图形AI粗读丨预训练特征与模型微调

前言
在上一篇中,我们读到了正则化相关的技术,以及它对提升训练效率和避免过拟合方面起到的作用。
这次的课件中,我们会继续深入机器学习中偏落地实现方面的内容。这部分的时间节点大约是距现在10年前,之前介绍到了以图像识别为主的AI技术逐步进入了商业化阶段,因此各种提升性价比和提升模型性能的考虑也被不断提出和实践;另外,如何以较低成本迁移已有的模型训练成果也是实际操作中的考虑方向。
本文还是以翻译PPT页内容为主,打星号的部分则是我的补充说明。
1 表征学习——Representation learning
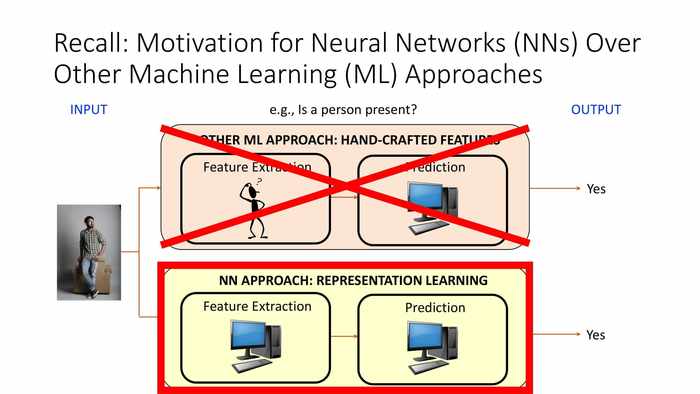 (回顾:在其它机器学习的基础上提出神经网络方式的动机)
(回顾:在其它机器学习的基础上提出神经网络方式的动机)
*之前某一篇中也介绍过,用NN提取特征时,人们只用设计少量超参数;如果是手动提取特征,则需要设计全部模型参数。
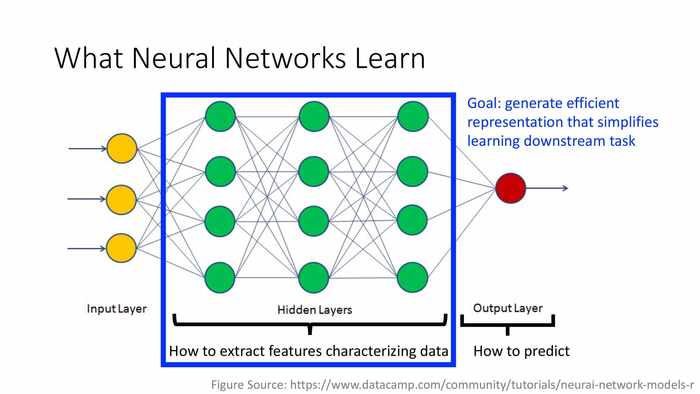 (神经网络学习的内容)
(神经网络学习的内容)
(蓝字):高效地生成表征数据,自上而下地简化学习任务。
隐藏层——学习如何提取特征数据;输出层——学习如何预测。
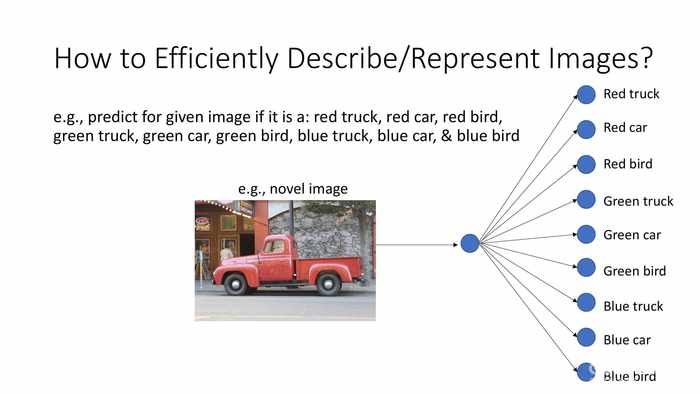 (如何高效地描述、表征图像?)
(如何高效地描述、表征图像?)
*以图中的汽车预测为例,需要预测颜色和车的种类。图中的全展开式参数也是一种方式,虽然明显不太成熟。
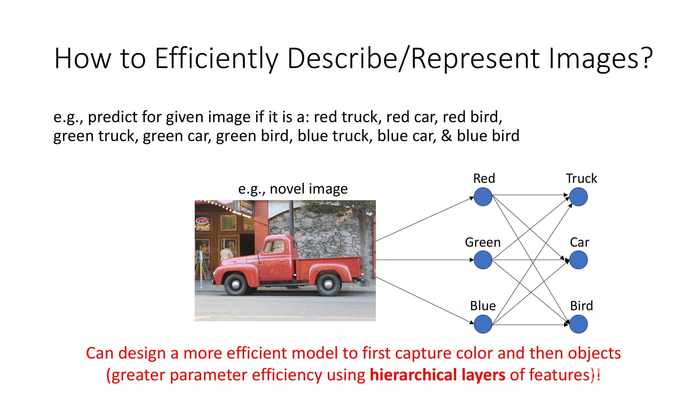
(红字)设计一个模型,先提取颜色、之后提取物体种类(使用多层提取特征的方式获得了更高的参数效率)。
 (诠释表征的一些核心技巧)
(诠释表征的一些核心技巧)
- 视觉过滤器和结果激活图层。
- 基于相似特征检索相似的图像。
- 通过有着最大值激活单元的神经网络来分析图像。

