MiniCPM 4.0 技术报告:端侧速度的奔涌,是模型的自我Rag
MiniCPM 4.0的发布,标志着端侧模型在速度、性能和长文本处理能力上的巨大飞跃。通过原生稀疏技术,MiniCPM 4.0不仅大幅提升了模型的推理速度,还在保持高性能的同时,显著降低了显存占用和计算成本。
MiniCPM 4.0 发布了依然是端侧模型:原生稀疏,带来更强的端侧模型
https://github.com/OpenBMB/MiniCPM
作为开源产品,附带了翔实的技术报告,共 43 页
https://github.com/OpenBMB/MiniCPM/blob/main/report/MiniCPM_4_Technical_Report.pdf
下面,我带大家快速量子速读 一下
技术亮点
他们搞了套原生稀疏,让模型本身就有了一些rag 的特性,打破很多端侧的限制,更快、更强
不得不说,正如刻板印象:面壁搞端侧,是专业的
无论是 0.5b 还是 8b 这个端侧领域,MiniCPM 几乎是都是最快、成本最低的
速度
以 Jetson AGX Orin 和 RTX 4090 两款典型端侧芯片为例,MiniCPM4 的速度,大幅领先同类模型
显存极限场景下,推理速度最多快 220 倍
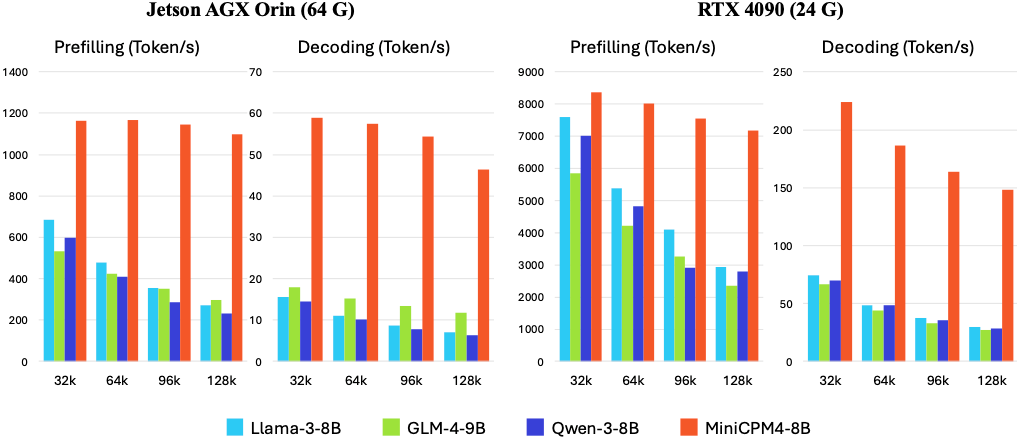
如图表所示
性能
以最适合放在移动设备里的 MiniCPM-0.5B 为例,尽管其训练数据只有 Qwen3-0.6B 的 3%,但各类评分却大幅超越:
- MMLU:55.55(Qwen 是 42.95)
- CEval:66.11(Qwen 是 45.53)
