主流 AI 生成 3D 技术流派辨析:Text-to-3D, Image-to-3D 与 NeRF 应用概览 (AI+3D 产品经理笔记 S2E02)
AI生成3D技术正在迅速改变我们创造和体验三维内容的方式。从文本到图像,再到复杂的三维模型,AI技术的多样性为产品设计、游戏开发、虚拟现实等多个领域带来了前所未有的机遇。

引言:从“指令”到“立体”的技术光谱
在上一篇笔记(S2E01)中,我们共同探讨了 AI 生成 3D 技术之所以在当前节点迎来爆发的深层驱动力,分析了它旨在解决的行业核心痛点,并对现阶段的技术挑战与局限建立了初步的理性认知。我们认识到,AI+3D 并非单一的技术魔法,而是一个包含多种路径、处于不同发展阶段的技术集合。这种多样性源于问题的复杂性以及可用数据和计算资源的限制,迫使研究者探索不同的策略来弥合抽象指令(如文本)或低维数据(如图像)与高维、结构化的 3D 输出之间的鸿沟。

那么,当我们谈论“AI 生成 3D”时,具体指的是哪些主流的技术方法或流派呢?它们各自的工作逻辑是怎样的?需要什么样的输入?能产生什么样的输出?又分别适用于哪些应用场景?理解这些不同技术流派的特点、优势与局限,是产品经理进行技术选型、定义产品功能、评估可行性的基础。未能区分这些技术的光谱,可能导致产品定位失误、用户预期错配或技术路线选择不当。
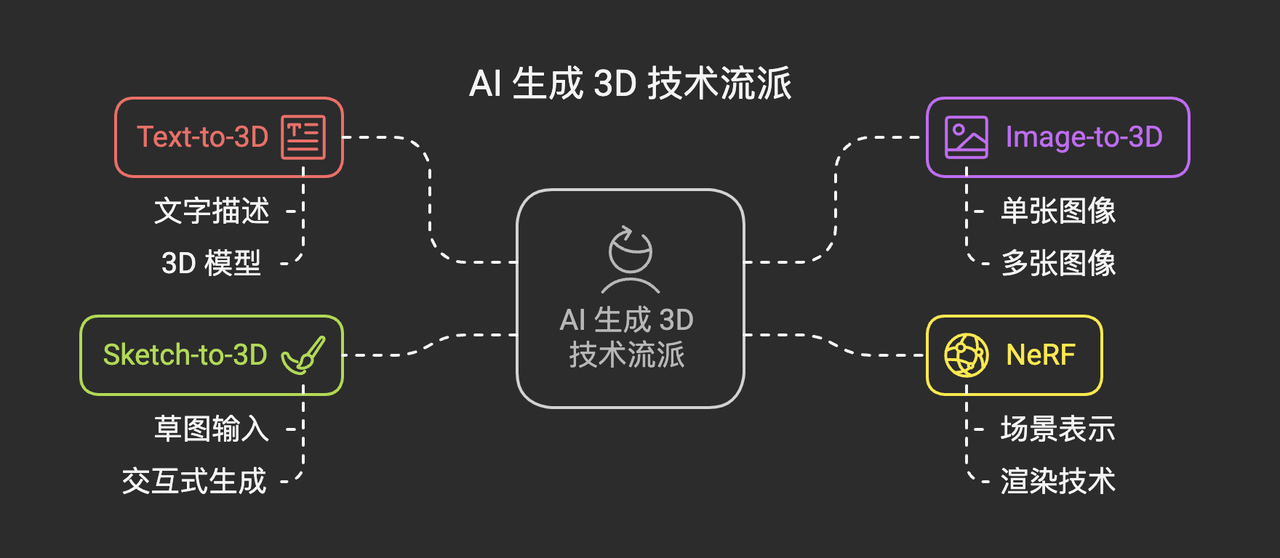
本篇笔记(S2E02)将聚焦于梳理和辨析当前备受关注的几种主流 AI 生成 3D 技术流派,主要包括:
- Text-to-3D (文本到三维): 如何让 AI 根据一段文字描述“凭空”创造出 3D 模型?
- Image-to-3D (图像到三维): 如何从单张或多张二维图像中恢复或生成对应的 3D 结构?
- NeRF (神经辐射场): 作为一种强大的场景表示和渲染技术,它在 3D 重建和生成中扮演着怎样的角色?
- (可能涉及) Sketch-to-3D (草图到三维) 及其他: 其他值得关注的交互式生成方式。
我们将尝试从产品经理的视角,深入浅出地解析这些技术流派的基本原理、输入输出特性、典型的应用场景以及初步的优劣势对比。目标是帮助大家建立一个关于 AI 生成 3D 技术“光谱”的清晰认知地图,认识到它们并非相互排斥,而是常常相互借鉴、融合,共同推动着领域的发展。为后续更深入的技术探讨和产品思考打下坚实基础。
一、 Text-to-3D:用语言“召唤”三维实体
Text-to-3D 无疑是近年来 AI+3D 领域最引人入胜、也最具“魔法感”的方向之一。它的核心目标是让用户能够仅仅通过输入一段自然语言文本描述(例如,“一个坐在扶手椅上看书的宇航员”,“一个带有锈迹和划痕的蒸汽朋克风格的机械臂”),就能让 AI 自动生成对应的三维模型。这极大地降低了 3D 内容创作的门槛,使得没有任何 3D 建模经验的用户也能将想象中的物体或场景快速具象化。这种潜力对于游戏开发、虚拟现实、影视制作等需要大量 3D 内容的行业具有革命性意义。
实现高质量的 Text-to-3D 并非易事,它需要模型同时具备强大的自然语言理解能力、丰富的世界知识以及生成复杂三维几何结构的能力。由于直接建立文本与高质量 3D 模型之间映射关系的大规模配对数据集极为稀缺,研究者们探索了多种间接的技术路径。
1️⃣ 核心技术路径与演进

实现高质量的 Text-to-3D 并非易事,它需要模型同时具备强大的自然语言理解能力、丰富的世界知识以及生成复杂三维几何结构的能力。目前主流的技术路径大致可以分为几类:
a. 基于 CLIP + 优化/生成器 的早期探索
核心思路:
- ① 借鉴 Text-to-Image: 利用 CLIP 强大的跨模态(文本-图像)对齐能力作为“语义引导”。
- ② 定义 3D 表示: 如 NeRF、SDF 或直接操作 Mesh 顶点。
- ③ 渲染与评估: 从不同虚拟视角渲染 3D 表示得到 2D 图像,用 CLIP 计算渲染图与输入文本的相似度得分。
- ④ 优化: 以最大化 CLIP 相似度为目标,通过反向传播优化 3D 表示参数或驱动 3D 生成器网络。
代表性工作:
- Dream Fields: 直接优化 NeRF 参数。
- CLIP-Forge: 两阶段方法,先训练 3D 形状自编码器,再训练以 CLIP 图像特征为条件的归一化流生成形状嵌入,推理时用 CLIP 文本特征驱动生成。
优缺点:
- 优点: 巧妙利用预训练 CLIP,绕开缺乏文本-3D 配对数据的难题;CLIP-Forge 生成速度相对较快。
- 缺点: 优化过程缓慢,易陷局部最优;缺乏固有 3D 理解,几何质量和三维一致性差,易出现“Janus 问题”(前后都有脸等矛盾特征)。
b. 基于 2D 扩散模型的“蒸馏” (Score Distillation Sampling – SDS)
核心思想: 利用强大的预训练 2D 文本到图像扩散模型(如 Imagen, Stable Diffusion)作为“教师”,将其二维生成能力“蒸馏”到三维表示(常用 NeRF 或 SDF)的学习中。
工作流程:
- ① 初始化 3D 表示。
- ② 随机视角渲染: 得到 2D 图像。
- ③ 2D 扩散模型评分: 将渲染图和文本 Prompt 输入 2D 扩散模型,利用其去噪网络估计一个“分数”或“梯度”,指示如何修改 2D 图像使其更符合文本。
- ④ 3D 表示更新: 利用 SDS 算法,根据 2D 分数计算更新 3D 表示参数的梯度,使其在任意视角渲染下都更符合文本。
- ⑤ 迭代优化: 大量迭代直至 3D 表示收敛。
代表性工作:
- DreamFusion (Google): 开创性工作。
- Magic3D (Nvidia): 两阶段优化(低分粗糙+高分精细),提高质量、分辨率和速度。
- ProlificDreamer: 提出 VSD,旨在解决 SDS 的过饱和、过平滑、低多样性问题。
优缺点:
- 优点: 生成细节更丰富、三维一致性更好(Janus 问题缓解)、语义更准确。
- 缺点: 训练(优化)过程仍非常耗时(小时级);对 Prompt 敏感,需“提示工程”技巧。
c. 直接在 3D 表示上进行扩散
核心思想: 尝试直接在三维数据表示(点云、体素、参数化 Mesh/SDF)上应用扩散模型,避免 SDS 的优化循环。
代表性工作:
- Point-E (OpenAI): 三步流程(文本到图像 -> 图像到低分点云扩散 -> 低分到高分点云扩散),速度较快(1-2 分钟)。
- Shap-E (OpenAI): 直接在隐式函数参数空间(可解码为纹理网格或 NeRF)进行扩散,生成速度相对较快,但公开模型细节有限。
- 挑战与优势:
- 挑战: 3D 数据维度高、结构复杂,高质量、大规模、带标注的 3D 训练数据稀缺,训练强大的 3D 扩散模型难度大。
- 潜在优势: 推理速度可能更快。
- 现状: 目前在生成质量和细节上普遍不如基于 SDS 的方法。
d. 结合检索与生成
- 核心思想: 给定文本描述,先在大型 3D 模型库中检索语义相似的模型,然后将其作为生成过程的起点、参考或组成部分,再利用生成模型进行修改、组合或添加细节。
- 优势: 有助于利用现有高质量资产的结构和细节,提高生成结果质量和结构合理性。
- 依赖: 效果高度依赖所用 3D 数据库的规模、质量和多样性。
2️⃣ 输入、输出与典型应用场景
输入:
- 核心: 自然语言文本描述 (Text Prompt)。Prompt 质量(清晰度、细节、具体性)影响巨大。
- 辅助: 可能支持否定提示、风格关键词、图文混合提示、迭代式文本指导。
输出 (通常需后处理):
- ① 隐式表示 (Implicit Representation): NeRF 或 SDF,需后续提取为 Mesh (如用 Marching Cubes)。
- ② 点云 (Point Cloud): 如 Point-E 输出,需表面重建得到 Mesh。
- ③ 体素网格 (Voxel Grid): 分辨率有限,外观块状,需平滑处理并转为 Mesh。
- ④ 显式网格 (Explicit Mesh): 如 Magic3D 或 GET3D 输出,但通常拓扑不规则、面片质量差,需拓扑优化 (Retopology)、UV 修复等。
- · 颜色信息: 通常生成顶点色或低分辨率纹理贴图。
典型应用场景:
- ① 快速概念设计与原型制作: 为设计师、艺术家、开发者提供快速可视化工具,用于早期评审、头脑风暴、沟通、迭代。
- ② 个性化内容生成: 在元宇宙、虚拟社交、游戏中,让用户通过文本创建独特虚拟化身、服装、道具、家园装饰。
- ③ 教育与创意启发: 激发想象力、辅助学习 3D 概念、降低创作门槛。
- ④ 填充虚拟世界背景: 快速生成大量非关键性背景道具或环境元素(需注意质量一致性)。
- ⑤ 辅助营销内容创作: 快速生成用于广告、社交媒体的简单 3D 视觉元素。
3️⃣ 优势与局限性 (产品视角)

