那么,羽绒服的成本包含哪些变量呢? 李旭告诉我们,羽绒服的出厂成本,一般包含人工成本、羽绒成本、面料成本、厂家的物流、设备、税费等。 他给我们算了一笔账:一件最普通款式的羽绒服,包含人工、设备的加工费有 80-100 块,面料一般是在一米 10-30 块之间,加上拉链等其他物料成本要 40-50 块。羽绒成本方面,**今年 90 鸭绒九月份最高时候涨到 55 万一吨了**( 现在回落到 46 万 )**比去年同期贵了 50%** ,一件短款羽绒服最少得填充 80 克,也就是 40 多块钱的羽绒成本,最后算下来整件出厂成本在 200 元左右。 **羽绒在整件成衣的成本里看起来占比并不多,但它几乎是唯一的变量,**刚才我们提到今年 90 鸭绒九月份的价格比去年同期贵了 50% ,这正是很多工厂开始接单子做羽绒服的时候。这个涨幅就意味着**一件充绒 80 克的短款羽绒服在成本端比去年贵了将近 20 块,放大到一线品牌货的售价上就要贵近 200 元。** 这就更别说长款羽绒服了,**长款羽绒服的充绒量基本要在 250-300 克,成本端要比去年贵 60-80 块,反映到一线品牌货的终端售价就要贵 500-800 元,**所以你会看到今年品牌羽绒服的挂牌价都蹭蹭涨,去年卖 2000 元的,今年卖 2500 元的,去年卖 2500 元的今年卖 3000 甚至更高。 涨价叠加了今年消费者消费意愿不高的因素,羽绒服厂家就很难受了,做品牌货的工厂还好点,只要做代工就能赚钱,而做市场货的厂家很多就不得不做歪心思掺假了。 李旭表示**热搜上提到的那种 “ 假羽绒服 ” ,基本都是市场货,** “ 如果是品牌货,它是会送检的,拿件整的好衣服过去,进行破衣检验。而一般像低价羽绒服则不会做送检的。 ” 总的来说就是,羽绒成本的上涨,让高端羽绒服变得更贵了,而低端羽绒服中的一部分厂商为了维持价格竞争力开始造假。 **那么,羽绒的价格,为什么会如此暴涨?** **[](https://static.cnbetacdn.com/article/2023/1219/e3394ff2b5487e1.jpg)** 这是叠加多重因素的供需关系导致的,**要从 2018 年开始说起。** 知危咨询了中国畜牧业协会水禽分会人员,他表示, “ 2018 年的非洲猪瘟,让猪肉供应量变少、价格变高,人们就会把鸭肉作为替代品,**鸭肉因短时间需求量激增而涨价。涨价后,养殖户为了更多的利润开始扩产,**到 2019 年,鸭肉供应就突然多了很多,**但随着猪肉价格近年的不断下跌,鸭肉开始产能过剩了。**产能过剩后鸭肉的价格就开始下跌,**养殖端因利润微薄而减少了养殖量。 ” ** 养殖量的减少,造成了出栏量的减少,使得羽绒的产量减少,而好巧不巧,羽绒的需求量突然暴增了。 某羽绒供应商经理林东( 化名 )告诉知危, “ 2023 年双十一,国内遇到了强降温,**消费者购买羽绒服欲望就非常强,**大家都在买,刚好那个时候鸭子的价格都在下跌,**养殖户养殖的意愿不强,**鸭绒的供给变少,导致羽绒的供需非常不平衡,最终价格上涨。 ” 看到这里,我们发现,原来网上流传的猪肉降价导致羽绒服变贵,还真不是一句玩笑。但,这里面有一个漏洞,**虽然鸭肉便宜了,但羽绒价格涨了,养殖户们不会因为羽绒价格的暴涨而去多养鸭子吗?** 答案是不会,因为尽管羽绒服供不应求,但对养殖户来说,**羽绒占整鸭的利润并不高,只有 30% 左右,所以为了羽绒而多养鸭,最后还是不赚钱。** 这里又产生了一个新的问题:每年有那么多旧衣服被淘汰,**羽绒价格现在这么高,为什么没人做羽绒回收再利用?** 林东告诉我们,这在业内叫 **“ 复用绒 ” **,之前我国向国外出口了很多旧羽绒被、羽绒服,这些地方会把绒给拆开再卖回来赚钱。