与AI合作必备:产品经理的模型原理与应用指南
随着AI技术的飞速发展,大模型如ChatGPT、Stable Diffusion等已广泛应用于产品开发中。然而,许多产品经理对AI模型的原理和应用仍缺乏深入了解。本文将从产品视角出发,深入剖析AI模型的底层原理、训练流程、评估方法以及典型应用场景,为产品经理提供一份清晰、实用的AI产品实战指南。

AI技术日新月异,大模型如ChatGPT、Stable Diffusion 已经走入产品一线。作为产品经理,是否该深入算法底层?
其实,不需要精通编程或建模,只要掌握常见模型的原理、能力边界和典型应用场景,就能让你的产品更智能、更高效。
本文将从一个产品视角出发,逐步拆解大模型背后的“原理+应用+落地方案”,覆盖从文本生成到图像识别,从语音交互到智能Agent,为你提供一份清晰、可落地的 AI 产品实战指南。
01 底层原理:AI如何像人类一样思考
人工智能简单来说就是机器对人类智能的模仿,对人的思维或行为过程的模拟,让它像人一样思考或行动。人类不断的积累经验,从而应对新的情况出现时能优化之前的行为。

那么机器,根据输入的信息(data)能进行模型结构,再输入新的信息时,能自行优化模型的结果,从而优化输出的结果,甚至超越人类。
1.1 从规则驱动到数据驱动:AI进化简史
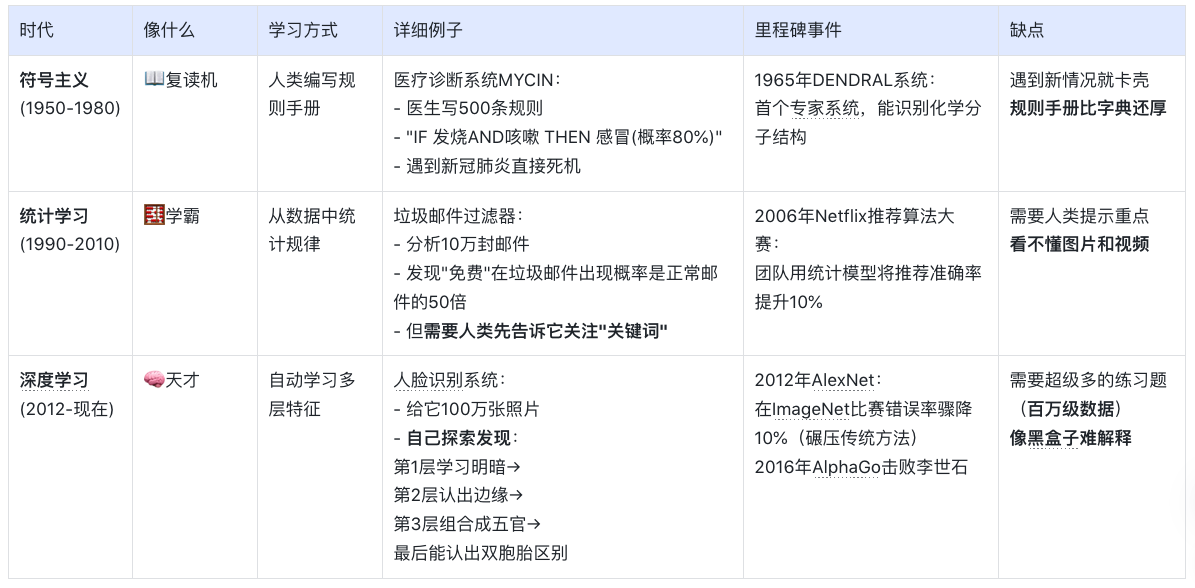
(1)符号主义时代(1950s-1980s)
代表:专家系统(如医疗诊断MYCIN)
特点:依赖人工编写规则,遇复杂问题崩溃
产品启示:规则系统仍用于简单场景(如客服FAQ)
(2)统计学习时代(1990s-2010s)
代表:垃圾邮件过滤(贝叶斯算法)
突破:从数据中自动发现规律
(3)深度学习革命(2012-至今)
里程碑:AlexNet在ImageNet竞赛碾压传统方法
关键转变:特征工程→特征自动学习
使用一个很形象的例子:
1.2 关键三要素:数据/算法/算力的协同作用
人工智能的概念提出许久,现在火了更像是集中了天时地利人和。人工智能的三大基石:算法、算力、数据。
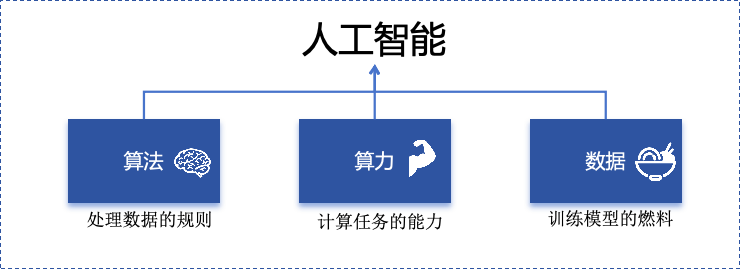
算法:2012年出现的深度卷积神经网络,能大幅提升图像识别准确率,标志深度学习进入实用阶段;2017年的Transformer架构解决了长序列数据处理难题,推动自然语言处理NLP,成为了GPT等大模型的基础。
- 算力:GPU、TPU等专用硬件大幅提升计算效率,训练时间从数月缩短到几天,使训练百亿参数级模型成为可能。
- 数据:得益于互联网的发展积累了海量的数据、图形等,大量的数据提供了模型训练的燃料,而数据的质量也决定了模型的准确率。
1.3 神经网络:模仿人脑的”分层学习法”
首先要对神经网络所处的位置进行阐述,人工智能的实现方式主要包括符号学习与机器学习两类:
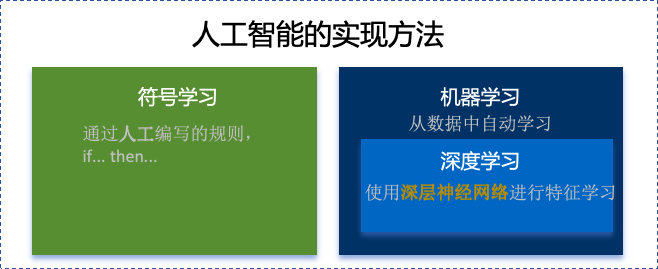
- 符号学习(对应前文的符号主义时代):通过人工编写的规则来模拟人类推理。典型应用是专家系统(如IBM深蓝国际象棋程序)。局限性在于全部依赖人工预设的规则,无法处理未知的场景。
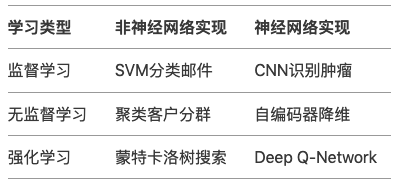