优势:
- ① 极低的创作门槛: 无需专业技能,自然语言即可创作,扩展创作者群体。
- ② 极高的创作效率 (概念阶段): 分钟/小时级获得初步结果,相比传统手工(天/周级)效率提升巨大。
- ③ 激发创意与想象力: 语言灵活性和模型随机性支持尝试各种想法,探索传统工具难实现组合。
局限性:
- ① 生成质量不稳定且普遍不高: 几何细节、纹理清晰度、拓扑规整性等普遍达不到专业要求,需大量后期修复。
- ② 可控性差: 难通过 Prompt 精确控制尺寸、比例、位置、特定细节。“开盲盒”感强,难稳定复现或精确迭代。
- ③ 三维一致性问题: 即使 SDS 有所改善,仍可能出现视角间结构矛盾(Janus 问题)。
- ④ 计算资源消耗大/生成速度慢: 尤其 SDS 方法,需较长计算时间(GPU 小时级),难实时交互。直接生成方法更快但质量通常更低。
- ⑤ 输出格式与下游可用性: 输出模型需复杂后处理(网格提取、拓扑优化、UV 重建、材质调整、绑定等)才能整合到专业工作流。
产品视角总结: 当前核心价值在于加速概念探索和降低创作门槛,而非取代传统建模。产品定位应侧重灵感激发、快速原型、个性化娱乐等,需管理用户对质量和可控性的预期。
4️⃣ 代表性技术/模型/工具与讨论

① CLIP-Guided Optimization:
Dream Fields: Zero-Shot Text-Guided Object Generation with Dream Fields

(来源:https://arxiv.org/abs/2112.01455)
CLIP-Forge: Towards Zero-Shot Text-to-Shape Generation

(来源:https://arxiv.org/abs/2110.02624)
② Score Distillation Sampling (SDS) & Variants:
DreamFusion (Google): Text-to-3D using 2D Diffusion

(来源: https://dreamfusion3d.github.io/)
Magic3D (Nvidia): High-Resolution Text-to-3D Content Creation
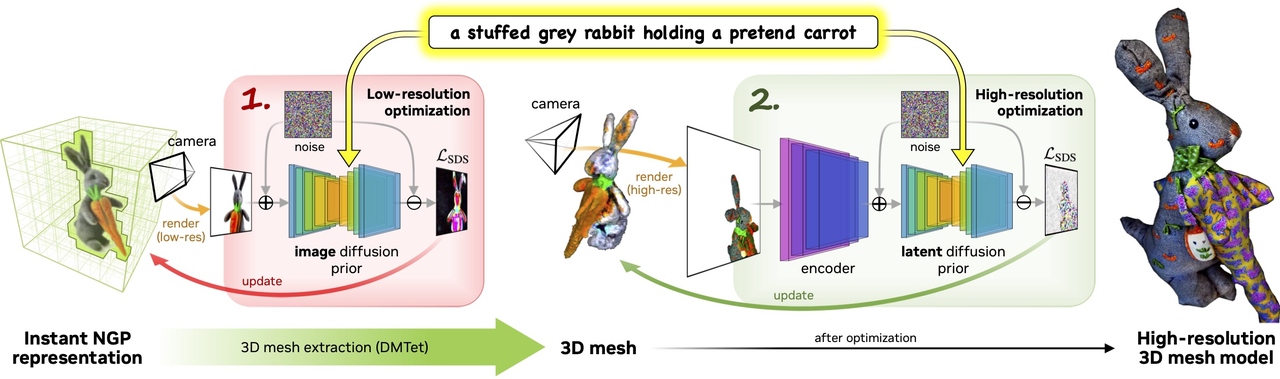
(来源:https://deepimagination.cc/Magic3D/)
ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation

(来源:https://arxiv.org/abs/2305.16213)
③ Direct 3D Diffusion:
Point-E (OpenAI): A system for generating 3D point clouds from complex prompts

(来源:https://openai.com/index/point-e/)
Shap-E (OpenAI): Generating Conditional 3D Implicit Functions

(来源:GitHub, https://arxiv.org/abs/2305.02463)
④ Representative Tools/Platforms:
Luma Genie: Luma AI’s Text-to-3D Tool

(来源:https://lumalabs.ai/genie?view=create)
Masterpiece X: AI-Powered 3D Model Generation

(来源:https://www.masterpiecex.com/)
Meshy AI: The #1 AI 3D Model Generator

(来源:https://www.meshy.ai/discover)
⑤ Quality & Challenge Discussion:
Janus Problem and View Inconsistency Analysis: Debiasing Score Distillation for Text-to-3D Generation
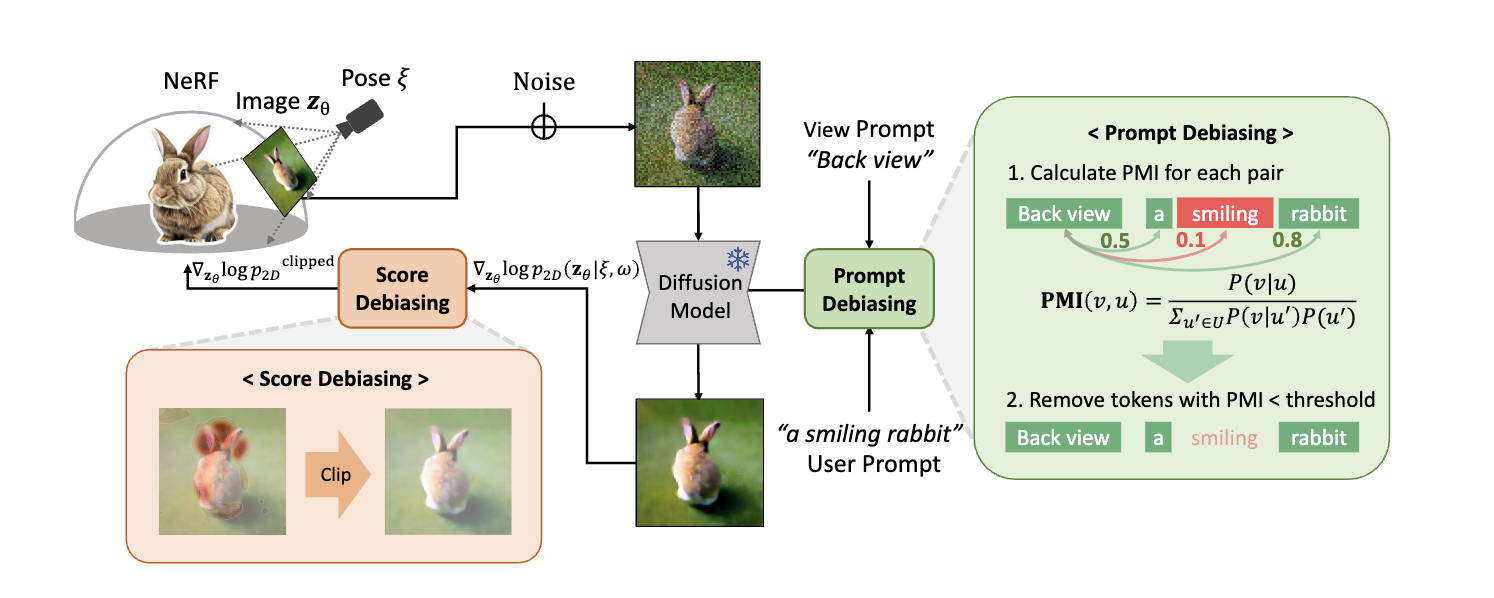
(来源:https://openreview.net/forum?id=jgIrJeHHlz)
A Quick Look at Text-to-3D Methods
(来源:https://www.pkowalski.com/?p=2415)
二、 Image-to-3D:从二维图像“还原”三维世界
Image-to-3D 技术的目标是从输入的单张或多张二维图像中恢复、重建或生成对应的三维模型。相比于 Text-to-3D 的“无中生有”,Image-to-3D 更侧重于利用图像中包含的丰富视觉信息——例如物体的轮廓、表面的纹理、光照产生的明暗、以及物体间的遮挡关系等线索——来推断其三维结构。根据输入图像的数量(单张 vs 多张)和类型(照片 vs 绘画),以及技术目标(精确重建 vs 合理生成)的不同,Image-to-3D 可以细分为多个子方向。
1️⃣ 主要技术分支与方法

