所有文章
 钛媒体 · 杜志强
钛媒体 · 杜志强
 人人都是产品经理 · 琢磨事
人人都是产品经理 · 琢磨事
<blockquote><p>随着人工智能技术的飞速发展,人们对AI的期待和幻想似乎已经超越了其实际能力。本文深入探讨了人类对AI的过度幻想及其潜在危害,供大家参考。</p> </blockquote>  AI给人的幻觉是个技术问题,随着技术进步会在确定的节奏里收敛;人对AI的幻觉却是个认知问题,存续时间可能远比我们想的长。 如果要比较那个害处更大,我想人对AI的幻觉所带来的坏处要远大于AI给人产生的。 我们很多对AI的基础认识是错的! 错误的认识带来错误的预期,错误的预期就带来错误的行为,典型的错误认识包括: - 我们真的可以认为学会和AI说话就会变的更安全么? - 我们真的可以以为学会提示词技巧能写和大模型交互的程序就是可以延长编程生涯么? - 我们真的可以认为部署几台服务器,公司里面每个人都用上DeepSeek就算拥抱AI了么? 这些基本都是幻觉。 从这个角度看,下面的《无人公司》其实是本去幻觉的书,基于案例和底层逻辑展露一个可能的、但残酷的AI世界。 ## 智能优先的世界 我们拿卖T恤的过程来举例,忽略某些细节后这个活有这么几个关键步骤: - 得有人盯市场,为了判断到底什么样的设计更可能卖出去某些团队要做很多分析,这个分析就是收集数据、建立模型的过程。 - 分析的结果最终就是新的设计,比如哪吒火了,那赶紧做哪吒相关的。 - 这个设计要扔给工厂,这时候一组工人按照既有生产流程把T恤做出来。 - 做出来后,要放在N种分发渠道上开卖。这时候又是另一组人,这组要关注流量等等。 - 所有事情都完成后需要整个复盘看哪里做的好,哪里做的不好。 在没有AI的年月里,上面所有的工作包括:收集数据、新设计、生产制造、销售完全由人驱动,为了避免混乱,就需要定义流程以及中间结果的交付标准,明确谁要交付什么,好在出错的时候看是谁的问题。 运转过程中也必然会滋生人与人之间的摩擦,工序上下游互相大骂的情形正常是很难避免的。为了万众一心就还要设计汇报机制、激励机制(人事、财务等)。 但智能优先的世界完全不是这样。 AI可以自己收集和T恤相关的数据并进行设计,然后转给AI完成生产,再转给AI完成宣传的图片等上线和销售。OpenAI O1,DeepSeek R1这样的模型日渐也可以承担反省总结的工作。 这时候公司就会变成一个AI智能体对AI智能体的系统,最多在关键环节比如设计图案是不是反动这种点上做些检查。 请注意现在我们有了完全不一样的两种选择: **选择1:保持原来的工作过程,每个人都开始使用AI来提升效率。** 这是渐进式的。 **选择2:全部导入AI,让人只在必须环节辅助下。** 这是颠覆式的。 前者靠人类智能进行驱动,靠工具进行辅助;后者靠AI的智能进行驱动,靠人类进行辅助。 这是完全不一样的两套体系。 即使不做详细对比,只要足够理智的人也会发现,AI越发展后面这样的体系优势越大。 现在前者谈的比较多,后者则太少。《无人公司》关注选择2。下场直播会展开说说。 ## 人类对AI的幻觉 假如选择2这种主要靠AI驱动的商业智能体覆盖N个领域,那显然现在许多努力其实都错误认识下的幻觉。 显然的在选择2下,业务单元是一块块崩的稀碎然后基于AI重建,和在原来的基础上精雕细琢的选择1完全是不一样的路子。 在这个背景下觉得学会和AI对话等就是跟上AI潮流是幻觉。在一个AI对AI为主的系统里根本就不需要人和AI做很多对话。 觉得把提示词写好是AI核心技能是幻觉。在那个体系里,AI会和AI自己改善提示词,让工作越做越好。 更进一步,觉得公司部署几台服务器,能和DeepSeek对话就能产生更高的生产力这也是幻觉。就这很像买了炮弹但没有炮,却认为自己具有了极大的火力。 这些幻觉都源自我们思维惯性,我们潜意识的认为现在的模式会延续,所以想各种办法改善当前模式的各种环节。于是花很多时间琢磨怎么把工具嵌入进来提高效率。但显然蒸汽机不是用来提供更好镰刀的。 电池也可以用来改进油车的里程,但很难改善出纯粹的电动车。这需要全新的设计和原则。 去除人类对AI的幻觉后才可能有真有意义的人类新定位。 ## 前奏的鼓已经震天的在响 有的同学可能觉得这是夸大其词,不过又是一次狼来了而已。 但这次看起来真的不是,各种领域关于此的实践风起云涌,从未断绝,只不过被关注的远远不够。下面列举一些: 前面武汉萝卜快跑其实就是这个模式,现在因为大家的反对声量小了很多,但这意味着它不会发生了么? 在米国Waymo投入车量的数目与日俱增,当前大概是接近1000台,随后特斯拉马上要进入这个名为Robotaxi的市场。 Robotaxi就是一套系统代表公司管理N台配备了自动驾驶能力的汽车对外提供出行服务。只在必要环节嵌入人的角色。实际上在关键环节也没法嵌入,一旦嵌入流转效率就差,这套系统可能就会亏损。 大概是受Robotaxi启发,有人也在把这套思路移植到采矿车上,所以就还有一帮人在尝试怎么构建一套无人机、采矿车的全自动系统,而不是单纯的卖车。 纯粹数字世界中的例子就更多。 老说的量化高频交易(Deepseek母公司幻方量化就是干这个的)是这样的。这种系统就和AlphaGo一样,你没办法塞入人的环节百分百算法驱动。 这里面最经典的系统正是大家每天都用的抖音,抖音显然是个全算法驱动的系统,假如抖音不再升级,那员工全部放假半个月估计问题不大。不这么做也不行,没有任何其它方法同时管理几千万主播和几亿的用户。在这个系统里面主播、算法、用户的匹配完全由算法进行驱动,而抖音的员工起的是辅助这套算法的作用。 这类系统中设想上最夸张的是马斯克和他最近爆出来的unboxed工厂(还未实现)。如果真实现了,那等于把工厂改造成原料进,汽车出的模式。这东西要做出来会石破天惊的,将对制造业产生根本性影响。 相比于互联网那个时代,现在这个时间点最大的变化是这种模式能覆盖的领域更多,成本更低了。过去江湖流传做这么套系统2亿美金起,现在如果领域选的小,几十万也是可以的。 所以是这模式大普及的前夜。 过去要做个聚合老师教英语的平台(VIPKID)要多少钱,往后呢? ## 看到现实后才有真定位 这类模式有极其残酷的一面,比如:萝卜快跑的模式如果起来,不管车开的多好,人也没用,尽管你可能学开车的同时掌握了N种AI工具。 类似的unboxed那种工厂,不管善用多少AI工具,在主流程上也不需要你。目标是5s一辆车的系统,人加进去就只能拖慢效能。 假设上面说的会发生显然比假设它不会发生要靠谱些。 那这时候人的位置到底在哪里呢? 很少一部分会保持原来的分工协作模式,他们分工合作负责推动现实中的科技发展,比如会有人继续研发AI,会有人研究芯片怎么从7nm到2nm,会有人研究量子计算机等等。 但我们要注意到,真正从事AI研究的人已经逐渐集中到极少的几所学校(5所),甚至都不是全部985院校。 更多的人必须自己是一个业务单元。每个业务单元需要一个AI驱动的无人公司。 具体来说就是:人(股东和战略设定)+一套《无人公司》系统能够完成赚钱的目标。 当前更贴近这个形态的其实是主播,主播只对平台有依赖,但基本是个独立经营的个体。 在基于AI的《无人公司》里说探讨的系统的加持下,能够独立出来的也必然不止是主播。这时候你要关注的并不是怎么写提示词,那个网红是因为AI技术好变成网红的呢! ## 小结 在AI大模型出来之前,我就一直关注这种算法驱动型的组织模式,也正因此更直接的体会到它在AI大模型后的加速趋势。(参见过去琢磨事的各种文章,包括智能原生等) 同时我也认识到这种体感和大量现行关于AI的观点是拧的,因此就把自己收集的案例、实践、技术脉络梳理出来,最终也就变成了《无人公司》。 本文由人人都是产品经理作者【琢磨事】,微信公众号:【琢磨事】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。

简介:HMOS世界是基于开发者技术演进的大型代码工程的最佳实践,本次交流主要介绍HMOS世界开发过程中撰写的技术文章,内容涵盖HMOS世界消息推送,华为账号登录,高端精致和简单易用。  视频链接:[<u>https://developer.huawei.com/consumer/cn/training/course/live/C101745215667481034</u><u>?ha_source=rrdscpjl&ha_sourceId=89000499</u>](https://developer.huawei.com/consumer/cn/training/course/live/C101745215667481034?ha_source=rrdscpjl&ha_sourceId=89000499) 标签:鸿蒙课程、中级课程、鸿蒙生态、HMOS世界、HMOS世界消息推送、华为账号登录 课程关键词:鸿蒙,鸿蒙生态,鸿蒙学习,鸿蒙生态课堂,鸿蒙Next ,鸿蒙5.0,鸿蒙课程,鸿蒙实战,鸿蒙开发,鸿蒙实践,鸿蒙实训,鸿蒙学习,鸿蒙资料,Harmony,HarmonyOS,HarmonyOS生态,HarmonyOS学习,HarmonyOS生态课堂,HarmonyOS Next,HarmonyOS 5.0,HarmonyOS课程,HarmonyOS实战,HarmonyOS开发,HarmonyOS实践,HarmonyOS实训,HarmonyOS学习,HarmonyOS资料
 cnBeta全文版
cnBeta全文版
华为在上周开启了华为Mate XT非凡大师的HarmonyOS 5花粉Beta版尝鲜招募。昨晚,Mate XT的首个花粉Beta版已经正式推送,版本号为5.0.0.160SP5,采用全新系统架构,带来智能、流畅、安全、便捷的全场景智能体验。   官方介绍,该版本目前开始推送给花粉Beta版尝鲜报名入选成功的首批用户,首批以外的用户会依据版本进度逐步分批审核,并为报名界面显示“审核已通过”的用户推送版本。 升级注意事项: 1、鸿蒙生态正逐步完善,在升级前,请您务必通过手机克隆、华为手机助手、云备份等功能做好设备数据备份,QQ、微信等三方软件建议单独迁移备份,并确认备份内容完整有效;如您暂未完成数据备份,您也可以使用全新云空间临时备份功能进行重要数据备份。全新云空间将提供不限空间的临时备份功能,数据可保存30天。在HarmonyOS 5升级期间(2025年6月30日前),备份记录在原有可保存30天的基础上再增加30天,共计60天。 2、因版本限制,请各位花粉先升级到4.2.0.175SP1版本,否则收不到版本推送。 3、HarmonyOS 5新版本尝鲜期间,请您开启用户体验改进计划开关(路径:设置>系统>用户体验改进计划),便于工程师进行系统和应用分析、故障诊断等,持续提升版本质量。 4、升级后,为提升使用体验,系统会在后台进行一系列优化动作,优化过程中,设备可能出现轻微发热、耗电量增加等情况,此为正常现象。设备正常使用2到3天后可自行恢复,请您放心使用。 5、本次更新需预留30%以上的剩余内部存储空间,安装包在更新后会自动删除,不占用存储空间。 [查看评论](https://m.cnbeta.com.tw/comment/1495816.htm)

对于那些坚定看好格力的人,并且用真金白银支持的,公司董事长董明珠依然是大方对待。现在,格力电器发布了2024年年度报告及2025年第一季度报告。报告显示,2025年第一季度,格力电器实现营业收入415.07亿元,同比增长14.14%;归属于上市公司股东的净利润达到59.04亿元,同比增长26.29%。 在2024年全年,格力电器实现营业收入1891.64亿元,同比下降7.26%;但归属于上市公司股东的净利润为321.85亿元,同比增长10.91%。此外,2024年基本每股收益为5.83元,同比增长11.69%。截至2024年末,格力电器总资产为3680.32亿元。 **在利润分配方面,格力电器董事会审议通过了利润分配预案。预案显示,公司拟以约55.85亿股享有利润分配权的股本总额为基数,向全体股东每10股派发现金红利20元(含税),不送红股,也不以公积金转增股本。** 之前董明珠曾回应与小米公司董事长雷军赌约,她表示,第一个5年雷军输了,至于第二个五年没有人跟他赌,成功不成功有各自的逻辑。“ **“我有股民利益最大化。那你雷军(小米公司董事长)跟我比,你给股民分了多少钱,拿了股民那么多钱用完了,钱到哪去了?股民回报是什么?”**  [查看评论](https://m.cnbeta.com.tw/comment/1495814.htm)

对于苹果公司要将所有美国iPhone机型改由印度生产的传闻,彭博社知名记者马克·古尔曼(Mark Gurman)在当地时间周日发文称,“几乎可以肯定的是”,苹果在2027年前无法在印度生产所有面向美国市场的iPhone。  苹果iPhone 16 Pro 古尔曼称,在特朗普加征关税后,苹果立即采取行动,优先在印度生产面向美国市场的iPhone。目前,苹果在印度的生产能力足以满足大约三分之一的美国年需求。印度即将兴建的工厂将有助于苹果实现剩余的产能需求,其中包括一家旨在成为全球第二大iPhone生产基地的工厂。 **他表示,苹果的目标是在2027年前将大部分美国iPhone改在印度生产。**然而,虽然古尔曼预计苹果能实现这个目标,但是它并非板上钉钉。未来的关税政策如何变化,谁也无法预测,更不用说18个月后的情况了。 而且,即便苹果能够将大部分面向美国市场的iPhone生产转移到印度,也几乎可以确定印度产能无法覆盖所有机型。**苹果正在为iPhone的20周年纪念版开发两款重要的新型号****,其中包括首款折叠屏手机和一款更加注重玻璃材质的Pro型号。**至少初期阶段,苹果在中国以外地方生产它们的可能性微乎其微。 尽管苹果在印度生产的iPhone质量已经达到了与中国相当的水平,但20周年纪念版的iPhone极为复杂。这些新型号将需要新的零部件和生产技术,这使得苹果在中国以外的地方生产这些设备存在很大不确定性。某个时候或许能做到,但肯定不可能在2027年之前实现。别忘了,苹果从未在中国以外的地方首先生产过一款重大新品设计。 [查看评论](https://m.cnbeta.com.tw/comment/1495812.htm)

自美国总统特朗普上任以来,他激进且反复无常的关税政策扰乱了全球贸易秩序,令美国的经济前景愈发黯淡。随着美国公众对他的经济议程越来越焦虑,特朗普周日表示,他的全面关税将有助于其降低年收入低于20万美元的美国人的所得税。 [](https://n.sinaimg.cn/spider20250424/341/w1242h699/20250424/d65b-01d033b5dd601fac96451ddddad0db1c.jpg) “当关税发挥作用时,许多人的所得税将会大幅降低,甚至可能完全取消。重点将放在年收入低于20万美元的人身上。” 特朗普周日在其自创的社媒平台Truth Social写道。 特朗普此前就曾表示,关税收入可以取代所得税。 “我们将赚很多钱,我们将通过关税收入为这个国家的人民减税,”特朗普在从新泽西州的高尔夫俱乐部返回华盛顿的途中表示。“我们需要一段时间才能做到这一点。” 特朗普希望延长其2017年第一任总统任期内批准的减税措施,其中许多措施将于2025年底到期。 他还提议扩大税收减免,包括对小费、社会保障福利免征所得税,同时将企业税率从21%削减至15%。 不过,经济学家普遍认为特朗普的这一计划(用关税收入取代所得税)难以实现。税务基金会首席经济学家埃丽卡·约克(Erica York)近日就指出,要弥补所得税约2万亿美元的收入,以2023年为例,关税税率需高达69.9%,且前提是进口量不变,这几乎不可能。 在特朗普发出上述言论之际,他的民调支持率大幅下滑。根据CBS新闻周日公布的一项民调,目前有69%的美国人认为特朗普政府没有足够关注降低物价。对特朗普经济处理方式的认可度从3月初的51%跌至42%。 特朗普的关税政策扰乱了市场,点燃了美国人对物价上涨的担忧,并引发了一连串的经济衰退警告。与此同时,投资者对美元资产的信心似乎也在逐渐流失。 美国财长贝森特在周日的一档采访中对此进行了回应。 当被问及是否对美国遭遇股债双杀、投资者似乎对美国失去信心一事感到担忧时,贝森特回应称 “你又在说失去信心了,我不认为这一定是失去信心,在两周或一个月的时间窗口内发生的任何事情都可能是统计噪音或市场噪音。” 他还表示,“我们是长期投资者,重要的是,我们正在为强势美元、强劲经济、强劲股市打下基础,并让投资者知道美国政府的债券市场是世界上最安全、最稳健的”。 特朗普于4月初宣布对许多国家征收所谓的对等关税,随后又给予其中大多数国家90天的关税暂缓期。 贝森特周日还表示,美国政府正在努力和其他国家达成双边贸易协定。他表示,这项努力涉及17个主要贸易伙伴,“在接下来的90天里,我们有一个与他们谈判的程序”,“其中一些进展非常顺利,尤其是与亚洲国家。” [查看评论](https://m.cnbeta.com.tw/comment/1495810.htm)

