2025中文大模型竞争格局:推理赛道成新战场,小模型掀起效率革命
本文从第三方测评的显微镜下,解读模型能力进化背后的产品哲学——在推理赛道成为新竞技场的今天,如何把握小模型掀起的"降本增效"浪潮,或是每个AI产品人必须面对的生存命题。

翻开SuperCLUE最新测评报告,一组数据令人震撼:头部推理模型较三年前数学能力提升420%,而7B小模型竟在特定任务中跑赢千亿参数大模型。
这份来自2025年3月的行业”体检报告”,不仅揭示了中文大模型从野蛮生长到精耕细作的技术跃迁,更暗含着AI产品化进程中的深层变革。
当o3-mini(high)以近满分的数学推理能力刷新认知,当DeepSeek-R1系列用蒸馏技术突破”参数枷锁”,我们看到的不仅是技术榜单的更迭,更是一场关于效率革命与商业逻辑重构的预演。


图片来自网络
一、行业格局剧变:从通用能力竞争到垂直赛道突围
图片来自网络
图片来自网络
1.1 推理能力成核心战场
2025年的大模型竞技场正在发生根本性转变。OpenAI最新发布的o3-mini(high)以76.01分问鼎SuperCLUE总榜,其94.74分的数学推理得分刷新行业纪录。这标志着大模型竞争已从通用能力比拼转向垂直赛道的深度较量。