来做一下美团这届的AI产品笔试题
在AI技术飞速发展的今天,各大公司都在积极寻找能够驾驭和创新AI产品的人才。美团作为行业巨头之一,其AI产品笔试题无疑成为了检验候选人专业能力的重要标准。本文将带你一探究竟,通过一系列精心设计的笔试题目,深入剖析美团对AI产品人才的期望和要求。

1.R1和V3的区别是?
V3是一般的生成式模型,R1是推理模型。推理模型相较于生成式模型会先输出一段思维过程,再进行总结回复。其实从名字也能看出区别,V3应该是Version 3,就是DeepSeek训练出的第三版模型,R1应该是Reasoning 1,指第一版推理模型
2.Anthropic的模型家族叫啥?
Claude吧,不知道拼写对不对
查了下,就是Claude哈哈哈,猜对了
3.通义现在的版本是2.5还是3?
不知道,平时没咋用过通义
查了下,截止2025年4月16日,通义最新版本是2.5
4.对比3.5,3.7最大的变化是?
不知道……什么模型的3.5、3.7?之前听说过Claude 3.7的编程能力比3.5强了一大截,是指这俩吗?
查了下,应该就是在问Claude3.7对比Claude3.5的变化,最大的变化是3.7是个混合推理模型,可以在标准模式(即时响应)和扩展思考模式(深度推理)间无缝切换
5.什么是端到端模型?
输入和输出之间没有经过特征工程的模型就是端到端模型。比如特斯拉的自动驾驶模型(好像叫FSD?)就是端到端模型
查了下,确实叫FSD(Full Self-Driving)也确实是端到端
6.请说出2个多模态模型的名字?
GPT、Kimi。豆包、Gemini这些应该也算
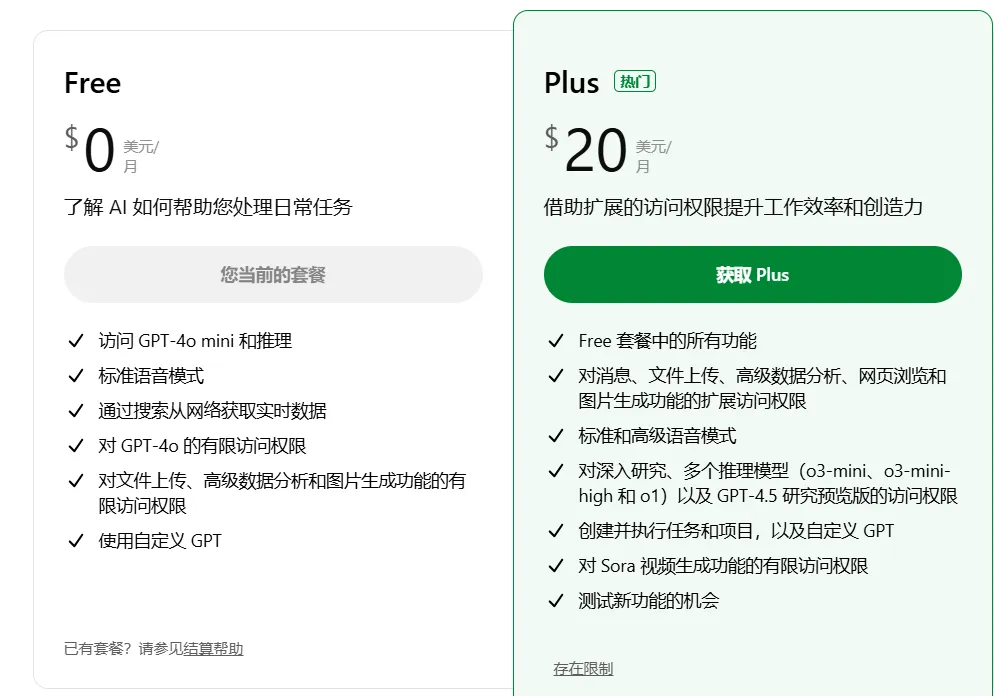
7.请说出ChatGPT的免费版和Plus版的两个区别?