a. 单视图 3D 重建/生成 (Single-view 3D Reconstruction/Generation)
目标: 仅从一张输入的 2D 图像(照片、绘画、草图)生成 3D 模型。
挑战:
- 固有歧义性 (Ill-posed Problem): 2D 投影丢失深度信息,单图可对应无限 3D 形状。
- 依赖先验: 模型需依赖强大的先验知识(常见形状、光照、透视)来“猜测”或“脑补”缺失信息(尤其是背面)。
技术路径:
- ① 基于深度学习的直接预测: 训练 DNN (CNN, Transformer 等) 直接从图像预测 3D 表示(体素、点云、网格参数、隐式场)。需大量“图像-3D 模型”配对数据监督训练。
- 代表: Pix2Vox (预测体素), Mesh R-CNN (预测粗糙体素再优化为网格)。
- 局限: 性能受训练数据多样性和质量限制。
- ② 结合生成模型与先验: 利用生成模型 (GAN, Diffusion) 学习 3D 形状先验,再根据输入图像条件生成或优化。
- ③ 利用 2D 扩散模型先验 (如 Zero-1-to-3): 近期热门且效果显著提升。
**核心思想: **利用强大预训练的、能生成新视角的 2D 图像扩散模型(如微调版 Stable Diffusion)作为先验。
**流程: **给定单张输入图,模型“想象”并生成该物体在不同新视角下的高质量图像。然后用这些 AI 生成的多视图图像,通过成熟的多视图重建技术 (NeRF, MVS) 恢复 3D 模型。
**代表: **Zero-1-to-3, SyncDreamer, Magic123。
**优势: **将困难的单视图问题转化为信息更充分的多视图问题,显著提升质量和一致性。
**特点: **结果依赖模型“想象力”和先验知识;对未显示部分需合理推断;几何精度通常不高,但视觉上可能合理完整。
b. 多视图 3D 重建 (Multi-view Stereo – MVS)
目标: 从多张已知(或可估计)相机位姿的、不同角度拍摄的图像中,重建精确的三维几何结构。
技术路径:
- ① 传统方法: 基于几何原理(特征点匹配 SIFT、三角测量、深度图估计融合)。
- **代表工具: **COLMAP, Meshroom (AliceVision)。
- **局限: **处理无纹理、高反光/透明、薄结构困难。
- ② 基于深度学习的方法: 用 DNN 提升 MVS 各环节(预测深度图、特征匹配)或端到端学习 3D 表示。
- ③ NeRF/Gaussian Splatting 作为 MVS 新范式:
NeRF: 优化 MLP 拟合所有视图光线,隐式学习精细几何和复杂外观(光照、反射、半透明),生成逼真新视图。Mesh 提取是研究热点。
Gaussian Splatting: NeRF 的显式、高效替代,用大量带参数的 3D 高斯椭球表示场景,训练更快,可实时渲染。
代表研究: BoostMVSNeRFs, MVS-GS (应用于大规模 MVS)。
特点: 输入信息丰富,几何精度和完整性通常远高于单视图方法;目标是忠实还原真实世界结构。
c. 特定类别物体重建 (Category-specific Reconstruction)
目标: 重建特定类别物体(人脸、人体、车辆、家具等)。
利用类别共有的形状先验,即使输入信息有限(单图或稀疏视图)也能得到结构合理、细节丰富的模型。
方法:
- 常用参数化模型 (Parametric Models):
- 人脸: 3D Morphable Models (3DMM),基于大量扫描数据构建参数空间(控制身份、表情),优化参数匹配输入图像特征。
- 人体: SMPL (Skinned Multi-Person Linear Model) 及其扩展(如 SMPL-X),通过参数控制体型 (Shape) 和姿态 (Pose),从图像/视频估计参数重建 3D 人体。
优势: 利用类别先验降低重建难度和数据要求,生成符合类别典型结构的、语义合理的模型。
2️⃣ 输入、输出与典型应用场景
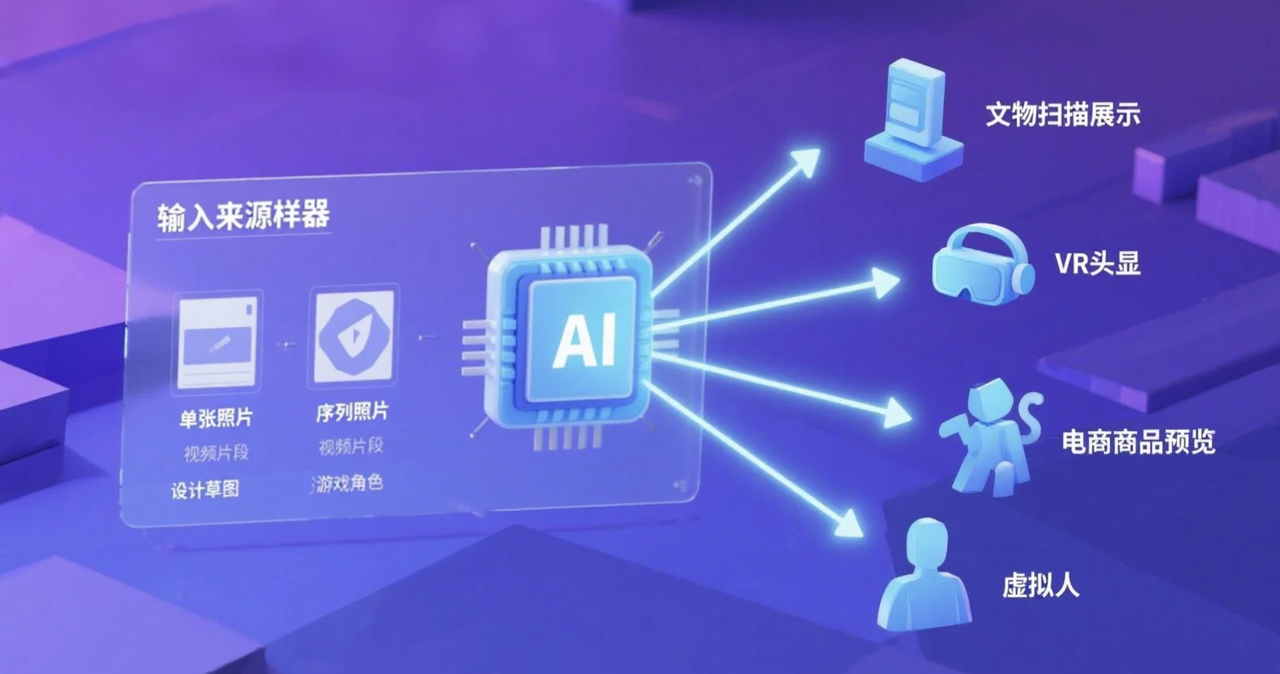
输入:
- 单视图: 一张 2D 图像(照片、绘画、设计图等)。
- 多视图: 多张不同角度图像,通常需相机内外参数(或能估计)。
- 视频: 时间连续的多视图图像序列,通常需估计相机轨迹。
输出:
- ① 显式网格 (Mesh): 最通用格式。MVS/NeRF 提取的 Mesh 几何较精确、拓扑较好。单视图生成的 Mesh 拓扑/精度可能较差,需后处理。
- ② 点云 (Point Cloud): 某些 MVS/扫描流程的中间输出,需表面重建得 Mesh。
- ③ 隐式表示 (NeRF, SDF): NeRF/SDF 方法的直接输出,需提取得 Mesh。
- ④ 体素网格 (Voxel Grid): 较少作为最终输出。
- · 纹理信息: 通常能恢复/生成 PBR 材质贴图或顶点色。
典型应用场景:
- ① 3D 扫描与数字化: 手机 App (Polycam, KIRI) 或专业设备拍摄,生成模型用于文物保护、存档、展示、逆向工程、BIM 等 (主要 MVS & NeRF/GS)。
- ② VR/AR 内容创建: 扫描现实物体/场景导入 VR/AR 环境,增强沉浸感 (主要 MVS & NeRF/GS)。
- ③ 电子商务商品建模: 从商品图生成 3D 模型用于在线 3D/AR 展示、虚拟试穿/戴 (单/多视图方法)。
- ④ 游戏与影视资产创建: 从概念图、照片、扫描数据创建 3D 资产 (各种方法)。
- ⑤ 虚拟人/化身生成: 从照片生成个性化 3D 人脸/人体模型 (单视图 & 特定类别重建)。
- ⑥ 辅助设计: 从草图、参考图、实物照片生成初步 3D 模型,加速迭代 (主要单视图生成)。
3️⃣ 优势与局限性 (产品视角)