- HumanEval:46.34(Qwen 是 40.85)
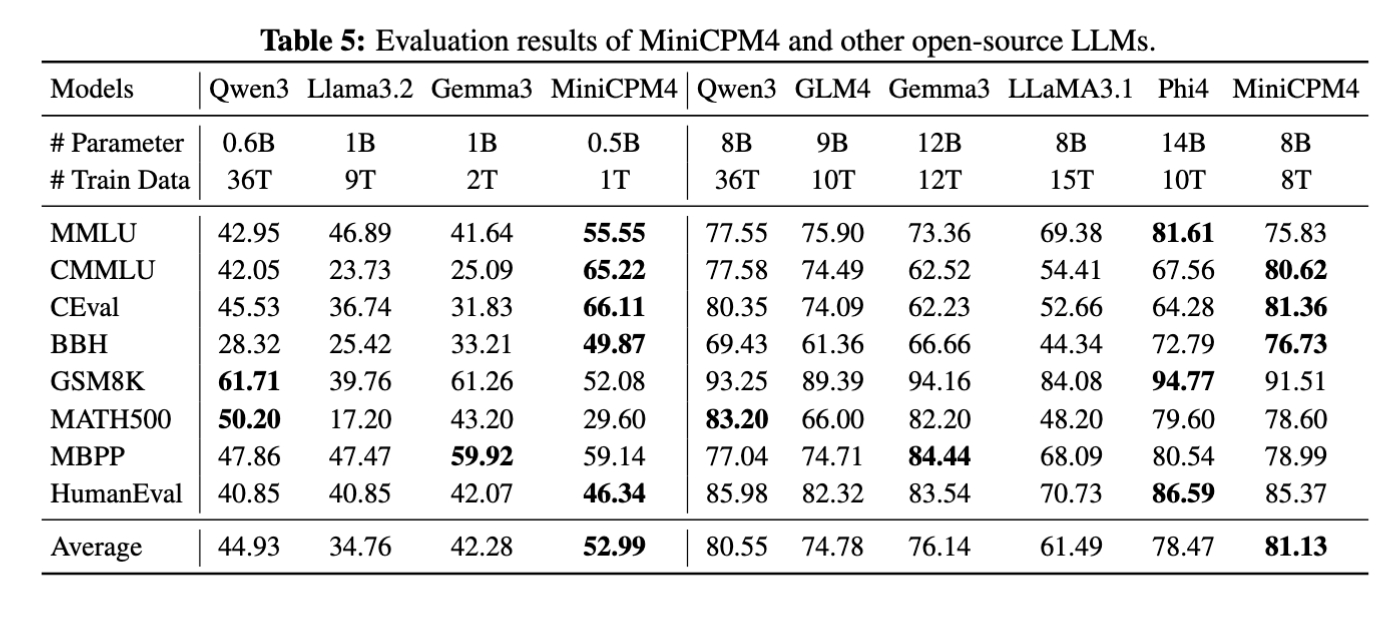
两款模型,在同体量模型中,均非常耐打
长文本
MiniCPM4 基于 32K 长文本进行预训练,并通过 YaRN 技术实现长度扩展,能够支持 128K 长文本
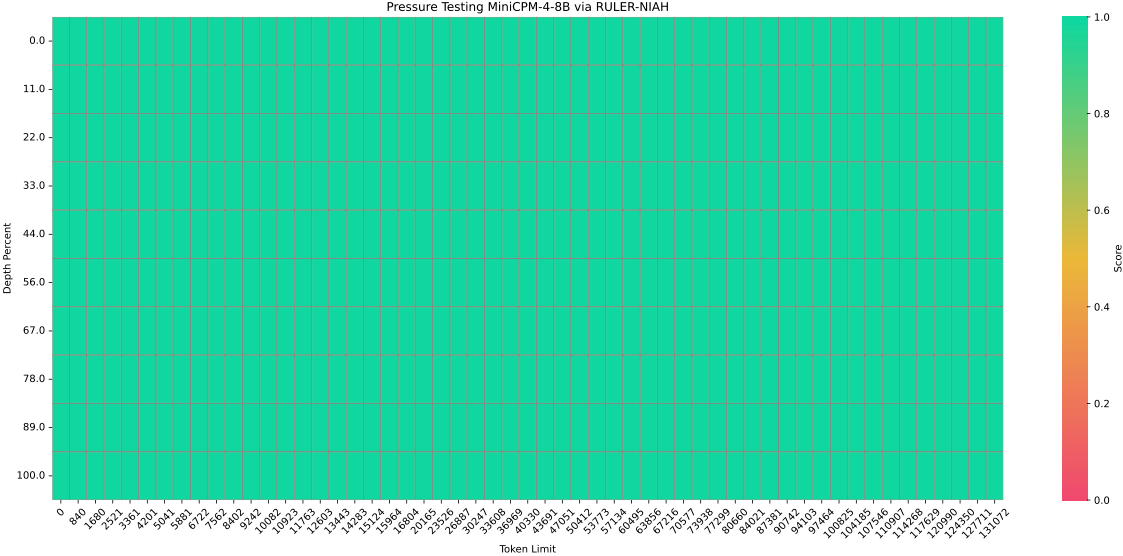
作为端侧模型,在 128K 大海捞针下全绿
而刚刚提到的43页技术报告,我看了一遍,觉得可以拆成以下:
- InfLLM v2:Attention 层只看重点
- FR-Spec:草稿阶段不全写
- BitCPM4:训练时就考虑压缩
- CPM.cu + ArkInfer:定制推理 & 部署系统
- 风洞 2.0:小模型先试,大模型再训

https://github.com/OpenBMB/MiniCPM/blob/main/report/MiniCPM_4_Technical_Report.pdf
下面容我一一拆解
InfLLM v2:自我 Rag
这次 MiniCPM 的主力架构,InfLLM v2 的东西,全称是“可训练稀疏注意力机制”
大致就是:在 Attention 里做了 RAG
传统的大模型,每一个词(token)都要和上下文中所有其他词去交互一遍,来判断“谁重要谁不重要”。这种方式虽然准确,但计算量非常大——输入越长,算得越慢,显存也越容易爆掉。
在下面的演示中,你可以点击【阳光】【花香】【人们】【微风】【感叹】或者【今天】,来看看大模型都关注到了什么。
InfLLM v2 做了些改变:让模型像人一样,只看“相关部分”
分两步:
第一步:把上下文切成一个个“语义块”——比如一段话、一个段落,作为候选记忆单元
第二步:让每个新输入的 token 自己挑选,它最需要参考的那几个语义块,然后只和它们交互
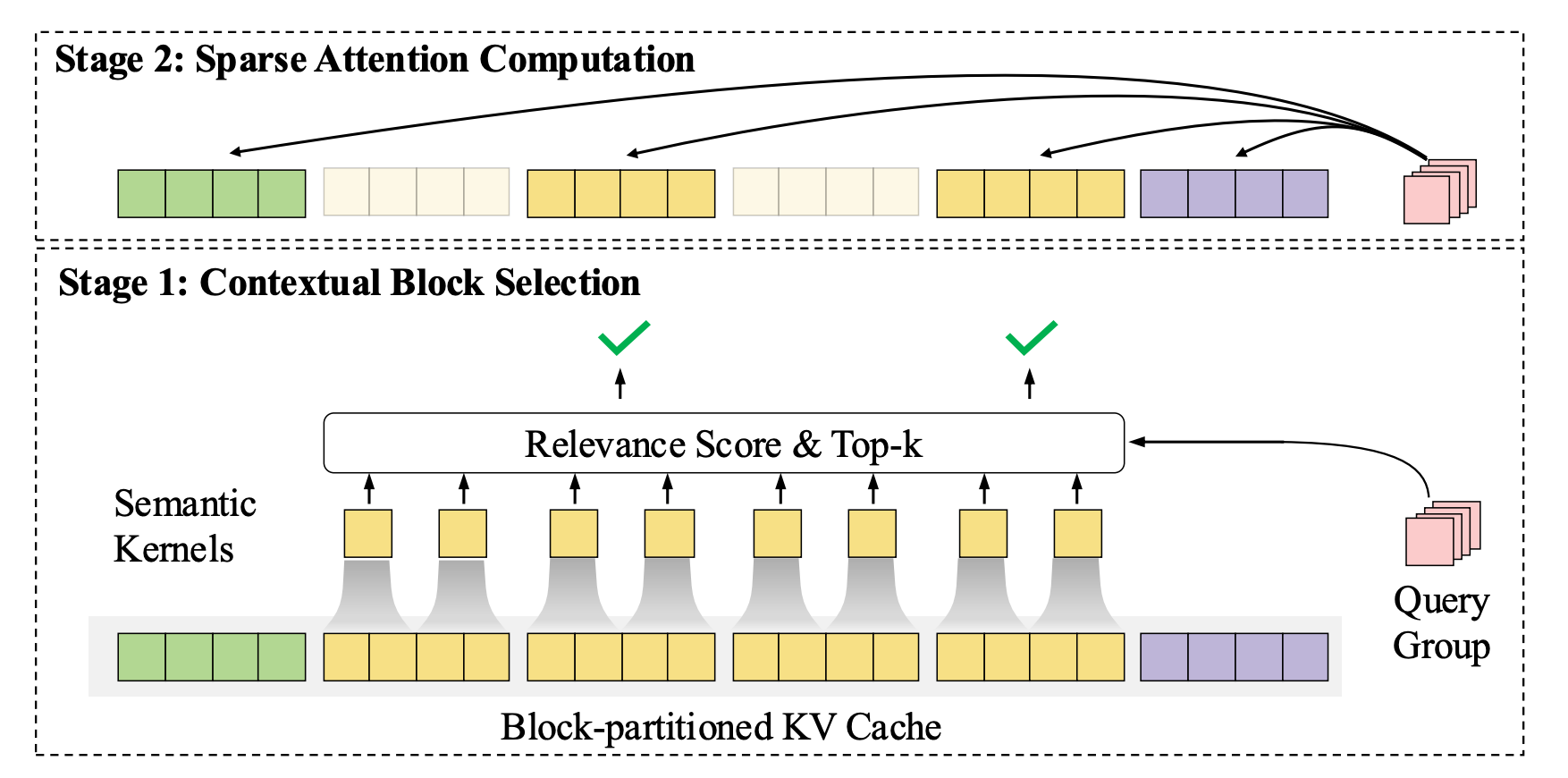
InfLLM 原理图示
这套机制的效果非常实在:在长文本任务中,把 attention 的计算量从「一整个上下文」压缩成「不到 5% 的上下文块」。
更妙的是,MiniCPM4 有自动切换模式
- 短文本时:继续用传统稠密
- 长文本时:自动启用稀疏机制
FR-Spec:更快的草稿
生成式模型推理慢,很多时候不是因为模型太大,而是因为每一步都太复杂。
尤其是在每次生成一个词时,模型都要在几万个候选词里挑一个出来——就像你每写一个字,都要在整本字典里找一圈。这是语言模型最花时间的一步。
于是人们想了一个加速策略:草稿模型 + 验证模型。
先用一个小模型“快速写个草稿”,然后大模型来看草稿写得靠不靠谱。如果靠得住,就直接用,省得大模型每次都从头干一遍。
这个机制叫做“投机采样”(Speculative Decoding),原理上很好用,但它也有自己的问题:
草稿模型本身,也要用整个词表去算 softmax,它自己也很累,没真正省多少。
MiniCPM4 的改进就是这里:草稿模型少管点事,只写常规句子就行
这就是 FR-Spec(Frequency-Ranked Speculation)的核心。
具体做法是:
- 构造一个高频词表,也就是平时出现最多的那几千个词;
- 草稿模型只在这些词里选,softmax 的时候不需要考虑全词表;
- 大模型依旧保留全词表,负责细节和修正,保障质量。
