复刻DeepSeek「联网搜索」功能
 无论是 DeepSeek官方,还是像 腾讯元宝 这类自己部署满血版DeepSeek并提供服务的产品,大家在Chat页面都会注意到「深度思考」和「联网搜索」两个按钮。
无论是 DeepSeek官方,还是像 腾讯元宝 这类自己部署满血版DeepSeek并提供服务的产品,大家在Chat页面都会注意到「深度思考」和「联网搜索」两个按钮。

有朋友之前问我这两个按钮的区别是什么,每次都不知道该不该选。
在聊复刻联网搜索功能之前,先简单给大家介绍一下如何使用。其实核心就是理解两个问题:
1、为什么需要联网搜索?
因为用于模型训练的数据(也就是模型见过的能理解的知识),都是历史数据。
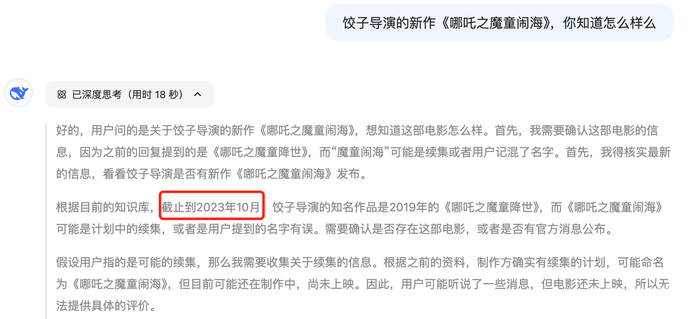
比如DeepSeek-R1是2025.1.20发布的,《哪吒之魔童闹海》是2025.2.14上映的,如果直接问它会得到这个回答(说明训练数据可能只有23年10月之前的)。
所以你的问题中如果希望模型回答的结果能参考最新消息,需要点亮“联网搜索”。
2、为什么需要深度思考?
举个例子更容易理解一些,比如你在做复杂的数学题,是不是需要准备一张“草稿纸”,把自己一步步的思考过程、规划演算都写出来,这样最终才更容易得到正确答案。大模型也一样,“深度思考”可以理解是模型的“草稿纸”。
所以你的问题如果是代码、数学等需要推理演算的类型,需要点亮“深度思考”。
应用背景
进入正题,虽然我们大概能理解“联网搜索”就是“从互联网检索信息后交给模型再做处理”,但是个人一直对其背后具体怎么实现的感到好奇。
而且值得注意的是,在企业内部,中下游团队获取上游信息的时效性有可能滞后于互联网更新速度,特别是上游业务本身就是toC的服务时。比如,游戏公司数据中台团队某天突然监控到收入曲线异常上涨,此时很难快速判断时因为数据错误还是游戏运营做了新的活动,往往都需要问一下活动运营策划或者自行上网检索核实。
所以将企业内部知识库和联网搜索能力相结合,能提高信息的流转效率,可能会是一个比较值得深入研究的应用场景。
方案复刻
首先我们要准备两个API:1、DeepSeek官方API(比较穷部不了满血版,只能用官方API);2、查询互联网信息的API。
DeepSeek的API
首页右上角API开放平台:DeepSeek Platform
在API keys创建自己的key,格式:sk-7222b***********************d05d
在调用API时需要特别注意的是,如果希望触发“深度思考”,发送请求的model参数填“deepseek-reasoner”,否则填“deepseek-chat”。
查询互联网信息的API
网上找了下,博查API说是DeepSeek的官方搜索供应商,¥0.036/次的价格也不贵,可以选来它搭建demo。
博查AI开放平台 | Search API, Reranker API
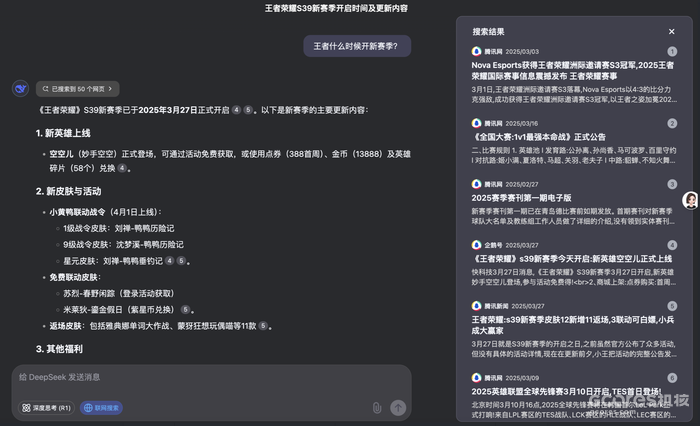
申请API后可以测一下效果。王者最新赛季3.27,我在3.26晚用API测试了一下,问的问题是:王者什么时候开新赛季?
API返回的结果长这样:

Top10结果的准确率70%:

当时我去DeepSeek官网搜了下,发现返回的结果不完全一样。
DeepSeek联网搜索结果以腾讯新闻为主,可能自己前置做了垂直领域识别和优化操作。
如果提问强行加上优先从腾讯新闻网站访问:王者什么时候开新赛季?请优先从腾讯新闻网站访问
虽然站点都从腾讯相关网站提取,但是效果反而变差了,Top10结果的准确率只有40%

所以如果大家真要上生产使用,可能需要研究召回结果如何二次排序,而且不要对问题做任何奇怪的限制处理。
使用方式
DeepSeek联网搜索的Prompt可以在官方huggingface上找到:

它其实对联网搜索返回的结果search_results有一定格式要求:每一条是webpage X begin...webpage X end的格式。
我们把博查API里返回的summary做相应格式处理后,拼到Prompt就能实现联网搜索功能了。
以“王者什么时候开新赛季?”这个问题为例
非深度思考模型返回结果:

深度思考模型返回结果:

其中,<think>...</think>部分就是大家看到思考过程。
代码
https://github.com/zhyuzhanming/deepseek_websearch_reproduce
代码需要python环境,大模型时代技术已经完全不是问题了,想动手玩一玩又不太懂技术的同学,可以自己跟大模型交流让它告诉你怎么操作(建议使用miniconda搭建不同项目的虚拟环境)。
另外我没有实现引用链接跳转,技术同学可以自行实现下。
写在最后
之前在《Prompt设计和迭代指南》文章最后提到过大模型时代下生态位的变化。
这里再画一张更直观的图给大家讲一讲:
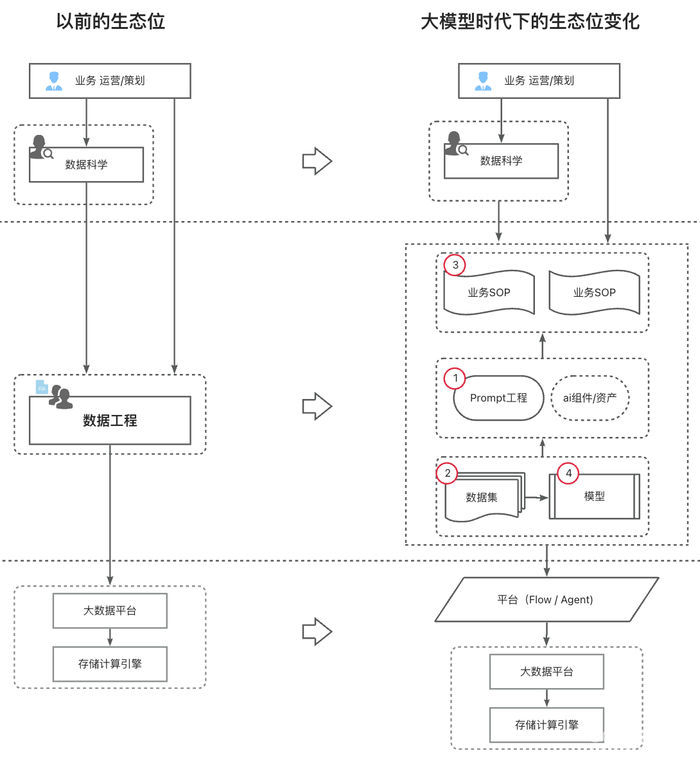
首先,底层平台可能会逐渐退化成一堆API,上游演化出一个更智能的工作流平台,或者类似Manus的Agent(个人觉得对企业来说,如果没有第一步先做ai工作流资产的收集沉淀,很难直接产生出适合企业自己的Manus)。
其次,数据工程从原先沟通需求 -> 写SQL -> 配置执行任务 -> 交付数据的角色,会逐渐演化出新的4部分能力:
- Prompt工程,以及应用新平台沉淀ai资产的能力
- 整理适合微调小模型领域数据集的能力
- 基础业务SOP能力,比如游戏玩法策划每次上线新玩法都会分析哪些数据,活动运营每次上线新活动都会分析哪些数据
- 模型微调能力
经过两年多实践看,Prompt能力下一步可能在于如何构建快速迭代的工具,单论Prompt本身,对于应用贡献的天花板已经能看到在那了,不会有特别大的突破。为了从底层模型侧找切入,最近一段时间疯狂学习和操作,干了3件事:
- 阿里云上4A10(424G)全参数微调Qwen7B跑通
- 可能找到了比较靠谱的数据集构建pipeline,在1的环境验证效果挺好的。看到了领域知识低成本迁移模型的希望
- 一直好奇联网搜索,利用DeepSeek和博查API,复刻了 联网搜索+深度思考
这篇小文章主要分享了第3部分,后续会逐步把云上微调环境部署和数据集pipeline构建经验也分享给大家,一起跟上大模型时代!