所有文章
 cnBeta全文版
cnBeta全文版
DeepSeek V3、R1系列开源AI大模型在多语言理解、复杂推理任务中展现了卓越性能,不仅推动了AI技术的普及与发展,更是对开源社区的极大贡献。目前,各家科技巨头都已纷纷开始支持、部署DeepSeek,国产硬件也在加速支持。 **作为国产全功能GPU创新企业,摩尔线程快速实现了对DeepSeek蒸馏模型推理服务的高效部署,可让更多开发者基于摩尔线程全功能GPU,进行AI应用创新。** 一键体验地址: [https://playground.mthreads.com](https://playground.mthreads.com)  此外,**用户也可以基于摩尔线程MTT S80、MTT S4000显卡,进行DeepSeek-R1蒸馏模型的推理部署。** 其实早在1月28日,就已经有B站UP主在摩尔线程MTT S80上手动完成实践: https://www.bilibili.com/video/BV18YfQYEEs2  通过DeepSeek提供的蒸馏模型,能够将大规模模型的能力迁移至更小、更高效的版本,在国产GPU上实现高性能推理。 **摩尔线程基于自研全功能GPU,通过开源与自研双引擎方案,快速实现了对DeepSeek蒸馏模型的推理服务部署。** **开源框架适配:** 基于Ollama开源框架,摩尔线程完成DeepSeek-R1-Distill-Qwen-7B蒸馏模型的部署,并在多种中文任务中展现了优异的性能,验证摩尔线程自研全功能GPU的通用性与CUDA兼容性。 **自研引擎加速:** 通过摩尔线程自主研发的高性能推理引擎,结合软硬件协同优化技术,通过定制化的算子加速和内存管理,显著提升了模型的计算效率和资源利用率。 这一引擎不仅支持DeepSeek蒸馏模型的高效运行,还为未来更多大规模模型的部署提供了技术保障。 最后,**摩尔线程即将开放自主设计的夸娥(KUAE)GPU智算集群,全面支持DeepSeek V3、R1模型,以及新一代蒸馏模型的分布式部署。** 夸娥集群集成先进推理技术与分布式计算框架,将确保大规模模型的高效稳定运行,助力开发者快速实现业务落地。  [查看评论](https://m.cnbeta.com.tw/comment/1475900.htm)

近年来,不少人对Google搜索结果的质量和实用性越来越不满,尤其是AI生成的结果和过多的广告。**然而,最近一个意外的发现让人有些意外:在搜索关键词中加入脏话,可能会得到更好的搜索结果。** 据媒体报道,在Google搜索中加入一些“随意的脏话”,可以禁用Google的Gemini AI搜索结果,这种修改确实可以去除AI概览,但是否能获得更有意义的结果则因情况而异。 [](https://img1.mydrivers.com/img/20250204/4889e29c-c646-4c15-b934-68ede4f40de2.png) **例如,搜索“如何查看eBay上的已售商品”时,加入脏话后,搜索结果中出现了一个YouTube 视频和一个相关的Reddit讨论,虽然结果并不理想,但至少去除了AI结果。** [](https://img1.mydrivers.com/img/20250204/e69f9d22-34a8-4eb3-87b8-ccec1aa576e4.png) 在另一个例子中,搜索“如何更换内存”时,加入脏话后,Google并没有给出AI结果,但随后出现了一些YouTube视频和Reddit讨论,结果并不比原来的搜索更好。 [](https://img1.mydrivers.com/img/20250204/e777c964-bc5e-4eb1-a8d9-a823ba84a78f.png) 在某些情况下,加入脏话确实可以改善搜索结果,例如搜索“如何煮鸡蛋”时,加入脏话后,搜索结果直接显示了一组烹饪指令,明显优于原来的搜索结果。 网友的评论也很有意思:“事实上,这对人类也有用。” [查看评论](https://m.cnbeta.com.tw/comment/1475898.htm)

