RAG一周出Demo,半年上不了线,怎么破?
许多从业者发现,尽管RAG能在短时间内快速搭建出Demo,但在实际生产环境中落地却困难重重。本文从AI大模型领域创业者的视角出发,深入剖析了RAG在产业落地中的核心问题——问题分级,并详细探讨四类问题的挑战与解决方案,供大家参考。

很多熟悉RAG的产品经理和工程师会吐槽,“做RAG一周就可以出Demo,但真正做到能上生产环境的水平,半年时间都不够!”。
这是现阶段RAG在产业落地的现实问题。RAG框架非常简单易懂,也有很多优化RAG全流程的方式和手段,风叔在此前的文章中也做过详细介绍,《Rag系统的发展历程,从朴素、高级到模块化》。
但无论是企业内部使用,还是面向C端用户,大家最直接的感受是,RAG只能检索和回答相对浅显直观的问题。
企业知识库领域的独角兽Hebbia也曾经做过实验,RAG实际上只能解决企业内部16%的问题,这到底是什么原因呢?
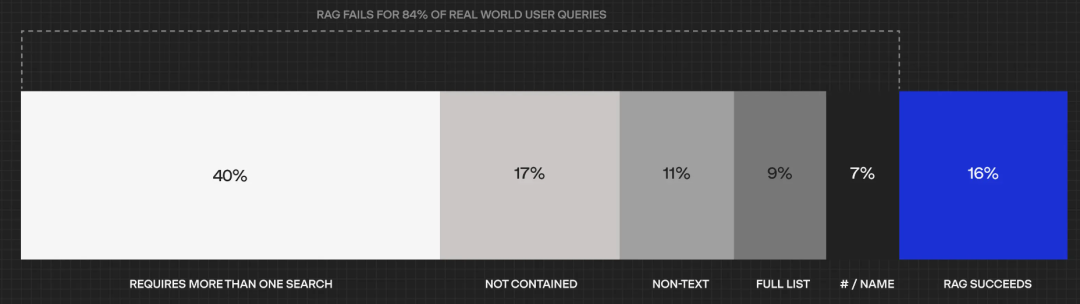
答案是问题分级。
任何用户检索问题都可以分成四类,显性事实查询、隐性事实查询、可解释性推理查询和隐性推理查询,这四类问题的复杂度和解题难度依次提升。
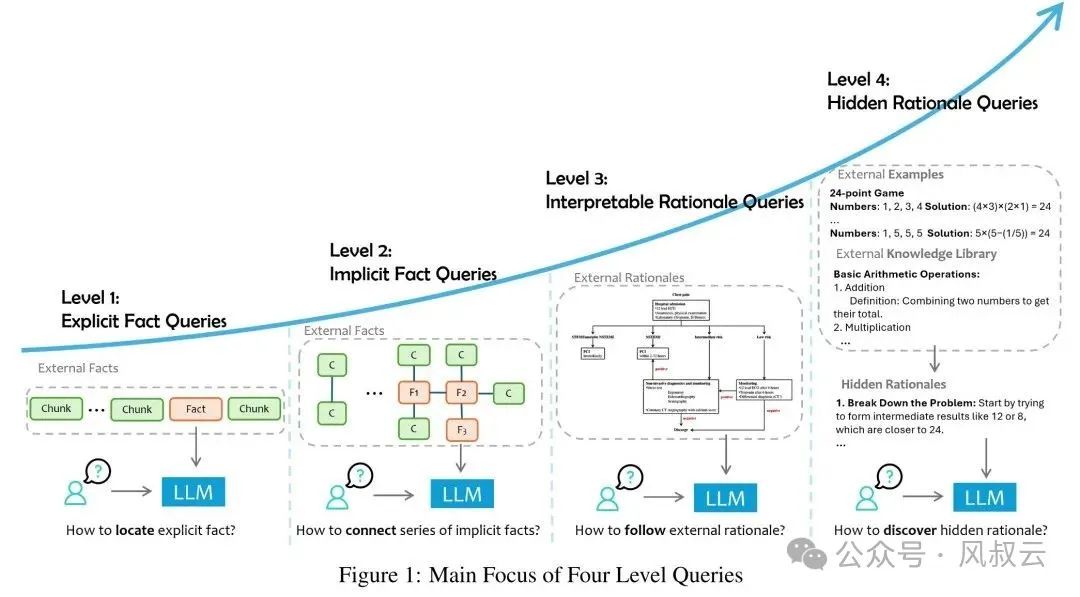
下图列出了每类问题面对的挑战和解决方法。可以看出,只有显性事实查询和部分隐性事实查询,可以通过RAG、Iterative Rag或GraphRag来解决。而可解释性推理查询和隐性推理查询问题,RAG就没有用武之地了,需要依靠其他更复杂和针对性的解决方案。
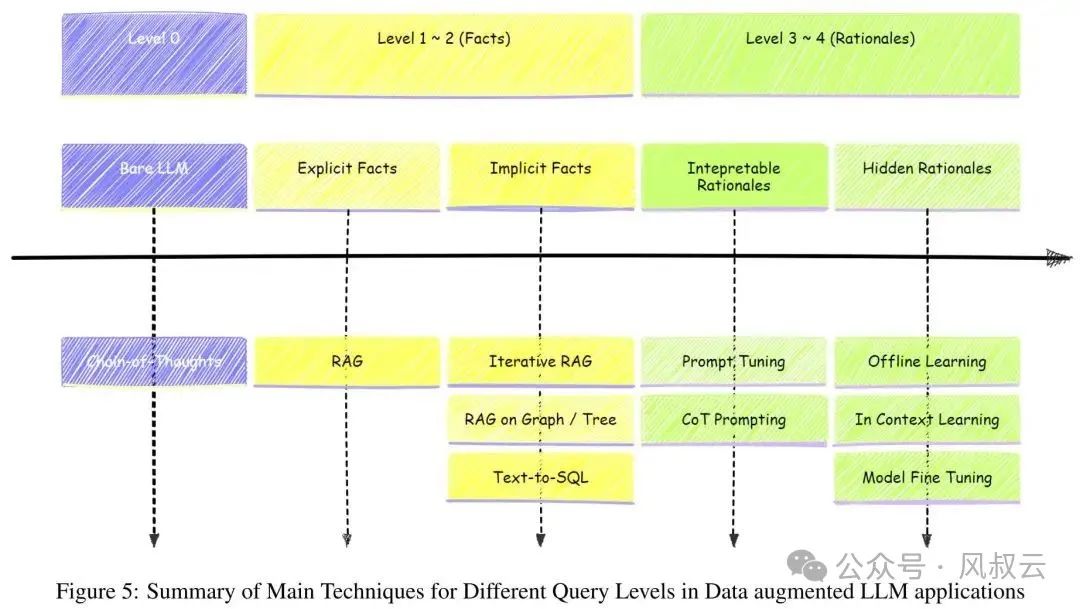
在实际企业应用场景中,绝大多数对业务部门有价值的问题都处于Level 3和Level 4,因此导致了“RAG一周出Demo,半年上不了线”的窘境。
接下来,风叔将详细阐述这四类问题的特点和解决方案。看到最后,相信你一定会有收获!
