机器学习最强入门总结,看这篇就够了
在人工智能迅速发展的当下,机器学习作为实现AI的核心技术路径,正吸引着越来越多的关注。本文为机器学习的初学者提供了一份全面的入门总结,从机器学习的基本概念、发展历程、核心原理到不同学习类型的分类和应用场景,进行了深入浅出的讲解。

近两年来 AI 产业已然成为新的焦点和风口,各互联网巨头都在布局人工智能,不少互联网产品经理也开始考虑转型 AI 产品经理,入门AI产品经理,或许你应该了解一些技术,本文将为你详细介绍机器学习
机器学习(Machine Learning, ML)与人工智能(Artificial Intelligence, AI)是技术演进中密不可分的两个概念
机器学习是实现人工智能的核心技术路径,而人工智能是机器学习的终极目标。
本文将为你详细介绍机器学习
一、基本概念
机器学习(Machine Learning, ML)是教会计算机从数据中自动发现规律,并利用这些规律进行预测或决策的技术。
简单来说,就是让机器像人类一样“学习经验”,而无需被明确编程每一步该怎么做。
机器学习不是某种具体的算法,而是很多算法的统称。机器学习包含了很多种不同的算法,深度学习就是其中之一,这些算法能够让计算机自己在数据中学习从而进行预测。无论使用什么算法,使用什么样的数据,最根本的思路都逃不出下面的3步!
机器学习的基本思路如下:
- 把现实生活中的问题抽象成数学模型,并且很清楚模型中不同参数的作用
- 利用数学方法对这个数学模型进行求解,从而解决现实生活中的问题
- 评估这个数学模型,是否真正的解决了现实生活中的问题,解决的如何?

其中,最难的部分也就是把现实问题转换为数学问题这一步
二、发展历程和关键阶段
(1)萌芽阶段(1950s-1960s)
以塞缪尔的下棋程序为代表,首次验证机器可通过学习提升能力,但局限于简单任务。
(2)知识驱动阶段(1960s-1970s)
研究者尝试将人类知识植入系统,但受限于知识表示和获取难度
(3)复兴阶段(1970s-1980s)
机器学习与专家系统结合,示例归纳学习成为主流,国际会议和期刊的诞生推动学科发展
*(4)大数据与深度学习时代(2000s至今)
随着算力和数据量爆发,深度学习(如AlexNet)在图像识别、自然语言处理等领域实现突破,推动自动驾驶、医疗诊断等应用落地
三、机器学习的基本原理
下面以监督学习为例,给大家讲解一下机器学习的实现原理。
假如我们正在教小朋友识字(一、二、三)。
我们首先会拿出3张卡片,然后便让小朋友看卡片,一边说“一条横线的是一、两条横线的是二、三条横线的是三”。
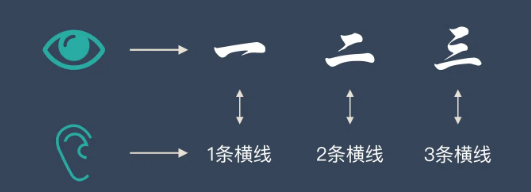
不断重复上面的过程,小朋友的大脑就在不停的学习。
当重复的次数足够多时,小朋友就学会了一个新技能——认识汉字:一、二、三。
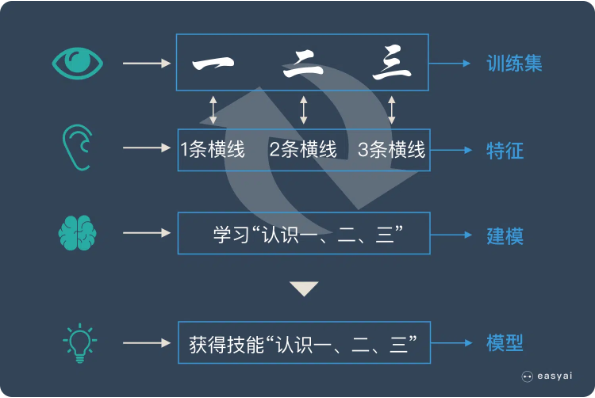
我们用上面人类的学习过程来类比机器学习。
机器学习跟上面提到的人类学习过程很相似。
- 上面提到的认字的卡片在机器学习中叫——训练集
- 上面提到的“一条横线,两条横线”这种区分不同汉字的属性叫——特征
- 小朋友不断学习的过程叫——建模
- 学会了识字后总结出来的规律叫——模型
通过训练集,不断识别特征,不断建模,最后形成有效的模型,这个过程就叫“机器学习”!