自4月9日以来,亚马逊平台上已有930种商品涨价,平均涨幅达29%;Shein在美国大部分涨价发生在周五,美容和健康类商品中排名前100的产品平均涨价51%,部分品类商品价格暴涨高达377%。周一,美股期货开盘走低,市场担忧涨价潮将导致消费需求萎缩和通胀压力上升的双重打击。 [](https://n.sinaimg.cn/finance/transform/129/w498h431/20250428/1983-392322f71609386dd97acec402967b85.png) 特朗普关税引爆连锁反应,价格飙升正在席卷美国市场。周一,美股期货开盘走低,市场担忧涨价潮将导致消费需求萎缩和通胀压力上升的双重打击。 亚马逊近千种商品平均涨价29%,而Shein美容和健康类商品中排名前100的产品平均涨价51%,部分品类商品价格暴涨高达377%。这波价格调整不仅影响在线零售商,还波及宝洁、联合利华等消费品巨头。 **电商平台掀起涨价潮** 在特朗普政府关税政策威胁下,电商巨头们已开始大规模涨价行动。 据环球时报报道,由于进口成本升高,亚马逊商家正在提高多种商品的价格,从纸尿布、冰箱贴到项链等畅销产品。 美国电子商务服务提供商SmartScout追踪数据显示,自4月9日以来,亚马逊平台上已有930种商品涨价,平均涨幅达29%,涵盖服装、珠宝、家居用品、电子产品和玩具等多个类别。 婴儿用品正成为关税冲击的典型案例。据报道,从5月初开始,美国最畅销的UPPAbaby婴儿车价格将从899美元飙升至1200美元,涨幅超过33%。部分品牌的婴儿车和汽车安全座椅价格已分别上涨100美元和50美元。 亚马逊平台上的商家正面临严峻抉择:要么提高价格,要么自行承担美国新关税带来的额外成本。而这些卖家早已面临利润被挤压的困境。过去几年,仓储、配送、运输和广告费等成本不断上升,同时激烈的平台竞争也带来了价格压力。 另据媒体报道,快时尚巨头Shein在即将到来的小包裹关税实施前大幅提高了美国产品价格。 数据显示,Shein在美国大部分物价上涨发生在周五,部分品类的涨幅明显高于其他品类。美国市场上Shein的美容和健康类商品中排名前100的产品较周四平均涨价51%,家居厨房产品和玩具平均涨幅超过30%,一款10件套厨房毛巾价格暴涨377%,女装价格平均上涨8%。 媒体对50件不同类别商品的抽样调查发现,4月24日至26日期间,Shein在美国市场的价格整体上涨了约10%,而同期其在英国市场的价格基本保持不变。在购物车的43件商品中,有30件的价格在两天内上涨超过10%。 **消费巨头连发涨价预警** 这波价格调整不仅影响在线零售商,还波及宝洁、联合利华等消费品巨头,对投资者而言,这预示着通胀压力可能反弹,消费者支出或将萎缩,零售股业绩承压风险加大。 上周,消费品巨头宝洁公司大幅下调全年销售和利润预期,并表示美国消费情绪正在明显恶化,特别注意到美国消费者在2月和3月份明显减少了支出。宝洁表示,美国新关税迫使其在2025年前3个月价格同比上涨1%的基础上再次提价。 联合利华在2025年第一季度将价格平均上调了1.7%,其公司总裁费尔南多指出,乳制品、可可和棕榈油等商品价格正在上涨,且由于美国政府征收的新关税,其美容产品的进口包装和一些原料成本也可能上升。 雀巢表示,在关税冲击导致的咖啡和可可成本飙升的背景下,公司不得不提高雀巢咖啡和奇巧(KitKat)巧克力棒等产品的售价。今年前3个月,其产品价格上涨了2%,其中咖啡胶囊价格上涨了3.2%,主要受咖啡和可可成本上涨的影响。 [查看评论](https://m.cnbeta.com.tw/comment/1495808.htm)

近日,摩托罗拉推出了其刀锋(Razr)翻盖手机的新版本,搭载由摩托罗拉自身人工智能技术以及包括Perplexity、Meta、微软和Google等多家公司的人工智能技术所驱动的功能。  和苹果、三星一样,摩托罗拉也将人工智能作为其新款手机的主要卖点。但与这两家公司不同的是,摩托罗拉的手机融合了来自多家不同供应商的人工智能模型和服务。 据称,5月15日将推出的新款刀锋、刀锋加强版(Razr Plus)和刀锋至尊版(Razr Ultra)手机是首批预装Perplexity人工智能应用程序的手机。Perplexity是一款由人工智能驱动的搜索引擎和研究工具,可在网页上和通过应用程序使用。 这款手机还搭载了Google的Gemini助手。据Meta称,摩托罗拉的新款手机还将默认集成Meta的Llama AI模型;微软的Copilot助手也将出现在这些设备上。 手机制造商与其他服务提供商合作并不罕见。例如,苹果与OpenAI合作,将ChatGPT的功能集成到Siri中,三星则与Google合作,为其Galaxy系列手机的一些人工智能功能提供支持。但以这种方式整合来自四家公司的技术却很罕见。  不过,有一家公司明显缺席:OpenAI。 当被问及为何没有将ChatGPT制造商的技术与其他主要竞争对手的技术一起纳入时,摩托罗拉北美产品组合主管艾莉森・易(Allison Yi)表示,该公司寻找的是在特定用例中表现出色、能够“补充”摩托罗拉自有AI的技术。 [查看评论](https://m.cnbeta.com.tw/comment/1495806.htm)

韩国第二大电池制造商三星SDI公司周一表示,将在下个月的欧洲主要电池展上推广其最新的储能系统(ESS)电池产品。三星SDI在一份新闻稿中表示,将参加欧洲2025年国际电池展(InterBattery Europe 2025)。 这是欧洲大陆最大的能源行业活动“更智能的欧洲”(Smarter E Europe)的主要展览之一,该活动将于5月7日至9日在德国举行。 在今年的展会上,三星SDI将重点展示面向人工智能(AI)时代的ESS技术,并推出多种新一代电池。 此次展出的产品包括为不间断电源(UPS)系统开发的新型电池“U8A1”和“三星电池盒(SBB) 1.5”。 UPS是一个重要的备份系统,在停电时为数据中心等设施提供应急电源。 SBB 1.5通过使用增强型直接喷射(EDI)技术,将灭火剂直接喷洒到电池模块上,以防止过热和热量扩散,从而提高了安全性能。 新闻稿称,三星SDI是唯一一家入围今年Smart E奖决赛的韩国电池公司。  [查看评论](https://m.cnbeta.com.tw/comment/1495804.htm)

今年一季度,京东创始人刘强东曾约上了三位互联网圈内大佬共聚晚餐,而这三位大佬分别来自三个场景:外卖、打车、本地服务。席间刘强东向三位“老友”表达了京东即将发力外卖的想法。  4月21日晚,刘强东在友人的朋友圈回复称:“在我外卖上线之前,我特意请了程维、兴哥和劲波一起见面喝酒聊天。我很简单直接:你做了这么多年的零售我从没有说过一句难听话,因为零售不是我的,不是京东的,任何人都可以做。我没有资格抱怨,做外卖也一样,只是希望兄弟们都能够守好自己的底线。” 京东内部人士向虎嗅表示,近期刘强东对于“外卖”这场战争的态度已经是“投入不设上限”,甚至给予京东目前管理层以“长期机会”:即不以短期的业绩收入、利润情况为考核,而是放眼长期,以扩大市场份额与提高口碑为更高优先级。 另据接近刘强东的人士透露,4月,刘强东把相当多的精力投入到“外卖”业务之中,不仅亲自送外卖,还密集与外卖业务核心管理层开会,并通过个人影响力推动集团内围绕外卖业务的“资源整合与协同”。 值得注意的是,在京东由创始人亲自“冲到一线”大举杀入外卖市场之际,美团内部的反应表面上并没有外界预期那么“紧张”。 和2024年面对抖音杀入本地生活业务后组建了名为应对抖音攻势的“烽火”项目组不同,截至目前美团内部并未针对京东的外卖项目组建单独的项目组或特战队。虎嗅获悉,4月王兴大部分时间依然投入在AI和具身智能领域,他去拜访了多位国际上知名的AI领域科学家,并参与了公司内部围绕无人机、具身智能和AI模型的几乎所有重要会议。 但美团近期也有变化。虎嗅获悉,美团在4月彻底完成了围绕外卖、即时零售等业务的架构整合。4月18日,王兴在内部信中宣布美团平台、到店事业群、到家事业群和基础研发平台合并成为 “核心本地商业”,由王莆中担任核心本地商业 CEO。值得注意的是,这一系列架构整合实际上启动于2025年2月,而2月8日京东外卖正式上线。 也就是说,目前在京东与美团这场围绕外卖和即时零售的激烈交火中,王兴把“前线”的统兵权交给了王莆中,并给予了王莆中前所未有的“空间和权限”。 有接近王兴的人士告诉虎嗅:“兴哥的兴趣目前聚焦于AI、具身智能等涉及未来的方向。”该人士表示,目前美团的架构是,内部围绕AI、具身智能的业务都由王兴亲自抓;而基本盘业务(如外卖、到店等)都由王莆中统筹,王莆中在重大决策上会请示王兴。 有熟悉王兴的人透露,在京东与美团外卖大战最为激烈的2~4月,王兴依然保持了自己的爱好:抽空和亲朋一起去看话剧类表演。 截至4月22日,京东外卖的“日单量峰值”突破了1000万单,目前覆盖了全国166座城市。相比之下,京东外卖目前的体量确实尚不足以对美团形成致命一击:有业内人士告诉虎嗅,美团目前日均单量已经超过七八千万单,日单量峰值可以超过一亿;而饿了么目前的日均单量大约在两三千万单,日单量峰值可以超过五六千万单。也就是说,京东目前的日单量峰值,尚不足以达到市场第一名和第二名的日均单量。而在市场份额上,目前美团和饿了么以7:3的比例,占据了整个份额大约95%以上的比重,其余外卖平台在整个大盘的占比有限。 但不可忽视的是京东外卖的增速。值得注意的是,从日单量500万到1000万,京东只用了一周。而在京东最新的计划中,未来三个月将招聘十万名全职骑手。 一位资深互联网外卖平台从业者告诉虎嗅,以目前的体量,京东外卖尚不足以对美团乃至饿了么形成真正压力,但如果京东保持投入和增速,一旦其日均订单量达到“1500万~2000万”这个“临界点区间”,美团和饿了么都会认真重视对手。 “关键点有二:投入周期有多久?保持的投入力度有多大。”该人士认为,以今天京东的体量和能力,如果坚决投入,是可能给美团带来“拼多多之于电商”的格局质变的。但该人士也认为,京东真正的目标可能并不在外卖本身,而是即时零售。 **外卖的皮儿,即时零售的馅儿** 虎嗅独家获悉,京东做外卖的计划于2023年就已经提上日程,当时京东原本计划于河南的郑州等地小范围测试外卖项目。 一位熟悉2023年京东外卖项目的前京东人士向虎嗅描绘了当时的计划:由京东旗下的达达负责配送,通过京东即时零售相关业务线承接品牌(小时达、京东到家)。“后来因为整个业务流还没有完全准备好,加上即时零售端围绕3C大品牌、日百头部连锁店的争夺愈发激烈,所以这个小范围实验搁置了。这个项目当时也是归属于即时零售整个大板块里面的。” 不难看出,今天京东最终落地的外卖项目和其“2023年的计划”如出一辙:基于达达的配送体系,京东增扩外卖骑手;通过即时零售业务线完成最早的品牌触达与开拓。 这其实正是此时此刻京东和美团这场“外卖大战”的本质与真相:外卖,是即时零售大战的延续,而非一场完全独立的、新开辟战场的热战争。 4月初,京东CEO许冉向虎嗅表示:“即时零售是我们非常重要的一个战略方向。外卖业务是一个很高频的非常日常的场景,它既可以带来用户的增长,也可以带来场景的延展,也包括用户的购物频次等。” 虎嗅获悉,在即时零售市场份额上,目前美团和京东占据了超过85%的份额,二者各自的份额均超过了40%,但对于谁是市场第一,各家都保持了“强宣称”。 即时零售对于美团和京东的核心价值是相同的:首先是利润引擎,其次是拉高核心用户消费频次的关键武器。 先看利润。2021年到2022年,京东的GAAP利润率分别为-0.38%、-0.99%,而2023年京东的GAAP利润率变为了2.1%。在2023年的财报电话会议上,京东高管对此的解释是即时零售订单增加带来了毛利率的明显增长。而到了2024年,京东的GAAP利润率达到了3.6%,而这一年京东即时零售(包括小时达等业务)订单量达到了有史以来的峰值。 同样的情况也出现在美团身上。2021年到2022年,美团的GAAP利润率分别为-13%、-3%,而到了2023年美团GAAP利润率变为了5%,而2023年美团业务上一个非常明显的增长点是其闪购的日订单峰值首次突破了1100万单/日。而2024年,美团的GAAP利润率达到了10.6%也是历年新高,而在财报电话会议上,王兴对此的解释视角是即时零售相关业务的规模效应对整体业务起到了作用。 不难看出即时零售对于美团和京东而言,都是其利润引擎,以及2023年对于两个平台而言都是一个节点。实际上,在2021年和2022年美团和京东的业务都遭遇疫情等因素冲击,两个平台都迫切寻找新的增长点,当时美团和京东所选择的方向都包括了两个:社区团购和即时零售。但社区团购最终被证明需要更漫长的投入周期,而疫情等因素意外催化了即时零售市场的超高速发展,所以两个平台的资源从2022年之后开始向即时零售业务倾斜。这也是为何从2023年开始,京东和美团几乎牢牢占据了即时零售市场的一二名宝座直到今日。而也正是从2023年,美团和京东围绕即时零售的战争逐渐火热。 这是因为,即时零售影响了两个平台核心用户的消费频次。 值得注意的是,在过去三年美团和京东都存在程度不同的“流量焦虑”:平台自造血流量有限,需要通过抖音、小红书、B站等新流量引流拉新、引流促单。为了解决这一痛点,两个平台都在尝试提高“自造血”能力,除了拼命做用户拉新外,如何提高核心基本盘用户的消费频次(以及APP打开率)也成为关键课题。 有熟悉美团的人士透露,2023年到2024年,美团围绕即时零售业务做了很多场景尝试:比如露营场景、宠物场景。美团通过丰富这些场景的产品供给,去增加用户在这些场景下的“美团打开率、下单率”。同样的事情也发生在京东身上,在过去几年,京东的小时达、到家等业务大幅度增加了在美妆、鲜花、宠物、潮玩等场景的供给,试图提高用户消费频次。 但随着双方“场景”增扩,交火面积越来越大。 从京东的视角看,2023年到2024年,美团的即时零售正在疯狂扩展3C供给,小米和苹果等品牌商家入驻美团,甚至出现了新品30分钟送到家的业务。这对于京东电商核心命脉的3C业务而言,显然是“杀入腹地”。但业内人士此前向虎嗅表示,在3C基本盘上,京东的供给丰富度、心智尚有优势。 而从美团视角看,京东过去几年在即时零售业务上对于“日百”类产品的大量增扩,几乎和美团的即时零售业务处于“贴身肉搏”,甚至一些原本在美团平台长期合作的品牌连锁店开始一鱼多吃在友商平台开店。 最终,京东和美团围绕即时零售的战争,已经成为了一场:争夺用户日常消费所有场景的全面战争。如今在两个平台的即时零售体系内,你几乎可以满足宠物、潮玩、美妆、鞋服、3C、绿植等等需求,甚至你可以买到活体宠物、PS5、高端望远镜…… 在这个情况下,京东杀入外卖业务其实是早晚的事情。 虎嗅获悉,美团的业务团队早在2024年初就意识到京东即将大力杀入外卖市场。当时京东相关人士已经开始与多个茶饮和咖啡品牌接洽,并有咖啡品牌拿着京东给出的合作条款找美团“坐地谈价”。 但令一部分美团人士没有料到的是,2025年初京东在外卖领域迅速投入的资源力度和“高声量”。据悉,在一些外卖订单中,京东目前拿出了20元/单的平台补贴力度,这甚至超过了抖音在2023年攻入到店业务时的投入力度。“以及确实没想到东哥会亲自下场,高调出镜。”一位美团知情人士说。 **京东和美团拼什么** 值得注意的是,虽然都在做外卖,但京东和美团的“根基模式”并不相同。 美团的核心命脉是强大的地推团队(以及基于此的庞大商家资源)、基于算法的骑手配送系统。美团的地推团队通过海量“堆人”,确保对终端餐饮门店的触达密度及深度。按照美团的模式,APP内一个新功能,从望京总部传递到乡镇一个普通面馆(并通过地推团队确保使用上),只需要1~3天。时至今日,美团地推的试用期考核都是以“开单”为标准——即成功说服没有入驻美团的门店入驻美团。此前,美团向虎嗅提供的数据显示,其合作商家总数超过1800万。任何平台,都很难在短期内获得这个体量的泛餐饮类商家。 而运力算法,则是美团的另一个超级武器。美团的运力基本上以1.5公里直径为一个圈,骑手主要在这个圈内拿单并完成配送,算法会根据时段和运力紧张度给骑手设计出“最短时间内拿最多单完成配送”的路线。实际上,这个运力算法才是美团外卖“利润”的核心源泉之一。 地推团队和运力算法,让美团的外卖业务成为一个典型的“阵地战”舞台:它很难通过一两次闪击,完成战线击穿。在过去两年中,抖音等平台都试图尝试在外卖领域对美团“冲锋”,但从结果看,均未能动摇美团的基本盘。 京东和美团的核心命脉是不同的。实际上,京东在电商基本盘核心武器是基于强大仓储物流体系的供应链,尤其在3C、日百等品类上可以通过自己的仓储物流体系实现速度优势;以及京东对于头部品牌及高净值用户的吸引力。它本质上做的是一种“扎实”的生意,通过仓储物流和供应链体系的精细化运营去获得“薄利”实现运转。 从过去三年的财报看,京东的归母净利润率分别为1%、2.23%、3.6%,实际上均未超过4%。换言之,京东并非一家靠流量变现或靠砸补贴运转的公司。 摆在外卖这件事上,京东面前的关隘是:如何迅速在美团构筑的“商家池+运力算法”城墙上,打开一个足够大的豁口,让主力军冲入其中。 目前看,京东的策略有二:一方面通过补贴吸引品牌商家和用户;另一方面通过完善骑手待遇补充骑手供给。 显然,这个战术是一场“持久战”,它很难通过一两次闪击分出胜负,但如果京东保持火力甚至扩大火力,并持续输出,格局走向或未可知。 但如果我们把视野拉回到最本质的即时零售,不难看出京东的另一张暗牌:一旦通过外卖让更多用户提高了消费频次,京东完全有可能凭借自己日百等领域的供给能力强化这些用户在即时零售领域的心智。 有知情人士向虎嗅透露,京东内部已经有一些涉及到“外卖与618联动”的规划,如果这些计划成真,那么京东整体的战略盘则更为清晰:它试图以外卖当作一个新的流量入口,去完成给核心基本盘业务拉新、拉高消费频次的用户转化。 **结语:当龙岩少年,遇上宿迁少年** 王兴和刘强东是两种人。 当刘强东在1992年以宿迁状元身份怀揣同村人援助76个茶叶蛋和500元现金到人大报到时,王兴正在龙岩市永定一中上初中。前者是村里的希望,时至今日被当地人誉为“项羽之后最有名的宿迁人”;后者则生活在相对更殷实的家中,2003年当王兴前往美国留学时,其父亲投资的水泥公司年产值已经达到10亿。 二人最早的交集大约是2004年前后,当时刘强东完成创业转型,从柜台模式升级为电商创立京东;而王兴也是在这一年回国创业。有知情人士透露,在早年的[中关村](https://finance.sina.com.cn/realstock/company/sz000931/nc.shtml)创业者活动上,二人有过一些交集。 有早年接触过这两个人的圈内人士,向虎嗅对比了二人的风格差异:“王兴在大学时,是清华大学莎士比亚戏剧社成员,酷爱戏剧,演过莎士比亚戏剧男主;刘强东在大学时虽然学的是社会学,同时自学了编程,因为家境贫困,刘强东又不得不边打工边上学,也开始了其创业积累。” 该人士透露,刘强东和王兴的性格差异明显。王兴很喜欢和各行各业的人聊天,他很善于倾听,直到他已经成为千亿市值公司老板后,他也经常会约上圈内好友去和一些“奇怪但有趣”的妙人闲聊。“他有时候没什么功利性,纯粹是好奇,会去拜访一些比他小很多但超级有意思的人。”从第三方的视角看,王兴更有一些浪漫主义的诗人气质,和他所喜欢的莎士比亚戏剧类似。 刘强东则有更浓郁的“质朴感”,他从中关村摆柜台创业以来,一直对基层员工有着独特的天然亲近。一位刘强东曾经的下属表示,只要谈到一线员工的工作环境或者待遇,刘强东都会展现出高度的关注。另一位熟悉他的人称,他会和人称兄道弟,他往往会给出自己的清晰态度并引领聊天的走向,他言出必行的特质让人印象深刻。 两个人的圈子是不同的。 时至今日,王兴都保持了和早期结识的互联网创业者、投资人们的友谊,他们定期聚会。他的朋友中很多在阿里、字节身居高位或是典型海归在国际知名公司打拼多年,他们会定期聚会畅饮大醉不谈业务只谈人生与各种趣事。而刘强东的朋友中,有很多互联网圈子之外的比如传统零售、餐饮等等赛道的朋友。 当这两个人终于在2025年彻底“交火”后,实际上是两种风格、两个圈子、两种势能的碰撞。 值得注意的是,如果京东接下来加大投入,会不会影响王兴的既定路线:按照王兴的思路,针对外卖业务,美团已经在做的是通过无人机、无人配送车以及AI模型进一步提高效率。 但京东即将投入的是十万骑手。在“赛博”之梦真正开启前,一场由“人”构成的真正硬仗。 [查看评论](https://m.cnbeta.com.tw/comment/1495802.htm)