一些工厂为了节省成本,就会掺入这些回收的绒。 但,复用绒是很容易出问题的,林东解释道,**“ 复用绒最大的问题是 APEO ( 一种表面活性剂 )会超标,**因为 2016 年版的国标对于 APEO 没有要求,当时大家为了把绒洗得干净,会使用非常强力的洗涤剂,而这种洗涤剂里边含有比较多的 APEO ,这种物质超标会对人体有害, 2021 版国标已经加上 APEO 含量要求了。 ” 除了复用绒,林东还告诉我们一种叫 “ 胶水绒 ” 的技术,就是可以把 “ 绒丝 ” 粘在 “ 绒朵 ” 上。绒朵主要来自鸭腹部、背部和翅膀根部,是保暖的关键因素,像前文提到的 90 绒,就是指一公斤羽绒里面, 90% 都是绒朵,而 “ 绒丝 ” 是羽毛末端的单丝,保暖性差,还容易钻毛。把它们用胶水粘在一起,就可以以次充好了。 林东告诉我们,这种手法消费者在买羽绒、甚至检测的时候都不会出现什么问题,但是胶水绒充到衣服里,消费者买了之后只要过水就会发现羽绒服的蓬松度大幅下降,衣服变得很干、蓬松不起来了,就也不保暖不了。 事实上,据林东所说,厂家如果铁了心造假,消费者能发现的几率很低。所以对于羽绒服,林东建议尽量只去买品牌货,并且最好避开一些看起来很熟悉但其实只是做品牌授权的品牌。 至于价格,在供需关系面前,暂时是无解的,想要价格低的买到好羽绒服,要等到下一个周期了。 [查看评论](https://m.cnbeta.com.tw/comment/1474284.htm)

近一周,来自中国的深度求索(DeepSeek)全球爆红,尤其让美国硅谷极为震撼和恐慌。**其最新发布的R1大模型不仅在性能上比肩甚至超越了OpenAI的o1,并完全开源,且以对手3%的超低成本实现了这一突破。** [](https://static.cnbetacdn.com/article/2025/0126/b5eec66a6c80e1a.jpg) 近日,一篇在匿名平台teamblind上发布的文章遭疯传,**有一位自称是Meta员工称公司内部因DeepSeek模型而进入恐慌模式,并提到DeepSeek-V3在基准测试中,已经让(Meta推出的)Llama 4相形见绌,而更让人难堪的是一家“仅用550万美元训练预算的中国公司”就做到这一点。** 该文称,Meta工程师正争分夺秒分析DeepSeek,试图复制其中的一切可能技术,而DeepSeek-R1的出现,也让情况更加严峻。 另据The Information爆料,**Meta生成AI小组和基础设施团队的经理和工程师已开设了四个作战室来学习DeepSeek的工作原理。** 其中两个动员起来的小组正在试图了解High-Flyer如何降低训练和运行DeepSeek的成本。第三个Meta研究小组正在试图弄清楚High-Flyer可能使用哪些数据来训练其模型。第四作战室正在考虑基于DeepSeek模型属性重构Meta模型的新技术。 AI科技初创公司Scale AI创始人亚历山大·王(Alexandr Wang)接受电视媒体公开采访时表示,中国人工智能公司DeepSeek的AI大模型性能大致与美国最好的模型相当。**过去十年来,美国可能一直在人工智能竞赛中领先于中国,但DeepSeek的AI大模型发布可能会“改变一切”。** Meta创始人兼CEO扎克伯格表示,**DeepSeek非常先进,并认为中美之间的AI差距非常小**。 扎克伯格还表示,中国正在全力冲刺,如果将来有一个开源模型能被全世界广泛使用,我们希望它是一个美国模型。 [查看评论](https://m.cnbeta.com.tw/comment/1474282.htm)