视觉过滤器和结果激活图层。
 (观察VGG16模型是如何学习的)
(观察VGG16模型是如何学习的)
*VGG16模型在上上篇中介绍ImageNet时介绍过。紫色框中间是3X3但个数逐步收敛的卷积核。
 (VGG16:3个卷积层中的过滤器)
(VGG16:3个卷积层中的过滤器)
(蓝字)过滤器从探测简单的特征(例如边缘、颜色)逐步演变至复杂的结构。
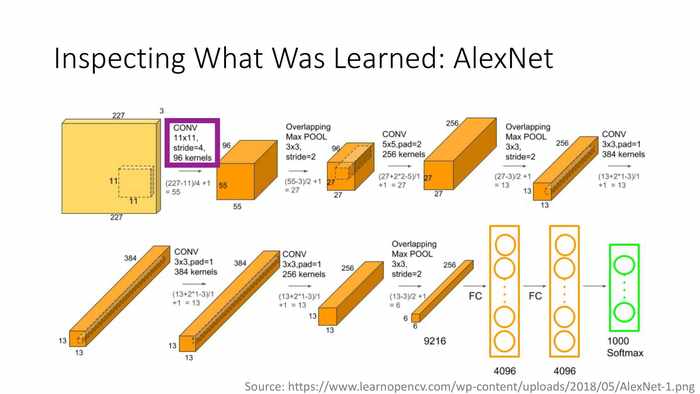 (观察AlexNet是如何学习的)
(观察AlexNet是如何学习的)
紫色框是11X11,步长为4的96个卷积核。
 (AlexNet:卷积层1中的96个过滤器)
(AlexNet:卷积层1中的96个过滤器)
(蓝字)过滤器探测不同的频率、朝向和颜色。
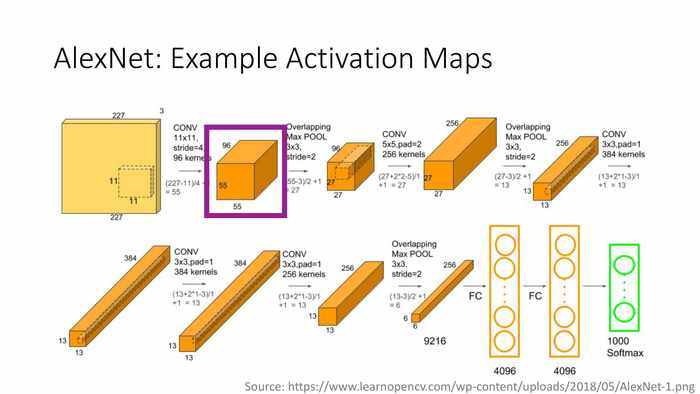 (AlexNet:范例激活图层)
(AlexNet:范例激活图层)
 (AlexNet:范例激活图层(回顾:每一个图层对应一个过滤器的结果))
(AlexNet:范例激活图层(回顾:每一个图层对应一个过滤器的结果))
*图中的例子,左侧彩色的是不同的图像,其右侧都是不同的特征提取(过滤器执行)的结果。
 (AlextNet:卷积层2中的256个过滤器)
(AlextNet:卷积层2中的256个过滤器)
(蓝字)如何在模型中诠释这些过滤器也是一项挑战。
 (AlexNet:采样的激活图层)
(AlexNet:采样的激活图层)
(蓝字)你能从图中推测每个过滤器各自提取的是什么特征么?
*能看出的有比如:轮廓、边缘、亮度等。