简介: HMOS世界是基于开发者技术演进的大型代码工程的最佳实践,本次交流主要介绍HMOS世界设计开发过程中撰写的技术文章,内容涵盖HMOS世界三层架构设计、MVVM实践以及一多适配。  视频链接:[<u>https://developer.huawei.com/consumer/cn/training/course/live/C501744600634884580</u><u>?ha_source=rrdscpjl&ha_sourceId=89000499</u>](https://developer.huawei.com/consumer/cn/training/course/live/C501744600634884580?ha_source=rrdscpjl&ha_sourceId=89000499) 标签:鸿蒙课程、中级课程、鸿蒙生态、HMOS世界、大型代码工程、HMOS世界设计开发、技术文章、HMOS世界三层架构设计、MVVM实践、一多适配 课程关键词:鸿蒙,鸿蒙生态,鸿蒙学习,鸿蒙生态课堂,鸿蒙Next ,鸿蒙5.0,鸿蒙课程,鸿蒙实战,鸿蒙开发,鸿蒙实践,鸿蒙实训,鸿蒙学习,鸿蒙资料,Harmony,HarmonyOS,HarmonyOS生态,HarmonyOS学习,HarmonyOS生态课堂,HarmonyOS Next,HarmonyOS 5.0,HarmonyOS课程,HarmonyOS实战,HarmonyOS开发,HarmonyOS实践,HarmonyOS实训,HarmonyOS学习,HarmonyOS资料

简介:本次交流主要介绍HarmonyOS应用的基础创新特性:实况窗和统一拖拽。为更好的服务于用户。应用可以从信息展示以及交互操作上进行体验提升。用实况窗将用户关心的活动状态突出显示。使用统一拖拽可以更方便的在应用间传递数据。  视频链接:[<u>https://developer.huawei.com/consumer/cn/training/course/live/C101744095002414785</u><u>?ha_source=rrdscpjl&ha_sourceId=89000499</u>](https://developer.huawei.com/consumer/cn/training/course/live/C101744095002414785?ha_source=rrdscpjl&ha_sourceId=89000499) 标签:鸿蒙课程、中级课程、鸿蒙生态、HarmonyOS应用、基础创新特性、实况窗、统一拖拽、信息展示、交互操作、活动状态、应用间传递数据 课程关键词:鸿蒙,鸿蒙生态,鸿蒙学习,鸿蒙生态课堂,鸿蒙Next ,鸿蒙5.0,鸿蒙课程,鸿蒙实战,鸿蒙开发,鸿蒙实践,鸿蒙实训,鸿蒙学习,鸿蒙资料,Harmony,HarmonyOS,HarmonyOS生态,HarmonyOS学习,HarmonyOS生态课堂,HarmonyOS Next,HarmonyOS 5.0,HarmonyOS课程,HarmonyOS实战,HarmonyOS开发,HarmonyOS实践,HarmonyOS实训,HarmonyOS学习,HarmonyOS资料

<blockquote><p>曾经被视为保护消费者权益的重要措施,为何如今会被各大平台叫停?从最初的用户体验优化到如今的规则调整,“仅退款”政策背后反映了电商平台、商家和消费者之间的复杂博弈。本文将深入剖析“仅退款”政策的前世今生,探讨其在市场竞争、商家利益和消费者权益之间的平衡难题,以及取消后的电商平台如何通过新的机制维护生态健康,实现多方共赢。</p> </blockquote>  日前,又一则关于电商领域的消息冲上热搜。据北京商报4月22日消息,拼多多、淘宝、抖音、快手、京东等多个电商平台将全面取消 “仅退款”,消费者收到货后的退款不退货申请,将由商家自主处理。 此消息一出,立刻引起了大范围讨论。“仅退款”政策从最初保护消费者权益的重要措施,到如今面临重大调整,各电商平台纷纷叫停,其命运的轨迹在市场、用户与监管的多重作用下发生了转变。这背后的起起落落,无一不在表明电商生态变得更复杂。 ## 为应战,也为破局 众所周知,“仅退款”功能最初是由拼多多在2021年率先推出的,最初只应用于生鲜品类,随后被拓展到全品类。在2024年,“仅退款”功能被淘宝、京东、抖音、快手等平台相继引入。那么,究竟是什么原因使得电商老大哥淘宝也上线“仅退款”功能呢? 一方面,淘宝会上线“仅退款”功能是出于行业竞争的需要。前文曾提到,“仅退款”模式是拼多多率先提出的,凭借着“仅退款”模式,拼多多在用户体验维度形成差异化竞争优势,迅速获得了消费者的信任,实现了用户数量的快速增长。财报显示,截至2021年底,拼多多年活跃买家数为8.687亿,较上一年底的7.884亿,同比增长10%。 面对拼多多快速抢占市场份额的竞争压力,淘宝不得不跟进推出同类型服务政策,旨在通过优化售后体验保持用户黏性。自推出“仅退款”政策等一系列措施,优化用户体验后,淘宝的业绩出现了回升。财报显示,2024年一季度,淘天集团商品交易总额(GMV)、订单数均取得同比两位数增长。 另一方面,淘宝推出“仅退款”功能,有助于获得消费者信任,消除网购信任壁垒。线上交易特性使消费者面临“信息不对称”的天然屏障,商品图文不符、质量缺陷等问题常导致消费决策迟疑。淘宝上线“仅退款”机制,能通过建立风险对冲通道,有效化解交易信任危机。比如,当消费者遭遇服装材质虚假宣传,或电子产品功能故障等质量问题时,免去烦琐退换流程即可快速获得全额退款。这种售后保障机制可保障消费者权益,有助于增强淘宝公信力,既优化了交易体验,又强化了其市场竞争力。 除此之外,“仅退款”功能的推出,也能促使商家更加重视产品质量和售后服务,从源头上减少问题商品的出现,有助于提升淘宝整个平台的商品质量和服务水平,提升消费者的满意度、拉高复购率。 ## 矛盾愈发凸显 任何商业机制的命运转折点,往往始于其引发的系统性反噬。曾被奉为“体验革命”的仅退款功能,逐渐演变成吞噬平台根基的“黑洞”。该功能引发的消费纠纷与商家经营压力持续上升态势,对平台生态健康造成显著冲击,最终,淘宝做出了取消的决定。 一来,淘宝平台遭遇“退货薅羊毛”乱象,原本保护消费者的“仅退款”功能,现在成了部分人钻空子的工具,商家利益受到严重损害。比如,部分消费者通过虚构商品瑕疵等方式,随意申请仅退款,并将商品据为己有。在此情况下,商家不仅既亏了钱财,又没了商品,成本大幅上升。部分中小型商家难以承受,选择缩减商品线或考虑退出平台,优质供给端的持续流失自然也会影响淘宝平台的生态健康度。 二来,恶意“仅退款”行为容易引发信任崩塌,让商家和消费者变得互相不信任。为了防范恶意仅退款,商家不得不耗费大量资源应对售后争议,甚至对合理退款请求也产生戒备心理。而当消费者感知到商家的过度防范时,维权过程中的负面体验极易升级为对抗情绪。对淘宝来说,这种互信缺失或许逐渐演变为平台生态的裂痕,不利于后续交易。 三来,“仅退款”行为还容易出现成本转嫁的恶性循环。看似由商家承担的成本,最终通过价格传导回归消费者。部分商家为对冲退款风险采取“防御性定价”,导致商品价格虚高;另一些商家则转向低成本低质量路线,形成“劣币驱逐良币”的恶性循环。为了避免恶意“仅退款”行为,淘宝也不得不投入更多的资源处理纠纷,这也在一定程度上拉高了成本。 ## 后仅退款时代的进化论 取消“仅退款”绝非倒退,而是一场更深刻的体验革命。淘宝需要回答的核心命题是:如何在保护消费者与尊重商家之间找到新支点?一是,淘宝需构建高效公正的纠纷协商机制,提升售后处理效率与用户满意度。比如,开发售后协商模块,自动跳转至协商界面并匹配标准化流程模板。智能客服实时分析交易数据与商品信息,在僵局时提供解决方案建议。对协商未果的纠纷,启用人工快速响应机制,由专业团队依据平台规则作出公正裁决,保障双方权益。 二是,淘宝正在细化评价维度,完善“真实体验分”体系。据了解,淘宝天猫在前不久公告了“关于新增《淘宝平台店铺真实体验分规范》的意见征集”,宣布将上线新版店铺评价体系“真实体验分”,通过商品质量、物流速度、服务保障三大维度建立客观评分机制。这一举措能让“真实体验分”成为消费者决策核心参考,倒逼商家提升商品质量与服务水平,推动平台品质升级。 三是,淘宝还能以强大AI能力为依托,构建智能风控系统。在用户层面,淘宝通过分析用户行为轨迹、交易特征、信用历史等多维度数据,实现风险预判与精准干预。在商家层面,可同步监测商家商品质量及售后纠纷数据,精准识别违规商家并采取降权、限流等措施,以技术手段维护平台交易公平性。 总的来说,取消“仅退款”功能绝非服务能力的倒退,而是平台治理的跃迁。当电商竞争进入存量博弈阶段,真正的决胜点在于能否构建“商家可持续经营、用户获得真实价值、平台生态健康发展”的三角平衡。淘宝的探索证明:最高级的用户体验解决方案,往往存在于规则创新与商业伦理的交汇处。这场静悄悄的革命,正在重塑中国电商的未来图景。 本文由 @三车财观 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