优势:
- ① 利用现有视觉信息: 比 Text-to-3D 更贴近现实物体或参考图,利用图像线索。
- ② 多视图方法精度高: 利用多视角几何约束,重建精度高、结果可靠。
- ③ 应用场景广泛: 从手机扫描到专业资产创建,满足不同需求。
局限性:
- ① 单视图的固有歧义性: 结果依赖先验和“猜测”,几何精度/可靠性有限,易出错。
- ② 对输入图像质量和视角的要求: 多视图方法需高质量、光照均匀、纹理丰富、视角分布合理的图像,相机位姿需准确。
- ③ 处理复杂材质和结构的挑战: 透明、高反光、无纹理、精细结构(头发、薄纱)仍是难点(KIRI Engine 等尝试解决)。
- ④ 输出质量与可用性问题: 生成模型(尤其单视图)也可能存在拓扑混乱、UV 不佳、材质不理想等问题,需后处理。
- ⑤ 计算成本: 高质量多视图重建(尤其 NeRF 训练/渲染)需较高计算资源和时间(Instant-NGP, GS 等已加速)。
4️⃣ 代表性技术/模型/工具与讨论
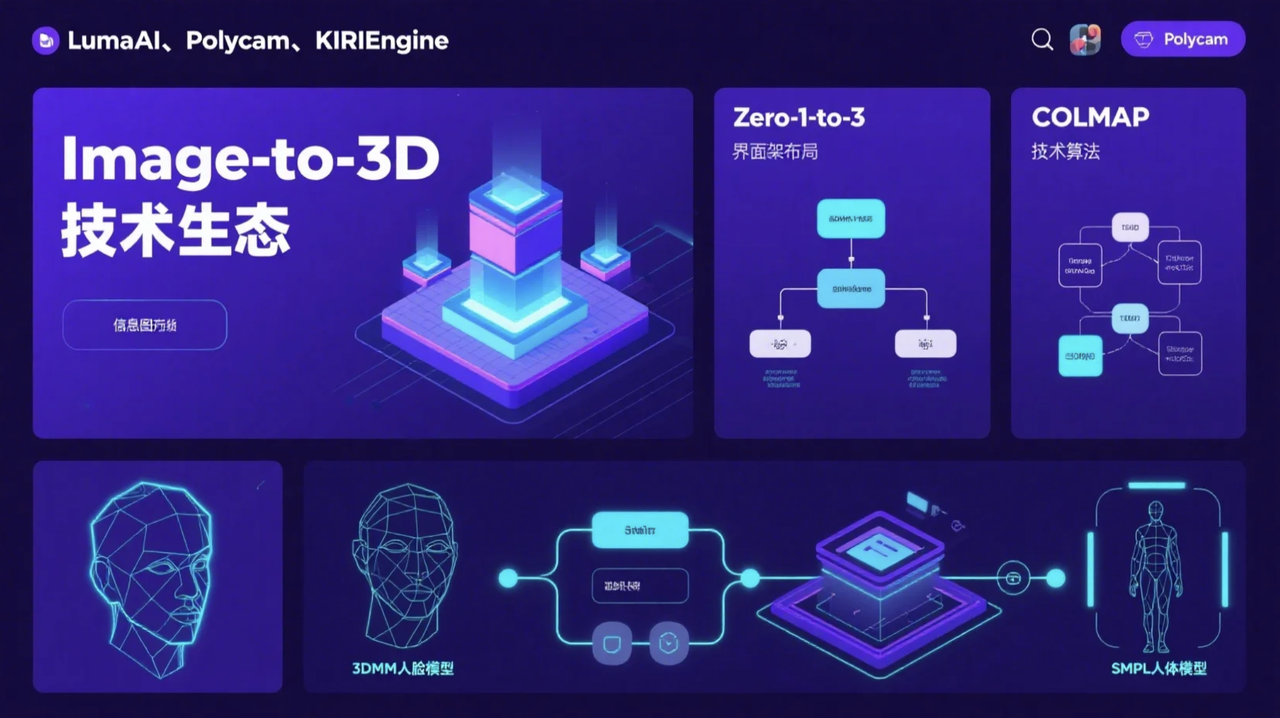
① 单视图重建/生成 (Single-View Reconstruction/Generation):
基于 2D 扩散先验 (2D Diffusion Priors):
Zero-1-to-3: Zero-shot One Image to 3D Object
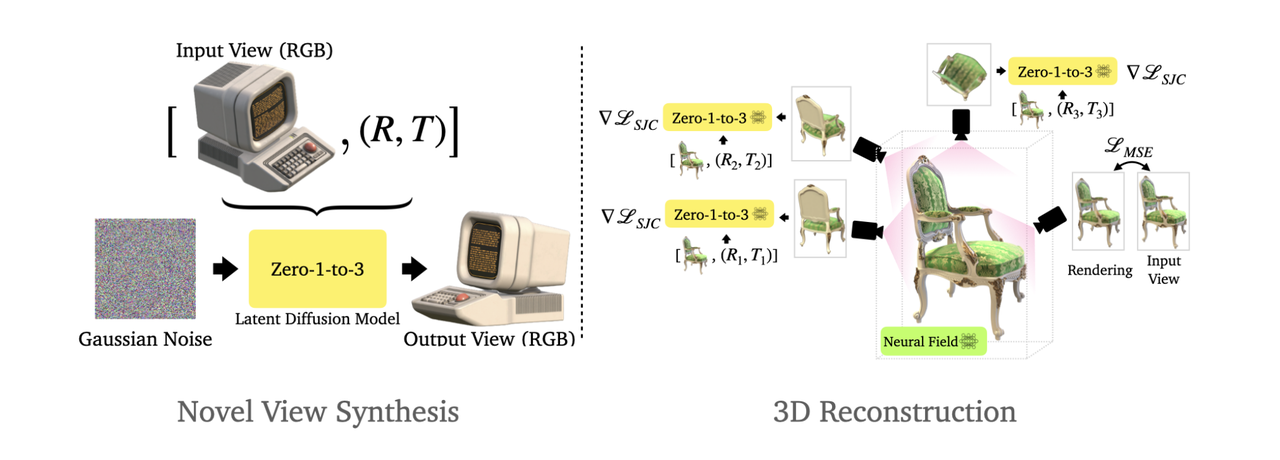
(来源: https://zero123.cs.columbia.edu , GitHub)
SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
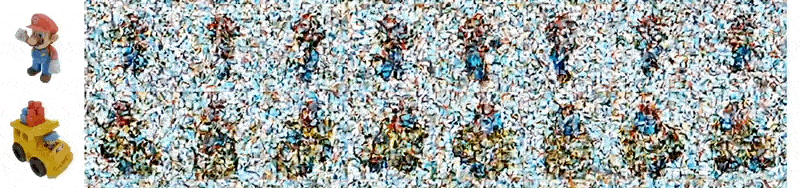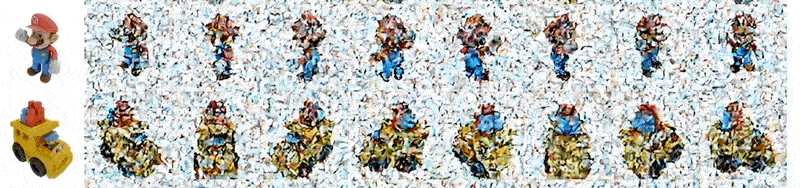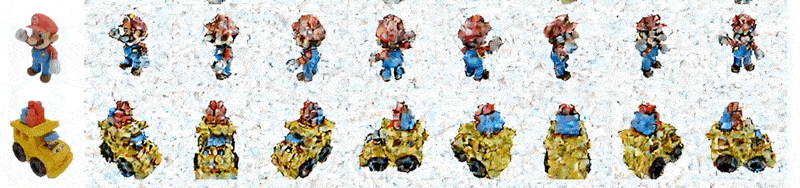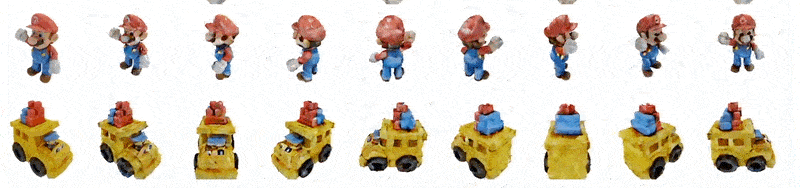
(来源:https://liuyuan-pal.github.io/SyncDreamer/)
Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors
(来源:https://openreview.net/pdf?id=0jHkUDyEO9)
早期直接预测 (Early Direct Prediction):
Pix2Vox: Context-aware 3D Reconstruction from Single and Multi-view Images
(来源:https://arxiv.org/abs/1901.11153)
Mesh R-CNN: Mesh R-CNN
(来源:https://arxiv.org/abs/1906.02739)
② 多视图重建 (Multi-View Stereo – MVS):
传统方法代表 (Traditional Representatives):
COLMAP: Structure-from-Motion and Multi-View Stereo Pipeline

(来源:https://colmap.github.io/ , GitHub)
Meshroom: Open-Source 3D Reconstruction Software
(来源:https://alicevision.org/#meshroom)
NeRF/Gaussian Splatting 应用 (NeRF/GS Applications):
NeRF for MVS: BoostMVSNeRFs: Boosting MVS-based NeRFs to Generalizable View Synthesis in Large-scale Scenes
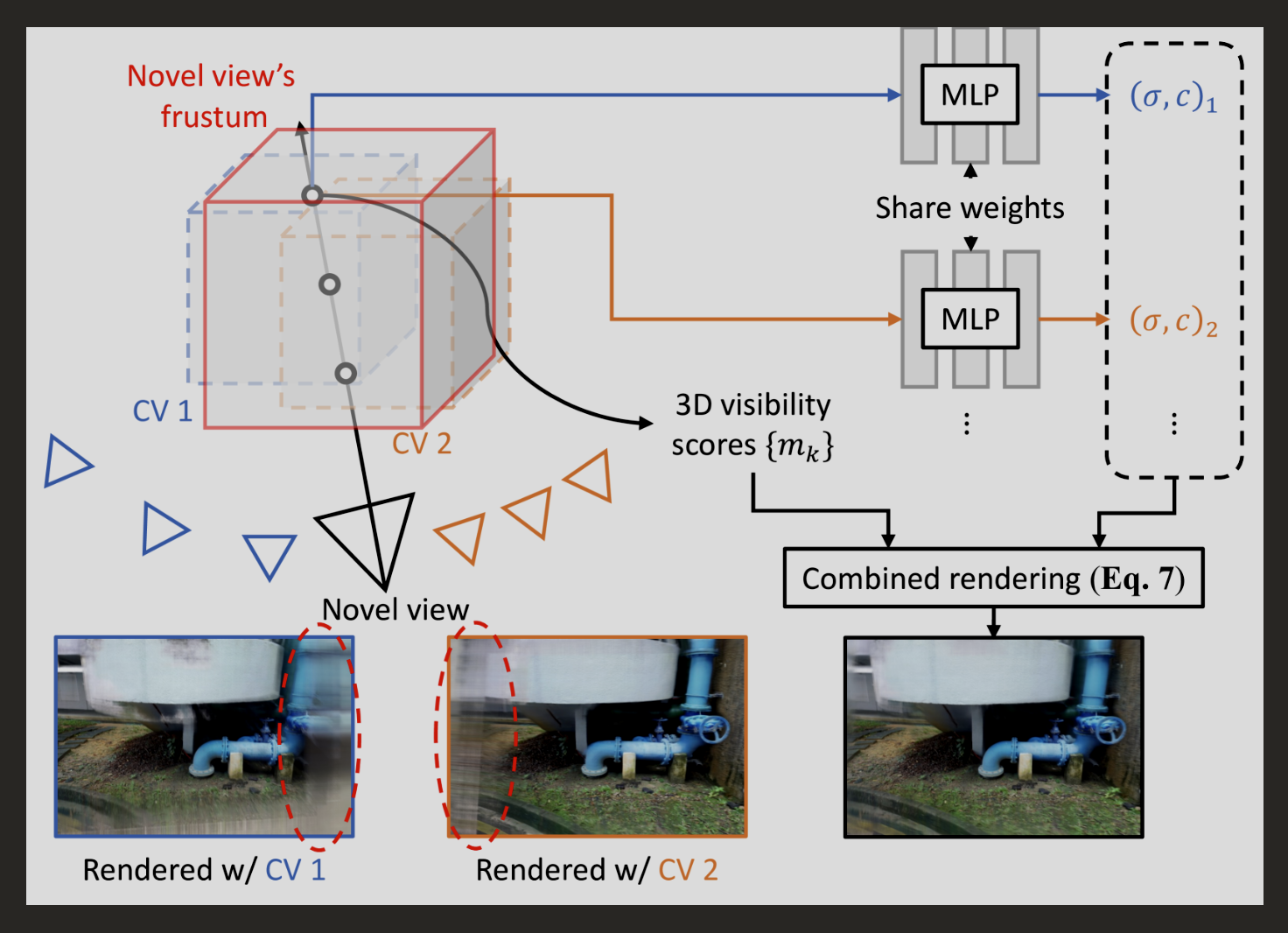
(来源:https://arxiv.org/abs/2407.15848)
Gaussian Splatting for MVS: MVS-GS: High-Quality 3D Gaussian Splatting Mapping via Online Multi-View Stereo
(来源:https://arxiv.org/abs/2412.19130)
GaussianPro: 3D Gaussian Splatting with Progressive Propagation
(来源:https://arxiv.org/abs/2402.14650)
③ 代表性工具/应用 (Representative Tools/Apps):
Luma AI: AI for Realistic 3D
(来源:https://lumalabs.ai/ )
Polycam: 3D Capture for Everyone

