一文读懂MCP及三大传输协议

现如今,人工智能(AI)和大语言模型(LLM)越来越聪明,甚至接近了人类的智慧水平。但如果它们只能利用自身已有的数据,无法获取外界实时信息或者调用外部工具(在线词典、天气、地图等),那么它们的能力就会被大大的限制。比如用户问,今天哪家公司股票涨幅最大?由于缺少实时数据和工具支持,再强大的AI也无法给出满意的答案。
在没有MCP之前智能体都是如何做的呢?
这里引入两个概念:
大模型
大模型(Large Language Model,LLM)是一种基于深度学习技术的人工智能模型,具有庞大的参数量和强大的学习能力,能够理解、生成自然语言文本,并执行多种复杂任务。
大模型在MCP协议出现之前已经经历了两个阶段:
第一个阶段:基于训练数据相对封闭阶段
最初大模型(GPT、Claude等)本质上是基于海量数据训练的下一个词的预测器(Next token prediction)。用户输入一个问题,大模型通过一个词一个词最大概率出现的方式去给到用户输出。他们是基于概率的预测,也意味着大模型并不是真的理解用户的意思,而是基于概率预测。因此会经常会出现一些幻觉(一本正经的胡说八道)。这个时期的大模型是孤立存在的,没有接收任何的外部信息。
第二阶段:LLM**+context 上下文输入给大模型阶段**
比如现在的deepseek、豆包、GPT、Kimi等,他们都有一个选项叫做联网搜索,这个就是网络的上下文。
- 短期记忆:模型的上下文对话记录
- 长期记忆:像RAG知识库。这些都是在给模型提供有力的上下文支撑。
现在以人造机器人举例,这个机器人姑且叫它张三。大模型就相当于张三的大脑,具备智力,可以和我们进行对话。
智能体
张三具备人类的大脑,可惜只能跟我们聊天,手脚发育还不完全,别的事情做不了。为了让张三具备更多的能力,经过学习研究,大家终于为张三安上了假肢(FunctionCall)。张三可以借助假肢来使用一些简单的工具。
Function calling 没有统一的标准,每家大厂的API定义都不一样。调用工具时,每个工具都要单独的适配,每个链接都需要去定制代码、去写特定性的服务、去处理权限、去管理格式、来保证足够的兼容性。最后就会导致这整个系统非常的复杂。极难去维护、极难去规模化。
就像由于假肢是后面才做的,张三的大脑还不知道如何使用,因此,大家为张三量身打造了一些工具(函数、插件),可以理解为“笔”、“菜刀”,并且把工具的使用方法写成详细的说明书(提示词)存储到假肢的芯片中。
并且告诉张三,以后我让你干活的时候,你可以先读取一下假肢里的说明书,看看都需要调用哪些工具。