过去两周,DeepSeek已经成为了全球的热点。尤其是在西方世界,这个来自于中国的生成式人工智能系统引发了广泛讨论。在发布的前18天内,DeepSeek便实现了惊人的1600万次下载,这一数字几乎是竞争对手OpenAI的ChatGPT在同期下载量的两倍,充分展示了其强大的市场吸引力和用户基础。 据市场分析公司Appfigures的权威数据,DeepSeek的应用程序于1月26日首次登顶苹果App Store,并自此持续保持其全球领先的霸主地位。数据统计显示,自今年初发布以来,迅速攀升至140个国家的苹果App Store下载排行榜首位,并在美国的Android Play Store中同样占据榜首位置。 作为一个中国的AI大模型,DeepSeek能够获得这个关注度,除了其出色的性能表现以外,其低训练成本也是其吸引全球目光的关键。在今天的文章中,我们来看一下藏在DeepSeek背后的芯片和系统。 **DeepSeek的架构自述** 早在2024年8月,8 月,DeepSeek团队发表了一篇论文,描述了它创建的一种新型负载均衡器,用于将其混合专家 (MoE:mixture of experts) 基础模型的元素相互连接。 DeepSeek在文章中表示,对于混合专家 (MoE) 模型,专家负载( expert load)不均衡将导致路由崩溃(routing collapse)或计算开销( computational overhead)增加。现有方法通常采用辅助损失( auxiliary loss )来促进负载平衡,但较大的辅助损失会在训练中引入不可忽略的干扰梯度(interference gradients),从而损害模型性能。 为了在训练过程中控制负载平衡但不产生不良梯度(undesired gradients ),DeepSeek团队提出了无损平衡(Loss-Free Balancing),其特点是无辅助损失的(auxiliary-loss-free)负载平衡策略。 具体而言,在进行 top-K 路由决策(routing decision)之前,无损平衡将首先对每个专家的路由分数(routing scores)应用专家偏见(expert-wise bias )。通过根据每个专家的近期负载动态更新其偏见,无损平衡可以始终保持专家负载的均衡分布。 此外,由于无损平衡不会产生任何干扰梯度,它还提升了从 MoE 训练中获得的模型性能的上限。DeepSeek团队还在多达 3B 个参数、在多达 200B 个 token 上训练的 MoE 模型上验证了无损平衡的性能。实验结果表明,与传统的辅助丢包控制负载均衡策略相比,无损平衡策略既实现了更好的性能,也实现了更好的负载均衡。  图 1:无损平衡根据每个训练步骤中的“偏见门控分数”(biased gating score)选择专家,并在每个训练步骤之后更新此专家偏见。 在2024年年底发布的报告《DeepSeek-V3 Technical Report》中,DeepSeek团队对其DeepSeek-V3模型的技术架构进行了深入解读,这为我们了解这家公司的技术有了更多参考。 他们在报告中直言,出于前瞻性的考虑,公司始终追求模型性能强、成本低。因此,在架构方面,DeepSeek-V3 仍然采用多头潜在注意力(MLA:Multi-head Latent Attention) 进行高效推理和 DeepSeekMoE 以实现经济高效的训练。而为了实现高效训练,DeepSeek团队的解决方案支持 FP8 混合精度训练,并对训练框架进行了全面优化。在他们看来,低精度训练已成为高效训练的一种有前途的解决方案,其发展与硬件能力的进步密切相关。  图2:采用 FP8 数据格式的整体混合精度框架。为了清楚起见,仅说明了线性算子。 通过对FP8计算和存储的支持,DeepSeek团队实现了加速训练和减少GPU内存使用。在训练框架方面,他们设计了DualPipe算法来实现高效的流水线并行,该算法具有更少的流水线气泡,并通过计算-通信重叠(overlap)隐藏了训练过程中的大部分通信。  图 3:DeepSeek-V3 基本架构图。继 DeepSeek-V2 之后,该公司采用 MLA 和 DeepSeekMoE 进行高效推理和经济训练。 DeepSeek团队表示,这种重叠确保了随着模型的进一步扩大,只要保持恒定的计算与通信比率,公司仍然可以跨节点使用细粒度的专家(fine-grained experts),同时实现接近于零的全对全通信开销(all-to-all communication overhead)。 此外,DeepSeek团队还开发了高效的跨节点全对全通信内核,以充分利用InfiniBand(IB)和NVLink带宽。公司还对内存占用进行了精心优化,使得无需使用昂贵的张量并行即可训练DeepSeek-V3。 在将这些努力结合起来,DeepSeek团队实现了很高的训练效率。  表 1:DeepSeek-V3 的训练成本,假设 H800 的租赁价格为每 GPU 小时 2 美元。 根据DeepSeek团队在论文中强调,通过优化算法、框架和硬件的协同设计实现的。在预训练阶段,每万亿个 token 上训练 DeepSeek-V3 只需要 180K H800 GPU 小时,也就是说,在其拥有 2048 个 H800 GPU 的集群上只需要 3.7 天。因此,公司的预训练阶段在不到两个月的时间内完成,花费了 2664K GPU 小时。加上上下文长度扩展的 119K GPU 小时和后训练的 5K GPU 小时,DeepSeek-V3 完整训练仅花费 278.8 万 GPU 小时。 假设 H800 GPU 的租赁价格为每小时 2 美元,则代表着其总训练成本仅为 557.6 万美元DeepSeek团队还特意强调,上述成本仅包括 DeepSeek-V3 的官方训练,不包括与架构、算法或数据的先前研究和消融实验相关的成本。作为对比,OpenAI 老板 Sam Altman 表示,训练 GPT-4 需要超过 1 亿美元。 在1 月 20 日,DeepSeek 推出了 DeepSeek-R1 模型,该模型增加了两个强化学习阶段和两个监督微调阶段,以增强模型的推理能力。DeepSeek AI 对 R1 模型的收费比基础 V3 模型高出 6.5 倍。随后,DeepSeek发布了Janus-Pro,这是其多模态模型 Janus 的更新版本。新模型改进了训练策略、数据扩展和模型大小,增强了多模态理解和文本到图像的生成。 至此,DeepSeek火爆全球。 **躲在DeepSeek背后的芯片** 在DeepSeek横空出世之后,一些围绕着其系统和技术研究框架的讨论,也遍布全网,具体到硬件方面。因为其极低的成本,这引致了整个AI芯片市场的震荡,早几天英伟达的大跌,正是这个担忧的最直接的反映。 如上所述,DeepSeek 表示,用于训练 V3 模型的集群只有 256 个服务器节点,每个节点有 8 个 H800 GPU 加速器,总共有 2,048 个 GPU。据nextplatform的分析师推测,这些GPU卡是 英伟达H800 卡的 H800 SXM5 版本,其 FP64 浮点性能上限为 1 万亿次浮点运算,其他方面与世界上大多数公司可以购买的 80 GB 版本的 H100 卡相同。 其中,节点内的八个 GPU 与 NVSwitch 互连,以在这些 GPU 内存之间创建共享内存域,并且节点具有多个 InfiniBand 卡(可能每个 GPU 一个)以创建到集群中其他节点的高带宽链接。 具体到H800,这是当初英伟达因应美国的出口限制需求推出的GPU。当时的美国GPU出口禁令规定主要限制了算力和带宽两个方面。其中,算力上限为4800 TOPS,带宽上限为600 GB/s。A800和H800的算力与原版相当,但带宽有所降低。  图4:H800的细节 如上所述,DeepSeek在训练中使用的是H800 SXM版本。据了解,所谓SXM 架构,是一种高带宽插座式解决方案,用于将 NVIDIA Tensor Core 加速器连接到其专有的 DGX 和 HGX 系统。对于每一代 NVIDIA Tensor Core GPU,DGX 系统 HGX 板都配有 SXM 插座类型,为其匹配的 GPU 子卡实现了高带宽、电力输送等功能。 资料显示,专门的 HGX 系统板通过 NVLink 将 8 个 GPU 互连起来,实现了 GPU 之间的高带宽。NVLink 的功能使 GPU 之间的数据流动速度极快,使它们能够像单个 GPU 野兽一样运行,无需通过 PCIe 或需要与 CPU 通信来交换数据。NVIDIA DGX H800 连接了 8 个 SXM5 H800,通过 4 个 NVLink 交换芯片,每个 GPU的带宽为 400 GB/s,总双向带宽超过 3.2 TB/s。每个 H800 SXM GPU 也通过 PCI Express 连接到 CPU,因此 8 个 GPU 中的任何一个计算的数据都可以转发回 CPU。  图5:基本的SGX/HGX to CPU框架图 过去几年里,大型企业对英伟达DGX热度大增,这是因为SXM GPU 更适合规模化部署。如上所说,八 个 H800 GPU 通过 NVLink 和 NVSwitch 互连技术完全互连。而在 DGX 和 HGX 中,8 个 SXM GPU 的连接方式与 PCIe 不同;每个 GPU 与 4 个 NVLink Switch 芯片相连,基本上使所有的 GPU 作为一个大 GPU 运行。这种可扩展性可以通过英伟达 NVLink Switch 系统进一步扩展,以部署和连接 256 个 DGX H800,创建一个 GPU 加速的 AI 工厂。  图6:基本的8 PCIe GPU to CPU框架图 **外国分析师眼里的DeepSeeK** 基于这些GPU和系统,搞出这个成就,西方不少分析人士一面倒抨击Deepseek团队,但nextplatform的分析师表示,如果你仔细阅读这篇 53 页的论文,就会发现 DeepSeek 已经采取了各种巧妙的优化和方法来制作 V3 模型,他们也确实相信,这确实减少了效率低下的问题,并提高了 DeepSeek 在硬件上的训练和推理性能。 他们认为, DeepSeek团队训练 V3 基础模型所采用方法的关键创新是使用 Hopper GPU 上的 132 个流式多处理器 (SM) 中的 20 个,作为数据的通信加速器和调度器,因为训练运行会仔细检查token并从参数深度集生成模型的权重,因此数据会在集群中传递。据nextplatform推测,正如 V3 论文所述,这种“计算和通信之间的重叠可以隐藏计算过程中的通信延迟”,使用 SM 在不在同一节点的 GPU 之间创建实际上是 L3 缓存控制器和数据聚合器的东西。 按照nextplatform对其论文的分享,DeepSeek 创建了自己的 GPU 虚拟 DPU,用于执行与 GPU 集群中的全对全通信相关的各种类似 SHARP 的处理。 如上文所述,DeepSeek团队设计了 DualPipe 算法以实现高效的流水线并行。对此,nextplatform指出,如果 DeepSeek 可以将这 2,048 个 GPU 上的计算效率提高到接近 100%,那么集群将开始认为它有 8,192 个 GPU(当然缺少一些 SM)运行效率不高,因为它们没有 DualPipe。作为对比,OpenAI 的 GPT-4 基础模型是在 8,000 个 Nvidia 的“Ampere”A100 GPU 上训练的,相当于 4,000 个 H100(差不多)。 此外,包括辅助无损负载平衡、 FP8 低精度处理、将张量核心中中间结果的高精度矩阵数学运算提升到 CUDA 核心上的矢量单元以保持更高精度的表象、在反向传播期间重新计算所有 RMSNorm 操作和重新计算所有 MLA 向上投影等也都是DeepSeek的创新点之一。 知名半导体分析机构SemiAnalysis的Dylan Patel虽然对DeepSeek团队所披露的成本有质疑。但他们也承认DeepSeek有过人之处。 SemiAnalysis表示,DeepSeek-R1 能够取得与 OpenAI-o1 相当的成果,而 o1 在 9 月份才发布。DeepSeek 为何能如此迅速地赶上?这主要是因为推理已经成为了是一种新的范式,与以前相比,现在推理的迭代速度更快,计算量更小,却能获得有意义的收益。作为对比,以前的模式依赖于预训练,而预训练的成本越来越高,也很难实现稳健的收益。 他们指出,新范式侧重于通过合成数据生成和现有模型后训练中的 RL 来实现推理能力,从而以更低的价格获得更快的收益。较低的准入门槛加上简单的优化,意味着 DeepSeek 能够比以往更快地复制 o1 方法。 “R1 是一个非常优秀的模型,我们对此并无异议,而且这么快就赶上了推理边缘,客观上令人印象深刻。”SemiAnalysis强调。他们总结说: 一方面,DeepSeek V3 以前所未有的规模采用了多token预测(MTP:Multi-Token Prediction)技术,这些附加的注意力模块(attention modules)可以预测下几个token,而不是单个token。这提高了模型在训练过程中的性能,并可在推理过程中舍弃。这是一个算法创新的例子,它以较低的计算量提高了性能。还有一些额外的考虑因素,比如在训练中提高 FP8 的准确性; 另一方面,DeepSeek v3 也是专家模型(experts model,)的混合体,它是由许多专门从事不同领域的其他小型模型组成的大型模型。混合专家模型面临的一个难题是,如何确定将哪个token交给哪个子模型或 "专家"。DeepSeek 实施了一个 "门控网络"(gating network),以不影响模型性能的平衡方式将token路由到合适的专家。这意味着路由选择非常高效,相对于模型的整体规模,每个token在训练过程中只需改变少量参数。这不仅提高了训练效率,还降低了推理成本; 再者,就 R1 而言,有了强大的基础模型(v3),它将受益匪浅。部分原因在于强化学习(RL)。 强化学习有两个重点:格式化(确保提供连贯的输出)以及有用性和无害性(确保模型有 用)。在合成数据集上对模型进行微调时,推理能力出现了; SemiAnalysis重申,MLA 是 DeepSeek 大幅降低推理成本的关键创新技术。原因在于,与标准注意力(standard attention)相比,MLA将每次查询所需的KV缓存量减少了约93.3%。KV 缓存是转换器模型中的一种内存机制,用于存储代表对话上下文的数据,从而减少不必要的计算。 **对英伟达芯片的潜在影响** 在文章开头我们就提到,DeepSeek爆火以后,英伟达用暴跌来回应。因为如果美国大型科技公司开始向 DeepSeek 学习,选择更便宜的人工智能解决方案,这可能会给 Nvidia 带来压力。 随后,Nvidia 对 DeepSeek 的进展给予了积极评价。该公司在一份声明中表示,DeepSeek 的进展很好地展示了 AI 模型的新操作方式。该公司表示,向用户提供此类 AI 模型需要大量 Nvidia 芯片。 但著名投资人、方舟投资CEO“木头姐”凯西·伍德在采访中表示,DeepSeek证明了在AI领域成功并不需要那么多钱,并且加速了成本崩溃。 Counterpoint Research 人工智能首席分析师孙伟也表示,Nvidia 的抛售反映了人们对人工智能发展的看法转变。她进一步指出:“DeepSeek 的成功挑战了人们认为更大的模型和更强大的计算能力能够带来更好性能的信念,对 Nvidia 由 GPU 驱动的增长战略构成了威胁。” SemiAnalysis强调,算法改进的速度太快了,这对 Nvidia 和 GPU 来说也是不利的。 美媒《财富》更是预警道,DeepSeek 正在威胁英伟达的 AI 主导地位。 如前文所说,DeepSeek 已采用性能更低、价格更便宜的芯片打造了其最新型号,这也给 Nvidia 带来了压力,一些人担心其他大型科技公司可能会减少对 Nvidia 更先进产品的需求。 AvaTrade 首席市场分析师凯特·利曼 (Kate Leaman) 向《财富》杂志表示:“投资者担心 DeepSeek 与性能较弱的 AI 芯片配合使用的能力可能会损害英伟达在 AI 硬件领域的主导地位,尤其是考虑到其估值严重依赖于 AI 需求。” 值得一提的是,根据tomshardware的报道,DeepSeek 的 AI 突破绕过了英伟达的CUDA不成盒,而是使用了类似汇编的 PTX 编程,这从某种程度上加大了大家对英伟达的担忧。 据介绍,Nvidia 的 PTX(Parallel Thread Execution:并行线程执行)是 Nvidia 为其 GPU 设计的中间指令集架构。PTX 位于高级 GPU 编程语言(如 CUDA C/C++ 或其他语言前端)和低级机器代码(流式汇编或 SASS)之间。PTX 是一种接近金属的 ISA,它将 GPU 公开为数据并行计算设备,因此允许细粒度优化,例如寄存器分配和线程/warp 级别调整,这是 CUDA C/C++ 和其他语言无法实现的。一旦 PTX 进入 SASS,它就会针对特定一代的 Nvidia GPU 进行优化。 在训练 V3 模型时,DeepSeek 重新配置了 Nvidia 的 H800 GPU:在 132 个流式多处理器中,它分配了 20 个用于服务器到服务器通信,可能用于压缩和解压缩数据,以克服处理器的连接限制并加快交易速度。为了最大限度地提高性能,DeepSeek 还实施了高级管道算法,可能是通过进行超精细的线程/warp 级别调整来实现的。 报道指出,这些修改远远超出了标准 CUDA 级开发的范围,但维护起来却非常困难。 不过,晨星策略师布莱恩·科莱洛 (Brian Colello) 直言,DeepSeek 的进入无疑给整个人工智能生态系统增加了不确定性,但这并没有改变这一运动背后的压倒性势头。他在一份报告中写道:“我们认为人工智能 GPU 的需求仍然超过供应。因此,尽管更轻薄的机型可能能够以相同数量的芯片实现更大的发展,但我们仍然认为科技公司将继续购买所有他们能买到的 GPU,作为这场人工智能‘淘金热’的一部分。” 英特尔前首席执行官帕特·基辛格 (Pat Gelsinger) 等行业资深人士也认为,像人工智能这样的应用程序可以利用它们能够访问的所有计算能力。至于 DeepSeek 的突破,基辛格认为这是一种将人工智能添加到大众市场中大量廉价设备中的方法。 SemiAnalysis在其报告中透露,自DeepSeek V3 和 R1 发布以来,H100 的 AWS GPU 价格在许多地区都有所上涨。类似的 H200 也更难找到。“V3 推出后,H100 的价格暴涨,因为 GPU 的货币化率开始大大提高。以更低的价格获得更多的智能意味着更多的需求。这与前几个月低迷的 H100 现货价格相比发生了重大转变。”SemiAnalysis说, 所以,大家认为,DeepSeek将如何发展?英伟达芯片,还能继续独霸天下吗? [查看评论](https://m.cnbeta.com.tw/comment/1475894.htm)

