谈谈分布式锁
不要使用分布式锁
 就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。
就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。
有的逻辑是没有副作用的(纯函数代码),那就可以无锁执行;有的数据经过合理的 sharding 之后,可以使用单线程(单节点)执行,那就单线程执行。
比如一种常见的模式就是使用 queue(比如 Kafka),任务全部放到队列中,然后根据 sharding 的逻辑,不同的 consumer 来处理不同的任务,互相之间不会干扰冲突。
还有一个例子是 Kotlin Coroutine,通过指定一个单线程的 dispatcher,也可以保证它执行的操作之间互相不会有多线程的冲突问题。
有了这样的原则以后,再来谈谈几种分布式锁。
数据库锁
分布式系统中,我觉得我们最常见的锁就是使用一个中心数据库来做的。
一种是悲观锁,就是 “select xxx … for update” 这样的,相应的数据行会被锁上,直到 commit/rollback 操作发生。如果被别人锁了,当前线程没得到锁的话就会等着。
还有一种是乐观锁,就是使用版本号,“update … where … version=A” 这样的。如果 update 成功,表示获取锁成功,并且操作也成功;否则就是 update 失败,需要重新获取状态再来操作一遍。
大多数情况下,后者要更高效一些,因为阻塞的时间通常更短,不过在锁竞争比较激烈的情况下,反而效率会反过来。另外一个,悲观锁代码写起来会容易一些,因为 select 语句执行和 commit/rollback 是两步操作,因此二者之间可以放置任意逻辑;而乐观锁则是需要把数据的写操作和 version 的比较放在一条语句里面。
这两种都很常见,基本上我接触过的一半以上的项目都用过两者。这个数据库不一定非得是关系数据库,但是强一致性必须是保证的。
S3
使用 S3 来创建文件,让创建成功的节点得到锁,文件里面也可以放自定义的内容。我们去年的项目用到这个机制。这种方式是建立在 S3 2020 年 12 月 1 日,上线的 strong consistency 的 feature。
大致上,有这样两种思路:
- 使用 S3 versioning,就是说,在 versioning 打开的情况下,文件的写入不会有 “覆盖” 的情况发生,所有内容都会保留。在创建文件的时候,response 种会有一个 x-amz-version-id header。节点写入文件后,再 list 一下所有的 version,默认这些 version 会根据创建的时间顺序递减排列,后创建的在前,因此比较其中最早的那个 version 和自己创建文件后得到的 version,如果两者相等,说明自己得到了锁。
- 使用 S3 Object Lock,这个可以控制让第一次写成功,后面的操作全部失败,所以第一次写入成功的节点得到锁。
使用这种方式,对于那些本来就需要使用 S3 文件系统来共享任意信息的情况很方便,但是需要自己处理超时的问题,还有 retention 策略(该不该/什么时候删掉文件)。
Redlock
Redlock 就是 Redis 的锁机制。Martin Kleppmann(就是那个写《Design Data-Intensive Applications》的作者)几年前写过一篇文章,来吐槽 Redlock 在几种情况下是有问题的:
- Clock jump:Redlock 依赖于物理时钟,而物理时钟有可能会跳(jump),并且这种状况是无法预测的。Clock jump 就是说,始终会不断进行同步,而同步回来的时间,是有可能不等于当前时间的,那么系统就会设置当前时间到这个新同步回来的时间。在这种情况下,依赖于物理时间的锁逻辑(比如超时的判断等等)就是不正确的。
- Process pause:得到锁的节点,它的运行是有可能被阻塞的。比如 GC,下面这个图说的就是这个情况——client 1 一开始得到锁了,执行过程中有一个超长时间的 pause,这个 pause 导致锁超时并被强制释放,client 2 就得到锁了,之后 client 1 GC 结束,缓过来后恢复执行,它却并没有意识到,它的锁已经被剥夺了,于是 client 1 和 client 2 都得到了锁,对于数据的修改就会发生冲突。
- Network delay:其实原理和上面差不多,网络延迟+锁超时被强制剥夺和重分配的逻辑,在特定情况下就是不正确的。
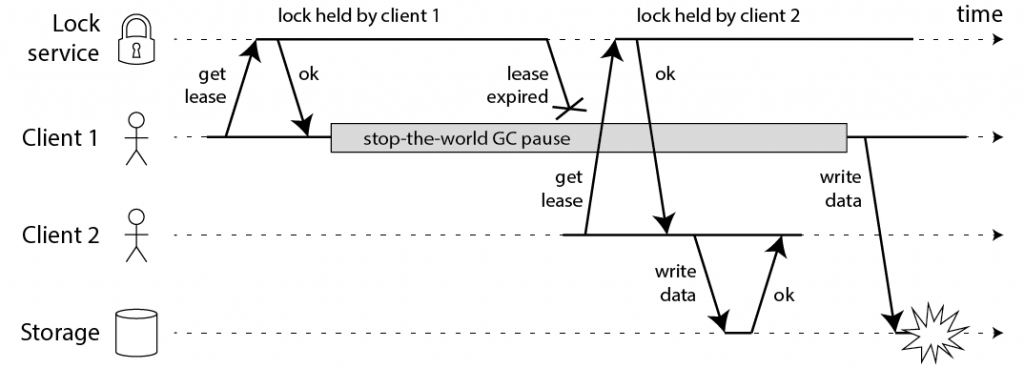
问题可以理解,可是仔细想想这个问题的本质是什么?它的本质其实就是消息延迟+重排序的问题,或者更本质地说,就是分布式系统不同节点保持 consistency 的问题,因为 lock service 和 client 就是不同的节点,lock service 认为之前的锁过期了,并重分配锁给了 client 2,并且 client 2 也是这样认为的,可是 client 1 却不是,它在 GC 之后认为它还持有者锁呢。
如果我们把数据的写操作和锁管理的操作彻底分开,这个问题就很难解决,因为两个节点不可能 “一直” 在通信,在不通信的时间段内,就可能会发生这种理解不一致的情况。但是如果我们把写操作和锁管理以某种方式联系上,那么这个问题还是可以被解决的。简单说,就是物理时钟不可靠,逻辑时钟可以解决这个问题。
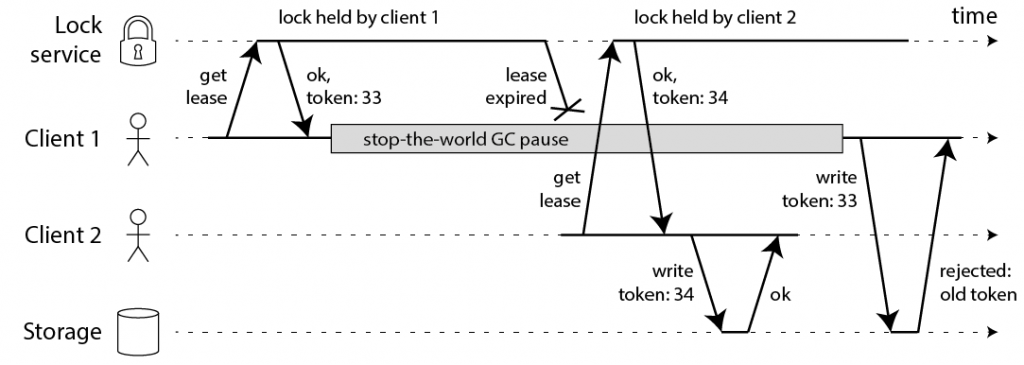
之后 Martin Kleppmann 提出了解决方案,他的解决方案也就是按照这个思路进行的。他的方法很简单,就是在获取锁的时候,得到一个永远递增的 token(可以被称作 “fencing token”),在执行写操作的时候,必须带上这个 token。如果 storage 看到了比当前 token 更小的 token,那么那个写操作就要被丢弃掉。
Chubby
Chubby 是 Google 的分布式锁系统,论文在这里可以找到,还有这个胶片,对于进一步理解论文很有帮助。从时间上看,它是比较早的。
Chubby 被设计成用于粗粒度的(coarse-grained)锁需求,而非细粒度(fine-grained,比如几秒钟以内的)的锁需求。对于这样一个系统,文中开始就提到 consistency 和 availablity 重要性要大过 performance,后面再次提到首要目标包括 reliability,能够应对较多数量的 clients,和易于理解的语义,而吞吐量和存储容量被列在了第二位。
Chubby 暴露一个文件系统接口,每一个文件或者文件夹都可以视作一个读写锁,文件系统和 Unix 的设计思路一致,包括命名、权限等等的设计都是基于它。这是一个很有意思的设计。
对于一致性的达成,它使用 Paxos,客户端寻找 master 和写数据都使用 quorum 的机制,保证写的时候大部分节点成功,而读的时候则是至少成功读取大部分节点(R+W>N,这个思路最早我记得是 Dynamo 的论文里面有写);如果 lock 有了变化,它还提供有通知机制,因为 poll 的成本太高。