一、显性事实查询
显性事实是指外部数据中直接存在的事实信息或数据,不需要进行额外的推理。比如“2016年奥运会在哪里举办的?”、“某传感器的品牌和工作温度是多少?”、“门店A上个月的营业额是多少?”。
显性事实查询是最简单的查询形式,直接从提供的数据中检索到明确的事实信息,不需要复杂的推理和思考,因此非常适合使用RAG。
当然,要准确、高效地检索和生成相关内容,还需要对RAG系统进行优化。可以通过风叔之前介绍的方法,这里再做个简单的回顾。
索引构建
- 块优化:通过滑动窗口、增加元数据、从小到大等方式,更加合理地对内容块的大小、结构和相关性进行分块。
- 多级索引:指创建两个索引,一个由文档摘要组成,另一个由文档块组成,并分两步搜索,首先通过摘要过滤掉相关文档,然后只在这个相关组内进行搜索。
- 知识图谱:提取实体以及实体之间的关系,构建一种全局性的信息优势,从而提升RAG的精确度。
预检索
- 多查询:借助提示工程通过大型语言模型来扩展查询,将原始Query扩展成多个相似的Query,然后并行执行。
- 子查询:通过分解和规划复杂问题,将原始Query分解成为多个子问题,最后再进行汇总合并。
- 查询转换:将用户的原始查询转换成一种新的查询内容后,再进行检索生成。
- 查询构建:将自然语言的Query,转化为某种特定机器或软件能理解的语言,比如text2SQL、text2Cypher。
检索
- 稀疏检索器:用统计方法将查询和文档转化为稀疏向量。其优势在于处理大型数据集时效率高,只关注非零元素。
- 密集检索器:使用预训练的语言模型(PLMs)为查询和文档提供密集表示,尽管计算和存储成本较高,却能提供更复杂的语义表示
- 检索器微调:基于有标记的领域数据微调检索模型,通常借助对比学习来实现
检索后
- 重排序:对于检索到的内容块,使用专门的排序模型,重新计算上下文的相关性得分。
- 压缩:对于检索到的内容块,不要直接输入大模型,而是先删除无关内容并突出重要上下文,从而减少整体提示长度,降低冗余信息对大模型的干扰。
二、隐性事实查询
隐性事实并不会直接在原始数据中显现,需要少量的推理和逻辑判断。而且推导隐性事实的信息可能分散在多个段落或数据表中,因此需要跨文档检索或跨表查询。