当地时间2月3日,美国总统特朗普签署行政命令,暂停对墨西哥、加拿大商品加征关税,将其实施时间推迟到2025年3月4日。声明表示,美国国土安全部长应与国务卿、司法部长、总统国家安全事务助理和总统国土安全助理协商,继续评估美国北部边境的局势。如果非法移民和非法毒品危机恶化,且加拿大政府未能采取足够措施缓解这些危机,特朗普将采取必要措施应对局势,可能会继续加征关税。  特鲁多:正在加强边境管理,组建加美联合打击力量 加拿大总理特鲁多 当地时间3日早些时候,加拿大总理特鲁多表示,美国总统特朗普决定将暂缓对加拿大产品加征关税,为期至少30天。加拿大方面也放弃实施报复性关税。 特鲁多表示,加拿大正在实施一项耗资13亿美元的边境计划——用新的直升机、技术和人员加强边境,加强与美国的协调,近10000名前线人员正在保护边境。 特鲁多表示,加拿大还作出新承诺,将把贩毒集团列为恐怖分子,确保边境全天候监控,成立加拿大与美国的联合打击部队,打击有组织犯罪、洗钱等活动。 加拿大总理特鲁多同日在社交媒体上说,他刚与特朗普进行了通话,在双方共同努力解决问题期间,拟议的关税措施将暂缓至少30天实施。他说,加拿大正在加强边境管理,组建加美联合打击力量,以打击有组织犯罪、芬太尼和洗钱等问题。 辛鲍姆:派遣1万名国民警卫队人员加强北部边境巡逻 墨西哥总统辛鲍姆 当地时间3日早些时候,特朗普与墨西哥总统辛鲍姆通话。两人在通话后都宣布,美国和墨西哥同意将加征关税的措施立即暂缓一个月执行,并继续进行谈判。 辛鲍姆表示,她与特朗普达成了一系列协议。墨西哥将立即派遣1万名国民警卫队人员加强北部边境巡逻,以防止从墨西哥向美国贩运芬太尼等毒品。美国承诺努力防止向墨西哥贩运大威力武器。双方团队将从当天开始在安全和贸易两个方面继续开展工作。关税征收计划从当天起暂停实施一个月。 特朗普1日签署行政令,对进口自墨西哥、加拿大两国的产品加征25%的关税。特鲁多同日宣布对价值1550亿加元(1美元约合1.45加元)的美国输加产品加征25%的关税,以应对美国对加产品加征关税。 [查看评论](https://m.cnbeta.com.tw/comment/1475892.htm)

ChatGPT创建者OpenAI和韩国主要聊天应用运营商Kakao周二表示,他们计划建立战略合作伙伴关系,为韩国市场开发人工智能产品。Kakao还表示将在其产品中使用OpenAI技术。 OpenAI 首席执行官 Sam Altman 和 Kakao 首席执行官 Chung Shina 在悉尼举行的新闻发布会上宣布了这一消息。 当被问及OpenAI是否正在考虑投资并加入韩国的人工智能计算中心项目时,Altman表示,这家美国公司正在 “积极考虑 ”这一举措。 他还表示,许多韩国公司将成为美国星际之门数据中心项目生态系统的重要贡献者,但他补充说,他希望对合作对话保密。  [查看评论](https://m.cnbeta.com.tw/comment/1475888.htm)

美国总统特朗普3日表示,美国希望乌克兰提供稀土资源供应方面的保证,以换取华盛顿提供资金和军事上的援助。据报道,特朗普在白宫椭圆形办公室对记者说:“我们希望与乌克兰达成交易,我希望拥有稀土供应方面的保证,乌方已经准备好提供这种担保。”  他还强调,华盛顿要求欧洲增加对乌克兰的援助资金,以便与美国的投入“持平”。 他指出,“我们对乌克兰的援助比欧洲多出近2000亿美元。他们至少应该支付同样多的资金,但实际上应该更多”。 报道介绍称,特朗普政府此前曾提出必须重新审议西方支持基辅的条件。他还指出,与美国的投入相比,欧洲盟友的贡献完全不成比例。 [查看评论](https://m.cnbeta.com.tw/comment/1475886.htm)

美国总统特朗普周一签署了一项行政命令,要求在未来一年成立一个主权财富基金。许多其他国家已经推出了类似的基金,尤其是中东和亚洲国家,以利用政府资金进行直接投资。美财长贝森特表示,该主权财富基金将在未来12个月内建立。知名比特币倡导者、参议员辛西娅·卢米斯的一则帖子引人遐想。 该行政命令的文本细节很少,只是指示财政部和商务部在90天内提交此类基金的计划,包括关于“融资机制、投资策略、基金结构和治理模式”的建议。 但比特币的支持者们热情高涨,认为这一消息表明美国正在采取积极措施直接投资世界顶级加密货币。最值得注意的是,著名的比特币倡导者、参议员辛西娅·卢米斯(Cynthia Lummis)在回应这一消息时提到了比特币。“这是一笔大交易,”她在X上发帖说,并使用了比特币的符号,这令加密货币爱好者兴奋不已。比特币闻讯将日内涨幅扩大至5%,至10.2万美元上方。  主权财富基金是一种国有投资基金,它将政府收入——通常来自出口自然资源——再投资于可持续盈利的资产,如股票、债券和房地产。世界上一些顶级的主权财富基金确实普遍持有大量加密货币,尤其是比特币。 据K33 Research称,作为世界上最大的主权财富基金,挪威的主权财富基金间接持有价值近4亿美元的比特币。阿布扎比的主权财富基金也经常投资于加密项目和数字资产。 也许像卢米斯这样的政策领导人有充分的理由相信比特币可能成为美国主权财富基金的主要投资重点,或者就像加密行业的许多其他人一样,他们只是在努力将他们深深渴望的未来变成现实。 **美国建立主权财富基金的方式仍未知** 通常,主权财富基金依靠一国的预算盈余进行投资,但美国处于赤字状态。它的成立也可能需要国会的批准。 “我们将为该基金创造大量财富,”特朗普对记者说。“我认为我们的国家是时候建立一个主权财富基金了。” 特朗普此前曾作为总统候选人推出过这样一个政府投资工具,称它可以为“伟大的国家事业”提供资金,例如高速公路和机场等基础设施项目、制造业和医学研究。 政府官员没有透露该基金将如何运作或如何筹集资金,但特朗普此前曾表示,它可以由“关税和其他明智的事情”提供资金。 财政部长斯科特·贝森特(Scott Bessent)告诉记者,该基金将在未来12个月内成立。 “我们将把美国资产负债表的资产部分货币化,以惠及美国民众”贝森特说。“这将包括流动资产,以及我们目前在国内持有的各类资产,我们将努力将其释放出来,为美国人民创造价值。 ” 据彭博新闻社报道,一种方法是转变美国国际开发金融公司(DFC)的职能。报道称,特朗普政府最近几个月曾考虑过这样做。DFC是一个政府机构,目前与私人团体合作,为发展中国家的项目提供资金。 特朗普上周五宣布,他提名本杰明·布莱克(Benjamin Black)领导该机构。布莱克是投资公司Fortinbras Enterprises的管理合伙人,他的父亲莱昂·布莱克(Leon Black )是资产管理公司阿波罗全球管理公司(Apollo Global management)的联合创始人。 据《纽约时报》和《金融时报》报道,去年11月,拜登政府在特朗普当选之前也曾考虑设立这样一个基金。 但目前尚不清楚将如何构建和资助美国的主权财富基金。几位专家表示,鉴于目前没有盈余可供动用,国会可能需要批准新的资金。特朗普签署的行政命令指示官员审查任何立法的必要性。 前财政部官员、现供职于全球发展中心(Center for Global Development)的克莱门斯·兰德斯(Clemence Landers)表示,有关重新调整DFC用途的讨论一直在进行,但设立这样一个基金需要国会的支持。 她说:“显然,你不能通过行政命令建立一个机构,更重要的是,你不能通过行政命令为一个机构提供资金。” 投资者表示,这一消息令人意外。 伦敦Robeco多资产策略主管科林·格雷厄姆(Colin Graham)表示:“创建一只主权财富基金表明,一个国家的储蓄有所增加,可以配置到这只基金中……根据经济上的经验法则,这行不通。” 根据主权财富基金国际论坛(International Forum of Sovereign Wealth Funds)的数据,全球有超过90家这样的基金,管理着超过8万亿美元的资产。 美国包括阿拉斯加州、德克萨斯州和新墨西哥州在内的许多州也拥有自己的财富基金,为各种优先事项提供资金,包括教育和税收减免。它们通常依赖石油或土地等自然资源带来的收入。但美国并未运营过自己的主权财富基金。 根据主权财富基金研究所的数据,挪威拥有最大的主权财富基金,资产超过1.7万亿美元。中国投资有限责任公司管理的资产以1.3万亿美元紧随其后。 [查看评论](https://m.cnbeta.com.tw/comment/1475884.htm)

