视觉模型落地:AI打工,干活全自动
随着人工智能技术的不断进步,视觉模型正在从实验室走向实际应用,逐渐改变我们的工作和生活方式。本文将探讨字节跳动最新发布的豆包1.5视觉模型如何实现视觉定位与计数功能,并通过实际案例展示其在图像标注、库存盘点等场景中的应用潜力。尽管目前仍存在一些挑战,但这一技术的进步已经为自动化工作流程带来了新的可能性,预示着AI在更多实际场景中的广泛应用前景。

算一下,一碟 15,这是吃了多少?

答:一共14盘,合计210

AI 是可以拿来做盘点的
方法:AI 数的,容我细细道来
字节发了新模型
今天是字节的发布会,我去了现场。
豆包 1.5 深度思考模型上线,200B MoE,20B 激活参数,R1 级别的性能。

豆包 1.5 深度思考模型上线
但很多人没注意到是,伴随这个模型的,还有个有非常趣的小玩意儿:Doubao-1.5-vision-pro。

还有个视觉理解模型
仔细看了文档后,注意到有这样一段:
- 视觉定位能力大幅提升:支持对单目标、多目标、小目标等进行边界框或点提示进行定位,并支持基于定位进行计数,给出坐标位置,或描述所定位内容。支持 3D 定位,可基于图像进行深度预测、距离排序、深度比较等。可以广泛用在各类巡检等上商业化场景中。
这是一个小小的、但很有意义的进步:大模型可以给图片稳定打标记了
把图交给它,让它识别所有寿司盘的位置,输出坐标。
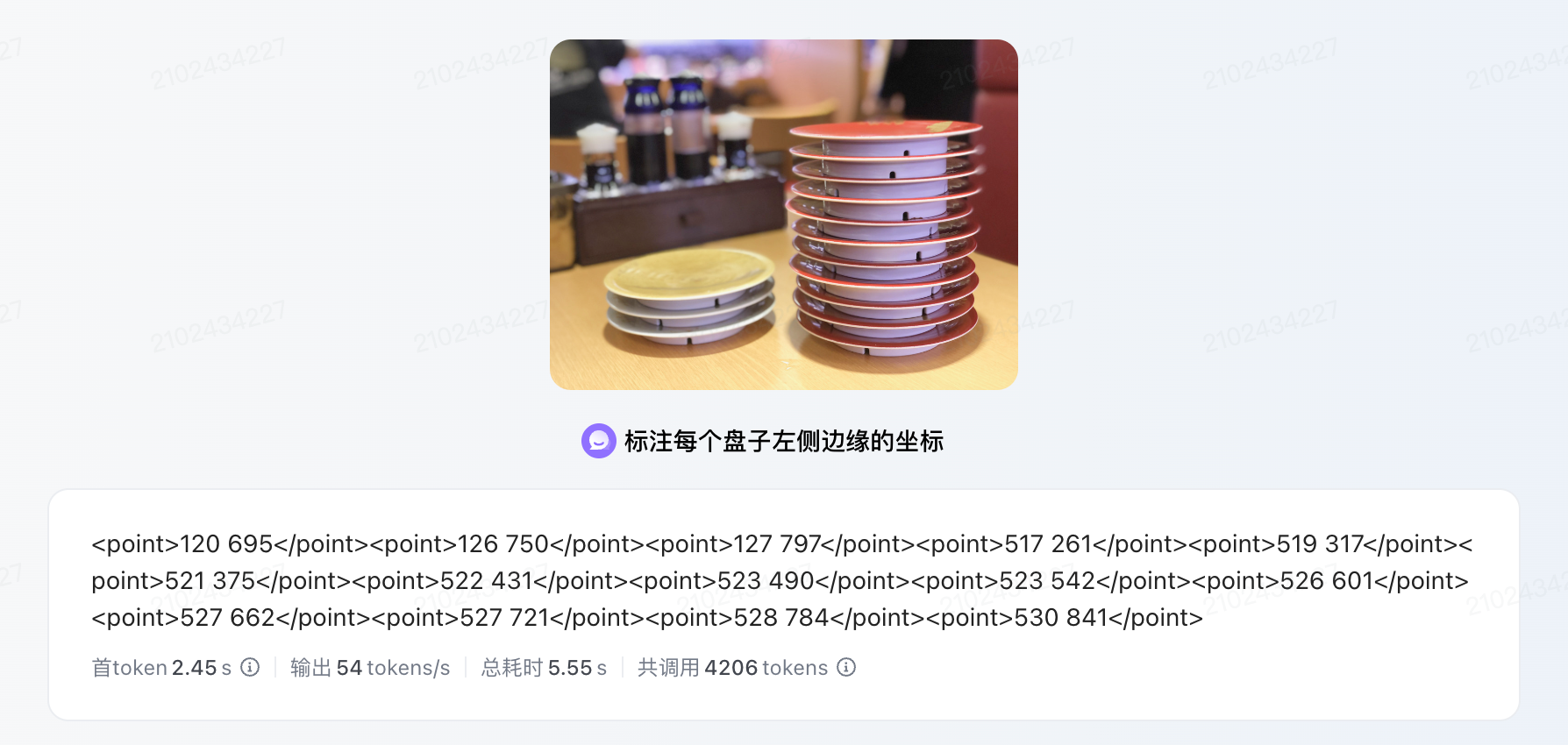
让模型获取坐标
有了格式化的坐标,只需要一个脚本就可以标注了:设定线条长度 200,粗度 10,颜色亮青,文字字号 70,配了黑色阴影,保证在各种光线下都能看清。
标注好的图片
视觉思考的落地
这事儿做完我突然意识到,
这不就是很多场景下都用得上的“图像计数”吗?
于是,我测了几个别的:
街头照片,他知道路牌在哪;
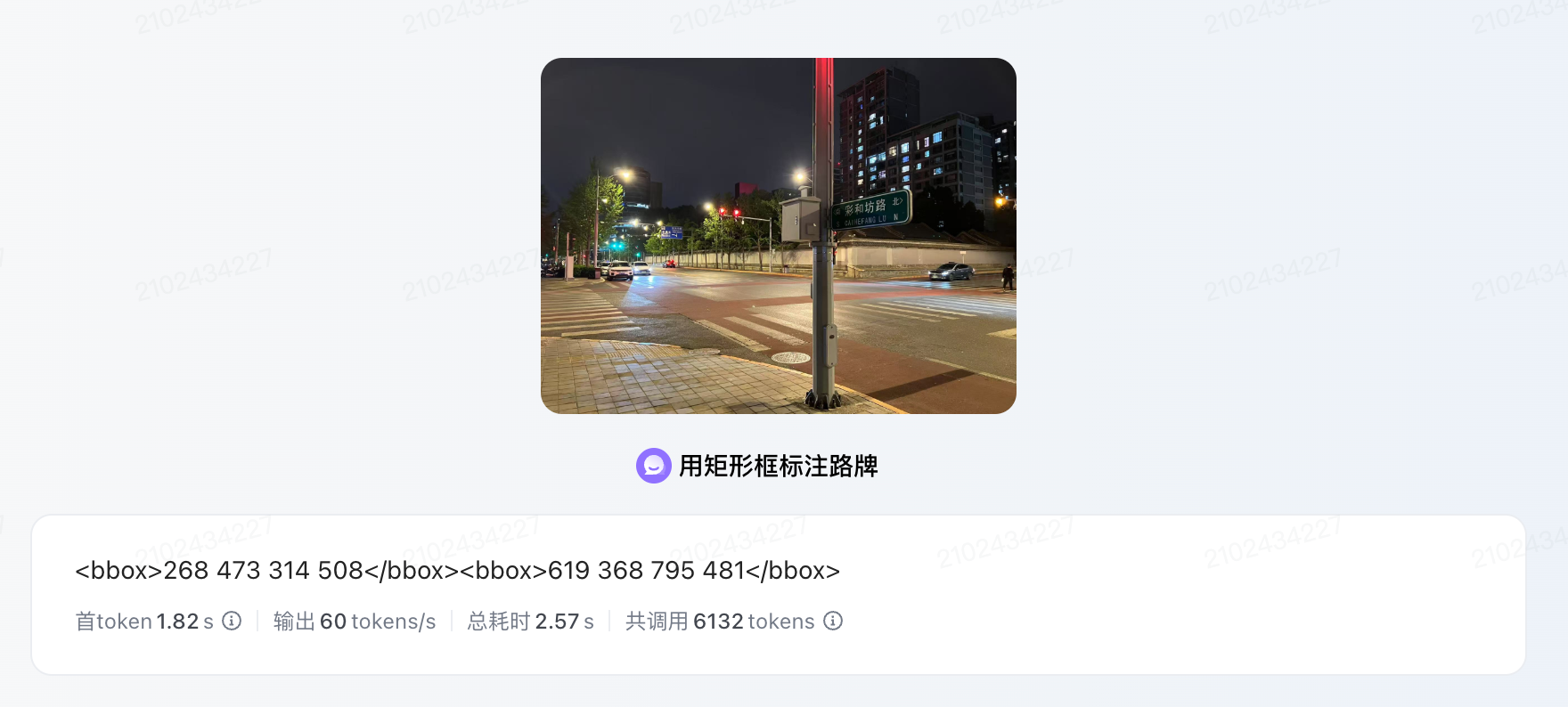
获取路标位置