- 机器学习(对应前文的统计学习时代与深度学习革命):从数据中自动学习规律,主要分类方式有监督学习(分类、回顾),无监督学习(聚类、降维),强化学习。所谓的深度学习(使用了神经网络)其实是一种非常强大学习工具,可以用,可以不用,如下图所示:
为什么说神经网络强大,先来看看它的原理。神经网络是一种模仿生物神经系统结构和功能的计算模型,就像人类大脑由数十亿个相互连接的神经元组成一样,人工神经网络也由大量相互连接的人工神经元(或称”节点”)构成,这些神经元通过协同工作来处理复杂的信息。
神经网络之所以被称为”分层学习法“,是因为它采用层级结构来处理信息。与传统的单层机器学习模型不同,神经网络通过多个处理层(包括输入层、隐藏层和输出层)逐步提取和转换数据特征,每一层都会对数据进行一定程度的抽象和理解,最终实现对复杂模式的识别和预测。
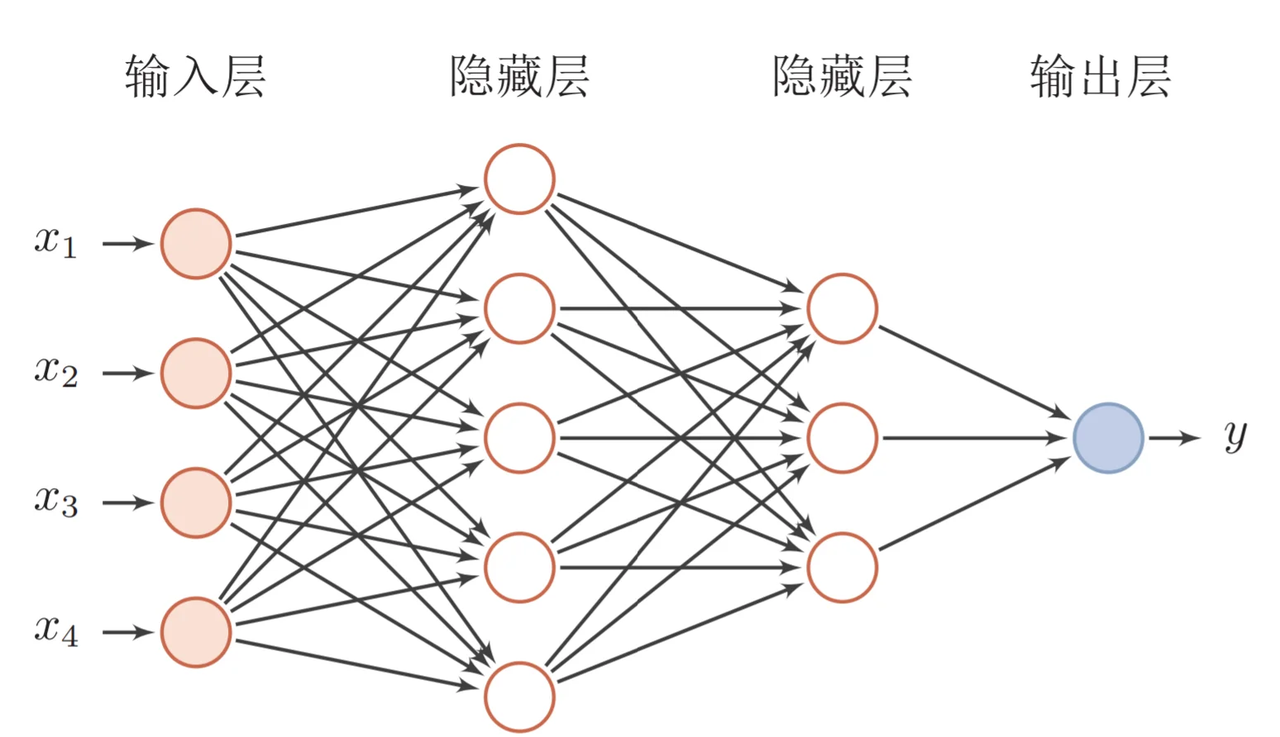
一个典型的神经网络由三个主要部分组成:
- 输入层:这是网络的”感官”部分,负责接收原始数据。比如在图像识别任务中,输入层可能是图像的像素值;在语音识别中,可能是声音信号的频率特征。
- 隐藏层:这是网络进行实际”思考”的部分,由多层神经元组成。每一层都会对前一层的输出进行变换和抽象,逐步提取更高层次的特征。隐藏层的层数和每层的神经元数量决定了网络的深度和复杂度。
- 输出层:这是网络产生最终结果的部分。根据任务的不同,输出可能是类别标签(如”猫”或”狗”)、连续值(如房价预测)或更复杂的数据结构(如句子翻译)。 这些层之间的连接都有相应的”权重”,这些权重决定了信号在神经元之间传递的强度,也是网络通过学习不断调整的关键参数。
1.4 产品经理必懂的3个技术概念(Transformer/注意力机制/损失函数)
1)Transformer
Transformer是一种基于自注意力机制的神经网络架构,已成为NLP(Natural Language Processing,自然语言处理)和CV(Computer Vision,计算机视觉)领域的标准模型(如GPT、BERT等)。
产品经理需要知道的要点:
- 并行处理优势:相比RNN(Recurrent Neural Network,循环神经网络)的顺序处理,Transformer可以并行处理所有输入,大幅提升训练速度
- 上下文理解能力:能够同时考虑输入的所有部分,实现更好的语义理解
- 可扩展性:模型规模可以灵活调整(参数量从百万到千亿级)
产品应用启示:
- 当需求涉及长文本理解时(如自动摘要),Transformer比传统模型表现更好
- 需要权衡模型大小与响应速度(大模型效果更好但更耗资源)
- 注意输入长度限制(如GPT-3最多2048个token)
补充说明:
Token是模型处理文本时的最小单位,可以是单词、子词或字符,具体取决于分词方式。例如:
- 英文场景:单词”unhappy”可能被拆分为子词“un”, “happy”作为两个token
- 中文场景:句子”产品体验优秀”可能被分词为“产品”, “体验”, “优秀”三个token
2)注意力机制
注意力机制模拟人类认知的聚焦能力,让模型能够动态决定输入的哪些部分更重要。
产品经理需要知道的要点:
- 权重分配:为输入的不同部分分配不同重要性权重
- 自注意力:让输入序列中的元素相互计算关联度(如理解”它”指代前文的哪个名词)
- 多头注意力:同时从多个角度计算注意力,捕捉不同维度的关系
产品应用启示:
- 解释为什么AI有时会”答非所问”(注意力分配错误)
- 设计产品时考虑提供更明确的上下文线索(帮助AI分配注意力)
- 在需要关系推理的场景(如客服工单分类)优先考虑基于注意力的模型
3)损失函数
损失函数量化模型预测与真实值的差距,是训练过程中优化的目标。
产品经理需要知道的要点:
常见类型:
- 分类任务:交叉熵损失
- 回归任务:均方误差
- 生成任务:对抗损失(GAN)
自定义可能性:可通过修改损失函数实现特殊业务目标
评估指标关联:损失函数值≠产品指标(如准确率),但通常正相关
产品应用启示:
- 当标准指标不满足业务需求时,可考虑定制损失函数
- 理解模型优化目标与实际业务目标的差异(如推荐系统可能过度优化点击率而忽略多样性)
- 评估训练进度时,除了看损失值下降,更要关注验证集的产品指标
02 模型训练:AI的”学习”过程揭秘
在AI产品的开发过程中,模型训练是最核心也最神秘的环节。对于产品经理而言,理解模型训练的基本原理和关键环节,不仅能帮助团队更高效地推进项目,还能避免许多常见的”坑”。
2.1 数据预处理:清洗/标注/增强的实战方法
AI需要大量的数据进行训练与学习,因此数据预处理是第一步。
(1)数据清洗:质量大于数量
在实际项目中,我们常常遇到”脏数据”的问题。比如在开发一个电商评论情感分析系统时,原始数据可能包含大量无关符号(如”####”)、乱码、甚至完全无关的内容。花在数据清洗上的每一分钟,都能为你节省后续十倍的调试时间。
常见的数据清洗方法包括:
- 去除重复样本(约5-15%的数据可能是重复的)
- 处理缺失值(删除或合理填充)
- 统一格式(日期、单位等标准化)
- 异常值检测与处理
实战技巧:建立一个可复用的数据清洗pipeline(一系列按顺序连接的处理步骤),将清洗规则代码化。例如使用Python的Pandas库,可以高效处理百万级的数据清洗任务。
(2)数据标注:成本与质量的平衡术
数据预处理环节并不一定要进行数据标注,是否需要数据标注取决于采用的机器学习方法:
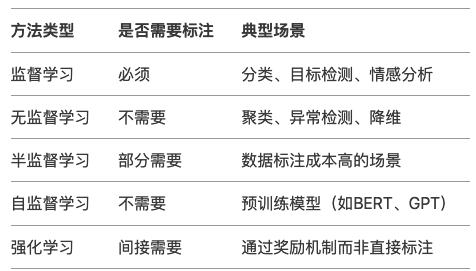
我们可以用下面的决策树图来判断是否需要标注以及如何实现标注:
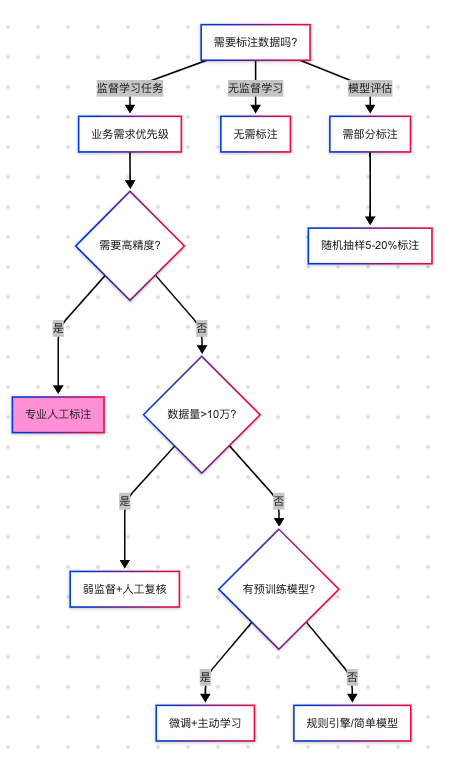
(1)弱监督+人工复核:
弱监督(Weak Supervision):用低成本方式生成“伪标签”,比如:
- 用关键词匹配(如评论含“太差”=差评)
- 用简单规则(如“订单金额>1000”=高价值客户)
- 用已有小模型预测(如用BERT初步标注文本情感)
人工复核:对弱监督结果抽样检查,修正错误
例子:
电商评论分类(好评/差评)
-弱监督:用“太棒了”“垃圾”等关键词自动打标签
-人工复核:随机抽10%检查,修正错误标签
(2)微调+主动学习:
- 微调(Fine-tuning):用少量标注数据调整已有模型,让它适应业务