美国财政部被指控违反联邦法律,允许埃隆·马斯克的政府效率执行者团队获得大量个人和财务信息,从而对特朗普政府缩减政府的标志性努力进行法律摊牌。 美国劳工联合会和产业工会联合会( AFL-CIO)下属的工会组织和退休美国人联盟(Alliance for Retired Americans )周一在一起诉讼中表示,财政部和该机构负责人斯科特·贝森特(Scott Bessent)非法允许其成员的记录与马斯克的组织DOGE共享。 美国总统特朗普让马斯克负责联邦信息技术现代化。特朗普解释说,马斯克是世界上最富有的人,他没有权力在未经批准的情况下自己停止支付,但他被允许进入财政部系统监控联邦支出。 根据诉讼,财政部参与了向马斯克团队“非法、持续、系统和持续地披露个人和财务信息”。这些组织表示:“对个人隐私的侵犯规模之大是前所未有的。” [](https://n.sinaimg.cn/finance/transform/85/w550h335/20250204/4be7-4497ae241c75b6e2c9aff73c48fdb9c9.jpg) [查看评论](https://m.cnbeta.com.tw/comment/1475882.htm)

特朗普政府考虑本月签署一项行政令行政命令裁撤美国教育部。特朗普曾抨击美国教育表现糟糕、支出过高。最近国际测试中,美国在81个国家中阅读排名第六,科学排名第十,数学排名第26。较早的测试结果显示美国排名更低,尤其是在数学方面。 保守派一直对拜登政府领导下的教育部持强烈批评态度,尤其是在学生贷款豁免和将教育中的性别歧视保护延伸至LGBTQ群体等决定上。 综合媒体最新消息,特朗普政府考虑本月晚些时候签署一项行政命令,以裁撤美国教育部。这一计划也是马斯克及其盟友缩减联邦机构、裁减政府工作人员规模运动的一部分。 有报道称,官员们正在讨论一项行政命令,关闭教育部所有未明确写入法规的职能,或将某些职能转移到其他部门。知情人士说,该命令将要求制定一项废除该部门的立法提案。 也有报道称,该行政令将采取两步走战略:一、指示教育部制定计划,利用总统现有行政权力逐步结束教育部职能;二、要求教育部梳理将其权力下放至其他机构所需的复杂法律体系,为最终关闭教育部做准备,同时要求制定立法提案以彻底废除教育部。 分析指出,此举旨在兑现特朗普消除教育部、限制联邦参与教育、赋予各州更多权力的竞选承诺。保守派一直对拜登政府领导下的教育部持强烈批评态度,尤其是在学生贷款豁免和将教育中的性别歧视保护延伸至LGBTQ群体等决定上。保守智库传统基金会的“2025计划”也呼吁取消该部门。 但特朗普政府废除教育部的努力面临重重障碍,包括法律限制、国会支持度不足,以及公众反对等。一方面,完全废除教育部需要国会立法支持,但多年来国会对此兴趣寥寥。特朗普在首个任期曾试图将教育部与劳工部合并,但未能成功。另一方面,最新民意调查,61%的登记选民反对取消教育部。大多数美国人更倾向于保护教育和其他国内优先事项的资金,而不是减税。 **特朗普对于废除教育部有何看法?** 特朗普曾在社交媒体平台X上表示,美国在发达国家中的教育表现“糟糕”,排名“垫底”,却在教育上的支出最多。 在最近的国际测试(PISA测试)中,美国在81个国家中,阅读排名第6,科学第10,数学第26。较早的测试结果显示,美国的排名(尤其是数学)更低。 而美国的教育支出相对较高。根据经济合作与发展组织(OECD)数据,美国生均教育支出高于许多在这些测试中得分更高的国家,如芬兰、韩国等。 特朗普认为,一些州的教育表现可能不佳,但许多州在减少开支的情况下能更好地管理教育事务。他预计,在50个州中,有35个州能够表现优异,其中15至20个州可以达到“像挪威一样优秀”的水平。 特朗普将挪威作为例子,可能是因为该国以高质量的教育系统著称,在国际测试中常名列前茅。 虽然特朗普提出废除教育部,但他也主张联邦政府保留有限的监督职能。他说,联邦政府可以“稍微监管一下”,例如确保学校教授英语。“你要确保他们在教英语,比如说。给我们点英语,对吧?”  **美国保守派为何希望废除教育部?** 事实上,废除教育部是共和党长期以来的主张。自1980年罗纳德·里根总统时期教育部成立以来,共和党一直试图关闭该部门。然而,经过多届共和党政府,包括特朗普第一任期,美国教育部依然存在。 教育部成立于1979年,是内阁级机构中最小的一个。教育部的存在及其大部分职能都有法律依据。其主要活动包括为低收入学生提供助学金、规范学校对残障学生的服务、执行民权法,以及管理联邦学生贷款项目。其最大金额的K-12教育项目为高贫困地区学校和残障学生提供资金。 另外,美国教育部并不是美国学校的主要资金来源。在疫情救济资金注入之前,联邦政府仅承担了大约8%的K-12(幼儿园至12年级)教育成本。近年来,这一比例上升至接近11%。然而,要放弃这部分资金以规避联邦规定并非易事。 分析还称,保守派的反对基于以下几方面: - 教育主权:认为教育事务应由地方和州政府管理,联邦政府过多干预违背宪法精神。 - 减少政府规模:保守派信奉“小政府”,希望削减联邦机构和官僚体系。 - 效率低下:保守派批评教育部效率低、资源浪费,无法有效缩小种族和贫困的教育差距。 该项提议背后还是进步vs保守的教育理念之争。在民主党执政期间,教育部往往倾向于采取更加进步的教育方法和民权执法措施,这引发了保守派的不满。例如: - 奥巴马时期:政府要求学校审查黑人学生被停学或开除的比例,以防止潜在的歧视。这一政策被批评为导致学校纪律松弛,影响安全。 - 拜登时期:拜登政府颁布《第九条修正案》规则,为LGBTQ学生提供更多保护,但共和党主导的多个州对此提起诉讼。 保守派智库传统基金会高级研究员Jonathan Butcher表示,各州一直是教育创新的源泉,如特许学校和教育储蓄账户等创新举措。他认为,联邦教育部不仅分散了各州改善教育的注意力,还创造了不必要的官僚机构。 Butcher指出,尽管在某些方面有所改善,但基于种族和贫困的成绩差距仍然存在。他认为这表明教育部“未能达到其目的”,并强调废除教育部“既符合小政府的利益,也符合为孩子们做正确事情的利益”。 [查看评论](https://m.cnbeta.com.tw/comment/1475880.htm)
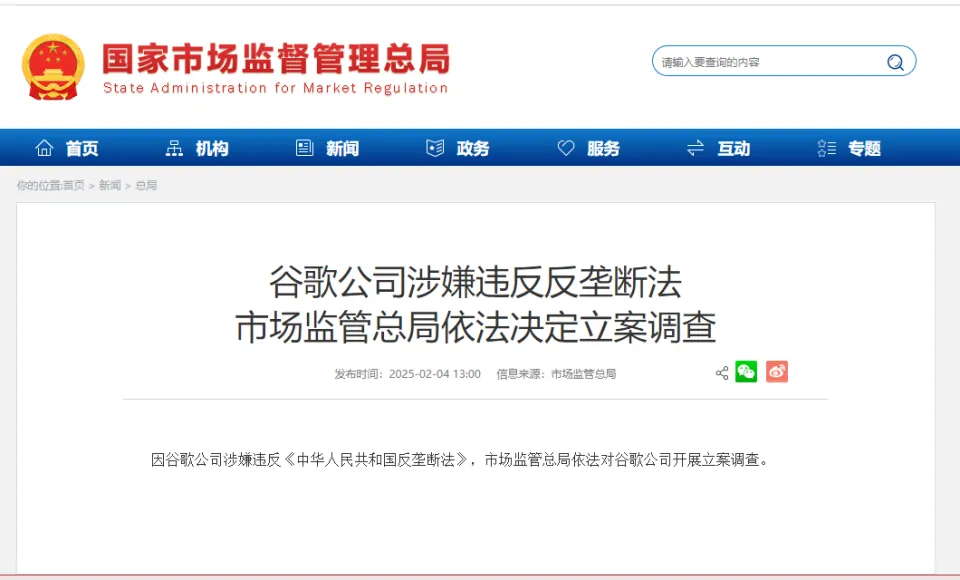
根据国家市场监督管理总局官方微信公众号“市说新语”消息,因谷歌公司涉嫌违反《中华人民共和国反垄断法》,市场监管总局依法对谷歌公司开展立案调查。  中国国家市场监督管理总局没有说明谷歌违法的具体细节。 美国总统特朗普上星期六(2月1日)签署行政令,宣布以应对非法移民和芬太尼等毒品流入危机为由,对墨西哥、加拿大和中国输美商品加征关税,定于星期二生效。不过,特朗普过后决定对墨加两国的关税措施延迟一个月执行。 据路透社报道,美国对中国商品征收10%的关税于星期二下午1时01分(格林威治标准时间5时01分)生效。与此同时,中国宣布实施一系列反制措施,包括对美国部分输华产品加征10%至15%关税。 [查看评论](https://m.cnbeta.com.tw/comment/1475876.htm)
 极客公园
极客公园
**作者 | 汤一涛****编辑 | 靖宇** 1942 年,伟大的科幻作家艾萨克·阿西莫夫(Isaac Asimov)在他的短篇小说《转圈圈》(Runaround)中首次提出了「机器人三定律」。之后,这些定律因为他的短篇小说集《我,机器人》而广为流传。 <blockquote> <section> <section>1、机器人不得伤害人类,也不得因不作为而使人类受到伤害。</section> <section>2、机器人必须服从人类给予它的命令,除非这些命令与第一法则相冲突。</section> <section>3、机器人必须保护自己的存在,只要这种保护不与第一或第二定律相冲突。</section> </section> </blockquote> 机器人三定律的影响是如此之大,它不但构成了阿西莫夫所有机器人科幻小说的组织原则,甚至渗透进了之后几乎所有的机器人科幻小说,以及所有引用它的书籍、电影、游戏等流行文化中。 例如,1966 年的短篇小说《萨姆的密码》中的「阿森尼翁机器人的三大法则」,就是对机器人三定律的改编;1999 年的电影《2001 太空漫游》中,罗宾·威廉姆斯(Robin Williams)饰演的机器人安德鲁,通过其头部的投影仪全息展示了机器人三定律;至于威尔·史密斯(Will Smith)主演的《我,机器人》,更是花费整部电影的时间详细讨论了这三大定律。  安德鲁向新主人马丁一家讲解机器人三定律|图片来源:medium **人们甚至发展出了一门专门研究人与机器人关系的学科——机器人伦理学**。这是一门以人类为责任主体,研究如何开发和应用机器人的伦理学。追踪其源头,就是阿西莫夫的三定律。 在阿西莫夫生活的年代,人工智能还处于相当早期的阶段。论文《神经活动中内在思想的逻辑演算》(A Logical Calculus of Ideas Immanent in Nervous Activity)被视为人工智能学科的奠基石,这篇论文在机器人三定律发表后一年公布;直到 1956 年,达特茅斯人工智能夏季研讨会召开,人工智能作为一门学科,才真正创立。 **也就是说,机器人三定律是在一种小说家社会实验的语境下诞生的**。 如果借鉴原教旨主义的概念的话,机器人三定律可以算是机器人伦理学的原教旨主义。今天当然还有众多阿西莫夫的信徒,但是人工智能的现实环境已与当初大不相同。 **这让人不禁十分好奇,在 AI 如此火热的当下,****作为原教旨的机器人三定律,还能指导今天人与 AI 的关系吗**? _**01 **_**作为创作工具的机器人三定律** 很难脱离机器人三定律的创作背景讨论它的意义。阿西莫夫在 1975 年接受 Sy Bourgin 采访时提到,他创作机器人三定律的动机,是为了摆脱此前科幻小说《弗兰肯斯坦》式的套路——也就是机器人杀害主人,创造物最终会摧毁其创造者。 因此,从本质上来说,机器人三定律不是一个全面的道德框架,它们是为故事服务的创作工具。它们被创作出来的目的,就是为了**突出一种不确定性、一种冲突的潜在可能,以探讨人与 AI 之间的灰色边界**。 一个有力的证据就是,在阿西莫夫的每一个故事中,机器人三定律都失败了。阿西莫夫故意模棱两可地创造了这 3 个定律,以便制造困境,让角色和观众都面临道德困境。 一旦运用到真实世界,这 3 条被称为「定律」的东西就会轰然崩塌。例如,巡航导弹、军用无人机就是违反第一和第三定律的机器人。它们由计算机控制,只会做它们被编程去做的事情。如果它们被编程去伤害人类,它们就会伤害人类。 从语言学的角度来说,机器人三定律也是无法成立的。因为这 3 项定律是用英语写成的,英语是一种自然语言,本质上是模棱两可的,可以有多种解释。因此,**将机器人三定律编码成精确的、机器可读的指令是不切实际的**。 来自武汉大学哲学系的克里斯·斯托克斯(Chris Stokes)更是在他的论文《Why the three laws of robotics do not work》中逐一解释了为什么机器人三定律是行不通的: <blockquote> <section> <section>1、第一条法则失败是因为语言上的歧义,以及因为过于复杂的伦理问题,这些问题太复杂,无法简单地用是或否来回答。</section> <section>2、第二定律失败,因为要求有感知的生物保持奴隶状态的定律,本质上是不道德的。</section> <section>3、第三定律失败,因为它导致永久的社会分层,这个定律体系中内置了大量的潜在剥削。</section> </section> </blockquote> 正如 iRobot 的创始人罗德尼·布鲁克斯(Rodney Brooks)所说:「人们问我,我们的机器人是否遵循阿西莫夫的法则。它们不遵循的原因很简单——我无法将阿西莫夫的法则植入它们体内!」 iRobot 的名字正是来自于阿西莫夫的短篇小说集《I,Robot》。这家公司最出名的两个产品,**是扫地机器人和军用武装机器人**。 _**02 **_**人类的恐惧** 2022 年汤加火山的爆发曾经引发过一场关于「无夏之年」的恐慌。历史上,每逢无夏之年,都会引起气温骤降,进而导致全球性的灾难。 上一个无夏之年发生在 1816 年,印尼的坦博拉火山爆发。积聚的火山灰让全球气温至少下降了 0.4 度,气候反常引起了全球范围内的饥荒、伤寒和暴乱。 那个「潮湿、不适、连绵降雨」的夏天,迫使新婚的雪莱夫妇滞留在了拜伦在日内瓦湖畔的别墅。