四、分类
机器学习常见的10个学习类型如下

其核心逻辑都是根据数据条件 (标注、规模、分布)、任务需求 (实时性、多任务、跨领域)和资源限制 (计算、隐私)选择合适方法。
其中,基础学习类型 (监督/无监督/强化学习)解决大多数传统问题,进阶学习类型突破数据、隐私、动态环境等限制。
1. 监督学习
监督学习是指我们给算法一个数据集,并且给定正确答案。机器通过数据来学习正确答案的计算方法。
其中,数据有明确的标签,其学习方式是根据输入(特征)和输出(标签)的关系,建立一个预测模型。
(1)典型任务
- 分类(预测类别):判断肿瘤是良性还是恶性。
- 回归(预测数值):预测房价、气温。
(2)常见算法
线性回归、决策树、支持向量机(SVM)、神经网络
(3)举例
我们准备了一大堆猫和狗的照片,我们想让机器学会如何识别猫和狗。
当我们使用监督学习的时候,我们需要给这些照片打上标签。
我们给照片打的标签就是“正确答案”,机器通过大量学习,就可以学会在新照片中认出猫和狗。
2. 非监督学习
非监督学习中,给定的数据集没有“正确答案”,所有的数据都是一样的。
无监督学习的任务是从给定的数据集中,挖掘出潜在的结构。
其中,数据没有标签,其学习方式是发现数据中的隐藏规律或结构(比如分组、简化数据)。
(1)典型任务
- 聚类(Clustering):把用户按购买行为分成不同群体。
- 降维(Dimensionality Reduction):将高维数据压缩成2D/3D可视化。
- 关联分析:发现超市商品之间的购买关联(如啤酒和尿布)。
(2)常见算法
K-Means、PCA(主成分分析)、Apriori。
(3)举例
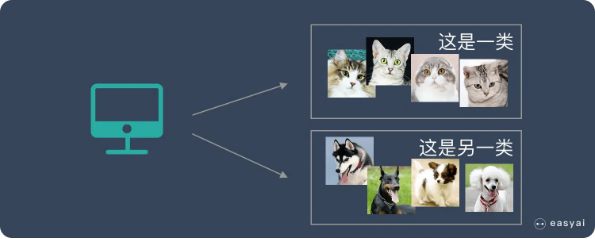
我们把一堆猫和狗的照片给机器,不给这些照片打任何标签,但是我们希望机器能够将这些照片分分类
通过学习,机器会把这些照片分为2类,一类都是猫的照片,一类都是狗的照片。
虽然跟上面的监督学习看上去结果差不多,但是有着本质的差别:
非监督学习中,虽然照片分为了猫和狗,但是机器并不知道哪个是猫,哪个是狗。
对于机器来说,相当于分成了 A、B 两类。
3. 强化学习
关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。
通过强化学习,一个智能体应该知道在什么状态下应该采取什么行为。
其中,没有现成的数据,而是通过与环境互动获得反馈(奖励/惩罚),其学习目标是找到最优策略(Policy),让智能体(Agent)在环境中获得最大累积奖励。
(1) 核心要素
- 环境 (如游戏世界、自动驾驶场景)
- 动作 (Agent的行为,如踩油门、左转)
- 奖励 (如得分增加、避免碰撞)
(2)典型任务
游戏AI(如AlphaGo)、机器人控制、自动驾驶。
(3)常见算法
Q-Learning、深度强化学习(DQN)
(4)举例
训练小狗接飞盘:
- 小狗成功接到飞盘 → 给它零食(正向奖励)
- 小狗没接到 → 不给零食(无奖励)
- 小狗逐渐学会“加速奔跑+跳跃”的策略,以最大化获得零食的机会
4. 半监督学习
结合少量标注数据 + 大量无标注数据联合训练,降低标注成本。
(1)典型任务
- 医学影像分析(标注成本高)
- 文本分类(部分文档无标签)
(2)常见算法
