RAG时代也要懂的召回和排序逻辑
无论是之前的搜索、问答、推荐还是目前基于大模型的RAG,召回和排序仍然是核心的两个工程模块。召回排序在不同场景有很多不同的算法和工程化实现方式,我们简单聊下其中的有代表性的方法。

一、召回策略
召回是从海量数据中筛选出与用户Query相关的候选集,需平衡相关性和覆盖率:
- **倒排索引召回:**基于关键词匹配的传统方法,通过建立倒排索引快速定位文档。优势是高效,但无法解决语义相似性问题(例如用户搜索“苹果”可能指水果或品牌)。
- **语义召回:**采用语义向量模型(如BERT、DSSM),将Query和文档映射到同一向量空间,解决长尾Query一词多义问题。例如,搜索“儿童读物”可召回“绘本”相关内容。
- **个性化召回:**结合用户画像(如历史行为、兴趣标签),动态调整召回结果。例如,用户频繁搜索科技产品,优先召回相关品牌或型号。
- **混合召回:综合多种召回策略(如倒排索引+语义召回),通过加权融合或多路召回提升覆盖率和多样性。
二、排序策略
排序阶段需对召回结果精细化打分,核心目标是提升意图准确率:
**1)特征工程:**提取Query与文档的匹配特征(如TF-IDF、BM25)、用户行为特征(点击率、停留时长)、内容质量特征(权威性、时效性)等。
2)分阶段排序
- 粗排(Top-K筛选):用轻量模型(如LR、GBDT)快速筛选候选集,降低计算成本。
- 精排(CTR预估):采用深度学习模型(如Wide&Deep、DIN)预测用户点击概率,结合业务目标(如转化率、GMV)优化排序。
**3)多目标优化:**平衡相关性和商业目标(如广告收入),通过多任务学习或强化学习动态调整权重。
三、优化策略
**1)效果评估与AB测试:**监控准确率、召回率、CTR、转化率等指标,通过AB实验验证策略有效性。例如,对比语义召回与传统召回的CTR差异。
2)Query理解优化
- 多粒度切词:结合实体识别(如品牌、品类)和意图识别(如导航类、信息类)。