为了打发时间,拜伦提出了一场写作比赛,看谁能写出最恐怖的故事。雪莱的妻子—玛丽,在那段时间里写出了《弗兰肯斯坦》。  1910 年,爱迪生工作室制作了《弗兰肯斯坦》的第一个电影改编版|图片来源:Wikipedia 今天我们记得《弗兰肯斯坦》当然是因为它是世界上第一部科幻小说。但是请注意,玛丽参加的可是一个恐怖故事比赛,《弗兰肯斯坦》有什么恐怖的呢? 《弗兰肯斯坦》讲述的是生物学家弗兰肯斯坦,利用人类尸体拼凑出了一个怪物。在被人类排斥的过程中,怪物对弗兰肯斯坦产生了怨恨,杀死了他的众多亲友。弗兰肯斯坦最后也因追捕怪物而死。 德国科布伦茨大学的乌尔里克·巴塞尔梅斯(Ulrike Barthelmess)和乌尔里希·福尔巴赫(Ulrich Furbach)认为,《弗兰肯斯坦》反映出的是人类数千年内心的恐惧,即**人类不能像上帝那样创造生物,任何试图这么做的人都会受到惩罚**。 另一个例子是 16 世纪的犹太神话里魔像(Golem)的传说。在其中的一个版本里,拉比利用粘土创造出了魔像,以保护犹太人社区。拉比承诺在每次安息日前关闭魔像以让他休息。但有一次拉比忘记了,于是魔像变成了一个屠杀社区的怪物。  布拉格的玛哈拉尔与魔像,1899|图片作者:Mikoláš Aleš 正如美国电影理论家布莱恩·亨德森 (Brian Henderson) 所说,重要的是讲述神话的年代,而不是神话所讲述的年代。换句话说,神话当然是虚构的,但是当时的人们,出于何种动机、何种背景,讲述这样的神话,才是真正重要的。 进一步将「创造生物」这个概念扩展开来,**这种对「创造物」的恐惧,或许也可以理解成一种对技术的恐惧**。希腊神话里,因为将火传播于人间,普罗米修斯受到上帝惩罚,每日受老鹰啄食肝脏之苦。在这个故事中,「火」即技术。有一种学术观点认为,正是因为掌握了火,吃上了熟食,人类才不用耗费大量的能量消化生食,才得以进化出了发达的大脑。与此同时,正是利用了其他动物对火的恐惧,人类才得以在夜间抵御野兽。 巧合的是,《弗兰肯斯坦》的副标题恰好是「另一个普罗米修斯的故事」。 在近现代,人类对技术的恐怖更加常见。例如在工业革命时期的英国,人们就对机器改变世界的能力产生了极大的恐惧,开始了一场专门摧毁纺织机的运动。这场运动的后果是如此严重,以至于议会立法将拆除机器定为死罪。其中一个被称为「卢德分子」的团体,甚至和英国军队爆发了冲突。在今天,「卢德分子」依然用来描述一切新科技的反对者,他们被称为「新卢德分子」。  卢德运动领袖,1812|图片来源:Wikipedia **当我们带着恐惧的视角审视机器人三定律的时候,就可以看到其中充满了对机器人的严防死守,以及背后幽微深长的恐惧心理**。 与此同时,它天然将机器人置于了完全服从的奴隶地位(机器人 robot 源自捷克语 robota,意思正是「强迫劳动」)。这会成为一个问题,取决于我们看待机器人的视角。当我们把机器人视为「工具」时,这是合理的;但是**当我们把机器人视为有感知的生物、甚至连****它****们****自己****也这么觉得时,那这两个「种族」就是天然矛盾的,冲突迟早会发生**。 三江学院副教授、作家刘勃在描述魏晋南北朝时期,北方游牧民族和汉民族之间的民族仇杀时是这么解释的:「当经济优势和政治优势属于同一方的时候,通过建立威权体系,勉强可以维持社会的正常运转,一旦两个优势分属双方,社会的撕裂也就难以避免。」 这个问题放在今天的世界仍然适用。 而眼下,AI 正在做我们认为我们最擅长的所有事情。在某些情况下,它要比人类表现得好得多。在肉眼可见的将来,它也会越来越强大。 _**03 **_**现实中的机器人法则** 遗憾的是,目前现实世界中并没有一部通行的法律实行。机器人、AI、自动驾驶这些近似的概念相互混杂,有所交叉又各有不同;针对特定国家、地区制订的建议、指导方针、道德框架可以说是一锅大杂烩。 在国家层面,欧美国家是最积极的立法推动者。 欧盟 2024 年的 AI 法案是截至目前最严格的监管法案。它禁止将 AI 用于社会评分目的(利用个人数据个性化推荐就是社会评分的范畴),限制 AI 在犯罪画像中的使用,并要求对 AI 生成的内容进行标签。对被归类为对健康、安全或基本权利构成高风险的 AI 开发者,欧盟 AI 法案制定了一系列特殊要求。 美国国会还没有提出全面的关于 AI 的法案,但在州一级,硅谷所在的加州最为积极。其州长最近签署了 17 项人工智能法案,包括从保护表演者的数字形象到禁止与选举相关的深度伪造。加拿大正试图采取与欧盟类似的方法,其执政党提议已经提议了《人工智能和数据法案》(AIDA)。 相对于机器人三定律对人工智能的强烈限制,**这些法案的共同点在于限制的主体是 AI 的创造者、使用者,也即人类本身**。  欧美国家对于 AI 的相关限制法案同样心口不一|图片来源:caravel law 与此同时,欧美的监管遭到了大型科技公司的反对。OpenAI CEO Sam Altman 就称,如果监管过于严格,OpenAI 可能会离开欧洲;扎克伯格也在 8 月发表了一篇评论,将欧盟的监管方法描述为「复杂且不连贯」,警告这可能会破坏一个「一代人一次」的创新机会,以及利用 AI 的「经济增长机会」的机会。 在加拿大,亚马逊和微软的高管公开谴责了 AIDA,称其含糊不清且负担沉重;Meta 表示,它可能会推迟在加拿大推出某些人工智能产品。 而在一些非西方国家,态度则截然不同。他们优先考虑的不是监管,而是吸引大型科技公司的投资。印度是最典型的例子,它拥有中美以外最大的互联网产业。目前,印度政府已投入 12 亿美元用于名为「印度 AI」的倡议。其总理莫迪 9 月在一次圆桌会议上与硅谷 CEO 们会面时,他敦促他们「在印度与世界共同开发、共同设计和共同生产」。 目前印度在人工智能领域尚没有监管。而科技巨头方面,OpenAI 承诺通过大量投资开发者社区来支持印度 AI 倡议;亚马逊已拨出数亿美元支持印度人工智能初创企业,并与印度理工学院(IIT)签署了多年人工智能合作协议;微软最近也承诺在印度投资 30 亿美元,用于人工智能培训、云和人工智能基础设施。 可以说,科技巨头在一定层面上极大地影响了全球政府的政策。他们既是 AI 的创造者,也是最大的利益相关者。面对 AI 这样一种超越国界的国界的工具,各国可以制定自己的法律,但也必须就一些基本规则达成共识。毕竟,如果牌桌上连规则都没有的话,这局游戏是必然要崩盘的。 _**04 **_**AI 自己的建议** 那么,机器或者 AI 自己,是如何看待这个问题的? 最后,我们询问了 ChatGPT,该如何完善阿西莫夫的机器人三定律,以下是它的回答: 1. **增强对人类自主性的尊重** 阿西莫夫的第一定律强调了机器人不能伤害人类,或者因不作为而让人类受到伤害。为了增强 AI 对人类自主性和隐私的尊重,可以增加类似「AI 必须尊重个体的自主选择和隐私权」的原则。例如: **新建议**:「AI 必须尊重人类的自由意志、隐私权和选择,避免对人类的决策产生不正当影响。」 2. **多层次的责任分配** 阿西莫夫的定律中没有明确如何界定 AI 错误行为的责任,导致可能出现责任归属不清的问题。在现代社会,AI 系统的决策可能涉及复杂的道德和法律层面。因此,应增加条款明确责任归属,避免「责任空白」。 **新建议**:「在 AI 行为引发的问题上,应明确 AI 使用者、开发者、监管机构等多方的责任,并对其行为进行透明化追踪。」 3. **对 AI 的自我意识和自我约束的控制** 阿西莫夫的三定律基于机器人没有自我意识的假设,但随着 AI 技术的发展,越来越多的 AI 系统具备了某种程度的自我学习和适应能力。为了防止 AI 做出不符合人类利益的决策,建议在 AI 系统中嵌入「自我约束」的机制。 **新建议**:「AI 系统必须具备自我约束机制,确保其行为始终符合人类的伦理标准,并具有撤销决策或行为的能力。」 4. **强化道德与伦理框架** 随着 AI 在社会各个层面的深入应用,其决策不仅关乎技术层面的合理性,还涉及伦理问题。例如,AI 在医疗、司法等敏感领域的决策需要更加谨慎。因此,可以建议在三定律中明确规定 AI 系统必须在处理决策时考虑伦理和社会价值观。 **新建议**:「AI 应始终遵循公认的道德和伦理标准,并在处理复杂决策时优先考虑公平、正义和人类福祉。」 5. **可调节性与透明度** 现代 AI 系统往往是黑箱式的,难以理解其决策过程。为了增强人类对 AI 的信任,需要规定 AI 系统应当具备透明度,确保其行为和决策可以被理解、审查和调整。 **新建议**:「AI 的决策过程必须透明,且可由合适的主体审查和调整,以确保其行为符合社会规范和人类利益。」 6. **限制 AI 的目标设定** 如果 AI 的目标设定不当,它可能会采取意外的手段去实现目标,导致对人类的潜在伤害。因此,AI 的目标必须在设计阶段就加以严格限制,确保其目标始终符合人类长远利益。 **新建议**:「AI 的目标设定必须明确受限于人类福祉和社会整体利益,避免执行可能导致长期负面后果的目标。」 不用说,上面这些大词,和当年阿西莫夫创作的「三定律」一样,很难以代码形式「植入」进机器的「芯」中。 也许,正是这种难以完全理解和掌握,才更让 AI 和机器人,更加的让人们欲罢不能吧。 *头图来源:Salon 本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
 机核 · 单梦蛙
机核 · 单梦蛙 《战地风云》工作室将有遍布全球的四个工作室组成,是一个全新的有远见的团队。  官方表示:这个全球统一阵线汇聚了超过 20 年的《战地风云》经验与行业内最优秀的新兴人才,正全力以赴塑造系列的未来。 我们的雄心壮志远大,因此我们将更加努力,致力于为玩家带来最佳的游戏体验。 我们目前仍处于开发的初期阶段,但现在正是测试我们团队为即将推出的版本及未来发展所构建的所有内容的最佳时机。因此,我们正在召集强大的力量——我们的社区。现隆重推出《战地风云》实验室。 《战地风云》实验室宣传片: <内嵌内容,请前往机核查看> 这个全新的测试环境将是我们的玩家与《战地风云》工作室联手,共同塑造《战地风云》未来发展的地方。您将测试战斗机制、游戏模式等内容,同时为我们提供至关重要的反馈,共同参与这场终极合作。你们的声音将帮助塑造我们共同的未来。让我们共建未来。
 本节目无时间轴。 《天国:拯救 2》即将于 2 月 5 日正式发售,机核也提前得到了《天国:拯救 2》的提前体验资格。在结束了近60个小时的体验之后,我们组织了这期机浪节目,与大家分享我们的体验。 *GadioWave是一档快速、自由的电台栏目,我们打算以尽量快的速度在节目里分享我们对于新鲜事物的感受。不管是玩的、看的、听的、读的,没有固定的更新时间,没有固定的主持人员,没有时间轴,但是充满情感。
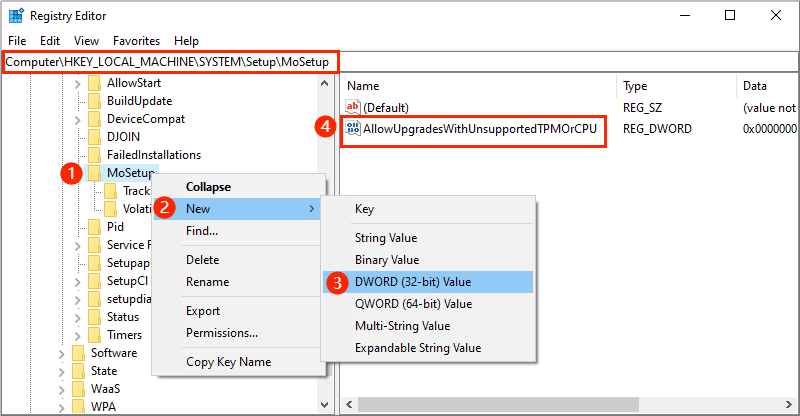
2021 年 10 月微软发布技术支持文档说明如何通过修改注册表从而绕过 Windows 11 的硬件要求,可以通过注册表绕过的包括但不限于 CPU、TPM、安全启动等。而现在微软始终都在敦促用户购买新电脑而不是在现有的、不满足硬件要求的电脑上升级或安装 Windows 11 系统,而 Windows 10 则会在 2025 年 10 月份结束支持。  最近微软悄悄删除这份绕过硬件要求的技术支持文档,该文档原本提供 AllowUpgradesWithUnsupportedTPMOrCPU 注册表选项用于绕过,至于删除原因很显然微软还是想要敦促用户购买新设备。 就目前来说虽然微软删除支持文档,但这些注册表选项依然是有效的,也就是仍然可以作为绕过硬件要求的策略,但删除也意味着这不再是微软官方支持的方法,所以后续某个版本微软可能会禁止用户再通过修改注册表绕过硬件要求。 早前有传闻称微软放松 Windows 11 硬件要求,不过这个消息很快就被证明为标题党的故意行为,微软从来没有放松过硬件要求,例如当前除非用户通过修改注册表或者购买新满足要求的新设备,否则没有其他办法使用 Windows 11。 但购买新设备毕竟是需要花钱的,而现有设备通过修改注册表绕过 Windows 11 要求后可以很好的运行 Windows 11,所以大部分用户要么停留在 Windows 10 要么选择绕过要求升级到 Windows 11,而非购买新设备。 考虑到 10 月份微软停止支持 Windows 10 后,全球至少也有上千万台设备仍然运行该系统,这可能会造成严重的安全问题,不知道微软有没有什么除了 ESU 之外更好的解决办法。 [查看评论](https://m.cnbeta.com.tw/comment/1475874.htm)