比如,“查询过去一个月营收增长率最高的门店”,就是一个典型的隐性事实查询。需要先获取所有门店这个月和上个月的营收,然后计算每个门店的营收增长率,最后排序得出结果。
隐性事实查询的主要挑战是,不同问题依赖的数据源和推理逻辑都各不相同,如何保障大模型在推理过程中的泛化性。
隐性事实查询的主要解题思路包括以下方法:
多跳检索和推理
Iterative Rag:在检索前先生成检索计划,然后在检索过程中不断根据检索结果进行优化。比如利用ReAct框架,沿着Thought – Action – Observation的分析思路,逐步逼近正确答案。
Self-Rag:构建四个关键的评分器,即检索需求评分器、检索相关性评分器、生成相关性评分器和回答质量评分器,从而让大模型自主决定何时开始检索、何时借助外部搜索工具、何时输出最终答案。
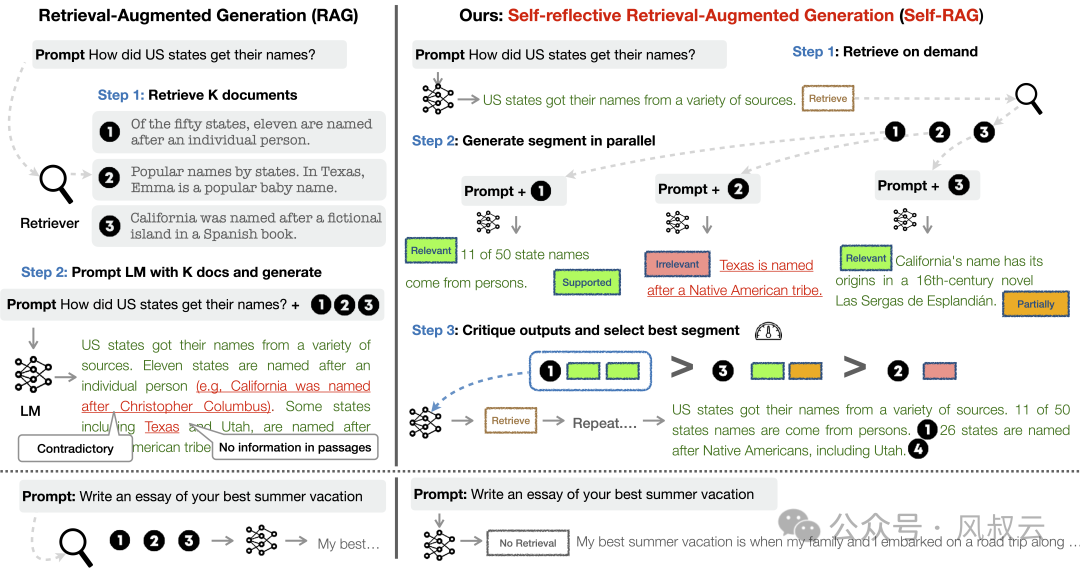
利用图和树结构
Raptor:RAPTOR 根据向量递归地对文本块进行聚类,并生成这些聚类的文本摘要,从而自下而上构建一棵树。聚集在一起的节点是兄弟节点;父节点包含该集群的文本摘要。这种结构使 RAPTOR 能够将代表不同级别文本的上下文块加载到 LLM 的上下文中,以便能够有效且高效地回答不同层面的问题。
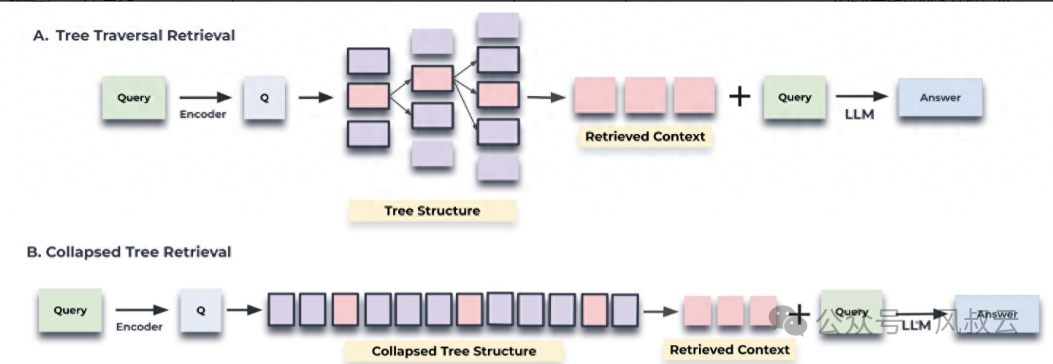
GraphRag:一种将知识图谱与Rag相结合的技术范式。传统Rag是对向量数据库进行检索,而GraphRag则对存储在图数据库中的知识图谱进行检索,获得关联知识并实现增强生成。
将自然语言转换成SQL查询
text2SQL:主要用于数据库查询,尤其是多表查询场景,可参考《一文读懂ChatBI的实现难点与解决方案,问答准确率超过99%》
三、可解释性推理
可解释性推理,是指无法从显性事实和隐性事实中获取,需要综合多方数据进行较为复杂的推理、归纳和总结的问题,并且推理过程具备业务可解释性。
ChatBI中的归因分析,就是典型的可解释性推理,比如”过去一个月,华南区域营收下滑5%的原因是什么?“。这个问题无法直接获取,但可以通过一定方式进行推理,如下所示:
总营收 = 新客 * 转化率 * 客单价 + 老客 * 复购率 * 客单价
经过分析,新客数量、转化率和客单价并未发生明显变化,而老客复购率下滑约10%,因此可以推断出可能是”服务质量、竞品竞争“等原因,引起了老客复购率的下滑,从而导致了总营收的下降。
可解释性推理问题主要有两个挑战,多样化的提示词和有限的可解释性。
- 多样化的提示词:不同的查询问题,需要特定的业务知识和决策依据。比如推理营收下滑的原因可以用上述的业务规则,但如果是推理毛利率下滑的原因,就需要另一种业务规则。这种多样化的规则沉淀,既需要行业专家进行梳理和沉淀,也需要将其转换为合适的提示词,让大模型理解背后的逻辑。
- 有限的可解释性:提示词对于大模型的影响是不透明的,我们很难评估提示词对模型的影响,因此会妨碍我们构建一致的可解释性
面对这样的挑战,风叔主要有以下建议:
提示词工程优化
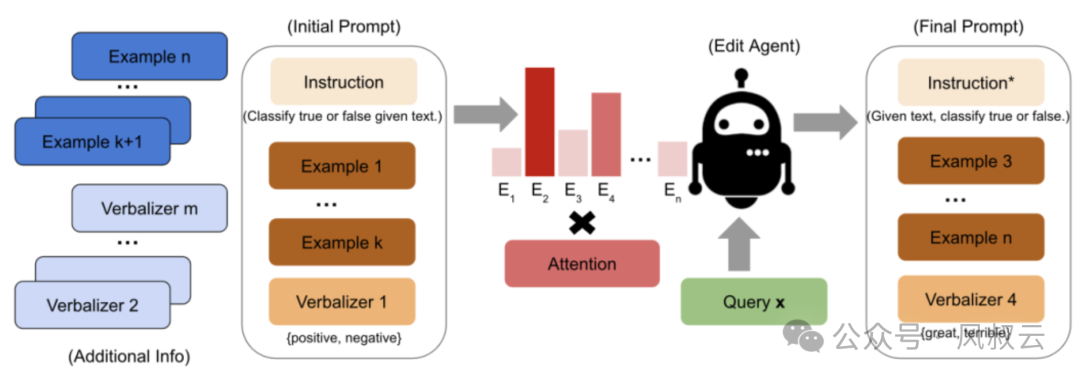
优化提示词:需要有效地将业务推理逻辑,整合到大语言模型中,比较考验提示词设计人员的行业know-how。
提示词微调:手动设计提示词会很耗时,可以通过提示词微调技术解决这个问题。比如通过强化学习,将大模型生成正确回答的概率作为奖励,指导模型在不同数据集上发现最佳提示词配置。
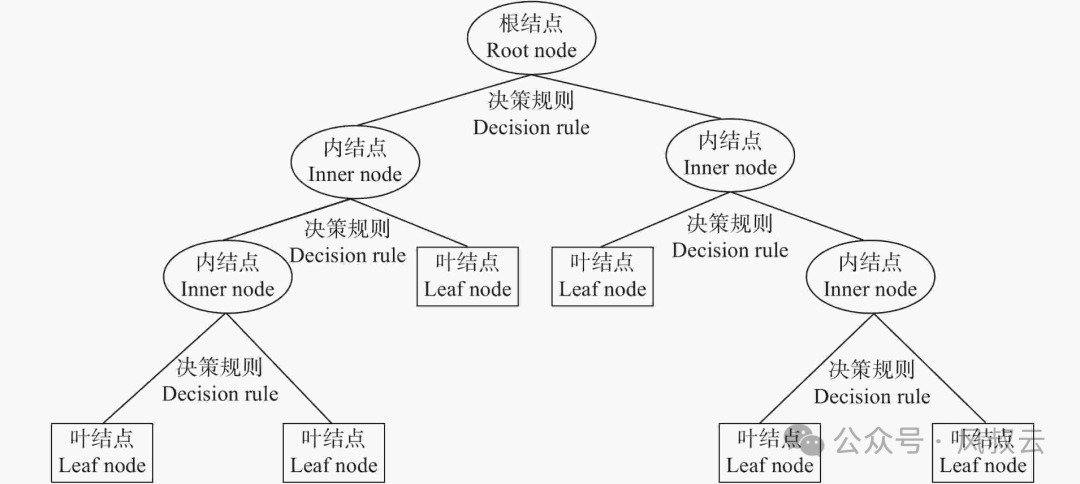
构建决策树
**决策树:**将决策流程转换为状态机、决策树或伪代码,让大模型执行。比如在设备运维领域,构建故障树就是一种非常有效的故障检测方案。
利用智能体工作流
Agentic Workflow:通过workflow构建大模型思考和行动的具体步骤,从而约束大模型的思考方向。这种方法的优点是能够提供相对稳定的输出,但缺点是灵活性不足,同样需要针对每类问题设计工作流。
四、隐性推理查询
隐性推理查询,是指难以通过事先约定的业务规则或决策逻辑进行判断,而必须从外部数据中进行观察和分析,最终推理出结论。