(来源:https://poly.cam/)
KIRI Engine: 3D Scanner App for iPhone, Android, and Web
(来源:https://www.kiriengine.app/)
CSM (Common Sense Machines): AI for 3D Asset Creation
(来源:https://www.csm.ai/ , https://3d.csm.ai/)
④ 特定类别重建 (Category-Specific Reconstruction):
3DMM (Faces) Review: 3D Face Reconstruction Based on A Single Image: A Review
SMPL (Bodies) Paper: SMPL: A Skinned Multi-Person Linear Model
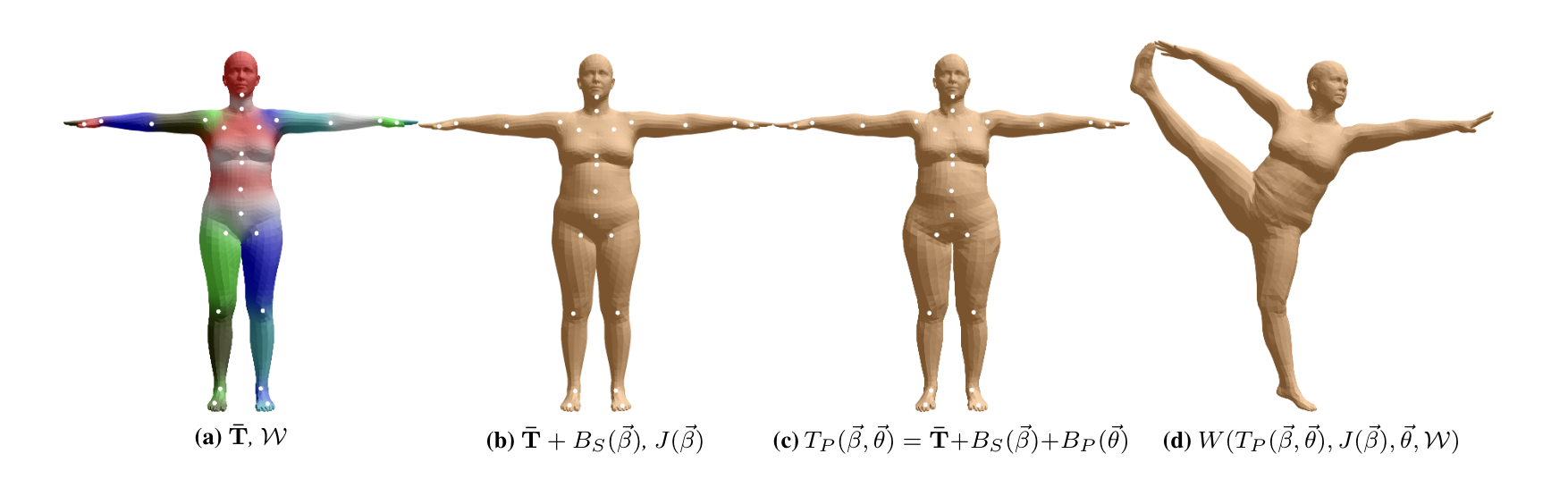
(来源:https://files.is.tue.mpg.de/black/papers/SMPL2015.pdf)
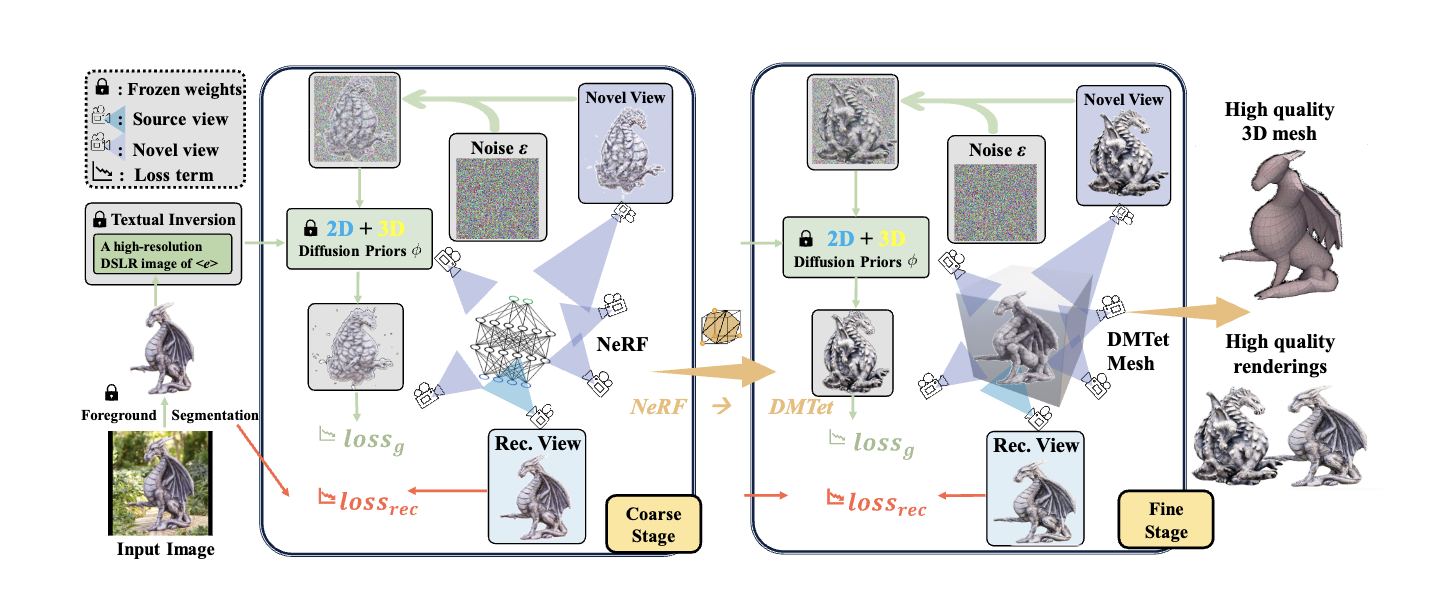
三、 NeRF (神经辐射场):超越几何,表示与渲染场景的新范式
虽然我们在前面讨论 Image-to-3D 时已经多次提及 NeRF,但它本身足够重要和独特,值得单独作为一个技术方向来理解。NeRF(Neural Radiance Fields)的核心贡献并不仅仅在于 3D 重建本身,更在于它提出了一种全新的、基于神经网络的、连续的三维场景表示方法,并能通过可微分的体积渲染技术生成极其逼真的新视图图像。它代表了从传统的离散几何表示(如网格、点云)向基于学习的隐式函数表示的重大转变。
1️⃣ 核心思想:用 MLP “记住”光线
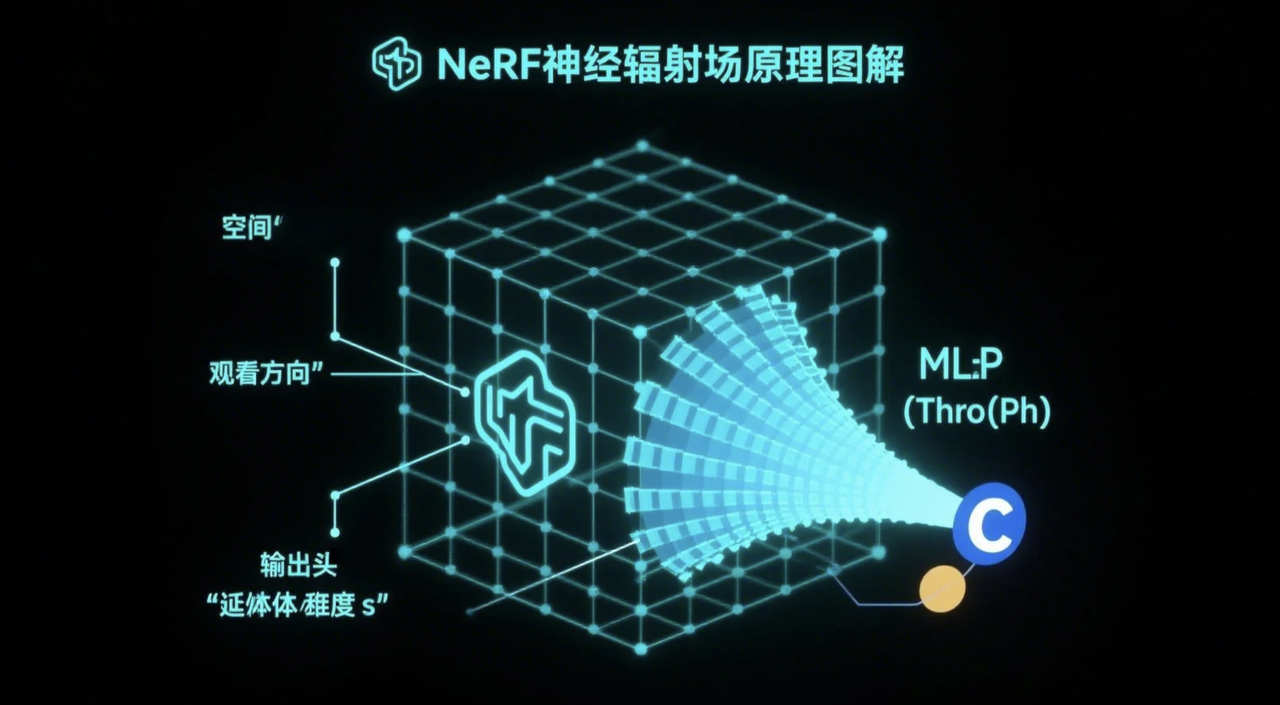
① 隐式表示: NeRF 用一个 MLP 神经网络隐式表示整个三维场景,而非离散几何。
② MLP 输入: 5 维向量 = 空间点坐标 (x,y,z) + 观察方向 (θ,ϕ) 或 (dx,dy,dz)。
③ MLP 输出: 该点在该方向下的物理量:
- 体积密度 (Volume Density, σ): 表示点的不透明度或光线吸收/散射概率。
- 颜色 (Color, c): 点在该方向呈现的颜色 (RGB),通常与视角相关 (View-dependent),以模拟高光、反射等。
④ 场景编码: 整个场景的几何与外观被编码在 MLP 的权重参数中,网络“记住”了每点对不同方向光线的响应。
2️⃣ 渲染过程:可微分体积渲染