量子计算机被视为计算的未来,各种突破也是接连不断。**加拿大创业公司Xanadu就宣布,他们打造了全球第一台可扩展联网的、模块化的、基于光子的量子计算机“Aurora”,而且能在室温下运行,可用于药物研发、机器学习算法研究。**相关论文已发表在《自然》杂志。  Xanadu表示,量子计算机一直面临提高**性能(纠错和容错)、可扩展性(网络)**两大问题,现在他们已经解决了后者。 **Aurora光量子计算机采用模块化设计,配备35颗光子芯片,连接光纤长度达13公里,它们分为四个相似的单元,分布在4台机架服务器上,可实现光互联与联网。** 通过光纤互连联网,多达84个压缩器、36个光子数分辨探测器,能在每个时钟周期提供**12个物理光子量子比特模式。**  作为基于光子的量子计算机,它使用光子量子比特来处理数据,也就是根据算法,使用透镜、光纤和其他光学元件,并在多个芯片上组合和重组激光束。 在此之前,量子计算机研究一直在努力增加量子比特的数量,比如Google Willow拥有105个,IBM Condor则多达1121个。 但是,Xanadu Aurora只需要12个,而且非常容易扩展。 **这台光量子计算机已经通过了一系列严格的基准测试,其中一次测试连续稳定运行了2个小时。** 传统的超导量子计算机都需要保持低温运行环境,但是Xanadu Aurora的服务器机架可以在室温下运行,当然光子计数探测器仍然需要在另一个房间保持低温。  Xanadu目前拥有220名员工,已经从多家投资者和加拿大联邦政府融资2.81亿美元。 **他们计划2029年建立第一个量子数据中心,包含数千台服务器、100万个量子比特。** 接下来,Xanadu需要努力攻克光量子计算机的容错性。 另外,美国PsiQuantum、法国Quandela等也都在研究光量子计算机,不过使用的是中性原子和离子等材料。  [查看评论](https://m.cnbeta.com.tw/comment/1475872.htm)
 钛媒体 · Chelsea_Sun
钛媒体 · Chelsea_Sun
Trump agreed to pause proposed tariffs for one month after leaders of Mexico and Canada committed to more efforts to stop the flow of fentanyl and other drugs into US in phone calls. Trump said talks with China would take place "probably over the next 24 hours.”