基于相似特征检索相似的图像。
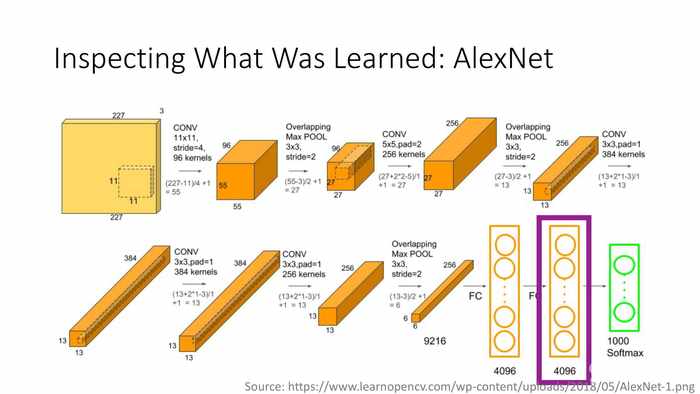
*图中紫框是AlexNet的4096个节点的全连通层部分。
 (AlexNet:以相似的FC7向量检索图像)
(AlexNet:以相似的FC7向量检索图像)
(黑子)最左侧一列是测试图像,右边是相比测试图像的FC7特征激活有着最小欧氏距离的训练图像。
(蓝字)从中你能推测出怎样的FC7特征表征?——与光照和物态无关的图像语义。
*FC7是全连接层,因其输出都是向量数据,因此可以计算与目标值的欧式距离。