- ① 模拟光线传播: 从虚拟相机为每个像素发射光线穿过 MLP 定义的体积场。
- ② 采样: 沿光线在近/远端边界间采样一系列 3D 点。
- ③ 查询 MLP: 将采样点坐标和光线方向输入 MLP,得到密度 σ 和颜色 c。
- ④ 体积渲染方程: 根据光路上所有采样点的密度和颜色,计算光线最终形成的像素颜色,考虑光线被遮挡的累积效应。
- ⑤ 关键特性:可微分: 整个渲染流程(MLP 查询 -> 体积渲染)完全可微分。
- ⑥ 意义: 可计算渲染图像与真实图像损失对 MLP 权重的梯度,从而通过反向传播和梯度下降优化网络。
3️⃣ 训练过程:从多视图图像学习
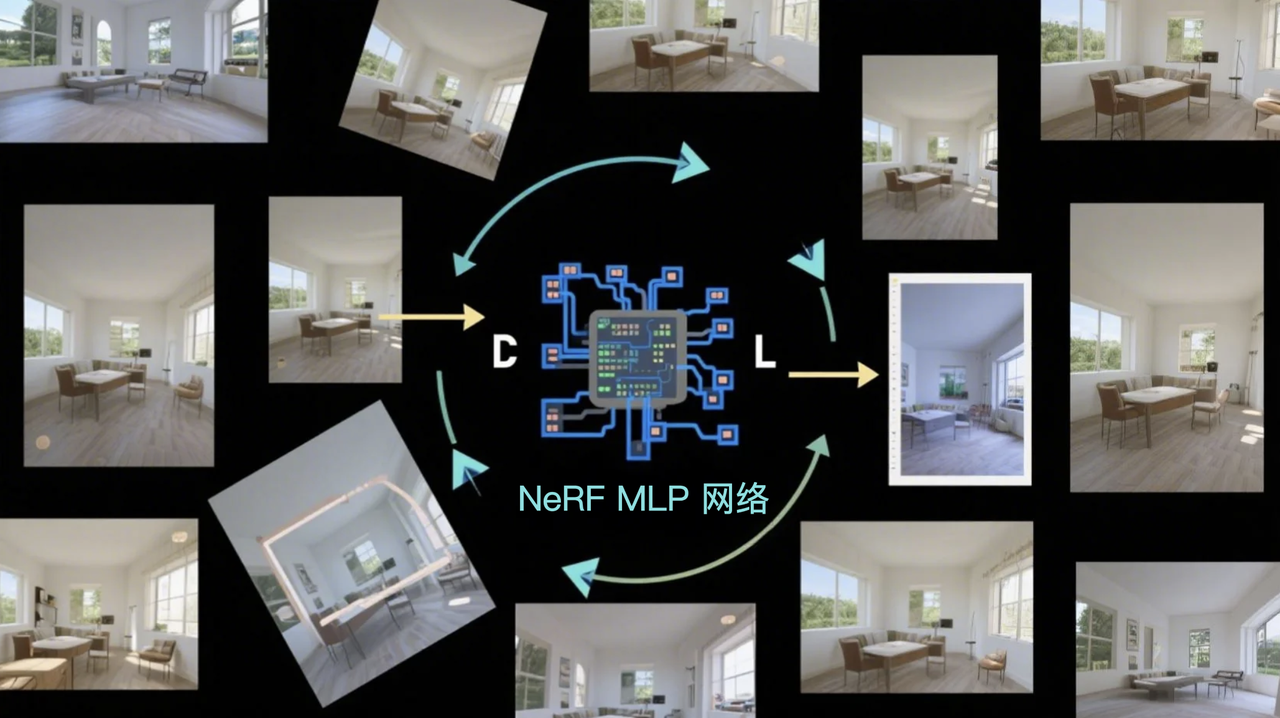
① 输入: 一组已知精确相机参数(内外参)的多视图图像。
② 目标: 训练 MLP,使其对任意给定视角渲染的图像尽可能与真实图像一致。
③ 方法: 随机梯度下降 (或 Adam)。
- 迭代过程: 随机采样像素光线 -> 沿光线采样 3D 点 -> MLP 查询密度颜色 -> 体积渲染得预测颜色 -> 计算预测与真实颜色的损失 (L2 loss) -> 反向传播计算梯度 -> 优化器更新 MLP 权重。
- 重复: 大量迭代直至收敛。
④ 技巧:
- 位置编码 (Positional Encoding): 帮助 MLP 学习高频细节。
- 层级体积采样 (Hierarchical Volume Sampling): 先粗采样再精采样,提高效率和质量。
4️⃣ NeRF 在 AI+3D 中的角色与应用
① 高质量三维重建 (Implicit MVS): SOTA 方法之一,擅长处理复杂光照、精细几何、反射、透明等,生成逼真结果。
② 新视图合成 (Novel View Synthesis, NVS): 核心应用,从任意新视角渲染逼真、连贯的图像,用于 VR/AR、特效预览、虚拟旅游、自由视角视频等。
③ 作为 Text-to-3D / Image-to-3D 的中间表示: 因其连续、可微特性,适合基于优化 (如 SDS) 的生成方法,许多生成方法输出 NeRF 或类似表示,需后续提取 Mesh。
④ 场景编辑与操纵: 后续研究探索对 NeRF 进行编辑。
- 代表: NeRF-Editing (通过代理几何变形), NeRFshop (cage-based 变形), Instruct-NeRF2NeRF (文本指令+2D 编辑模型指导), ED-NeRF (LDM 潜空间编辑)。
- 意义: 使 NeRF 不仅能“看”,还能被“修改”。
⑤ 动态场景表示: 扩展 NeRF 处理时变场景。
- 代表: D-NeRF (时间作输入+变形场), Nerfies (每帧变形潜码+连续变形场)。
- 目标: 重建和渲染含非刚性运动的动态场景。
5️⃣ 优势与局限性 (产品视角)

优势:
- ① 无与伦比的渲染质量: 照片级真实感,视角连贯,细节还原好。
- ② 处理复杂光学现象: 对高光、反射、透明等表现力好。
- ③ 连续表示: 避免离散表示的拓扑问题和分辨率限制,理论上可表示任意细节。
- ④ 紧凑表示: MLP 网络权重通常比密集体素或高精度点云小。
局限性:
- ① 训练速度慢: 标准 NeRF 耗时(小时/天级),虽有加速技术 (Instant-NGP, GS 等) 将其缩短至分钟/秒级,但复杂场景或极致质量仍可能慢。
- ② 渲染速度: 实时 (>30 FPS) 高质量渲染仍有挑战,需较多计算资源。GS 等显式方法在这方面突破显著。
- ③ 编辑性仍受限: 相比传统 Mesh 编辑,对隐式 NeRF 进行同等级别编辑仍困难,现有方法在通用性、精度、易用性上有差距。
- ④ 难以直接用于物理模拟等: 不直接提供显式表面,难用于碰撞检测、物理模拟、3D 打印等,需先提取 Mesh(可能引入误差)。
- ⑤ 泛化能力与场景范围: 标准 NeRF 针对单场景优化,难泛化。处理大/无界场景需特殊设计 (Mip-NeRF 360)。
6️⃣ 代表性技术/模型/工具与讨论
① 核心论文 (Core Paper):
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (Mildenhall et al., ECCV 2020)

(来源:http://www.matthewtancik.com/nerf)
② 重要改进工作 (Key Improvements):
加速训练/渲染 (Acceleration):
Instant-NGP: Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (Müller et al., SIGGRAPH 2022)

(来源:https://arxiv.org/abs/2201.05989 , https://nvlabs.github.io/instant-ngp/ )
Gaussian Splatting: 3D Gaussian Splatting for Real-Time Radiance Field Rendering (Kerbl et al., SIGGRAPH 2023)
(来源:https://www.researchgate.net/publication/372989904_3D_Gaussian_Splatting_for_Real-Time_Radiance_Field_Rendering , GitHub)
编辑性 (Editability):
NeRF-Editing: Geometry Editing of Neural Radiance Fields