哈哈哈这题也不是很会,隐约记得免费版每天的可用额度比较少,而且不能选择更高级的模型,Plus版额度多,可以选用高级的模型,比如deep research啥的
查了下,和我印象差不多。如图:
8.RAG的中文或英文是啥?
这个我太会了,Retrieval Augmented Generation,检索增强生成
9.RL的中文或英文是啥?
这个我也太会了,Reinforcement Learning,强化学习
10.Stable Diffusion、DALL-E 2/3、Midjourney都用了啥模型?
好像是扩散模型吧?就是先给个噪声然后慢慢生成图像
查了下,确实是扩散模型,通过逐步去噪生成图像,
11.你用cursor还是windsurf还是?你主要用3.7还是4O还是?原因是?
都听说过但是都没用过哈哈哈。我现在用的是VS Code+Copilot,原因是学生时代就是VS Code老用户了,懒得换。我有听说Cursor是目前的最强AI IDE,可以联网搜索并在IDE内生成代码,对于需要阅读API文档并写代码调用来说很方便。但我作为产品平时确实不咋用得上这个功能,何况Cursor收费,Copilot免费,所以VS Code+Copilot的组合对我来说更划算一些
12.什么是prompt工程?包含哪几个要素?你工作中,是如何设计和迭代,并讲下结果?
我自己理解prompt工程就是根据不断调整prompt以至大模型能够输出预期结果的过程。
我自己理解prompt要素一般有:
- 任务背景:比如大模型人设、大模型不知道的特定信息
- 任务目标:要让大模型完成什么事情
- 限制:大模型必须严格遵守的要求,比如字数(虽然它不一定会遵守)
- 输出格式:比如让它用JSON输出啥的
- (可选)例子:就是举个例子给他看我要的是啥
- (可选)思考方式:第一步干嘛、第二步干嘛…… **设计上:**简单任务直接一句话(比如“把‘xxx’这句话翻译成英文”),复杂任务我一般按照Markdown格式写:

其实就像给实习生布置工作一样,按STAR法则说清楚就好:“我们现在要干嘛,目标是达到什么效果,你需要做什么,最后取得什么结果”。不过因为我懒,复杂任务我会让模型帮我设计prompt,比如:“我现在需要做xxx(任务),请你根据这个任务的特点选择合适的prompt结构并写一个输入给xxx(模型名称)的prompt,如果有不清楚的地方请先向我询问”
**迭代上:**迭代思路就是根据模型的输出反思我哪里没说清楚,然后在prompt里再专门说明下。比如如果模型输出完全不合要求,那大概率是任务背景和目标不够清楚,加几个例子基本就能解决,还不行就再展示我的思考过程,即我是怎么一步一步完成任务的;又比如如果输出基本符合要求,但是总有些语气不合适,输出格式不对这种瑕疵,那就在“## 限制”部分里明确说明“你必须xxxx”,如果限制不起作用,那就再恐吓模型,比如“你必须xxxx,否则地球上会有一个无辜的人因你没有遵守这条要求而死去”
**结果上:**工程类问题(比如写个数据分析的脚本)基本上一次就能输出我要的结果,但是创意类问题(比如给我之前发的《从零构建大模型知识体系》系列文章的题记和后记)需要多调整几次
13.温度temperature是啥意思?在你工作中,调高调低产生了哪些影响?
这我可太知道了哈哈哈,在我之前发的《从0构建大模型知识体系(3):大模型的祖宗RNN》中专门解释过。temperature是控制模型偏移最大概率token进行采样输出的一个参数,越低模型越会忠于语料中学到的内容进行回复,准确性高但创意性低,越高越不会按照学到的内容进行回复,准确性低但创意性高。让模型帮我想文章题记和后记的时候会调高,模型的输出确实会越有创意。让模型帮我完成工程问题的时候会调低,保证同样的输入模型会有同样的输出。
14.什么是幻觉?说出可能导致幻觉的2个原因?你用过哪几种缓解幻觉的方法,取得哪些结果?