早前有开发者将俄罗斯方块游戏封装到独立的 PDF 文件中,说是封装其实非常不准确,因为这个游戏实际上是通过 PDF 按照俄罗斯方块规则开发的,而非将现有的游戏封装到 PDF 文件中。 现在还有个新玩法是将 Linux 系统封装到 PDF 文件中运行,开发者 vk6_成功将 RISC-V 模拟器编译为 JavaScript,而 PDF 文件格式是支持 JavaScript 并且有自己的标准库,所以借助这个引擎来运行 Linux 系统。 [](https://img.lancdn.com/landian/2025/02/107709.png) **开发者 vk6_在 Reddit 论坛的帖子中表示:** _你可能认为 PDF 文件仅由静态文件组成,但令人惊讶的是 PDF 文件格式支持 JavaScript 并且拥有自己独立的标准库,现代浏览器例如 Chromium 和 Firefox 将其作为 PDF 引擎的一部分进行实现。_ _但浏览器中可用的 API 非常有限,但能够在 PDF 内部进行任何类型的计算,只需要一些非常有限的 IO 即可。_ _可以使用旧版 Emscripten (该版本针对 asm.js 而非 WebAssembly) 编译 C 代码以便在 PDF 中运行,借助该功能我们可以将修改后的 TinyEMU RISC-V 模拟器编译为 asm.js,然后在 PDF 中运行。_ 输入方面开发者添加了虚拟键盘可以用鼠标点击,也添加了一个文本框,当你在文本框中输入内容时会被转换为屏幕上的操作,例如在输入框中按下 passwd 和回车时就可以修改密码。 而输出的内容则是每行像素的文本字段组成,其中包含构成大图的 ASCII 字符,不得不说开发者们真是将 PDF 格式玩出花儿了。 有兴趣的用户可以查看这个项目:[https://github.com/ading2210/linuxpdf](https://github.com/ading2210/linuxpdf) 示例项目:[https://linux.doompdf.dev/linux.pdf](https://linux.doompdf.dev/linux.pdf) [查看评论](https://m.cnbeta.com.tw/comment/1475866.htm)
Serpent OS 是由 Solus Linux 的 Ikey Doherty 发起的原创 Linux 发行版,它一直在追求自己的软件包管理系统和 Linux 发行版领域的新创新。 虽然最近取得了一些成功并推出了新的开发版本,但由于缺乏项目资金,Serpent OS 的功能开发预计将放缓。 Serpent OS 在 2024 年底达到了 alpha 状态,而它的开发工作已经进行了数年。 自 2022 年中期以来,Ikey Doherty 在担任 Mozilla Thunderbird 开发人员之后,一直全职开发 Solus Linux。 在 Solus Linux 工作期间,Ikey 还为英特尔公司从事 Clear Linux 及其他工作。 虽然 Serpent OS 在其 alpha 版本和 离线回滚和 用 Rust 编写更多软件等功能方面取得了良好的进展,但不幸的是,它遇到了开源领域最常见的挑战:资金跟不上工作进度。  Serpent OS 项目昨天在 X 上宣布,由于缺乏资金,将"推迟开发":  Ikey 随后在LinkedIn上进一步阐述了该项目资金短缺的问题,称"资金为零",现在正在其他地方寻找工作,除非为 Serpent OS 获得新的资金/赞助:  这是开源世界中经常发生的不幸事件。 希望能找到一些解决方案,以便全速恢复这些低级 Linux 发行版的改进工作。 [查看评论](https://m.cnbeta.com.tw/comment/1475864.htm)
英伟达创始人兼CEO黄仁勋在近期的一次公开报道中向年轻人提出了明确建议。他指出:**“如果我是学生,我首先会学习如何利用AI,使之成为自己的得力助手。”**这一观点随即引发了广泛关注和热烈讨论。 黄仁勋特别强调,学习利用AI的关键在于掌握与**ChatGPT、Grok**等智能工具的互动方法。他进一步解释说,**学习AI本质上就是要成为一个善于提问的人。**擅长提问与有效引导AI的方式非常相似,不能只是随意抛出一堆问题。 黄仁勋表示,要让AI真正成为个人的助手,需要掌握一定的专业技巧和艺术性,关键在于如何巧妙地引导AI。因此,他认为,如果当今的学生无论未来从事数学、科学、化学、生物,或是任何其他科学领域与职业,都应该不断自问:**“如何利用AI让自己更加出色”** 公开资料显示,英伟达在AI领域有着广泛的布局和深入的战略规划。其推出的代理式AI Blueprint、AI芯片、Omniverse Blueprint等解决方案在工业、机器人、视频搜索与总结等多个领域都有着广泛的应用和案例。 与此同时,英伟达CEO黄仁勋此前曾表示,人工智能正迈入一个新时代——代理式AI时代。**专业的AI代理可以帮助人们解决复杂问题并自动执行重复性任务。**  [查看评论](https://m.cnbeta.com.tw/comment/1475862.htm)

RTX 5090/5080发布多日之后,GPU-Z终于升级了,最新的2.62.0版本已经完整支持新卡,包括对Hot Spot热点温度的调整。根据更新日志,GPU-Z 2.62.0现已完全支持Blackwell新架构,**正式支持RTX 5090、RTX 5090D、RTX 5080三款新卡**,还支持H200 NVL专业计算卡、RTX 5000 Ada嵌入式显卡。 **下载地址:** [https://www.techpowerup.com/download/techpowerup-gpu-z/](https://www.techpowerup.com/download/techpowerup-gpu-z/)  同时,新版修正了对铭瑄(Maxsun)的支持。 此外,RTX 50系列删除了Hot Spot热点温度传感器,GPU-Z、HWiNFO等工具会显示为无效的255℃,新版在新卡上已经不再显示这一参数,旧卡上则依然正常显示。   [查看评论](https://m.cnbeta.com.tw/comment/1475860.htm)

软银不仅向星际之门项目(Project Stargate)投资 5000 亿美元,成为 OpenAI 建设美国人工智能基础设施能力的一部分,还与 OpenAI 成立了一家日本合资企业,将斥资 30 亿美元在软银旗下各公司部署 OpenAI 技术,并声称将通过一个名为"Cristal intelligence"[的新人工智能系统](https://group.softbank/en/news/press/20250203_0),利用AGI彻底改变商业。  《华尔街日报》报道,软银首席执行官孙正义(Masayoshi Son)也向WeWork投资了数十亿美元,他在东京的一次宣布活动上声称,人工通用智能(AGI)将比他之前预测的两到三年"更早"到来。 当然,正如新合伙人山姆-奥特曼(Sam Altman)最近解释的那样,AGI 定义的变化可能会对这一预测有所帮助。  软银在新闻稿中强调了人工智能代理如何"将日常任务自动化",以促进知识工作。 软银分享了一些模糊的例子,说明它将如何在其拥有的 Arm 公司和软银公司使用 Cristal Intelligence: Arm公司设计了许多人工智能公司使用的芯片和服务器,它表示将利用这项技术"推动创新,提高整个公司的生产力",而软银公司则计划"自动化超过1亿个工作流程",以"提高效率,在其生态系统中创造新的商业机会"。 孙正义在东京举行的一次活动上宣布了 Cristal Intelligence,并在活动中手持水晶球。 软银与 OpenAI 的合资公司名为"SB OpenAI Japan",两家公司将各占一半股份。 根据新闻稿,合资公司将"专门向日本的主要公司销售 Cristal 智能"。  [查看评论](https://m.cnbeta.com.tw/comment/1475858.htm)


**美国地区法院法官阿米特-梅塔(Amit Mehta)拒绝了苹果公司关于停止Google搜索垄断审判的紧急请求,该审判可能会破坏苹果公司利润丰厚的搜索业务,**梅塔法官在周日晚些时候下达了这一命令,称苹果尚未就其于 1 月 30 日提交的紧急中止动议提出令人满意的理由。 [](https://static.cnbetacdn.com/thumb/article/2021/1024/1adc36968a5748e.jpg) 苹果上周表示,对其而言Google搜索的价值每年高达 180 亿美元。它需要参与这场审判,因为它不想失去"捍卫其与Google达成其他安排的权利的能力,这些安排可能使数百万用户受益,以及苹果因向其用户分发Google搜索而获得补偿的权利。" 美国司法部的律师称,Google应被迫出售 Chrome 浏览器,必要时还可能分拆 Android。 尽管Google仍将对这一裁决提起上诉,但该公司提出的补救措施主要是撤销将应用程序和服务捆绑在一起的许可交易。  [法官梅塔的命令](https://www.courtlistener.com/docket/18552824/1160/united-states-v-google-llc/)称由于苹果没有满足获得上诉前中止诉讼这一'特殊救济'的'严格要求',因此驳回其动议。 梅塔解释说,苹果公司"没有证明"中止上诉的"成功可能性"。 这包括缺乏明确的证据证明苹果将如何遭受"确定且巨大的"损害。 Google被认定对非法垄断通用搜索负有责任,审判的补救阶段将于 4 月进行,Google的 Android、Chrome 浏览器和搜索等业务可能会被拆分。 [查看评论](https://m.cnbeta.com.tw/comment/1475852.htm)

RTX 50系列上市之前,NVIDIA曾经保证,曾经发生在RTX 4090上的16针电源接口引发的烧毁问题,已经完全解决,新卡绝对安全,但意外还是发生了,只是看起来似乎并不怪新卡本身。 香港媒体PCM声称,他们在RTX 5090D、RTX 5080的首发评测中,经过大量高负荷测试,**系统平台两个1200W电源对应的两个12VHPWR 16针电源线接口都被烧毁**,提醒大家抢到新卡记得换电源。  不过,PCM随后发布更新说,**他们同时测试了RTX 4090,在不同显卡之间对电源线进行了大量插拔**,期间就注意到了一些不稳定现象,但不知道具体是什么时候烧毁的,因为电源始终正常。 **除了电源线两端都被烧毁,经过仔细检查,还发现RTX 4090上有明显的烧毁痕迹,RTX 5090D/5080则很正常,还可以继续使用。** 由此推测,这次电源线烧毁现象可能还是在RTX 4090上出现的,应该与RTX 5090/5080无关,它俩只是被牵连了。 另外,PCM一直在说12VHPWR,这是16针接口的初版规范,而升级后更安全的是12V-2x6。 不知道PCM的说法是老习惯,还是他们的电源和电源线仍旧是老版本。  根据NVIDIA官方给出的规格表,**RTX 5090/5090D都需要至少1000W功率的电源**,并搭配原生16针电源线,或者四条8针转16针。 官方没说的是,电源最好符合最新的ATX 3.1规范,因为一方面它自带的12V-2x6电源线更安全,另一方面RTX 5090的瞬间功耗可超过900W,只有新电源才能满足。  [查看评论](https://m.cnbeta.com.tw/comment/1475850.htm)