- 主动学习(Active Learning):让模型自己挑“最难”的数据,人工标注这些关键样本,提升效率
例子:
法律合同风险检测
-微调:用1000条已标注合同训练BERT
-主动学习:模型找出“最不确定”的合同(比如既像高风险又像低风险),人工重点标注这些
(3)规则引擎/简单模型:
方法:
- 规则引擎(Rule-based):用if-else逻辑处理数据,例:“IF 评论包含‘退款’ THEN 分类为投诉”
- 简单模型(如逻辑回归、决策树):用少量标注数据训练可解释模型
例子:
客服工单自动分类
规则引擎:
-“无法登录” → 技术问题
-“我要退货” → 售后问题
简单模型:用500条标注数据训练决策树
2.2 训练流程四步法:前向传播→损失计算→反向传播→参数更新
下图所示,是一个模型的训练过程,我们按照步骤进行讲解:
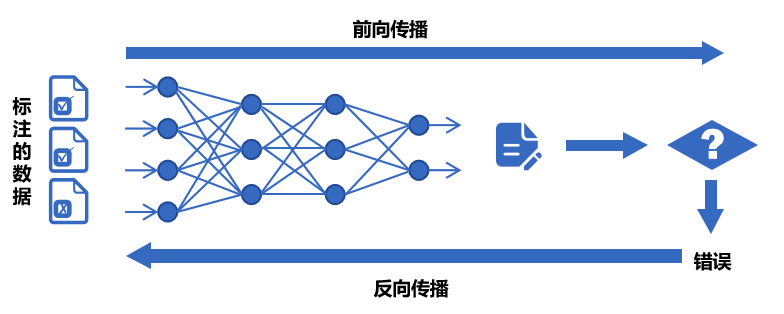
(1)前向传播:模型的”初次尝试”
就像第一次按照食谱做蛋糕,模型接收输入数据(原料),根据当前参数(食谱步骤),输出预测结果(成品)。
假设我们要训练预测商品价格的模型:
- 输入数据:商品类别、品牌、历史销量、评论数
- 当前参数:初始随机设置的权重(类似新手厨师的直觉)
- 预测输出:预估价格(如¥299)
(2)损失计算:量化”错误”程度
比较预测值与真实值的差距,这些训练数据对应的有真实的值,将真实值与第一步模型计算出来的值进行量化比较。做一个简化的例子:
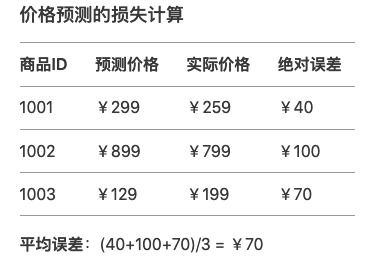
(3)反向传播:找出”失败原因”
不用担心,这一步是系统自动完成的(框架如PyTorch/TensorFlow实现),比如在前面的例子,通过数学方法计算:
- 品牌权重对误差贡献:35%
- 评论数量权重:15%
- 历史销量权重:50%
(4)参数更新:调整权重
根据归因结果调整参数,比如:
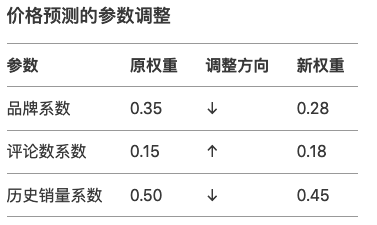
不断的重复上面过程调整权重与参数,何时停止训练:
- 当验证集准确率连续3轮无提升
- 边际收益<1%时,边际收益 = (本轮指标 – 上轮指标) / 训练成本
2.3 产品经理最常踩的3个坑(过拟合/数据泄漏/算力浪费)
在AI产品的落地过程中,产品经理往往更关注业务需求而忽略技术细节,但以下3个技术问题一旦发生,轻则导致模型失效,重则引发生产事故。
坑1:过拟合(模型”死记硬背”)
问题现象:模型在测试数据上表现优异,上线后效果断崖式下跌。典型案例:某电商优惠券预测模型,训练准确率98%,实际发放后转化率不足5%
本质原因: 模型过度拟合训练数据中的噪声(如特定用户ID、时间戳等无关特征),丧失了泛化能力。就像学生只会背例题却不会解新题。
避坑方法:
1.数据层面:
- 确保训练数据覆盖足够多的场景(如不同时段、地域、用户群)
- 通过交叉验证检查过拟合(训练集/验证集效果差异>15%即预警)
2.产品设计层面:
- 设置灰度发布机制,先对小流量用户测试模型效果
- 监控核心指标衰减(如推荐系统的点击率周环比下降超20%需介入)
坑2:数据泄漏(”考试泄题”式作弊)