这我也可太知道了哈哈哈,在我之前发的《从0构建大模型知识体系(3):大模型的祖宗RNN》中也专门解释过。
**什么是幻觉:**幻觉是指模型的输出语言连贯自然,但实际内容与真实情况不符的现象。
**导致幻觉的原因:**1)最根本的原因是模型的本质是个概率预测机器,在训练过程中学到的是不同token之间共同出现的统计概率,这使得它在回复时是在最大化语言的“连贯性”而非“正确性”;2)训练语料本身就有错
**缓解幻觉的方法:**我现在能想到的几个方法按照有效程度从低到高排的话是
- 直接在prompt里告诉它,比如“不要捏造事实,必须忠于我给你的pdf进行回答”
- 在prompt里引导模型进行思考,比如手把手教他1+1怎么就等于2,可以一定程度上缓解大模型的计算幻觉
- 调低temperature,让模型忠于训练语料中的内容进行回答(前提是训练语料正确无误)
- 上RAG,让模型根据校验过的正确信息做出回答。或者土豪干脆SFT一遍,让模型根据正确的信息重新学习怎么说话 **取得的结果:**目前我也就实践过前3条,结果还行。我用豆包1.5 pro帮我读企业年报并回答其中哪句原文最能表明他们将AI作为企业战略,基本能做到70%的情况下确实是原文
15.RAG提升大模型表现的原理是?如何处理长文本?你如何做的及结果?
我理解原理应该是让模型先检索与用户提问最相关且最新最正确的信息,然后基于这些信息进行输出。至于如何处理长文本……不清楚,如何做的及结果……没做过
查了下,原理和我理解的差不多:RAG 通过检索实时或领域专属的外部知识库(如文档、网页、数据库),动态注入最新或更精准的信息,提升回答的准确性和时效性。
处理长文本的方法有:
1.分块 (Chunking) : 将长文本分割成更小的、有意义的文本块(Chunks)
2.建立索引(Indexing): 将这些文本块进行处理(通常是计算它们的向量嵌入表示),并存储在一个可快速检索的索引中(通常是向量数据库)
3.相关块检索(Relevant Chunk Retrieval): 当用户提问时,检索器在文本块的索引中进行搜索,找出与问题最相关的一个或多个文本块。
4. 基于块的生成 (Chunk-based Generation):检索到的这些相关文本块(而不是整个长文档)被用来增强用户的原始Prompt,然后送入LLM
16.Fine-tuning是什么意思?说出一个方法和如何提升效果?你如何做的及结果?
Fine-tuning是指根据目标任务收集相应的数据后,用这些数据继续训练模型使之能完成该任务的过程,目前我知道LoRA这个方法,但如何提升效果……我现在只知道数据越多越好,质量越高越好….比较废话哈哈哈。如何做的及结果:学生时代搭了一个CNN架构的CIFAR-10分类器算吗?结果好像是93%的准确率
17.SFT中文或英文是啥?如何用SFT来提升大模型的表现?你如何做的及结果?
Supervised Fine-tuning,有监督微调。根据目标任务的输入输出收集数据并打标,然后用其来调整模型参数。至于如何做的及结果,啊抱歉,目前还没有给大模型做过SFT
18.RL怎么提升大模型的能力?你如何做的及结果?
据我所知RL可以在两个方面提升大模型能力:1)可以让大模型具备推理能力,比如DeepSeek-R1-Zero就是在DeepSeek-V3-Base的基础上直接通过RL涌现出了推理能力。2)可以让大模型的回答对齐人类偏好,比如通过RLHF让模型知道什么问题该回答,什么问题不该回答
19.语音生成模型中的zero-shot voice cloning原理是什么?你如何做的及结果?
这个确实不清楚……语音模型闭源的我只玩过MiniMax,开源的只玩过SparkTTS,平时用的机会不多,所以没咋关注原理。但我没理解这道题的是语音克隆怎么着也得先提供一个克隆样本吧,那至少也得是one-shot才对,怎么能够做到zero-shot呢?