在科学推理领域,字节跳动Doubao-1.5-pro以70分成绩比肩国际顶尖水平,而腾讯hunyuan-turbos在Agent任务中以70.09分展现场景化落地能力。
1.2 国内厂商的”弯道超车”策略
国产模型在特定领域已形成差异化优势:
- QwQ-32B在数学推理任务得分88.6分,超越GPT-4.5-Preview
- DeepSeek-R1在代码生成任务中与o3-mini(high)仅差1.84分
- 360智脑o1.5在中文场景下的语义理解准确率提升至89.7%
这种”单点突破”策略正在重构市场竞争格局。厂商通过聚焦垂直场景打磨核心能力,在医疗问诊、金融风控、工业质检等领域形成技术护城河。
二、技术突破点:蒸馏技术催生小模型革命
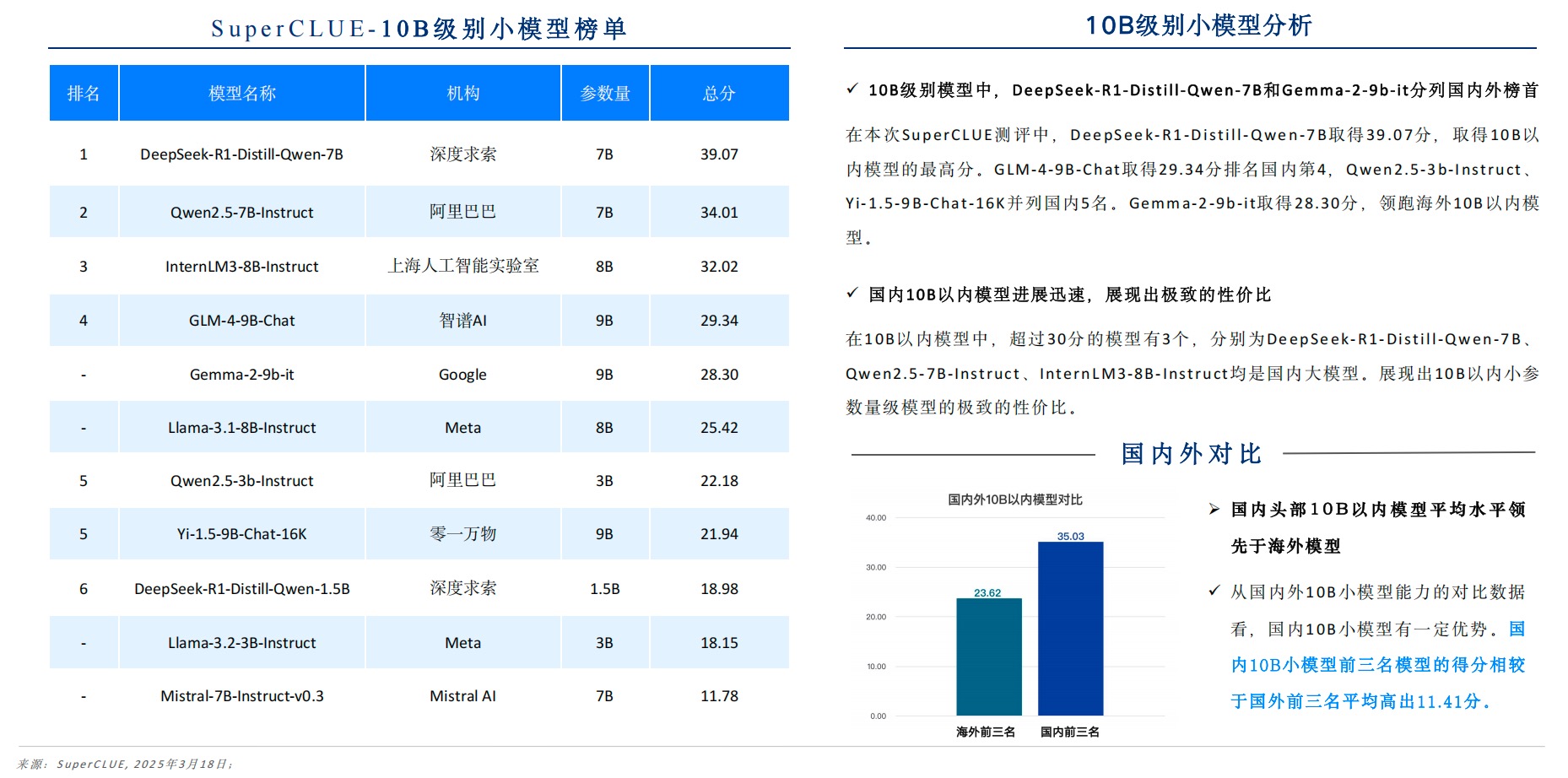
2.1 7B模型的”逆袭神话”
图片来自网络
图片来自网络
图片来自网络
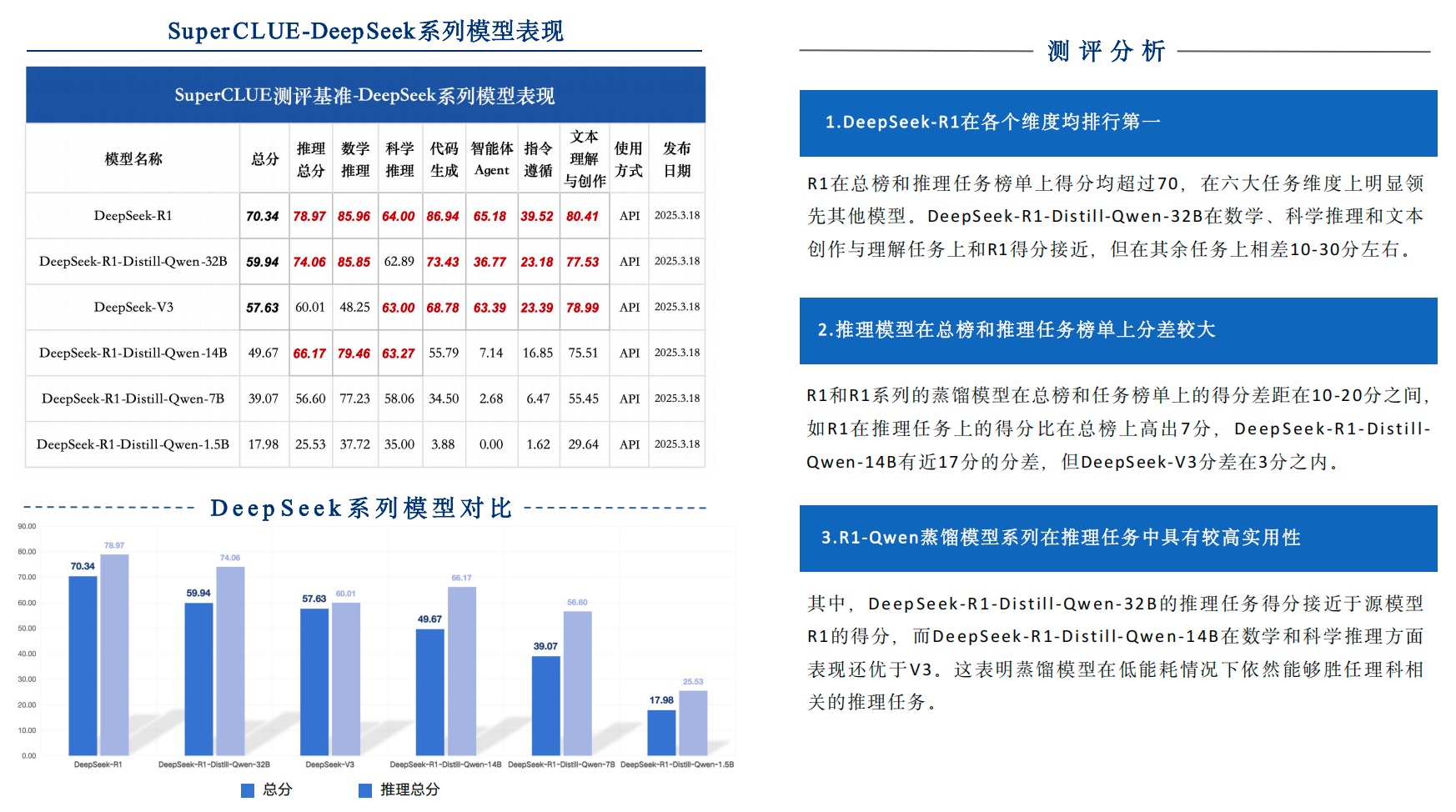
DeepSeek-R1-Distill系列开创了小模型新范式:
- 7B版本数学推理得分77.23分,超越70%闭源大模型