比如,让我们告诉张三:请帮我们切个菜,他首先会拿出使用说明书看一下,找找他现在已有的工具中可以使用来做这件事的工具。
像这样,拥有了工具使用能力的机器人(大模型)我们就称它为智能体了。所以说智能体最核心的特点,就是具备工具调用的能力。
后来,大家做出了更多的大模型,比如又来了个李四(豆包)、王五(DeepSeek)……为了更加高效的组织和管理这些人呢,有人就创建了公司A(Coze、Dify等),将张三、李四、王五都招了进来,并且专门制定了一套公司的工具使用制度(各自匹配的Function call),还专门给张三、李四、王五配上了许多干活的工具(插件)。
这样,这家公司A就就开始给大家提供各种各样的服务,给大家干各种各样的任务了。
可是有一天,有人建立了公司B,想把张三、李四和王五等人挖进来,但是公司A的制度和工具肯定不会给B对吧?于是为了让张三、李四和王五工作,公司B也只能重新研发工具使用制度和配备相关的工具(插件)。
那么现在问题来了,明明是同样的工具,公司A和公司B没法通用。
更夸张的是,有个人之前都是在公司A雇佣张三干活,还专门给他做了工具,但是现在这个人觉得公司A的费用太贵了,想找公司B,但是之前工具都在放在公司A那里根本拿不过来,更别说迁移使用了,只能重新再做。
后来这个人想,干脆不找公司A或者公司B了,我单独雇佣张三来帮我干活(自己部署大模型研发智能体),自己还是要专门给他配个工具。
就这样,重复做了好多事,浪费了很多资源。
如何让他们安全、高效地与外部资源和工具进行交互,就成了一个亟待解决的核心问题。
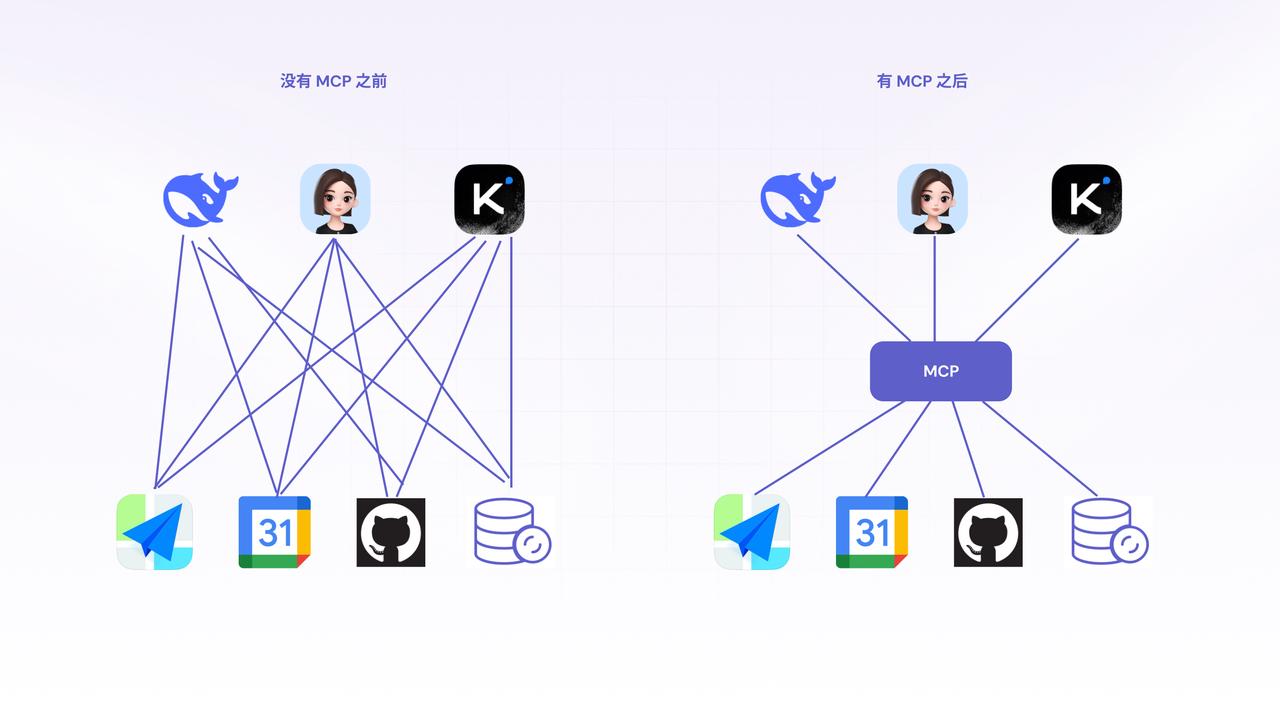
一、MCP应运而生
因为前面遇到的问题,于是终于有人Claude母公司(Anthropic公司)制定了一个标准– MCP
MCP(全称是Model Context Protocol, 即模型上下文协议)
从它的名称上我们就可以看出,MCP不是一个产品、不是一个应用,也不是一个API SDK,而是一个协议。它的目标是希望任何一个AI的模型(Chatgpt、Claude、deepseek等)都能够以一个统一的方式去访问资源和工具。
任何你希望模型能知道、能用、能调用的内容主要分为两块
- 资源(resources):数据库、API、第三方的saas等
- 工具(tools):天气、地图、在线词典、日历、邮件、执行命令、远程控制等等; 这些资源和工具是让模型变得真的能干活的关键。
二、MCP是如何工作的呢?