(来源:https://github.com/IGLICT/NeRF-Editing , arXiv:2205.04978)
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
(来源: https://instruct-nerf2nerf.github.io/ ,arXiv:2303.12789)
动态场景 (Dynamic Scenes):
D-NeRF: Neural Radiance Fields for Dynamic Scenes
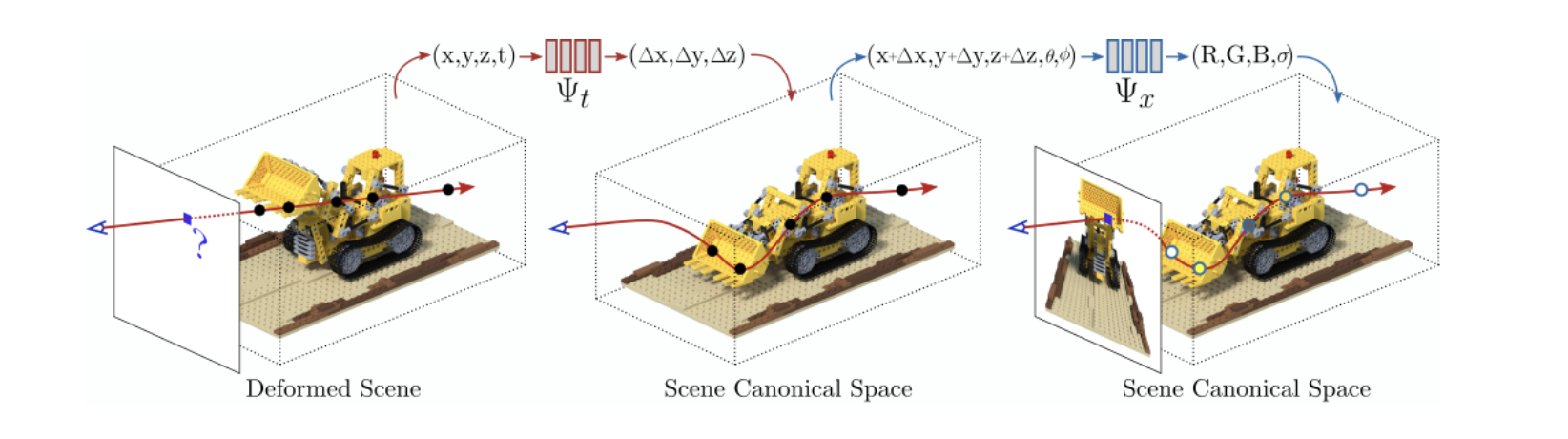
(来源: https://www.albertpumarola.com/research/D-NeRF/index.html ,arXiv:2011.13961, GitHub)
Nerfies: Deformable Neural Radiance Fields
(来源: https://nerfies.github.io/ ,arXiv:2011.12948, GitHub)
③ 应用平台/工具 (Application Platforms/Tools):
Nvidia Instant-NGP: Open-Source Implementation
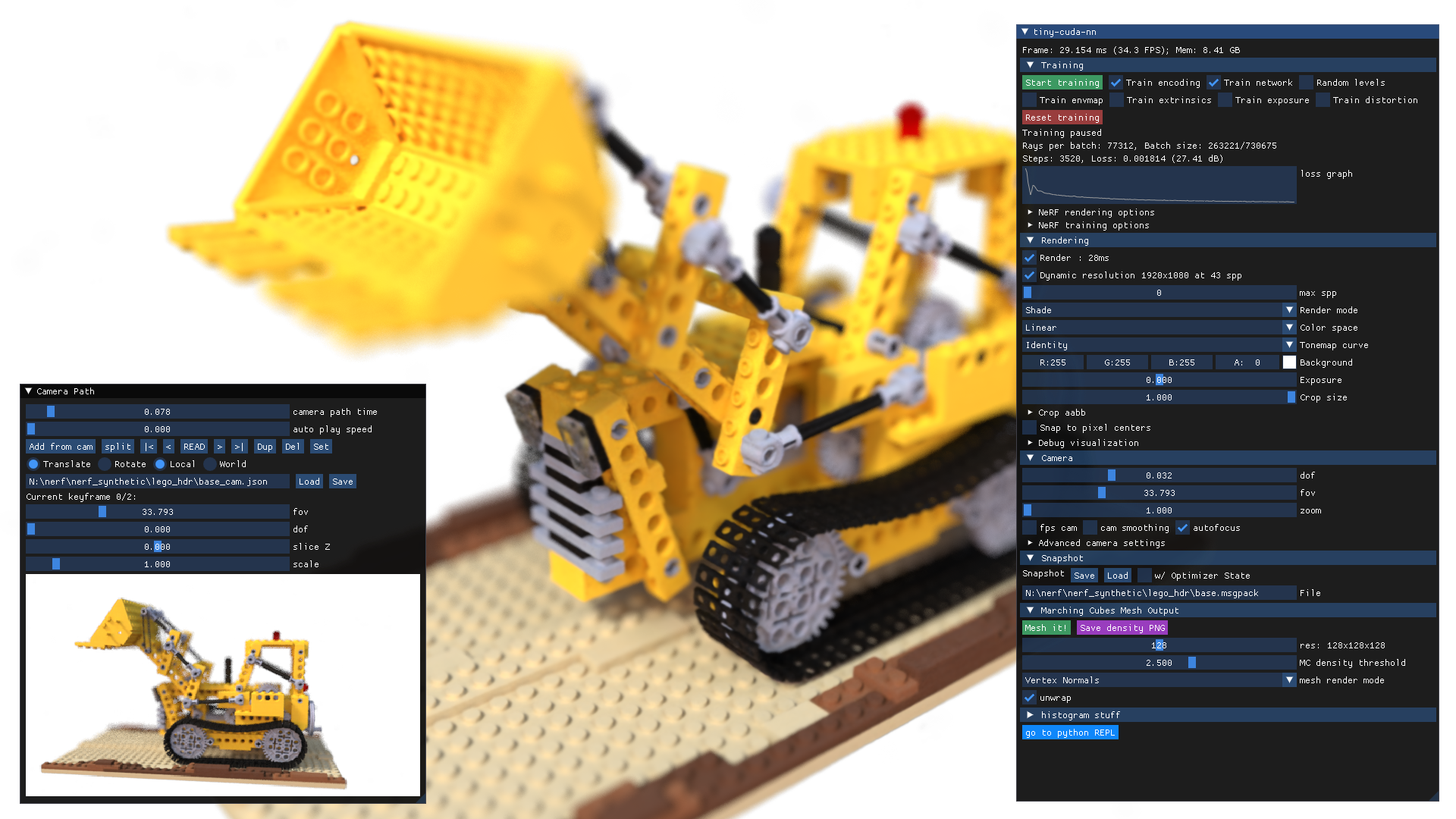
(来源:https://github.com/NVlabs/instant-ngp )
四、 其他值得关注的技术方向与趋势
除了上述三大主流方向(Text-to-3D, Image-to-3D, NeRF),AI 生成 3D 领域还有一些其他值得关注的技术路径和发展趋势,它们可能代表了未来的重要方向或补充了现有技术的不足。
1️⃣ Sketch-to-3D (草图到三维)

目标: 用户通过绘制 2D 草图(轮廓、结构线、颜色提示)引导 AI 生成 3D 模型。
优势:
- 输入直观: 对擅长绘画或习惯草图表达的用户更直观,更能表达空间形态。
- 交互性强: 可通过修改草图迭代调整 3D 结果,实现更精细控制。
- 挑战:
- 理解意图: AI 需理解草图几何意图和风格,并合理“膨胀”到 3D。
- 处理歧义: 如何处理手绘线条歧义(边缘/轮廓/细节?)、从稀疏线条推断完整形状是难点。
应用: 概念设计、教育、创意娱乐(快速动画角色)。
- 代表: Sketch2Model (从单草图生成视点感知模型), Google Monster Mash (绘制 2D 部件“充气”成可动 3D 模型)。
2️⃣ 3D-aware Generative Models (感知三维的生成模型)

目标: 让生成模型 (GANs, Diffusion) 在生成 2D 图像时就具备“三维意识”,生成的 2D 图隐含合理且一致的 3D 结构。
方法:
- 架构设计: 在生成器中间层引入 3D 表示 (NeRF, 体素, 带纹理 Mesh),再通过可微渲染生成 2D 图。
- 损失函数: 设计损失鼓励生成结果在不同视角保持 3D 一致性。
意义:
- 生成的 2D 图像因内在 3D 一致性,更易用于后续 3D 重建/编辑。
- 可从生成图像直接提取对应的 3D 模型和纹理,保证视图一致性。
代表性工作:
- EG3D (Nvidia): 混合三平面表示+StyleGAN2,生成高分辨率、多视图一致图像和高质量 3D 几何。
- GET3D (Nvidia): 直接生成显式、带纹理的 3D 网格,输出可直接用于渲染引擎。
- StyleSDF: 结合 SDF (3D 表示) 和 StyleGAN2 (2D 生成器),旨在同时实现高分辨率图像和精细 3D 形状。
3️⃣ 多模态融合与交互式生成
趋势: 结合多种输入模态(文本、图像、草图、语音、手势等),提供更丰富、自然、精确的控制。生成过程更交互式,用户与 AI 持续对话、指导、共创,实时调整。
驱动力:
- 解决单一模态局限: 文本难描几何,草图难表材质。
- 提升可控性: 弥补当前生成模型可控性差的问题。
- 市场趋势: AI 领域向多模态发展;内容创作中 AI 从自动化工具变协作伙伴,交互性更重要。
4️⃣ 代表性技术/模型/工具与讨论

① Sketch-to-3D:
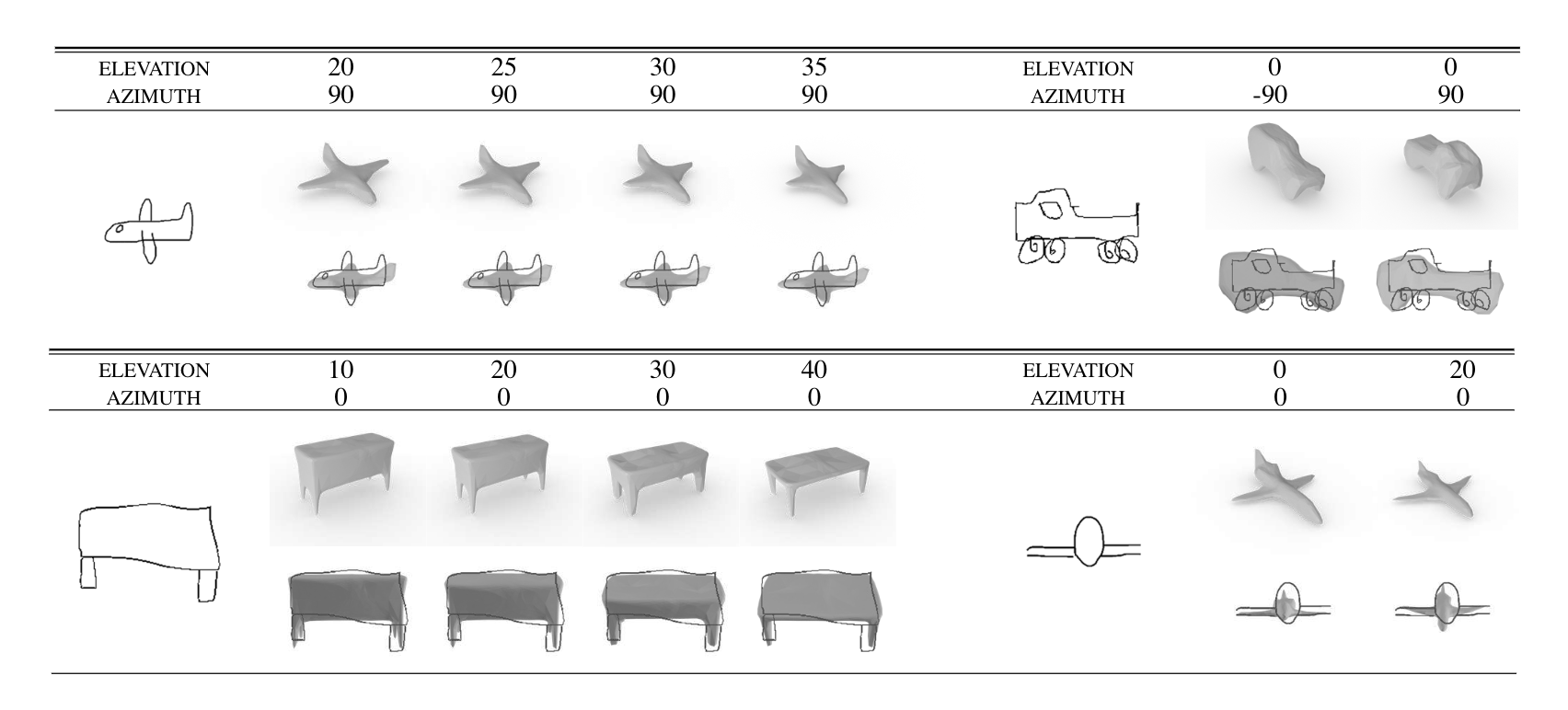
Sketch2Model: View-Aware 3D Modeling from Single Free-Hand Sketches (arXiv:2105.06663)
Google Monster Mash: Sketch-Based Modeling and Animation Tool
(来源:https://monstermash.zone/# Demo, GitHub, https://research.google/blog/monster-mash-a-sketch-based-tool-for-casual-3d-modeling-and-animation/)
② 3D-aware Generative Models:
EG3D: Efficient Geometry-aware 3D Generative Adversarial Networks