<blockquote><p>从曾经的“低价低质”刻板印象,到如今成为众多连锁餐饮品牌和中小餐馆的新宠,拼好饭不仅吸引了汉堡王、老乡鸡、南城香等知名品牌入驻,还通过独特的拼单模式和高效的供应链优化,实现了真正的低价与品质兼得。</p> </blockquote>  老乡鸡卤肉饭套餐 14.9 元,塔斯汀香辣鸡腿堡套餐 12.94 元,南城香麻婆豆腐套餐 16.5 元…… 曾经被吐槽“便宜没好货”的拼好饭,如今画风突变,竟也打起了品质堂食和大牌餐饮的招牌。 打开拼好饭页面,品牌商家已占据大半位置,从汉堡王、老乡鸡、南城香、魏家凉皮等连锁快餐品牌,乃至蜜雪冰城、茶百道、沪上阿姨等茶饮品牌都随处可见,据称已有超过 5000 个连锁餐饮品牌入驻了拼好饭。 即便是中小餐馆,也有专门的品质堂食专区,点开商家页面可以清楚看到餐馆环境,到店取往往还能再便宜两瓶可乐钱,不用抢券也不用拼单。其中不少餐馆还都同时在红黄蓝三家平台同时上线,主打一边品质堂食,一边拼好饭。 过去人们对于拼好饭的印象是低质低价,怎么现在却成了低价也有品质外卖? ## 拼好饭不只是把价格打下来 即便拼好饭正式上线已有 3 年之久,不少用户打开拼好饭仍会对打了半折不止的餐品价格感到惊讶。6.9 元一份张亮麻辣烫六荤六素套餐,13.7 元一份田老师红烧肉盖饭,开遍全国的沙县小吃在北京也能 10 元畅吃。 无一例外,这些餐品的销量往往都能比主站外卖的餐品高出一个数量级,单量在 4000 以上的不在少数。点击一份餐品,最先跳入眼帘的并不是传统外卖平台的加入购物车,而是“拼单”。餐品页面上会随机滚动附近的拼单信息,单击即可拼单成功。   拼好饭与拼多多商品页面对比 发现了吗?拼好饭的前端页面几乎是拼多多在外卖平台的翻版。同样的弱化店铺信息,同样的放大商品和价格,同样的拼单团购逻辑,同样都简化了付款流程,取消购物车的概念。简单来说,拼好饭就是将电商行业的爆款策略复刻到了外卖领域。 但餐饮行业毕竟与电商零售不同——电商平台没有区域限制,且多是规格商品,链条长、水分多,平台依靠直采减少中间环节,用补贴代替营销,就能将价格打下来。 餐饮外卖商家则大多是中小商户,覆盖人群局限在周边三五公里范围,食材成本、房租成本、配送成本都是硬性开支,利润微薄,即便加上平台补贴,也很难挤出多余水分。 也就是说,仅仅依靠在前端商品策略上学习电商平台,拼好饭也无法将餐品价格打下来。要想做到真正便宜,拼好饭还得解决供给端和配送端的问题,必须从传统餐饮的供需模式和生产效率入手。 传统外卖模式是一种满足消费者多样化需求的选购逻辑。商家提供足够多的餐品,消费者按照不同喜好下单,商家依次备餐、骑手单独配送。但这种分散式点餐模式却并不是效率最高的,商家为了满足菜品种类增加更多食材及人工成本,每单的配送成本也居高不下。 拼好饭并不只是餐饮界的拼多多。你可以简单将其理解为一个链条更短的 C2M 定制。打开拼好饭,你能直观感受到与主站外卖的不同。普通外卖的餐品更加丰富,但拼好饭的餐品则集中在米饭、面点、盖饭小炒这些主食品类上,种类少而精,商家只需做好少数几个爆款餐品即可,能显著降低食材成本。 配送端也有所不同。拼好饭的拼单逻辑下,骑手一次性将距离更近的几个订单统一配送,单均配送价格更低,提升配送效率。 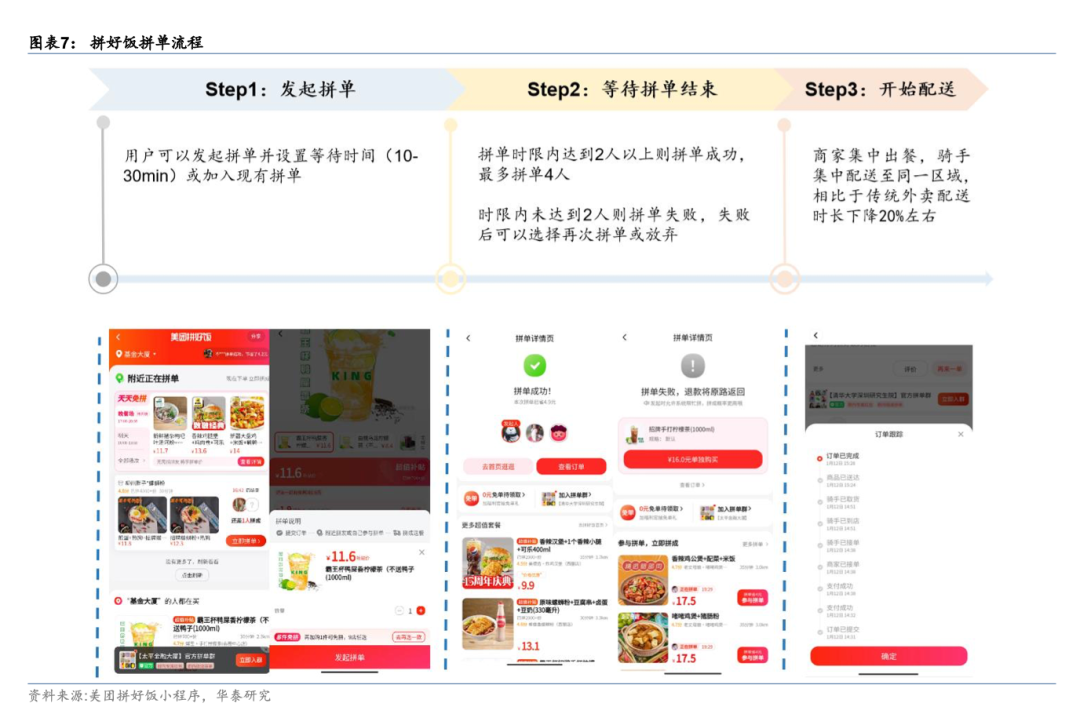 拼好饭拼单流程/图源华泰证券调研报告 华泰证券去年发布的一份拼好饭调研报告指出,与市场认为拼好饭只是“相比主站价格更低的外卖”观点不同,他们认为拼好饭带来了一种全新的外卖模式:价格更低的背后是平台在供给端与商家协商“以量换价”,在用户端鼓励同地拼单并集中化配送,从而显著降低了单均配送成本。 “拼好饭本质是外卖提升效率的新模式,并且有助于用户、商家、骑手三方效用增强。”华泰证券在调研报告中表示。 一位中小餐饮商家此前对《山上》表示,商家在外卖平台的支出大头并非抽佣,他们更主要的支出是在平台上常态化的营销投流以及每单的配送成本。 在拼好饭模式下,中小餐饮商家可以凭借价格优势形成差异化竞争。传统外卖的展示主体是店铺,商家需要依靠常态化的投放维持曝光,但拼好饭以商品展示为主,中小餐饮商家实际上是用低价来换取曝光和销量,再通过高周转盈利,配送价格的降低也能挤出更多利润。 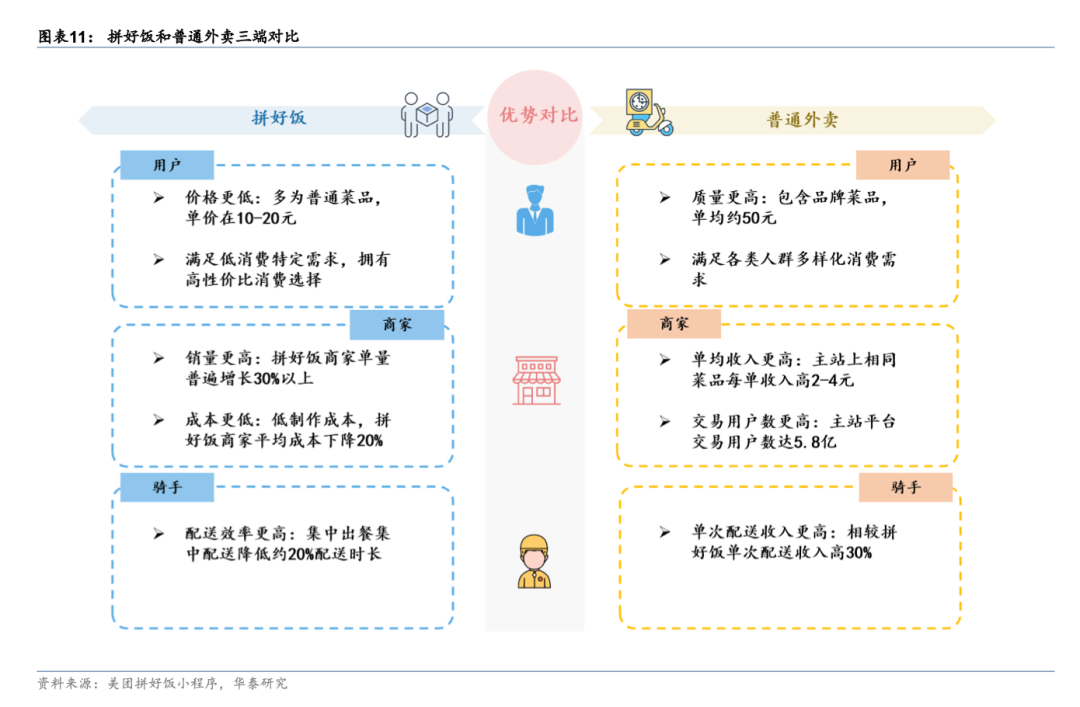 华泰证券调研报告 上述华泰证券调研报告指出,和主站商家相比,拼好饭销量更高,单量普遍增长 30% 以上,同时成本更低,拼好饭商家平均成本下降 20%。而主站商家单均收入更高,与拼好饭相同餐品主站每单收入高 2-4 元,但同时单次配送成本也更高。 东北特色快餐品牌齐品达创始人叶超说,拼好饭推动了他们品牌整体大盘交易额的提升,单个门店月销量最高能达 9000 多单,单门店月净利润增长万元。 他们为拼好饭上线的爆款单品是鸡排鸡柳双拼饭,两款肉加上“七选二”素材的套餐,售价不到 10 元,但毛利润能达 40%以上。原因是高销量带动了成本降低 15%,消费者复购率超过 40%。 “拼好饭就要性价比,好吃不贵、量大便宜才有高销量。”叶超说。 ## 拼好饭怎么就成了互联网爆梗 不知从何时起,拼好饭在互联网上逐渐走红,成为一种中文互联网上特有的 meme 梗。 不只是有人开始编排起“锅里的堂食,锅沿的外卖,掉在地上的拼好饭”这样的网络段子,甚至“拼好饭”本身都已经上升成为一种骂人词汇,诸如“拼好饭吃多了”“我看你是吃拼好饭吃中毒了”等类似语言层出不穷,在年轻人之间颇为流行。 这些对于拼好饭的刻板印象,本质上是消费者天然对低价就等于低质的心智导致,但却与实际情况不符。 事实上,大多数拼好饭商家都是有着门店堂食的中小餐饮商家,他们本身在线下经营的就是量大管饱的主食类餐品,诸如现炒盒饭、安徽板面乃至沙县小吃等等。甚至多数拼好饭商家除了提供平台拼单外,也都支持到店自取订单,自取订单因为省去了配送成本,还能再便宜 4-7 元钱不等。   拼好饭中的品质堂食与明厨亮灶入口 “哪有功夫做两种餐?还能分两个锅,一个做正常的,一个做拼好饭?顾客不是傻子。”一位拼好饭商家称,人为降低餐饮品质,往往会引发更多客诉,降低门店口碑,得不偿失。 专注于餐饮行业的红餐网此前报道称,对于多数街边小店来说,拼好饭是他们增收的重要方式。“在餐饮连锁品牌纷纷降价抢夺性价比赛道的时候,拼好饭是街边小店通过灵活成本优势来去参与市场竞争的重要部分。” 红餐网调研的一位张亮麻辣烫店长透露,拼好饭和正常外卖的菜品一致,都是根据订单在门店展架上取菜,全程有监控,菜量也没有区别,他们主要是根据市场价格波动来调节蔬菜的搭配。比如当某款蔬菜价格上涨时,就选用更便宜的菜品替换。“关键是通过搭配控制成本,整体仍然是满满一大碗,客户体验和满意度都会比较稳定。”红餐网引述该店长发言称。 不可否认,虽然拼好饭的业务逻辑是通过高订单+低配送成本来实现低价,但餐饮商家众多,餐饮标准化程度也不高,客观上仍然存在商家以次充好的可能。 但和主站外卖不同,拼好饭讲究的是爆款策略,单一品类的销量往往是主站同等菜品的数倍级别,单品月销订单在千单以上的不在少数,如果存在食品安全问题更容易暴露出来,反而会让商家在选购食材和制作时更加谨慎。 平台对于拼好饭商家的管理也更深入。和主站外卖不同,拼好饭上的菜品多数都是平台与商家根据市场需求共同协商定制的,菜品成本和最终价格维持在一定区间内。它并不是追求绝对低价,而是要保证单量和利润平衡基础上的低价。 《晚点 Latepost》此前报道指出,拼好饭供给模式是平台来决定卖哪些低价餐食,定向招商,与商家协商制定低毛利的供货价格,相较过去的价格可以做到更便宜。 连锁品牌宏状元的外卖运营负责人张贺介绍,宏状元的菜品以粥饼面和堂食炒菜为主,他们在为拼好饭选品时就会和平台沟通,“比如哪些品还有机会点,相当于共创。” 他们在选品时会基于几个基础,一是用户能够认可,二是门店操作不复杂,不浪费人工成本,三是用户能吃饱。拼好饭虽然价格更低,但由于单量可控、菜品可控,门店能够提前设定库存、人力,效率相较普通外卖会更高。 为了实现低价,他们当然也要做成本优化,但并不是通过降低食材质量,更多是砍掉此前外卖流程中不必要的成本环节。 张贺举了一个例子,比如盖饭餐盒上的内衬,它是用于将外卖盒中的米饭和菜品区隔开来。在拼好饭上他们就将这个内衬取消,“这个也要成本,我们就把这个成本省下来,把价格降下来。”张贺说,通过一系列的优化,他们在餐盒上的成本每份能够降低几毛钱。 平台也试图做出更多举措来规范加强食品安全,定期开展拼好饭商家食品安全培训,同时建立拼好饭食品安全标准,定期抽检。美团此前上线的“明厨亮灶”入口,其中也引入了不少拼好饭商家。 网友玩梗归玩梗,对拼好饭的热爱是一分都没减。拼好饭自上线以来订单持续攀升,去年第三季度日均订单量已突破 900 万单,且还在继续增长之中。社交平台上,也有不少用户发帖称,拼好饭成了打工人的“平价食堂”。 ## 拼好饭也能是品质外卖 拼好饭正式上线于 2022 年,正值国内餐饮行业面临结构性调整时期。 中国烹饪协会此前发布的 2020 年中国餐饮市场分析指出,2020 年全国餐饮收入 39527 亿元,同比下降 16.6%,餐饮行业连续多年的稳定增长势头不再。国家统计局发布的数据显示,2022 年全国餐饮收入 43941 亿元,同比下降 6.3%。 国人整体消费观念也在慢慢发生转变,在追求质量的同时更讲究性价比,整个消费市场都面临“质价比”的转向。过去那些华而不实的高端餐饮溢价已经很难被市场认可,餐饮行业需要探索一种更为适应当下消费趋势的发展路径。 过去几年,越来越多的大牌连锁餐饮品牌开始将目光投向下沉市场,麦当劳、肯德基等快餐连锁巨头在县城开出了更多门店,星巴克、瑞幸咖啡等都将县域市场作为更主要的增长渠道。 即便在一线城市,不少过去主打高价位的餐饮品牌也开始主动拥抱低价。越来越多的商场餐饮品牌上线了外卖平台,推出平价套餐,连海底捞都开始亲自下场和张亮麻辣烫们竞争,推出“海底捞下饭火锅菜”,最低 23.4 元就能吃上一顿“捞派豆花干拌麻辣烫套餐”。 在这种整体消费趋势的转变下,拼好饭也开始成为连锁品牌商家们争相涌入的渠道之一。在拼好饭的“大牌专区”里,你不仅能看到老乡鸡、大米先生、汉堡王、杨国福、塔斯汀这样的快餐连锁品牌,还能看到诸如茶百道、益禾堂、沪上阿姨这样的茶饮品牌。目前,已有超 5000 家餐饮品牌入驻了拼好饭,涵盖茶咖、中式简餐、西餐等不同品类的知名品牌商家。  部分入驻拼好饭的品牌商家 宏状元是最早一批上线拼好饭的连锁品牌商家,2023 年 10 月就实现全部门店上线。宏状元外卖运营负责人张贺说,他们的初衷是希望拼好饭能够吸引更多的年轻消费者,“我们是抱着利润不太高的想法去做拼好饭的,想尝试用几支爆品把品牌打出去,希望拼好饭能够成为外卖生意中的额外增量。” 上线一年多以来,拼好饭的增长超出他的预期,单品月销量能做到 999+,加上主站外卖订单一个月能做到 1.4 万单,整体的订单量上涨了 70%-80%。 华泰证券此前在研报分析中认为,由于拼好饭的低价属性,品牌商家或缺乏入驻动力。比如蜜雪冰城本身就是深耕下沉市场,用户基础稳固,不需要更多折扣获取订单。 但现实情况却有所不同,包括蜜雪冰城、华莱士等拥有庞大下沉市场用户的连锁餐饮品牌同样入驻了拼好饭。部分原因或许与拼好饭在一二线城市表现更好有关。此前雷锋网报道指出,从拼好饭页面显示数据看,五线城市的区域单量会更少一些,一二线城市区域的单量则普遍表现较好。 对于多数连锁品牌来说,拼好饭更大的吸引力在于其带来的新增用户群体,这些都是过去品牌无法触达的增量用户。 汉堡王相关负责人称,他们入驻拼好饭大牌专区,更主要的是希望探索更多新用户和年轻客群的互动链接与扩展。他们目前上架拼好饭的汉堡三件套 14.9 元已经是最低价格,没有下探空间,他们已经在考虑针对拼好饭渠道打造 C2M 专供品,来解决低价问题。 在外卖已经成为当下餐饮市场最重要的组成部分时,想将外卖价格打下来,无法依靠补贴这样不可持续的短期路径。外卖是一个链条长、环节多且参与商家众多、极度分散的赛道,实现低价依靠的是用户、骑手、商家的三方共赢。至少从目前来看,拼好饭已经先做出了尝试,让低价也能有高质量。 作者|王彬 本文由人人都是产品经理作者【山上Hillvue】,微信公众号:【山上】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。