- 标签传播(Label Propagation)
- 半监督GAN(生成对抗网络)
- 自训练(Self-training)
(3)举例
训练一个AI模型来自动识别肺部X光片中的肿瘤,但仅有少量标注数据 (如1000张明确标注“正常”或“肿瘤”的X光片)和大量未标注数据 (如10万张未标注的X光片)。
半监督学习通过以下步骤解决标注不足的问题:
①初始模型训练:1000张已标注的X光片(如500张正常、500张肿瘤),用这些标注数据训练一个基础分类模型(如卷积神经网络),学习初步的肿瘤识别规律,例如肿瘤区域的纹理、边缘模糊度等特征
②未标注数据的伪标签生成:将10万张未标注的X光片输入初始模型进行预测,生成伪标签 (即模型预测的“正常”或“肿瘤”结果),仅保留模型预测置信度高的样本(例如预测概率>90%的5万张),作为“伪标注数据”加入训练集,其原理是假设模型对高置信度样本的预测基本正确,通过扩大数据量优化模型对肺部结构的理解
③迭代优化与核心假设:合并初始标注数据和伪标注数据,重新训练模型。重复此过程多次,逐步优化模型性能
④实际应用:最终模型可识别更多复杂病例(如早期肿瘤、微小病灶),准确率显著高于仅使用标注数据训练的模型。
5. 自监督学习
自监督学习属于无监督学习的一种。数据本身没有任务需要的标签。
自监督学习需要人为的构造标签,让模型来学习特征。
(1)典型任务
- 预训练通用表征(如文本、图像)
- 下游任务微调(如问答系统、图像分类)
(2)常见算法
- BERT(掩码语言模型)
- GPT(生成式预训练)
- SimCLR(对比学习)
- MAE(掩码自编码器)
(3)举例
- 文本填空 (如BERT):遮盖句子中的词语,让模型预测被遮部分(如“猫喜欢喝__”预测“牛奶”)。
- 视频帧预测:利用视频相邻帧的连续性,预测下一帧内容。
- 图像着色:将黑白图片输入模型,预测原始颜色分布
6. 多任务学习
同时学习多个相关任务,共享部分模型参数以提高泛化能力
(1)典型任务
- 自动驾驶(同时检测车辆、行人、车道线)
- 自然语言处理(如联合学习命名实体识别和词性标注)
(2)常见算法
- 多任务神经网络(共享底层,任务特定输出层)
- 联合训练Transformer
(3)举例
- 自然语言处理:同时处理文本分类、情感分析、命名实体识别等任务。
- 计算机视觉:同时处理目标检测、图像分割、人脸识别等任务。
- 医疗健康:结合病例诊断、预测疾病风险等多个任务,提供更全面的医疗辅助服务。
- 语音识别:同时处理语音识别、语音情感分析、说话人识别等任务。
7. 在线学习
模型每次接收一个或一小批新数据(如用户点击行为),立即调整参数,无需重新训练整个模型,适应数据分布动态变化。
(1)典型任务
- 实时推荐系统(如新闻、广告)
- 金融风控(如实时检测欺诈交易)
(2)常见算法
- 在线梯度下降(Online Gradient Descent)
- 跟随正则化领导(FTRL)
(3)举例
根据用户实时点击行为调整短视频推荐策略,每小时更新模型。
8. 迁移学习
迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务,解决目标数据不足问题。
迁移学习的灵感来源于人类的学习方式。
例如:会骑自行车的人更容易学会摩托车(两者平衡技巧相似)