内部实现上面,每一个 Chubby 的 cell 都是由作为 replica 的 5 个服务节点组成,它们使用 Paxos 来选举 master 和达成一致,读写都只在 master 上进行(这个看起来还是挺奢侈的,一个干活,四个看戏)。如果 master 挂掉了,在 master lease 过了以后,会重新选举。Client 根据 DNS 的解析,会访问到该 cell 里面的某一个节点,它不一定是 master,但是它会告知谁是 master。
分布式锁里面比较难处理的问题不是失败,而是无响应或者响应慢的超时问题。Chubby 采用一种租约的机制,在租约期内,不会轻易变动当前的 master 节点决定。在响应超时的时期,客户端的策略就是 “不轻举妄动”,耐心等待一段时间等服务端恢复,再不行才宣告失败:
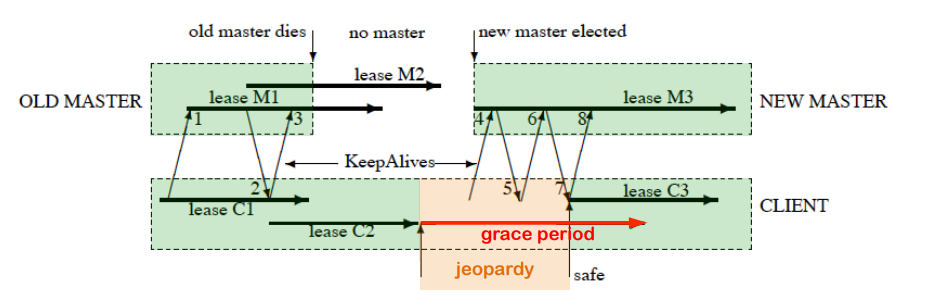
这个图的大致意思是,第一次租约 C1 续订没有问题;第二次租约续订 C2 了之后,原来的 master 挂了,心跳请求无响应,这种情况客户端不清楚服务端的状况,就比较难处理,于是它只能暂时先阻塞所有的操作,等到 C2 过期了之后,有一个 grace period;接着再 grace period 之内,新的 master 被选举出来了,心跳就恢复了,之后租约续订的 C3 顺利进行。
这显然是一个异常情形,但是一旦这种情况发生,系统是被 block 住的,会有非常大的延迟问题。思考一下,这种情况其实就是从原来的 master 到新的 master 转换的选举和交接期间,锁服务是 “暂停” 的。再进一步,这个事情的本质,其实就是在分布式系统中,CAP 原理告诉我们,为了保证 Consistency 和 Partition Tolerance,这里的情形下牺牲掉了 Availability;同时,为了保证 consistency,很难去兼顾 performance(latency 和 throughput)。
此外,有一个有点反直觉的设计是,Chubby 客户端是设计有缓存的。通常来讲,我们设计一个锁机制,第一印象就是使用缓存会带来复杂性,因为缓存会带来一致性的难题。不过它的解决办法是,使用租约。在租约期内,服务端的锁数据不可以被修改,如果要修改,那么就要同步阻塞操作通知所有的客户端,以让缓存全部失效(如果联系不上客户端那就要等过期了)。很多分布式系统都是采用 poll 的方案——一堆 client 去 poll 一个核心服务(资源),但是 Chubby 彻底反过来了,其中一个原因也是低 throughput 的考虑,毕竟只有一个 master 在干活。
对于前面提到的 Martin Kleppmann 谈到的那个问题,Chubby 给了两个解决方法:
- 一个是锁延迟,就是说,如果一切正常,那么持有锁的客户端在释放掉锁之后,另外的客户端可以立即获取锁。但是如果出现超时等等异常,这个锁必须被空置一段时间才可以被分配。这个方法可以降低这个问题出现的概率,但是不能彻底规避问题。
- 第二个就是使用序列号了,对于写入操作来说,如果请求携带的序列号要小于前一次写入的序列号,那就丢弃请求,返回失败。
回过头思考 Chubby 的实现机制,我觉得有这样几个启发:
- 不要相信任何 “人”(节点),必须询问到多数人(quorum),多数人的结论才可以认为是正确的。这个方式发生在很多操作上,比如寻找 master,比如选举 master,比如写数据。
- 超时是很难处理的,它采用了租约的机制保证节点丢失时间的上限,使用 grace period 来容忍 master 选举发生的时延,使用序列号来保证正确性。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》