通过有着最大值激活单元的神经网络来分析图像。
 (AlexNet:图像经过最大值激活函数,得到单输出的结果)
(AlexNet:图像经过最大值激活函数,得到单输出的结果)
意味这100张图像中的哪些(例如,有着更高的激活分数)。
*紫框部分是一个多层重叠的MaxPool。关于最大值池在之前介绍池层时提到过。
 (总结:诠释表征的一些核心技巧)
(总结:诠释表征的一些核心技巧)
除了之前提到的3点,还有更多新的技术没有在课件中覆盖到。
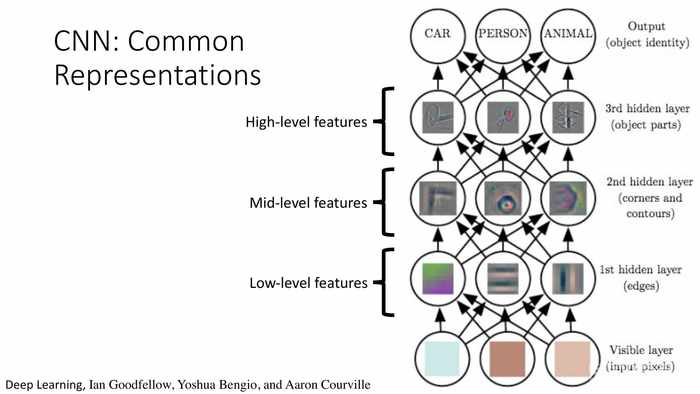 (CNN:通用表征)
(CNN:通用表征)
*这里是指通过不同训练目标的共同特征的提取,来实现跨模态信息融合的一种方案。可以看到自下而上,特征级别逐步提高;不同的物体识别共有了一部分特征提取节点。
 (研究CNN的一些在线工具)
(研究CNN的一些在线工具)
2 预训练特征——Pretrained features
*这部分可以理解成预先集成进模型的一些卷积过滤器或激活函数过滤器。
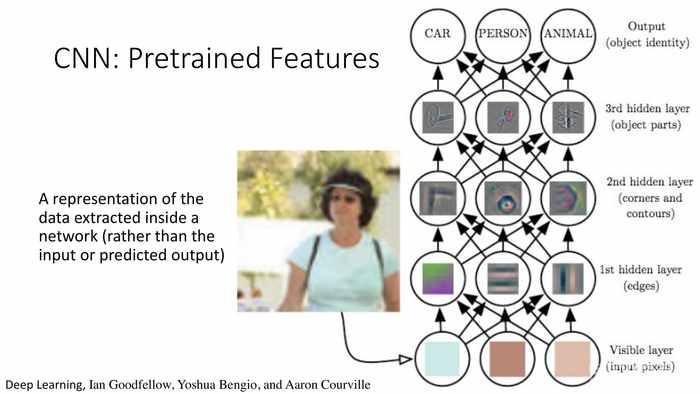 (CNN:预训练的特征)
(CNN:预训练的特征)
(预训练特征是)神经网路内已提取的数据表征,而不是来自输入或输出预测。
 (将AlextNet中预训练的CNN特征提取与不同的数据集比较)
(将AlextNet中预训练的CNN特征提取与不同的数据集比较)
数据集1:ImageNet(1.5M的物体图片,摘录自搜索引擎)
数据集2:Places(2.5M的场景图片,摘录自搜索引擎)

*下面关注紫框中的卷积层——过滤器的情况。这部分会进行一轮特征提取。
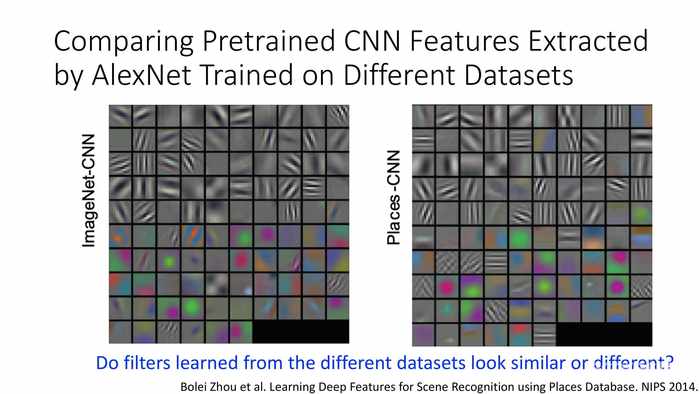
(蓝字)不同数据集的过滤器看起来相似还是不同?