比如IT智能运维,并不存在先验的完整文档,详细记录每种问题的处理方法和规则,只有运维团队过去处理的各种故障事件和解决方案。大模型需要从这些数据中挖掘出针对不同故障的最佳处理方案,这就是隐性推理查询。
同样,在产线智能运维、智能量化交易等场景中,都涉及大量的隐性推理查询问题。
隐性推理问题的主要挑战是逻辑提炼困难、数据分散和不足,是最为复杂和困难的问题。
- **逻辑提炼困难:**在海量数据中挖掘隐性逻辑,需要开发复杂且有效的算法,能够解析和识别隐藏在数据背后的逻辑。因此,仅依靠表面的语义相似性是远远不够的,需要构建专门的小模型来应对。
- **数据分散和不足:**隐性逻辑往往隐藏在非常分散的知识中,因此要求模型具备强大的数据挖掘和综合推理能力。同时,当外部数据有限或者数据质量不满足要求时,也很难从中挖掘出有价值的信息。
对于隐性推理问题所面临的挑战,有以下解题思路:
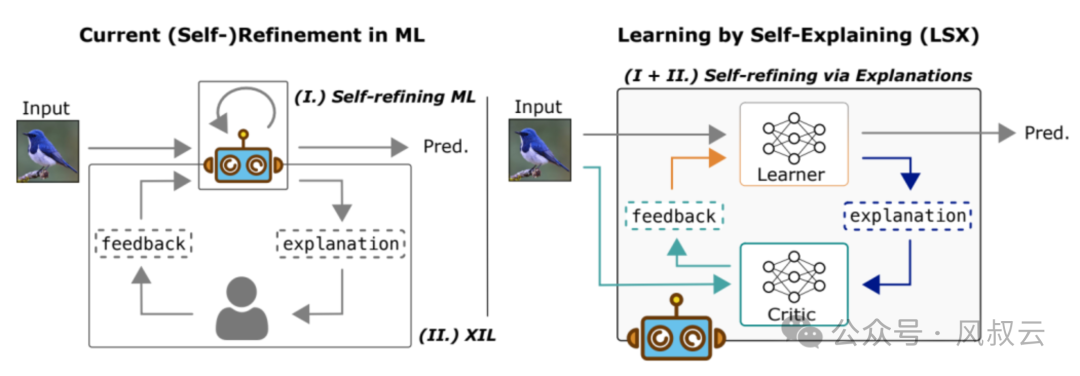
- 机器学习:通过传统的机器学习方法,从历史数据和案例中总结出潜在的规则。
- 上下文学习:在提示中涵盖相关的示例,给模型进行参考。但是这种方法的缺陷在于,如何让大模型掌握其训练领域之外的推理能力。
- 模型微调:通过大量业务数据和案例数据,对模型进行微调,将领域知识进行内化。但是这种方法的资源耗费比较大,中小企业谨慎使用。
- 强化学习:通过奖励机制,鼓励模型产生最符合业务实际的推理逻辑和答案。
五、总结
在本篇文章中,针对Rag上手容易上线难的问题,风叔介绍了用户检索的四类问题,以及每类问题对应的解题思路。
对于显性事实查询和隐性事实查询类问题,可以通过多种Rag优化方案来解决。但是,面对可解释性推理和隐性推理问题时,只使用RAG就会力不从心了,需要引入提示词工程、决策树、Agentic Workflow、机器学习、模型微调和强化学习等多种方法。
其中每个方法要详细展开阐述的话,都可以单独写一个系列。因此,本文只是先抛出这些解题方向,不做展开。后续有时间,风叔再结合实际案例做详细介绍。
本文由人人都是产品经理作者【风叔】,微信公众号:【风叔云】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。