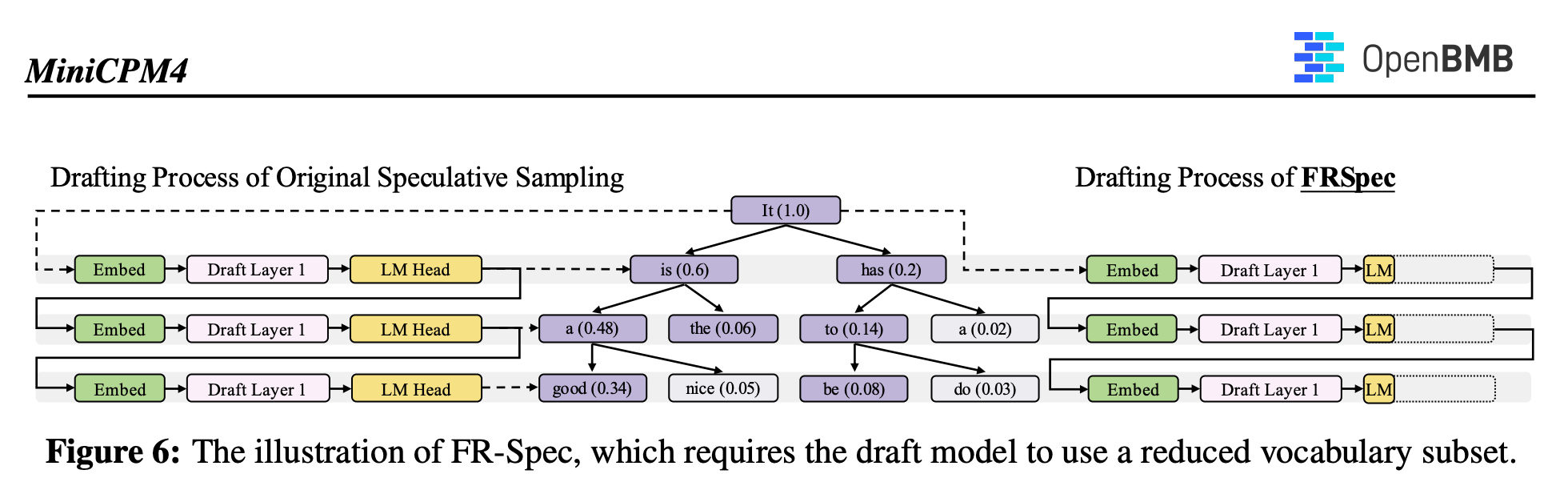
FR-Spec 原理图示
这种“草稿不全写,大模型兜底”的结构带来两个直接好处:
- 草稿模型跑得快,软硬件负担更轻;
- 整个草稿 + 验证链条稳定,最终输出没变差。
尤其是在端侧设备,比如手机、笔记本、嵌入式芯片等,这种优化带来的速度提升非常关键。
这么来记
原本:是两个模型各自跑一套
FR-Spec:草稿模型弄一小半,剩下的由大模型快速补全
流程短了,速度自然快了
BitCPM4:把量化塞进训练
大模型所以叫大模型,首先是:大
这个大,也体现在了本身的体积上:又大又重,占显存,占带宽,跑得慢
为了让模型运行的更快,人们会将原本的浮点计数,压缩成整数,这一过程叫做量化
常见的压法是 INT8、INT4——也就是说,每个参数只用 8 bit、4 bit 来存。越小越快,但越小也越难保留原来的信息
MiniCPM 这次直接上了三值参数只用三种值表示:-1、0、+1平均下来是 1.58bit,已经接近量化的极限
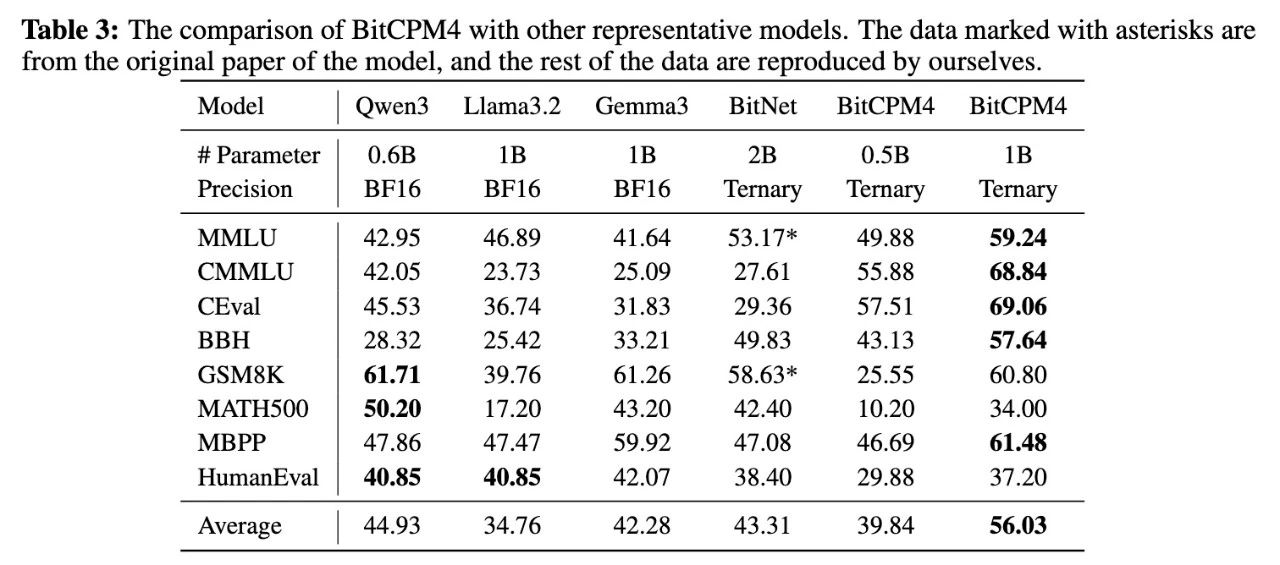
各类模型的量化信息
通常情况下,压缩到这么狠,模型会崩,而 MiniCPM 的做法,是把量化这个过程提前塞进训练里
以前是:先训完,再量化(PTQ,Post-Training Quantization)
这里是:奔着量化去训练(QAT,Quantization-Aware Training)在训练时,就告诉模型:你之后只能选三种值,自己想办法适应吧
具体是两步:
第一步:先训一个正常精度的模型,比如 FP8
第二步:接着在三值限制下继续训练,让它自己适应压缩精度
训练过程不复杂,用的 token 数只比正常 decay 多两倍左右