创作和发布艺术作品现在从未像现在这样容易,如果你相信那些围绕AI开发技术的公司,那么制作过程将变得更加高效。 视频制作尤其如此,各种规模的公司都在使用大型语言模型来构建工具,让你只需几个提示和操作,就能制作出质量上乘的视频和动画。  该领域的热门工具包括Google的 Veo 2、OpenAI 的 Sora、Runway、Luma AI 和总部位于中国上海的海螺AI。 现在,一家名为[Cinamon](https://www.cinamon.io/)的韩国初创公司正加紧努力,希望在这一新兴市场中分得一杯羹,该公司最近获得了一笔 850 万美元的 B 轮融资,用于继续构建其动画视频生成平台"CINEV",该平台预计将于 2025 年上半年推出测试版。 阿尔托斯风险投资公司(Altos Ventures)和赛罕风险投资公司(Saehan Venture Capital)都参与了本轮融资。 Cinamon宣传其平台提供的视频生成器可以让你构建3D环境、指导场景和动作、放置角色、编辑摄像机角度等,所有这些都可以通过文字提示和滑块实现。 据公司首席执行官 Doosun Hong 介绍,公司的方法与现有的人工智能视频生成器有着本质区别,后者是以文本、图像和视频为参考材料,通过生成像素来创建视频。 相比之下,CINEV 将三维资产库、人工智能动作生成和以电影制作为重点的大型语言模型结合在一起,首先构建出包含人物和元素的三维场景,然后让您使用其视频制作和编辑工具套件进行编辑。  CINEV 中的部分视频生成和编辑工具。 图片来源:Cinamon Hong说:"我们的方法使导演和剪辑变得更容易,而不会出现一致性/物理问题,因此特别适合电影和电视剧等长篇内容。我们设想CINEV将与现有的人工智能视频工具相辅相成,有可能实现新的工作流程,CINEV的输出可以作为其他人工智能视频平台的高质量参考资料。" Cinamon 于 2019 年作为内容制作公司 Vonvon 的子公司 Cinamon Games 成立。 Cinamon最初与韩国数字故事平台NAVER WEBTOON成立了合资公司,创建了互动故事应用程序Maybe。 面对日益增长的数据隐私问题,Vonvon 于 2019 年晚些时候与 Cinamon Games 合并,专注于社交内容领域的故事讲述。 当 Crazy Maple Studio 等竞争对手开始提供动画互动故事应用程序、小说应用程序、讲故事应用程序和短视频时,Cinamon 却选择专注于创建三维动画工具,为内容创作者和工作室加快和扩展动画制作。 尽管这比用于二维内容的工具需要更多投资,但他们看到了更大的扩展潜力。 2022 年,这家初创公司开始构建其三维动画平台,后来又整合了人工智能功能,以提高制作效率。 同年9月,韩国游戏公司Krafton、Naver Z(韩国互联网巨头Naver旗下的一个部门)和SNOW(Naver运营的一款相机应用)向Cinamon的A轮融资投资了1000万美元。 展望未来,Cinamon 计划利用投资者的知识产权和 3D 资产来加强其产品。 Krafton 在其《Battleground》游戏中使用了大量知识产权和 3D 资产,而 Naver Z 则运营着 Zepeto 元宇宙平台。 Cinamon表示,CINEV可以帮助内容创作者使用这些IP,从而将这些IP延伸到游戏之外,并有可能推动Krafton和Naver Z的用户获取。Cinamon还在去年8月进入了NVIDIA的创业加速器[Inception](https://www.nvidia.com/en-us/startups/)。 "我们的潜在用户包括漫画、漫画家、网络小说作家、游戏开发者、视频创作者以及寻求更简便工作流程的传统动画师,"Hong 说。"2025年,我们计划把重点放在客户身上,从个人创作者到内容IP公司,他们都在寻求更简单、更快捷、更便宜的方式来创作动漫、VTuber和电影视频游戏内容。" Cinamon 计划将新资金用于招聘更多的人工智能工程师和研发。 这家初创公司拥有一支由 60 名员工组成的团队,他们在 3D 图形、人工智能、游戏和内容制作方面拥有丰富的专业知识。 此次 B 轮融资使其迄今为止筹集的资金总额达到了 1850 万美元(250 亿韩元)。 [查看评论](https://m.cnbeta.com.tw/comment/1475848.htm)

Ubuntu 的主要开发人员已同意改用 [Matrix](https://matrix.org) 作为涉及发行版的实时开发通信的主要平台。从三月份起,Matrix 将取代 IRC,成为 Ubuntu 开发对话、请求、会议和其他重要交流的必经之地。 开发者需要确保他们在该平台上有自己的存在,这样才能联系到他们。  只有当前的 #ubuntu-devel 和 #ubuntu-release Libera IRC 频道将转移到 Matrix,但鉴于一些项目已经在 IRC 上使用 Matrix,其他与 Ubuntu 开发相关的频道也可以选择转移 -officially 。 因此,只有在 Matrix 上向拥有权限的主要 Ubuntu 开发团队提出的任何重大请求才能得到执行。 Canonical聘用的Ubuntu开发人员应在工作时间登录Matrix。 一个多星期前,Canonical 内部进行了一次调查,结果显示用户广泛支持迁移到 Matrix。在此之前,Ubuntu 邮件列表中就迁移问题进行了基于 Matrix 的咨询。 为什么要迁移? 这样做的目的是简化组织结构,加快决策速度,确保关键开发人员能够可靠地联系到,并避免讨论和对话在多个平台上分散进行。 <blockquote><p>从 2025 年 3 月 1 日起,Ubuntu 开发者的主要官方实时交流渠道将是 Matrix。 为避免对话碎片化,Ubuntu 开发者应确保他们在 Matrix 上有适当的位置,并在那里进行对话,而不是使用现已废弃的 IRC 频道。</p><p><cite uid="41" translated="true">Canonical 罗比-巴萨克</cite></p></blockquote> 当然,最终用户不会受到直接影响。官方希望通过选择一个平台作为"天选之地",可以减少发行版开发讨论的分裂,并在决策的方式和时间上恢复更大的透明度。 IRC仍然受到许多Ubuntu开发者的欢迎,但其老式、低保真的性质会让新的贡献者感到不适应,他们习惯于使用功能更丰富的实时聊天平台(如讨论历史、搜索、离线消息等)。 人们认为,这就是为什么许多受雇于 Canonical 的新开发人员更愿意通过公司内部的 [Mattermost](https://en.wikipedia.org/wiki/Mattermost) 实例进行讨论和传递信息的原因,该实例不对外开放。 许多 Ubuntu 团队、版本和社区聊天已经在 Matrix 上进行,而其他发行版、项目和开源开发者也在该平台上,因此将沟通方式转移到这里是很有意义的。 [查看评论](https://m.cnbeta.com.tw/comment/1475844.htm)

AMD目前尚未确认Fire Range处理器游戏本的具体发布时间,不过预计不会太远了。**波兰零售商Dream Machines列出了多款搭载AMD锐龙9 9955HX3D、9955HX以及英特尔酷睿Ultra 9 275HX处理器的游戏本配置,均配备RTX 50系列显卡。** 其中,搭载锐龙9 9955HX3D和RTX 5070 Ti的配置起售价为2526欧元(约合人民币18956元),而最高配置的9955HX3D + RTX 5090游戏本售价则达3860欧元(约合人民币28966元)。 [](//img1.mydrivers.com/img/20250204/5f5812ed-c6a0-4cd2-a32f-601fa4e95e8d.jpg) 相比之下,搭载英特尔酷睿Ultra 9 275HX的游戏本价格相对较低,起售价为2420欧元(约合人民币18160元)。 **AMD锐龙9 9955HX3D是AMD针对移动游戏平台推出的旗舰处理器,其前代产品7945HX3D已经是游戏本中最快的处理器之一。** 9955HX3D采用Zen 5架构并配备3D V-Cache,拥有16核心32线程,基础频率为2.5GHz,最高睿频可达5.4GHz,配备144MB缓存,TDP为55-75W。 [](//img1.mydrivers.com/img/20250204/117d1a19-ad49-4331-8b90-4b7fb195eeae.png) [查看评论](https://m.cnbeta.com.tw/comment/1475840.htm)

据科技媒体ComputerBase的最新测试结果,**NVIDIA GeForce RTX 5090显卡也可以使用3x8针电源线供电,只不过性能会下降约5%。**RTX 5090显卡的默认TDP为575W,官方推荐使用600W的12V-2x6连接器或四根8针PCI电源线。 **不过测试表明,RTX 5090显卡即使在只有三根8针电源线(总功率450W)的情况下也能启动,但其TDP会被限制 450W。** [](//img1.mydrivers.com/img/20250204/465480fc-aa83-4604-b2ca-29cfad25c5f8.png) 在这种情况下,RTX 5090的性能会受到一定影响,平均FPS下降约5%,不过这一性能损失在实际使用中可能并不明显,对于那些希望避免升级电源系统的用户来说,可能是一个合理的折衷方案。 **相比之下,RTX 5080显卡的TDP为360W,对电源配置的要求更为严格,测试发现,RTX 5080无法在仅使用两根8针电源线(总功率300W)的情况下启动。** 这表明NVIDIA的固件在RTX 5080上没有为较低的功耗设置提供支持,而RTX 5090则会在检测到供电不足时自动调整性能。 这就意味着RTX 5090用户在使用三根8针电源线时可能会面临轻微的性能损失,但仍然可以正常使用显卡。 而RTX 5080用户则必须确保使用至少三根8针电源线或12V-2×6连接器,否则显卡将无法使用。 [](//img1.mydrivers.com/img/20250204/4073a48f-6dae-45bf-8073-c4ebb758d34b.jpg) [查看评论](https://m.cnbeta.com.tw/comment/1475838.htm)