大模型的 “超级大脑”:从输入到输出的奇幻之旅
本文将带你深入探索大语言模型的内部世界,从输入到输出的每一个环节,揭示其如何将人类语言转化为智能回答。
大语大语言模型的核心架构是一个超级大脑,主要由三部分组件,分别是输入、中间层和输出层。输入层的主要作用是把人类的语言转化成机器能理解的数字符号。中间层的核心是 Transformer,主要的作用是对输入的数字序列进行深度语义分析,建立词与词之间的关联。最后是输出层,输出层的主要作用是把中间层处理后的数字符号还原成人类能理解的内容(文字、语音等)。举个简单的例子来理解一下,比如我到福周菜馆点餐,我输出:“我要鱼丸和 MASK” ->大模型找到与 “鱼丸” 向量最接近的词(如 “拌面”,因为福州人常搭配吃)->“我要鱼丸和拌面”。
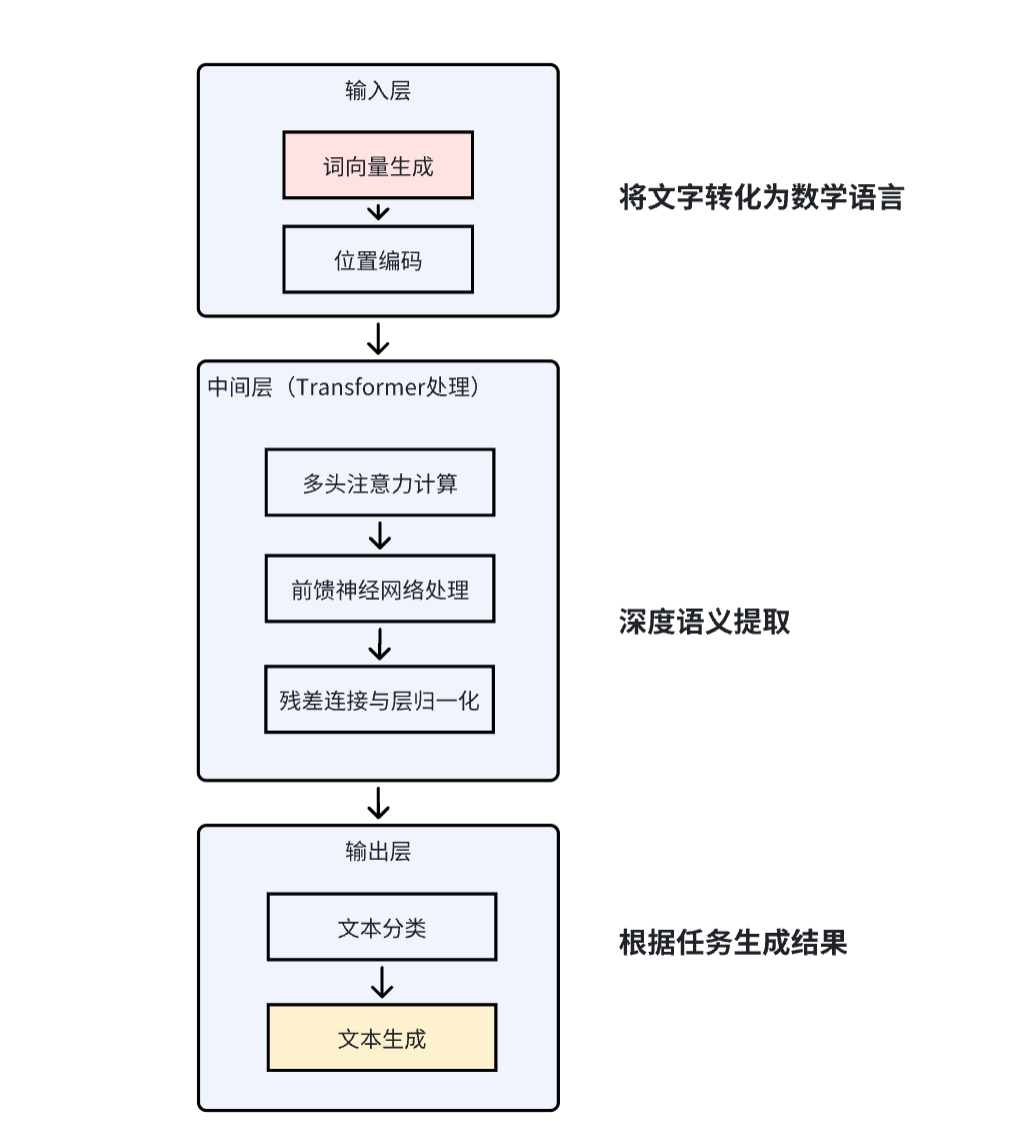
一、输入层
要让机器能理解人类语言,首先要将人类语言(文字、语音等)转化为计算机能处理的数学符号。输入层相当于是翻译官,把中英文翻译成机器语言。这层主要包括两个主要步骤:
1、词向量生成
在说明词向量生成之前,要理解分词(Tokenization)的概念。分词是将句子拆分成最小语义单元(词或子词)。比如把我们福州的鱼丸拆分成“福州”, “鱼丸”。这里涉及到的技术有BPE(字节对编码)、WordPiece 等。
生成完分词后,需要将每个词转换为多维数字向量(类似坐标),多维数字向量是由多个数字组成的 “坐标点”,这个坐标点能反映词的语义和语法信息。比如:“猫” → 0.2, -0.5, 0.7,不同词的向量空间位置反映语义关联。当然,这些词的多维向量是通过预训练模型(如 Word2Vec)生成的。
为什么是多维向量?