*下面关注紫色框的MaxPool,这里会进行一轮最大值激活运算。

(蓝字)不同数据集中的过滤器是倾向于学习探测相似还是不同的特征?
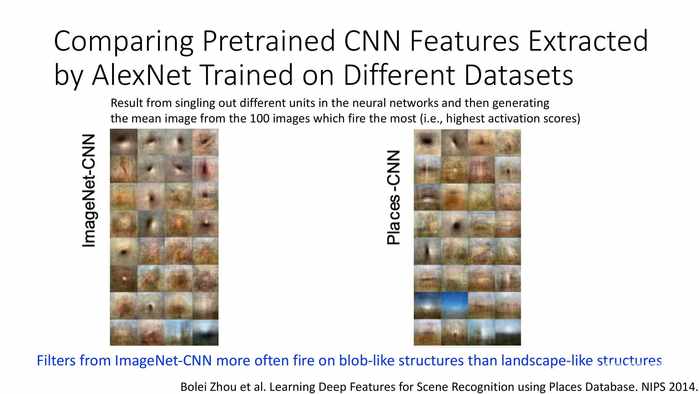
(蓝字)ImageNet-CNN中的过滤器更倾向于探测斑状结构而不是地形类结构。

*下面关注紫框中的MaxPool。

(蓝字)ImageNet-CNN中的过滤器更多被斑状结构激活——相较于地形类结构。

*最后关注全连通层FC7的激活情况。

(蓝字)ImageNet-CNN中的过滤器更多被斑状结构激活——相较于地形类结构。
 (总结)
(总结)
特征的表征方式受很多因素决定,包括:
- 用于解析特征的层
- 用于训练模型的数据类型
3 模型微调——Fine-tuning
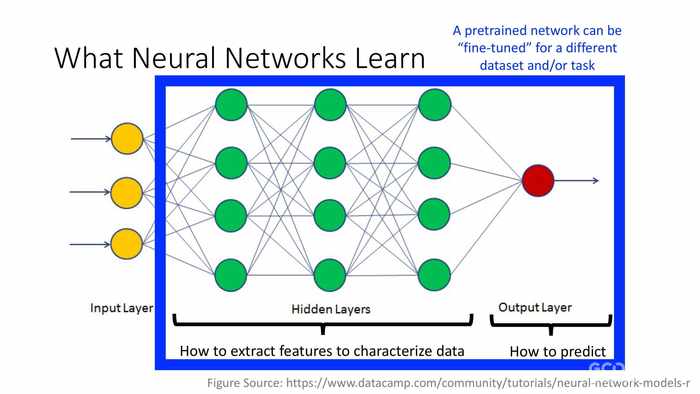
(蓝字)一个预训练的神经网络可以被“微调”以用于不同的数据集或目标任务。
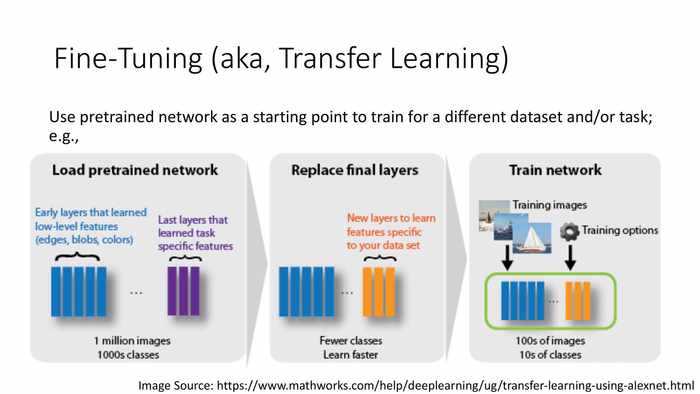 (调优——也被称为转化学习)
(调优——也被称为转化学习)
使用预训练的神经网络作为不同数据集或目标任务的训练起点,例如:
- 加载预训练的神经网络——(蓝字)早期层学习低级别的特征(边缘、斑点、颜色等);(紫色)后期层学习任务特化的特征。
- 替换最终层——(橙色字)将后期层替换成新的层,用于学习新的数据集特化的特征。
- 训练网络——使用新的数据集作为训练图像,新的最后层作为训练选项。
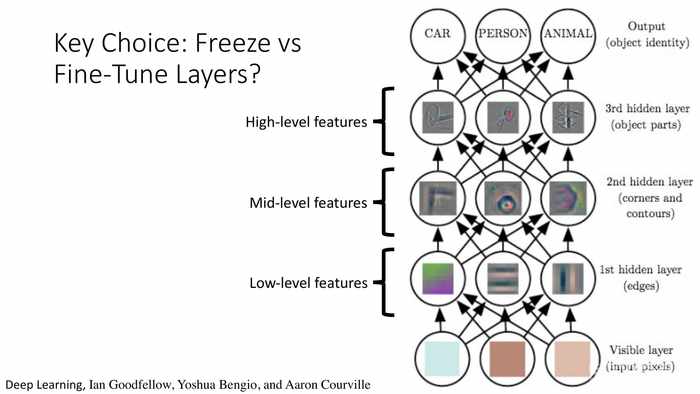 (核心选择:冻结还是微调对应的层?)
(核心选择:冻结还是微调对应的层?)
*这里冻结就是指保留原模型中的层,微调就是替换成新的待学习的层。
 (分组讨论)
(分组讨论)
假设你需要开发识别低收入家庭中常用物体的分类模型:
- 如果你需要微调基于ImageNet预训练的AlexNet,会移除或冻结哪些层,为什么?
- 如果现有一个对应低收入家庭物品的大规模数据集,你会从零开始(from scratch)训练AlexNet或针对ImageNet预训练的模型进行微调?为什么? *问题1参照前面的介绍,应该会替换最的FC6和FC7层,基于数据量不算丰富的情况进行少量样本训练,生成新的一套权重;对于问题2的假设,要达成更好模型预测结果,是需要从零开始训练的——相对于ImageNet数据来源地的情况(如图)。
*文末会附一篇网络上关于Fine Tuning的介绍。
4 训练神经网络:软件与硬件——Training neural networks: hardware & software
 (回顾:神经网络成功的核心要素)
(回顾:神经网络成功的核心要素)
*文中的关键字:算法、数据、处理器。