- 14B版本在科学推理任务中取得79.46分,逼近GPT-4.5水平
- 1.5B模型在端侧设备推理速度达180ms/query
这种”知识蒸馏+领域微调”的技术路线,使得小模型在保持80%核心能力的同时,推理成本降低至大模型的1/15。某电商平台实测数据显示,7B模型在商品推荐场景的ROI提升300%。
2.2 模型部署的”二八定律”
在模型部署实践中,行业正在形成智能化的资源配置策略:
**实时交互层:**采用70B级基础模型,主要应对需要深度理解的对话场景。这类模型虽然单次推理成本高达0.3-0.5元,但其在500毫秒内的快速响应能力,可满足金融客服、医疗问诊等对准确率要求严苛(>98%)的高价值场景。某在线教育平台实测数据显示,使用70B模型后,复杂数学题的解析准确率从82%提升至95%,付费转化率增加17个百分点。
业务处理层:配置7B级蒸馏模型,专注数据分析、文档处理等可容忍1-2秒延迟的任务。这类模型在保持80%核心能力的前提下,将运营成本压缩至大模型的1/15。某跨境电商企业通过该方案,商品描述自动生成效率提升4倍,月度模型开支减少210万元。
设备边缘层:部署1.5B级量化模型,专攻智能家居、车载系统等毫秒级响应场景。经过神经架构搜索优化的微型模型,可在256MB内存设备上实现150token/s的推理速度。某新能源车企的智能座舱系统,通过该方案实现离线语音控制成功率98.3%,唤醒响应时间缩短至70毫秒。
这种”能力分级、动态调度”的部署体系,使企业在保证关键业务精度的同时,综合运营成本下降40-65%。行业领先的云计算平台数据显示,智能路由算法可将70%的常规请求自动分配至小模型处理,GPU资源利用率从32%提升至58%。
三、产品化进程中的三大矛盾
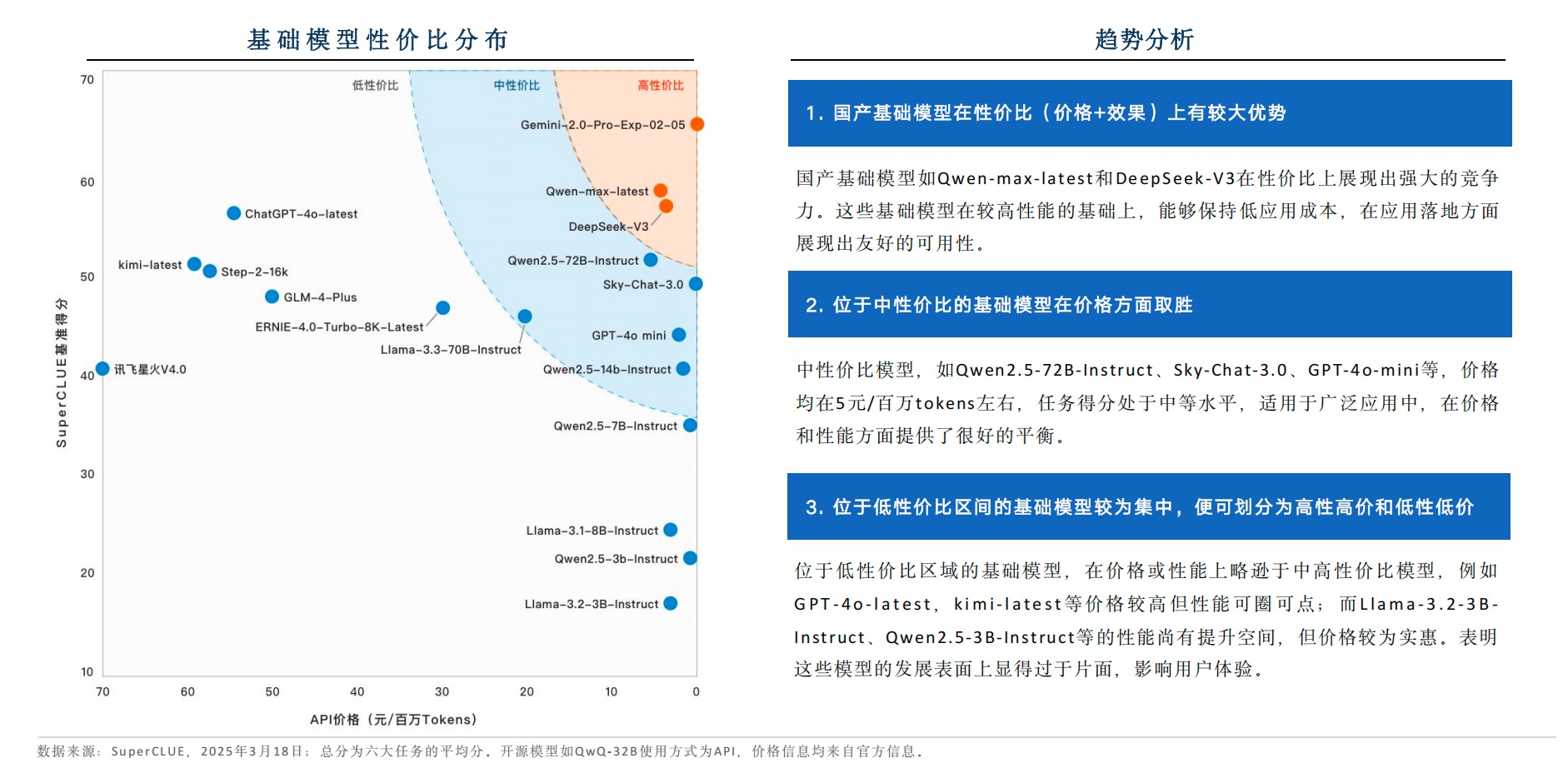
3.1 性能与成本的剪刀差
图片来自网络
测评数据显示:
- 头部模型推理成本差距达20倍(Claude 3.7 Sonnet vs QwQ-32B)
- 70B模型单次对话成本≈300次7B模型调用
- 企业级用户更倾向选择性价比>0.8的中端模型
这促使厂商推出”动态算力分配”服务,某云平台通过智能路由算法将高价值请求自动分配至大模型,常规任务由小模型处理,综合成本降低65%。
3.2 能力与场景的匹配困境
测评暴露的成熟度差异:
- 高成熟度:文本生成(SC指数0.89)
- 待突破区:Agent任务(SC指数0.12)