简介:稳定高效的打印系统,是保障企业办公流畅运行的关键。本课程聚焦前端打印系统方案实践,详解权限配置等基础能力。通过基础概念到实践案例,轻松实现应用一键打印,掌握稳定高效的打印方案。课程安排:打印管理及文件打印能力概述、基于Web组件打印实践、打印机管理技术方案实践、打印能力技术方案实践。  视频链接: [<u>https://developer.huawei.com/consumer/cn/training/course/live/C501744617835810581?ha_source=rrdscpjl&ha_sourceId=89000499</u>](https://developer.huawei.com/consumer/cn/training/course/live/C501744617835810581?ha_source=rrdscpjl&ha_sourceId=89000499) 标签:鸿蒙课程、鸿蒙生态、中级课程、打印系统、前端打印系统方案、权限配置、应用一键打印、打印管理、文件打印能力概述、基于Web组件打印实践、打印机管理技术方案实践、打印能力技术方案实践。 课程关键词:鸿蒙,鸿蒙生态,鸿蒙学习,鸿蒙生态课堂,鸿蒙Next ,鸿蒙5.0,鸿蒙课程,鸿蒙实战,鸿蒙开发,鸿蒙实践,鸿蒙实训,鸿蒙学习,鸿蒙资料,Harmony,HarmonyOS,HarmonyOS生态,HarmonyOS学习,HarmonyOS生态课堂,HarmonyOS Next,HarmonyOS 5.0,HarmonyOS课程,HarmonyOS实战,HarmonyOS开发,HarmonyOS实践,HarmonyOS实训,HarmonyOS学习,HarmonyOS资料

<blockquote><p>在互联网巨头的激烈竞争中,外卖市场一直是兵家必争之地。美团凭借强大的地推团队和精准的补贴策略逐渐占据主导地位,而饿了么作为曾经的行业先锋,如今却似乎在竞争中逐渐失势。</p> </blockquote>  之前说过美团外卖和京东外卖战火纷飞,现在这个时候,饿了么就有点被遗忘了。为什么饿了么作为一家更早去探索外卖模式的产品,或者说这样一家公司,现在沦落到此? 其实阿里收购了很多的业务,大家普遍发现收购的业务活得好的不太多,这又是为什么呢?首先我想谈谈创始人和创始团队的一个价值。很多时候我们好像看到很多的一些产品最后被大厂收购了。人们固有的印象会认为大厂收购的这批人的能力,可能是要比被收购的那个创始团队、创始人他们的能力更强。实际上这是不对的,一般情况下是更弱不是更强。我们有的时候其实会去高估资源、资本的一个力量,而低估人的力量。 比如说一件事情从 0 到 1 难,还是从 1 到 10 或者是到 100 难,这个问题各有各的看法。我的观点是,普遍来说应该是从 0 到 1 会更加的难。然后从 1 到 10、到 100,其实只要这个 “1” 能够站住 ,我指的站住是什么意思?比如说你这个产品推出来能获得几万个用户,10 万个用户,然后能有 10 万块钱的收入。类似这种的话,你就可以认为它是基本上有了一个最小的 MVP。然后再到后面,你怎么样把它做到 100 万、1000 万,这个是一个放大的过程。 其实在前面的阶段,因为从 0 到 1 可能能够参考的一些东西非常有限,反而是一片混沌黑暗中去寻找方向。这个过程中会考虑很多的东西。一方面是你的创始人以及你的创始团队有没有信念。你首先需要有信念,相信这个事情是对的,能够把它做成。还需要有具体的一些方式方法,能够找到这个比较合适的一个路径。这个时候往往可能什么资源都没有,那基本上都是要靠徒手去做一些事情。 反而到后面你有模型在了,有数据在了,你可以去找到投资人或者是说获得其他的一些资源的支持。可以去用更加理性或者是说科学的一些方式去探测它。比如说投一部分资源去试这个方向到底行还是不行,这个优化改进到底有没有用。但是在初创的时候,实际上有可能根本就没有办法去做很多的测试。基本上只能是凭着一股劲头遇山开山,遇水架桥。 我自己现在所在的公司,其实也是从很早期的状态发展过来的。然后中间有一次被一家集团并购了。然后我们的创始人和创始团队的很多合伙人,都基本上都退出了。这个过程中我会明显发现,在公司被并购之后,其实是两种风格和两种状态。在前面的时候有很多的东西,其实大家的勇气也好,或者是说尝试的力度也好,明显比后面要更大。 被并购到一个更大的公司之后,你会发现从职业经理人的角度来说,有时候他未必不知道应该要去大力创新,大力做尝试。但很多时候一定会出于一个更加保守的考虑。比如说一件事情,也许做了会有价值、有用、有收获,但是也许会出错。那这个时候你会发现,好像决策者的考虑里面,把不犯错的比重提上来了。就导致很多时候该去大力尝试、大力验证的,反而好像用一些比较简单的方式浅尝辄止。这个时候往往又验不出来到底这个策略奏不奏效。 所以我会感觉,一家公司如果有创始人在和没有创始人在的话,其实完全可以认为是两家公司。然后这个里面,其实创始人和创始团队的价值,是一个很难用一些数字去衡量的,它其实是一个本质上的区别。而字节的张一鸣之前有个观点,就是只有认知是你的真正的一个壁垒,其他的都不是。这句话我理解其实也可以换成只有独特稀缺的人是壁垒,其他的都是可以去凑齐的。但是人就是这样非标准化的,所以创始人和创始团队的价值是不可衡量的。然后到饿了么的这个案例里面,它其实也是它的创始人和创始团队被收购之后,后面就逐步退出了。 然后后面更像是一个职业经理人经营的状态。然后很多人可能就会考虑到,我今年的绩效会不会受影响,比如说有的时候需要去做补贴、打广告之类的,或者是说如果你从回归到一个产品或商业竞争的本质,那你有可能需要去看影响到两年以后、三年、五年的这种指标。比如说钱怎么花会更有价值,能够有更多的用户沉淀下来、留存下来。但是如果从一个职业经理人的视角,你会关心我下个月、下个 Q 的绩效到底能不能扛得住,然后我年底我能不能评 3.75 ,能不能拿比较多的奖金和股票。那如果是这样的话,假设你的 KPI 定成了一个用户活跃量或者其他的,那我现在有钱,就想着各种去发福利、发优惠券之类的,最后好像看起来很热闹,但是实际上真正有价值沉淀下来的却不是很多。 然后可能在第一个 Q 或者是说第一年这样还是 ok 的。但是等到复盘下来,发现这个方式行不通。然后最后的话业绩也不是很好,对吧?那第二年的话还会不会再这么去投呢?但是如果你的竞争对手就是在花钱,而且比你用钱用得更加有效率,那你可能经过前面这些情况,后面预算就没有那么大了。你想投就需要去拼命地跟上级领导去各种争取啥的。 这种情况你就会发现明显是很大的阻力的。而之前有创始人和创始团队在的时候,有可能只需要开一次会,就这么愉快地决定了,整个的效率就是非常不一样的。之前有个观点我觉得也是类似的,说跨国公司的中国团队去做一些事情,往往比不上中国本土的一些比较 “土” 的创业团队。因为比较 “土” 的创业团队,决策的链路很短很清晰。而那些配置看起来很高的团队,可能改一个地方的文案都得去提个申请,然后审批个十天八天的,这样的话肯定战机马上就没有了。 然后阿里收购了很多的公司,但是能够真正继续维持之前的优势,或者是说市场规模的,其实很少,或者说基本上就是没有。这里面又是为什么呢?我觉得除了一方面是创始人退出的这个问题,其实基本上很多被收购的情况,最后创始人都会退出。有的可能当时就退出,有的可能会再带个一年左右的时间,一般来说都不会超过一年的。然后可能挂联席 CEO 的这样一个 title。 然后两个团队去进行合并。以前 58 和赶集网,还有美团和大众点评,还有滴滴和快的,都是这样的案例。这属于两个业务体量差不多,可能背后甚至有相同的投资方都砸了很多的钱。哪一个失败可能都不能接受,最后两个互相消耗其实也没有必要。所以干脆一拍即合,两个合并了,然后形成一个相对的垄断优势。然后后面也没有其他的人来竞争,这个时候就可以不用那么补贴,价格能够定得高点,就变成一个赚钱的生意了,大概是这样子的。 然后我觉得阿里收购的产品,其实有一个通用的逻辑,或者说特点。当然饿了么的情况其实算另外一个逻辑。阿里收购的其他的一些,比如说之前的虾米音乐、优酷这些,本身是一个内容的平台。阿里的逻辑是,它作为电商,其实是最缺流量的,所以想要去获取更多的这种流量来源,包括之前投资微博也是这个逻辑。但是阿里收购的这些产品,其实都没有在行业内有垄断性的优势,或者说优势没有那么大。它其实还是处在一个护城河没那么宽的赛道。 大家可以想一下,一般来说如果一家公司活得好好的,是不太可能被收购的。除非创始人老板觉得自己不想做这个事情了。但是我们看到很多被收购的公司,其实就是迫于无奈。它们可能在跟对手的竞争中已经扛不住了,然后没有这么多的资源弹药。这样的话,阿里收购它们,这些公司本来可能期望是找到大金主了,然后继续去投钱,继续去竞争。 但是阿里的逻辑,回到刚刚讲的,其实是一个流量变现的逻辑。它需要这个产品给它提供流量,而不是说投钱到这个产品,然后帮助这个产品去做大。这和腾讯系不一样。腾讯系在 3Q 大战之后调整方向,然后以投资赋能为主,腾讯系有很多的产品其实都活得挺好的。 这个逻辑的最大区别,其实就是腾讯不需要流量,因为 QQ、微信有源源不断的流量,它反而缺的是内容场景,缺的是如何把用户留在腾讯的整个体系内,所以它是真正能做到赋能。而阿里的逻辑其实是一个消耗的逻辑。它自己不愿意投钱,反而是需要流量过来。那这样的话岂不是源头的水越来越小,但是你的竞争对手他们自己能够从外面引水源过来,那自然就越做越差,竞争对手就超过了。 然后回到外卖这里,我想聊一下外卖这个业务的底层特征。然后为什么最后是美团兴起呢?我自己也只是从一个角度、一个切片,以有限的认知去判断。我理解外卖这个模式说复杂也复杂,但说简单也简单。其实只要把钱和资源花在刀刃上就可以了。这也是美团之所以之前在千团大战中脱颖而出,我觉得是至关重要的因素。 然后我好久之前看过美团的一些复盘,为什么最后是美团胜出?因为原来团购网站竞争的那个时代,大家可能有大把的钱,然后都基本不去算后续的回报。反正就是想着怎么把用户带到自己的网站上来,然后让他去下单,然后关注每天的成单量有多少,也不管这个钱后面能不能赚回来,这是当时比较普遍的做法。当时有好几个团购的网站比美团做的规模要大,比如说拉手、糯米这些。但是美团王兴他们这个时候反而冷静下来,他们觉得这个时候不应该花那么多钱,应该把钱留着,然后做比较小的投入。然后,他们会关注自己的投入产出比,而不是单纯地去补贴、冲规模。当时他们的逻辑是觉得整个市场现在很乱,如果大家都在做这件事情,你也在做这个事情,其实最后大家都是拼烧钱,这肯定是不健康的。当时他们判断,那个时候是一个市场教育和普及的阶段。也就是说不管谁花钱,那都是在帮助团购的这个模式去做市场的普及。所以美团就是等竞争对手去烧钱,烧到最后,然后竞争对手钱已经烧得差不多了,没有什么弹药了。最后美团的钱就没有怎么烧,或者说相对烧得更少,它的账户里面比较充足。所以最后美团就把那些后面因为资金断裂没办法持续的都收编了。 曾经不是还出现很多质疑说美团是不是也资金链断裂了。结果王兴他们做了一个事情,就直接把银行账户的余额晒出来给大家一看,去增强这个信心。然后这个时候,其他的团购网站其实已经没办法去提供这个服务了。然后美团还正常经营着。这些用户被各种团购服务体验了好几次之后,最后发现美团能够稳定地提供服务,觉得团购这种模式真好。所以慢慢就全部都变成了美团的用户,就一波把对手都打趴下。 当然了,这只是其中一方面的策略。实际上美团在快速扩张的时候,包括和饿了么竞争的时候,它其实还有一个核心的策略,叫做狂拜访、狂补贴。一手就是想着如何增加商户的供给,这个就靠它建立起来的一个地推团队去疯狂地拜访商户。另外一方面是去做用户端的补贴,发各种优惠券。然后好像十几块钱就能吃到一顿比较不错的午餐。那个时候它还不是上市公司,所以花钱更容易做出决策。饿了么没办法跟美团一样这样去做补贴,或者说做这么大的额度。所以饿了么只能自己找别的一些方式。 饿了么曾经尝试过跟钉钉做组合,然后在钉钉上面推办公场景的订餐,这个看起来好像很合理,实际上这是一个三方服务入口,由钉钉提供下单页面,饿了么负责服务,支付由支付宝去完成。这样必然会在流程上面不够简洁,而且里面的一些优惠券体系也不完善。这样的一个组合只有一个场景比较合适,那就是请同事去吃东西。但是请客吃饭的这个体验,我觉得是没有办法和到店就餐相比的。因为吃好吃的、聊聊天,增进一下彼此的关系,这个其实更适合到店里面去,大家一起现场就餐。除非是疫情的时候,没办法,可能会有一些阶段性的红利,但是这个不是持久的。所以我其实我的观点是流量不是万能的,但是没有流量却是万万不能的。 那么饿了么还有没有机会?我认为是有的,但是需要阿里给到足够的支持。因为纯交易类的平台其实是没有什么特别的壁垒的,如果一定说要有的话,那就是规模和口碑。规模和口碑是可以通过砸钱、花时间去打磨好的。 阿里集团其实并不缺钱,甚至可以这么说,它最不缺的就是钱了。那么它到底缺什么呢?我觉得一方面是缺对这个业务足够的重视,如果真正重视,应该投很多的钱去发展这个业务。如果你认为这个业务非常重要,但是显然没有做到。除了这方面之外,我觉得还是对这个行业或者说这个领域缺尊重,缺敬畏之心,缺打磨业务的耐心。 当团队每个人都在关注自己能不能在老板面前刷存在感、刷印象分,然后关注自己的绩效奖金远远多于真正产品带来的价值的时候。当员工都在做着各种形式主义的事情,没有问题也要创造问题,让自己显得很忙碌、不可替代的时候。当绝大部分人都只关注半年到一年的收益的时候,这个产品其实是没有办法去打动人心的。这个就又回到了我前面说的那个观点,就是创始人和创始团队对一个产品的至关重要的价值。 有的时候我们其实还是把问题搞得太复杂了,其实没有那么复杂。群众支持谁,谁就能赢,这个是自古以来不变的一个真理。如果你在竞争中落后了,那么一定是你的投入没有竞争对手多,那可能不是一天、一周甚至一个月的投入,更是长期积累以来的投入。这个投入不仅仅是说钱的投入,当然了,钱是很重要的一个方面。 我觉得饿了么它是处在一个不好也不坏的环境里面。不好也就是说它可能没有得到那么多的资源投入。不坏是说它相比创业公司,生存的紧迫感没那么强,因为背靠阿里这棵大树,一时半会儿倒不下来。那这样的话短期之内,员工的拼劲就没有办法体现出来。我的观点是温室里的花朵是没有办法和恶劣环境中成长起来的 “战狼” 去拼的。 这个时候我想到另外一个问题,就是同样是做电商平台的京东杀向了外卖的领域,此前做线下不做线上的美团也做起了线上电商,抖音也在冲锋陷阵。而阿里此时此刻 all in AI ,感觉不聊 AI 都没办法聊天了。 这个决定到底是对是错?我自己的观点是,AI 的方向是对的,但是 AI 也不是全部,甚至对于电商业务来说,连主要的都算不上。电商的本质就是人和人之间的交易。除非将来完全实现 AI 生产、制造、AI 发货、AI 运输,人更多地作为消费者的角色,而不是生产者和服务者存在,我认为才会对电商的模式有非常大的颠覆。除此之外,不至于影响到当下的电商的市场格局。我认为外卖的这个领域,仍然是一场用王兴的话来讲就是无限的游戏。 那饿了么也在牌桌上面,能不能加入牌局,打好自己手上的筹码呢?另外,东家能不能给比较充足的筹码呢?这个我觉得后面还是要再看看。然后这是一场赚钱和花钱的较量。目前我判断其实已经进入到决赛圈了,让我们拭目以待。 本文由人人都是产品经理作者【李明Bright】,微信公众号:【李明Bright】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。 题图来自Unsplash,基于 CC0 协议。
 机核 · 单梦蛙
机核 · 单梦蛙 《赛马娘 Pretty Derby》国际版宣布将于6月26日登录PC平台(Steam)、iOS平台(App Store)和Android平台(Google Play)上线,预先注册将于4月28日开始。  其国服 《闪耀!优俊少女》于2023年8月30日正式推出,但目前已经有相当长的时间没有进行更新,并且无法在其国服代理B站处进行下载。 需要注意的是,游戏的Steam版锁国区。 <内嵌内容,请前往机核查看>