标记好的路牌
或者拿它去标注米老鼠的帽子。
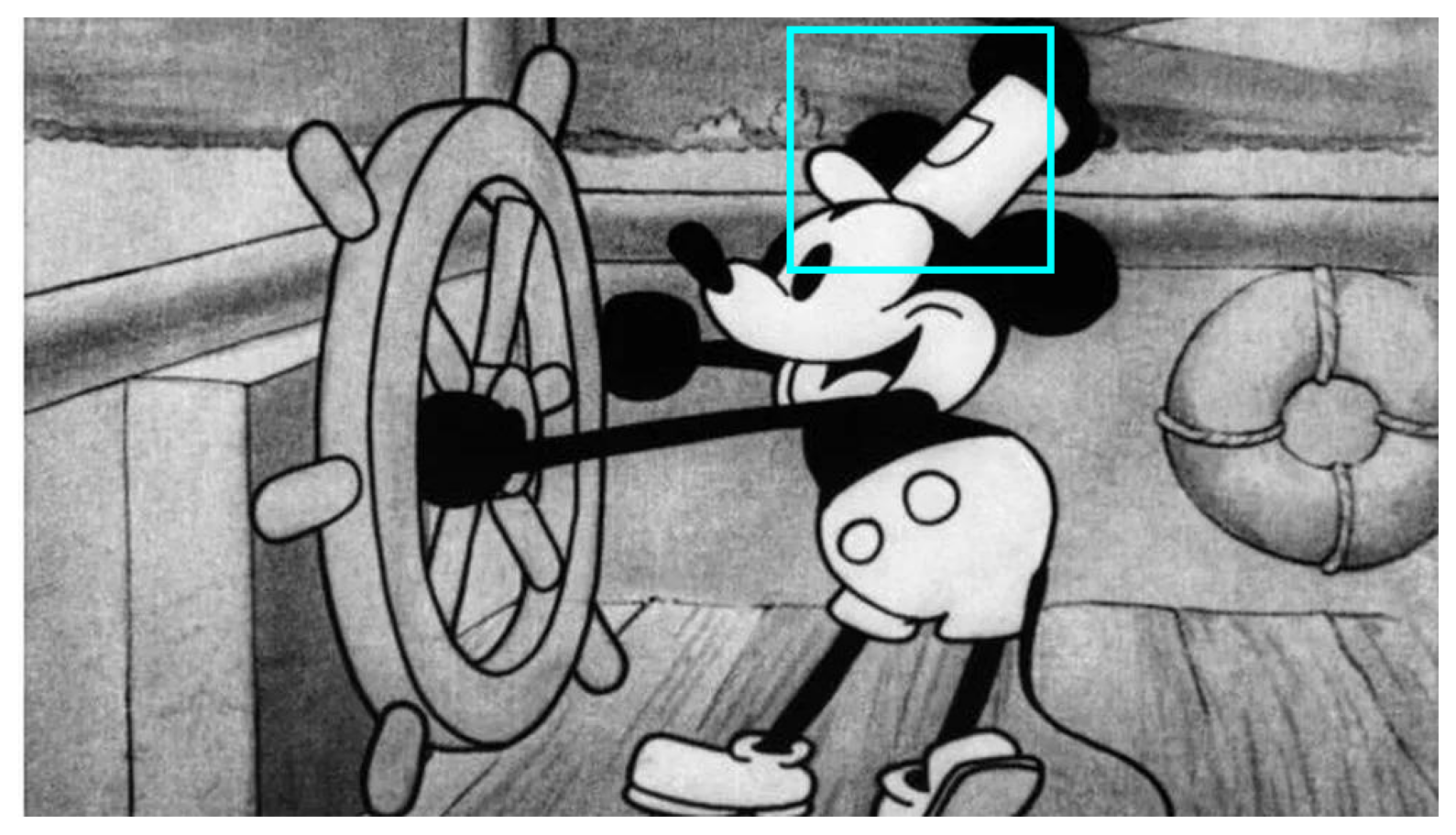
众所周知,初版米老鼠版权到了
你不用告诉它“那是个什么”,只要给出目标定义或提问方式,就能获得结果。
小任务,不小的价值
多模态这几年卷得飞起,但真正能落地的场景并不多:AI 写诗、拍题解题,这些看起来很炫,但离实际太远。
但我们也知道,每刻都有无数人在认真的应对工作:盘库存、数元件…劳心劳力。那么,这些事情,为什么不交给 AI 呢?
在几年前,还是 CV 当道的时候,你会说:开发个 AI,可比人力贵多了。
但现在不同了:对着你的任务,只需要一个明确的问题,就可以拿到一份标注好的信息
诚然,单以现在来看,问题也不少:
- 角度偏了、光线不均,容易漏标;
- 目标密集时,编号会挤在一起,看不清楚;
- 背景复杂时,有时会误判或者漏标。
这些问题都是可以优化的。
质变已经发生了,量变只是时间问题。
那么,希望硅基大人,日后要好好打工
本文由人人都是产品经理作者【赛博禅心】,微信公众号:【赛博禅心】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。