其技术本质是通过共享源域和目标域的底层规律(如特征、模型参数),让模型避免从零学习,快速适应新任务
(1)迁移学习的基本问题
- How to transfer: 如何进行迁移学习?(设计迁移方法)
- What to transfer: 给定一个目标领域,如何找到相对应的源领域,然后进行迁移?(源领域选择)
- When to transfer: 什么时候可以进行迁移,什么时候不可以?(避免负迁移)
(2)常见算法
- 预训练模型微调(如ResNet、BERT)
- 特征提取(固定预训练模型,仅训练新分类层)
(3)举例
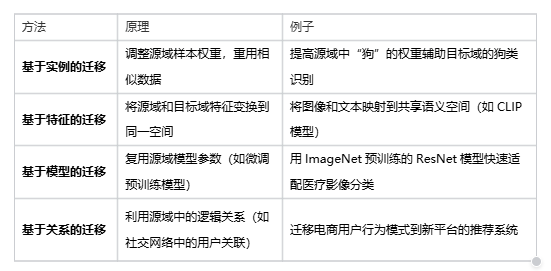
9. 联邦学习
多个设备/机构协同训练模型,数据不离开本地,保护隐私
联邦学习(Federated Learning, FL) 是一种分布式机器学习范式 ,
其核心目标是 在保护数据隐私的前提下,联合多个参与方(如设备、机构或数据孤岛)共同训练模型 ,而无需共享原始数据。
(1)基本流程
- 初始化全局模型 :中央服务器(或协调方)初始化一个基础模型并分发给各参与方。
- 本地训练 :各参与方利用本地数据训练模型,生成模型参数或梯度更新。
- 参数上传与聚合 :参与方将本地模型更新上传至服务器,服务器通过加权平均等方式聚合参数,生成全局模型。
- 迭代优化 :重复上述步骤,直至模型收敛
(2)常见算法
- FedAvg(联邦平均)
- 差分隐私联邦学习(添加噪声保护数据)
(3)举例
- 金融风控 :银行间联合建模反欺诈系统,不共享客户数据。
- 医疗健康 :医院协作训练疾病预测模型,保护患者隐私。
- 智能终端 :手机输入法(如苹果Siri)通过本地数据优化语音识别。
- 自动驾驶 :多车协同训练驾驶模型,提升安全性
10. 元学习
元学习的目标是 学习“如何学习” ,而非直接解决单一任务。
它通过分析多个相关任务的共性(如数据分布、特征关联性等),提取可迁移的元知识(Meta-Knowledge),从而在面对新任务时仅需少量样本即可高效调整模型
(1)主要方法分类
根据知识迁移方式,元学习可分为三类主流方法:
①基于优化的元学习
- 学习一个适用于多任务的模型初始化参数,使模型通过少量梯度更新即可适应新任务
- 无需修改模型结构,通用性强。
②基于度量的元学习
- 学习一个相似性度量空间,通过比较新样本与已知样本的距离进行分类。
- 如少样本图像分类(如清华团队在MetaDL挑战赛中提出的自适应度量方法)
③基于模型的元学习
- 设计具有记忆或注意力机制的模型结构,动态存储和调用任务相关知识。
- 适合处理时序依赖强的任务(如机器人连续决策)
(2)常见算法
- MAML(模型无关元学习)
- Prototypical Networks(原型网络)
(3)举例
机器人在不同地形中调整行走策略
仅需几张新类别图片即可完成图像识别
五、如何选择对应的方法
选择机器学习方法的关键在于平衡数据、任务与资源三角关系,其核心决策原则
- 从数据出发:数据质量与规模决定方法上限。
- 任务驱动:明确目标是分类、聚类还是决策。
- 资源适配:在算力、时间、成本间权衡。
- 迭代优化:从简单方法开始,逐步升级复杂度(如:线性模型 → 树模型 → 神经网络)