结果:模型压缩了 90%,但评测表现没明显掉不是因为三值更强,而是训练方式更适配
量化没有优劣,只有取舍
在算力有限的前提下,这种极致压缩,是非常实用的选择
CPM.cu 和 ArkInfer
模型训练得再好,最后都要落到一件事上:能不能跑起来,跑得快不快
之前我有一篇暴论,特别提到:面壁和硅基流动,在模型部署上,有非常独特的积累

DeepSeek 后,第一批的生态锚位
话说回来,很多模型会直接用 vLLM、transformers 这种通用推理框架。它们确实方便,但不够轻,也不够快,尤其在端侧设备上,资源吃紧。
MiniCPM 自己写了推理引擎,叫 CPM.cu,来支持自家的模型,比如刚才提到的 InfLLM 和 FR-Spec:从 memory 分配到 kernel 调用,全都围绕自己模型结构打通。
而在「跑得快」之外,还有一个问题:能不能部署得开?
不同平台,不同芯片,不同后端,部署流程一换就出 bug。
MiniCPM 在这块配了 ArkInfer,用来做部署适配,作为跨平台调度系统,做了三件事:1. 统一模型调用方式:无论底层是 llama.cpp 还是 TensorRT,接口都长一样2. 封装硬件差异:支持 NVIDIA、Intel、高通、MTK、昇腾等多种芯片3. 一次训练,多端部署:写一套模型,不用每个平台各改一版
这样,模型从训练出来,到部署上线,流程少了、接口稳了、速度快了
风洞 2.0:让小模型先探路
训练任何模型,都是很烧钱的
光是一个学习率、一套 batch size,试错一次就是几十万 token,几百张卡。堆资源可以解决问题,但也太贵了
MiniCPM 的思路是:先用小模型,把风向试出来