- 语义扩展:通过同义词、近义词扩展Query(如“手机”扩展为“智能手机”)。
**3)个性化与场景化:**根据用户设备、地理位置、搜索场景(如电商、资讯)动态调整策略。例如,电商搜索优先召回促销商品。
**4)长尾问题处理:**针对低频Query,采用语义召回或热门结果兜底策略,减少零少结果率。
四、前沿趋势
生成式引擎优化(GEO):通过调整内容呈现形式,适配生成式AI的检索偏好(如结构化信息、简洁描述)。
RAG技术:结合检索增强生成(Retrieval-Augmented Generation),提升答案的准确性和上下文连贯性。
五、名词解释
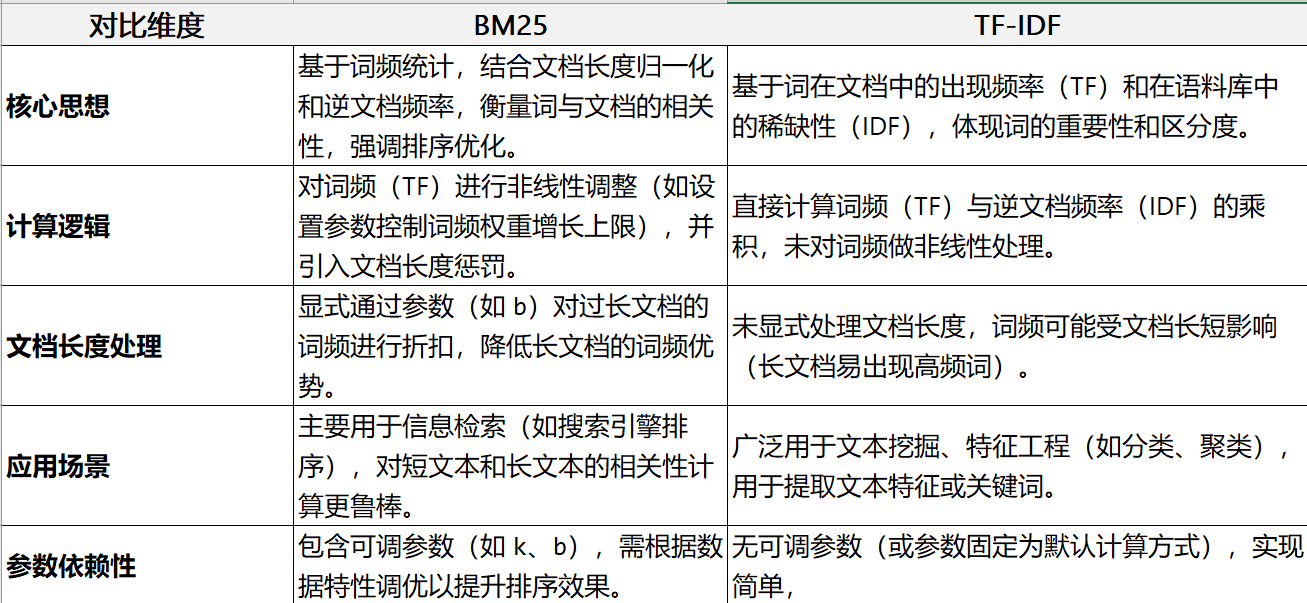
TF-IDF:词频-逆词频,核心思想是,一个词的重要性与它在当前文档中出现的频率成正比,但与它在整个语料库中出现的频率成反比。
BM25:(Best Match 25)是一种经典的信息检索算法,用于衡量查询(Query)与文档(Document)的相关性,广泛应用于搜索引擎、推荐系统召回阶段等场景。其核心思想是通过统计学方法对文档中的关键词权重进行综合评估,是传统检索模型中的标杆算法。
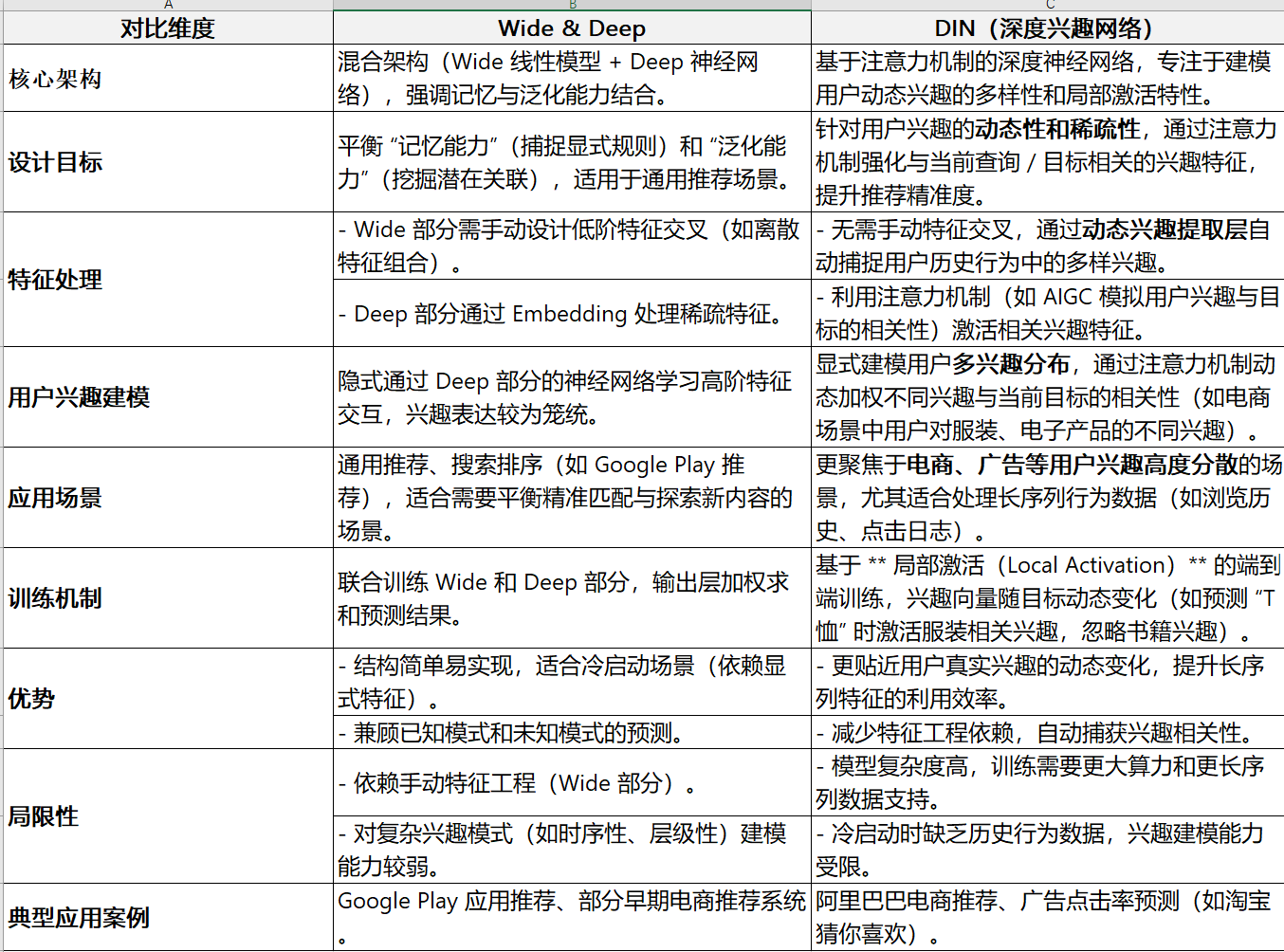
**Wide & Deep **
核心思想是联合训练线性模型(Wide)与深度神经网络(Deep),兼顾记忆(Memorization)与泛化(Generalization)能力,用于用户点击率(CTR)预测和推荐系统。
DIN(Deep Interest Network)
核心创新是引入注意力机制,动态捕捉用户多样且变化的兴趣,解决传统模型对用户行为序列建模的不足。
**Wide & Deep和DIN对比 **
本文由 @福田贝叶斯 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务