当“毛坯房”遇上“精装房”:大模型私有化部署中RAG和Fine Tune的技术选择
在人工智能领域中,大模型的私有化部署正在成为企业技术发展的重要方向。然而,选择哪种技术路径才能让大模型在实际应用中发挥最大效用?是RAG,还是Fine Tune?本文将深入探讨这两种技术在大模型私有化部署中的优势与挑战,帮助企业在“毛坯房”与“精装房”之间做出最优选择,实现技术与商业价值的双重提升。

01 一场被按下快进键的AI革命
过去一个月,国内掀起了一场本地化大模型部署浪潮。从金融银行到三甲医院,从制造车间到政务大厅,企事业单位纷纷宣布本地化部署DeepSeek大模型。”DeepSeek赋能智慧医疗”、”DeepSeek驱动教育转型”等新闻标题高频刷屏,似乎中国产业智能化已跑步进入”大模型时代”。
但在这股热潮背后,一个关键细节被选择性忽略——从DeepSeek-R1模型发布到首批落地案例官宣,时间跨度仅仅一个月。这甚至不够完成一次标准的大模型微调训练,抑或搭建稳定可靠的RAG系统。当技术部署周期被压缩至极限,我们不禁要问:
这些”成功案例”究竟是AI能力的内化突破,还是企业在数字化转型焦虑下的”样板间工程”?
技术幻象与产业逻辑的断裂
在DeepSeek本地化落地的狂欢叙事中,技术部署的“形式追求”与行业需求的“实质适配”正在割裂。这些行业困境指向同一个技术真相:大模型的“开箱即用”本质是概率游戏,而产业应用需要确定性输出。当医疗诊断和法律判决的容错率是0,当金融决策的误差成本以亿元计,任何跳过RAG知识校准、规避微调领域适配、省略A/B测试验证的“裸奔式部署”,都是在用行业公信力为技术不确定性买单。
从”样板间”到”自住房”
面对大模型本地化部署的三重时空挤压——技术准备时间不足、领域知识消化不全、业务验证周期不够,行业大模型应用需要回归本质问题,选择正确路线:
价值锚点
- RAG不是简单的文档搜索框嫁接
- Fine Tune更非专业术语的查找替换
真正的价值增量应体现在业务关键指标的可量化、稳定性提升。
混合路径
在DeepSeek等国产模型的落地实践中,”渐进式增强”路径才是科学合理的:
- 先架设RAG应急通道:用3-5天快速部署知识检索系统,解决现有业务80%的共性需求
- 同步启动轻量化微调:通过QLoRA等技术,用20%计算资源实现核心业务逻辑内化
- 构建动态评估网络:设立A/B测试对照组,持续监测人工替代率、任务完成度等核心指标
大模型私有化部署常面临两种核心方案:RAG(检索增强生成)和Fine Tune(微调)。这两种技术路径的差异,可以用“毛坯房+明线明管”与“精装房+暗线暗管”进行简单类比。
02 技术实现难度:从“自主布线”到“专业施工”
RAG(毛坯房+明线明管)
自行规划电路和管道走向(设计检索逻辑),安装明线明管连接到供电和供水系统(部署知识库),再连接到各种家用电器(大模型用户界面)。建设周期短、成本低、灵活性高,但使用体验、稳定性相对较差。
技术核心:外挂知识库 + 检索算法(如向量检索)+ 大模型生成
实现步骤:
- 从各种来源获取文档数据,如本地文件系统、数据库、网络存储等。使用相应的文件处理库来加载文档,如LangChain中的相关加载器。
- 将加载的文档分割成较小的片段或块(Chunks)。切分的方式可以根据文档的结构和内容来确定,例如按段落、句子、标题或固定长度进行切分。
- 使用嵌入模型将切分后的文档块转换为向量表示,这些向量能够捕捉文档的语义信息。常见的嵌入模型有 Word2Vec、GloVe、BERT 等。
- 将生成的向量存储到向量数据库中,以便根据向量的相似度进行快速查询。
Fine Tune(精装房+暗线暗管)
将暗线暗管预埋于墙体(模型参数内化),需要专业施工队(算法工程师)操作。若想修改电路(更新知识),必须凿墙(重新训练模型)。相比RAG建设周期更长、成本相对较高、灵活性低,但稳定性相对较高。
技术核心:调整大模型参数(如LoRA、QLoRA) + 领域数据训练。