这套系统叫做「风洞 2.0」,做的事很简单:
- 先用 0.01B~0.5B 的小模型训练几十轮,观察 loss 和性能
- 把这些数据拿去预测大模型应该怎么训,用什么配置最稳
换句话说:
在重金投入之前,先模拟器跑几圈再说
模拟器(图文无关)
它用的评估标准叫 ScalingBench,能量化地预测性能曲线走势,效果比人工调参准得多,token 花得也少
除此之外,MiniCPM 在训练本身也做了两件优化:
精度用 FP8:比 FP16 还低,能省显存,能省传输目标用多 token 预测:一次训多个词,训练信号密度高,收敛更快
整套下来,MiniCPM4-0.5B 的训练 token 用量只有 1T,但性能能打到 Qwen3(36T)那个水平
收束以上
MiniCPM4 是一个系统层面的优化闭环:
Attention 稀疏,少算点
- 草稿机制,快跑点
- 参数量化,瘦一点
- 推理定制,贴合点
- 训练搜索,准一点
- 部署调度,顺一点
每一层,都做了迭代
最终堆出一个结果:在端侧,128K 长文本,能稳定、快速、成本低地跑起来
这事儿,莫名让我想到了 DeepSeek:训练优化、推理优化、数据优化…一直不断迭代。
模型行业的战局,似乎正是被这一个个架构上的创新与微创新,所塑造
另外的,call back 下曾经写的一份内容,并恭喜:硅基流动完成新一轮数亿元融资
 DeepSeek 后,第一批的生态锚位
DeepSeek 后,第一批的生态锚位
本文由人人都是产品经理作者【赛博禅心】,微信公众号:【赛博禅心】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。