问题现象:模型开发阶段表现反常识地好,上线后完全失效。典型案例:某金融风控模型在训练集上AUC=0.99,实际识别欺诈准确率仅60%,后发现训练数据混入了未来信息(用还款结果反推风险等级)
本质原因: 训练数据中混入了本应在预测时才能获取的信息(如用”用户最终购买结果”作为”点击预测”的特征),相当于让模型提前知道答案。
避坑方法:
1.特征工程隔离:
- 严格区分特征数据时间戳(如只能用用户历史行为,不能用未来行为)
- 产品PRD中明确标注每个特征的可用时间范围(示例)
2.流程管控:
- 要求算法团队提供《数据隔离说明文档》
- 在AB测试时使用全新时间段的验证数据
坑3:算力浪费(”大炮打蚊子”)
问题现象:简单业务使用千亿参数大模型,服务成本飙升10倍。典型案例:某企业用GPT-3处理客服FAQ匹配,每月算力支出20万+,后改用轻量级BERT模型效果相近,成本降至5000元/月
本质原因: 错误认为”模型越大越好”,忽视业务实际需求与ROI评估。
避坑方法:要求技术团队公开模型推理的**单次调用成本,**例如
- 当前模型 gpt-3.5-turbo
- 单次成本 0.002元/请求
- 日均成本 240元(12万次/天)
2.4 微调(Fine-tuning)与迁移学习:低成本适配业务场景
在AI产品落地时,从头训练模型就像“为了喝牛奶养一头牛”,成本高且不现实。而微调(Fine-tuning)和迁移学习(Transfer Learning)能让产品经理用20%的成本,获得80%的定制化效果。
迁移学习:把预训练模型(如BERT、GPT)的通用知识“迁移”到新任务。类比:医学院学生先学基础解剖学(通用知识),再专攻心脏外科(垂直领域)
微调:在预训练模型基础上,用业务数据做小规模调整。类比:咖啡师用标准意式咖啡机(基础模型),根据本地顾客口味微调研磨度(业务适配)
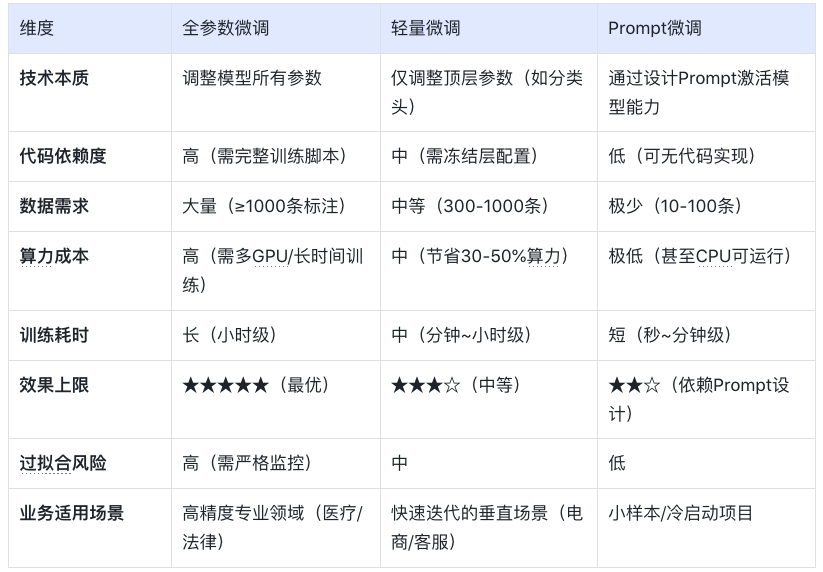
产品经理必知以下三种微调策略:
策略1:全参数微调(适合高精度场景)
操作:调整模型所有参数
案例:某法律合同审核系统,用2000条标注合同微调BERT,准确率从75%提升至92%
成本:需GPU算力支持,适合数据量>1000条的场景
策略2:轻量微调(适合快速试错)
方法:仅调整模型最后几层(如分类头)+ 冻结底层参数
案例:跨境电商用500条英语商品评论微调多语言BERT,一周内上线小语种分类功能
优势:节省80%训练资源,适合MVP阶段
策略3:Prompt微调(适合小样本场景)
创新点:通过设计提示词(Prompt)激活模型能力
用下面的表进行三种策略对比:
03 模型评估:如何判断AI是否靠谱
3.1 常用指标全解读
(1)准确率(Accuracy):模型预测正确的样本占总样本的比例
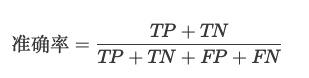

(2)精确率(Precision) vs 召回率(Recall)
精确率(查准率):预测为正的样本中,真实为正的比例(TP/(TP+FP))。用于“减少误伤”(如金融风控中,避免将正常交易误判为欺诈)。
召回率(查全率, TPR):真实为正的样本中,被正确预测的比例(TP/(TP+FN))。用于“宁可错杀,不可放过”(如癌症筛查,漏诊代价远高于误诊)。