关键问题:到达目标(实现上句中的目标,进行数据预测)需要多长时间?
 (挑战:训练神经网络需要大量运算(例如百万级的参数))
(挑战:训练神经网络需要大量运算(例如百万级的参数))
*这个图表之前的篇中也反复提到过了,简单再提一下就是前向输入数据——基于当前参数权重得出结果——将预测结果和目标值比较,计算变化梯度并反向调整参数。
 (理念:更好的硬件)
(理念:更好的硬件)
理念:使用GPU而不是CPU进行算法训练。
*“得益于”英伟达的市场推广,在10年前还要放在课件里提一嘴的事,现在应该已经是大众常识了。
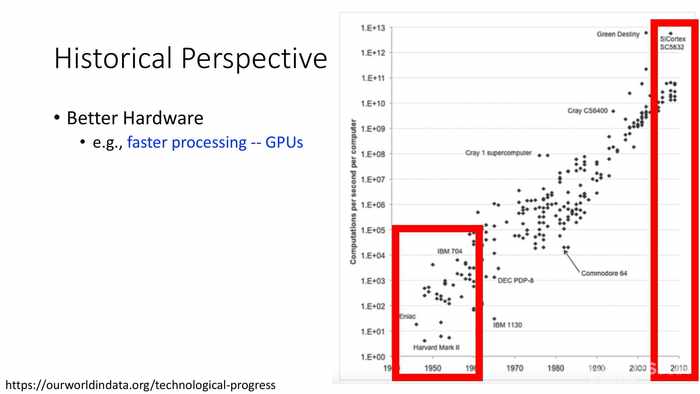 (历史回顾)
(历史回顾)
更好的硬件——例如更好的处理器:GPU。(*图中是几十年间处理器算力的差距)