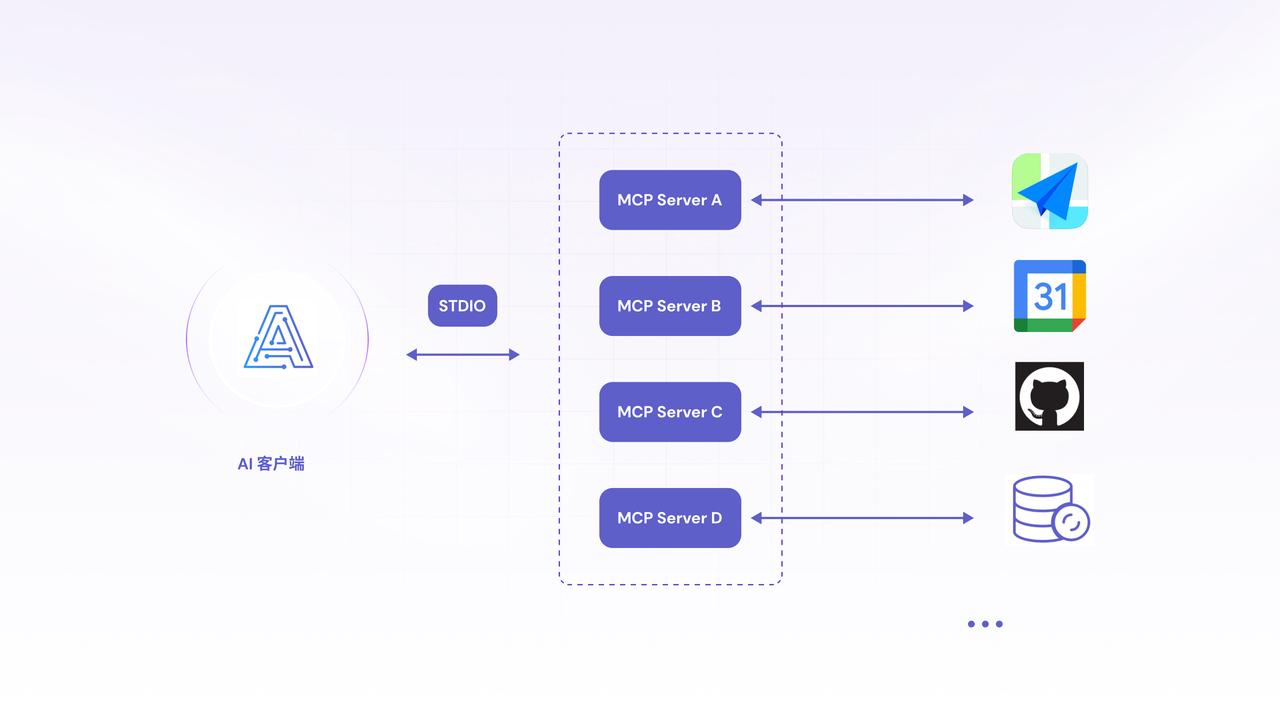
- AI 客户端:就像你手机里的 ChatGPT / 豆包 App,是和 AI 聊天、发指令的 “入口”,就是把一些含糊不清的自然语言转化成一个明确的意图。比如用户要发一封邮件,我要看日历。这种明确的意图。
- STDIO:理解成 “信息快递站”,负责把 AI 说的话、要干的事儿,打包发给后面的 “服务器”
- MCP Server:用户意图就会这些请求就会发给MCP server(能力适配器)。MCP server 就负责和外部的系统通信,比如邮箱、日历、地图等等。并且会声明出它提供的工具或者资源。把它们当 “AI 管家团队”,A 管家对接高德地图、B 管家对接日历、C管家对接Github, 分工帮 AI 跑腿干活。
比如用户要发一封邮件,我要看日历,这些请求就会发给MCP server(能力适配器),MCP server 就负责和外部的系统通信,比如邮箱、日历、地图等等。并且会声明出它提供工具或者资源。
比如 Gmail的MCP server 它可以去发邮件、接收邮件,写邮件。
一个Calendar server,可以去设置日历、创建日历提醒等
一个Github Server 可能会执行代码的审查、代码编写等。
这些Server都实现了一个统一的协议,支持通过http、Json、或者通过本地输入输出的方式去跟MCP的Client进行通信。
再举一个更加实际的例子:
比如我发出请求说,帮我约小七老师这周日一起去健身,并发一个邮件给她提醒。
仔细拆解这个请求,其实包含着两个任务,第一个任务是去找到我和小七老师周日都有空闲的时间段。第二个任务是去创建一个日程提醒并发送邮件给小七老师。
那么AI应用作为一个MCP的Client,会先向系统中已经注册的MCP server去查询它的能力列表。比如是不是可以访问日历,是不是有权限去发邮件,是不是能获取到小七老师的联系人信息?
这些能力的声明和用户的请求一并去交给大语言模型去处理。
模型基于给定的上下文,去判断我应该怎么整合现有的工具去完成任务。
比如决策后发现:
第一步:我先从Calendar server里面去找我和小七老师都空闲的时间段
第二步:决定最终的健身时间
第三步:调用Email server去发邮件
第四步:可能还会提问用户,是不是还要叫上其他好友? 整个流程非常的清晰标准化、逻辑也是闭环的,关键是你不需要为每个流程去写死一个逻辑,模型也不需要提前训练才知道每个API
只要MCP server有这个能力的声明,模型就能够动态的发现、调用、并且执行。
三、MCP常用的几种传输机制有哪些呢?