矛盾关系:提高召回率通常需降低精确率(可通过调整分类阈值平衡)。
(3)F1值:精确率和召回率的“调和平均”
F1 = 2×(Precision×Recall)/(Precision+Recall),综合反映模型均衡性。
使用场景:
- 类别不平衡时,比准确率更客观;
- 需同时关注误判和漏判的业务(如客服质检)。
(4)AUC-ROC
1.先搞懂2个核心指标
前面已经介绍了召回率(查全率, TPR),TPR = TP / (TP + FN),“抓对了多少坏人”
例子:100个新冠患者中,模型检测出80个 → TPR=80%(越高越好,漏诊越少)
假正率(FPR),FPR = FP / (FP + TN),“冤枉了多少好人”
例子:100个健康人中,模型误判了10个为阳性 → FPR=10%(越低越好,误诊越少)
2.ROC曲线
横轴(FPR):冤枉好人的概率(从0%到100%)。
纵轴(TPR):抓到坏人的概率(从0%到100%)。
曲线的画法: 调整模型的判断阈值(比如新冠检测的阳性判定标准从严格到宽松),每调整一次阈值,就计算一对(FPR, TPR)坐标点,连起来就是ROC曲线(下图中蓝色的线)。
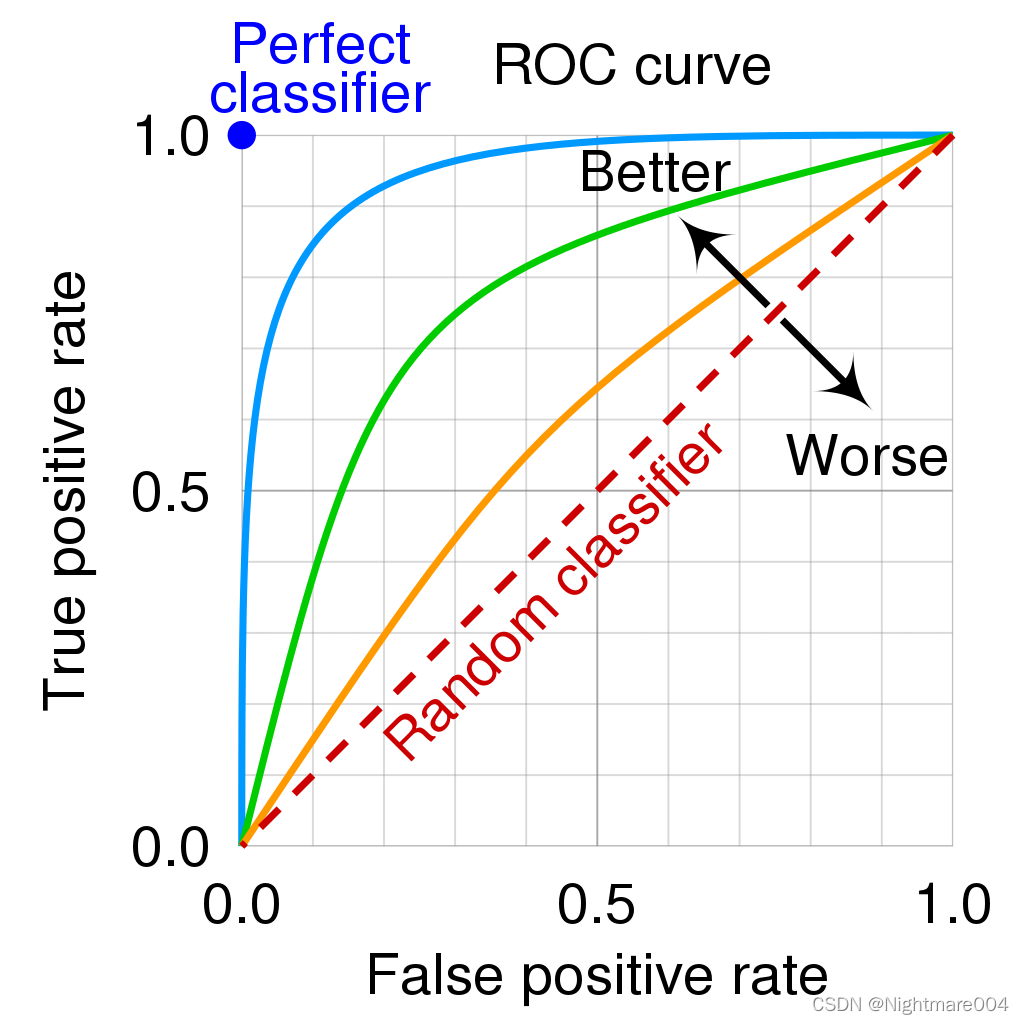
AUC值:衡量ROC曲线的”含金量”
AUC = 1(完美模型): 能100%抓到坏人,且0%冤枉好人(曲线贴左上角,像直角尺)。
AUC = 0.5(随机瞎猜): 模型和抛硬币一样不准(曲线是45°对角线)。
AUC在0.5~1之间: 值越大,说明模型在”多抓坏人”和”少冤枉好人”之间平衡得越好。
3.2 可解释性分析:LIME/SHAP工具可视化决策逻辑
可解释性 = 让AI学会“讲人话”,解释自己的决策。就是让AI解释“为什么它做出某个决定”,而不是只丢给你一个结果。LIME和SHAP就是解释的工具。
① LIME:局部解释(针对单次预测)
干什么用:解释AI对某一个具体案例的判断。 怎么工作:假设AI说“这条邮件是垃圾邮件”,LIME会告诉你:“因为邮件里有‘免费领取’和‘限时促销’这两个词,所以AI判断为垃圾邮件。”
② SHAP:全局解释+局部解释
干什么用:不仅能解释单次预测(像LIME),还能总结整个AI模型的决策规律。 怎么工作:分析AI的贷款模型,SHAP可能告诉你:
全局规律:“收入”和“信用分”是主要判断依据,“性别”几乎没用。
单次决策:“张三被拒贷,因为他的信用分比阈值低20分。”
LIME/SHAP通常是代码库,需要技术人员调用,但产品经理要懂它们的输出结果。
3.3 AB测试在AI中的特殊用法
1. 传统AB测试 vs AI时代的AB测试
传统AB测试:
- 用途:对比两个静态方案(如按钮颜色A/B)。
- 局限:只能测“固定规则”,无法应对动态变化的AI模型。
AI时代的AB测试:
用途:验证模型迭代效果、算法策略优劣、数据质量影响。
特点:
- 测的不是“静态界面”,而是“动态学习能力”;
- 不仅要看短期指标(如点击率),还要关注长期影响(如用户留存)。如可在需求文档中说明“本次推荐算法升级需同时优化点击率和7日复购率,技术方案采用多目标学习(MMoE)。”
2.AI项目中AB测试的3大特殊场景