例如,更多的存储空间。
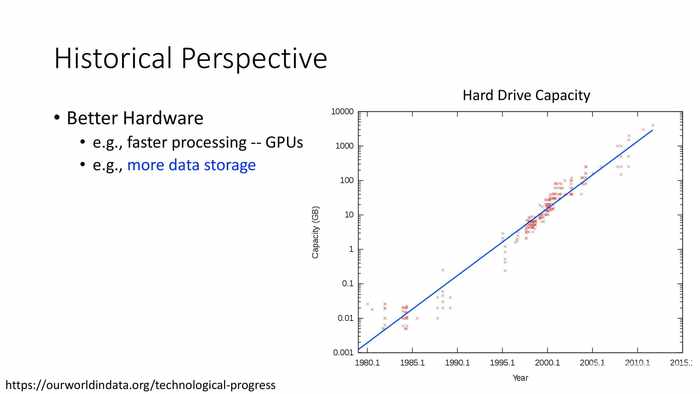
*图中是近几十年硬盘容量的变化。
 (硬件:CPU对比GPU)
(硬件:CPU对比GPU)
图形处理单元(GPU):能加速运算载荷,因为有着更多的处理核心。
*CPU单元少是因为设计出来是要处理复杂逻辑和计算,而神经网络中需要的计算GPU都能搞定。

如果不注意,读取数据输入到GPU可能会称为训练的瓶颈。解决方案:
- 将所有数据读入内存
- 使用SSD存储设备
- 使用多CPU线程来预载数据
 (GPU设备:租还是买?)
(GPU设备:租还是买?)
*这篇大概反映了美国10年前的设备价格,可以参考一下相应的AI训练成本。
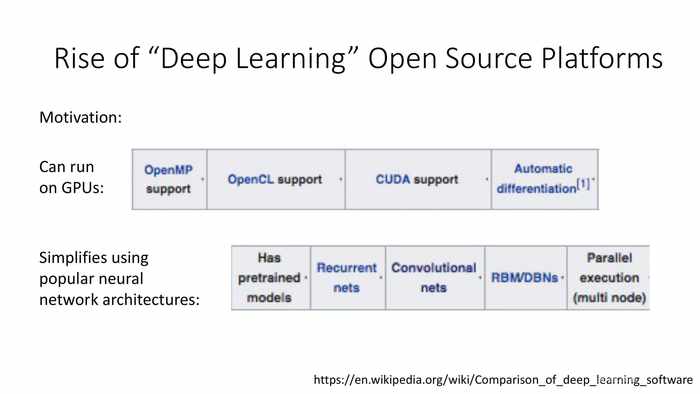 (“深度学习”开源平台的兴起)
(“深度学习”开源平台的兴起)
动机:
可以在GPU上执行:OpenMP支持、OpenCL支持、CUDA支持、自动微分。
使用流行的神经网络架构来简化训练:有预训练的模型、回归型网络、卷积网络、RBM和DBN、并行执行(多节点)。
*RBM是限制性波尔兹曼机的缩写,DBN是深度信念网络的缩写。文末会附一篇介绍。

*图中可以看到一些开源深度学习训练的平台,有些到现在还是AI模型训练的常客。
 (Microsoft Azure支持的平台)
(Microsoft Azure支持的平台)
*Microsoft Azure是微软的一个云计算系统服务平台,而其中列出名字的一些平台很多还是AI模型训练甚至入门级学习的常客。
结语
这一篇的内容,在课件中并没有对各个方面进行很深入的讲解,更像一篇提纲。
我个人对此的理解是:具体的实践智慧,在10年前和目前肯定也有了非常大的变化,近些年全球高校和头部科技公司涌现出的论文汗牛充栋,很大一个方面就是模型训练的算法优化和效率提升;另一方面,这篇课件确实引出了例如TensorFlow、PyTorch等目前比较成熟的开放训练技术平台,在10年后的现在,对于志业在AI大模型方向的人来说,在TensorFlow上训练一个基于ImageNet的模型就已经是偏“入门级”的操作内容了。
下篇会进入有更多算法细节的部分,会读到物体探测和语义分析。
下面是资料链接:
NeuralNetworksAndDeepLearning-Spring2022/Lectures/09-PretrainedFeaturesAndFineTuning.pdf