实现步骤:准备高质量领域数据(如法律文书、医疗报告)。选择微调方法(全参数微调或参数高效微调)。
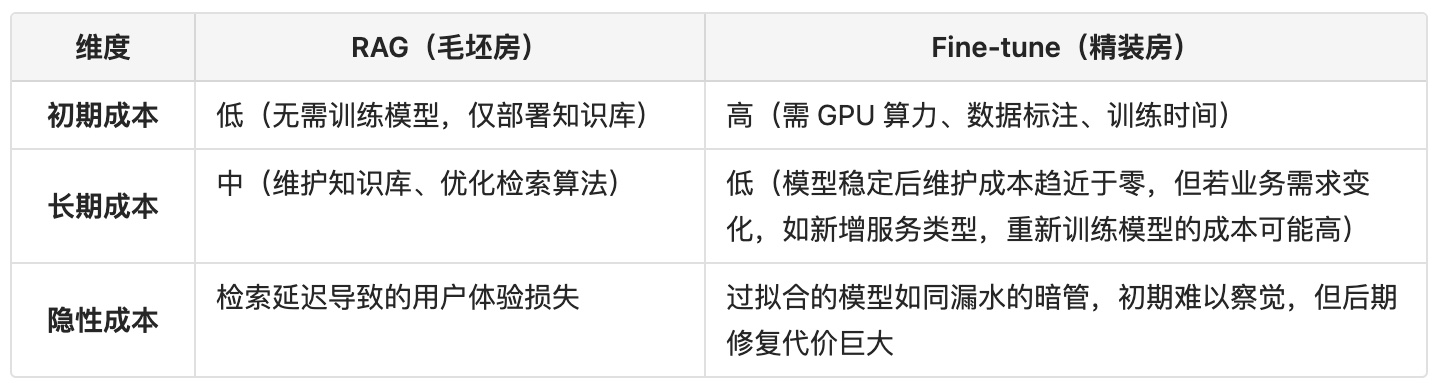
03 成本对比:短期省钱 vs 长期省心
毛坯房(RAG)初期装修便宜,但后期若频繁更换电器(更新知识库),需反复调整线路(检索策略),人工费可能累积; 精装房(Fine Tune)一次性投入高,但入住后无需操心电路(模型稳定运行),除非需要整体翻修(领域迁移)。
04 可靠性对比:外挂模块 vs 内生系统
RAG的“明线逻辑”
优势:知识库与大模型本身解耦,如果出现故障,可以及时隔离。例如检索模块宕机时,大模型仍可生成通用回答。此外,RAG还可以通过设置检索触发器等方式,优化模型输出,一定程度上减少“AI幻觉”。
风险:若知识库包含错误文档(如过期的政策文件),模型可能输出误导性内容。大模型可能过度依赖检索结果,忽略自身推理能力(如仅拼接文档片段,缺乏逻辑连贯性)。
Fine Tune的“暗线哲学”
优势:端到端的流畅体验。模型内化知识后,回答更连贯,对训练知识的“理解”更加深入和全面。
风险:模型可能死记硬背训练数据,遇到边缘案例时错误率提升,出现比较严重的“AI幻觉”。若训练数据未覆盖新场景,模型无法自主更新。
05 延展性对比:灵活改造 vs 深度固化
RAG的“乐高式扩展”
动态适配:新增知识只需上传文档,无需修改模型,适合多领域切换)。
瓶颈挑战:知识库规模膨胀后,检索效率可能下降,需优化索引结构(类似明线过多时需整理线槽)。
Fine-tune的“一体化设计”
深度定制:模型可学习领域专属逻辑。例如金融风控模型能识别“流水异常”的抽象模式,而非依赖关键词匹配。
扩展枷锁:医疗微调的模型无法直接用于法律场景(如精装商品房无法秒变办公室)。若业务分布变化(如从信用卡欺诈检测扩展到跨境支付),模型可能需推倒重来。
06 故障与误差:透明排查 vs 黑盒困境
RAG的“可见故障”
- 典型问题:检索结果不相关(如搜索“苹果”却返回水果而非公司财报),知识库覆盖不全(如缺少某款新产品的技术参数)。
- **调试方案:**检查检索算法(测试BM25权重或向量编码模型)。分析日志定位缺失数据(类似用万用表检测电路断点)。
Fine Tune的“隐蔽风险”
- 典型问题:过拟合(模型在训练集上准确率99%,但实际场景中漏洞百出)。灾难性遗忘(学习新知识后遗忘旧能力,如学会法律条款却不会写邮件)。
- 调试方案:通过对抗样本检测模型鲁棒性(压力测试电路负载);使用LoRA等参数高效微调技术局部更新(仅修补部分墙体)。
07 终极答案:没有完美方案,只有最佳适配
何时选择RAG?
- 知识高频更新:如实时新闻、市场咨询、电商产品、行业政策
- 试错成本敏感:初创企业需快速验证MVP
- 多领域需求:通用客服系统等需同时处理多领域问题的场景
何时选择Fine-tune?
- 垂直领域深耕:如医疗诊断、法律合同审查、工业质检
- 输出一致性优先:如生成标准化的财务报告、专利申请文书
- 数据资产雄厚:企业拥有数十年积累的行业标注数据
混合架构:精装房+智能中控
- 对基础模型进行轻量微调(如QLoRA),内化核心领域知识; 外接RAG补充实时数据(如客户档案、市场动态)。
08 结语:技术没有高下,场景决定成败
RAG与Fine Tune的选择,本质是“开放灵活”与“封闭可控”的永恒辩证。企业需厘清自身需求:
- 如果业务像快时尚行业——潮流瞬息万变,选RAG
- 如果业务像高端定制——追求极致体验,选Fine Tune
- 如果既要“面子”又要“里子”——混合架构才是未来
最终,这场“AI装修战役”的胜利者,永远是那些深刻理解业务痛点,并能在技术天平上精准落子的人。
本文由 @李庆宇 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务