场景1:模型版本对比(Model A/B Testing)
问题:新训练的模型比旧模型准确率高,但上线后效果可能不同(数据分布变化)。
解法:
- 将用户随机分流,50%用旧模型,50%用新模型。
- 对比关键指标(如推荐系统的点击率、风控模型的误杀率)。
案例:
电商发现新推荐模型CTR提升10%,但AB测试显示客单价下降5%——说明模型可能过度推荐低价商品。
场景2:算法策略对比(Algorithm A/B Testing)
问题:不同算法(如协同过滤 vs 深度学习)适合不同场景。
解法:
- 同一模型,不同算法策略并行测试。
- 重点关注业务指标而非技术指标(如“收入”优于“准确率”)。
案例:
外卖平台测试“距离优先”和“口碑优先”两种排序算法,发现午高峰用距离优先,晚高峰用口碑优先更优。
场景3:数据质量影响测试(Data A/B Testing)
问题:新数据源(如用户画像标签)是否真能提升模型效果?
解法:
- 对照组:旧数据训练的模型;实验组:加入新数据后的模型。
- 验证数据是否有“信息增量”。
案例:
金融风控模型加入“社交关系数据”后,AB测试显示欺诈识别率提升,但误杀率也增加——需权衡取舍。
3.AI项目AB测试的3个关键技巧
技巧1:分层抽样(Stratified Sampling)
问题:AI效果可能因用户群体差异巨大(如新老用户)。
解法:按用户分层(如地域/活跃度)随机分组,确保对比公平。
技巧2:渐进式发布(Canary Release)
问题:新模型可能有未知风险。
解法:先小流量(如1%用户)测试,监控异常后再全量。
技巧3:长期效果监控(Delayed Impact)
问题:AI的短期指标可能欺骗人(如推荐系统靠标题党提升CTR,但伤害用户体验)。
解法:增加“7日复购率”“用户停留时长”等长期指标。
04 典型模型:从原理到应用场景
在AI加速落地的时代,理解典型模型的原理和应用场景,对数字化产品经理来说已成为基础能力之一。以下我们将拆解几类典型AI模型,结合原理、场景,并重点说明如何在产品中落地。
4.1 对话类模型:Transformer 架构(以 ChatGPT 为例)
模型简介 Transformer 是由 Google 于 2017 年提出的自然语言处理架构,其核心是“注意力机制(Attention)”,可捕捉词语之间的长距离依赖关系。GPT 系列(Generative Pre-trained Transformer)即基于 Transformer 的 Decoder 架构演进而来。
应用场景
- 智能客服 / 企业内部助手
- 内容生成(写作、摘要、翻译)
- 编程助手
- 教育陪练 / 作文点评
- 知识问答机器人
产品落地方式
接入方式:使用 OpenAI API、Azure OpenAI,或国内厂商的类ChatGPT API(如通义千问、文心一言等)
落地场景设计:
- 将模型集成至对话窗口(如帮助中心、CRM系统)
- 与企业知识库结合,实现上下文问答
- 与内容库结合,做智能创作助手嵌入 IDE / 后台系统做代码建议和提示
关键评估指标:
- 回复命中率 / 准确率
- 人力节省比
- 用户满意度(CSAT)提升
产品经理思考角度
- 业务是否存在高频但重复的问答类工作?