如果是单维向量,则用 1 个数字(如 1 维)只能表示简单差异(比如用 0 表示 “猫”,1 表示 “狗”),但无法体现语义关联(如 “猫” 和 “狗” 都属于动物)。词的多维数字向量是大模型的 “语言密码”,他的本质是将词映射到高维空间的坐标点,通过坐标距离和运算,让机器理解词的语义、语法和逻辑关系。让模型能像人类一样 “理解” 语言背后的含义。
2、位置编码
给每个词添加位置信息(如 “福州” 是第 1 个词,“鱼丸” 是第 2 个词)。由于Transformer 并行处理不依赖顺序,所以需额外加入位置信息(如 “鱼丸” 在前和在后的意义不同)。比如:第 1 个词(福州) → 0.1, 0.9,第 2 个词(鱼丸) → 0.3, 0.8
示例说明
输入文本
“福州鱼丸和沙县小吃都是福建的特色美食”
1. 词向量生成
通过预训练模型(如 Word2Vec)生成每个词的多维向量(假设示例):
- 福州 → 0.2, -0.5, 0.7
- 鱼丸 → 0.3, -0.6, 0.8
- 沙县小吃 → 0.4, 0.1, -0.3
- 福建 → 0.1, 0.9, -0.2
- 特色美食 → 0.7, 0.3, 0.4
2. 位置编码
给每个词添加位置信息(假设用正弦函数生成):
- 第 1 个词(福州) → 0.1, 0.9
- 第 2 个词(鱼丸) → 0.3, 0.8
- 第 3 个词(沙县小吃) → 0.5, 0.7
- 第 4 个词(福建) → 0.7, 0.6
- 第 5 个词(特色美食) → 0.9, 0.5
最终输入向量:
每个词向量与位置编码拼接,例如: 福州 → 0.2, -0.5, 0.7, 0.1, 0.9
二、中间层
1、Transformer 架构
Transformer的核心任务是将原始词向量转化为富含语义关联的深度特征。它替代了传统循环神经网络(RNN),让大模型能并行处理所有词。传统 RNN 需按顺序处理词(如 “我→爱→中国”),Transformer 能同时处理所有词,并通过注意力机制捕捉远距离词的关联(如 “北京” 和 “首都” 相隔很远仍能关联)。
2、注意力机制(Attention)
自注意力(Self-Attention)
自注意力是为了让每个词 “关注” 其他词的重要性。比如:翻译 “猫追老鼠” 时,“追” 需要关注 “猫”(施动者)和 “老鼠”(受动者)。自注意力计算时,会先进行相关性打分:计算 “追” 与 “猫”“老鼠” 的关联度(如 “追” 和 “猫” 的分数更高);然后再加权求和:根据分数生成 “追” 的新向量(重点融入 “猫” 的信息)。
多头注意力(Multi-Head Attention)
多头注意力是为了从不同角度分析词关系(类似用不同滤镜看同一张照片)。比如:处理 “苹果公司发布了新 iPhone”。多头注意力为了捕捉更全面的语义关联,分工如下:
- 头 1:关注公司与产品(“苹果”→“iPhone”)。
- 头 2:关注动作与对象(“发布”→“iPhone”)。
- 头 3:关注时间或地点(若句子有 “今天”)。
注意力计算流程
- 词向量转换:每个词转为坐标点(如 “鱼丸”→0.2, -0.5, 0.7)。
- 计算相关性:“鱼丸” 对 “拌面” 的关注度:根据向量距离打分(福州人常搭配吃,分数高)。
- 生成新向量:“鱼丸” 的向量会重点融合 “拌面” 的信息(因为关注度高)。
多头注意力 = 多个自注意力头 + 结果拼接。每个头独立计算自注意力,然后将结果合并(类似拼图)。示例如下
示例(以句子 “猫追老鼠” 为例):
-自注意力头 1:关注动作关系 → [猫:追,老鼠:被追]