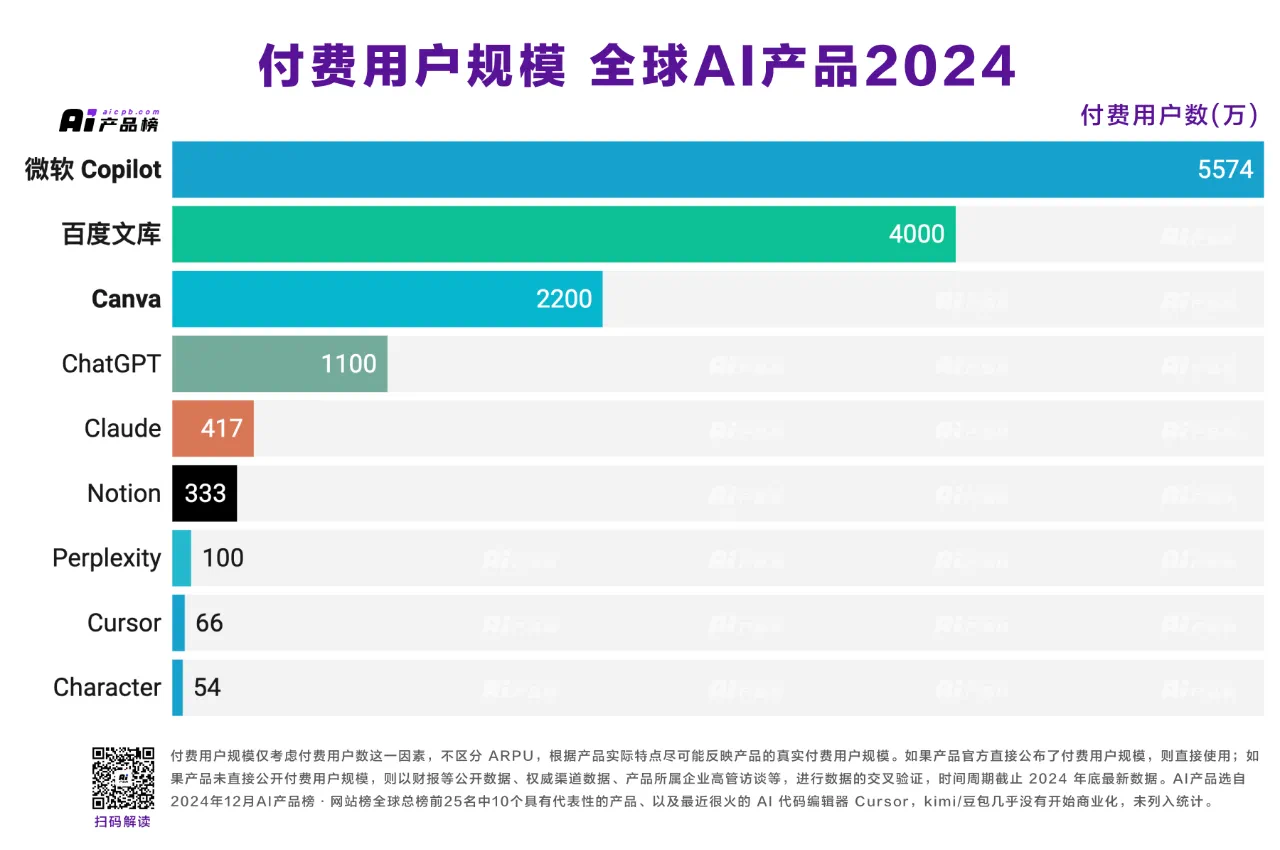
AI产品榜官方发布“全球AI产品2024付费用户规模”榜单。数据显示,**百度文库付费用户达4000万,位列国内第一、全球第二,仅次于微软Copilot。由此可见,百度文库已成为唯一商业化的中国AI应用。** AI产品榜指出,付费用户才是真用户,用户用付费行为跨越了“感兴趣”和“真正需要”之间的鸿沟。经大模型重构下,百度文库进化为“一站式AI内容获取和创作平台”,推出了智能PPT、智能研报、AI全网搜、AI有声画本、智能漫画、智能海报等上百项AI能力。 百度文库联合百度网盘推出的内容操作系统“自由画布”,也**在近日全面公测,成为思想碰撞与灵感激发的AI领先产品。** 据媒体报道,百度文库AI MAU已突破9000万,AI DAU年同比增长230%。同时,百度文库总付费率年同比增长60%,这一增长几乎完全由AI功能带动。 [](//img1.mydrivers.com/img/20250127/154b064bc5cf4e7e99203b6751b79a15.png) [查看评论](https://m.cnbeta.com.tw/comment/1474280.htm)

RTX 50系列即将上市开卖,RTX 5090/5090D的评测已经出炉,但奇怪的是,这次全球媒体评测的样卡,没有一块和FE公版价格相同的标准版,也就是俗称的“丐版”。大家知道,NVIDIA显卡的非公版有两种,一是和官方MSPR建议零售价完全相同的标准版,二是价格更高的豪华版/超频版,后者往往晚一天解禁,但基本都是同步上市。 **这一次,无论是国外媒体拿到的RTX 5090,还是国内媒体拿到的RTX 5090D,除了少数公版之外,全都是价格更贵的非MSPR版本,无一例外(当然5090D没有公版)。** 对此,有一种说法是,**NVIDIA留给AIC品牌厂商做RTX 5090/D的利润实在是太薄了,导致再做MSPR标准版简直就等于做慈善,所以干脆就都不玩了。**  NVIDIA的强势有目共睹,对于AIC厂商的控制也是十分严格,甚至包装盒的设计样式都统一标准,任何人不得擅自僭越。 同时,NVIDIA一直是将GPU芯片与显存芯片打包卖给AIC厂商,而这正是此次AIC厂商做RTX 50系列利润微薄的关键原因,因为**新的GDDR7显存实在太贵了,NVIDIA将这一成本几乎全都转嫁给了AIC!** 对此有人想起了**EVGA当初毅然退出显卡市场、放弃核心业务,根本原因就是觉得后者几乎将利润全部拿走了,为此不惜与NVIDIA公然闹翻。**  目前,厂商均未公布RTX 5090/5090D显卡的具体价格,但是根据曝料,部分RTX 5090型号在海外的售价如下: 华硕ASTRAL:2800美元 微星SUPRIM LIQUID SOC:2500美元 微星SUPRIM SOC:2400美元 同德GAMEROCK:2200美元 **再考虑到RTX 50初期的供货极度紧缺,如果你想原价买到一块RTX 5090/5090D,想都不要想了。** 另外,NVIDIA FE公版虽然不会大量供应,但也和AIC存在直接竞争关系,毕竟有原厂信仰加持。 RTX 50系列则更加激进,国外媒体收到的RTX 5090 FE公版,芯片上赫然印着**“Press Build”(媒体专用)**的字样。  送测的非公版RTX 5090,则无一例外都没有以往常见的“Qual Sample”(质量样品)字样,这意味着他们送出的都是量产版本。 换言之,**NVIDIA根本没有给AIC试产样品的时间,只是自己抢跑了一段时间。**    [查看评论](https://m.cnbeta.com.tw/comment/1474278.htm)