(来源: https://nvlabs.github.io/eg3d/ arXiv:2112.07945, GitHub)
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
(来源:https://research.nvidia.com/labs/toronto-ai/GET3D/ , https://proceedings.neurips.cc/paper_files/paper/2022/file/cebbd24f1e50bcb63d015611fe0fe767-Paper-Conference.pdf, GitHub)
StyleSDF: High-Resolution 3D-Consistent Image and Geometry Generation
(来源: https://stylesdf.github.io/ ,arXiv:2112.11427, GitHub)
③ 多模态/交互式生成趋势 (Multimodal/Interactive Trends):
Multimodal AI Market Analysis: Multimodal AI Market Size & Share Report, 2030
Multimodal AI: Everything You Need to Know
(来源:https://www.superannotate.com/blog/multimodal-ai)
结语:理解光谱,拥抱多元
通过本篇笔记的梳理,我们对当前 AI 生成 3D 的主流技术流派——Text-to-3D 的“语言召唤”、Image-to-3D 的“视觉还原”、NeRF 的“光场记忆”以及其他如 Sketch-to-3D 的交互探索——有了更清晰的认识。我们看到,每种技术路径都有其独特的优势、局限和最适宜的应用场景,它们共同构成了 AI+3D 技术的“光谱”。
Text-to-3D 以其极低的创作门槛和近乎无限的创意可能性,在快速概念设计和大规模个性化内容生成方面展现出巨大潜力。然而,现阶段其输出质量的稳定性和精度,以及对生成结果的精细控制能力,仍然是亟待突破的瓶颈。
Image-to-3D 则更侧重于从现有的视觉信息中恢复三维结构。其中,基于多视图输入的方法(特别是结合 NeRF 或 Gaussian Splatting)在重建精度和视觉真实感上表现突出,是推动 3D 扫描和现实世界数字化的重要力量;而单视图方法则在利用强大的 AI 先验知识进行“脑补”式生成方面不断取得进步,尤其是在 Zero-1-to-3 等利用 2D 扩散先验的技术出现后。
NeRF 作为一种革命性的场景表示与渲染技术,不仅极大地推动了高保真三维重建的发展,也因其可微性而成为了许多 AI 生成方法(如 SDS)的底层表示支撑。其在新视图合成和处理复杂光学现象方面的优势无与伦比,但训练与渲染效率、以及直接编辑性仍然是其广泛应用面临的挑战,尽管 Instant-NGP、Gaussian Splatting 和 NeRF 编辑等研究正在积极应对。
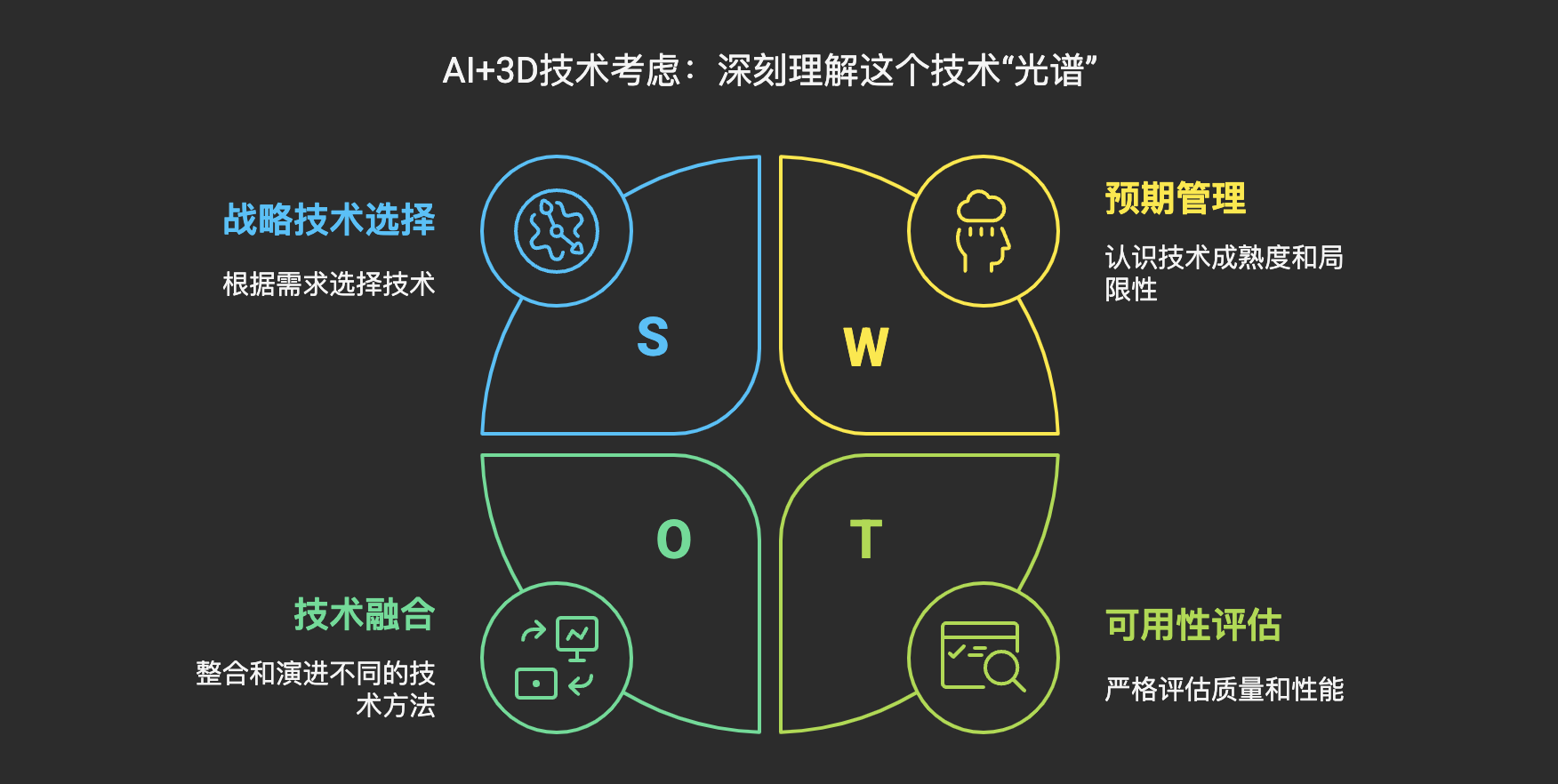
作为 AI+3D 领域的产品经理或从业者,深刻理解这个技术“光谱”至关重要。这意味着我们需要:
- 避免“一刀切”思维: 根据产品目标、用户需求、场景及对质量/速度/成本/可控性要求,审慎选择技术路径或组合。
- 科学管理预期: 清晰认识技术成熟度、能力边界和局限,传递准确预期,避免过度承诺。
- 关注融合与演进: 不同流派在相互借鉴融合,持续关注前沿研究和技术趋势。
- 聚焦最终“可用性”: 严格评估生成结果质量(几何、拓扑、UV、材质)和性能,考虑后处理工作量,判断产品价值。
在接下来的笔记中,我们将开始更深入地钻研这些技术背后的核心机制和挑战,例如 NeRF 的具体工作原理、面临的挑战及加速方法(S2E04 预告),Diffusion Model 如何作为强大的先验驱动 3D 内容生成(S2E05 预告),以及如何建立一套科学的评估体系来衡量 AI 生成 3D 模型的“可用性”(S2E08 预告)。理解了这些基础技术流派及其特点,我们将能更好地把握 AI+3D 领域未来的发展脉络和涌现的产品机遇。
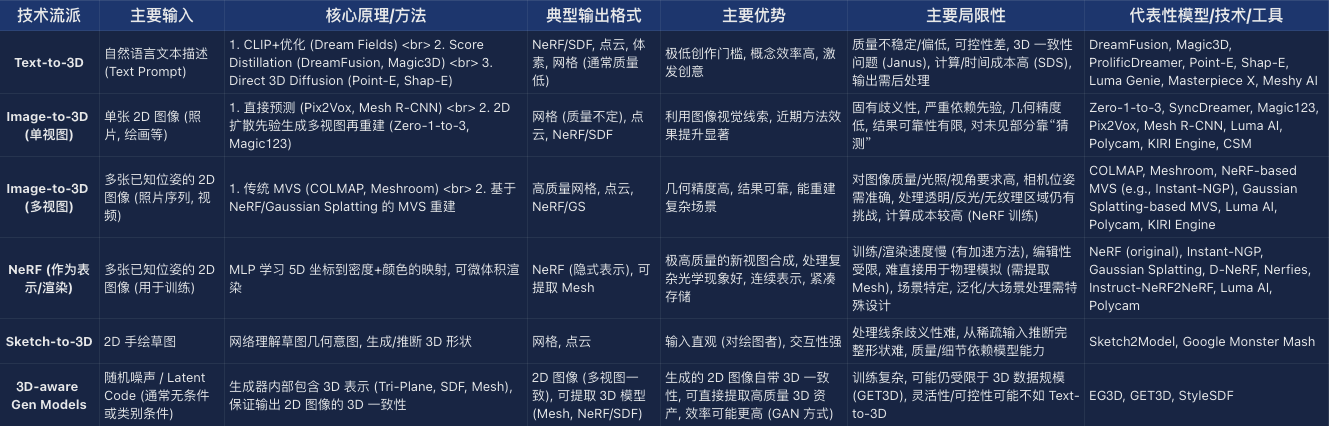
附录:主流 AI 生成 3D 技术流派对比概览
本文由人人都是产品经理作者【Mu先生Ai世界】,微信公众号:【Mu先生Ai世界】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图由作者提供