-自注意力头 2:关注实体关系 → [猫:动物,老鼠:动物]
-多头结果:综合两个头的信息,得到更全面的理解。
3、前馈神经网络(Feed-Forward Network)
FFN是对注意力处理后的向量进行非线性变换(类似炒菜时的调味),因为注意力机制本质是线性加权,无法处理复杂非线性关系,通过激活函数(如 ReLU)让模型学习更复杂的语义模式。比如:将 “鱼丸” 与 “福建” 的关联从 “地域特产” 提升为 “文化符号”。
4、残差连接与层归一化
- 残差连接:将原始输入与 FFN 输出相加,防止信息丢失。
- 层归一化:标准化数值范围,确保稳定性。
示例说明
1. 多头注意力(Multi-Head Attention)
通过 8 个头(假设)从不同角度分析词关系:
头 1(地域关系):
- 重点关注 “福州” 和 “福建” 的关联,将它们的向量加权融合。
- 输出:0.25, -0.4, 0.65, 0.12, 0.88(增强地域特征)。
头 2(食物类别):
- 关注 “鱼丸” 和 “沙县小吃” 的相似性,融合后突出 “小吃” 属性。
- 输出:0.35, -0.5, 0.75, 0.32, 0.78。
头 3(常识推理):
- 捕捉 “福建” 和 “特色美食” 的逻辑关系,确认 “福建有美食”。
- 输出:0.65, 0.2, -0.15, 0.68, 0.52。
拼接多头结果:
将 8 个头的输出拼接后通过线性层,得到每个词的新向量。
2. 前馈神经网络(FFN)
对注意力后的向量进行非线性变换: 福州 → 0.3, -0.6, 0.7, 0.1, 0.9(增强 “省会” 语义)。 福建 → 0.8, 0.7, -0.1, 0.7, 0.6(强化 “省份” 特征)。
3. 残差连接与层归一化
- 残差连接:将原始输入与 FFN 输出相加,防止信息丢失。 福州 → 0.2+0.3, -0.5+(-0.6), … → 0.5, -1.1, …。
- 层归一化:标准化数值范围,确保稳定性。 福州 → 0.5/√(0.5²+…), … → 0.2, -0.4, …。
三、输出层
1、文本分类
文本分类的主要作用是把句子贴标签,并判断这个标签的概率。处理流程包括“中间层总结的句子密码 → 分类筛子 → 概率计算器 → 贴标签“。
- 中间层总结的句子密码:通过中间层已经把句子变成一串数字(比如 0.8, 0.6, -0.3),就像给句子生成一个 “数字身份证”。
- 分类筛子:用一个数学公式(类似筛子)把这串数字变成两个分数。比如 1.2, -0.5,代表 “是美食” 的可能性更高。
- 概率计算器:把分数转化为百分比。比如 77%, 23%,说明 77% 概率是美食描述,23% 概率不是。
比如:
- 输入:“这道菜很好吃”
- 输出:77% → 贴标签 “是美食”
2、文本生成
文本生成的主要作用是给出完整的回答。主要流程包括”中间层知识 → 故事续写机 → 逐词创作 → 完整回答“
- 故事续写机:大模型像一个会写故事的人,先记住中间层提供的福建相关知识(比如沙县小吃、佛跳墙)。
- 逐词创作:每次只生成一个词,根据已写的内容决定下一个词。比如:开头写 “福建”,接着想到 “特色”,然后生成 “有”,最后补充 “沙县小吃”。
- 注意力机制:写每个词时,会重点关注之前提到的关键词。比如写 “小吃” 时,会特别注意 “沙县” 这个词。
示例说明
- 输入问题:“福建有什么特色?”
- 输出回答:“福建的特色有沙县小吃、佛跳墙等。”
本文由 @产品老林 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。