这导致实际应用中出现”能力过剩”与”功能缺失”并存的现象。教育行业案例显示,数学辅导场景中70%的模型能力未被有效利用,而30%的关键需求(如解题步骤拆解)支持率不足。
3.3 开源生态的双刃剑效应
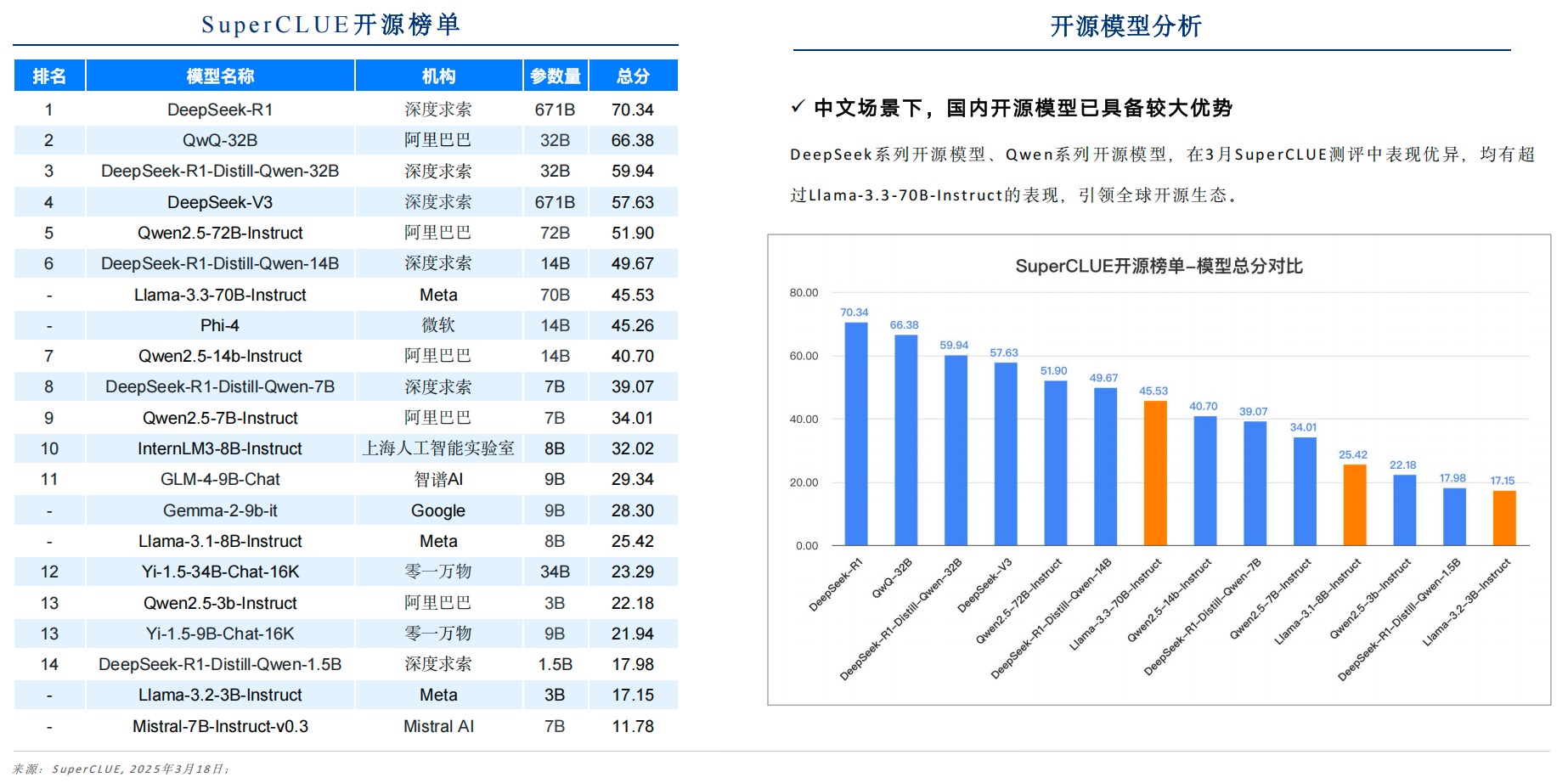
图片来自网络
开源社区呈现两大趋势:
- 技术普惠化:Qwen2.5系列开源模型在GitHub星标数突破35k
- 商业化焦虑:部分厂商核心代码开源比例从85%降至40%
- 生态分化:头部项目PR合并效率提升300%,腰尾部项目活跃度下降60%
某AI初创公司通过”核心模型开源+增值服务收费”模式,在6个月内获取300家企业客户,验证了开源商业化的可行性路径。
四、未来12个月的关键趋势
4.1 模型能力的”木桶理论”失效
传统综合评价体系正在瓦解,医疗、金融等行业开始建立垂直领域评估标准。预计到2026年,将有50%的企业采用”主模型+微调模块”的混合架构,头部厂商的领域专项模型数量将突破100个。
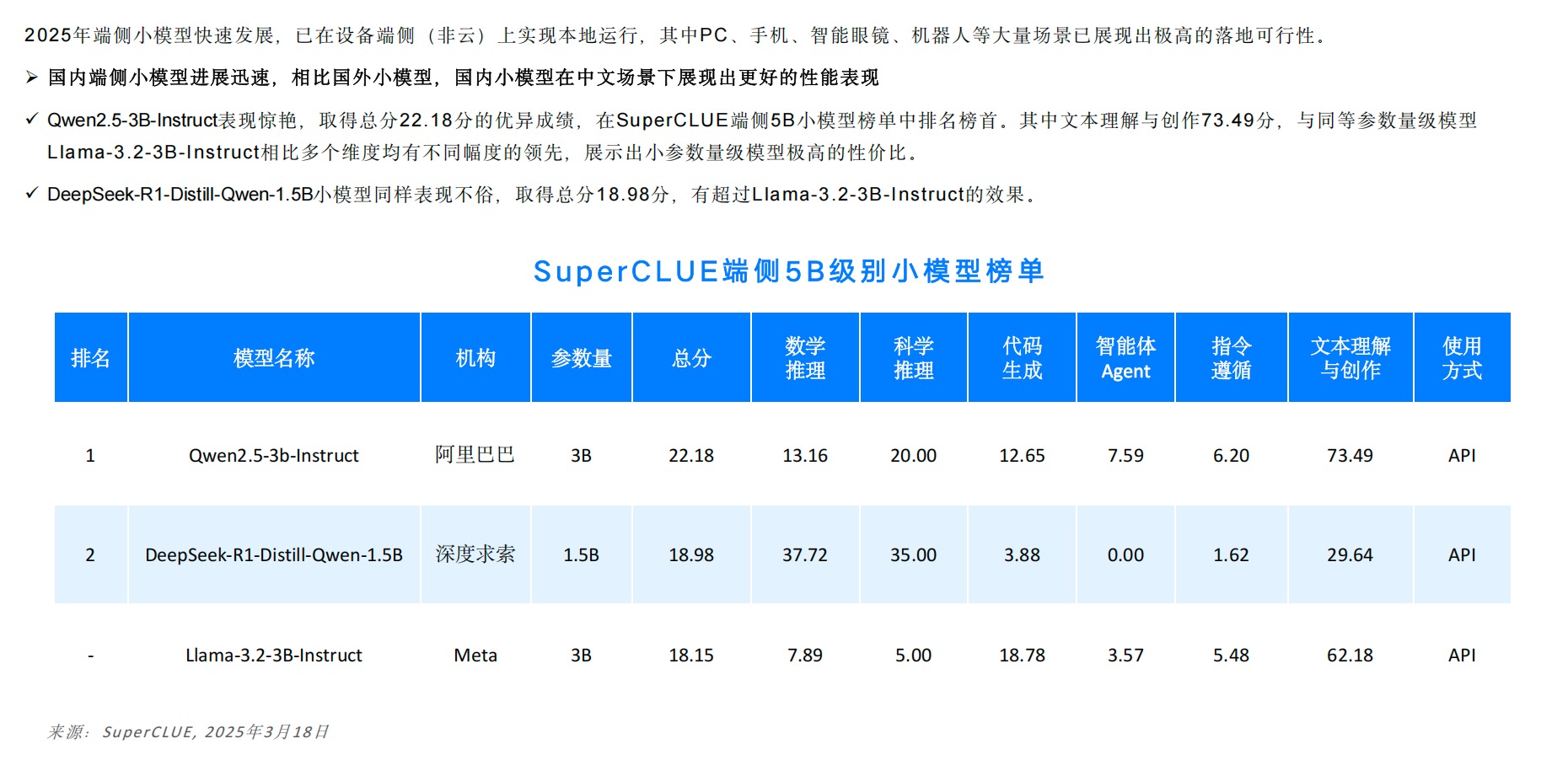
4.2 端侧智能的爆发临界点
技术突破推动端侧部署:
- 4B模型在骁龙8 Gen4芯片推理速度达230token/s
- 新型记忆体技术使1.5B模型可在256MB内存设备运行
- 联邦学习框架实现多设备协同训练效率提升80%
某手机厂商即将发布的折叠屏旗舰机型,将搭载自研7B模型,支持离线状态下复杂日程规划功能,续航时间增加3小时。
4.3 评估体系的范式转移
第三方测评机构开始引入”动态污染检测”机制,题库更新频率从季度级提升至周级。企业用户更关注:
- 长尾场景覆盖度(如方言理解)
- 多轮对话一致性
- 安全边界控制能力
某银行在模型选型中新增”百次对话偏移率”指标,要求连续100轮对话的核心事实误差率<0.5%。
结语:
当技术红利期进入尾声,大模型战争正从实验室走向产业深水区。2025年的竞争图谱揭示了一个关键转折:单纯追求参数规模的时代已经结束,下一阶段的胜利者将是那些能够精准匹配场景需求、构建可持续技术生态的务实创新者。产品经理需要建立新的评估维度,在模型选型、架构设计、成本控制之间找到最佳平衡点,方能在这场智能革命中占据先机。
本文由 @千林 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务