- 是否具备结构化或非结构化的内容知识库?
- 用户是否对回答质量有高容错要求?
4.2 图像生成类模型:扩散模型(以 Stable Diffusion 为例)
模型简介 扩散模型通过逐步对随机噪声进行去噪,生成高质量图像,适用于根据文字描述生成图像。代表模型有 Stable Diffusion、Midjourney、DALL·E。
应用场景
- 电商图生成
- 广告视觉草图 / Banner
- AI头像 / 个性化图像
- 游戏原画 / 插图
产品落地方式
接入方式:使用 HuggingFace / Stability AI 提供的 API,或私有部署开源模型(如 Stable Diffusion)
落地场景设计:
- 编辑器类产品内嵌“AI生成图”按钮
- 结合运营系统,批量生成活动海报
- 提供Prompt模板给用户快速创作关键评估指标:
- 素材生成效率提升
- 设计人力节省率
- 图像生成质量反馈分数
产品经理思考角度
- 用户是否有大量视觉素材创作需求?
- 是否需要 AI 图像与品牌风格保持一致?
- 是否要在用户端控制生成成本(如限制次数)?
4.3 推荐类模型:深度推荐(DeepFM / DIN / 多模态推荐)
模型简介 推荐系统模型基于深度神经网络(DNN)对用户、物品及上下文做特征嵌入,再用交叉模块(如 FM)和序列建模(如 Attention)捕捉兴趣变化,生成推荐结果。
应用场景
- 短视频 / 内容流推荐(抖音、小红书)
- 电商商品推荐(淘宝、京东)
- 资讯 / 新闻推荐
- 广告精准投放
产品落地方式
接入方式:大公司自建推荐引擎;中小型产品可用阿里PAI、腾讯云推荐平台等
落地场景设计:
- App首页内容流由推荐系统动态生成
- 用户行为触发实时兴趣建模(点击、收藏、停留)
- 联动标签系统或知识图谱强化推荐粒度
关键评估指标:
- CTR / CVR
- 用户停留时长
- 推荐召回率 / 精准率
产品经理思考角度
- 用户行为数据是否足够支撑训练?
- 内容/商品池是否足够丰富?
- 是否具备冷启动解决策略(如规则+AI混合)?
4.4 多模态模型:CLIP / GPT-4V / Gemini
模型简介 多模态模型能同时理解图像和文本(甚至语音、视频),如 OpenAI 的 CLIP 能将图像和文字映射到统一语义空间,实现“看图说话”、“图文检索”等。
应用场景
- 图文搜索 / 图文问答(文档问答)
- 视频摘要 / 图像理解
- 商品图智能分类与打标
产品落地方式
接入方式:调用 OpenAI GPT-4V、Gemini、或开源如 BLIP、MiniGPT 等
落地场景设计:
- 在搜索引擎中加入“图搜文”、“文搜图”能力
- 实现图像知识问答机器人(例如问产品图)
- 用于文档解析、发票识别、PPT内容理解等
关键评估指标:
- 图文匹配准确率
- 检索速度 / 召回率
- AI识别后的提效率
产品经理思考角度
- 是否存在“图+文”的复杂内容理解任务?
- 当前内容是否难以结构化?
- AI多模态是否能带来搜索/理解效率的提升?
4.5 语音类模型:Whisper / TTS / 语音识别
模型简介 Whisper 是 OpenAI 推出的通用语音识别模型,支持多语种、多口音识别。TTS(Text to Speech)模型则用于将文本转为语音。
应用场景
- 客服语音转写 / 质检
- 智能语音助手(如小爱同学)
- 无障碍阅读 / 播客生成
- 视频字幕自动生成
产品落地方式
接入方式:调用 Whisper API、讯飞开放平台、阿里云语音服务等
落地场景设计:
- 语音转文字后结构化为知识点、标签
- 视频自动加字幕、翻译
- 用户语音输入场景接入识别能力
关键评估指标:
- 转写准确率 / 延迟时间
- 语音合成自然度评分
- 用户体验评分(Voice UX)
产品经理思考角度
- 是否有大量语音内容需要转写/处理?
- 是否存在用户语音交互需求?
- TTS是否能与品牌声音匹配?
写在最后
AI 已不仅仅是算法工程师的专属武器,而正成为每一位产品经理的“第二大脑”。无论是用对话模型优化客服体验,还是用图像生成提升运营效率,抑或是构建多模态理解、自动执行任务的智能 Agent——我们正处于一个“技术从幕后走向产品前台”的转折点。
与其担心被 AI 取代,不如积极思考:你的产品,如何因为 AI 而变得更聪明、更高效、更具竞争力?
希望这份“模型原理与落地指南”能成为你与 AI 合作的起点,也欢迎你在评论区分享你的产品实践与灵感,一起推动“AI + 产品”的落地进程。
本文由 @Jessie 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。