该内容解答了:<span data-report-tagid="span-48-span---0" lang="EN-US">arkxtest自动化测试框架的实现原理。 

据斯坦福大学HAI团队统计,2010年至2023年期间,全球AI专利数量从3833件,激增至12.2511万件。仅2024年,全球AI专利量增长接近30%。

北京亦庄4月27日宣布设立北京亦庄北工智造股权投资基金合伙企业(有限合伙),首期规模达3亿元,主要投向亦庄机器人和智能制造产业。

<blockquote><p>支付巨头们纷纷布局订阅支付领域,试图通过技术创新和业务拓展来抢占市场份额。本文将深入探讨订阅支付的业务流程、风控要点、技术实现方式以及主流支付平台的接口对比分析,帮助大家全面了解这一支付领域的竞争格局和发展趋势。</p> </blockquote>  目录概览 - 主要参与方 - 典型信息流 - 风控与合规要点 - 案例:微信支付周期扣费产品业务流程 - 商户接口调用process - 订阅支付的UML流程概览 - 主流竞品接口对比分析 ## 主要参与方 - **用户**:就是你我这样的消费者,想订阅个服务,比如会员、自动续费啥的,就得先发起请求,授权支付方式(比如绑卡),然后等着接收扣款通知。 - **商户**:就是提供那些订阅服务的商家,比如视频网站、软件开发商。他们得配置好订阅计划,等收到支付结果后,就给你开通服务。 - **支付公司(聚合支付平台)**:这帮家伙就像是支付界的“中间人”,把各种支付渠道都集成起来。他们得处理订阅的那些事儿,比如周期性扣款、扣款失败了咋办,还得负责资金清算和对账。 - **银行/卡组织**:他们是“真金白银”的搬运工,负责实际的资金划转,还提供代收付接口和风控支持。 - **第三方服务商**:比如 WildCard(虚拟卡)、Stripe(支付网关)这些,他们在一些特定场景下,给支付能力“加把劲”。 ## 典型信息流 ### 订阅发起阶段 用户(就是你咯)在前端页面上选好订阅计划,然后授权支付方式(比如填个虚拟卡信息)。 支付公司就会调用银行或支付网关的 API,生成一个订阅协议(比如 PayPal 的 Billing Agreement),顺便把扣款周期和金额给记下来。 商户收到订阅 ID 后,就会给你开通服务权限,你就能开始享受服务啦。 ### 周期性扣款阶段 到了该扣款的时候,支付公司就会按周期触发扣款请求,通过银行或卡组织把钱划走。 扣款结果会通过 Webhook 通知商户(成功了就继续服务,失败了就提醒一下,具体细节流程见下文:订阅支付UML流程)。用户(还是你)会收到扣款通知,还能通过支付公司或商户平台管理订阅状态,比如查看、修改或者取消订阅。 ### 异常处理阶段 **支付失败**:系统会自动尝试重试,要是还是不行,就暂停服务。这时候,得把失败原因(比如余额不足、风控拦截)记录下来,并且通知用户(还是你)。后续如能扣到款是否支持恢复服务? **取消订阅**:要是用户(你)不想订阅了,发起取消请求后,支付公司就会终止扣款计划,并且把状态同步给商户。 **业务方面:** 如扣款周期已过,仍然没有扣款成功,是否立即停止用户的服务,具体业务场景措施肯定不同? **更改订阅计划:** - 正好在扣款等待期更改订阅计划,如订单金额和周期,如何处理。 - 扣款等待期是否允许修改,或者是否需要定义扣款等待期的变更计划下月生效? **Webhook消息丢失** 商户系统检测到订阅一直处于pending状态(超过30分钟)。 调用支付平台提供的「订阅状态查询接口」主动补偿: <blockquote><p>GET /v1/subscriptions/{subscription_id}</p> <p>Response:</p> <p>{</p> <p>“status”: “active”,</p> <p>“last_payment_time”:</p> <p>“2024-05-20 14:00:00”</p> <p>}</p></blockquote> 根据查询结果更新本地状态,并补发用户通知。 ### 风控与合规要点 - **反欺诈**:支付公司会结合 IP 检测、交易行为分析(比如有没有高频小额扣款这种异常行为)来拦截异常交易。像 WildCard 这种,还会针对高风控平台(比如 OpenAI)优化支付渠道。 - **数据隐私**:大家都得遵循 GDPR 这些法规,把用户支付信息加密存储好。尤其是虚拟卡服务,得注意别让敏感信息泄露(比如 WildCard 就没有 KYC 选项)。 - **资金存管**:支付公司要和银行合作,实现资金分账,确保商户结算合规,别出现什么二清风险。 ## 案例:微信支付周期扣费产品业务流程 下发扣费前通知后,在约定时间内: - 若用户拒绝续费,**可关闭扣费服务** - 若用户接受续费,则无需额外操作 注意:目前支持通知后24小时自动扣费、或提前使用独立的通知接口两种模式。(**支付中签约:pay/contractorder是独立接口,以下扣款规则只适用于申请扣款接口:pay/pappayapply,两种模式只能二选一)**  ## 微信周期扣费商户接口调用流程 1)商户在1号调用预扣费通知。 2)2号为扣费等待期,商户不可扣费,用户可随时关闭。 3)3~9号共7天为可扣费期 - - 扣费期内仅在每天7:00~22:00期间可以发起扣费 - 扣费期内可多次尝试扣费 - 扣费期内实时扣费 - 扣费失败用户无感知 - 扣费成功后用户可收到扣费凭证,扣费成功后,当前周期提前结束 ## 订阅支付的实现方式 ### 1. 技术集成方案 - **支付SDK/API对接**:通过**集成支付网关**(如Stripe、PayPal)或**银行提供的订阅接口,实现周期性扣款**。例如,Laravel Cashier通过Stripe API管理订阅计划,支持创建、取消订阅及处理失败支付。 - **智能合约与区块链**:基于Cardano的Revuto平台利用智能合约自动执行订阅扣款,用户可通过质押代币(如REVU)或稳定币(EURR)支付,同时引入DeFi借贷功能降低费用。 - **虚拟卡解决方案**:针对跨境支付场景,WildCard等虚拟卡服务支持绑定国际订阅平台(如Patreon、ChatGPT Plus),通过支付宝/微信充值,规避国内银行卡限制。 ### 2. 核心功能模块 - **订阅计划管理**:支持灵活设置周期(月/季/年)、价格阶梯及试用期,例如PayPal需提前24小时创建订阅协议并设置首次扣款费用7。 - **支付失败处理**:自动触发邮件提醒、重试扣款或冻结服务,需结合Webhook接收支付状态通知(如PAYMENT.SALE.COMPLETED)7。 - **合规与用户通知**:根据《消费者权益保护法实施条例》,需显著提醒自动续费条款,并在扣款前通过多通道(短信、邮件)通知用户 ## 主流竞品接口对比分析 ### Stripe订阅支付接口 **接口功能**:支持创建订阅计划、周期性扣款、试用期设置及失败重试。 **核心请求参数**: - customer(必填):用户唯一标识,需通过创建客户接口获取。 - items[price](必填):订阅计划价格ID,需预先在Stripe后台配置。 - payment_behavior:控制首次扣款行为(如允许失败后自动重试)。 - trial_period_days:试用期天数。 **响应参数**: - id:订阅ID,用于后续管理。 - status:订阅状态(如active、past_due)。 - current_period_start/end:当前计费周期起止时间。 **调用流程**: - 用户选择订阅计划并授权支付。 - 商户调用POST /v1/subscriptions创建订阅。 - Stripe验证支付方式并生成首次扣款。 - 商户通过Webhook接收invoice.payment_succeeded事件更新订阅状态。 ### PayPal定期付款接口 **接口功能**:支持固定周期扣款、账单协议管理。 **核心请求参数**: - plan_id(必填):订阅计划ID,需通过产品创建接口生成。 - subscriber:用户信息(如邮箱、姓名)。 - application_context:定义支付流程的返回URL及取消页面。 **响应参数**: - subscription_id:订阅唯一标识。 - status:状态码(如APPROVAL_PENDING、ACTIVE)。 - links:包含用户授权支付的跳转链接。 **调用流程:** - 商户调用POST /v1/billing/plans创建订阅计划。 - 用户通过授权链接完成支付授权。 - PayPal通过Webhook通知商户激活订阅。 - 周期性扣款自动执行,商户监听PAYMENT.SALE.COMPLETED事件。 ### 支付宝自动扣款接口(alipay.fund.auth.order.app.freeze) **接口功能**:基于预授权协议实现定期扣款。 **核心请求参数**: - out_order_no(必填):商户订单号,需唯一。 - auth_code:用户授权码(通过扫码或SDK获取)。 - product_code:固定为PRE_AUTH。 - amount:预授权金额。 **响应参数**: - auth_no:支付宝资金授权号。 - status:授权状态(如SUCCESS)。 - gmt_trans:授权时间戳。 **调用流程**: ### 微信支付合约支付接口 **接口功能**:支持按周期或按次扣款,适用于会员订阅。 **核心请求参数**: - contract_id(必填):签约协议号,通过用户授权获取。 - body:订单描述(如“月度会员费”)。 - total_fee:扣款金额(单位:分)。 **响应参数**: - transaction_id:微信支付订单号。 - time_end:支付完成时间。 - trade_state:交易状态(如SUCCESS)。 **调用流程**: ## 接口文档设计关键点 ### 幂等性处理 - **Token机制**:通过唯一请求ID(如idempotency_key)避免重复扣款,需在请求头或参数中传递。 - **数据库约束**:在扣款逻辑中使用update … where status=unpaid确保仅处理一次扣款。 ### 有容错能力的序列设计 <blockquote><p>用户 -> 商户系统: 选择订阅计划并支付</p> <p>商户系统 -> 支付平台: 调用创建订阅接口(携带idempotency_key)</p> <p>支付平台 -> 支付平台: 校验幂等性(通过idempotency_key)</p> <p>支付平台 -> 银行: 验证支付方式并扣款</p> <p>alt 扣款成功</p> <p>支付平台 –> 商户系统: 返回{“code”:0, “subscription_id”:”sub_123″, “status”:”pending”}</p> <p>支付平台 -> 商户系统: Webhook发送PAYMENT_SUCCESS事件</p> <p>商户系统 -> 商户系统: 更新状态为active,开通服务</p> <p>商户系统 -> 用户: 发送成功邮件</p> <p>else 扣款失败</p> <p>支付平台 –> 商户系统: 返回{“code”:2001, “message”:”余额不足”}</p> <p>支付平台 -> 支付平台: 记录待重试任务(定时触发)</p> <p>loop 重试逻辑(最多3次)</p> <p>支付平台 -> 银行: 重试扣款</p> <p>alt 重试成功</p> <p>支付平台 -> 商户系统: Webhook发送PAYMENT_SUCCESS事件</p> <p>else 重试失败</p> <p>支付平台 -> 商户系统: Webhook发送PAYMENT_FAILED事件</p></blockquote> 本文由 @支付唧唧咋咋 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
 雷峰网
雷峰网 作者|包永刚 编辑|王亚峰 雷峰网独家获悉,国内某互联网大厂芯片团队的高级别员工DZ已于近期离职。他是团队中为数不多的高职级成员之一,也是CPU团队的负责人。 公开信息显示,DZ在芯片行业拥有超过25年的从业经验,尤其在CPU领域积累了深厚的技术背景。他曾在英特尔和MIPS任职,在加入这家互联网公司前,担任华为的首席架构师,主导Arm处理器的研发工作。 自2019年加入该互联网公司的芯片团队之后,DZ一直是芯片团队的核心成员。在他的带领下,该互联网公司迅速研发并推出了自研CPU产品,赢得了业界的广泛认可。 有消息人士透露,DZ离职可能与该芯片团队当前面临的挑战密切相关,这一挑战在中美科技博弈背景下,成为了国内大芯片企业普遍面临的困境。 雷峰网此前也了解到,该互联网公司在下一代CPU产品的迭代决策上表现出一定程度的犹豫,这也可能与DZ的离职有关。 虽然目前尚不清楚DZ的下一步去向,有业界人士猜测DZ可能会加入另一家互联网公司的芯片团队。 但考虑到他在业内的资历与级别已属顶尖,若选择加入其他公司,可选空间非常有限,如果是创业,在资本市场整体趋冷的背景下面临不小挑战。 互联网公司芯片团队高层的变动,会引发哪些组织结构变动?更多信息欢迎添加作者微信BENSONEIT交流。
 36氪