MCP 提供了几种不同的“沟通方式”(传输机制),最受关注的是以下三种:Stdio、SSE、Streamable HTTP,他们就像不同的交通工具,各有优缺点,适用于不同的“路况”(应用场景)。理解他们的差异,正是为 AI 应用挑选最佳交互方式、充分释放其潜力的关键所在。下面我们来详细了解这三种协议及其优缺点。
1. Stdio 协议
1)通信原理
Stdio(Standard Input/Output,标准输入 / 输出)协议,是基于操作系统提供的标准输入输出机制实现的一种数据传输方式。在很多编程环境和系统交互中,Stdio 作为基础的数据交互通道,承担着数据输入与输出的基础功能。
例如在常见的命令行程序中,用户通过标准输入向程序传递指令和数据,程序则通过标准输出返回处理结果。
2)核心优势
- 通用性和易用性:几乎所有的操作系统和编程语言都原生支持标准输入输出,开发者无需额外配置复杂的网络环境或引入特定的库文件,就能快速实现数据的传输与交互,大大降低了开发门槛;
- **低延迟****效率高:**进程间通过标准输入输出进行数据交换,直接通过内存或者内部管道传输,能够实现快速、高效的协作;
- 高安全性:数据只在你的电脑内部传输,不会流到外面去,隐私安全方面有保障。
3)局限性
- 传输效率相对较低,在处理大量数据时,频繁的输入输出操作容易成为性能瓶颈。无法同时处理多个请求,不适合大规模应用;
- 限定于本地只能在同一台电脑上使用,无法满足远程数据交互的需求(访问不了其他电脑或者云端资源)
4)适用场景
本地小工具集成、处理个人隐私数据、快速做功能Demo看效果等。
2. SSE 协议
1)通信原理
SSE(Server-Sent Events,服务器发送事件)协议是一种基于 HTTP 协议的单向数据传输协议,由服务器主动向客户端推送数据。
在 Web 应用中,SSE 常用于实现实时数据更新功能,如股票行情的实时展示、新闻动态的即时推送等。服务器端可以随时将新的数据变化推送给客户端,而不需要客户端频繁地向服务器发起请求,有效降低了客户端与服务器之间的交互压力。
2)核心优势
- 实时性: 实现了服务器端的主动推送,能够快速将最新数据传递给客户端,极大地提升了数据的实时性,为用户带来更加流畅的实时交互体验;
- **稳定性好:**SSE 基于 HTTP 协议,在网络兼容性方面表现良好,能够轻松穿越各种网络代理和防火墙,保证数据传输的稳定性;
- **支持远程访问:**可以连接不在同一台电脑上的服务器,适合分布式系统;
- 实现简单,开发成本较低,对于只需要服务器向客户端单向推送数据的场景,是一种高效的解决方案。
3)局限性
- 单向传输协议,客户端无法主动向服务器发送数据,这限制了其在双向交互场景中的应用。
- **服务器压力大:**需要一直建立连接,如果有多个客户端,服务器负担过重;
- **兼容问题:**对浏览器的兼容性存在一定差异,在一些老旧浏览器中可能无法正常使用;