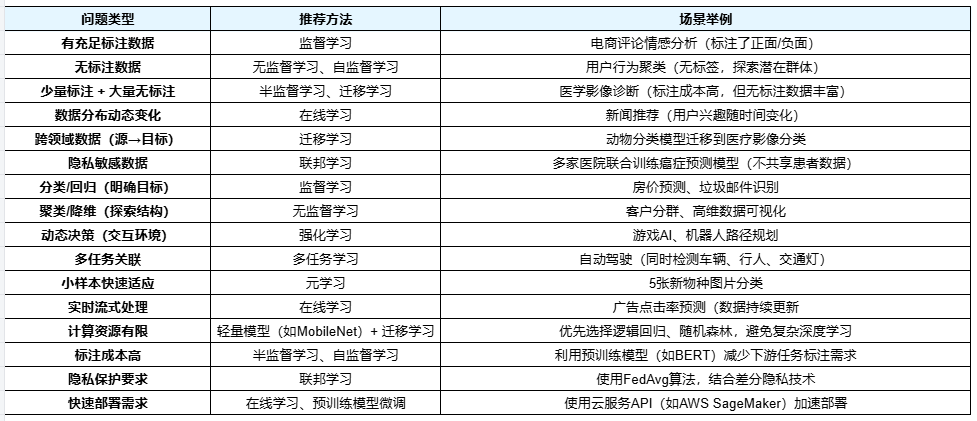
在选择机器学习方法时,可参考以下表格进行选择
六、机器学习实操步骤
机器学习在实际操作层面一共分为7步:收集数据、数据准备、选择一个模型、训练、评估、参数调整、预测

1. 收集数据
获取与问题相关的原始数据(如用户行为记录、传感器数据、图片等)
(1)数据来源
公开数据集(如Kaggle)、爬虫抓取、传感器采集(如摄像头图像)。
(2)常见问题
- 数据量不足(如只有100条样本)
- 数据偏差(如只收集了某地区的房价)
2. 数据准备
清洗数据、处理缺失值、标准化、特征提取等
(1)数据清洗
处理缺失值(如删除缺失行或用平均值填充)、去除重复或错误数据(如年龄字段出现负数)。
(2)特征工程
- 提取特征:从日期中拆分“月份”和“星期几”。
- 转换数据:将文本转为数值(如“男/女”编码为0/1)。
- 标准化:将身高数据从“厘米”统一为“米”。
(3)划分数据集
- 训练集(70%):用于模型学习。
- 验证集(15%):调参时评估效果。
- 测试集(15%):最终考核模型。
3. 选择一个模型
根据问题类型选择算法模型
- 分类任务 (如垃圾邮件识别)→ 逻辑回归、随机森林、神经网络。
- 回归任务 (如房价预测)→ 线性回归、梯度提升树。
- 聚类任务 (如用户分群)→ K-means、层次聚类。
新手建议:从简单模型(如线性回归)开始,再尝试复杂模型(如深度学习)
4. 训练
让模型从数据中学习规律评估
(1)核心过程
- 模型通过调整内部参数(如权重)拟合数据。
- 使用优化算法(如梯度下降)最小化预测误差(损失函数)
(2)关键参数
- 学习率:控制参数调整幅度(太大可能“跳过”最优解,太小训练慢)
- 迭代次数(Epochs) :数据被模型学习的轮次
5. 评估
用测试集验证模型效果,判断模型是否“学得好”
(1)评估指标
- 分类任务:准确率、精确率、召回率、F1分数。
- 回归任务:均方误差(MSE)、R²分数。
- 聚类任务:轮廓系数、类内距离。
(2)验证方法
交叉验证:将数据分成多份,轮流用其中一份作为验证集,提高评估可靠性。
(3)常见问题
- 过拟合:模型在训练集表现好,测试集差(像死记硬背的学生)。
- 欠拟合:训练集和测试集都表现差(没学会规律)。
6. 参数调整
调整模型的超参数(如学习率、树的深度)提升效果
(1)调整内容
- 模型超参数:如神经网络的层数、决策树的深度。
- 训练参数:如学习率、批量大小(Batch Size)。
(2)调参方法
- 网格搜索:遍历所有可能的参数组合,寻找最优解(计算成本高)。
- 随机搜索:随机尝试参数组合,效率更高。
- 自动化工具:如AutoML(自动机器学习)
7. 预测
将训练好的模型投入实际使用
(1)部署方式
封装成API、嵌入到App或硬件设备中。
(2)持续监控
模型上线后可能出现性能下降(如数据分布变化)
七、常见算法
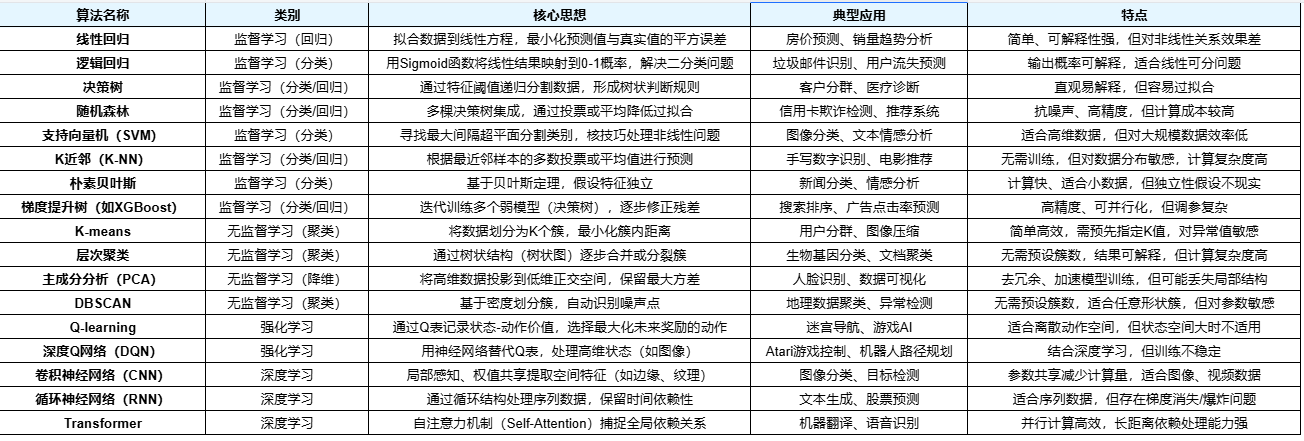
注意,深度学习更多是监督学习的一种延伸,或者属于模型类型而非训练方法
本文由人人都是产品经理作者【诺儿笔记本】,微信公众号:【诺儿笔记本】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。