36氪**文|邓咏仪** **编辑|苏建勋** 大模型的风,如今又刮到了一个新名词上:MCP。 AI圈中不缺新鲜事,但这次不一样,互联网仿佛又回到了十多年前的春天。**“现在,基于MCP开发智能体,就像2010年开发移动APP。”**4月25日,百度董事长李彦宏在百度Create大会上说到。 如果还没有听过MCP,但你肯定听过上一个热词:Agent(智能体)。2025年初,中国初创公司Manus的爆火,把这个名词瞬间推到了大众面前。 “真·能干活的AI”,是Agent爆火的关键。在这之前,大模型可以答疑解惑,但它只是一个简单的对话窗口,依赖于模型接受过的训练,大模型内的数据往往不是最新的,如果只有大模型本体,调用外部工具,要经历非常繁琐的过程。 MCP这个概念,就和Agent密不可分。**MCP是Agent愿景得以实现的的重要路径——大模型可以自由地调用支持MCP协议的外部工具,完成更具体的任务。** 现在,包括高德地图、微信读书在内的应用,就已经纷纷推出官方的MCP Server(服务器),这意味着,所有开发者都可以像搭积木一样,先确定自己用什么大模型,而后调用高德地图、微信读书的MCP服务器,大模型就可以完成查询地图等等任务。 从2月开始,一场MCP浪潮已经如火如荼地席卷全球。 几乎所有大厂—— OpenAI、谷歌、Meta,以及国内的阿里、腾讯、字节、百度等等,纷纷宣布支持MCP协议,也都推出了自家的MCP平台,邀请各路开发者、应用服务商进驻。 如果复盘2024年国内AI领域讨论得最火的名词,“超级应用”肯定算其中一个。人们普遍认为,2024年会迎来AI应用的大繁荣,但并没有如预期般快速发展。AI领域的创新生态,更多还是星星点点地散落在各处。 正因如此,MCP的爆火,不亚于春秋战国时期,秦始皇一扫六合的意义——统一各国的书写、交通、度量标准,从而大大方便了经济和商品往来。 不少市场评价认为,随着MCP等协议逐渐成为共识和趋势,2025年会迎来一场真正意义上的AI应用大爆发。 ## **MCP,AI的“超级外挂”** 事实上,MCP并不是一个新事物,早在2024年11月,就已经由Anthropic宣布推出。 MCP的全称是“Model Context Protocol”,即模型上下文协议。这是一项开放标准,基于大模型的应用如果支持了MCP协议,就像学会了一门标准化“语言”,和外界的数据源、工具等等进行互动。 如果你觉得这个解释依然复杂,那么可以看看手机、电脑上的数据接口——MCP相当于给大模型装上了一个“万能插座”,定义了一个标准的“USB接口”。 有了这个接口,开发者得以有章法地,在更标准化的框架和约定下进行应用开发,对接不同的数据源和工作流。 在MCP成为趋势之前,开发AI应用的门槛一直在高位。 如果一位开发者想开发一个AI旅游助手,需要让大模型至少完成几项工作:查看地图、在网络上查找攻略、结合用户需求撰写一份新的旅游计划。 那么,为了让大模型顺利能够查询地图,在浏览器上查找现有的攻略。开发者所经历的开发过程是这样的: 首先,每个AI提供商(OpenAI、Anthropic等)对Function Calling的实现略有���同。如果中间涉及两个大模型的切换,那开发者还需要为不同模型重写适配代码,相当于帮大模型写一个外部工具的“使用手册”,大模型才能学会用更好的Prompt调用外面的工具。否则,模型输出的结果准确度会直线下降。 简单总结,就是大模型在和外界交互时,缺少统一标准,导致代码复用性太低。AI应用生态的发展就会自然滞后。 “对于任何一个大模型应用开发者,在MCP出现之前,开发者不仅需要懂大模型,也需要自己做二次开发,把外部的工具嵌入到自己的应用中。并且,工具的性能如果不好,开发者自己还需要去研究,究竟是应用本身的问题,还是工具的问题。”阿里云魔搭社区算法技术专家陈子谦对《智能涌现》等媒体表示。 Manus也是一个典型例子。不久前,《智能涌现》也曾对Manus进行测评,哪怕只是写一篇简单的新闻,Manus很容易就需要调用十多种工具,比如开启浏览器,浏览和抓取网页、进行写作、验证和交付最终结果。 在每个环节里,如果Manus选择要调用外部工具,那么就需要编写一个“函数”,用来安排外部的工具如何运行。结果就是,Manus常常因为任务过载而中止任务,也是因为单个任务所消耗的Token太多了。 **但在MCP之后,最核心的转变就是:开发者不需要对外部工具的性能负责,只需要对应用本身做维护和调试,大大减少了开发工作量。** 相对应的,生态中的一个个单点Server,则会维护好自己的MCP服务——比如支付宝、高德地图等等应用方,维护好自己的MCP服务器,更新到最新版本,等待开发者来接入即可。 不过,MCP生态还相当早,现在也远不是一个完美方案。已经有不少开发者表示,MCP有点为建标准而建——API也许是更简洁的方案。而如果MCP服务器并非官方推出,也没有人精心维护,那么接入MCP的的安全性、服务稳定性也不容乐观。 尽管如此,MCP可以说是第一个真正意义上爆火出圈的调用工具协议,它的效应也在快速显现。据MCP社区PulseMCP统计,全球已经有超过4000个MCP服务器上线,而这一数字还在迅速增长中。 **但在MCP之后,最核心的转变就是:开发者不需要对外部工具的性能负责,只需要对应用本身做维护和调试,大大减少了开发工作量。** 相对应的,生态中的一个个单点Server,则会维护好自己的MCP服务——比如支付宝、高德地图等等应用方,维护好自己的MCP服务器,更新到最新版本,等待开发者来接入即可。 **听上去很理想,但MCP生态还相当早,现在也远不是一个完美方案。** 已经有不少开发者表示,MCP有点为了建立标准而建——在那之前,API已经是更简洁的方案了,大模型也已经可以通过很多协议调用API,MCP有一种画蛇添足之感。 现在大公司们发布的MCP服务,基本都由厂商自己定义,可以被LLM调用什么功能,以什么样的方式调度。但同样的问题也会出现在MCP上——大公司很大概率不会把最核心、最实时的信息给你。 而如果MCP服务器并非官方推出,也没有人精心维护,那么接入MCP的的安全性、服务稳定性也不容乐观。 独立开发者唐霜就分享了自己遇到的案例:某度地图的MCP Server,工具不足20个,有5个要求传入经纬度,再来一个查天气,要求用户提供行政区划ID来查询天气,但却没有提供如何获取这些ID的方法或文档。解决方案只能是用户回到这一服务商的生态中,按部就班获取信息与权限 如此看来,MCP的爆火只是表面,但背后的博弈远未结束——大模型厂商虽愿意提供MCP服务,但主动权仍然抓在厂商手中,没有人愿意为Anthropic的生态做嫁衣。如果没有心思好好提供服务,开发者反倒要做双倍的工作,这个生态的逻辑也不会存在。 ## **开放路线的再一次胜利** 不过,为什么MCP现在才火起来? 在Anthropic刚推出MCP协议的初期,其实关注者寥寥。当时,只有有限的应用支持MCP协议,比如Anthropic自家的Claude Desktop。开发者们也没有形成一个统一的AI开发生态,基本属于各自闭门造车的状态。 **是因为开发者群体的接纳,MCP才开始慢慢走到舞台中心。**2025年2月开始,AI编程领域的一众明星应用——包括Cursor、VSCode、Cline等等,纷纷宣布支持MCP协议,这让MCP协议声名鹊起。 在开发者群体中掀起声浪之后,真正引爆MCP协议的,是大模型厂商们的接入。 关键性的一步,无疑是3月27日,OpenAI宣布支持MCP协议,紧随其后的则是Google。 Google CEO 桑达尔·皮查伊曾在X上表达过对MCP的纠结。3月31日,他发了条推特,表示:“接入MCP还是不接入MCP,这是个问题。”但发完这条推特短短4天后,Google也宣布接入MCP。 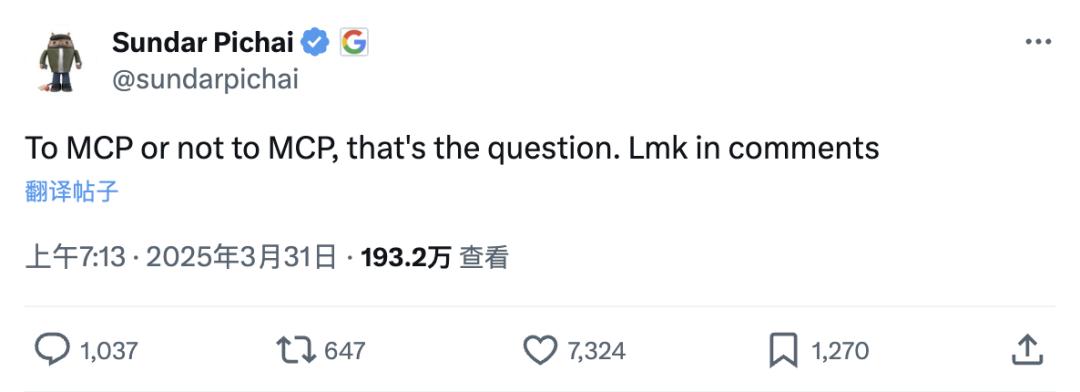 △来源:X(Twitter) 大厂们最终都选择拥抱MCP,这和DeepSeek冲击硅谷的故事异曲同工:接入MCP,本质上也是大模型厂商在生态战略上的转向——**与其各自为政,不如求同存异,拥抱一套更开放的协议,集体把蛋糕做大。** 过去两年中,大模型厂商在AI战略的布局上,往往都还是想圈占地盘为主。这个逻辑和互联网的发展历史别无二致,比如苹果,成为平台厂商,建立起强大的开发者生态,而非单纯提供单点的产品服务,才能逐步建立起垄断性的优势。 OpenAI也是学着苹果这么做的。 在接入MCP协议之前,OpenAI开发者生态的路线,总体从开放逐渐走向封闭。ChatGPT Plugins在2023年3月上线,当时的Plugins,还允许第三方开发者为ChatGPT添加特定功能,也支持同时使用多个插件,是一个较为开放的扩展生态系统。 但在2024年1月推出GPTs及商店后,OpenAI很快终止了Plugins的服务。GPTs被设计成一个更封闭的商店模式——GPTs只能在OpenAI平台上运行,从模型到应用全部由OpenAI控制,通过平台抽成获利。而开发者也需要针对ChatGPT这一个平台开发,开放程度相当有限。 截至目前,OpenAI的GPTs生态效果并不如人意,商店中充斥着大量低质的简单套壳应用,商业化闭环也远未跑通。 Anthropic的MCP协议,很多思路也并非行业首创。OpenAI推出的Function Calling,其实同样是大模型调用外部工具的一个主流标准,MCP的许多技术思路,也和Function Calling一脉相承。 但MCP在产品层面做得更用户友好。Function Calling的问题在于,开发者还需要做二次编程和大量的适配工作,但MCP让服务方将这些需求打包成一个个的“乐高积木”,大大降低了AI应用的开发门槛。 而且,MCP还拥有一个最核心的优势:它更开放、抽象程度更高。MCP只是一个网络协议,并且没有对底层的模型作限制,任何AI模型或平台,都可以基于MCP进行交互,也适用于云端或本地的多种部署形式。 MCP足够开放,也并不会让任何一家大厂独大,这大厂们都能找到一个比较舒服的位置和心态,接入这套协议。 某种程度上,这也是Anthropic用更开放的姿态,以夺回开发者生态的尝试——OpenAI的封闭战略,则再一次被证明是战略上的误判。对于仍处早期的前沿科技行业而言,从DeepSeek到如今的MCP,无一不告诉我们:开放、开源的路线,依旧是当下的最优解。  欢迎关注  欢迎交流 本文来自微信公众号[“智能涌现”](https://mp.weixin.qq.com/s/cIEveJ87hhMjlgoZR_rAGw),作者:邓咏仪,36氪经授权发布。
极氪与领克合并后,吉利集团在上海车展上又公布了一项重大合并举措——整合电池业务。 36氪了解到,吉利控股集团旗下电池业务已经完成战略整合,正式成立浙江吉曜通行能源科技有限公司(以下简称“吉曜通行”)。 原有的金砖电池、神盾短刀电池,统一成为神盾金砖电池品牌,实现吉利自研自产电池安全系统与电芯产品的“强强合体”,神盾代表吉利极致的电池安全系统,金砖代表吉利行业领先的电芯技术。  神盾金砖电池 整合后,吉曜通行将一跃成为行业内目前短刀产能最大的电池公司,目前已在全国构建覆盖6大生产基地的智能化制造网络。 在吉利集团董事长李书福发布《台州宣言》后,整合已经成为了吉利集团的主旋律。未来吉利集团要形成两横七纵的战略布局。 两横指的是纳入极氪和领克的极氪科技集团,极氪向上,领克向宽;几何、翼真并入银河,雷达并入吉利汽车,全面走向面大众市场。 七纵则是整车架构、电子电气架构、智能驾驶、智能座舱、电驱系统、动力电池、超级电混的七大领域深化协同。这次电池业务的整合,就是七纵布局的其中之一。吉曜通行将聚焦磷酸铁锂短刀电池路线,未来为吉利集团的各个品牌、各个车型提供电池产品。 本次车展上,36氪与吉利控股集团副总裁兼CSO郑鑫聊了聊。他向我们阐述了这次整合的过程以及未来吉曜通行的发展规划。 ### 全方位整合电池业务,降本增效 在《台州宣言》之后,吉利集团旗下各车型子品牌的研发、采购等便开始逐步整合,电池业务的整合也一直在酝酿之中。 郑鑫介绍到,这次整合并非单纯的品牌整合,而是全链路地涉及到了集团内与电池相关的所有业务、人才、产能基地等。整合的形式是全面的合并,已经开展了3-4个月,研发、供应链体系都已经整合完毕。 吉曜通行将整合吉利旗下所有与电池相关的资产,包括耀宁、极电、耀能等多家电池公司,未来或还将管理吉利跟宁德的合资公司,以及吉利跟欣旺达合资的公司。 “目前管理工作已经完成整合,整合后,吉利的电池业务将只有一个主体。”郑鑫说。 吉曜通行目前主要电池产品为金砖电芯,聚焦磷酸铁锂路线和短刀形态,将优先服务极氪品牌。同时,吉曜通行也会将短刀电池应用到吉利汽车的战略车型上,比如银河E5,实现短刀平权。“目前,行业内仅在更高端的品牌或车型上使用短刀电池,因此我们提出了“短刀平权”的理念。”郑鑫表示。 在产品规划上,吉曜通行的目标还是聚焦爆款。据郑鑫介绍,目前吉曜通行电芯产品规划不超过十款,每款单一产品平均下来至少要有5GWh的产能。“整体战略是做好细分赛道上的爆款电芯,体现成本竞争力、性能竞争力。” 当前,吉曜通行短刀产能占其动力电池总产能的90%左右。 作为吉利控股集团内部的电池公司,吉曜通行也会让吉利旗下车型具有更大的成本和价格优势。能做到更低价格一方面是内供的优势,另一方面则是吉曜通行整合和优化供应链来降低成本,提升产品质量和竞争力。 郑鑫举了一个例子,“我们也在往上游走,比如磷酸铁锂,若采用普通二烧方式增加产能,成本可能增加两三千,而新建产能时加长炉子,成本则只需一千多。” 通过对电池业务的整合,吉利控股集团未来将拥有更具成本优势,且电池规格更标准化的电池产品。这样可以让制造业的规模效应最大化,做到良性循环。 ### 用神盾金砖电池,推动安全平权 “神盾金砖电池”品牌,以神盾代表安全系统,而电芯则统一为金砖电芯,下设超级快充版、高能量密度版和超级混动版。超级快充版主要针对800V以上高压架构;高能量密度版则主要针对400V架构;超级混动版将既有800V,也有400V,以满足不同市场需求。 将金砖电芯与神盾系统整合,安全性能得到了最大的提升。郑鑫说,“安全是首要考虑的因素,无论是在3万块钱的车还是100万的车,安全都是最重要的。” 未来,吉利集团将标明哪些车型使用了金砖电芯,哪些车型使用了神盾系统,由于吉利也有外购的情况,也会向用户讲清楚神盾系统内用了哪家企业的电芯。“不管用谁的电芯,我们的系统安全是一以贯之的。”郑鑫说。 同时,吉曜通行的电池规格也将主攻短刀,搭配磷酸铁锂体系,可以兼顾安全、体积利用率和成本,也可以做到郑鑫所说的“短刀平权”、“安全平权”。 短刀电池也是这次快速整合的助力之一。据郑鑫介绍,三年前,耀宁与极电就决定一起做短刀电池,在技术路线和内部管理上达成了共识。因此,这次合并,产线几乎没有浪费,直接形成了行业内最大的短刀产能。 合并后,吉曜通行也会不断提升短刀的能量密度、快充能力和寿命,根据市场需求,推出不同性能的产品,以满足不同客户的需求。 在对内供应上,吉曜通行的目标是:未来两年上升到30%。 他认为,要做到30%的供货比例有两个理由,一是规模问题,这影响成本;另一个则是产能利用率和产线良率,这更为重要。 郑鑫介绍到,在爆款爆品方面,吉曜通行已经有了很好的实践,例如在盐城基地,一款电芯就能拉满整个工厂,从长期来看是稳定的。这不仅实现了成本最优,而且在品质和稳定性上也表现出色,因为无需频繁切线,能够稳定地交付。 目前,吉曜通行跟吉利还有不少车型在适配过程中,因此后续增量会很快,不过这也取决于吉曜通行的产能爬坡速度。 当然,吉曜通行未来也不会做到100%独供吉利。吉利的供应链策略一直是开放的,不管是新能源时代的电池、还是燃油车时代的关键零部件,都是如此。 郑鑫说:“吉利不会完完全全做自己垂直的、封闭的、一体化的零部件产业,吉曜通行和包括宁德在内的电池公司会保持非常良性的合作与竞争关系。而且我们未来也会走出去,向全球输出领先的产品技术解决方案、品牌、供应链生态和工程服务能力。”