- 即将“淘汰”:官方觉得有更好的替换方案,准备用下面要讲的第三种 Streamable HTTP来代替。
4)适用场景
适用于需要服务器实时推送通知到客户端的远程服务器。
3. Streamable HTTP 协议
1)通信原理
Streamable HTTP 协议是一种基于 HTTP 协议的流式传输协议,它允许数据以流的形式在客户端和服务器之间传输,而不需要一次性将所有数据加载完成。在视频流播放、音频在线收听等场景中,Streamable HTTP 协议发挥着核心作用。用户无需等待整个媒体文件下载完成,就可以开始播放内容,大大提高了用户体验。
2)核心优势
- **流式传输灵活性高:**能够显著提升数据传输的效率和用户体验,对于大文件或持续产生的数据,采用流式传输可以避免因等待数据全部传输完成而造成的长时间延迟,实现数据的边传输边处理。
- 稳定性好,基于广泛使用的 HTTP 协议,具备良好的网络适应性和跨平台性,无论是在 Web 应用还是移动应用中,都能稳定运行。
- 兼容性****好:能很好地配合API网关、CDN(内容分发网络)、负载均衡器等现代网络设施一起工作。
3)局限性
- 网络环境的依赖性较高:在网络不稳定的情况下,可能会出现卡顿、缓冲等问题,影响数据的连续性和流畅性。
- **稍复杂:**由于数据是按流传输,在数据完整性校验和错误恢复方面相对复杂,一旦出现数据丢失或错误,修复难度较大,可能需要开发者自己多做一些努力。
4)适用场景
Streamable HTTP 协议凭借其灵活高效的数据传输特性,成为云函数(比如 AWS Lambda)、需要根据负载自动伸缩的分布式****系统以及无状态服务架构等场景中远程通信的理想选择。
4. 对比总结
选择建议
- **只在自己电脑上使用?**建议用Stdio,简单直接;
- **需要连接远程服务器?**直接用Streamable HTTP,拥抱未来,避免以后还要改代码,维护起来更麻烦。
5. 推荐几个MCP市场给大家
https://bailian.console.aliyun.com/?tab=mcp#/mcp-market
https://tcb.cloud.tencent.com/mcp-server
总结
最后,咱们来总结一下,MCP 从根本上重构了AI的整个应用架构。真正把AI从Chatbox阶段推进到了AI Agent阶段。它不仅仅是一个方便的工具接入接口,他是一个全新的协议标准,正在重构AI和世界的交互方式。它让我们真的做到了 从人使用AI生成文字、图片、视频到 AI自主使工具和资源的新范式。
本文由 @梧桐AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务