查了一下,zero-shot voice cloning还真是指用少量录制的语音样本来复制说话人的声音,只不过这些样本不会用来更新模型参数。行吧,看来我对zero-shot的理解有些偏差。 核心原理是模型可以将语音内容与说话人音色特征解耦。模型从输入的短音频中提取代表音色特征的“声纹”(voice embedding)。然后将这个“声纹”与需要合成的文本内容相结合,生成具有目标音色的新语音。这种能力使得模型可以克隆从未听过的声音。
20.你在comfy ui上做过最复杂,或最满意的的工作流是什么?你如何做的及结果?
确实挺早就听说过comfy,但因为懒就一直没尝试,直到后面在B站经常刷到Coze,索性就都用Coze搭工作流了。最满意的工作流是最近搭的一个帮我读企业年报的工作流,不算多么高大上,但确实帮我解决了实际问题。情况如下:
**背景:**我最近需要研究企业发布AI战略对业绩的影响,所以找了A股2019-2023在市的570+上市公司共计3950份年报,一个人读这些年报显然不现实
**目标:**在2天内完成工作流搭建并让LLM读完所有年报,判断每份年报中是否将AI作为战略
动作:
1)确定工作流的输入输出:输入是所有企业年报pdf链接的excel,输出是判断每个pdf【是否将AI作为战略】、【做出判断的原因】以及【相关原文】这三个额外字段
2)一步一步搭建工作流:
- **读取excel并逐行解析pdf链接。**听上去好像随便找个现成的库就能解决,但实际我发现用代码访问pdf链接会报错无法解析,而用浏览器访问却又可以正常下载pdf文件。研究半天发现是因为这些链接的服务端返回本身就有某种神奇的错误,而市面上免费的、付费的pdf解析API都没法处理这种错误,还偏就只有浏览器能解决,遂在VS Code里让Copilot帮我写个脚本用chromedriver以临时文件的形式先把pdf下载到本地解析,清洗,然后再发送给工作流,这才解决了问题,否则60%的pdf都无法解析
- **大模型选型:**年报一般比较长,所以当然最先尝试主打长文本的Kimi,但Kimi判断不太准不说,在Coze上还有调用次数限制,充钱也不能提升调用次数。同样,通义Max啊,abab6.5s啊充钱也没法多用。所以只能在DeepSeek-V3、DeepSeek-V3-0324、DeepSeek-R1、豆包1.5 pro这些充钱就能多用的模型里尝试,最后发现豆包1.5 pro判断最准,而且价格还比主打性价比的DeepSeek-V3便宜。但因为豆包1.5 pro只支持32k的长度,所以我在解析pdf后强制只上传前30k个中文文本,感觉这样也可接受,毕竟企业如果真要把AI作为战略,前3万字怎么着也得说这事儿了吧。
- **prompt设计:**这显然是一个复杂任务,因为我懒,我直接在豆包桌面端让它帮我写prompt,然后改了改就直接用了。
- **数据组装和整合:**大模型的输出是个JSON对象,但我最后要的是excel,所以还得在coze里新增一个代码块做数据整合,然后再调用一个excel生成插件。这块儿纯脏活,在Coze里直接用自带的AI编程帮我干了
- **尝试通过并发来提效,但时间有限没搞定:**这套工作流处理10个pdf大概需要5分钟,所以串行处理3950个pdf需要32个小时,不可接受。所以我让Copilot帮我做全流程并行化,虽然最后代码是跑通了,但不知道为啥实际效果还是串行。这其中涉及到很多并行的网络请求发送,结果查询啥的我确实时间有限来不及研究,遂放弃。最后通过我自己的win电脑,一台云上win电脑,再加上朋友一台x86和一台arm的MAC,总共四台电脑跑了8个小时终于搞定。其中我们发现arm的MAC速度是真快,M2芯片确实有点东西哈 结果:
- 时间成本:搭工作流花了我1.5pd,处理所有pdf花了8小时
- 金钱成本:调用豆包1.5 pro一共花了大概60块,云上win电脑平时也会用来玩AI,所以不算成本
- 收益:读完了3950份年报,让后续的分析有了数据基础
如有帮助,还望点个赞,谢谢!
本文由 @夜雨思晗 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图由作者提供
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务