文丨果脯 4月13日,《永劫无间》公众号发布了玩家直面会的招募推文。 推文中提到,自3月开始游戏社区传出了不少失望的声音,工作室的想法和玩家的需求出现了偏差,工作室将进入“紧急状态”,认真聆听玩家的声音。 这也是《永劫无间》的真实现状。自年初开始,游戏的平均在线人数就在逐渐下降,即使它两个月前宣布入选亚运会电竞项目,也仍旧无法挽救数据下跌的趋势。 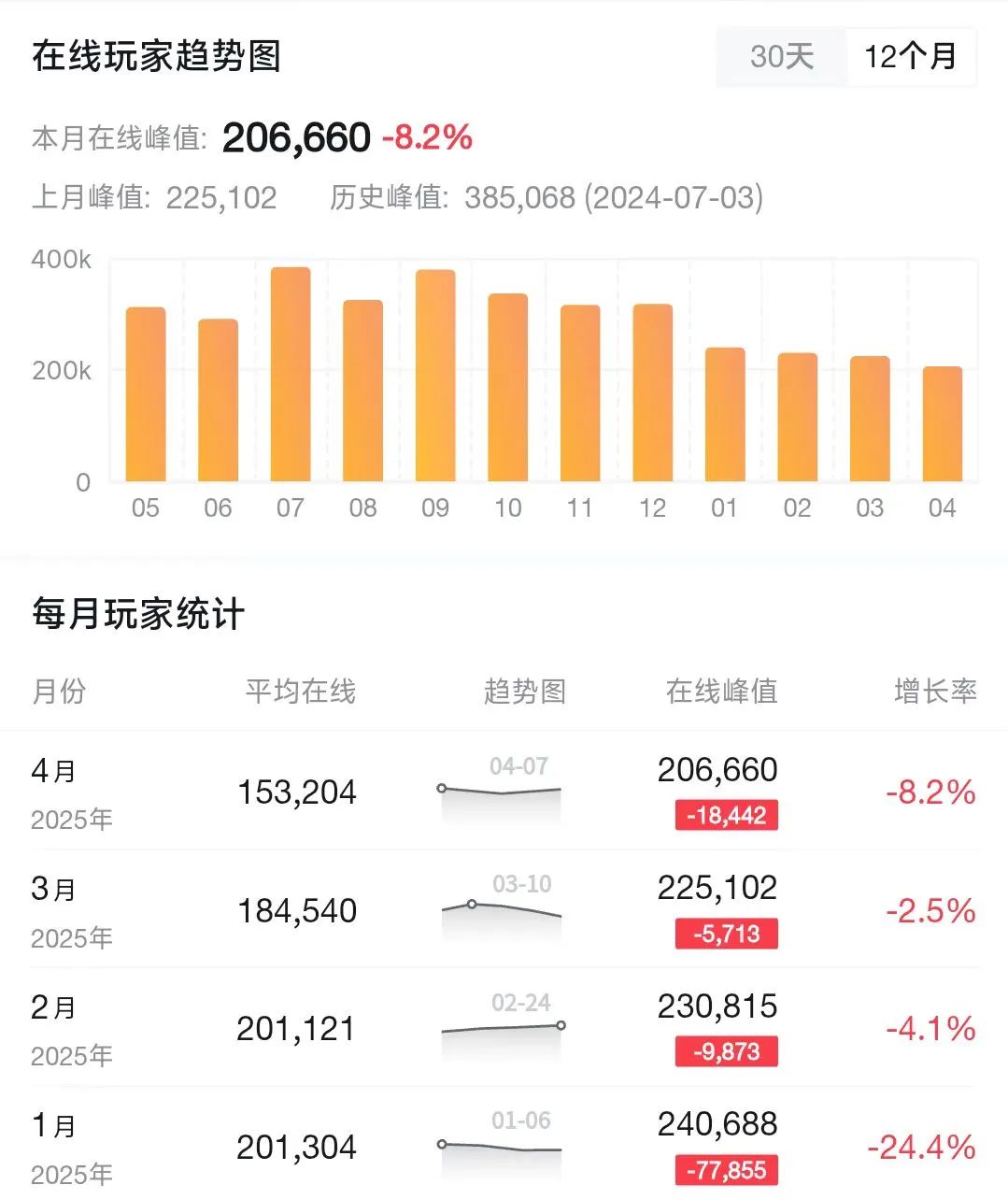 数据来源于“小黑盒”App 这两个月来,我刷到了不少指责《永劫无间》的视频,有人抱怨策划不做事,有人指责版本没内容,还有人已经开始直接宣泄负面情绪。偶尔开黑,我也能从朋友口中听到对游戏的不满。 偶尔好不容易看到一个帮忙说话的,往下一看本质是在玩卖号梗。  出号梗 每个人心中此刻想必都会冒出这个疑问,包括我。毕竟昔日《永劫无间》上线时,3个月卖出600万份,不到1年销量就突破千万,创下了国产买断游戏的新纪录,一时也是风光无两。 我在网上也看到过不少推测。比如有人认为工作室现在的重心完全放在了手游上,有了更挣钱的二胎,端游自然失宠了;有人觉得是最近官方过分关注一些看似性价比更高的内容,用博眼球的做法维持游戏内容,反而丢掉了初心。 作为开服玩家,我不禁回顾自己过去600多小时的游戏经历,这两天才终于想明白这个问题——24工作室现在需要解决的问题,可能从游戏一开始就存在,**即《永劫无间》的长线迭代到底该怎么做。** 这个问题得从游戏的玩法迭代聊起。 《永劫无间》的核心框架,可直接分为动作博弈、英雄设计和大逃杀玩法三部分。经过3年的迭代,这三者的比重逐渐转变、失衡,才导致游戏体验也慢慢变得跟最初截然不同。 其中,动作博弈是《永劫无间》最底层的玩法架构。它使用的是格斗游戏设计思路,并在操作层面做了大量简化,即采用“剪刀石头布”的模式。在对战时,玩家往往需要围绕普通攻击、蓄力攻击和振刀三者之间互相克制的关系,进行反复的出招博弈,从而获得战斗优势。  振刀 在这种模式下,格斗游戏的门槛大幅度降低,初上手的玩家也能迅速享受到博弈的乐趣。 同时,高熟练度的玩家也依旧能基于自由的战斗场景、技能、战斗技巧,尝试更多的战斗可能性。比如玩家们经常提起的主播“克烈”,就凭借对重刃武器的深度、英雄技能理解,以及超高的远程武器熟练度,打过许多惊为天人的操作。  抖音“克烈”的精彩操作集锦 遗憾的是,《永劫无间》这套框架虽好,但在长年缺乏变化和深度研究的情况下,大部分玩家已经找到了个中的漏洞——游戏存在一套不讲道理的博弈通解,那就是闪避和连招。 游戏现在的闪避操作比打出蓄力攻击、振刀等操作的收益高了不止一个档次。最初,闪避的缺点是无法形成有效反例,在博弈选择中最多相当于一个“不亏不赚”的选项。如果操作得当,玩家甚至可以闪过对手的所有攻击。 但如果算上连招,其中的博弈逻辑就变了。 最初大家对游戏的研究还没那么深,连招可能还只是限定在“民工三连”,或是中间穿插升龙等攻击。这样一来,受到攻击的玩家不会一直处于僵直无法操作的状态,有继续博弈,试图反击的空间。 而随着“真连”,即能稳定打满输出的连招相继出现,纯粹的剪刀石头布收益降低,变成了互躲伤害抓僵直。比如最基础的连招“钩索百裂”,就能稳定打出一次普通攻击、一次升龙和一次蓄力伤害。离谱的时候,玩家还可以一套连招直接击败对手。 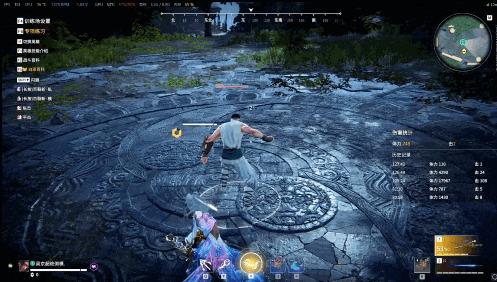 钩锁百裂 当然,格斗游戏存在连招本身很合理,也很正常,连招也相当于玩家深度训练后收获的成果。但如今连招的重要性早已盖过“剪刀石头布”的博弈收益,最明显的案例就是高分段玩家成功振刀后,往往更倾向于借助此次僵直起手打连招,而非使用处决。 《永劫无间》在此暴露的根本问题,本质在于缺乏体系化的战斗动作标准和持续迭代思考,该系统在内部的评判优先级也不高,最终才导致“博弈党”和“连招党”之间的矛盾。 这个情况的一种直接表现,是游戏许多玩法细节很长一段时间都停留在原地,修改动机也相对被动。比如振刀后短闪接处决的设计,能保证玩家振刀后顺利打出处决伤害,在前年底手游试玩会上经由玩家提出后才正式改动。 而全方位振刀设计,则来源于英雄迦南大招引起的争议。改版后,迦南开启大招可以远距离蓄力然后闪现到对手身边释放。尽管它对提升游戏的动作深度有帮助,但一定程度上,这个设计也是回应社区呼声,防止迦南太过无解。  改版后迦南技能 不难看出,动作系统本身在内部评判体系中缺失优先级,这和游戏最初格斗博弈的定位形成了相互矛盾的关系。 “剪刀石头布”的简化体系框架被打破,游戏重新回到了传统格斗游戏拼招式、抓僵直连招的即时战斗模式。而现有的动作系统,又没有丰富深厚到足以撑起大逃杀玩法场景,最终才呈现出了如今基础玩法薄弱的结果。 这个问题官方或许也有感知,比如推出闪避也能保留蓄力的拳刃,可以自由调控攻击方向的飞刀,都是在机制层做新尝试,想用更加多样的武器内容来覆盖玩法。 而与之相对应,更明显的是他们这两年优先将迭代重心放在了英雄身上。 这当然是一种解法。一方面,英雄能丰富游戏的内容背景,给玩家提供更加多元化的选择。而且在长线运营背景下,不断推出新英雄本身就是件“必须去做”的事情。另一方面,足够有趣的英雄技能,也能补齐动作系统薄弱的短板,说白了,持续更新英雄可以保证下限,提高上限。  游戏英雄界面 那么答案自然显而易见——《永劫无间》从最初英雄技能打辅助的定位,慢慢变成了技能为主、动作为辅的模式。 然而,这其中又衍生出了新的问题。《永劫无间》的英雄概念和传统格斗游戏的角色并不一样。在传统格斗游戏中,角色和游戏的玩法、博弈思路息息相关,不同的角色对应不同的连招和解法。每出一个新英雄,就是一套新玩法。 但《永劫无间》不是。它把传统格斗游戏的角色内容,拆分成了武器、英雄两大体系,英雄决定特殊技能,武器决定招式变化。 这点在早期游戏中还好,两者表现相对平衡。当时英雄的技能更多围绕提供控制、治疗回复等效果展开,整体更多偏功能性,输出重心并不算多,整体感受还是动作博弈和武器招式为主。 其中,最接近格斗游戏质感的,就是迦南和季沧海两位英雄。 比如季沧海的大招能提供霸体和精力回复,由此衍生出了“颠勺”玩法,即借助大招提供的精力恢复,不断用太刀升龙挑飞对手,直到对方血条清零。当然,由于这个操作太过无脑且强,季沧海也一度成为玩家游玩的主流英雄。  火男颠勺 而迦南拥有多样化的位移技能,大招还能隐身,与各类身法结合能不断拉扯对手,因此也是高玩比较常用的英雄。 游戏公测后,技能的设计似乎开始转变。比如首个新英雄岳山明显和其他人不太一样,技能的重要性开始直线上升。 同为大招提供“变身”的角色,岳山与开服角色天海的设计逻辑明显不同。后者明显更为笨重,想要造成伤害必须像射击游戏那样瞄准并抓住角色,更大的作用是为队友提供站场威慑。而前者模型更小,不吃僵直,还非常灵活,在多排游戏里能轻松左右战场。因此,时至今日岳山也依旧是多排游戏里比较常见的角色之一。 后续更新的崔三娘,拥有的瞬发强力团控,更是直接催生出了游戏首套无解的“大招流”阵容。玩家使用宁红夜、天海、崔三娘,可以在对手从始至终都无法反抗的情况下获胜。唯一需要的操作,就是崔三娘玩家的大招需要覆盖2个以上的对手。 尽管现在理解闪避重要性的玩家,基本能够借助闪避躲开,防止被一波带走,但大招流阵容,在当时玩家圈子里无疑拥有着绝对的统治力。  一波流的大佛双抓 经此一役,《永劫无间》后续很长一段时间都没有推出大招是强时间硬控的英雄,直到后续的玉玲珑。 而上线后的这些时间里,游戏的英雄技能方向可谓百花齐放。妖刀姬、武田信忠等大招具有强力攻击伤害的英雄接连出现,无尘能够传送队友或对手,殷紫萍为所有人提供一次免死,能在天上乱飞的哈迪,把对手当宝可梦收起来的刘练…… 不可否认,多元化的英雄设计给《永劫无间》提供了很多意想不到的乐趣,但也削弱了动作博弈的占比,算是优劣参半。 基于这点,玩家这两年还创作了一段“战斗口诀”,口诀每段末尾对应英雄大招语音。  口诀 如果英雄设计得足够有趣,那倒还好。但偶尔也会出现一些比较极端的案例,比如经常受到玩家吐槽的季莹莹和张起灵。 他们的大招类似于变身,但英雄形态不会发生变化,机动性没有受到限制,只是替换出一套更加强力的武器——无法被振刀,优先级更高,玩家除了闪避或者短时间逃离战场,基本很难与之形成有效对抗。 在部分玩家眼里,喜欢游玩这两个英雄的人还被打上了“残手党”“拒绝博弈”的标签。 举个极端一点的比喻,那种感觉有点像《守望先锋》里面士兵76的大招(自动瞄准)跑到了《Apex》里面。你当然可以通过卡掩体、卡对手视角,或是用身法拉扯反杀,但不影响它对游戏整体底层玩法逻辑造成破坏。 而这种情况,在上一个新英雄席拉出来后,更是变得无比明显,以至于让不少玩家叫苦不迭。“博弈全赢,因为大招输了”的情况屡见不鲜。 技能主导俨然是游戏目前的核心发展方向。比如最初大家小技能都优先选择“受击”,能提供一次规避连招的机会,但这样一来英雄差异化就无法体现。于是,非受击技能的使用占比在逐渐扩大。  英雄技能 只是,当技能的主导功能越来越强,主流动作玩法持续转变,《永劫无间》最初“剪刀石头布”博弈乐趣,究竟还能剩下多少? 而如果游戏想实现技能博弈和英雄主导,现有的设计似乎又太过薄弱了。大多情况下,同水平玩家不过是在做纯粹的大招互换——你开大,我也开大,或者是你开大,那我就跑。 想不清楚这些问题,《永劫无间》后续的迭代思路恐怕会依旧受限,并且越来越难得抓住玩家的心。这也是他们在玩法迭代中暴露的最根本问题:只是强调不断做出新东西,却缺乏一套足够明确的设计规范限制和迭代思路方向。 核心玩法之外的长线迭代问题,主要来源于《永劫无间》一口气将盘子铺得太大,以团队目前的体量难以支撑。比如他们目前除了推出大逃杀玩法,还设计PvE模式,举办持续性的电竞赛事,以及开发迭代手游。 如此之多板块,细分下来,最终留给《永劫无间》大逃杀PvP部分的又有多少——网上不满的声音,很多都来自这部分玩家,同时他们也是游戏最初起步的基本盘。 站在这部分玩家的视角,游戏上线3年来的变化确实有可圈可点的部分。 比如除了玩法和英雄迭代,游戏的大逃杀地图也在持续推陈出新。这些新地图的设计可圈可点,围绕场景做了很多有趣的设计,比如加入机关陷阱、天气系统、解谜内容,或者是一些场景限定的装备(红甲和红长剑)。  红长剑 2022年11月更新的回阳境机制,更是迄今来看都很完美。它允许两队人能在独立场景中对抗,更是增加游戏的节奏和趣味性。其中,回阳境的胜者会获得限时的强力Buff,而败者会变成“阳虚”状态,如果不能在一定时间内淘汰他人获取返魂花,那么就会当场殒命。 也就是说,参与回阳境对战后,不论胜负,玩家都会更加积极在地图上寻找对手,有效促进了游戏早期节奏慢的问题。 而缺点可能是内容更新问题了。对这部分玩家而言,游戏内容更新无非四点:武器、英雄、地图和活动。 其中,前三者近半年来都依旧保持原来的更新节奏,整体变化不大,而赛季整体的迭代速度也并不慢。真正和玩家当下的游玩体验高度挂钩的,其实是活动内容。 过去几年,《永劫无间》其实推出过不少有意思、有情怀的活动,比如联动李小龙、联动整个武林等等,实打实展现了中国武术文化传承的魅力。在与文涛坊古兵器博物馆的合作中,数百万玩家更是挤爆了文涛坊官网。 2023年周年庆,《永劫无间》还借助物理扫描技术,在游戏的等待大厅“蓬莱岛”还原了整幅《富春山居图》,玩家可以通过乘坐纸鸢,来回观赏。当时直观感受到的文化冲击,恐怕很难用文字直接描述出来。  富春山居图 让我印象比较深刻的,是游戏和《斗罗大陆》、“尼尔”IP等作品的联动。这两次活动除了推出对应角色的外观,还在游戏中额外加入了特殊内容。 比如在“尼尔”联动中,玩家可以通过拾取“月之泪”,与埃米尔交换魂玉。大地图的一些场景,也替换成了月之泪盛开的花田。偶尔在路上捡到的辅助机,还能持续帮玩家恢复护甲。  尼尔联动 而2025年来,游戏不论是文化内容,还是IP联动,似乎都很难比肩游戏过去做出的事情,活动更加集中于“收集道具-获取奖励”的反复循环。既不有趣,也对玩法毫无影响。 这其实也是《永劫无间》在内容迭代层面的困境,只不过当缺乏有趣IP、文化内容的支撑,才彻底暴露出来。 抛开这两点回过头看,游戏整体活动明显在玩法层面的趣味性相当贫瘠,没有娱乐玩法,也很难给游戏提供限定性的创造性内容。原因可能也不难猜:在做好已有内容的情况下,工作室没有那么多的额外产能再去做新东西了。 《永劫无间》手游其实同样面临着相同的问题,甚至手游玩家对娱乐性内容有着更高的追求。相同的情况,放在手游里面只会爆发得更早,更直接,官方如今也已经到了避无可避的情况。 究竟该怎么做好下一步迭代,持续的玩家运营又该怎么做,《永劫无间》如今已经无法忽略这个持续数年的问题。 **结语** 《永劫无间》过去的成绩,得益于每个工作室成员的共同努力。他们对待玩家的态度一直都是谦虚与敬畏的,大家反馈的大多问题他们都相当重视,一如此次没有选择沉默而是站出来发布道歉信。 但只凭“听劝”,很难让游戏走得更久更远。或许当局者迷旁观者清,但比起我,比起玩家,工作室的成员应该对游戏的设计、发展思路与现状都有更加明确的感知。 比如随着玩法比重变化,早期的迦南现在早已改版,而季沧海的重做也提上了日程。此次道歉信中,官方也提到会邀请相关玩家参与见面、讨论。究竟该如何处理这位早期英雄,想必见面会之后就会有答案。 每款成功的长线运营游戏,都离不开持续性的挑战和新尝试,起起落落也很正常。只不过,《永劫无间》这次面临的问题比以往都大,他们需要面对的是游戏从一开始就存在的问题,并且要在短时间内就拿出一套可行的解决方案。 下周一就是官方举办见面会的时间,而到了5月,策划也计划将和玩家们再度讨论游戏现状。作为玩家之一,如今我也只能希望《永劫无间》此次依旧可以如它“我身无拘”的slogan那般,打破桎梏,冲破瓶颈。 本文首发自[“36氪游戏”](https://mp.weixin.qq.com/s/8oFe0rylm3M4rpre3hnVEw)。


